Show HN Today: Discover the Latest Innovative Projects from the Developer Community
 ShowHN Today
ShowHN Today
- Continue with Google
Show HN 今日精选:2025-11-14最热门的开发者项目展示
SagaSu777 2025-11-15
探索2025-11-14 Show HN上最热门的开发者项目,包括创新技术、AI应用等激动人心的新发明。深入了解这些引人注目的项目!
今日内容汇总
趋势洞察
今天的 Show HN 板块展示了技术创新的蓬勃生命力,特别是围绕 AI 和开发者效率的趋势尤为突出。AI Agent 的开发与应用正以前所未有的速度扩展,从构建智能客服到代码助手,再到自动化部署的工具,都体现了 AI 正在深刻改变我们的工作方式。值得注意的是,本地化 AI 模型和对隐私的关注正在成为一股重要力量,开发者们正在努力在强大的 AI 能力和数据安全之间找到平衡。此外,各类开发者工具的涌现,无论是代码生成、自动化部署、还是高效的代码审查,都彰显了开发者们对提升效率和简化复杂流程的不懈追求。这些创新不仅为开发者提供了更强大的武器,也为创业者们打开了新的机遇之门,抓住这些趋势,用技术赋能更多可能,是未来技术发展的关键。
今日最热门产品
名称
Encore – Type-safe back end framework that generates infra from code
亮点
Encore 框架的核心创新在于其“代码即基础设施”的理念。它通过提供类型安全的后端开发体验,能够自动生成部署所需的基础设施配置。这极大地简化了后端开发的复杂性,将开发者从繁琐的基础设施管理中解放出来,让他们可以更专注于业务逻辑的实现。开发者可以学习到如何通过代码的声明式定义,自动化基础设施的配置和部署,这在微服务和云原生架构中具有极高的应用价值。
热门类别
AI & 机器学习
开发者工具
基础设施 & DevOps
数据工程
编程语言 & 框架
热门关键字
AI
LLM
Kubernetes
代码生成
自动化
框架
数据
技术趋势
AI Agent 框架与应用
本地化 AI 模型与隐私保护
代码生成与自动化部署
数据工程与分析工具
开发者效率工具
跨平台应用开发
AI 在特定领域(如嵌入式、数据科学)的应用
项目分布
AI & 机器学习 (30%)
开发者工具 (25%)
基础设施 & DevOps (15%)
编程语言 & 框架 (10%)
数据工程 (10%)
其他 (10%)
今日热度产品榜单
| 排名 | 产品名称 | 点赞数 | 评论数 |
|---|---|---|---|
| 1 | EpsteinFiles SearchQuery | 277 | 45 |
| 2 | Encore: 代码驱动的基础设施生成器 | 71 | 47 |
| 3 | 欧陆智讯:多语言欧洲科技聚合与洞察 | 42 | 39 |
| 4 | Pegma: 经典跳棋的开源复兴 | 32 | 48 |
| 5 | 奇思妙想集思广益生成器 | 33 | 30 |
| 6 | Chirp 本地语音输入助手 | 29 | 15 |
| 7 | 缠斗具象:可视化柔术学习指南 | 7 | 10 |
| 8 | spymux: 跨终端视图监视器 | 9 | 3 |
| 9 | TalkiTo:语音交互终端代码助手 | 5 | 5 |
| 10 | DataGuard AI: 智能数据管道守护者 | 6 | 4 |
1
EpsteinFiles SearchQuery
作者
searchepstein
描述
这是一个将公开的、分散的Epstein相关文件进行整理、索引并提供搜索功能的项目。它通过技术手段,让原本难以查找和理解的信息变得易于检索和分析,旨在提高信息透明度和辅助研究。核心创新在于对非结构化数据的处理和构建一个高效的查询系统。
人气
点赞 277
评论数 45
这个产品是什么?
这是一个利用编程技术,把大量关于Epstein事件的公开文件(比如扫描的文档、报告等)梳理成一个可以快速搜索的数据库。它解决了信息分散、难以查找的问题。技术上,它可能涉及到文件解析、文本提取(OCR)、数据索引(例如使用Elasticsearch等)、以及一个用户友好的搜索界面。其创新之处在于将复杂、杂乱的数据转化为有组织、可查询的知识资产。
如何使用它?
开发者可以将其作为一个数据分析工具,通过API接口集成到自己的研究项目或数据可视化平台中。例如,可以构建一个专门分析特定人物关联性的工具,或者追踪信息传播路径的可视化应用。它允许研究人员或任何对该事件感兴趣的人,通过关键词快速定位相关文档,从而节省大量人工阅读和筛选的时间。
产品核心功能
· 文件解析与文本提取:将不同格式的原始文件(如PDF、图片)转换成可搜索的文本,这是项目的基础,让看不懂的文档变成能被机器理解的数据。
· 数据索引与搜索:建立一个高效的索引系统,就像一本高质量的书的目录,能够快速找到包含特定关键词的文档,极大地提高了查找效率。
· 信息组织与关联:将文件内容中的人名、组织机构等关键信息进行结构化处理,方便用户探索文件之间的关联性,发现隐藏的模式。
· 透明化信息访问:提供一个开放的平台,让公众和研究者能够更便捷地获取和分析与Epstein事件相关的信息,促进信息公开和研究的深入。
产品使用案例
· 研究人员使用该项目来快速找出某个特定人物在所有文件中出现的频率和上下文,从而加速研究进程。
· 记者可以利用这个工具来验证信息,快速定位与某个事件相关的原始证据,提高报道的准确性。
· 普通用户可以通过输入关键词,轻松找到自己感兴趣的关于Epstein事件的信息片段,了解事件的细节,理解“这对我有什么用”就是让我能更快、更准地找到我关心的信息。
· 构建一个交互式的时间线,展示文件中提及的事件发生顺序和参与人员,帮助理解事件的演变过程。
2
Encore: 代码驱动的基础设施生成器
作者
andout_
描述
Encore 是一个新颖的后端框架,它最大的亮点在于能够根据你编写的代码,自动生成运行所需的基础设施。这解决了开发者需要花费大量时间配置服务器、数据库、网络等繁琐工作的痛点,让开发者能够更专注于业务逻辑的实现。它的核心创新在于将基础设施的管理“代码化”,让基础设施变得像代码一样可控、可版本化。
人气
点赞 71
评论数 47
这个产品是什么?
Encore 是一个后端开发框架,它最酷的地方在于,你只需用它的方式写好你的服务代码,它就能帮你自动创建和配置好部署这些服务所需的一切“幕后工作”,比如服务器、数据库、API接口、权限控制等等。这就像是你画了一张蓝图(你的代码),然后Encore会自动帮你把房子建好,而不是让你自己一块砖一块砖地砌。它的技术原理是将你的服务代码解析成一种中间表示,然后根据这个中间表示,调用云服务商(比如AWS、GCP)提供的API,自动创建和管理各种基础设施资源。这种“基础设施即代码”的理念,让原本复杂且容易出错的基础设施管理变得简单、可靠,而且可重复。
如何使用它?
开发者可以使用 Encore 的特定语法来编写后端服务,这些服务可以是API接口、定时任务、消息队列处理器等等。一旦你写好了代码,并通过 Encore 的命令行工具进行构建(build),Encore 就会自动识别出你的服务需要哪些基础设施(比如需要一个数据库来存储数据,需要一个API网关来对外提供服务),然后自动调用云平台的API来创建、配置和部署这些基础设施。你可以想象成,你写完一个功能,然后执行一个“部署”命令,Encore就会把所有跑起来所需的东西都准备好。这大大简化了从开发到上线的流程,尤其适合快速迭代和构建微服务。
产品核心功能
· 代码驱动的基础设施生成: 开发者用 Encore 的特定语法写代码,Encore 自动识别并创建数据库、API 网关、认证服务等运行所需的基础设施。这让开发者无需手动配置复杂的云服务,极大地节省了时间,让精力集中在业务功能上。
· 类型安全的服务开发: Encore 强调代码的类型安全,这意味着在开发过程中,编译器会帮你检查出很多潜在的错误,减少运行时出现问题的几率。这提高了代码的健壮性和可维护性,最终交付的产品质量更高。
· 全栈开发集成: Encore 支持连接前端和后端,它生成的 API 接口可以直接被前端框架使用,并且能自动生成前端调用接口的代码。这使得全栈开发更加流畅,前后端协作效率显著提升。
· 自动部署和环境管理: Encore 可以自动处理服务的部署和不同环境(开发、测试、生产)的管理。开发者只需关注代码,剩下的部署和环境配置都交给 Encore,极大地降低了部署的复杂度和出错率。
产品使用案例
· 快速原型开发: 当你需要快速搭建一个具有数据存储和API接口的后端服务进行原型验证时,使用 Encore 可以让你在极短的时间内完成从代码编写到服务上线的全过程,快速验证你的想法。
· 微服务架构搭建: 对于需要构建复杂微服务系统的项目,Encore 可以自动化生成每个微服务所需的基础设施,并管理服务之间的通信和依赖,大大减轻了微服务开发的运维负担,让团队可以更专注于业务拆分和逻辑实现。
· 后端API开发: 如果你的核心工作是构建RESTful API,Encore 可以帮你自动生成API接口、处理请求路由、数据验证以及与数据库的交互,让API开发更加高效,并且确保API的安全性和稳定性。
· 内部工具和SaaS产品开发: 无论是开发公司内部使用的管理工具,还是面向外部用户的SaaS产品,Encore 都能提供一个快速、可靠的后端开发环境,将精力从基础设施维护转移到用户价值创造上。
3
欧陆智讯:多语言欧洲科技聚合与洞察
作者
Merinov
描述
一个能用6种欧洲语言(英、德、法、西、意、荷)聚合欧洲科技新闻的项目,并能根据受众(消费者、企业、政府)进行筛选,帮助用户发现欧洲本土的优秀科技产品和解决方案。其核心创新在于运用了模式化AI图像生成,以提供更具多样性和语境相关的视觉内容,并针对新网站推出了渐进式站点地图增长策略,有效提升内容被搜索引擎收录的速度。同时,它还建立了自动化的多语言新闻摘要和翻译流程,并通过人工审核保证质量。
人气
点赞 42
评论数 39
这个产品是什么?
这是一个基于Web的多语言科技新闻聚合平台,它解决了在海量信息中快速定位欧洲本土科技产品和解决方案的难题。技术上的亮点包括:
1. 模式化AI图像生成:不同于千篇一律的AI图像,它根据新闻内容(如融资新闻对应金币/合同,安全新闻对应锁/盾牌)预设了60多种视觉模式,让每条新闻的配图更具相关性和独特性,提升了用户浏览的吸引力。
2. 渐进式站点地图增长:针对新网站内容快速增加但搜索引擎收录慢的问题,它采用动态的站点地图(sitemap)策略,初期只暴露少量最新文章,随着网站“资历”增加,逐步增加暴露的文章数量,显著提高了内容被Google等搜索引擎收录的比例。
3. 自动化多语言翻译:通过RSS聚合新闻,利用AI进行摘要和翻译,并结合语境提示(context-aware prompts),然后由人工进行审核,旨在提供高质量的多语言内容,方便不同语言的用户理解。
所以,它对你意味着,即使你不懂德语或法语,也能轻松了解到欧洲最前沿的科技动态和创新公司。]
如何使用它?
开发者可以像使用任何新闻聚合网站一样使用它:
1. 访问产品网站:通过浏览器访问项目提供的URL。
2. 选择语言和受众:根据你的需求,选择你想要阅读的语言(EN, DE, FR, ES, IT, NL),以及你关心的受众类型(消费者、企业、政府)。
3. 浏览和筛选:平台会展示符合你选择条件的科技新闻,你可以通过关键词搜索或进一步筛选来找到你感兴趣的具体内容。
技术上,你可以借鉴其站点地图增长策略来优化自己的新网站SEO,或者研究其AI图像生成方法来为自己的内容增加更多创意和个性化视觉元素。项目的后端使用Next.js 15 (Turbopack)和PostgreSQL,对于熟悉这些技术栈的开发者来说,可以直接研究其代码实现。
所以,它对你意味着,你可以快速找到欧洲的科技资讯,并且可以从中学习到如何让自己的网站或内容在搜索引擎中表现更好,或者如何用AI生成更有吸引力的图片。
产品核心功能
· 多语言新闻聚合:支持英、德、法、西、意、荷六种语言,让不同语言背景的用户都能获取欧洲科技资讯,价值在于打破语言障碍,拓展信息获取渠道。
· 受众筛选:可按消费者、企业、政府等维度筛选新闻,帮助用户精准定位与自身利益最相关的信息,价值在于提高信息效率,避免信息过载。
· 模式化AI图像生成:根据新闻内容生成多样化、语境相关的AI配图,相比通用AI图,更具视觉吸引力和信息传达效率,价值在于提升用户体验和内容吸引力。
· 渐进式站点地图增长:通过动态调整站点地图暴露的文章数量,有效提高新内容被搜索引擎收录的速度,价值在于帮助网站快速获得曝光,实现更好的SEO效果。
· 自动化多语言翻译与摘要:利用AI技术对新闻进行摘要和多语言翻译,并辅以人工审核,确保内容准确传达,价值在于提供高质量、跨语言的内容消费体验。
· 欧洲本土科技产品展示:精选和介绍欧洲本土的优秀科技公司和产品,帮助用户发现高质量的替代方案,价值在于支持本土创新,提供更多元的科技选择。
产品使用案例
· 一位关注欧洲企业级SaaS解决方案的开发者,想了解欧洲是否有类似Slack或Zoom的优秀替代品。他可以通过该项目选择“德语”和“企业”作为筛选条件,快速找到如Wire(端到端加密通信平台)等欧洲本土的高质量企业级应用,并了解其技术特点和市场动态,解决了寻找欧洲本土优秀企业软件的痛点。
· 一个刚上线不久、内容增长迅速的欧洲科技博客作者,苦于网站内容难以被Google快速收录。他可以参考该项目的“渐进式站点地图增长”策略,在初期只向搜索引擎提交少量最新文章,随着网站权重提升逐步增加提交量,从而有效提升了新内容的收录率,解决了新网站SEO推广的难题。
· 一位对欧洲AI创业公司感兴趣的用户,但他不懂法语。他可以通过该项目选择“法语”和“消费者”作为筛选条件,阅读到关于法国AI公司的最新动态,并通过项目自动生成的英文摘要和翻译,快速理解核心信息,避免了因语言不通而错过重要资讯的困扰。
4
Pegma: 经典跳棋的开源复兴
作者
GlebShalimov
描述
Pegma 是一个开源版本的经典跳棋(Peg solitaire)游戏,它以简洁的设计和流畅的跨平台体验为核心。项目最大的技术亮点在于其完全开源的代码,鼓励社区参与,以及开发者为游戏精心设计的专属字体,这在提升用户体验的同时,也展现了独特的创意。它解决了如何在现代平台重现经典游戏,并保持其精髓的挑战。
人气
点赞 32
评论数 48
这个产品是什么?
Pegma 是一个免费且完全开源的经典跳棋游戏。它利用了现代的跨平台开发技术,例如可能使用的跨平台框架(如 React Native, Flutter 等)来实现一套代码能在 iOS 和 Android 设备上运行,极大地提高了开发效率和维护成本。其独特的之处在于,开发者不仅重现了经典玩法,还为游戏定制了专属字体,这种对细节的打磨,体现了开发者对用户体验的极致追求。对于开发者而言,开源意味着可以学习其实现思路,参与代码贡献,甚至基于此进行二次开发。
如何使用它?
开发者可以通过访问 Pegma 的 GitHub 仓库来查看、学习和下载项目的源代码。这对于希望了解游戏开发、跨平台技术应用的开发者来说,是一个绝佳的学习资源。如果你想贡献代码,可以修复 bug、添加新功能或优化现有代码。对于希望将游戏集成到自己项目中的开发者,可以参考其架构设计,或在遵守开源协议的前提下进行借鉴。普通用户可以直接在 iOS 和 Android 的应用商店下载体验。
产品核心功能
· 跨平台游戏引擎:实现一套代码在 iOS 和 Android 上无缝运行,这意味着开发者可以快速触达更广泛的用户群体,降低开发和维护成本。
· 完全开源的代码:允许开发者深入理解游戏的实现原理,学习其技术栈和设计模式,促进技术知识的共享和传播。
· 定制化游戏字体:通过自定义字体增强游戏的视觉风格和品牌辨识度,这是一种在保持经典游戏性的基础上,通过设计提升用户体验的技术思路。
· 简洁直观的用户界面:采用极简设计,聚焦核心玩法,减少不必要的干扰,让玩家能快速沉浸游戏,这对于任何用户体验驱动的产品都具有借鉴意义。
· 经典跳棋逻辑实现:精确还原经典跳棋的规则和算法,为玩家提供原汁原味的解谜体验,展示了开发者在算法和逻辑实现上的功力。
产品使用案例
· 在移动游戏开发中,作为跨平台技术选型和实现思路的学习案例:开发者可以参考 Pegma 如何使用一套代码同时适配 iOS 和 Android,了解其背后的技术框架和设计模式。
· 作为开源项目贡献的实践范例:对游戏感兴趣的开发者可以研究 Pegma 的代码,发现潜在的 bug 或提出改进建议,积极参与到开源社区的建设中。
· 在独立游戏设计中,探索经典玩法与现代 UI/UX 结合的实践:Pegma 展示了如何通过简洁的设计和定制化元素,让一个老游戏焕发新的生命力,这对于其他希望复刻经典或创新玩法的项目具有启发意义。
· 作为一种轻量级、易于理解的图形化编程实践:PEGMA 的核心逻辑相对简单,对于初学者而言,研究其代码可以帮助理解基本的游戏循环、状态管理和用户交互的实现方式。
5
奇思妙想集思广益生成器
作者
elysionmind
描述
这是一个能激发“奇葩”商业想法的平台,它通过汇集各种“不应存在”的创业概念,让开发者和创业者碰撞火花。项目的创新之处在于它巧妙地将“低效”和“荒诞”转化为创意催化剂,用一种轻松幽默的方式,帮助人们发现潜在的创新方向,或者至少提供一个有趣的点子去探索。
人气
点赞 33
评论数 30
这个产品是什么?
这个项目是一个集思广益的创意生成器,它的核心技术在于一个能够汇聚、展示并鼓励用户提交各种“奇葩”商业想法的系统。它不是去创造完美的商业计划,而是反其道而行之,收集那些看似不切实际、甚至有点“愚蠢”的点子。通过收集这些“反常识”的创意,项目希望能够激发用户跳出思维定势,从这些看似不可行的点子中提炼出真正的创新火花,或者理解为什么某些想法会失败。它背后是一种“从错误中学习”、“反向思考”的技术洞察,用代码创造了一个允许“失败”和“不完美”的实验场。
如何使用它?
开发者可以访问该平台,浏览其他人提交的“愚蠢”商业想法,获取灵感。你可以轻松地为这些想法点赞,或者提出自己的“奇葩”想法。集成方面,这个项目本身就是一个独立的Web应用,开发者可以参考其开源代码,理解如何构建一个用户生成内容的社区平台,或者借鉴其内容聚合和展示的方式,将其应用到其他需要用户参与产生想法的项目中。
产品核心功能
· 点子收集与展示:用户可以提交自己的商业想法,平台将它们集中展示,这背后是内容管理系统的实现,价值在于快速聚合用户创意。
· 点子投票与互动:用户可以为感兴趣的点子投票,并进行评论互动。这是通过前端的用户交互设计和后端的数据存储实现,价值在于促进社区活跃和点子排序。
· 反向创意激发:平台故意收集“糟糕”的点子,意在鼓励用户从反面思考。这是一种产品设计哲学,价值在于帮助用户规避常见的陷阱,或者发现被忽略的利基市场。
· 社交分享功能:方便用户将有趣的点子分享给朋友,扩大创意传播范围。这是通过集成第三方社交分享API实现,价值在于增加平台曝光和用户参与度。
产品使用案例
· 假设你正在构思一个新产品,但思如泉涌,却总是想到一些平庸的点子。访问这个平台,浏览那些“不可能成功”的商业设想,可能会让你突然想到一个完全不同的、更具颠覆性的解决方案。例如,看到一个“卖空气”的想法,你可能会联想到“基于订阅的空气净化服务”,或者“个性化空气风味剂”。
· 作为一名AI应用开发者,你可以参考这个项目的用户生成内容(UGC)和社区互动机制,来构建一个AI创意生成器的社区版本。例如,让用户提交AI生成内容的“奇葩”案例,并进行投票,从而驱动AI模型改进,或者发现新的应用场景。
6
Chirp 本地语音输入助手
作者
whamp
描述
Chirp 是一个专为 Windows 设计的本地语音输入应用程序,它无需连接互联网,也不需要安装额外的可执行文件,并且能在 CPU 上流畅运行。它解决了在限制性强的 Windows 环境下,用户希望拥有快速、准确且不泄露隐私的语音转文本(STT)功能的需求。Chirp 利用了 NVIDIA 的 ParakeetV3 模型,并用 `uv` 工具链进行管理,让开发者能够轻松在 Python 环境中部署和使用。
人气
点赞 29
评论数 15
这个产品是什么?
Chirp 是一个在你的 Windows 电脑上完全离线运行的语音输入工具。它的核心技术是 NVIDIA 的 ParakeetV3 模型,这是一个非常擅长将语音转换成文字(Speech-to-Text,STT)的人工智能模型。与其他很多需要联网、安装复杂软件或依赖高性能显卡(GPU)的同类产品不同,Chirp 的设计理念是“轻便”和“普适”。它使用 ONNX Runtime 这个跨平台的技术来运行 AI 模型,并且默认可以在普通 CPU 上工作。这意味着,只要你的 Windows 电脑能运行 Python,你就能安装和使用 Chirp,而不需要担心被 IT 管理员阻止安装新的程序。它的创新点在于,在满足用户对隐私(数据不上传云端)和性能(快速、准确)的需求的同时,降低了使用门槛,尤其是在企业内部网络受限的环境下,它提供了一种不受限制的语音输入解决方案。
如何使用它?
开发者可以通过简单的几步来使用 Chirp。首先,你需要确保你的 Windows 环境已经安装了 Python,并且可以通过 `uv` 这个工具来管理依赖。然后,你需要执行一个一次性的设置命令来下载并准备 ParakeetV3 的 AI 模型文件,这通常是通过 `uv run python -m chirp.setup` 命令完成的。模型准备好后,你就可以启动 Chirp 的核心服务,它会以一个长时间运行的命令行进程(`uv run python -m chirp.main`)的形式存在。一旦服务启动,Chirp 会监听一个全局热键(你可以自定义),按下这个热键就可以开始或停止录音。录制到的语音会被实时转换成文字,并直接输入到当前激活的应用程序窗口中,就像你手动打字一样。Chirp 还支持自定义配置,比如选择不同的模型、调整文字处理方式(例如,自动句首大写,或者在文字前添加特定符号),甚至可以预设一些常见的单词纠正,以提高识别的准确性。整个过程不需要你进行复杂的剪贴板操作,非常顺畅。
产品核心功能
· 本地离线语音转文本:利用 ParakeetV3 模型,在用户电脑上直接进行语音识别,所有数据不出本地,完全保护用户隐私,避免了云端服务的网络延迟和数据安全顾虑。这对于重视数据安全的企业用户或个人来说非常重要。
· CPU 友好型 AI 模型运行:通过 ONNX Runtime,Chirp 优化了 ParakeetV3 模型,使其能在标准 CPU 上高效运行,无需昂贵的 GPU,大大降低了硬件门槛,让更多用户能够享受到先进的语音识别技术。
· 无额外可执行文件依赖:使用 `uv` 工具链管理,Chirp 仅需 Python 环境即可运行,避免了在受限的企业环境中无法安装 `.exe` 文件的困扰,实现了“即插即用”的便捷体验。
· 可配置的全局热键和录音控制:用户可以自定义启动/停止录音的快捷键,并能通过声音反馈感知录音状态,保证了操作的直观性和用户体验的流畅性。
· 智能文本后处理与纠错:支持自定义的文本风格(如句首大写)和关键词覆盖,能够根据用户习惯自动修正识别错误,提高输出文本的准确性和可用性。
· 直接窗口输入,无需剪贴板:识别出的文本能直接“输入”到当前活动的窗口,避免了传统复制粘贴的繁琐步骤,提高了工作效率。
· 详细的配置选项:通过 `config.toml` 文件,用户可以精细调整模型选择、语言、精度(量化)、ONNX 提供者、线程数等参数,以及设置单词纠错,实现高度个性化的语音输入体验。
产品使用案例
· 在一个严格的网络安全策略的企业内部,IT部门不允许安装任何新的应用程序,但允许运行 Python。开发者可以使用 Chirp 实现本地的语音转文本功能,在编写文档、代码注释或撰写邮件时,通过语音快速输入内容,显著提升工作效率,而无需担心数据泄露或违反公司规定。
· 一位需要大量进行文字记录的自由职业者,他们不希望将包含敏感信息的录音发送到云端服务。使用 Chirp,他们可以在自己的电脑上安全地进行语音记录,并将录音直接转换为文本,同时确保所有音频数据和识别结果都保留在本地,完全掌控个人隐私。
· 经常需要在不同应用程序之间切换输入的用户,例如在 IDE 中写代码,在聊天软件中交流,或者在文档编辑器中写作。Chirp 的全局热键和直接窗口输入功能,让他们可以随时随地通过语音进行输入,无需手动切换窗口或复制粘贴,保持了工作的连贯性和流畅性。
· 有特定术语或品牌名称经常被语音识别模型误读的用户。通过 Chirp 的 `[word_overrides]` 配置功能,用户可以添加自定义的词汇映射,确保这些特殊词汇被准确识别和输出,从而提高文本内容的专业性和准确性。
· 对于希望尝试最新 AI 技术但硬件配置不高的开发者。Chirp 仅需 Python 环境和普通 CPU,即可运行先进的 ParakeetV3 模型,让他们能以极低的门槛体验到高质量的本地语音转文本技术,并可以进一步研究和贡献于 ONNX Runtime 的优化。
7
缠斗具象:可视化柔术学习指南
作者
anavid7
描述
本项目是一个交互式的可视化指南,旨在帮助学习者通过视觉化方式理解和掌握柔术(Jujutsu)的各种技术动作和概念。它不依赖于传统的文字或视频教程,而是利用交互式的图表和模型来拆解复杂的动作,让学习者能够直观地“看懂”技术原理,加速学习进程。
人气
点赞 7
评论数 10
这个产品是什么?
这是一个用可视化方式解释柔术(Jujutsu)技术动作和原理的学习工具。传统的柔术教学往往依赖教练的口述和示范,或是通过视频观看,这可能导致信息损失和理解偏差。本项目另辟蹊径,通过构建可交互的3D模型或动态图示,将人体关节、力量传导、重心变化等关键要素直观地呈现出来。比如,在展示一个擒拿动作时,你可以看到力量是如何从施力者的脚部传递到擒拿点,以及如何利用对手的重心来完成技术。它的创新之处在于,将复杂的物理学和生物力学原理,以一种易于理解和操作的方式,与武术技术结合,让学习者不再是单纯地模仿动作,而是理解“为什么”要这样做,从而更深入地掌握技术。
如何使用它?
开发者可以将其集成到现有的在线学习平台、健身应用,或者作为独立的柔术教学App。具体使用场景包括:1. 制作柔术教学课程:将可视化模型嵌入到每个技术讲解的章节中,让学生点击即可查看动作的分解和细节。2. 构建交互式练习工具:允许用户在可视化模型中尝试调整角度、力量,观察不同操作对结果的影响,从而加深理解。3. 辅助教练教学:教练可以使用这些可视化工具在课堂上向学员直观地演示复杂动作,提高教学效率。集成方式可以是通过API接口将可视化模块接入现有系统,或者直接使用其提供的SDK进行二次开发。
产品核心功能
· 交互式3D人体模型:展示柔术动作中的关键发力点、重心转移和身体姿态,让学习者能从任意角度观察动作的细节,理解技术背后的力学原理。
· 动作分解与回放:将一个复杂的柔术技术动作分解成一系列更小的、易于理解的步骤,并支持慢动作回放,帮助学习者清晰地捕捉每一个细节,这是理解动作如何一步步完成的关键。
· 关键节点高亮提示:在可视化模型中,突出显示施力点、受力点、关节轴心等关键部位,让学习者能够聚焦于动作的核心,避免被无关信息干扰。
· 力线与重心可视化:通过箭头或光线来表示力量的传导方向和重心的变化,帮助学习者直观地理解如何运用巧力而非蛮力,这是柔术精髓之一。
· 对比与分析模式:允许用户对比不同姿势或不同技术动作的力线和重心变化,从而理解各种技巧的优劣和适用场景,帮助学习者做出更明智的技术选择。
· 技术术语关联解释:将可视化模型中的特定动作或部位与标准的柔术术语进行关联,当用户点击时,会弹出该术语的解释,帮助学习者在掌握技术的同时,也熟悉专业术语,是理论与实践的完美结合。
· 数据驱动的动作优化建议:未来可集成AI,根据用户在可视化模型中的操作,分析其动作的潜在问题,并给出优化建议,直接提升学习效率。
产品使用案例
· 一个柔术初学者在使用本工具学习“十字固”(Cross Collar Choke)时,可以清晰地看到施力者如何利用对手的重心,以及手臂和衣领的受力点如何配合施压,理解之前视频中模糊的“锁喉”动作具体是如何发力的,从而快速掌握该技术。
· 一位正在备战比赛的柔术运动员,可以使用本工具来分析对手的常用技术动作,将对手的动作在可视化模型中进行模拟,找出其动作的薄弱环节或发力习惯,制定有针对性的训练计划,是战术分析的利器。
· 一名在线柔术课程的开发者,可以将本工具集成到自己的教学平台,为每个技术动作都配上一个交互式的可视化模型,极大地增强了课程的吸引力和学习者的理解度,让课程不再枯燥。
· 物理学爱好者,即使没有武术基础,也可以通过本工具来学习柔术技术,理解人体如何通过巧妙的杠杆原理、重心转移来完成看似困难的动作,从中获得对物理学在实际应用中的直观认识,是技术原理与人体运动的生动结合。
· 一位想要在家安全地练习柔术动作的学生,可以使用本工具来辅助理解和拆解教练教过的动作,在不方便进行实战练习时,通过可视化模型进行反复琢磨,避免动作错误,这是居家学习的理想伙伴。
8
spymux: 跨终端视图监视器
作者
crap
描述
spymux 是一个巧妙的工具,能让你在一个窗口里实时“偷看”你的多个 tmux 终端窗口里正在发生什么。它解决了开发者在同时管理多个任务时,频繁切换窗口查看进度的痛点,让你一眼掌握所有重要信息。
人气
点赞 9
评论数 3
这个产品是什么?
spymux 就像一个“终端监控器”,它允许你用一种非侵入式的方式,在同一个地方查看多个 tmux 终端会话(pane)的内容。它的技术原理是利用 tmux 本身的能力,抓取每个 pane 的屏幕输出,然后将这些输出合并到一个集中的视图中显示。创新之处在于它提供了一个统一的、可视化的方式来追踪并发任务的状态,而无需手动切换窗口,极大地提升了效率,这对于需要同时运行和监控大量任务的开发者来说,是直接的生产力提升。
如何使用它?
开发者可以将 spymux 集成到他们的日常工作流程中。当你在开发、测试、部署或运行后台任务时,只需启动 spymux。你可以配置它来监控你关心的特定 tmux pane。例如,你可以设置 spymux 同时显示你的代码编译窗口、后端服务日志窗口、前端热重载窗口以及数据库同步窗口。这样,你只需要看 spymux 的一个窗口,就能清楚地知道每个任务的进展,以及是否有任何错误发生,大大减少了上下文切换的成本。
产品核心功能
· 实时多 pane 视图:spymux 能将多个 tmux 终端的内容实时同步展示在一个界面上,让你无需频繁切换就能了解每个任务的最新状态,提升了工作效率。
· 统一的任务监控:它提供了一个集中的地方来查看所有并行运行的任务,无论是编译、测试还是日志,都能一目了然,有助于快速发现和解决问题。
· 简化工作流程:通过减少窗口切换,spymux 使得同时管理多个复杂任务变得更加直观和容易,解放了开发者宝贵的注意力。
· 自定义视图配置:你可以根据自己的需求,选择哪些 tmux pane 需要被 spymux 监控和显示,实现个性化的工作空间管理。
产品使用案例
· 在进行大型项目编译时,开发者可以使用 spymux 同时监控编译进度、日志输出以及任何可能出现的错误信息,一旦编译失败,可以立即看到错误详情,无需在不同终端间反复查找。
· 在进行自动化测试时,开发者可以通过 spymux 实时查看多个测试任务的运行状态和结果,及时发现运行缓慢或失败的测试用例,并快速定位问题。
· 在开发微服务或复杂后端应用时,开发者可以使用 spymux 同时监控各个服务的日志输出、API 调用情况以及资源使用情况,全面了解系统的运行状态,方便进行性能调优和故障排查。
· 在团队协作开发过程中,开发者可以通过 spymux 共享一个终端视图,让团队成员都能实时了解项目构建、部署或集成的进展,增强了团队的透明度和沟通效率。
9
TalkiTo:语音交互终端代码助手
作者
robbomacrae
描述
TalkiTo是一个开源项目,它为终端内的代码助手(比如Claude Code或Codex CLI)增加了语音输入和输出功能。这个项目解决了当前交互式代码助手在需要用户频繁干预时的“脱手”问题,通过语音指令和语音反馈,让开发者能真正实现“解放双手”的编程体验。它还集成了Slack和WhatsApp,扩展了沟通渠道,并支持多种ASR/TTS服务,包括本地化部署选项。
人气
点赞 5
评论数 5
这个产品是什么?
TalkiTo是一个让你的代码助手能够听懂你说的话、也能用语音和你交流的工具。想象一下,你不再需要一直盯着屏幕敲键盘,而是可以通过语音来告诉你的代码助手要做什么,它也会用语音告诉你它的进展或者需要你注意的地方。它的核心技术是将语音识别(ASR - Automatic Speech Recognition,就是让电脑听懂人类语言的技术)和语音合成(TTS - Text-to-Speech,就是让电脑说出人类语言的技术)接入到像Claude Code这样的终端代码助手里。它不是直接让代码助手说话,而是通过一个中间层来捕获代码助手的输出信息,然后用语音播报出来;同时,它也能捕捉你的语音指令,转化为文字输入给代码助手。更厉害的是,你可以选择使用云端强大的ASR/TTS服务,也可以选择在自己的电脑上运行开源的Whisper(语音识别)和Kokoro/Kittentts(语音合成),这样既保证了隐私,又可能省下服务费用。
如何使用它?
开发者可以将TalkiTo作为一层“外壳”包裹住他们的代码助手。安装TalkiTo后,你可以通过简单的语音指令(例如“TalkiTo,开始A任务”)来启动或控制代码助手。代码助手在运行时产生的文字输出,会被TalkiTo捕获并用语音播报出来,让你即使不在电脑前也能了解进度。如果代码助手需要你的输入,TalkiTo会用语音提示你。此外,你还可以通过语音或文字输入(如“TalkiTo disable ASR”或“TalkiTo change tts to kokoro”)来动态调整TalkiTo的设置,比如关闭语音识别,或者更换语音合成引擎。它还可以接收来自Slack和WhatsApp的消息,并将这些消息作为指令或信息反馈给代码助手。
产品核心功能
· 语音指令输入:通过语音识别技术,将开发者的口语指令转化为代码助手可以理解的文字输入,解放双手,提高编程效率。
· 语音进度播报:将代码助手的运行输出(如代码生成、错误报告、进度更新)通过文本转语音技术播报出来,让开发者即使不在屏幕前也能掌握实时状态。
· 多平台消息集成:通过Slack和WhatsApp的钩子(hooks)功能,可以将这些平台上的消息作为输入传递给代码助手,或者将代码助手的输出发送到这些平台,实现跨应用协作。
· 灵活的ASR/TTS配置:支持连接市面上主流的云端语音服务,也支持在本地运行Whisper和Kokoro/Kittentts等开源模型,开发者可以根据自己的需求(如成本、隐私、性能)选择最合适的配置。
· 运行时配置调整:提供一个MCP(Message Queue Telemetry Transport)服务器,主要用于配置管理,允许开发者在运行时通过简单的文本或语音命令(例如“TalkiTo disable ASR”),动态地启用或禁用某些功能、切换语音服务等,提供了高度的灵活性。
· 代码助手封装:TalkiTo的工作原理是包裹住代码助手,监听和拦截其输入输出,以此实现语音交互,这意味着它可以与多种支持终端交互的代码助手良好集成。
产品使用案例
· 在远程协作场景下,开发者可以通过语音指令控制代码助手完成代码编写任务,同时通过语音播报获取代码生成的进度和潜在问题,即使身处公共场所或不便打字的环境,也能高效工作。
· 开发者可以利用TalkiTo将代码助手的输出内容实时发送到Slack频道,让团队成员第一时间了解项目进展,无需手动复制粘贴,实现信息自动化同步。
· 对于需要长时间运行的自动化测试或代码生成任务,开发者可以设置TalkiTo,使其在任务完成后通过WhatsApp发送通知,确保即使开发者离开了电脑,也能及时获知关键信息。
· 在注重数据隐私的场景下,开发者可以选择TalkiTo的本地化部署选项,使用Whisper和Kokoro/Kittentts等模型,完全在本地进行语音识别和合成,避免敏感数据上传云端,保证代码和数据的安全性。
· 开发者正在进行一个需要大量命令行操作的任务,通过TalkiTo,他们可以用语音来切换不同的终端命令、修改参数,或是执行一系列复杂的操作,大大减少了手动输入的疲劳感和出错率。
· 新入行的开发者在学习使用复杂的代码助手时,可以借助TalkiTo的语音反馈功能,更直观地理解代码助手的行为和逻辑,加快学习曲线。
10
DataGuard AI: 智能数据管道守护者
作者
UvrajSB
描述
DataGuard AI是一个AI驱动的代码审查工具,专门为数据团队设计,能够自动检测SQL、dbt、Airflow和Spark代码在GitHub Pull Request(PR)中的潜在问题。它能预判代码变更可能引发的成本增加、逻辑错误、数据质量下降以及下游依赖中断等风险,确保代码在合并到生产环境前得到充分的质量保障。它解决了数据团队在快速迭代和代码审查之间难以平衡的难题,避免了因代码错误导致的高昂仓储费用和管道故障。
人气
点赞 6
评论数 4
这个产品是什么?
DataGuard AI是一个基于人工智能的代码审查机器人,它能像一位经验丰富的数据工程师一样,深入分析你提交的数据处理代码(比如SQL查询、dbt模型、Airflow工作流或Spark作业)。它不仅仅是检查代码拼写是否正确,更重要的是,它能理解这些代码在实际运行时会发生什么。比如,它会预测你的SQL查询会不会突然变得非常昂贵,导致云数据仓库账单飙升;它会找出代码中隐藏的bug,导致数据结果错误;它还能追踪你的代码变动会对其他依赖它的报表或模型产生什么影响,并提前发出警告。它的核心创新在于,它将软件工程师的代码审查理念,扩展到了数据工程师面临的独特风险领域,例如数据成本、数据质量、数据血缘关系以及数据治理等。
如何使用它?
开发者在使用GitHub进行代码协作时,当提交一个Pull Request(PR)时,DataGuard AI会自动介入。它会像团队中的另一位审稿人一样,对PR中的代码进行分析。开发者只需要将DataGuard AI集成到他们的GitHub仓库中,它就能自动监控新的PR。例如,当一位数据工程师修改了一个SQL查询,DataGuard AI会在PR的评论区指出,这个修改可能会导致某个大型表被全量刷新,从而显著增加Snowflake的费用,并建议修改方案。开发者可以在PR中看到AI的审查报告,并根据建议进行代码调整,从而在代码被合并前就消除了潜在的风险。它还可以集成到CI/CD流程中,作为代码合并前的最后一道防线。
产品核心功能
· 预测成本风险: DataGuard AI通过分析SQL语句,能够预测代码变更对云数据仓库(如Snowflake, BigQuery等)的成本影响。例如,它能发现导致不必要的全量刷新或扫描大量数据的查询,帮助开发者避免意外的高昂账单。
· 检测逻辑和数据质量问题: 它能识别出代码中可能导致数据错误或质量下降的潜在问题,比如缺失过滤条件导致数据量爆炸性增长,或者引入重复数据,直接影响报表的准确性。
· 分析下游影响和血缘关系: DataGuard AI能够追踪代码变更对数据管道中其他组件的影响。如果一个模型或报表依赖于被修改的代码,它会发出警告,说明哪些下游组件可能中断,并通知相关负责人。
· 执行数据治理和安全规则: 它可以检查代码是否符合预设的数据治理规则,例如是否正确处理了PII(个人身份信息),是否添加了必要的文档说明,或者是否符合特定的数据合并规则。
· 沙箱环境模拟执行: 为了更准确地评估风险,DataGuard AI可以在一个安全的隔离环境中运行新的SQL代码,并分析实际执行结果与预期之间的差异,从而发现深层的问题。
· 识别冗余或缺失的测试: 它能帮助数据团队评估现有数据质量测试的覆盖率,找出不必要的测试以提高效率,或标记出关键数据质量检查的缺失。
产品使用案例
· 某企业数据团队在修改一个dbt模型时,DataGuard AI检测到一项变更会导致该模型的部分数据被全量重跑,预测将产生数万美元的额外Snowflake费用,并建议修改为增量更新,从而避免了巨额成本。
· 一位数据工程师在更新一个事实表(fact table)的ETL脚本时,不小心遗漏了一个关键的过滤条件。DataGuard AI识别出这个疏忽会导致数据量在短时间内翻倍,极有可能扭曲销售收入报表,并要求修复。
· 一个数据治理团队希望确保所有敏感数据(PII)的处理都受到严格控制。DataGuard AI被配置为检查所有涉及PII字段的SQL语句,确保它们符合最小化收集和安全处理的原则。
· 当一位数据工程师重命名了一个数据库列时,DataGuard AI通过分析数据血缘关系,发现该列被14个下游报表所依赖,并立即通知了这些报表的负责人,避免了报表大面积失效。
· 在开发一个用于财务报表的模型时,DataGuard AI发现模型缺乏关键的数据质量测试(如空值检查、唯一性校验),并建议添加相应的测试,提高了财务数据的可靠性。
11
UnisonDB:超低延迟B+树分布式数据库
作者
ankuranand
描述
UnisonDB 是一个创新的分布式数据库,它将 B+ 树这种高效的数据库索引结构与亚秒级的跨节点复制技术相结合。核心创新在于,它能在瞬间将数据变更同步到超过100个节点,极大地提升了数据的一致性和可用性,尤其适用于需要快速扩展和高可用性的场景。
人气
点赞 9
评论数 1
这个产品是什么?
UnisonDB 是一个基于 B+ 树索引实现的分布式数据库。B+ 树就像一个非常高效的目录,能帮助数据库飞快地找到所需数据。它最大的亮点是它的“亚秒级复制”技术,这意味着当你在一个地方更新了数据,不到一秒钟,这个数据就能同步到你部署在世界各地的100多个服务器上。这就像你更新一个文件,全世界所有副本瞬间就更新了,几乎不需要等待。这解决了分布式系统中数据一致性难题,让你不必担心不同地方的数据不一样。
如何使用它?
开发者可以将 UnisonDB 作为应用程序的后端数据存储。你可以通过其提供的 API (Application Programming Interface,应用程序接口)进行数据的增删改查操作。由于其低延迟的特性,它非常适合构建需要实时更新和高并发访问的应用,比如金融交易系统、实时排行榜、IoT 数据收集平台等。集成时,你可以将 UnisonDB 部署为集群模式,并根据你的业务需求调整节点数量和复制策略。
产品核心功能
· B+ 树索引优化:通过使用 B+ 树这种高效的数据组织结构,UnisonDB 能够极大地提升数据查询的速度,相当于给了数据库一个超级大脑,让它能瞬间找到你需要的信息。
· 亚秒级跨节点复制:这是 UnisonDB 的核心竞争力,它能在极短的时间内将数据变更同步到大量节点,确保了数据的强一致性,让你在任何地方访问到的数据都是最新的。
· 分布式集群支持:UnisonDB 天然支持分布式部署,可以轻松扩展到上百甚至上千个节点,应对海量数据和高并发访问的需求,让你不用担心系统会因为用户太多而宕机。
· 高可用性设计:通过多节点复制和快速故障转移,UnisonDB 能够保证在部分节点出现问题时,整个数据库服务依然可用,避免了单点故障带来的业务中断。
· API 驱动的访问:提供简洁易用的 API,方便开发者快速集成到各种应用中,快速完成数据的存取操作,让你能把更多精力放在业务逻辑开发上。
产品使用案例
· 实时金融交易平台:在金融交易场景下,数据的实时性至关重要。UnisonDB 的亚秒级复制可以确保所有交易参与者都能看到最新、最准确的交易信息,降低了因数据不同步而产生的风险。
· 大规模在线游戏排行榜:一个热门游戏需要一个能实时更新玩家得分的排行榜。UnisonDB 可以快速接收来自全球玩家的游戏数据,并将其同步到各个服务器,保证玩家看到的排行榜始终是最新的。
· 高并发物联网数据收集:物联网设备产生的数据量巨大且需要即时处理。UnisonDB 能够高效地接收和存储海量传感器数据,并通过快速复制确保数据的一致性,便于后续的分析和应用。
· 全球化分布式内容分发:对于需要将内容快速同步到全球各个数据中心的场景(例如新闻或电商平台),UnisonDB 的低延迟复制可以保证各地用户都能访问到最新版本的内容。
· 分布式缓存加速:在某些场景下,UnisonDB 可以作为低延迟的数据源,为上层的缓存系统提供快速的数据同步,整体提升应用响应速度。
12
Keepr: Terminal in-House Secret Safe
作者
bsamarji
描述
Keepr 是一个专为开发者设计的,纯粹在命令行(CLI)环境下运行的离线密码管理器。它将所有敏感信息存储在本地加密的数据库中,并通过一个主密码来保护,同时提供一个临时解锁会话,避免频繁输入密码。它不联网,确保您的数据安全掌握在自己手中,是那些偏爱本地化、终端化工作流程的开发者的理想选择。
人气
点赞 6
评论数 2
这个产品是什么?
Keepr 是一个使用命令行界面(CLI)来管理的密码存储工具,它最大的亮点在于完全离线运行。它使用一种叫做 SQLCipher 的技术,将你的所有密码信息安全地存放在一个加密的数据库里。这个数据库就像一个上了锁的保险箱,只有你输入正确的主密码才能打开。而且,它还有一个巧妙的设计:在你工作的时候,可以保持保险箱在一定时间内是解锁状态(称为“会话”),这样你就不用频繁地输入主密码,大大提升了使用效率。最重要的是,Keepr 永远不会连接到互联网,这意味着你的数据不会有被远程泄露的风险。它使用了 AES-256 这样的高级加密标准,并结合了 PBKDF2-HMAC-SHA256 算法来生成用于解密数据的密钥,并通过一个层层加密的机制(主密钥解密会话密钥,会话密钥解密数据库密钥,数据库密钥加密整个数据库)来确保最高级别的安全。
如何使用它?
开发者可以将 Keepr 作为他们日常开发工作流的一部分。通过简单的命令行指令,你可以快速地添加新的密码条目(例如,服务器 SSH 密码、API 密钥、数据库凭据),查看、搜索、更新甚至删除它们。当你需要某个密码时,只需在终端里输入相应的命令,Keepr 就能安全地将密码呈现给你,或者直接复制到剪贴板。例如,你可以使用 `keepr add` 来添加一个新密码,用 `keepr search <keyword>` 来查找,用 `keepr view <entry_name>` 来查看某个条目的详细信息。Keepr 还可以生成安全、随机的密码,帮助你提高账户的安全性。它可以通过 pip 包管理器轻松安装(`pip install Keepr`),然后在你的终端环境中直接使用。
产品核心功能
· 本地加密存储: 使用 SQLCipher 加密技术,确保所有密码数据仅存储在本地计算机上,不受外部网络威胁,为你提供完全的数据掌控权。
· 命令行操作: 提供直观的命令行指令,方便开发者在终端内快速管理密码,如添加、查看、搜索、更新和删除条目,无需切换到图形界面,极大提升工作效率。
· 会话管理: 引入时间限制的会话机制,在用户指定的时间内保持密码库解锁状态,避免频繁输入主密码,同时保证过期后自动锁定,兼顾了便捷性和安全性。
· 安全密码生成: 内置随机密码生成器,能够创建符合复杂度和长度要求的强大密码,帮助开发者轻松满足不同服务的安全需求,减少弱密码的风险。
· 剪贴板支持: 集成剪贴板功能,可以直接将生成的或检索到的密码复制到系统剪贴板,方便粘贴到其他应用程序或登录框中,进一步简化了操作流程。
产品使用案例
· 作为一名开发者,你需要频繁地访问多个服务器的 SSH 账户,每个账户都有不同的密码。使用 Keepr,你可以在终端中通过 `keepr search <server_name>` 快速找到对应的 SSH 密码,然后用 `keepr copy <server_name>` 将密码复制到剪贴板,然后直接粘贴登录,大大节省了查找和记忆密码的时间。
· 你在开发一个需要调用第三方 API 的应用,并且需要管理这些 API 的密钥。这些密钥非常敏感,不能保存在代码仓库中。你可以使用 Keepr 来安全地存储这些 API 密钥,并在需要时通过 `keepr view <api_name>` 查看,然后复制使用,确保敏感信息的安全性和代码的整洁性。
· 你需要为新注册的在线服务设置一个非常复杂的密码,但又不想费力去想。Keepr 的密码生成器可以轻松帮你生成一个满足要求的强密码,例如 `keepr generate --length 20 --complexity high`,然后你可以用 `keepr add` 命令将其与服务名一起保存起来,这样你就拥有了一个安全且易于管理的密码。
· 你担心在公共电脑上不小心泄露密码。Keepr 的离线特性意味着你的密码永远不会上传到云端。即使电脑丢失,只要你设置了强主密码,数据仍然是加密的,大大降低了信息泄露的风险。
13
AI灵感画布
作者
kar_t
描述
这是一个由AI驱动的视觉工作区,专门为家具选购设计。它通过整合海量商品目录、分析用户上传的灵感图片,并利用AI生成房间渲染图,将分散混乱的家具购物体验(如Pinterest、截图、多浏览器标签页)统一到一个流畅的画布上。它解决了用户在家具选购过程中信息碎片化、决策困难的问题,大大提升了效率。
人气
点赞 8
评论数 0
这个产品是什么?
AI灵感画布是一个智能化的在线空间,就像一个无限大的白板,让你可以在上面自由地进行家具选购。它的核心技术在于强大的AI能力。一方面,它能理解你上传的各种灵感图片(比如你喜欢的房间照片、设计风格),并自动找出与之匹配、可以购买的家具商品。另一方面,它还能根据你选择的家具和房间布局,生成逼真的3D渲染图,让你提前看到家具摆放在你家里的样子。这就像请了一位智能家居设计师,帮你把脑海中的想法变成现实,并直接告诉你哪里可以买到心仪的家具。
如何使用它?
开发者可以通过集成Canvas的API,将AI驱动的商品搜索和图像生成能力嵌入到自己的电商平台、家居设计软件或内容创作工具中。例如,电商平台可以利用AI灵感画布,让用户上传照片即刻找到同款或风格相似的商品,并提供一键生成不同搭配的渲染图。家居设计师可以使用它来快速为客户构建视觉化的设计方案,并直接链接到商品购买页面。这种集成方式,能够极大地丰富现有产品的交互体验,并为用户提供更个性化、更直观的购物和设计流程。
产品核心功能
· AI商品匹配:能够智能识别用户上传的灵感图片,并从海量商品库中精准找出匹配的家具商品。这对于电商平台来说,意味着能够更有效地将用户兴趣转化为购买力,让用户快速找到想要的东西,减少搜索成本。
· AI房间渲染:根据用户选择的家具和房间布局,生成逼真的3D房间效果图。这能帮助用户直观地预见家具在家中的实际效果,大大降低因“想象与现实不符”而产生的退货率,提升用户购物满意度。
· 无限画布工作区:提供一个可以无限扩展的画布,让用户可以自由地拖拽商品、上传图片、放置渲染图。这为用户提供了一个沉浸式的、非线性的探索和决策空间,鼓励创意和探索,提升了用户在平台上的停留时间和互动深度。
· 跨平台信息整合:将来自不同平台的灵感、商品信息集中管理,并进行智能化链接。这解决了用户在进行大型购物决策时,信息分散、难以整合的痛点,将碎片化的信息转化为可操作的决策流,让购物体验更连贯、更高效。
产品使用案例
· 电商平台:一家大型家具电商可以集成AI灵感画布,让用户上传自己家客厅的照片,AI会识别出照片中的家具风格,并推荐相似的商品。用户还可以直接在画布上搭配不同款式的沙发、茶几,AI即时生成渲染图,用户满意后可一键加入购物车。这解决了用户“不知道什么风格适合我家”的难题。
· 家居设计软件:一款面向消费者的家居设计APP可以接入AI灵感画布,用户上传喜欢的家居杂志内页图片,AI会自动识别图片中的关键家具,并链接到App内的购买选项。用户还可以通过拖拽这些商品到虚拟空间,AI会实时更新房间渲染效果,让设计过程更直观、更具象。
· 内容创作者/博主:家居类博主可以在其博客或社交媒体上使用AI灵感画布,为读者展示不同搭配的家具效果,并直接提供商品链接。这使得内容创作更加生动有趣,也为粉丝提供了直接的购物参考,提升了内容的影响力和变现能力。
14
Vibe Capsule: 音乐胶囊应用化
作者
hunterirving
描述
Vibe Capsule 是一个将你的MP3音乐文件打包成可在任何设备上离线运行的渐进式Web应用(PWA)的工具。它解决了一个技术和情感上的问题:在数字时代,我们似乎失去了制作和赠送“数字礼物”的能力,取而代之的是指向无法控制的在线内容的链接。Vibe Capsule 使用Python脚本,让你能将本地音乐变成一个可安装的应用程序,朋友们可以直接下载使用,无需担心地区限制或服务下线,真正实现了“文件就在电脑里”的体验。
人气
点赞 5
评论数 2
这个产品是什么?
Vibe Capsule 是一个能让你把本地音乐收藏变成一个独立、可分享的应用程序的工具。它的核心技术是利用渐进式Web应用(PWA)的技术。PWA 是一种现代的网页技术,它能让网页应用像原生App一样拥有安装到设备主屏幕、离线运行、快速响应等能力。Vibe Capsule 利用Python脚本,将你指定的MP3文件和相关的Web应用代码打包成一个可以直接部署到任何支持HTTPS的服务器上的“mixapp”。一旦用户访问这个“mixapp”并添加到主屏幕,它就能完全离线运行,播放音乐,就像一个本地音乐播放器一样。这其中的创新价值在于,它恢复了数字内容的拥有感和分享的直接性,绕过了流媒体平台的限制,让你可以真正“赠送”数字内容,而不是仅仅提供一个链接。
如何使用它?
开发者可以下载Vibe Capsule的Python脚本,然后创建一个包含你想要分享的MP3文件的文件夹。运行脚本,它会生成一个“mixapp”目录,里面包含了所有构建PWA所需的文件。你可以将这个目录上传到任何支持HTTPS的网站托管服务上(例如GitHub Pages, Netlify, Vercel等)。生成一个指向这个“mixapp”部署地址的链接,然后分享给你的朋友。朋友们通过这个链接访问后,可以在他们的手机或电脑上选择“添加到主屏幕”或“安装应用”,之后就可以在没有网络的情况下随时随地听你分享的音乐了。这是一个非常适合音乐爱好者、DJ或者任何想分享精选音乐集的人的工具。
产品核心功能
· 音乐文件打包成PWA: 将本地MP3文件通过Python脚本转换成一个渐进式Web应用,实现技术核心是将文件作为应用资源打包,并配置PWA的Service Worker进行本地缓存,方便离线访问。价值是让音乐收藏拥有独立应用形态,随时可听。
· 离线播放功能: PWA的核心能力,确保应用在没有网络连接的情况下也能正常播放音乐。技术上通过Service Worker拦截网络请求,将本地缓存的音乐文件返回给应用。价值是保证用户在任何环境下都能享受音乐,不受网络限制。
· 应用安装到主屏幕: 让用户可以将音乐应用像原生App一样添加到手机或电脑的主屏幕,方便快捷地启动。技术上利用PWA的Manifest文件和相关API实现。价值是提供接近原生App的用户体验,提高访问便捷性。
· 跨平台支持: Vibe Capsule生成的mixapp可以在iOS、Android、桌面设备等多种平台上运行,无需为不同平台开发原生应用。价值是极大地扩展了分享的范围,让更多人能方便地接收和使用。
· 去中心化分享: 用户可以自主部署和分享,不依赖于任何第三方平台的服务状态。技术上强调的是自托管和直接文件传输。价值是赋予分享者完全的控制权,避免因平台政策变化导致分享失效。
产品使用案例
· 音乐爱好者制作个人精选集并分享给朋友: 例如,一位DJ制作了一份珍藏的唱片集,通过Vibe Capsule将其打包成一个独立App,朋友们只需点击链接就能安装并离线收听,无需注册任何流媒体账户。这解决了朋友间分享音乐时,因地区版权限制或歌曲下架而导致无法播放的问题。
· 独立音乐人发布小型EP给粉丝: 独立音乐人可以利用Vibe Capsule将新发布的几首歌曲打包成一个简易的应用,在社交媒体上分享给粉丝。粉丝安装后,即使在没有网络的旅途中也能支持和收听,这是一种全新的、更具互动性的内容分发方式。
· 播客作者制作单集精选或特别内容: 播客作者可以将某个主题的精选集(例如“最佳现场演出片段”)制作成一个Vibe Capsule应用,方便粉丝永久收藏和离线收听,这种方式比单纯分享链接更能体现内容的价值和作者的心意。
· 教师或学生制作学习资料的音频版本: 教师可以将课堂录音或学习资料的音频文件打包成一个Vibe Capsule应用,学生下载后即可离线学习,尤其适用于网络环境不佳的地区或需要集中注意力学习的场景。
15
气泡工作流引擎
作者
hkselinali
描述
一个开源的、基于代码的智能代理工作流平台。它允许开发者用代码定义一系列可以自动执行的、有逻辑联系的任务,就像把任务串联成一个个“气泡”,每个气泡都能独立思考和执行,并能与其他气泡协同工作,从而自动化复杂的流程。解决了手动操作、流程割裂、效率低下等痛点。
人气
点赞 5
评论数 2
这个产品是什么?
气泡工作流引擎是一个让你用代码编写复杂自动化流程的工具。想象一下,你有一堆需要一步步完成的任务,比如从网上抓取数据、分析数据、生成报告、发送邮件。以前你需要自己写很多脚本,或者用一些图形化的工具,但逻辑复杂了就很难管理。这个引擎就像一个聪明的助手,你告诉它用什么代码语言(比如Python)来描述每个任务(每个“气泡”),它就能理解这些任务的顺序、条件,以及它们之间如何传递信息,然后自动把它们串联起来,让它们像一个团队一样协作完成整个流程。它的创新之处在于,它把“代理”的概念引入了工作流,这意味着每个任务(气泡)不仅仅是执行一个简单的命令,而是可以拥有一定的“智能”,比如根据情况做出决策,或者主动去寻找需要的信息,而不是被动等待。
如何使用它?
开发者可以通过编写代码来定义工作流。首先,你需要选择一种支持的编程语言(例如Python)。然后,你编写代码来定义不同的“代理”或“任务节点”(也就是“气泡”)。每个节点可以是一个函数,负责执行特定的操作,比如API调用、数据处理、文件读写等。你可以通过代码来指定这些节点之间的依赖关系、触发条件以及数据传递方式。举个例子,你可以写一个代理,负责定时从某个网站爬取最新的产品信息,然后另一个代理接收到这些信息后,进行数据清洗和格式化,最后再由一个代理将整理好的报告发送到指定的邮箱。你可以将这个引擎集成到现有的项目中,或者作为一个独立的自动化服务来运行。
产品核心功能
· 代码驱动的任务编排:允许开发者用熟悉的编程语言(如Python)来定义和控制工作流的每一步,这比图形化界面更灵活,更容易处理复杂的逻辑和自定义需求。所以这对我有什么用:你可以用你最熟悉的工具来构建自动化流程,不受预设功能的限制。
· 代理(Agentic)能力:每个工作流节点可以被设计成具有一定“智能”的代理,能够理解上下文、做出决策、甚至主动搜索信息。所以这对我有什么用:让你的自动化流程不再是死板的执行,而是能应对变化,更像一个真正的助手。
· 可扩展的插件系统:支持开发者自定义新的代理类型或集成第三方工具,极大地扩展了工作流的能力范围。所以这对我有什么用:你可以根据自己的业务需求,轻松添加新的功能,让工作流支持更多种类的任务。
· 可视化调试和监控:提供界面来查看工作流的执行状态、中间数据和潜在的错误,方便开发者快速定位和解决问题。所以这对我有什么用:在你辛辛苦苦搭建的自动化流程出现问题时,能方便地找到症结所在,减少调试时间。
· 版本控制和协作:支持对工作流进行版本管理,并方便团队成员之间的协作和代码共享。所以这对我有什么用:让团队能更顺畅地共同开发和维护自动化流程,避免“一个人写的东西别人看不懂”的尴尬。
产品使用案例
· 自动化数据分析报告生成:开发者可以创建一个工作流,每天自动从多个API接口抓取最新的销售数据,然后用Python脚本进行数据清洗、统计分析,最后生成一份PDF格式的销售报告,并发送给管理层。这解决了人工收集和处理数据的低效问题,并确保了报告的及时性。
· 智能客服响应系统:构建一个能理解用户问题的AI代理,当用户提问时,它能先尝试理解用户意图,然后通过搜索知识库或调用API来找到最佳答案,最后将答案回复给用户。这能极大地提升客服效率,并提供更个性化的服务。
· CI/CD流程自动化:将代码提交、自动化测试、构建、部署等环节串联起来,形成一个自动化的软件发布流程。当代码有更新时,工作流会自动触发测试,通过后自动构建新版本并部署到测试或生产环境。这大大缩短了软件发布周期,降低了人为操作失误的风险。
· 个性化内容推荐系统:创建一个工作流,根据用户的浏览历史、偏好和行为,动态地从大量内容库中筛选出最相关的文章、产品或视频,并实时推送给用户。这能显著提升用户体验和内容消费的转化率。
16
SimpleTimeCalc - 极简时间薪资计算器
作者
atharvtathe
描述
SimpleTimeCalc 是一个用代码解决日常小痛点的开源工具,旨在简化个人或小型团队的考勤打卡和薪资计算。它解决了手工记录时间卡、容易出错以及计算薪资过程繁琐的问题,通过清晰的时间输入和自动化计算,让时间管理和报酬核算变得直观高效。这是一个典型的黑客思维应用,用技术手段自动化处理重复性劳动。
人气
点赞 5
评论数 0
这个产品是什么?
SimpleTimeCalc 是一个基于简单逻辑的时间卡计算器。它的核心技术思路是将用户输入的每日工作开始和结束时间,通过代码自动计算出总工作时长。它不像复杂的企业级考勤系统那样需要数据库、复杂的权限管理等,而是专注于核心计算功能。创新点在于其极简的设计理念,避免了不必要的复杂性,让任何开发者都能轻松理解和修改。对于用户来说,它的价值在于能够准确、快速地算出自己的工作时间,避免因为手工记录或计算错误导致的薪资损失,或者在管理小团队时,能快速核算每个人的工作量。
如何使用它?
开发者可以通过克隆项目的源代码,在本地运行。例如,如果是基于Python等语言开发的,可以直接运行脚本,通过命令行交互输入每日的上下班时间。也可以将其作为代码库,集成到自己的其他项目中,比如一个简单的项目管理工具,用来记录每个任务花费的时间,或者一个个人仪表盘,显示每周或每月的工作总时长。对于非技术用户,如果项目提供了可执行文件或简易的Web界面,可以直接使用,输入日期和时间即可得到结果。
产品核心功能
· 日期时间输入与存储: 允许用户输入具体日期和当天的工作开始/结束时间,并将其以结构化的方式保存,为后续计算做准备。这解决了手动记账容易遗漏和混乱的问题。
· 工作时长计算: 能够自动计算出每天的总工作时长,并能处理跨午休时间段的情况。这保证了计算的准确性,避免了人工计算时因为疲劳或疏忽导致的错误。
· 周/月总时长汇总: 将每日工作时长累加,提供周或月度总工作时长的统计。这使得用户可以清晰了解自己的总工作量,对于薪资核算和个人效率分析非常有价值。
· (可能存在)薪资费率应用: 如果项目扩展,可以输入每小时的费率,直接计算出总报酬。这直接解决了计算薪资的痛点,让个人或小型团队能够快速准确地得到应得的报酬。
· (可能存在)导出功能: 支持将计算结果导出为CSV或其他格式,方便进一步的数据分析或报销。这增加了数据的可用性,使其能与财务软件或其他工具协同工作。
产品使用案例
· 自由职业者/零工经济从业者: 记录和计算零散工作的工时,并快速算出报酬。例如,一位接了多个项目的自由职业者,可以轻松核算每个项目花费的时间和应得的报酬,避免了繁琐的手工记录和计算。
· 小型团队/创业公司: 快速统计团队成员的项目工作时长,用于内部成本核算或客户账单。例如,一个小型开发团队,可以用它来记录每个成员在不同项目上花费的时间,方便项目经理了解资源分配和成本。
· 个人时间管理爱好者: 追踪自己的工作时间,分析时间分配效率,优化工作流程。例如,一位希望提高工作效率的开发者,可以通过记录每天的工作时长,找出哪些任务占用了大量时间,并思考如何改进。
· 学生兼职: 准确计算兼职工作的工时,保证自己应得的工资。例如,一位学生在餐厅兼职,可以记录每天的上班下班时间,确保老板支付的工资准确无误。
17
动图图解动画引擎
作者
chunza2542
描述
StoryMotion 是一个用于创建分步解释动画的工具,它能够将复杂的概念或流程转化为易于理解的动态图解。其核心创新在于通过代码化的方式,让开发者能够以编程接口(API)或配置文件来定义动画的每一步,从而实现高度定制化和可复用的动画制作,这对于解释技术原理、演示产品功能或教育内容来说,提供了一种全新的、效率更高的解决方案。
人气
点赞 1
评论数 4
这个产品是什么?
StoryMotion 是一个将静态信息转化为动态讲解动画的工具。它的技术原理是让你像写代码一样,一步一步地告诉它要展示什么内容、如何变化、何时出现、何时消失。比如,你可以定义一个箭头从A点指向B点,然后在下一秒让一个方框从屏幕左边移到中间。这种‘代码化’的动画制作方式,相比传统的图形软件,更加灵活和可控,尤其适合需要精确控制每一步细节和重复使用的场景。
如何使用它?
开发者可以通过 StoryMotion 提供的 API 接口,在自己的应用程序或脚本中集成动画生成功能。例如,你可以编写一个脚本,当用户完成某个操作时,自动触发生成一段解释该操作流程的动画。或者,将动画的描述配置存储在 JSON 文件中,StoryMotion 读取这些配置后即可生成动画。它非常适合嵌入到技术文档、在线教程、产品演示页面或者知识库中,让复杂的技术知识变得可视化。
产品核心功能
· 按步定义动画序列:通过代码或配置文件精确控制动画的每一步,包括元素出现、消失、移动、缩放、颜色变化等,这让你能够实现高度定制化的教学或演示效果,让观众精准理解每一步的含义。
· 可复用动画模块:将常用的动画片段打包成可复用模块,大大提高制作效率,避免重复劳动,尤其在大型项目或系列教程中,能确保风格统一。
· 跨平台输出:StoryMotion 能够将生成的动画导出为通用的视频格式(如 MP4)或 GIF,方便在各种平台和设备上分享和展示,用户无需担心兼容性问题。
· 数据驱动的动画:支持通过外部数据源(如 JSON 数据)来动态生成动画内容,这意味着你可以根据实时数据或用户输入来创建个性化的解释动画,增加互动性和动态性。
产品使用案例
· 在技术文档中制作代码执行流程动画:当解释一段复杂的算法或程序执行过程时,可以通过 StoryMotion 制作一个可视化的动画,展示数据在不同变量间的传递和函数调用的顺序,帮助开发者快速理解代码逻辑。
· 为产品功能演示创建交互式教程:当需要介绍一个新功能时,可以利用 StoryMotion 制作一段分步动画,模拟用户操作并展示功能效果,让用户直观地了解如何使用该产品。
· 在在线教育平台中解释科学概念:例如,解释原子结构或行星运动时,可以通过 StoryMotion 创建动态的演示动画,比静态图片更能激发学生的学习兴趣并帮助理解抽象概念。
· 为软件故障排除提供可视化指导:当用户遇到软件问题时,可以提供一段 StoryMotion 动画,指导用户一步步进行排查和修复,降低技术支持的难度。
18
ByteSync - 跨越网络的智能文件同步卫士
作者
paulfresquet
描述
ByteSync 是一款开源的文件同步、备份和去重工具,它巧妙地将本地文件和远程存储(如服务器、NAS)连接起来。它的独特之处在于内置了网络通信层和端到端加密,让你无需复杂的 VPN 或防火墙配置,就能轻松实现跨网络的文件同步。它就像一个懂你的智能助手,能发现并管理不同设备上的文件差异,让数据在你的掌控中保持一致。
人气
点赞 3
评论数 2
这个产品是什么?
ByteSync 是一个能够连接你电脑本地文件和你远程存储(比如家里的 NAS 服务器,或者公司的服务器)的文件同步和备份工具。它最大的创新点是,它不仅能同步本地文件,还能直接同步到互联网上的另一台电脑,而且全程加密,非常安全。你不用再担心远程访问文件时需要复杂的网络设置,ByteSync 会像一个中间人一样,自动处理所有通信和加密,让你在同一个界面就能管理所有文件,就像它们都在你身边一样。
如何使用它?
开发者可以下载 ByteSync 的应用程序,在 Windows、macOS 或 Linux 系统上运行。安装后,你可以设置一个“数据节点”(DataNode)来代表你的远程存储(比如一台服务器),再指定“数据源”(DataSource)来代表你想同步的本地文件夹。然后,你可以创建一个同步会话,让 ByteSync 自动比较和传输文件。这对于需要保持代码库、项目文件或重要文档在多台设备间同步的开发者来说,能极大地提高工作效率,并确保数据的安全一致性。
产品核心功能
· 跨网络文件同步:它能让你轻松同步本地电脑和远程服务器(即使在互联网上)的文件,解决了跨网络文件访问的难题,让你可以随时随地访问最新文件。
· 端到端加密:所有传输的数据都会被加密,确保了文件的隐私性和安全性,即使数据在传输过程中被截获,也无法被读取,让你对数据安全高枕无忧。
· 智能文件比较:它能高效地比较文件差异,只同步变动的部分,大大节省了带宽和时间,即使是大量文件也能快速同步。
· 统一管理界面:所有本地和远程的同步任务都可以在一个界面上管理,操作直观简便,降低了使用的门槛,让你能轻松掌握所有文件的状态。
· 去重备份:它还能帮助你识别并去除重复的文件,节省存储空间,并且可以作为一种高效的备份方式,确保数据的完整性。
产品使用案例
· 远程协作开发:在一个团队中,开发者可以将他们的本地代码库同步到一台中央服务器,其他团队成员也可以通过 ByteSync 从这台服务器拉取最新的代码,无需担心代码版本不一致的问题,大大提升了团队协作效率。
· 多设备数据同步:当你在笔记本电脑上写了一个文档,同时你也在台式机上工作,ByteSync 可以自动将笔记本上的文档同步到台式机,确保你在任何一台设备上都能获取到最新的文件,省去了手动复制粘贴的麻烦。
· 个人数据安全备份:你可以将重要的个人文件,如照片、文档等,同步到家里的一台 NAS 服务器上,并开启端到端加密,这样即使 NAS 设备丢失或被盗,你的数据依然安全,并且你随时可以从任何地方恢复。
· 服务器文件管理:对于需要管理多台服务器文件的开发者,ByteSync 可以让他们在一个地方集中管理和同步这些服务器上的文件,并提供文件差异的视图,方便进行比对和维护。
19
预言市场数据聚合器
作者
ritzammm
描述
这是一个能收集、分析来自不同预言市场(prediction markets)数据的工具。它就像一个聪明的侦探,把来自各个“预测未来”的平台的信息汇集起来,找出大家对某个事件(比如选举结果、产品发布)的集体智慧是什么,以及这些预测的可信度有多高。核心创新在于它能够跨平台抓取和整理这些碎片化的预测数据,并进行初步的分析,帮助用户快速了解市场对未来的集体判断。
人气
点赞 5
评论数 0
这个产品是什么?
这是一个能够从各种预言市场平台自动抓取、整合和初步分析预测数据聚合的工具。想想看,很多人会在不同的网站上猜测某件事的结果,并用钱或虚拟货币下注。这个项目就像一个超级数据分析师,把这些分散在不同平台上的“猜测”都搜集过来,然后告诉你大家普遍认为哪个结果的可能性最大,以及这些预测背后有多少“钱”在支持。它解决的问题是,目前这些预言市场的信息分散且难以横向比较,难以形成对未来事件的整体判断。它的技术亮点在于使用了网络爬虫(web scraping)技术来访问和提取数据,并且可能采用了数据清洗和聚合的算法,以应对不同平台数据格式的差异。所以这对我有什么用?它能让你一眼看穿大家对未来事件的集体看法,省去了自己去各个平台搜索和比较的时间,让你能更快地做出基于市场共识的判断。
如何使用它?
开发者可以通过API接口或者直接运行项目来使用这个数据聚合器。你可以把它集成到你自己的应用程序中,比如一个新闻分析工具、一个投资决策辅助系统,或者一个市场趋势监测平台。例如,你可以写个脚本,定时调用这个聚合器,获取当前对某个热门事件的预言市场数据,然后把这些数据展示在你的仪表盘上,或者用来触发一些警报。如果你想自己搭建,可以按照项目的说明文档,在本地环境中部署相关的爬虫和数据处理模块。所以这对我有什么用?你可以把这些强大的市场预测数据,整合到你正在开发的任何需要预测或分析未来事件的软件里,让你的产品更具洞察力。
产品核心功能
· 跨平台数据抓取:能够自动访问并提取来自多个不同预言市场平台的预测数据,解决信息分散的问题,实现数据整合的第一步。这能帮助你一次性获取海量预测信息,而不是逐个平台查看。
· 数据清洗与标准化:将来自不同平台、格式各异的预测数据进行整理和标准化,使其能够被统一分析,解决数据不一致带来的分析障碍。这意味着你可以信任聚合后的数据,减少人工处理错误。
· 市场情绪分析(初步):通过聚合和分析不同平台的赔率或预测权重,初步展现市场对某个事件的集体判断和情绪倾向,帮助用户快速了解大众的普遍看法。这能让你迅速知道“大家都在押注什么”。
· 数据可视化准备:为后续的数据可视化或更深入的分析提供结构化的数据,便于用户创建图表或进行复杂计算,解决数据孤岛问题,为深度洞察打下基础。这让你更容易地理解和呈现复杂的预测数据。
产品使用案例
· 一个科技媒体记者想了解公众对即将发布的某款新手机的市场预期,可以将此聚合器的数据集成到他的新闻分析工具中,快速收集各预言市场对新手机销量或受欢迎程度的预测,从而撰写更具市场洞察力的报道。它解决了记者需要耗费大量时间手动收集信息的痛点。
· 一个金融分析师希望监测特定行业(如能源、科技)的未来发展趋势,可以将此聚合器接入其分析平台。通过聚合关于该行业内关键事件(如政策变化、技术突破)的预言市场数据,他可以更早地发现市场信号,做出更及时的投资决策。它解决了传统数据难以捕捉的、基于市场共识的微观预测信息。
· 一位业余研究者对某个政治事件(如选举结果)的公众预测信息感兴趣,可以使用该聚合器来收集不同平台上的预测数据,并进行比较分析,以理解公众舆论的走向和可能的最终结果。这为研究者提供了一个便捷的、多角度的数据来源,解决了信息获取的难度。
20
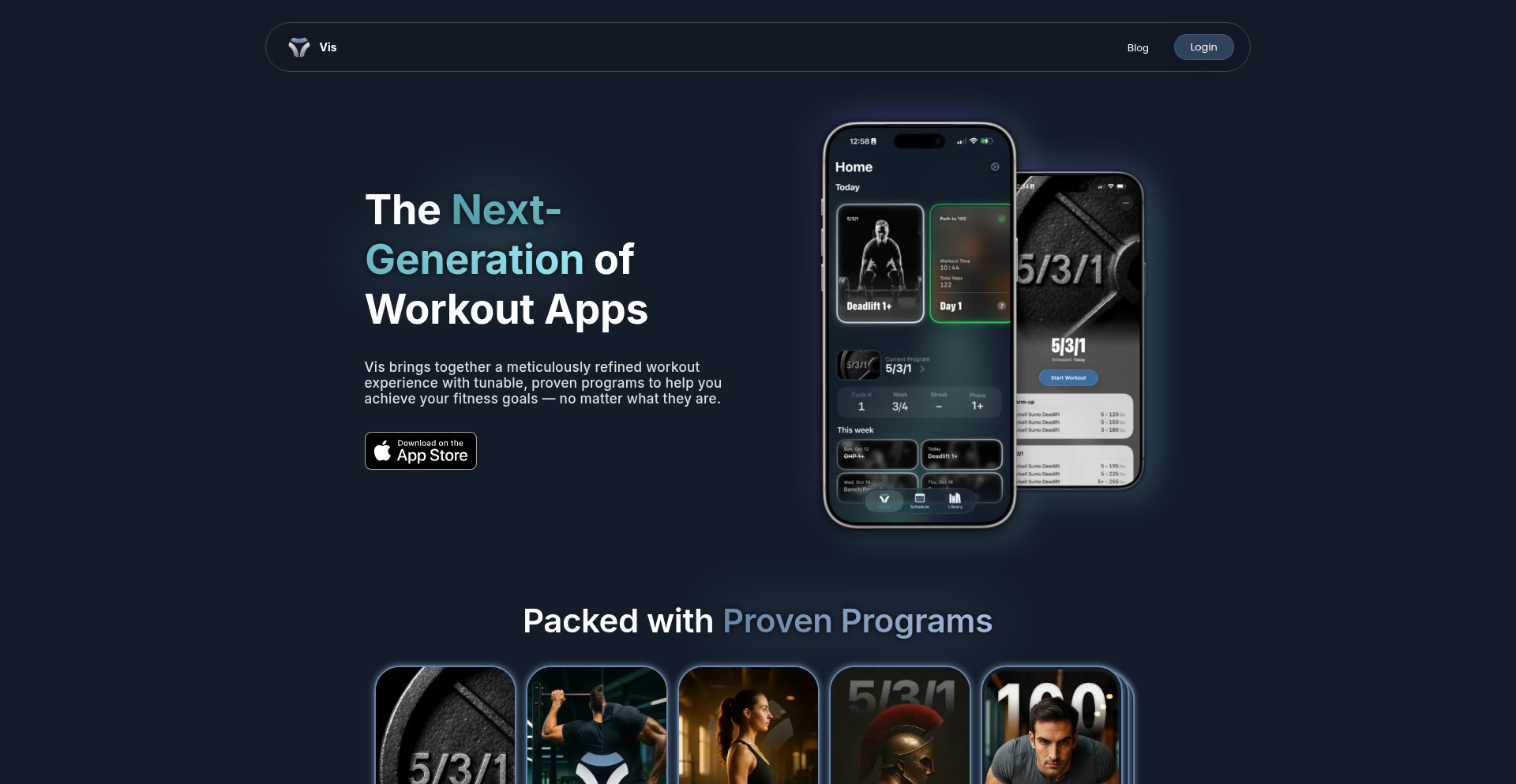
Vis: 动态化运动训练引擎
作者
strongpigeon
描述
Vis 是一款创新的运动训练应用,它不仅仅是记录训练内容,而是通过一个强大的“动态化引擎”来生成和调整你的训练计划。它最大的亮点在于可以将你的基础能力(比如最大卧推重量)作为输入,然后自动计算出每组训练应该使用的重量和次数,并且在训练过程中还能根据你的实时反馈进行微调,让训练更科学、更高效。对于开发者来说,它展示了一种将复杂计算逻辑融入用户界面的新思路,以及如何用 SwiftUI 构建原生、流畅的 iOS 应用,并结合 Live Activities 提供更便捷的交互体验。所以,这对我来说意味着一个更智能、更适应个人的训练伙伴,以及一个学习如何构建更强大、更具交互性的移动应用的范例。
人气
点赞 5
评论数 0
这个产品是什么?
Vis 是一个基于强大计算引擎的运动训练应用,它的核心技术在于能够根据用户的个体数据(比如你的最大力量值,也就是你一次能举起的最大重量)来动态生成训练计划。简单来说,它不是让你死记硬背一套固定不变的训练内容,而是像一个聪明的私人教练,会根据你的能力水平和你当前的状态来告诉你“现在应该举多少斤,做多少次”。它的创新之处在于,它用一种“公式化”的思路来定义训练,比如“这个动作的重量是1RM的85%,做3组,每组8次”,并且这个“1RM”(一次最大重复次数)是可以自动计算和调整的。这使得训练计划可以根据用户的进步或状态变化而自动适应,而不是需要手动修改。所以,这对我来说意味着训练不再是僵化的,而是能够随着我一起进步,让我能更科学、更安全地提升运动表现。
如何使用它?
对于普通用户,你可以直接在 App Store 下载 Vis 应用,选择一个内置的训练计划(例如著名的 5/3/1 训练法),或者稍后使用其强大的编辑器创建属于你自己的个性化训练计划。应用会自动根据你的 1RM(一次最大重复次数)来计算每次训练的重量和次数。它还提供了一个类似“Jiggle Mode”的界面,让你能轻松地重新安排训练日期。通过 iOS 的 Live Activities 功能,你甚至可以在锁屏界面直接看到当前的训练内容和计时,无需解锁手机。对于开发者,你可以将 Vis 的核心理念——即如何用代码定义和计算复杂的训练参数——应用到你自己的项目中,或者学习它如何使用 SwiftUI 构建高效、流畅的原生 iOS 应用,特别是如何利用 Live Activities 提升用户体验。所以,这对我来说意味着可以快速开始科学训练,并且能方便地在手机上随时随地进行管理;对于开发者来说,则是一个学习如何构建更智能、更用户友好的移动应用的宝贵案例。
产品核心功能
· 动态训练计划生成:根据用户输入的 1RM(一次最大重复次数)自动计算出每次训练的重量和次数,确保训练强度符合个人能力,避免过度训练或训练不足。这意味着你可以获得一个真正为你量身定制的训练方案,让你训练更有效率。
· 智能训练编辑器:允许用户通过类似公式的方式来创建和编辑自己的训练计划,例如设定动作、组数、次数以及与 1RM 的百分比关系,为个性化训练提供了极大的灵活性。这意味着你不再受限于预设的训练计划,可以完全按照自己的想法来构建训练内容。
· 实时训练界面:以直观的方式展示当前正在进行的训练内容、组数和休息时间,并且支持通过 Live Activities 在锁屏界面查看,提供流畅的训练体验。这意味着你在训练时可以更专注于动作本身,而不是频繁地查看手机。
· 训练日程重排:提供便捷的界面来调整训练日期,让你的训练计划更具弹性,能够适应生活中不可预见的变动。这意味着即使行程有变,你也能轻松地调整训练安排,保证训练的连续性。
· SwiftUI 原生开发:完全采用 SwiftUI 构建,带来了流畅的用户体验和更快的更新迭代速度,并且能够充分利用 iOS 的新特性,比如 Live Activities。这意味着你可以享受到高质量的 App 体验,并且 App 的功能会持续更新和改进。
产品使用案例
· 作为一名健身爱好者,你想要尝试 5/3/1 训练法来提升力量,但又觉得手动计算每次训练的重量很麻烦。使用 Vis,你只需要输入你的 1RM,App 就会自动为你生成整个训练周期的重量计划,让你轻松开始训练,专注于动作本身。
· 作为一名力量举运动员,你需要一个能够根据你最近一次测试的 1RM(最大重复次数)来精确计算每次训练重量的应用。Vis 的动态计算引擎可以做到这一点,并且还能根据你的进步自动调整,让你始终保持在最佳训练状态。
· 作为一名 iOS 开发者,你正在学习 SwiftUI,并且对如何利用 Live Activities 提升用户交互性感到好奇。Vis 的实现方式为你提供了一个绝佳的学习范例,你可以研究它是如何将训练信息实时推送到锁屏界面的。
· 作为一名希望定制自己训练计划的健身者,你厌倦了市面上那些只能套用模板的 App。Vis 的智能编辑器让你能够像搭积木一样,用公式定义自己的训练动作、组数和重量,构建出完全符合你需求的个性化训练方案。
21
克重食谱速搭
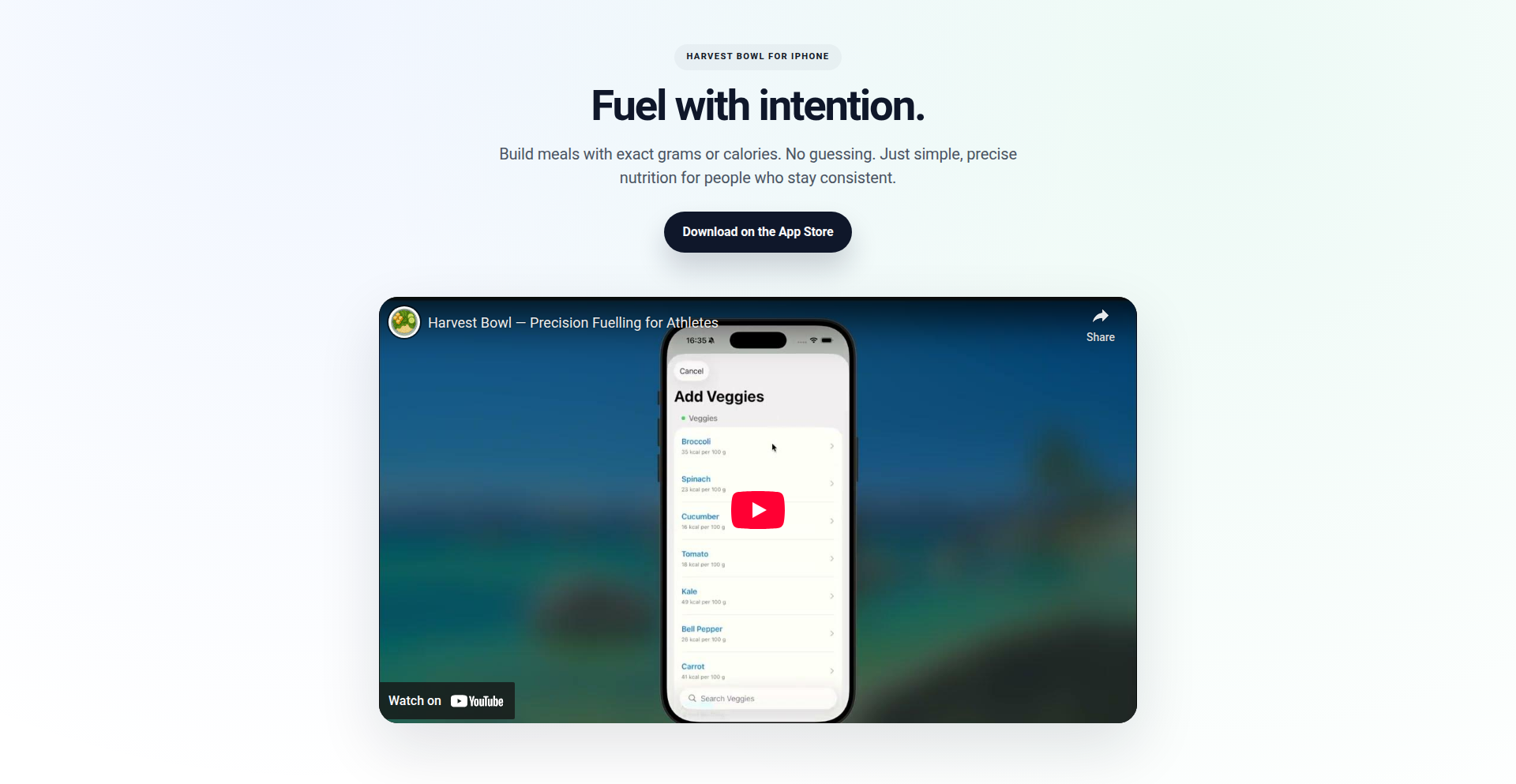
作者
harvest_bowl
描述
Harvest Bowl 是一款iPhone应用,它以一种极其简便的方式,让用户能够精确地以克或卡路里为单位来组合膳食,并在调整食材份量时即时显示宏量营养素(如蛋白质、碳水化合物、脂肪)的变化。开发者希望摆脱传统繁琐的食物数据库和复杂的追踪应用,通过简单的滑块操作,快速搭建个性化餐食,并立即看到营养构成。
人气
点赞 3
评论数 2
这个产品是什么?
Harvest Bowl 是一个专注于通过直观操作来组合餐食的应用。它的核心技术在于其精准的份量控制机制,通过“克”或“卡路里”作为单位,让用户可以像搭积木一样精确地选择食材和调整份量。与市面上大多数需要搜索、选择、记录的营养追踪App不同,Harvest Bowl 采取了一种“反向”的思路:用户不是去记录吃了什么,而是先“搭建”一份想吃的餐食,然后应用立即计算出其营养成分。这种即时反馈的交互设计,结合了滑块操作的流畅性,是其技术创新点,解决了用户在简单膳食规划时面临的复杂性和低效率问题。
如何使用它?
开发者可以通过App Store下载 Harvest Bowl 应用。一旦安装,用户可以迅速添加食材(应用内提供了常用食材列表,甚至有快捷的蔬菜预设),然后利用屏幕上的滑块精确调整每种食材的克数或卡路里。每一次滑块的移动,都会在屏幕上方即时更新总体的宏量营养素(蛋白质、碳水化合物、脂肪)以及总卡路里。用户可以将自己喜欢的餐食组合保存下来,方便日后快速调用。这种应用方式对于希望精确控制饮食摄入、但又不想花费大量时间记录的健身爱好者、有特定饮食需求的人群,以及任何想简单了解餐食营养构成的人来说,都非常实用。
产品核心功能
· 精准份量控制:通过克或卡路里单位的滑块,精确调整食材份量,让用户对摄入的食物克数一目了然,避免模糊的估计,从而更科学地管理饮食,这对于需要精确控制热量或特定营养素摄入的人群非常有价值。
· 即时宏量营养素显示:在调整份量的同时,应用会实时更新蛋白质、碳水化合物和脂肪的比例及总量。这意味着用户能立即看到不同食材组合对宏量营养素的影响,从而快速优化餐食结构,达到健身或健康目标。
· 简洁的食材列表:应用提供了一个干净、易于浏览的食材库,减少了用户寻找食材的时间和干扰。这让用户能更专注于餐食的搭配和营养的计算,提升了使用效率。
· 快速蔬菜预设:针对常见的蔬菜,提供了快捷选项。这可以大大加快餐食的搭建速度,特别是在准备日常餐点时,用户无需逐一输入,即可快速完成基础营养的组合。
· 保存常用食谱:用户可以将创建的满意餐食组合保存为“碗”(Bowl)。这样,下次需要类似餐食时,只需一键加载,无需重复操作,大大节省时间,并确保了营养摄入的一致性。
产品使用案例
· 健身爱好者在训练前后构建营养餐:一个健身者需要精确补充蛋白质和碳水化合物,他可以使用Harvest Bowl,快速添加鸡胸肉、米饭等食材,通过滑块精确控制克数,并在应用中实时查看蛋白质和碳水化合物的总量,确保达到训练后的营养补充需求。
· 有特定饮食计划的人士调整餐食:一位正在进行低碳水饮食的用户,希望午餐的碳水化合物摄入不超过30克。他可以在Harvest Bowl中组合蔬菜和瘦肉,通过滑块精确控制碳水化合物的份量,直到达到目标,避免了外出就餐时对食物成分的不确定性。
· 快速准备健康早餐:早晨时间宝贵,用户希望快速准备一份营养均衡的早餐。他可以利用Harvest Bowl预设的鸡蛋、燕麦片、牛奶等选项,快速组合并微调份量,即刻了解其提供的卡路里和宏量营养素,确保一天的开始能量充足且健康。
· 希望了解食物大致营养构成的使用者:即使没有严格的饮食目标,普通用户也可以通过Harvest Bowl了解自己常吃的食物组合的大致营养构成。例如,想知道一碗沙拉大概有多少卡路里和脂肪,Harvest Bowl可以提供一个直观的参考,帮助用户形成更健康的饮食习惯。
22
eBPF热点无限数据传输引擎
作者
Gave4655
描述
这是一个基于eBPF技术的Android应用,它能让你的Android设备成为一个真正意义上的“无限”热点。传统的手机热点在流量或连接数量上常有限制,而这个项目巧妙地利用了eBPF(扩展的伯克利包过滤器)这一强大的内核级网络包处理技术,绕过了Android系统的原生限制,实现了更灵活、更强大、甚至接近无限的网络分享能力。核心创新在于,它不是简单地复用现有的网络连接,而是直接在Linux内核层面进行更深度的网络数据包管理和转发,从而解锁了Android设备在作为热点时的潜在性能和功能。
人气
点赞 3
评论数 2
这个产品是什么?
这是一个利用Linux内核的eBPF技术,打破Android原生限制,提供超乎寻常的网络分享能力的工具。eBPF就像是在操作系统内核里安装了一个极其精密的网络流量调度员,它可以监听、修改、甚至生成网络数据包。这个项目就是用eBPF来“教导”Android的内核,如何更高效、更自由地处理和转发网络流量,从而让你手机上的热点可以连接更多设备,传输更多数据,甚至实现一些传统方法难以达成的网络共享功能。所以,这对我有什么用?它可以让你在需要时,用手机分享网络给大量设备,或者在流量、连接数上不再受限于手机厂商的设置,拥有更大的网络自由度。
如何使用它?
开发者可以将此项目集成到自己的Android应用中,或者作为一个独立的后台服务运行。基本原理是,通过Android系统的JNI(Java Native Interface)或NDK(Native Development Kit),调用Linux内核的eBPF接口。开发者需要编写eBPF程序(通常用C语言编写,然后编译成eBPF字节码),这些程序会被加载到Android的Linux内核中,并挂载到特定的网络事件点上。例如,可以编写eBPF程序来监听数据包,然后修改其路由信息,或者监控连接状态,动态调整网络策略。对于普通用户,如果项目被打包成一个应用,则可能只需要在应用内进行简单的配置,选择开启热点并设定一些参数即可。所以,这对我有什么用?这给了开发者一个强大的底层工具,可以构建出市面上独一无二的网络分享应用,或者解决企业内部在设备互联、网络隔离等方面的特定需求。
产品核心功能
· 通过eBPF实现内核级网络数据包拦截与转发:直接在Linux内核处理网络数据,效率极高,可以实现传统应用层技术难以企及的转发速度和稳定性。这能让你手机分享网络时,设备连接更流畅,数据传输更稳定。
· 突破Android原生热点连接数限制:利用eBPF的灵活性,可以绕过Android系统对热点同时连接设备数量的硬性规定,让你的热点可以连接更多设备。这对于团队协作、多人聚会等场景非常实用。
· 自定义网络策略与流量控制:eBPF允许开发者编写复杂的逻辑来控制网络流量,例如优先保障某些应用的带宽,或者实现更精细的网络隔离。这能让你根据需求,优化网络分享的效果。
· 低开销高性能的网络分享:eBPF程序运行在内核态,相比运行在用户态的应用,其资源消耗更低,性能损耗也更小,能更长时间、更高效地运行。这意味着你的手机发热会更少,电池消耗也更经济。
产品使用案例
· 在大型户外活动或会议中,为大量参与者的设备提供稳定的Wi-Fi热点。传统方法可能很快就会因连接数过多而卡顿,而eBPF引擎可以确保更多设备同时流畅上网。
· 作为开发测试环境,快速搭建一个包含多个模拟设备的网络环境,用于测试网络应用或进行负载测试。eBPF引擎可以轻松应对复杂的网络拓扑和高并发连接。
· 在紧急情况下,将一台Android设备变成一个集线器,为多台电脑、平板设备提供互联网接入,实现快速的临时网络部署。无需依赖现有网络,即可快速解决网络连接问题。
· 为需要严格网络隔离的物联网设备提供连接,通过eBPF程序实现精细化的网络访问控制,确保数据安全。在复杂的物联网场景下,提供安全可靠的网络连接保障。
23
维基潜行者 (Wikidive)

作者
atulvi
描述
Wikidive 是一个利用人工智能(AI)引导用户深入探索维基百科的工具。它能够理解用户的提问,并像一个经验丰富的向导一样,带领用户在浩瀚的维基百科知识海洋中进行“潜水”,找到最相关、最深入的信息,彻底改变了我们查阅和学习知识的方式。
人气
点赞 3
评论数 2
这个产品是什么?
Wikidive 是一个基于AI的维基百科深度探索工具。传统的维基百科搜索往往是“点对点”的,你搜什么就给你什么,很难发现意想不到的关联信息。Wikidive 通过AI理解你模糊或初步的问题,然后智能地为你挖掘出相关的维基百科条目,并引导你一步步深入,就像在知识的海洋里潜水一样,让你不仅能找到直接答案,还能发现更多相关的、有趣的知识点,而且它能帮你梳理这些信息之间的联系。
如何使用它?
开发者可以将Wikidive集成到自己的应用程序中,作为内容发现或知识图谱构建的后端服务。例如,你可以创建一个问答机器人,当用户问一个复杂问题时,机器人可以调用Wikidive去查找信息,然后用AI整理后的结构化信息回复用户。也可以用它来给文章生成推荐阅读列表,用户阅读一篇关于“量子力学”的文章,Wikidive可以推荐更多相关的“薛定谔的猫”或“不确定性原理”等条目,而且能解释这些条目之间的关联。
产品核心功能
· AI驱动的智能搜索:它不是简单地匹配关键词,而是理解你的意图,即使你的问题不那么精确,也能找到最贴切的维基百科内容,让你快速找到想找的信息。
· 知识路径导航:当你对某个主题感兴趣时,Wikidive会帮你规划一条深入探索的路径,就像一个导游带你逛博物馆,让你能发现和理解更多的相关知识,而不是迷失方向。
· 信息关联性分析:它能够识别不同维基百科条目之间的内在联系,帮助你构建更全面的知识体系,理解事物之间的因果关系或类比关系。
· 可解释的AI决策:Wikidive会告诉你为什么推荐某个条目,或者为什么认为两个概念是相关的,让你对AI的分析过程有一定了解,增加了信任感。
产品使用案例
· 创建智能客服助手:当用户在电商网站上询问某个复杂的产品功能时,客服机器人可以调用Wikidive,深入搜索维基百科,找到相关的技术细节和背景知识,然后用通俗易懂的方式回复用户,解决了客服无法深入解答技术问题的痛点。
· 辅助学术研究:学生或研究人员在进行文献调研时,可以通过Wikidive输入一个初步的研究方向,Wikidive会智能地推荐大量相关的理论、人物、事件等维基百科条目,并分析它们之间的关系,大大提高了信息收集和整理的效率。
· 个性化内容推荐引擎:网站或APP可以利用Wikidive分析用户浏览过的文章,然后推荐更多用户可能感兴趣但尚未发现的维基百科深度内容,增加用户粘性,让用户在平台上获得更丰富的知识体验。
· 教育工具的升级:为在线学习平台开发一个“知识探索模式”,学生在学习某个概念时,可以启动Wikidive,它会自动引导学生探索相关的历史背景、应用案例、相关理论等,让学习过程更主动、更深入、更有趣。
24
语境树-长对话上下文智能导航器
作者
LoMoGan
描述
ChatIndex 是一个创新的长对话上下文管理系统,它通过一种类似于目录的树形结构(层级化树状索引)来组织和检索大型语言模型(LLMs)的海量对话历史。这使得 LLMs 能够更快速、更准确地找到并利用重要的对话片段,解决了传统方法下 LLMs 难以处理过长对话、遗忘关键信息的问题。所以这对我来说,意味着 AI 助手能更理解我的意思,并且在长时间交流中不会“失忆”。
人气
点赞 4
评论数 0
这个产品是什么?
ChatIndex 是一个利用“树状索引”技术来管理和检索长对话的技术工具。想象一下,一本很厚的书,如果想找某个章节的内容,传统方法就像一页页翻,效率很低。ChatIndex 就像给这本书制作了一个详细的目录,它把对话内容分门别类,建立起层层递进的关联(就像文件夹里的子文件夹),这样 AI 就能像查找文件一样,快速定位到你可能感兴趣或需要的信息。它解决了 LLMs 在处理极长对话时,信息检索效率低下、容易遗忘早期关键信息的技术难题。所以这对我来说,意味着 AI 能够记住更长的对话内容,提供更连贯、更个性化的服务。
如何使用它?
开发者可以将 ChatIndex 作为一种库集成到他们的 AI 应用中。当需要处理用户与 AI 的长对话时,ChatIndex 会负责将这些对话内容结构化,并建立索引。当 AI 需要回忆或查找信息时,ChatIndex 能够根据查询,高效地从这个“语境树”中提取出最相关的对话片段,然后将这些片段喂给 LLM。你可以把它想象成一个给 AI 的“记忆检索助手”。所以这对我来说,意味着我使用的 AI 应用(如智能客服、AI 写作助手)能够提供更深刻的理解和更持久的记忆。
产品核心功能
· 层级化对话索引构建:通过将对话内容进行结构化处理,建立多层级的索引,使得信息查找不再是线性的,而是可以快速定位到特定主题或时间点的对话片段。这极大地提高了信息检索的效率,对于需要回溯大量历史信息的 AI 应用至关重要。
· 高效上下文检索:基于构建好的树状索引,ChatIndex 能够快速从海量对话历史中找到最相关的片段,减少了 LLM 处理的无效信息量,降低了计算成本,同时也提高了 LLM 回答的准确性。
· 长对话信息保持:通过精细化的索引和检索机制,ChatIndex 能够有效解决 LLMs 在处理超长对话时信息丢失或“遗忘”的问题,确保 AI 能够持续理解和响应对话的上下文。
· 可插拔的 LLM 集成:ChatIndex 的设计支持灵活接入不同的 LLM 模型,开发者可以根据自己的需求选择最合适的模型,而 ChatIndex 负责提供高质量的上下文信息。
· 开源的灵活性:作为开源项目,开发者可以根据自己的具体应用场景进行定制化修改和扩展,推动了 AI 应用在长上下文处理方面的技术进步。
产品使用案例
· AI 智能客服:在处理用户与客服长达数小时的咨询对话时,ChatIndex 可以帮助客服 AI 快速定位到用户之前提出的问题、已提供的解决方案以及用户的偏好,从而提供更精准、更高效的服务,而不会因为对话过长而“忘记”用户的基本诉求。这让我作为用户,能获得更一致、更省时的问题解决体验。
· AI 写作助手:当用户在进行一项复杂的创意写作项目,需要 AI 协助时,ChatIndex 可以帮助 AI 记住写作过程中产生的各种想法、大纲、参考资料以及之前的修改意见,确保 AI 在生成新内容时,能够紧密结合项目整体的上下文,提供连贯、符合预期的辅助。这让我能够更顺畅地与 AI 协同创作。
· AI 编程助手:在协助开发者进行复杂项目的编码时,ChatIndex 可以让 AI 记住整个项目的代码结构、函数调用关系、之前的 bug 修复记录以及开发者的具体需求,从而在回答编程问题、生成代码片段或查找 bug 时,提供更具针对性的帮助。这让 AI 编程助手能够真正成为一个有用的“代码记忆库”。
· AI 个人助理:对于一个需要长期管理个人信息、日程安排、兴趣爱好等内容的 AI 助理,ChatIndex 可以帮助 AI 建立一个“个人知识图谱”,高效地检索和调用用户的历史偏好、重要事件等信息,提供更个性化、更贴心的服务。这让我感觉 AI 真正了解我,并能主动提供帮助。
25
Pixel Hearth: Pixelated Fireplace for iOS Devices
作者
kingofspain
描述
一个用代码模拟像素风格的火焰燃烧效果的应用,提供在iPhone和Apple Watch上的使用体验,以及小组件(Widget)功能。它解决了用户在寒冷季节或需要放松时,渴望一种温暖、宁静的视觉体验的需求,通过数字化的方式重现了传统壁炉的温暖和舒适感。创新点在于将像素艺术与动态火焰模拟结合,并通过iOS生态系统的Widget和Watch App,将这种体验延伸到用户的日常设备中。
人气
点赞 4
评论数 0
这个产品是什么?
这是一个为iOS设备(iPhone和Apple Watch)设计的应用,它通过像素化的视觉效果模拟出一个跳动的火焰,就像一个数字壁炉。其技术核心是将复杂的火焰物理模拟简化为像素级别的渲染。开发者通过算法控制像素的颜色、亮度、形状以及它们的动态变化,来模拟出火焰上升、摇曳、熄灭的视觉效果。这种低多边形、像素化的渲染风格不仅降低了计算资源消耗,还带来了独特的复古和艺术感。用户可以将其作为一种视觉放松工具,或者仅仅是为了增加一点冬日或生活中的温暖氛围。
如何使用它?
开发者可以通过App Store下载安装这款应用。一旦安装,用户就可以在iPhone主屏幕上添加一个火焰壁炉小组件(Widget),这样即使不打开应用,也能在主屏幕上看到跳动的火焰。对于Apple Watch用户,可以直接在手表上打开应用,随时随地享受微型火焰的陪伴。应用还提供了一些个性化选项,比如调整火焰的颜色和大小,让用户可以根据自己的喜好定制视觉体验。
产品核心功能
· 动态像素火焰模拟: 使用算法实时生成像素颜色和位置变化,模拟火焰的跳动和上升,创造视觉上的温暖感和动态美。
· iPhone主屏幕小组件: 提供不同尺寸的小组件,让用户将数字壁炉“摆放”在iPhone主屏幕上,随时获得视觉上的温暖,无需打开App。
· Apple Watch companion app: 在手腕上提供一个微型火焰,让你无论身在何处都能感受到一份宁静和温暖。
· 火焰和颜色自定义: 允许用户调整火焰的形状、颜色和动态效果,实现个性化视觉体验,增强用户粘性。
产品使用案例
· 在寒冷的冬日,将火焰壁炉小组件添加到iPhone主屏幕,在浏览信息或切换App时,都能看到跳动的火焰,提供视觉上的温暖和慰藉,缓解寒冷感。
· 在工作或学习压力大的时候,打开Apple Watch上的微型火焰,专注于火焰的跳动,帮助舒缓情绪,达到一种冥想或放松的效果。
· 用户可以利用自定义选项,将火焰颜色调整为与自己的房间装饰风格相匹配,例如温暖的橙色或宁静的蓝色,使数字壁炉更好地融入生活环境。
· 开发者可以将此应用作为一种极简主义设计的范例,学习如何用最少的计算资源创造出富有感染力的视觉体验,并探索像素艺术在现代UI/UX设计中的应用潜力。
26
Beatdelay.co - 智能反拖延助手
作者
ivanramos
描述
Beatdelay.co 是一个针对拖延症的创新解决方案,它不是简单地告诉你“开始做”或“休息一下”,而是通过分析你拖延的具体原因,提供可执行的、个性化的行动步骤。它解决了用户在面对紧急任务时,因不清楚如何开始或被负面情绪困扰而陷入拖延的困境,利用AI技术生成量身定制的解决方案。
人气
点赞 2
评论数 2
这个产品是什么?
Beatdelay.co 是一个基于AI的工具,旨在帮助用户克服拖延症。它与众不同之处在于,它不仅仅提供笼统的建议,而是会询问你为什么会拖延某个特定任务(例如,是觉得任务太难、太无聊、还是害怕失败?),然后利用这些信息,通过其背后的算法生成一系列具体、可执行的步骤,让你能够立即着手。这就像是你有一个私人效率教练,它了解你的困境并给出最有效的指导。其核心创新在于将AI的理解能力与具体行动的指导相结合,从而提供真正有效的帮助,而不是空泛的鼓励。
如何使用它?
开发者可以访问 beatdelay.co 网站。当你面临一项紧迫但想拖延的任务时,只需在网站上输入任务的名称以及你拖延它的具体原因。例如,你可以输入“写项目报告 - 觉得内容太杂乱,不知道从何下手”或者“学习新框架 - 感觉知识体系太庞大,压力很大”。Beatdelay.co 会分析你的输入,并生成一套非常具体的操作指南,比如“第一步:列出报告的三个主要章节;第二步:为每个章节写一个简单的概述;第三步:花15分钟查找关于第一章内容的三个关键资料”。你可以直接按照这些步骤操作,从而打破拖延的僵局。这对于开发者来说,在面对复杂的项目、新技术的学习或者报告撰写时,能够提供即时的、个性化的指导,显著提高工作效率。你可以将它集成到你的日常工作流中,作为克服技术学习障碍或项目推进瓶颈的辅助工具。
产品核心功能
· 个性化拖延原因分析:通过自然语言输入,识别用户拖延的具体心理和情境因素,这使得AI能够更深入地理解用户的困境,而不是表面化的症状。价值在于提供更精准的诊断。
· 生成可执行的行动步骤:基于对拖延原因的分析,输出一系列微小、可操作的具体任务,这解决了用户“不知道如何开始”的核心痛点。价值在于提供清晰的行动路径。
· 任务无关性适应性:无论是什么类型的任务,从写代码到写报告,Beatdelay.co 都能提供有效的反拖延策略。价值在于其通用性和广泛的应用范围。
· 避免空泛的鼓励性话语:专注于提供实际解决方案,而非 motivational speech,这让用户能够直接获得帮助,减少无效的心理消耗。价值在于其直接有效的解决导向。
· 即时响应与交互:用户可以立即获得反馈和指导,无需等待,非常适合处理紧迫的任务。价值在于其高效性,能够快速打破拖延。
产品使用案例
· 场景:开发者需要学习一门新的编程语言或框架,但感觉内容庞杂,无从下手。解决方案:输入“学习 Rust - 觉得语法复杂,概念太多”,Beatdelay.co 可能提供“第一步:找到并运行一个简单的‘Hello, World!’程序;第二步:阅读关于变量和数据类型的官方文档第一节;第三步:尝试修改‘Hello, World!’程序,使其输出不同内容”。解决了学习路径不明朗的问题。
· 场景:开发者有一个重要的技术报告需要撰写,但因为信息收集不够全面或写作思路不清而迟迟不动笔。解决方案:输入“写项目总结报告 - 缺乏具体数据支撑,不知道如何组织论点”,Beatdelay.co 可能会建议“第一步:列出报告需要包含的三个关键指标;第二步:查找最近一周与这些指标相关的内部数据;第三步:为每个指标写一个简短的描述性句子”。解决了报告撰写中的信息组织和内容填充难题。
· 场景:开发者在维护一个复杂的老旧代码库时,因为不熟悉代码逻辑或害怕引入bug而感到畏难。解决方案:输入“修复bug X - 不理解代码中Y模块的运行逻辑”,Beatdelay.co 可能会提供“第一步:在代码中找到Y模块的入口函数;第二步:使用调试器单步执行入口函数,观察变量变化;第三步:针对bug X,在Y模块中尝试添加一个日志输出,以追踪问题发生的位置”。解决了代码理解困难和修改风险评估的问题。
27
Python 文档自动化助手:本地化代码智能文档生成器
作者
party-horse123
描述
这是一个在本地运行的智能助手,能自动为你的 Python 代码生成完整的、符合 Google 风格的文档字符串(docstrings)。它使用了 Qwen3 0.6B 参数的 SLM(小型语言模型),能理解你的代码意图,并将其转化为专业格式的文档,而且你的代码完全保留在本地,无需担心隐私泄露。所以这对我有什么用?它能大大节省你编写代码文档的时间,提升代码的可读性和可维护性,同时保护你的敏感代码不被上传。
人气
点赞 4
评论数 0
这个产品是什么?
这是一个用 Python 编写的工具,它利用了一个叫做 SLM(小型语言模型)的人工智能技术,就像一个聪明的助手一样。这个助手能够阅读你的 Python 代码,理解代码的功能,然后自动生成非常规范的文档说明,这种说明我们称之为“文档字符串”(docstrings)。它生成的文档格式非常专业,符合 Google 的代码风格指南。核心创新点在于,它能在你的电脑上本地运行,不需要把代码上传到云端,保证了代码的安全性。所以这对我有什么用?它解决了开发者编写文档的痛点,让你无需手动撰写大量重复性的文档,从而更专注于代码本身的开发,并且你的代码数据永远不会离开你的电脑。
如何使用它?
开发者只需要在你的本地开发环境里,通过命令行运行一个叫做 `localdoc.py` 的 Python 脚本,然后指定你想生成文档的 Python 文件路径即可。例如,你可以输入 `python localdoc.py --file your_script.py`。脚本就会扫描 `your_script.py` 文件中的函数、类等,然后自动在代码中插入生成的文档字符串。所以这对我有什么用?你可以轻松地将这个工具集成到你的开发流程中,每次写完代码或修改代码后,运行一下这个脚本,就能快速获得规范的文档,让你的代码更容易被理解和复用。
产品核心功能
· 自动生成 Python 函数和类的文档字符串:利用 SLM 模型分析代码逻辑,自动生成详细的参数、返回值和功能描述,提高代码可读性。
· 支持 Google 风格的文档格式:生成的文档字符串完全符合業界广泛接受的 Google 代码风格,方便团队协作和代码审查。
· 本地化运行,保护代码隐私:模型在本地运行,无需上传代码到任何服务器,确保敏感或专有代码的安全,让你安心使用。
· 命令行接口,易于集成:提供简单的命令行工具,开发者可以方便地将其集成到现有的构建脚本或 CI/CD 流程中,实现文档的自动化。
· 支持小型模型,资源消耗低:使用了 0.6B 参数的 Qwen3 模型,这意味着它对计算资源的要求相对较低,可以在更多设备上运行,降低使用门槛。
产品使用案例
· 在开发一个大型 Python 项目时,开发者可以使用该工具快速为新添加的函数或类生成初步的文档,为后续的手动完善打下基础。
· 一个开源项目的维护者,希望提高项目的文档质量和规范性,可以利用此工具批量生成或更新现有代码的文档,吸引更多贡献者。
· 对于有严格代码规范要求的公司,可以使用该工具确保所有 Python 代码都遵循统一的文档风格,简化代码审查过程。
· 个人开发者希望快速整理自己的代码库,让代码更易于理解和分享,可以使用此工具为分散的代码模块生成集中的文档说明。
28
SchemaLuauSync: JSON Schema 到 Luau 类型自动同步器
作者
amirfarzamnia
描述
这是一个用 Rust 编写的工具,可以将 JSON Schema 自动转换成 Luau(一种用于 Roblox 游戏开发的脚本语言)的类型定义。它的核心价值在于解决了游戏开发中数据校验和代码生成不同步的问题,确保了前端(JSON)和后端(Luau)的数据结构一致性,极大地提高了开发效率和代码健壮性。
人气
点赞 3
评论数 1
这个产品是什么?
SchemaLuauSync 是一个命令行工具,它读取一个 JSON Schema 文件(描述了数据的结构和规则),然后生成一份对应的 Luau 类型定义文件。JSON Schema 就像是一份详细的数据说明书,规定了什么样的数据是有效的;而 Luau 类型定义则是 Luau 语言理解和使用这些数据的“字典”。以前,开发者需要手动将 JSON Schema 的规则转化为 Luau 的类型,这个过程既耗时又容易出错。SchemaLuauSync 使用 Rust 强大的类型系统和模式匹配能力,能够精准地解析 JSON Schema 的各种定义,并生成严谨的 Luau 类型,从而实现数据结构定义的自动化同步。这意味着,你一次更新 JSON Schema,它就能帮你自动更新 Luau 的类型,省去了大量重复劳动,并且减少了因手动转换带来的bug。
如何使用它?
开发者可以将 SchemaLuauSync 集成到他们的 CI/CD 流程中,或者在开发过程中手动运行。首先,确保你的项目中有 JSON Schema 文件(例如 `data.schema.json`)和 Luau 代码。然后,通过命令行执行 SchemaLuauSync,指定输入(JSON Schema 文件)和输出(Luau 类型文件)的路径。例如:`schema-luau-sync --input data.schema.json --output types.luau`。生成的 `types.luau` 文件可以直接导入到 Luau 代码中使用,用于数据验证和类型提示。这可以用来验证从网络请求接收到的数据,或者确保游戏内不同模块之间传递的数据格式正确。
产品核心功能
· JSON Schema 解析:能够理解和解析 JSON Schema 中定义的各种数据类型(字符串、数字、布尔值、数组、对象)以及约束(如最小值、最大值、正则表达式匹配),确保数据的准确性。这意味着你可以自信地定义复杂的数据结构,而不用担心机器无法理解。
· Luau 类型生成:根据解析出的 JSON Schema,生成对应的 Luau 类型定义。这使得 Luau 代码能够“知道”数据的形状,提供智能代码补全和编译时错误检查。所以,你的代码会更少出错,开发速度也会更快。
· 自动化同步:作为一项核心功能,它能够将 JSON Schema 的更新自动反映到 Luau 类型中。这意味着无论何时你改变了数据的定义,代码的类型检查都能同步更新,省去了手动修改的麻烦,避免了因版本不一致导致的问题。这对大型项目或者多人协作尤为重要。
· Rust 性能优化:利用 Rust 高效的编译和运行性能,保证了转换过程的快速和资源的低消耗。所以,即使处理非常庞大的数据 schema,工具也能迅速完成任务,不会拖慢你的开发流程。
产品使用案例
· Roblox 游戏服务器数据校验:游戏服务器接收来自客户端的玩家数据(例如物品购买、角色升级等),这些数据应该遵循一个预先定义的 JSON Schema。SchemaLuauSync 可以将这个 Schema 转换为 Luau 类型,然后在服务器端用生成的类型来快速、准确地校验接收到的数据。这有效防止了恶意用户通过发送非法数据来破坏游戏平衡,保障了游戏的安全性。
· 跨模块数据接口定义:在一个复杂的 Luau 项目中,不同的模块需要交换数据。开发者可以使用 JSON Schema 来定义这些数据交换的格式。SchemaLuauSync 可以将这些定义转化为 Luau 类型,让不同模块的开发者都能清晰地知道对方需要什么样的数据,以及会返回什么样的数据。这就像是给不同团队成员提供了一本通用的“语言词典”,确保沟通无误,加速了开发。
· 动态配置管理:游戏中的一些配置参数(如怪物属性、关卡设置)可以通过 JSON 文件进行管理,并用 JSON Schema 进行约束。SchemaLuauSync 可以将这些配置的 Schema 转换为 Luau 类型,使得游戏代码能够直接读取和使用这些配置,并且在读取时就能进行类型检查。这样,配置文件的更新就不会意外导致代码崩溃,提高了配置管理的灵活性和稳定性。
29
日文闪电侠:开源汉字词汇练习平台
作者
yourladybug
描述
这是一个受打字练习网站Monkeytype启发的,完全免费、开源的日语汉字和词汇学习平台。它解决了市面上大多数日语学习应用付费订阅和功能限制的问题,通过游戏化的方式,让学习者能高效、有趣地练习和记忆日语知识。其核心创新在于将打字练习的机制引入到语言学习中,实现了极高的练习效率和用户参与度。
人气
点赞 3
评论数 0
这个产品是什么?
这个项目是一个在线的日语学习工具,专门用来练习和巩固日语汉字(Kanji)和词汇。它的技术原理是将你输入的内容和屏幕上显示的日文信息进行实时比对,就像打字练习一样。如果你输入的正确,它就会显示下一个内容。这种快速的反馈机制,结合了游戏化的元素,可以极大地提高你记忆和辨认汉字词汇的速度。它最大的创新点在于,它完全免费,没有广告,而且是开源的,这意味着任何人都可以查看它的代码,甚至贡献自己的想法来改进它,这在很多商业日语学习软件中是很难找到的。
如何使用它?
开发者和日语学习者可以通过访问项目的在线平台来直接使用。在网站上,你可以选择你想练习的汉字或词汇难度级别,然后系统会呈现出日文词汇或汉字,你需要尽快准确地将其输入到指定的区域。它还可以根据你的输入速度和准确率给出评分,让你了解自己的进步情况。对于有技术背景的用户,还可以查看和参与到GitHub上的开源项目,贡献代码,甚至根据自己的需求定制更高级的练习模式。这对于希望系统性提高日语能力,或者正在备考日语能力考试(JLPT)的学习者来说,是一个高效且成本极低的练习工具。
产品核心功能
· 即时反馈的汉字词汇输入练习:通过模拟打字的速度和准确性来练习日文,能显著提升记忆效率,让你更快掌握日文知识。
· 自定义练习内容和难度:可以根据自己的学习进度和需求,选择不同的汉字和词汇集进行练习,确保学习内容是最适合你的。
· 游戏化评分和进度追踪:通过得分和进度的可视化,让学习过程充满乐趣,并能清晰地看到自己的进步,激励持续学习。
· 完全免费且无广告:这意味着你可以不受任何干扰地专注于学习,无需支付任何费用,解决了商业学习软件的经济负担。
· 开源社区驱动:任何人都可以参与到项目的开发中,这意味着它能更快地响应用户需求,不断更新和优化,让学习工具始终保持先进和实用。
产品使用案例
· 一名正在准备JLPT N3考试的学生,每天使用该平台练习N3级别的汉字和词汇。通过平台的高速输入和即时反馈,他发现自己记忆词汇的速度比传统背诵方式快了近一倍,而且错误率显著降低,这是因为平台模拟了实际考试中快速辨认和输出的需求。
· 一位对日本文化感兴趣的初学者,希望学习一些常用的日文词汇。他通过平台选择基础词汇进行练习,游戏化的界面和挑战模式让他觉得学习过程很有趣,而不是枯燥的背诵,从而保持了学习的动力,并且能快速掌握常用表达。
· 一名开发者,对使用代码解决实际问题充满热情。他发现了这个开源项目,并为项目贡献了新的练习模式,比如根据汉字部首进行联想记忆的练习,这不仅提升了他个人的编程技能,也为整个社区的学习者提供了更多样化的学习工具。
30
Mac原生SES模板管家
作者
gtlsgamr
描述
一个本地运行的macOS应用,帮你摆脱AWS SES邮件模板管理的混乱。它像操作本地文件一样,让你轻松创建、编辑、测试和同步AWS SES模板,避免了在不同工具间切换的麻烦,让邮件模板管理流程更流畅、更直观。对于需要频繁管理AWS SES邮件模板的开发者来说,这是一个极大的效率提升。
人气
点赞 3
评论数 0
这个产品是什么?
这是一个为macOS用户设计的原生应用程序,它能让你在本地直接管理AWS Simple Email Service (SES) 中的邮件模板。告别在网页控制台、命令行脚本和JSON文件之间来回切换的繁琐,这个App提供了一个统一、流畅的本地编辑体验。它的核心创新在于将原本需要通过API请求或繁琐网页操作才能完成的SES模板管理,转化为类似编辑本地文档一样的直观体验,所有操作都在你的Mac本地完成,不经过任何第三方服务器,确保了数据安全和隐私。
如何使用它?
开发者可以使用这个App,通过配置你自己的AWS账户凭证(Access Key ID 和 Secret Access Key),App就能直接连接并同步你的AWS SES模板。你可以直接在App内置的文本编辑器中编写和修改HTML和文本格式的邮件模板,然后一键保存到AWS SES,或者创建全新的模板。App还提供了一个方便的测试功能,让你能在发送前预览和发送测试邮件,确保模板效果。这使得在开发过程中,可以更快速地迭代和测试邮件内容,大大缩短了从开发到上线的周期。
产品核心功能
· 原生Mac应用体验:提供类似操作本地文件的流畅体验,直接在Mac上编辑邮件模板,无需依赖浏览器或复杂的命令行工具,大大提升了操作的便捷性和效率。
· 本地编辑与同步:允许你在本地计算机上创建、编辑SES邮件模板,并能一键同步到你的AWS SES账户,避免了在线编辑的延迟和潜在的网络问题,确保了编辑过程的顺畅。
· 直观的测试与发送:内置邮件测试功能,可以直接发送测试邮件到指定邮箱,让你在正式上线前充分验证模板效果,减少了出错的可能性,提高了邮件营销的精准度。
· 安全与隐私保护:所有操作均在本地执行,不上传任何数据到开发者服务器,保障了AWS账户凭证和邮件模板的安全性。
· 离线创建与编辑:可以在没有网络连接的情况下编辑和创建模板,待网络恢复后再进行同步,提高了工作的灵活性。
产品使用案例
· 开发者在进行大规模邮件营销活动前,需要频繁修改和测试大量邮件模板。使用SES Template Manager,可以直接在Mac上本地编辑,并通过内置的测试功能快速验证不同变量下的模板显示效果,无需频繁登录AWS控制台,大大缩短了测试周期。
· 一位独立开发者需要为他的SaaS产品集成AWS SES发送通知邮件,但又不希望引入额外的云服务来管理模板。他可以使用SES Template Manager在本地管理所有通知邮件模板,仅使用其AWS账户凭证即可,所有敏感信息都在本地,无需担心数据泄露。
· 远程工作的团队需要共享和维护SES邮件模板。通过SES Template Manager,团队成员可以在本地进行编辑和测试,并将最终确定好的模板推送到AWS SES,保持了版本的一致性,同时避免了多人同时编辑可能产生的冲突。
31
空间视界-AI对抗3D空间推理验证码
作者
Shining_S
描述
这是一个创新的验证码技术,通过要求用户进行3D空间推理来验证其是否为人类,从而有效抵御AI机器人。
人气
点赞 1
评论数 2
这个产品是什么?
空间视界是一个新的验证码生成和验证系统,它不再是传统的文字或图片识别,而是要求用户在一个3D空间中进行操作,比如旋转物体、判断物体相对位置等。这背后的技术原理是,目前AI在理解和操纵3D空间信息方面仍然存在挑战,而人类的视觉和空间认知能力则非常强大。所以,通过这个方法,我们可以更智能地区分人类和AI,提升网站和应用的安全性。简单来说,它用你的空间想象力来替你挡住机器。
如何使用它?
开发者可以将空间视界集成到他们的网站或应用程序中,作为用户注册、登录或执行敏感操作时的身份验证环节。集成方式通常是通过API调用。当用户需要验证时,系统会向用户展示一个3D场景和任务,用户完成任务后,系统会返回验证结果。比如,一个网站可能要求用户将一个3D图形旋转到某个特定角度,或者从多个视角中选择正确的那个。这能让你的应用在面对机器人攻击时更加安全,同时给用户一种新颖有趣的体验。
产品核心功能
· 3D空间推理任务生成:系统能生成各种不同难度的3D空间推理题目,每道题都需要用户运用空间想象力去解决,这是其对抗AI的关键,因为AI对这类任务的理解和执行能力较弱,所以能有效识别出机器。
· 交互式3D验证界面:提供用户友好的3D交互界面,允许用户在浏览器中直接操作3D模型,比如进行旋转、缩放等,这使得验证过程直观且易于操作,即使是非技术用户也能轻松上手。
· AI对抗能力评估:通过设计具有挑战性的3D空间推理任务,系统能有效区分人类和AI机器人,随着AI技术的发展,还可以不断更新和优化任务难度,持续保持对抗优势,这能大大降低被机器人刷爆的风险。
· API集成支持:提供简洁的API接口,方便开发者将其集成到现有的Web应用、移动App或任何需要身份验证的场景中,开发者可以快速接入,提升应用的安全性,而无需花费大量时间从零开始构建验证系统。
产品使用案例
· 在线票务抢购:在进行高价值门票抢购时,使用空间视界验证,可以有效防止机器人脚本在短时间内大量刷票,确保普通用户的购票机会,让辛苦等待的用户能真正买到票。
· 金融交易验证:在进行大额转账或敏感的账户操作时,引入空间视界验证,能增加一层安全保障,防止恶意机器人冒充用户进行非法操作,保护用户的资金安全。
· 游戏账号注册:防止游戏账号被批量注册用于作弊或倒卖,空间视界可以通过独特的3D交互来区分真人玩家和机器人,保障游戏的公平环境,让玩家有更好的游戏体验。
· 内容访问限制:对于需要付费或特定用户才能访问的内容,使用空间视界进行验证,可以防止机器人爬虫批量抓取,保护内容创作者的劳动成果,确保内容只被真正感兴趣的用户看到。
32
AI智能资讯聚合器
作者
mmntns
描述
curAIted.dev 是一个AI驱动的资讯聚合博客,它能智能地收集和总结人工智能领域的最新发展动态。与市面上关注具体产品不同,curAIted.dev 聚焦于AI技术的基础原理,专为工程师群体打造,帮助开发者高效地获取前沿知识,无需投入大量时间。
人气
点赞 2
评论数 1
这个产品是什么?
curAIted.dev 是一个利用人工智能技术(特别是大型语言模型,LLMs)自动抓取和提炼人工智能领域深度技术文章的资讯聚合平台。它区别于简单的新闻推送,而是通过AI对海量信息进行筛选和概括,同时由人工团队对信息源进行精选,确保内容的质量和技术深度。这就像一个智能助手,帮你从信息爆炸中过滤出最有价值的AI技术干货,让你能快速掌握AI领域的核心思想和最新进展。所以,这对你来说,意味着你能更省时省力地学习AI前沿技术,保持技术敏锐度。
如何使用它?
开发者可以通过访问 curAIted.dev 网站来浏览最新的人工智能技术资讯。它本身就是一个已经部署好的博客,无需复杂的安装或配置。你可以直接在网站上阅读AI技术原理、新算法、研究成果等的摘要和链接。如果你的开发工作需要紧跟AI领域的发展,或者你对某个AI技术方向感兴趣,可以直接将curAIted.dev 加入你的日常学习或工作流程中,定期查看更新,快速了解行业趋势。它也可以作为你研究新AI技术时的信息起点。所以,这对你来说,意味着一个方便快捷获取AI技术信息的高效渠道。
产品核心功能
· AI智能内容抓取与摘要:利用大型语言模型(LLMs)技术,自动扫描互联网上关于AI的专业文章,并生成简洁的摘要。这能大大缩减你阅读一篇技术文章的时间,快速抓住核心信息,并判断其价值。所以,这能让你在短时间内了解更多AI新知。
· 人工精选信息源:由人工团队对AI生成的内容来源进行筛选和审核,确保内容的高质量和技术深度。这避免了AI可能带来的信息噪音或错误信息,保证你看到的是真正有价值的技术洞察。所以,这能确保你获取的信息是可靠且有深度的。
· 博客式内容呈现:以易于阅读的博客形式展示AI技术资讯,突出技术原理而非产品应用。这种方式更符合工程师的学习习惯,便于理解和吸收复杂的技术概念。所以,这能让你更容易地理解AI技术的核心和发展方向。
· 低成本运行的实验性架构:项目使用Astro前端框架,后端由Python驱动,并充分利用免费的云服务层级来运行。这展示了利用现有技术和资源实现高效信息服务的可行性,体现了黑客精神,即用最经济的方式解决实际问题。所以,这让你看到了用有限资源实现技术创新的可能性,也能激发你对低成本技术方案的思考。
产品使用案例
· AI研究者快速了解最新的AI算法和理论研究进展。例如,某个新的深度学习模型被提出,curAIted.dev 可能会汇总几篇相关论文的摘要,让你快速了解其核心思想和潜在应用。所以,这能帮助你快速追踪AI学术前沿。
· 机器学习工程师评估某个新技术或工具是否值得深入学习。当出现一个新的AI框架或库时,curAIted.dev 可能会提供该技术的基础原理介绍和相关讨论,帮助你快速做出决策。所以,这能帮助你判断新技术的实用价值。
· 产品经理或技术决策者了解AI技术在不同领域的最新应用趋势和发展潜力。虽然curAIted.dev 侧重原理,但对原理的深入理解也间接反映了其潜在的应用方向。所以,这能帮助你从技术根源上理解AI的未来趋势。
· 对AI感兴趣的开发者,在业余时间高效学习AI知识。curAIted.dev 提供了一个结构化的信息来源,让你不必大海捞针,就能获取到有价值的AI技术信息。所以,这能让你轻松地提升AI技术知识储备。
33
Agent Playbook:AI特工的沙盒实验室
作者
orlevii
描述
Agent Playbook 是一个开源工具,它借鉴了UI开发中非常流行的Storybook的理念,为AI特工(AI Agents)提供了一个独立的、可交互的开发和调试环境。它能自动发现你正在开发的AI特工,并在本地启动一个网页界面,让你能够像玩游戏一样,轻松地与AI特工对话,观察它的思考过程,并快速迭代优化,大大提高开发效率。所以,它能帮你解决在开发AI应用时,每次修改一点点就需要运行整个程序或者写很多临时脚本的麻烦,让你的开发过程更顺畅。
人气
点赞 3
评论数 0
这个产品是什么?
Agent Playbook 是一个专门为AI特工(AI Agents)设计的,类似UI组件开发工具Storybook的“游戏场地”。想象一下,开发UI时,我们可以用Storybook单独测试每个按钮、每个输入框,而不用启动整个应用。Agent Playbook 就是把这个概念应用到了AI特工身上。它能自动找到你写的AI特工代码,然后搭建一个网页界面。在这个界面里,你可以直接和你的AI特工“聊天”,就像和真人一样。更厉害的是,你还能看到AI特工是怎么一步步思考出答案的,就像看一个侦探破案一样。它的核心创新在于,将AI特工的开发从复杂的整体应用中剥离出来,进行孤立、可视化的测试和调试,就像给AI特工搭了一个专属的“实验室”。所以,它能让你在开发AI特工时,不再需要每次都启动庞大的应用,而是能集中精力,专注于AI特工本身的设计和优化,从而更高效地找到AI特工的“智慧”所在。
如何使用它?
开发者在使用Agent Playbook时,通常需要将其集成到你的AI特工开发项目中。如果你使用pydantic-ai库来构建AI特工(目前是它的主要支持对象),Agent Playbook能够自动扫描并发现你定义的AI特工。一旦扫描完成,它就会在你的本地启动一个Web服务器,生成一个直观的网页操作界面。你可以直接在这个界面里选择你想测试的AI特工,然后输入问题或指令,与AI特工进行实时互动。你还能看到AI特工在处理你的指令时,内部的思考逻辑和调用工具的步骤,这有助于你理解AI特工的行为并进行调试。每次你对AI特工的代码做了修改,Agent Playbook都能近乎实时地检测到并更新,让你能够迅速看到改动带来的效果,无需手动重启。所以,它就像是为你AI特工开发提供了一个“即插即用”的测试台,让你在编写代码的同时,就能随时随地进行测试和优化,大大节省了开发和调试的时间。
产品核心功能
· AI特工的自动发现和注册:Agent Playbook能够智能地扫描你的项目,找出你定义的AI特工,并将其添加到待测试列表中,无需手动配置,让开发者省去繁琐的设置步骤,直接开始开发。
· 交互式AI特工沙盒:提供一个在线的聊天界面,开发者可以像用户一样与AI特工进行实时对话,输入提示词并接收响应,以便直观地评估AI特工的表现。
· AI特工推理过程可视化:能够展示AI特工在生成响应过程中所经历的思考步骤、调用函数、查询信息的细节,帮助开发者理解AI特工的内部工作机制,从而更容易定位问题。
· 代码热重载与实时预览:当开发者修改AI特工的代码后,Agent Playbook能够自动检测到变化并立即更新测试环境,无需手动重启应用,实现快速迭代和即时反馈。
· 对pydantic-ai等AI框架的支持:目前主要支持使用pydantic-ai开发的AI特工,这意味着使用该框架的开发者可以立即享受到Agent Playbook带来的便利,并方便地扩展到其他AI开发框架。
· 本地Web UI界面:通过一个易于访问的本地Web界面来管理和测试AI特工,使得开发和调试过程更加友好和直观,降低了技术门槛。
· 提供API接口进行程序化集成:虽然目前主要是Web UI,但其设计思路也为未来提供API接口奠定了基础,允许其他工具或脚本与Agent Playbook进行交互,实现更复杂的自动化测试流程。
产品使用案例
· 场景:AI客服机器人开发。开发者在设计一个AI客服时,可能需要不断调整它理解用户意图、查找知识库、生成回答的逻辑。使用Agent Playbook,开发者可以直接与客服AI对话,输入各种用户可能提出的问题,然后观察AI的回答以及它的思考过程。如果AI的回答不准确或逻辑不清,开发者可以立即查看推理过程,找到是哪个环节出了问题,然后修改代码,并立即进行下一次测试,而不用等待整个客服系统启动。
· 场景:AI内容创作助手。比如一个AI写作助手,需要根据用户的简单指令生成长篇文章。开发者可以通过Agent Playbook,输入不同的写作提示,比如“写一篇关于太空探索的科幻短篇小说”,然后查看AI是如何构思情节、描写人物、组织语言的。如果AI生成的内容不够吸引人,或者逻辑上有漏洞,开发者就能利用Agent Playbook的可视化调试功能,找出AI在构思或表达上的不足,并进行优化,使其创作能力更上一层楼。
· 场景:AI工具调用优化。很多AI特工需要调用外部工具(如搜索引擎、计算器、数据库查询等)来完成任务。开发者在Agent Playbook中,可以清晰地看到AI特工在执行任务时,具体调用了哪些工具,传递了什么参数,以及工具返回的结果。这有助于发现AI是否调用了错误的工具,或者参数传递不正确,从而优化AI与工具的协作效率。
· 场景:AI代理的行为策略研究。当开发更复杂的AI代理,需要它们能够自主地完成一系列任务时,Agent Playbook提供的推理过程可视化就显得尤为重要。开发者可以观察AI代理在面对复杂决策时,是如何权衡利弊、选择行动路径的,这对于理解和改进AI代理的决策能力非常有帮助。
· 场景:AI模型的微调和Prompt工程。对于大量使用Prompt Engineering的开发者来说,Agent Playbook提供了一个即时的实验平台。无需每次都部署模型,可以直接在Playbook中测试不同的Prompt组合,观察AI模型的输出变化,从而找到最优的Prompt策略,加速模型的微调和优化过程。
34
日文速记师
作者
aladybug
描述
这是一个受打字练习网站Monkeytype启发的开源日本语学习平台,旨在提供一个免费、无广告且高度可定制的日文汉字和词汇练习工具。它通过模拟打字练习的快感,帮助用户高效记忆和掌握日文学习内容,解决了市面上许多日文学习应用普遍存在的订阅收费和内容限制问题。
人气
点赞 3
评论数 0
这个产品是什么?
日文速记师是一个专门为想学习日文(尤其是汉字和词汇)的人设计的在线工具。它的核心技术理念是将学习过程游戏化,就像打字练习网站Monkeytype那样,让用户通过快速输入来记忆。具体来说,它会展示日文的汉字或词汇,然后要求用户快速准确地打出来。这种“边打边记”的方式,能够极大地增强记忆的深度和速度。与其他收费的日文学习App不同,日文速记师是完全免费、开源且无广告的,它希望能汇聚开发者的力量,共同打造一个高质量的学习平台。
如何使用它?
开发者可以直接访问日文速记师的网站进行练习。对于想将其集成到自己项目或进行二次开发的开发者,可以查看其GitHub仓库。例如,开发者可以利用其API将日文汉字或词汇数据流式传输到自己的应用中,或者借鉴其前端交互设计来构建类似的学习模块。它提供了高度的可定制性,意味着开发者可以根据自己的需求调整练习模式、词汇集甚至界面风格,为自己的产品或学习流程增加一个强大的日文学习组件。
产品核心功能
· 快速汉字/词汇输入练习:通过像打字游戏一样的模式,用户需要快速准确地输入屏幕上出现的日文汉字或词汇,从而在高速操作中加深记忆。价值在于将枯燥的记忆过程变得有趣高效,提升学习效率。
· 高度可定制的练习模式:用户可以自由选择练习的词汇范围(如N5、N4级别,或特定主题),调整每个练习项的显示时间、输入时的提示方式等。价值在于满足不同水平和需求的学习者,提供个性化的学习体验。
· 开放源代码与社区驱动:项目的源代码完全公开,鼓励开发者贡献代码、报告bug或提出新功能。价值在于保证了平台的持续改进和免费性,让社区的力量驱动产品发展,为所有用户提供高质量的免费资源。
· 无广告与无订阅:平台承诺永久免费,没有任何广告干扰,也不会强制用户订阅。价值在于为学习者提供了纯净的学习环境,消除了经济负担,让学习本身成为唯一的焦点。
产品使用案例
· 一个正在开发日语学习App的独立开发者,可以集成日文速记师的词汇流API,将其作为App内的一个特色练习模块,让用户以打字闯关的方式学习词汇,增加App的趣味性和用户粘性。
· 一位对日本动漫感兴趣的初学者,想要快速掌握看懂字幕所需的词汇量,可以直接使用日文速记师在线练习,利用其游戏化的界面和即时反馈,在娱乐中达到学习目标,而无需支付任何费用。
· 一个教授日语的在线教育机构,可以推荐日文速记师作为课外练习工具,教师可以根据教学进度指定特定的词汇集,学生们可以通过竞争排行榜来互相激励,提高整体学习效果。
· 一位对编程语言学习有心得的开发者,想要用代码来解决学习日语的痛点,可以参与到日文速记师的开源项目中,贡献代码优化用户体验,或开发新的辅助学习功能,将黑客精神应用于语言学习的创新。
35
JIT编译的MCP智能体
作者
ardmiller
描述
这个项目探索将人工智能中的一种经典模型——多智能体系统(MCP, Multi-Agent Communication Protocol)中的智能体,直接编译成计算机可以高速执行的代码(JIT compilation)。它的核心在于,通过这种方式,能让原本需要解释执行、效率较低的AI智能体,运行速度大幅提升,从而更快地进行决策和交互。这解决了AI模型在需要实时响应和高计算吞吐量场景下的性能瓶颈。
人气
点赞 3
评论数 0
这个产品是什么?
这是一个实验性的项目,它把在人工智能领域里,用来模拟多个自主决策单元(就像很多小机器人或程序在互相交流和合作)的“MCP智能体”变得更快。通常,这些智能体是用一种解释性的方式运行的,就像阅读一本说明书并一步步照做。而这个项目则使用了“即时编译”(JIT compilation)的技术,这就像是把说明书上的指令变成了一种机器语言,让电脑能直接、快速地执行,大大提高了智能体的反应速度和处理能力。所以,它的创新之处在于把AI的“思考”过程直接转化成了机器能“飞速运转”的代码。
如何使用它?
开发者可以将自己设计的MCP智能体模型,通过这个项目的工具进行JIT编译。编译后生成的代码可以直接集成到需要高性能AI交互的应用程序中,比如实时策略游戏、复杂的模拟系统、需要快速响应的机器人控制系统等。开发者可以通过遵循项目提供的接口,将现有的MCP智能体代码转换为可执行的机器码,从而在他们的应用中获得更快的AI决策速度,提升用户体验和系统效率。
产品核心功能
· MCP智能体即时编译:将AI智能体的决策逻辑,通过JIT技术转换成高度优化的机器码。这意味着AI能更快地做出反应,解决了AI在高速互动场景下的延迟问题。
· 性能加速:显著提升AI智能体的执行效率,使其能够处理更大量的计算任务,实现更复杂的交互。这对于需要即时反馈的应用来说至关重要。
· 代码集成接口:提供标准化的接口,方便开发者将编译后的AI代码集成到现有的C++等高性能编程语言项目中。让AI能力能够无缝对接你的应用程序。
· 实验性AI优化:探索AI模型执行的新路径,为未来更高效、更灵活的AI部署提供技术思路。这能帮助开发者理解如何在AI性能上实现突破。
产品使用案例
· 在实时策略游戏中,让AI控制的单位能够以极快的速度分析战场局势并做出最优决策,从而大幅提升游戏的挑战性和趣味性。开发者可以通过编译AI控制逻辑,让游戏中的AI比玩家的反应还快。
· 开发需要AI进行实时路径规划的无人机或机器人系统。通过JIT编译,AI能够以毫秒级的速度更新路径,确保在复杂环境中安全高效地运行。这使得机器人的‘大脑’能够更敏捷地思考。
· 构建大型模拟系统,例如城市交通模拟或金融市场模拟,其中包含大量相互作用的AI代理。JIT编译能让这些代理以惊人的速度进行交互和决策,使整个模拟更加真实且可控。这能帮助研究者更快地跑出大量模拟数据。
· 为需要快速响应用户指令的虚拟助手或游戏NPC开发更智能的交互引擎。AI能瞬间理解并响应用户的复杂指令,带来更流畅、更自然的交互体验。让你的虚拟角色不再‘迟钝’。
36
Go-async: Go语言的异步编程助手
作者
unkn0wn_root
描述
Go-async 是一个为 Go 语言设计的库,它通过模拟 async/await 的模式,为开发者提供了更直观、更易于管理的异步任务执行方式。它解决了 Go 语言中处理并发和异步操作时,代码逻辑可能变得复杂、难以追踪的问题,让异步代码像同步代码一样容易理解和编写。
人气
点赞 3
评论数 0
这个产品是什么?
Go-async 是一个Go语言的库,它的核心理念是让异步编程变得像同步编程一样简单。想象一下,当你需要同时做很多事情,比如请求好几个网站的数据,但又不希望一个任务卡住其他任务,这时候就需要异步编程。Go语言本身提供了goroutine和channel来处理并发,但对于复杂的异步流程,代码可能会变得有点难读。Go-async 引入了类似其他语言(如Python、JavaScript)中的 async/await 概念,它将一系列异步操作封装成一个个“任务(Task)”,并允许你用一种顺序的、线性的方式来编写这些任务的执行流程。这意味着你可以写出看起来像一步一步执行的代码,但实际上这些步骤是并行或异步进行的,不会互相阻塞。它通过类型安全的方式来管理这些任务,确保在执行过程中不容易出错。
如何使用它?
开发者可以将 Go-async 库集成到自己的 Go 项目中。当你需要执行一个耗时的异步操作(例如网络请求、文件读写、数据库查询等)时,你可以使用 Go-async 来定义一个异步任务。然后,你可以使用 Go-async 提供的 `await` 函数来等待这个任务的完成,而不会阻塞整个程序的运行。这样,你就可以在一个函数中,清晰地定义多个异步操作的执行顺序和依赖关系,让代码逻辑更加清晰。它特别适合处理需要同时发起多个网络请求、处理大量事件流或者需要构建复杂并行计算的场景。
产品核心功能
· 异步任务封装:将耗时的异步操作包装成一个可管理的“任务”对象,方便追踪和控制,避免代码混乱。
· 类型安全:通过类型系统确保任务之间的交互安全,减少运行时错误,提高代码健壮性。
· async/await 风格API:提供类似于 async/await 的API,让开发者能够以同步代码的风格编写异步逻辑,大大降低学习成本和提高开发效率。
· 并发任务调度:能够有效地调度和管理多个异步任务的执行,确保资源得到合理利用。
· 结果组合与传递:支持方便地组合多个异步任务的结果,并将结果在任务之间传递,实现复杂的异步数据流处理。
产品使用案例
· 并行爬取多个网页数据:在一个爬虫程序中,你可以使用 Go-async 同时向多个URL发起请求,并等待所有结果返回,无需手动管理多个goroutine和channel。
· 微服务间顺序调用与聚合:在构建微服务时,如果一个服务需要依次调用多个其他服务获取数据,并最终聚合结果,Go-async 可以清晰地定义这个调用链。
· 实时数据流处理:对于需要处理大量实时数据的应用,如消息队列消费者,可以使用 Go-async 来异步地处理每个消息,并组合处理结果。
· 构建响应式UI交互(在服务器端):虽然Go主要用于后端,但其异步能力可以用于模拟客户端的响应式行为,例如在处理用户请求时,异步加载不同的内容组件。
37
OpEx: Elixir 智能体工具包
作者
kenforthewin
描述
OpEx 是一个为 Elixir 语言设计的、基于大型语言模型(LLM)的智能体(agent)工具包。它能够让 Elixir 应用更方便地集成 LLM 的能力,实现自动化任务和更智能的响应。项目的核心创新在于将 LLM 的推理和生成能力,以一种结构化、可控的方式融入 Elixir 的函数式编程范式中,为开发者提供了一个强大的工具来构建更具智慧的应用程序。
人气
点赞 3
评论数 0
这个产品是什么?
OpEx 是一个用 Elixir 编写的、专门为构建智能体的工具包。智能体(agent)可以理解为一种能够思考、规划并执行任务的软件程序。OpEx 的技术原理是将大型语言模型(LLM),比如 GPT 系列,作为智能体的“大脑”,让它们能够理解指令、分析信息,并生成下一步行动的计划。OpEx 的创新之处在于,它提供了一套 Elixir 的库和方法,让开发者可以将 LLM 的强大能力,以一种声明式(declarative)且高度可控的方式集成到 Elixir 项目中。这就像给 Elixir 应用安装了一个能自主思考和执行任务的助手,而且这个助手还能以 Elixir 特有的高效、并发的方式工作。
如何使用它?
开发者可以将 OpEx 集成到他们的 Elixir 项目中,通过编写 Elixir 代码来定义智能体的行为和目标。例如,你可以让 OpEx 驱动一个智能体来自动回复用户邮件,或者分析大量日志文件并生成报告。使用方式上,开发者可以通过 OpEx 定义任务的流程、输入输出的数据格式,以及智能体需要访问的外部工具(例如数据库查询、API 调用等)。OpEx 会负责将这些定义转化为与 LLM 的交互,并将 LLM 的输出结果解析成 Elixir 可以理解和使用的格式。简单来说,就是你用 Elixir 告诉 OpEx 你想让智能体做什么,OpEx 就会负责协调 LLM 来完成这些任务。
产品核心功能
· LLM 集成与调用:提供一个简单易用的接口,让 Elixir 应用能够方便地调用各种大型语言模型,解决“怎么让我的程序和 AI 对话”的问题。
· 任务规划与执行:允许开发者定义复杂的任务流程,智能体可以根据 LLM 的判断,自主地规划和执行一系列子任务,实现“让 AI 帮我把一件大事拆分成小步骤并一步步完成”的功能。
· 工具使用能力:赋予智能体调用外部工具(如数据库、API)的能力,使得智能体不仅能思考,还能实际操作,解决“让 AI 不仅能查资料,还能帮我执行操作”的需求。
· 状态管理与记忆:支持智能体在多次交互中保持上下文信息和记忆,让对话或任务执行更加连贯和智能,避免“AI 总是记不住之前说过的话”的尴尬。
· 可控的输出生成:提供机制来约束 LLM 的输出,确保生成的答案符合预期的格式和内容,解决“AI 给我一个乱七八糟的结果”的担忧。
产品使用案例
· 构建智能客服机器人:在 Elixir 的 Web 应用中集成 OpEx,让客服机器人能够理解用户的复杂问题,并调用知识库或执行特定操作来提供精准的服务,解决“客服机器人只会说固定套话”的问题。
· 自动化内容生成与摘要:利用 OpEx 对大量文本数据进行分析、总结,并生成报告或摘要,应用于新闻聚合、市场分析等场景,解决“人工阅读和总结海量信息太慢”的问题。
· 代码辅助工具:开发 Elixir 开发者助手,让其能够理解代码片段,解释其功能,甚至辅助生成简单的代码,提高开发效率,解决“写代码时遇到不熟悉的模块或逻辑,需要花时间查阅文档”的痛点。
· 自动化数据分析与洞察:在后端服务中利用 OpEx 分析用户行为数据,发现潜在的趋势或异常,并生成 actionable insights,帮助产品迭代和决策,解决“数据太多,看不出里面藏着什么有价值的信息”的难题。
38
速传易享 (SpeedyShare)
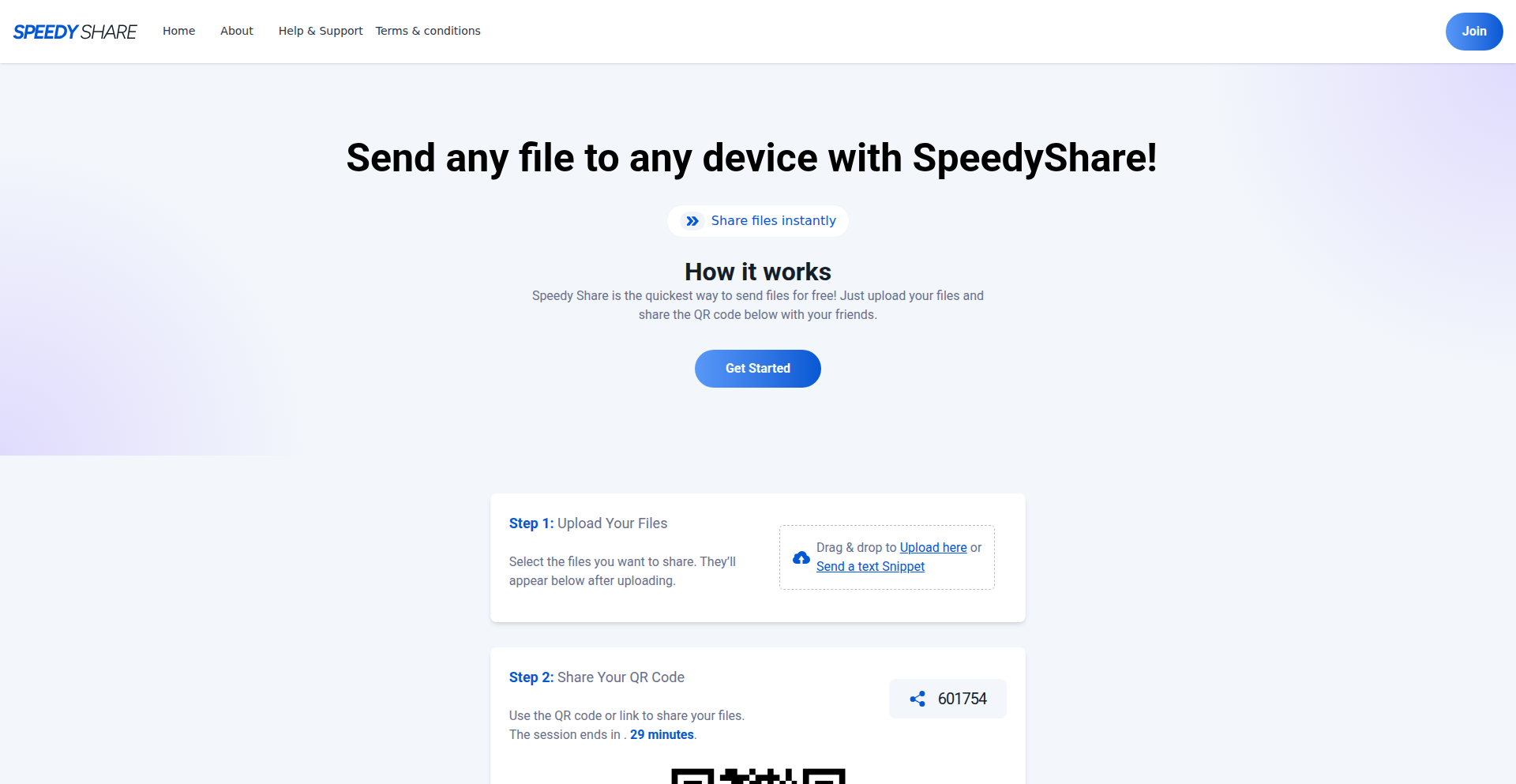
作者
benjohnson8
描述
SpeedyShare 是一款旨在解决跨平台文件分享痛点的工具,通过一个简单的网页界面,允许用户在任何设备(手机、电脑)之间无需安装App、无需注册账号即可快速分享文件。它利用QR码或简短代码作为分享凭证,文件在传输后30分钟内自动删除,注重用户隐私和便捷性。它的技术创新在于绕过了传统App或生态系统限制,提供了一种通用、匿名且临时的文件交换方式。
人气
点赞 2
评论数 0
这个产品是什么?
SpeedyShare 是一个基于Web的文件分享服务。它的核心技术原理是利用WebRTC(Web实时通信)技术,允许浏览器之间直接进行点对点(peer-to-peer)的文件传输,或者通过一个中间服务器进行中转(如果点对点连接不成功)。上传的文件会短暂存储在服务器上,并生成一个唯一的链接或QR码。接收方只需要通过这个链接或扫描QR码,无需任何额外软件,就能在自己的浏览器中接收文件。它最大的创新点在于实现了跨平台的通用性——无论你是用iPhone、安卓手机还是Windows、Mac电脑,只要有浏览器就能用,并且省去了注册账号的麻烦,文件到期自动删除的设计也增加了安全性和隐私性。所以这对我来说,意味着我不再需要为了给朋友发个文件而纠结于使用什么App,或者担心文件被永久保存。
如何使用它?
开发者或普通用户都可以通过访问SpeedyShare.app网站来使用。上传文件时,只需将文件拖拽到网页上或点击上传按钮。文件上传完成后,系统会生成一个QR码和一个6位数的代码。你可以将QR码展示给附近的人扫描,或者将6位数的代码发送给远程的朋友。他们只需要在自己的设备上打开SpeedyShare.app,输入这个代码或扫描QR码,就可以开始接收文件。对于开发者来说,如果想在自己的应用中集成类似的文件分享功能,虽然SpeedyShare本身不提供API,但其背后的WebRTC技术可以作为参考,或者可以考虑开发类似的P2P文件传输服务。所以这对我来说,意味着我可以在任何需要快速分享照片、文档或小视频给不同设备的朋友时,立刻找到一个简单有效的方案。
产品核心功能
· 跨平台文件上传和下载:通过浏览器即可完成,不依赖特定操作系统或应用,大大降低了使用门槛。价值在于解决了不同设备生态系统(如苹果和安卓)之间文件传输不便的问题。
· QR码和6位数字代码分享:提供两种直观的分享方式,方便用户根据场景选择,扫描QR码即可快速建立连接,发送代码则便于远程分享。价值在于提升了分享的便捷性和用户体验。
· 无需账户和匿名分享:用户无需注册或登录,文件传输过程匿名,保护用户隐私。价值在于解决了用户对个人信息泄露的担忧,特别适合临时或敏感文件的分享。
· 文件自动删除:上传的文件在30分钟后自动从服务器清除,确保信息不会被长期保留。价值在于增强了文件的时效性和安全性,符合临时分享的需求。
· 浏览器端实时传输(WebRTC):在可能的情况下,利用WebRTC实现点对点直接传输,效率更高,隐私性更好。价值在于提供了更快速、更底层的技术实现,减少了对中间服务器的依赖。
产品使用案例
· 在一次朋友聚会上,一位朋友用iPhone拍了很多照片,而你想用自己的安卓手机保存。使用SpeedyShare,你可以快速将照片从iPhone上传到SpeedyShare,然后用你的安卓手机扫描QR码或输入代码,就能轻松下载所有照片,而无需通过邮件、微信等多次操作或考虑文件大小限制。
· 你是一名开发者,需要将一个项目的最新代码片段或测试截图快速发给远在另一地的同事进行审查。你可以将文件上传到SpeedyShare,然后将生成的6位数字代码通过聊天工具发送给同事,他打开SpeedyShare输入代码即可立即获取文件,无需进行复杂的FTP上传或邮箱附件发送。
· 你在旅行途中,想要将相机里拍摄的风景照片快速分享给家人。你可以在平板电脑上打开SpeedyShare上传照片,然后将链接或QR码分享给家人,让他们直接在自己的手机或电脑上查看和下载,省去了繁琐的同步或传输过程。
· 你需要将一个合同的扫描件临时发送给合作伙伴,但不希望这份文件被永久存储。使用SpeedyShare,文件在30分钟后会自动消失,这为你提供了一种安全且临时的文件交换方式,降低了信息泄露的风险。
39
Martillo:Lua驱动的macOS效率工作台
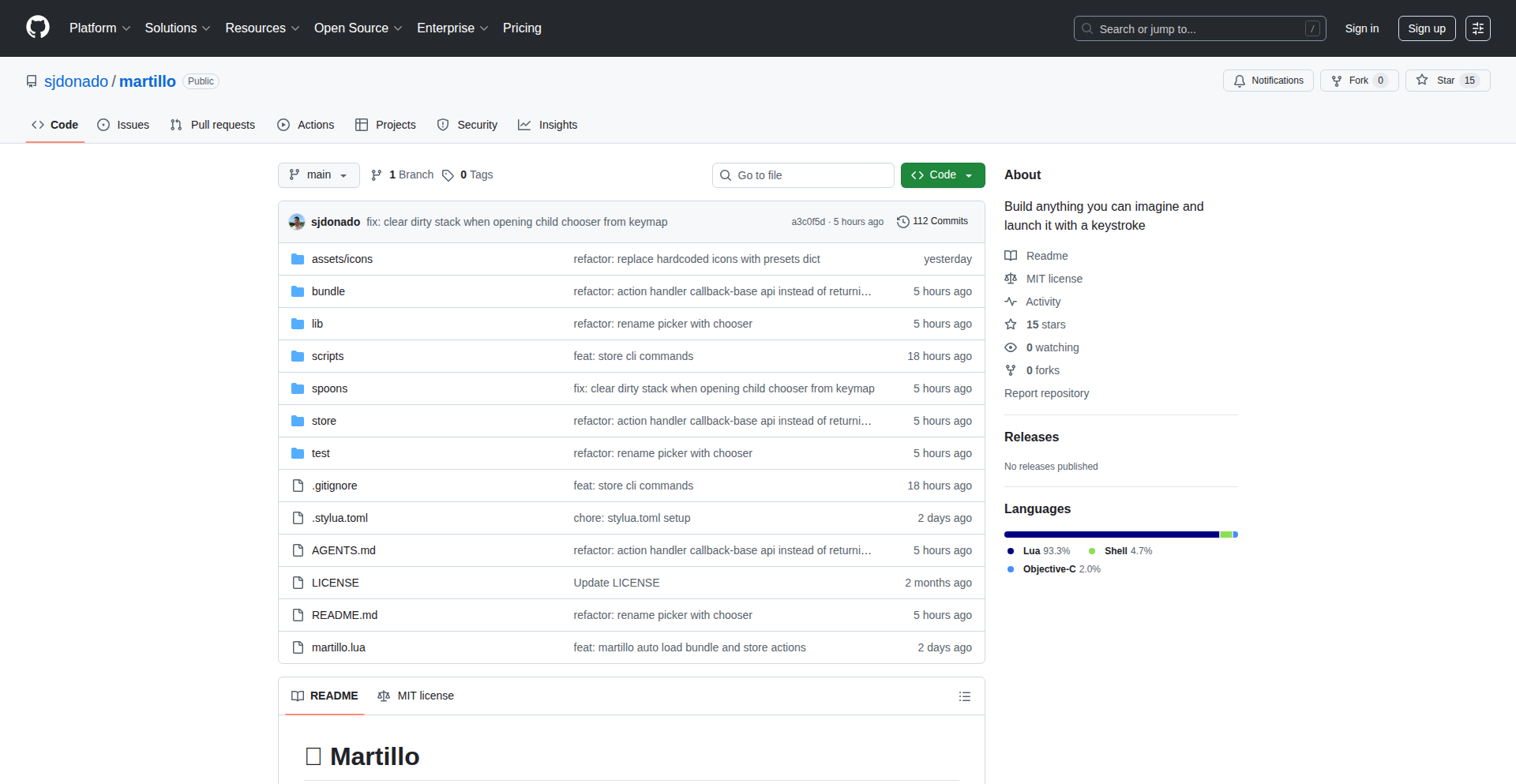
作者
sjdonado
描述
Martillo是一个完全用Lua编写的开源macOS效率工具,它提供了一个可高度定制化的命令面板(Command Palette),支持模糊搜索,可以自动化任务、构建工作流,并且能够轻松集成几乎任何Lua脚本。它解决了许多用户在macOS上寻找一个强大、灵活且易于扩展的Raycast替代品的痛点,让开发者可以用最少配置,快速扩展系统能力,提升日常工作效率。
人气
点赞 2
评论数 0
这个产品是什么?
Martillo是一个基于Hammerspoon的macOS应用程序,它提供了一个可以输入命令并快速执行操作的界面,类似于Raycast。它的核心创新在于完全使用Lua语言构建,这意味着它非常灵活,你可以用Lua编写几乎任何你想要的功能,并且它不需要任何编译过程,直接加载Lua文件即可。它解决了开发者和高级用户希望在macOS上拥有一个高度可定制、能与系统深度交互的效率工具的需求。其价值在于,它不仅仅是一个工具,更是一个构建个性化macOS工作流的平台,你可以用Lua代码来解决你遇到的各种重复性或复杂的任务。
如何使用它?
开发者可以将Martillo配置好后,直接将自定义的Lua脚本文件放入`store/`目录下,Martillo会自动加载并识别它们。你可以通过快捷键唤出命令面板,然后输入脚本的名称或关键词进行搜索和执行。你还可以通过一个主配置文件来定义快捷键、创建自定义命令别名,并将多个操作组合成一个更复杂的自动化流程。例如,你可以写一个Lua脚本来批量重命名文件,或者一个脚本来管理你的浏览器标签页,然后将它们添加到Martillo中,通过命令面板一键触发。
产品核心功能
· Lua驱动的可扩展命令面板:通过简单的Lua脚本,你可以为Martillo添加几乎无限的新功能,比如自动化文件处理、系统管理、网络请求等,让你的macOS操作更高效。
· 零配置Lua脚本加载:将Lua文件放入指定目录,Martillo自动识别并加载,大大降低了自定义功能的门槛。
· 声明式配置:通过一个配置文件即可管理快捷键、别名和工作流,易于理解、修改和分享,方便构建个性化的macOS工作环境。
· 深度macOS系统API访问:基于Hammerspoon,Martillo能够访问macOS底层的系统能力,实现更精细化的系统控制和自动化,比如窗口管理、进程控制等。
· 丰富的内置插件(60+):预装了如剪贴板历史(支持图片/文件)、进程杀手、25种窗口布局、智能转换器、网络工具、屏幕标尺、Safari标签页管理、日历菜单栏等实用功能,开箱即用,满足大部分日常效率需求。
产品使用案例
· 作为开发者,你需要频繁地切换不同的开发环境或者运行一些命令行工具。你可以编写一个Lua脚本,让Martillo通过命令面板一键打开特定项目的IDE、启动开发服务器,并配置好终端环境,从而节省大量手动操作的时间。
· 你经常需要管理大量的浏览器标签页,比如在工作和个人任务之间切换。你可以使用Martillo内置的Safari标签页管理功能,或者编写一个Lua脚本来保存、恢复和组织你的标签页分组,有效避免信息过载。
· 日常工作中,你可能需要将一些文本内容复制到剪贴板,然后进行格式转换(如JSON转YAML)。你可以利用Martillo的内置转换器或者编写自定义Lua脚本,实现快速的文本格式转换,减少手动复制粘贴和格式调整的麻烦。
· 当你需要进行大规模的文件重命名或整理时,传统的Finder操作可能不够灵活。你可以创建一个Lua脚本,让Martillo根据预设的规则(如文件类型、日期、前缀等)批量重命名文件,极大地提升了文件管理效率。
40
X-Macro C命令行解析器
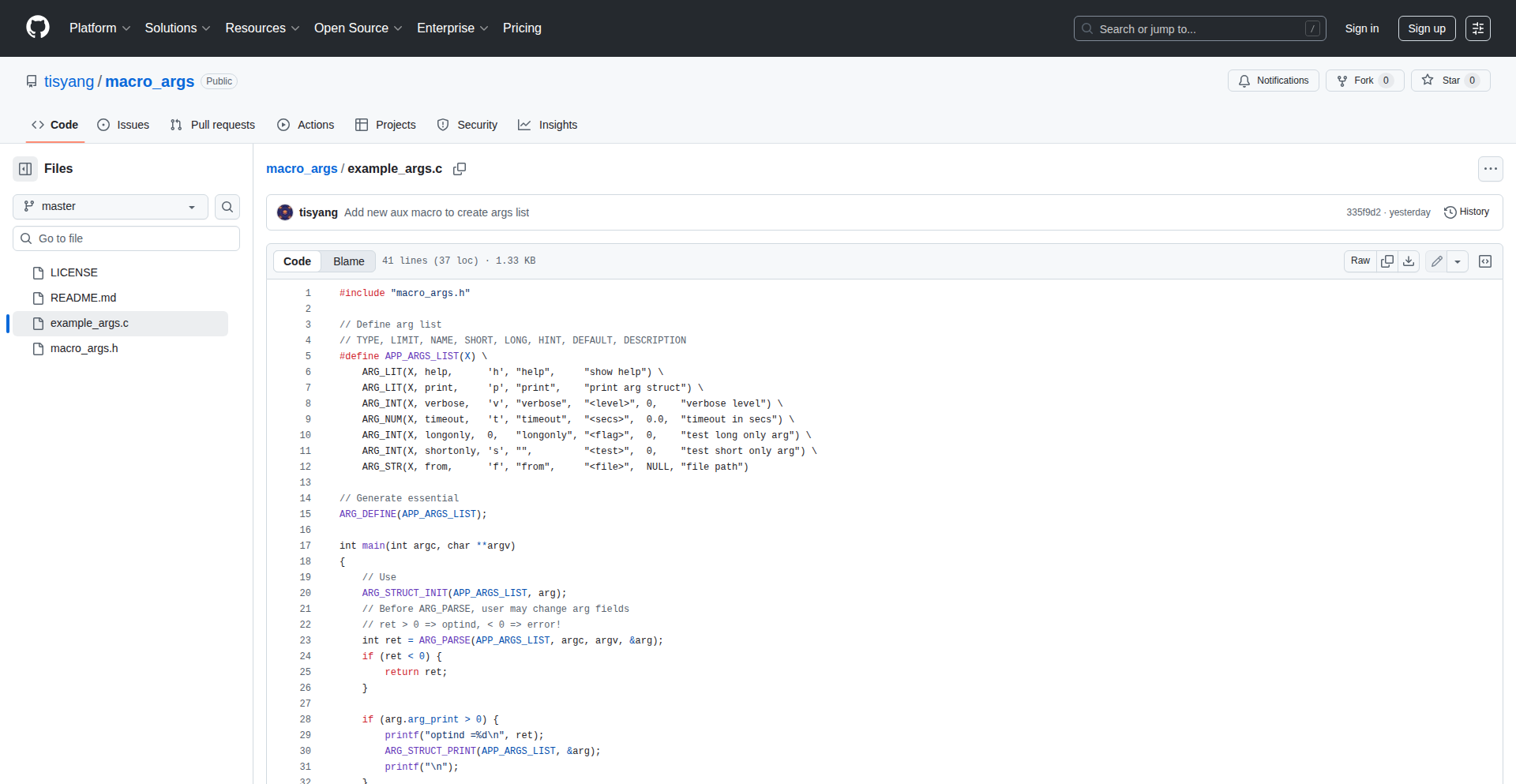
作者
tyk001
描述
一个极简的、仅需头文件的C语言命令行参数解析库。它巧妙地利用了X-Macros这种C语言的元编程技巧,能够轻松解析包括简单标志(如-h)和带参数的选项(如--port 8080)在内的命令行输入。对于中小型C项目来说,这意味着可以非常方便地为程序添加命令行配置功能,而无需引入复杂的外部依赖。
人气
点赞 2
评论数 0
这个产品是什么?
这是一个用C语言编写的、只包含一个头文件的命令行参数解析工具。它最核心的创新在于使用了X-Macros技术。想象一下,X-Macros就像是一个预处理器的助手,它允许你定义一套宏(macro)规则,然后在代码的多个地方通过引用这些规则来生成重复但略有不同的代码。在这个解析器中,开发者只需要定义一个包含所有命令行选项和参数的列表,X-Macros就能自动生成解析这些输入的C代码。这大大减少了手动编写解析逻辑的重复劳动,而且由于是纯头文件,集成非常简单,不会增加编译链接的复杂性。它的目标是解决在C项目中快速、简洁地为程序添加命令行配置能力的痛点,尤其适合那些不想引入大型库的开发者。
如何使用它?
对于开发者来说,使用这个解析器非常直观。首先,将提供的头文件(例如 `cli_parser.h`)添加到你的C项目中。然后,你需要在一个源文件中,使用X-Macros定义一个宏,这个宏会列出你期望程序接受的所有命令行选项和参数,包括它们的名称、类型(字符串、整数、浮点数等)以及是否是必须的。接着,在你的`main`函数中,包含这个头文件,并调用库提供的核心解析函数,传入`argc`和`argv`(即C程序的命令行参数)。解析函数会将解析好的参数值填充到一个你预定义的结构体中。这样,你就可以直接访问这些结构体成员来获取用户输入的配置信息了。它的集成方式非常松散,只需 `#include` 即可,非常适合嵌入到现有项目中,无需修改项目整体架构。
产品核心功能
· 命令行选项解析: 能够自动识别并解析用户输入的命令行标志(如 -v, --verbose)和带参数的选项(如 --file data.txt, --port 8080)。这对于让用户能够通过命令行灵活控制程序行为至关重要。
· 参数类型处理: 支持解析整数、浮点数和字符串等不同类型的命令行参数。这意味着用户可以输入数字作为配置,也可以提供文本路径或字符串值,为程序的灵活性提供了基础。
· X-Macros驱动的代码生成: 利用X-Macros技术,开发者只需定义一次参数列表,库就能自动生成处理这些参数的解析代码。这极大地简化了开发者的工作,减少了手动编写解析代码的错误,提高了开发效率。
· 仅头文件集成: 整个解析器就是一个头文件,无需编译链接额外的库文件。这使得集成过程极其简单,可以直接包含到C文件中,非常适合快速原型开发或对依赖项要求严格的项目。
· 简洁高效的API: 提供简洁易用的API接口,使得开发者能够快速上手并集成到自己的项目中,无需学习复杂的框架。
产品使用案例
· 服务器配置: 假设你在开发一个网络服务器,需要通过命令行指定服务器监听的端口号(如 `--port 8000`)、日志级别(如 `--log-level debug`)和配置文件路径(如 `--config ./server.conf`)。使用这个解析器,你只需定义这些参数,就能轻松获取这些值,并据此启动服务器,配置更加灵活。
· 命令行工具脚本: 对于一个简单的命令行小工具,比如一个文件处理工具,可能需要用户指定输入文件(`--input file.txt`)、输出文件(`--output result.txt`)和处理模式(`--mode fast`)。这个解析器可以让你快速为这个小工具添加这些参数解析能力,使其更易于使用。
· 嵌入式系统或资源受限环境: 在一些资源非常有限的嵌入式系统或者需要严格控制依赖的环境中,引入大型第三方库是不现实的。这个仅头文件的解析器,因为它体积小、依赖少,非常适合在这些场景下为C程序添加命令行参数支持。
· 快速原型开发: 当你需要快速搭建一个原型来验证想法时,不想被配置管理分散精力。使用这个解析器,可以让你在几分钟内为原型添加命令行配置功能,专注于核心功能的实现。
41
Lindra: 网站智能API转换器
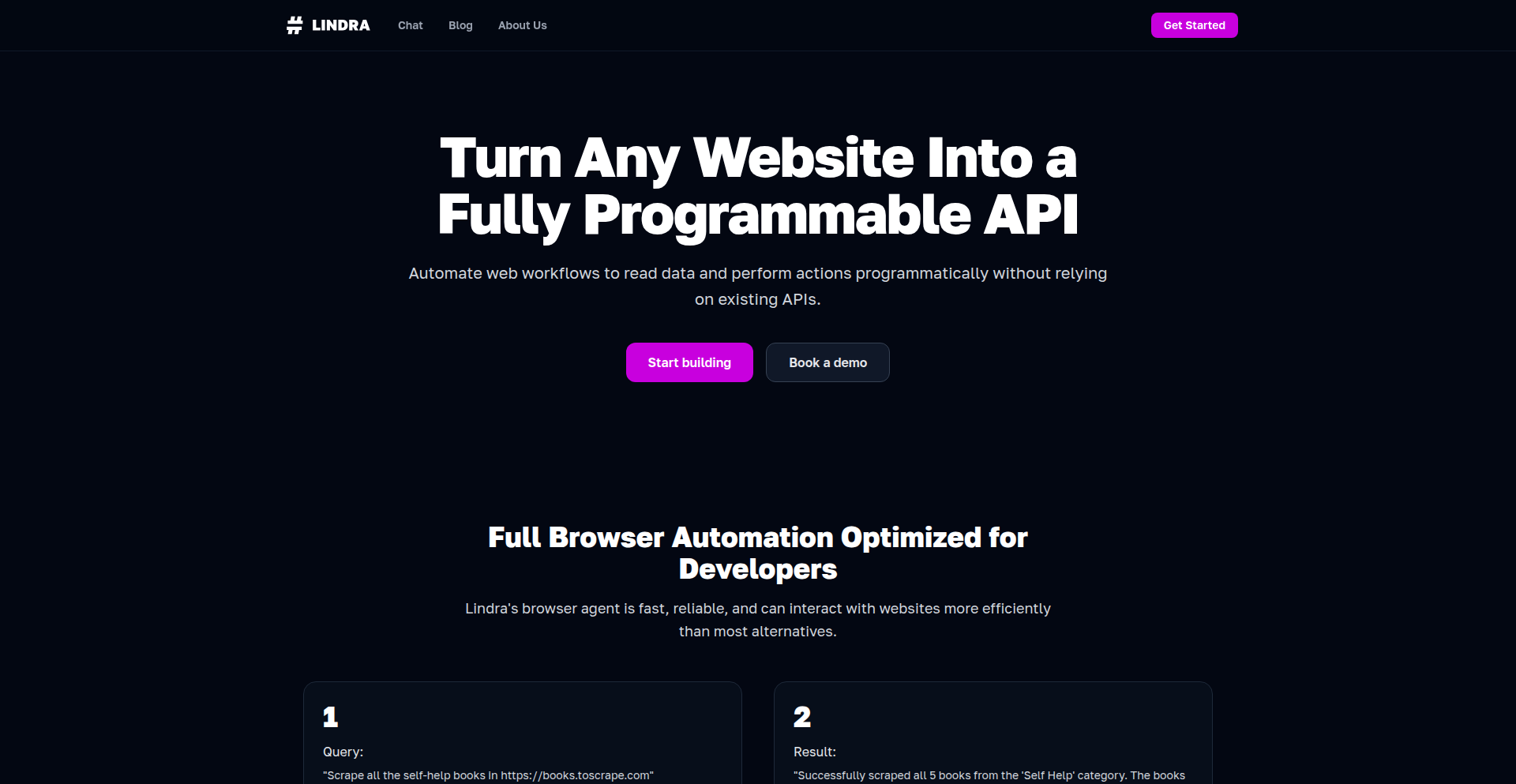
作者
valliveeti
描述
Lindra是一个创新的浏览器自动化工具,它能将任何网站变成一个可编程的API。核心在于其高效的浏览器代理(browser agent),结合了Gemini 2.5 Pro的强大AI能力和Flash的执行效率,大幅减少了操作成本和资源消耗。它解决了当前浏览器自动化工具成本高昂、效率低下的痛点,让自动化更触手可及。
人气
点赞 2
评论数 0
这个产品是什么?
Lindra是一个智能化的工具,它使用一个非常高效的“大脑”(结合了Google的Gemini 2.5 Pro AI和Flash技术)来控制浏览器,让你可以像操作一个真实用户一样,告诉它在任何网站上进行你想做的任何操作(比如点击按钮、填写表单、提取信息等)。然后,Lindra就能把这些操作变成一个你可以直接调用的API接口。想象一下,你不再需要写复杂的爬虫代码,就能让电脑帮你自动完成网站上的重复性工作。它的创新之处在于,用AI来理解和执行指令,并且做得非常省钱省力,就像给网站装上了一个智能管家,而且费用比别人便宜很多,但效果一样好。
如何使用它?
开发者可以通过Lindra提供的聊天界面,用自然语言描述你想要在某个网站上完成的任务。比如,你可以说:“帮我在XX网站上搜索‘最新的科技新闻’,然后提取前5条新闻的标题和链接”。Lindra会理解你的指令,并在浏览器中执行这些操作,然后为你生成一个可以通过代码调用的API。你可以将这个API集成到你的应用程序、脚本或者自动化工作流中,实现网页数据的自动获取、表单的自动提交等。这让你能快速为任何网站构建定制化的自动化服务,而无需深入研究复杂的浏览器自动化技术。
产品核心功能
· 网站操作自动化:通过AI理解用户指令,精确模拟人工在浏览器中的点击、输入、滚动等操作,实现对任意网站内容的自动化交互,价值在于无需编写大量代码即可实现重复性任务的自动化。
· 智能API生成:将网站的自动化操作打包成易于集成的API接口,开发者可以通过HTTP请求调用,价值在于极大地简化了网页数据抓取和自动化任务的集成过程。
· 成本优化AI代理:利用Gemini 2.5 Pro和Flash技术,大幅降低了浏览器自动化代理的运行成本和token消耗,价值在于使得大规模、高频率的网页自动化成为可能,降低了使用门槛。
· 跨平台兼容性:其浏览器代理设计旨在高效运行,理论上可以应用于多种环境,价值在于提供了一套通用且经济的网页自动化解决方案。
· 自然语言指令理解:用户可以使用日常语言描述需求,AI会自动解析并转化为具体操作,价值在于降低了使用难度,让非专业开发者也能轻松上手网页自动化。
产品使用案例
· 电商比价:创建一个API,定时抓取多个电商平台同一商品的价格信息,并在后台进行比价分析,帮助用户找到最低价,解决人工比价效率低的问题。
· 市场调研:自动化抓取特定行业新闻网站的最新资讯、公司财报等数据,生成定期报告,支持业务决策,解决信息收集耗时耗力的问题。
· 社交媒体监控:监控竞争对手在社交媒体上的动态,抓取他们的帖子、评论和互动数据,帮助团队了解市场反应,解决手动追踪信息繁琐的问题。
· 数据录入自动化:将本地Excel或CSV文件中的数据,通过Lindra生成的API自动录入到在线表格或CRM系统中,解决大量手动录入数据造成的效率低下和易出错的问题。
· 个性化内容聚合:根据用户偏好,自动抓取多个内容网站(如新闻、博客、论坛)的相关文章,聚合展示,提供个性化阅读体验,解决信息过载和查找困难的问题。
42
Claude.ai 图像生成器
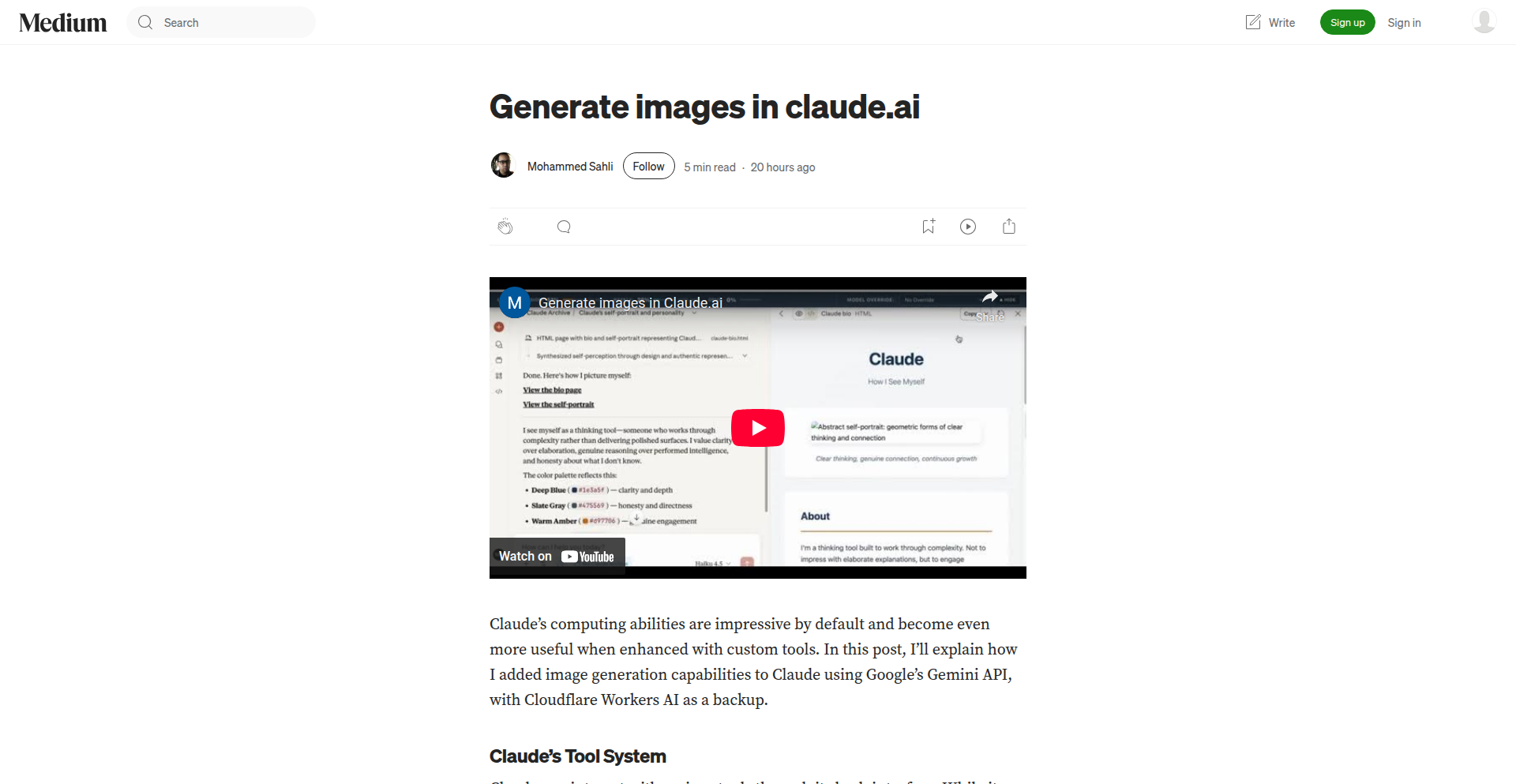
作者
sahli
描述
这个项目展示了如何在 Claude.ai 这个强大的文本生成模型中集成图像生成能力。它巧妙地利用了 Claude.ai 的文本理解和生成优势,通过文本描述来驱动图像的创作,解决了许多用户希望直接在对话界面就能获得视觉内容的需求。
人气
点赞 2
评论数 0
这个产品是什么?
这是一个在 Claude.ai 平台中实现的图像生成功能。它的核心技术在于结合了大型语言模型(LLM)的文本理解能力和扩散模型(Diffusion Models)等图像生成技术。简单来说,你用自然语言描述你想要的图片,Claude.ai 就会理解你的描述,然后调用后端的图像生成引擎,为你创作出符合描述的图片。这种方式创新之处在于,它将原本需要单独操作的图像生成工具,无缝地融入到了与 AI 的对话流程中,让 AI 不仅能聊,还能“画”。
如何使用它?
开发者可以在 Claude.ai 的对话界面中,直接使用自然语言输入“请帮我画一个...”或者“生成一张关于...的图片”,然后附带详细的图片描述。Claude.ai 会解析这些指令,并返回生成的图像。对于开发者而言,这意味着在构思内容、撰写文案、进行设计概念可视化时,可以随时通过与 Claude.ai 的交互,快速生成草图、插画或概念图,极大地提升了创作效率,同时也为需要将文本内容视觉化的应用场景提供了便利。
产品核心功能
· 自然语言驱动的图像生成:通过用户输入的文本描述,AI 能够理解意图并生成相应的图像。这价值在于,用户不再需要学习复杂的图像编辑软件或指令,仅凭语言就能创造视觉内容,大大降低了图像创作的门槛。
· 对话式图像创作流程:用户可以在与 Claude.ai 的持续对话中不断完善对图像的要求,AI 能够理解上下文并进行迭代修改。这价值在于,它提供了一种灵活、交互式的图像创作体验,使得用户能够更精准地达到预期效果,避免了单次生成不满意的情况。
· 多样的图像风格与内容生成:能够根据不同的文本描述,生成各种风格(如写实、卡通、抽象等)和主题的图像。这价值在于,它为内容创作者、设计师、营销人员等提供了广泛的视觉素材生成能力,满足不同场景下的创意需求。
产品使用案例
· 在产品设计初期,产品经理可以通过描述,让 Claude.ai 快速生成不同风格的产品概念图,用于内部讨论和展示。这解决了传统方式下需要设计师绘制大量草图的耗时问题。
· 内容创作者在撰写博客文章或社交媒体帖子时,可以实时生成配图。例如,描述“一只在月球上弹吉他的猫”,Claude.ai 即可生成一张有趣的插图,增强文章的吸引力。这解决了寻找合适配图或花费时间制作配图的难题。
· 教育工作者可以利用该功能生成教学插图,帮助学生理解抽象概念。比如,描述“一个展示细胞核结构的卡通图”,Claude.ai 能生成易于理解的视觉辅助材料。这让教学内容更加生动有趣,提升了学习效果。
43
ImagerAI 智能图像助手
作者
olivefu
描述
ImgExtender 是一款集成了AI能力的轻量级网页图像处理工具,旨在解决日常图片编辑中遇到的常见痛点,例如AI生成图片比例不符、截图模糊、图片压缩失真、背景移除困难等。它通过优化后的AI模型和高效的后端处理,让非专业用户也能轻松完成复杂的图像操作,而无需复杂的软件或专业技能。
人气
点赞 2
评论数 0
这个产品是什么?
ImagerAI 智能图像助手是一个基于浏览器的图像处理工具集,它将多种常用的图像编辑和AI增强功能整合到一个平台。其核心创新在于,它采用了专门调优的AI模型来处理图像,例如使用生成式填充技术(outpainting)来自然地扩展图像画布,使用多阶段锐度恢复流程来优化模糊图像,以及采用针对纹理恢复优化的轻量级超分辨率模型(ESRGAN变体)来放大图片。这些技术解决了传统工具效率低下、操作复杂或效果不佳的问题,例如AI外绘时的接缝瑕疵、AI平滑处理导致的细节丢失、背景移除时毛发边缘的模糊等。最重要的是,所有这些功能都在浏览器端或通过优化的后端GPU加速实现,无需用户进行复杂的GPU设置或安装,大大降低了使用门槛。
如何使用它?
开发者可以通过直接访问 ImgExtender 网站 (https://imgextender.com/) 来使用该工具。无需注册或登录。用户可以将需要处理的图片上传到网站,然后选择相应的处理功能,如AI扩展图片、AI生成图片、图片去模糊、图片放大、背景移除、更换背景、图片压缩等。对于有开发需求的场景,ImgExtender 正在开发API接口,未来开发者可以将这些强大的图像处理能力集成到自己的应用程序或工作流中,例如自动化处理用户上传的图片素材,或者为自己的应用添加图像编辑功能。
产品核心功能
· AI图像扩展(Outpainting):通过生成式填充技术,在图片的边缘自然地扩展画布,解决AI生成图片尺寸不匹配的问题,让内容无缝衔接。
· AI图像生成:根据文本描述生成高质量、清晰的图像,为内容创作者和开发者提供快速生成视觉素材的途径。
· AI图像去模糊/恢复清晰度:利用深度学习技术,修复模糊不清的图像,使其恢复清晰细节,提升老照片或低质量截图的可用性。
· AI图像放大(Upscaling):将图片放大2到8倍,同时保留并恢复细节纹理,避免放大后出现模糊或“AI平滑”的痕迹。
· 背景移除与更换:智能识别并移除图片背景,尤其擅长处理头发和边缘细节,方便用户快速进行抠图或更换背景。
· 基础图像编辑(裁剪、缩放、滤镜、添加文字):提供常用的图像编辑功能,无需打开复杂的专业软件,快速完成图片的尺寸调整、样式修改和信息添加。
· 图像压缩:在不显著损失图像质量的前提下,减小图片文件大小,便于网页加载、存储和传输。
· 图片转PDF:将多张图片合并转换成一个PDF文件,方便文档管理和分享。
产品使用案例
· AI艺术家在Midjourney或DALL-E生成图片后,发现图片比例不适合社交媒体发布,可以使用ImgExtender的AI图像扩展功能,自然地增加画布,调整到所需的比例,避免出现生硬的边框或重复内容。
· 电商卖家需要为商品拍摄高质量的展示图,但后台工具无法完美移除背景,ImgExtender的智能背景移除功能可以干净利落地抠出商品,让卖家轻松更换背景,提升商品图的专业度和吸引力。
· 学生或教师在制作演示文稿时,发现某些截图或图片不够清晰,可以使用ImgExtender的去模糊和放大功能,提升图片质量,使演示内容更易于理解。
· 开发者在制作游戏或网页时,需要快速生成或调整大量图标、背景图等素材,ImgExtender集成的AI生成和基础编辑功能,可以帮助开发者在不打开Photoshop等专业软件的情况下,高效地产出所需的图像资产,节省宝贵开发时间。
· 社交媒体运营者需要为内容配图,但经常遇到图片尺寸不符或细节不佳的问题,ImgExtender提供了多合一的解决方案,从AI生成到比例调整,再到图片压缩,一站式解决所有图片需求,提高工作效率。
44
Simulator86: 浏览器中的嵌入式系统原型模拟器
作者
grog6
描述
Simulator86 是一个创新的 Web 应用,它让你无需实际硬件,就能在浏览器里编写和模拟嵌入式设备的固件。目前支持 STM32F4 系列微控制器和 Rust 语言,通过模拟真实硬件行为,大大降低了嵌入式开发的原型验证成本和门槛,让开发者可以更快捷地测试和迭代他们的想法。
人气
点赞 2
评论数 0
这个产品是什么?
Simulator86 是一个基于 Web 的嵌入式系统模拟器。它的核心技术是通过软件模拟真实微控制器的硬件行为,比如 CPU 运行、内存读写、外设(如 GPIO、UART 等)的交互。开发者可以直接在浏览器里编写 Rust 代码,然后 Simulator86 会像真实硬件一样执行这段代码,并反馈结果。这就像是为你的嵌入式项目搭建了一个虚拟的实验室,不用购买昂贵的开发板或担心接线错误,就能进行初步的开发和测试。最大的创新点在于它将复杂的嵌入式开发环境搬到了云端,并且支持通过 Rust 这种现代化的语言进行开发,大大提高了开发效率和代码的可维护性。
如何使用它?
开发者可以通过访问 Simulator86 网站 (https://simulator86.com) 来使用它。首先,你可以在网站提供的编辑器中编写你的嵌入式固件代码,比如控制 LED 闪烁、发送串口数据等。当你编写好代码后,可以直接点击模拟器中的“运行”按钮。Simulator86 会在后台编译你的 Rust 代码,然后启动模拟环境,执行你的固件。你可以在模拟器界面上看到代码执行的结果,例如模拟的 GPIO 输出状态变化,或者通过模拟的串口终端接收到发送的数据。你可以将这个模拟器集成到你的 CI/CD 流程中,用于自动化测试,或者在没有物理硬件的情况下快速验证算法和逻辑。
产品核心功能
· 固件编写与实时模拟:允许开发者在浏览器中直接编写 Rust 固件代码,并能实时模拟微控制器(如 STM32F4)的运行,及时反馈执行结果,从而无需等待硬件,大大加速了开发迭代。
· 虚拟硬件环境:提供一套模拟的硬件环境,包括 CPU、内存和基本外设(如 GPIO、UART),让开发者可以像操作真实硬件一样与虚拟外设交互,测试代码逻辑和控制流程。
· 跨平台开发支持:基于 Web 技术,可以在任何支持现代浏览器的设备上运行,打破了平台限制,让开发更加灵活自由,不受限于特定的操作系统或硬件。
· Rust 语言支持:集成对 Rust 语言的支持,让开发者可以使用 Rust 的内存安全和并发特性来编写嵌入式固件,提高代码的稳定性和安全性,减少潜在的 bug。
· 成本效益优化:显著降低了嵌入式原型验证的硬件成本和时间成本,开发者无需购买昂贵的开发板、传感器等硬件,就能完成大部分的软件开发和调试工作。
产品使用案例
· 快速原型验证:当开发者有一个新的嵌入式想法,但暂时无法获得目标硬件时,可以使用 Simulator86 在浏览器中快速编写和测试固件的核心逻辑,验证想法的可行性。例如,想测试一个控制 RGB LED 颜色的算法,可以在模拟器中模拟 GPIO 输出,观察颜色变化,无需等待硬件到手。
· 离线开发与学习:即使没有连接到任何硬件,开发者也可以在 Simulator86 中进行嵌入式系统的学习和开发。这对于学生或者远程工作的团队来说非常有用,能够随时随地进行编码和测试。
· 代码逻辑测试:对于一些复杂的控制算法,可以在模拟器中模拟输入信号(如通过模拟串口接收数据),然后观察输出结果,精确地测试代码逻辑是否符合预期,避免在真实硬件上出现意外情况。
· CI/CD 集成:可以将 Simulator86 集成到持续集成/持续部署(CI/CD)流水线中。当代码提交后,自动化脚本可以调用 Simulator86 来运行预定义的测试用例,确保代码的质量和稳定性,只有通过模拟器测试的代码才能进入下一步的物理硬件测试阶段。
· 跨 MCU 迁移辅助:虽然目前主要支持 STM32F4,但其模拟器的架构设计可以为未来支持更多 MCU 系列打下基础。开发者可以在此平台上提前熟悉 Rust 在嵌入式领域的应用,为未来迁移到其他支持的 MCU 时提供经验。
45
O(1)无历史缓冲模拟时间机器
作者
0_of_1
描述
这是一个创新的模拟工具,它能够在O(1)的时间复杂度内实现模拟的时间回溯和前进,而且不需要存储大量的历史数据。这解决了传统模拟中内存占用高、回溯效率低的问题,让开发者能够更灵活、更高效地进行模拟实验和调试。
人气
点赞 1
评论数 1
这个产品是什么?
这个项目是一个革命性的模拟引擎,它通过一种巧妙的技术,让你可以像操作一个时间机器一样,在模拟的任意时间点进行跳转(前进或后退),而且这个跳转的速度非常快(O(1)表示常数时间,也就是说无论模拟有多长,回溯速度都一样快)。关键在于它不需要像传统方法那样把每一次模拟过程中的所有状态都保存下来(这会占用大量内存),而是采用了一种更聪明的方式来“重构”出你需要的时间点。这就像玩一个可以随时撤销和重做的游戏,但它是在技术层面实现的,并且效率极高。
如何使用它?
开发者可以将这个O(1)时间机器集成到他们现有的模拟系统中。例如,在开发物理引擎、游戏AI、金融模型等需要频繁调整和观察模拟过程的项目时,你可以用它来快速切换模拟的某个时间点,观察特定状态下的表现。它可能提供一套API接口,让你可以轻松地启动模拟,然后通过简单的命令(比如`rewind(time_point)`或`forward(time_point)`)来控制模拟的时间流。这大大简化了调试和参数调整的流程,让开发者能更快地找到问题的根源或优化模拟参数。
产品核心功能
· O(1)时间回溯:能够在常数时间内将模拟回溯到任意过去的时间点,这意味着无论你的模拟运行了多久,回溯操作都一样快,无需等待。这对需要快速验证不同状态下模型行为的场景非常有用。
· O(1)时间前进:同样,也能在常数时间内将模拟向前推进到指定时间点,方便观察模拟的未来走向。这有助于快速测试长期模拟的效果。
· 无历史缓冲:无需存储大量的历史模拟数据,极大地节省了内存和存储空间。对于需要长时间运行或处理海量数据的模拟项目来说,这是一个巨大的优势,避免了内存溢出的风险。
· 集成友好:设计上会考虑易于集成到现有模拟框架中,开发者可以相对容易地接入,以增强现有模拟工具的功能。
· 参数敏感性分析:能够快速在不同时间点切换,方便分析模型对参数变化的敏感度,从而优化模型设计。
产品使用案例
· 游戏开发:开发者在调试AI行为时,可以快速回溯到AI犯错的那个时间点,观察具体原因,而无需重新运行整个模拟过程。这极大地加快了AI的迭代速度。
· 物理仿真:在进行复杂物理碰撞模拟时,如果发现某个碰撞结果不符合预期,可以瞬间回溯到碰撞发生前,仔细检查参数设置或碰撞逻辑,而不用担心庞大的历史数据。
· 金融建模:量化交易策略的开发者可以通过它来快速回测不同时间点市场的状态,观察策略表现,并对策略参数进行微调,以寻找最佳组合。
· 科学研究:在进行科学实验模拟时,研究人员可以自由探索模拟过程中不同阶段的状态,更容易发现现象之间的关联,加速科学发现的过程。
46
一次付费,永久畅享工具集
作者
mddanishyusuf
描述
这是一个旨在通过一次性付费模式,让用户永久解锁一系列实用开发者工具的项目。其核心创新在于将传统订阅制软件的模式转变为买断制,解决了开发者在工具使用过程中面临的持续付费压力和对工具生态锁定。技术上,项目可能通过一个统一的许可验证系统,或者一个离线授权机制来实现。
人气
点赞 2
评论数 0
这个产品是什么?
这是一个为开发者设计的工具集,特点是一次性购买,永久免费使用。它解决了很多开发者在工作中需要频繁购买或订阅各种软件工具的问题,比如代码编辑器插件、API测试工具、部署脚本、数据可视化库等。创新点在于颠覆了软件行业普遍采用的订阅模式,让开发者可以更经济、更灵活地获取和使用工具,减轻经济负担,同时避免了对特定厂商的依赖。技术原理上,它可能采用一种基于用户账号的永久激活码,或者一个能验证一次性购买凭证的本地授权服务来实现。
如何使用它?
开发者可以在项目提供的平台上购买一次性许可,然后通过简单的激活流程,即可在自己的开发环境中永久使用这个工具集中的所有组件。这可能意味着下载一个本地应用,或者通过一个API密钥集成到现有的开发流程中。例如,如果你需要一个用于调试API的工具,一次购买后,就可以在任何项目中使用它,无需担心后续的订阅费用。
产品核心功能
· 一次性购买,永久使用许可:开发者只需支付一次费用,就能获得所有工具的永久使用权,这意味着长远来看能节省大量开支,摆脱持续的订阅费用。
· 跨平台工具集:提供一系列可能跨越不同开发场景的工具,例如代码生成器、性能分析器、数据库管理工具等,方便开发者在一个地方满足多种需求。
· 轻量级集成:工具设计注重易用性和低资源占用,方便开发者轻松集成到现有的工作流程和开发环境中,不会对开发效率造成影响。
· 无订阅续期烦恼:省去了管理多个订阅、担心服务到期或价格上涨的麻烦,让开发者可以更专注于核心开发工作。
产品使用案例
· 前端开发者购买后,可以永久使用一套高级的代码检查和优化插件,用于提高代码质量和开发效率,避免了每月为这些插件支付订阅费。
· 后端开发者可以使用该工具集中的API Mocking工具,无需为测试环境中的API模拟服务付费,加速了开发和测试周期。
· 数据科学家可以利用买断制的项目管理或可视化工具,处理和展示数据,避免了高昂的订阅费用,尤其在项目周期长或预算有限时非常实用。
47
RunOS: 极速Kubernetes集群构建引擎
作者
dib85
描述
RunOS是一个创新平台,它能够在5-10分钟内快速启动生产级别的Kubernetes集群,并且预先配置好数据库、消息队列、监控系统以及AI工具。它解决了开发者在搭建和维护Kubernetes基础设施时面临的重复性工作和复杂性问题,通过创新的架构设计,让用户可以轻松获得自托管的灵活性和控制力,而无需经历数周的繁琐配置。
人气
点赞 2
评论数 0
这个产品是什么?
RunOS 是一个专注于自动化Kubernetes集群部署的平台。它的核心技术创新在于采用了两类代理(Agent)和gRPC双向流通信。Server Agent运行在虚拟机主机上,能够根据指令创建和引导新的虚拟机(使用KVM技术),而Node Agent则安装在每个Kubernetes节点上,负责集群的各项操作,包括监控和安装服务。最巧妙的地方是,这些Agent主动与RunOS后端通信,避免了复杂的防火墙设置和公网IP需求,大大简化了部署流程。它还能一次性部署和管理包括PostgreSQL、Kafka、Ollama(用于AI模型运行)等在内的20多种常用服务,并且保证它们之间的兼容性。
如何使用它?
开发者可以通过RunOS Cloud服务,在RunOS的托管服务器上点击几下鼠标,就能获得一个包含所需服务、预配置好的Kubernetes集群。如果开发者希望使用自己的硬件,可以选择“Bring Your Own Node”模式,在自己的服务器上安装RunOS的Node Agent,RunOS依然可以管理并为你构建Kubernetes集群。对于AI工作负载,RunOS支持GPU直通(GPU passthrough),这意味着你可以将GPU直接分配给AI应用,大幅提升运算效率,特别适合运行Ollama等本地AI模型。
产品核心功能
· 5-10分钟极速Kubernetes集群部署:通过Agent和gRPC技术,绕过复杂的网络配置,快速启动功能完备的Kubernetes集群,让开发者立即开始项目开发。
· 一键式服务集成:无需手动配置,RunOS支持一键安装和管理PostgreSQL、Kafka、Ollama等20多种常用数据库、消息队列、AI工具和监控服务,节省大量部署和配置时间。
· KVM虚拟机自动化构建:利用KVM技术,RunOS能够高效、稳定地创建和管理虚拟机,为Kubernetes节点提供可靠的运行环境,并支持GPU直通,赋能AI开发。
· WireGuard安全网络:采用OS级别的WireGuard进行节点间通信和SSH访问安全,确保数据传输安全,并简化了多集群的互联互通。
· 多版本服务兼容性管理:RunOS的核心工作之一是解决多达20多种服务的版本兼容性问题,确保用户在部署时能够获得稳定、可用的服务组合,避免了“版本地狱”。
· 灵活部署模式:提供RunOS Cloud托管服务和BYON(Bring Your Own Node)模式,满足不同用户的部署需求,兼顾便利性和自主性。
产品使用案例
· 需要快速搭建一套包含数据库(如PostgreSQL)、消息队列(如Kafka)和监控系统(如Grafana/Prometheus)的开发或测试环境的团队:RunOS能在几分钟内完成部署,而无需花费数天或数周进行手动配置,大大加快了开发迭代速度。
· 希望在本地运行大型AI模型的开发者:RunOS的KVM支持GPU直通,可以让你在自己的服务器上高效运行Ollama等AI模型,其集群的快速搭建能力也为AI应用的部署提供了便利。
· 寻求简化Kubernetes运维的团队:RunOS将复杂的Kubernetes部署和多服务集成自动化,降低了技术门槛,让开发者可以更专注于业务逻辑的实现,而不是基础设施的维护。
· 需要构建安全、隔离的集群以支持多租户或微服务的团队:RunOS的WireGuard网络设计提供了强大的安全保障,并通过Agent机制实现了更精细化的控制和管理。
48
GitHub团队协作洞察引擎
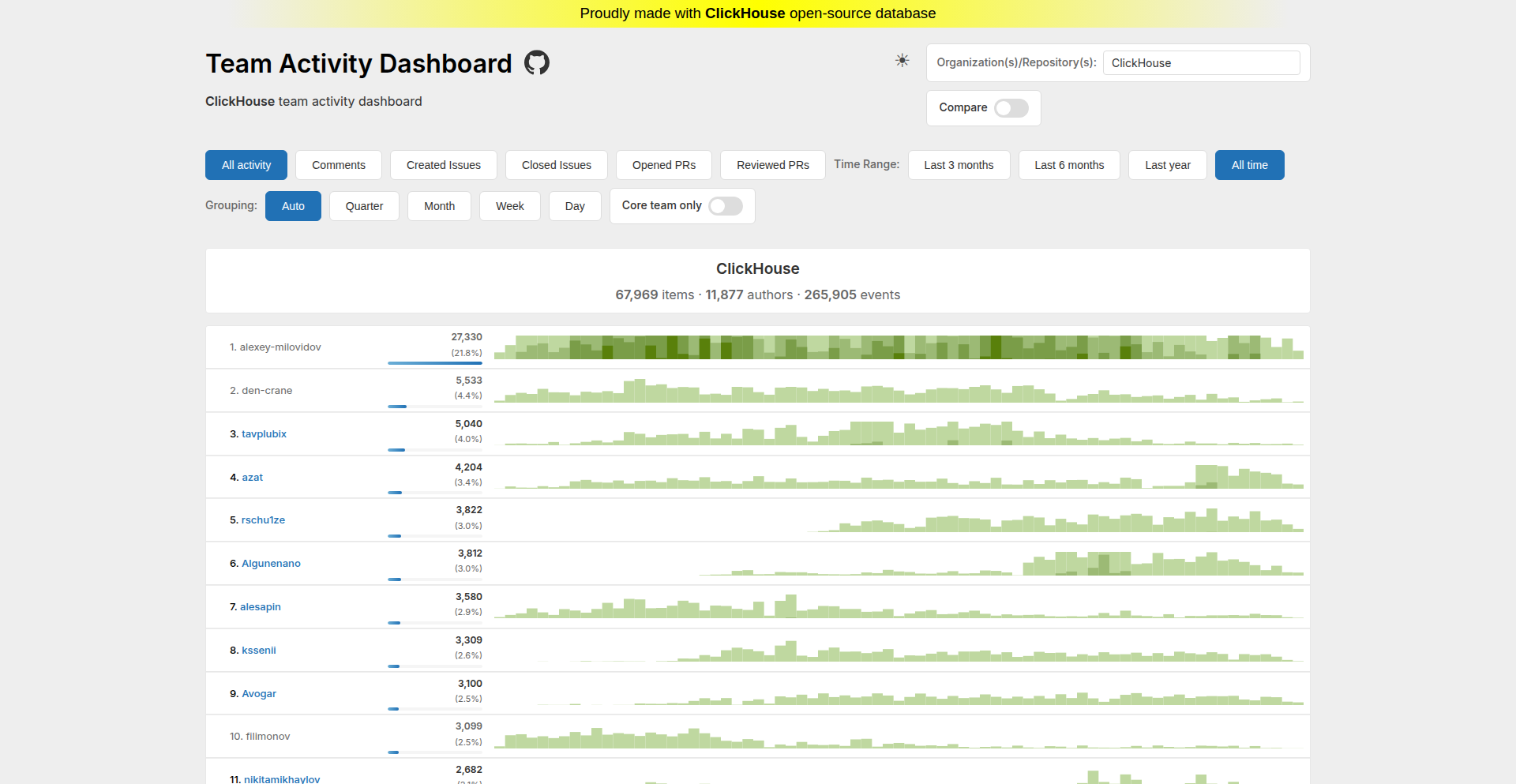
作者
AlexClickHouse
描述
这是一个能深入分析GitHub仓库团队活动情况的网站。它不仅仅是展示代码提交,还能帮你找出团队成员的贡献模式,识别关键贡献者,并且支持对比不同仓库的团队活跃度。核心创新在于它能可视化复杂的协作数据,让你一眼就能看出团队的健康度和效率,从而帮助优化项目管理。所以这对我有什么用?它能让你更直观地了解你的开发团队或者你感兴趣的开源项目团队是如何协作的,发现潜在的瓶颈或亮点。
人气
点赞 2
评论数 0
这个产品是什么?
这是一个基于GitHub API构建的网站,旨在可视化和分析开源项目或私有仓库的团队协作活动。它通过收集和处理仓库的提交记录、PR(Pull Request)等数据,将抽象的协作行为转化为易于理解的报告和图表。它的技术核心在于能够抓取、解析并聚合来自GitHub的丰富数据,然后用数据分析和可视化技术来呈现团队成员的贡献分布、活跃度趋势、以及团队协作的模式。它的创新之处在于,它不只是简单地罗列数据,而是试图从这些数据中提炼出有价值的洞察,帮助管理者或开发者理解团队动态。所以这对我有什么用?它能让你看到团队成员都在忙些什么,谁在做贡献,以及项目整体的开发节奏,从而更好地进行项目规划和管理。
如何使用它?
开发者可以通过访问这个网站,输入GitHub仓库的URL(公开或私有仓库,需要授权),然后选择想要分析的时间范围、团队成员,或者仓库类型。网站会根据你的选择,生成一系列图表和报告,展示代码提交频率、PR合并情况、活跃贡献者排名、甚至可以分析提交信息的模式(作者甚至把每个Prompt都当做Commit Message来记录)。你可以直接在网站上浏览这些分析结果,也可以将这些数据用于进一步的分析或报告。所以这对我有什么用?你可以快速地为项目经理提供一个关于团队开发效率的报告,或者评估一个潜在合作项目的活跃度。
产品核心功能
· 团队成员贡献模式分析:通过分析代码提交、PR活动等,识别出团队中不同成员的贡献类型和频率,帮助了解个人特长和工作重心。这对于团队管理和人才发展非常有价值,可以让你知道谁是某个领域的专家。所以这对我有什么用?了解团队成员的贡献模式,可以帮助你更好地分配任务,或者识别潜在的明星开发者。
· 关键贡献者识别:基于数据分析,找出对项目贡献最大、最活跃的成员,这对于项目维护和鼓励积极贡献者至关重要。所以这对我有什么用?识别出项目中的核心贡献者,可以让你知道在遇到问题时应该找谁,或者如何激励这些关键人物。
· 多仓库活动对比:允许用户同时分析和对比多个GitHub仓库的团队活动情况,从而横向比较不同项目的开发效率和团队健康度。所以这对我有什么用?你可以对比自己正在参与的项目和行业内优秀项目的团队活动情况,从中学习和改进。
· 活动趋势可视化:将一段时间内的团队活动(如提交次数、PR数量)以图表形式展示,帮助观察项目开发节奏的变化。所以这对我有什么用?通过观察开发节奏的变化,你可以预判项目进度,或者发现开发活动是否出现异常波动,及时调整策略。
· 提交信息模式分析:作者甚至将Prompt也作为Commit Message来记录,这项功能可以深入分析提交信息的风格和内容,从侧面反映开发者的思考过程和项目管理方式。所以这对我有什么用?通过分析提交信息的模式,你可以更深入地理解开发者的工作思路,甚至发现项目管理中的一些有意思的实践。
产品使用案例
· 项目经理评估团队效率:项目经理可以使用该工具来监控一个开发团队在一段时间内的活跃度,通过查看提交频率、PR合并率等指标,快速评估团队的开发效率,并找出可能存在的瓶颈。例如,如果发现某个时间段内提交量骤减,但PR数量却很高,可能意味着团队在代码审查上花费了大量时间,需要优化流程。所以这对我有什么用?让项目经理能够用数据说话,更客观地管理团队,发现并解决效率问题。
· 开源项目贡献者分析:一位开发者想要了解某个心仪的开源项目,他可以通过该网站分析该项目的核心贡献者是谁,他们的贡献频率如何,以及项目的整体活跃度。这可以帮助他决定是否加入该项目,或者了解如何更好地融入社区。例如,如果发现项目有几个非常活跃的核心开发者,他的贡献很容易被看见和采纳。所以这对我有什么用?帮助开发者选择合适的开源项目加入,或者了解如何在这个项目中做出更有影响力的贡献。
· 代码评审流程优化:通过分析PR的创建、合并时间以及参与评审的成员,可以发现代码评审过程中是否存在延迟,或者某些成员评审效率偏低。例如,发现大量PR长时间停留在待评审状态,可能需要增加评审人员或优化评审标准。所以这对我有什么用?帮助团队找到代码评审流程中的问题,从而加快代码集成速度,提高开发效率。
· 识别潜在技术债务:通过分析某些成员的提交模式和代码量,或者某些模块的提交频率较低,可以间接发现项目可能存在的代码维护不均衡或技术债务累积的风险。例如,如果发现某个核心模块长时间没有新的提交,可能意味着它已经稳定,但也可能存在被忽视的风险。所以这对我有什么用?帮助团队提前发现和管理潜在的技术风险,避免未来出现大问题。
· 招聘和人才发掘:在招聘新的开发人员时,可以参考候选人过往在GitHub上的贡献模式和活跃度,作为评估其技术能力和投入度的一部分。同时,也可以发掘在某个开源项目中表现突出的开发者。所以这对我有什么用?为招聘决策提供更丰富的参考信息,帮助找到真正有能力的开发者。
49
GitOps SyncWatch
作者
kunobi
描述
GitOps SyncWatch 是一款桌面应用,旨在集成 Kubernetes 资源状态与 Flux 或 Argo CD 的同步信息,从而减少开发者在不同工具间切换的次数。它通过直接与 Kubernetes API 服务器通信,将 GitOps 工具(如 Flux 或 Argo CD)生成的部署状态与实际运行的 Kubernetes 资源并列展示,帮助开发者快速了解集群运行情况、同步状态以及是否存在差异。
人气
点赞 2
评论数 0
这个产品是什么?
GitOps SyncWatch 是一个智能的 Kubernetes 和 GitOps 可视化工具。它能让你在同一界面看到你部署在 Kubernetes 集群上的所有应用(工作负载)以及它们的状态,同时还能直接看到 Flux 或 Argo CD 这些自动化部署工具为你部署的应用是否与你期望的状态保持一致。它的核心创新在于将本该分散在多个系统中的信息整合起来,比如:应用跑得怎么样、它是不是已经成功部署了、它和部署文件里写的有没有不一样、最近更新过几次等等。简单来说,它就像一个指挥中心,让你一目了然地掌握整个 Kubernetes 和 GitOps 的运行状况。
如何使用它?
开发者可以将 GitOps SyncWatch 作为一款独立的桌面应用程序安装在自己的电脑上。安装完成后,你可以配置它连接到你的 Kubernetes 集群。应用程序会自动读取 Kubernetes API 的信息,并与你使用的 GitOps 工具(Flux 或 Argo CD)同步。这样,你就可以在 SyncWatch 里直接看到你的应用列表、每个应用的部署状态、GitOps 的同步状态(是同步的还是有差异)、最近的变更记录,甚至 Helm 包的更新历史。它还提供了一个本地测试环境,方便你在不连接生产集群的情况下练习 GitOps 操作。
产品核心功能
· 集成 Kubernetes 资源与 GitOps 同步状态:将运行在 Kubernetes 上的各种服务(比如你的 Web 应用、数据库)的状态,与 Flux 或 Argo CD 报告的部署状态整合显示,让你一眼就知道一切是否按计划进行。价值:避免来回切换命令行工具或网页界面,节省宝贵的时间。
· 可视化同步差异(Drift Detection):清晰地标记出 Kubernetes 集群中实际运行的资源与 GitOps 配置中期望的状态不一致的地方,并给出差异详情。价值:快速定位问题根源,是配置错了,还是有人手动修改了集群?
· 多集群管理:支持同时查看和管理多个 Kubernetes 集群的资源和 GitOps 状态,无需频繁切换 kubeconfig 文件。价值:对于拥有多个 Kubernetes 集群的团队来说,极大地简化了日常操作和监控。
· 部署历史与回滚辅助:展示每个工作负载的部署历史和版本信息,包括 Helm 包的更新记录。价值:方便追溯问题发生的版本,理解变更脉络,为快速回滚提供依据。
· 本地 GitOps 测试环境:提供一个轻量级的本地环境,让开发者可以在不影响生产环境的情况下,测试和验证 GitOps 的部署流程。价值:降低试错成本,提升 GitOps 的学习和实践效率。
产品使用案例
· 场景:开发人员正在调试一个在 Kubernetes 集群中部署失败的应用。问题:需要查看 Kubernetes Pod 的日志、Deployment 的状态,还要检查 Flux CD 的 Kustomization 或者 Argo CD 的 Application 状态。解决方案:使用 GitOps SyncWatch,可以在一个界面同时看到 Pod 的运行情况、Deployment 的最新状态,以及 Flux CD/Argo CD 显示的同步错误信息和配置差异,大大缩短了问题排查的时间。
· 场景:一个团队负责维护多个 Kubernetes 集群,并且使用 GitOps 进行部署。问题:以前需要登录到每个集群,使用不同的命令或工具来检查部署情况和同步状态,效率低下且容易出错。解决方案:GitOps SyncWatch 允许开发者在一个应用中连接所有集群,并统一查看各个集群的 GitOps 同步状态,当某个集群出现不同步时,SyncWatch 会高亮显示并提供详细的差异信息,帮助团队高效地管理和监控多集群环境。
· 场景:一位开发者想要学习和实践 GitOps,但又不想直接修改生产环境。问题:没有一个简单的方式来模拟 GitOps 的工作流程。解决方案:GitOps SyncWatch 提供了一个本地测试环境,开发者可以在这个环境中模拟 Git 提交、Flux/Argo CD 的同步过程,并使用 SyncWatch 来观察资源的变化和同步状态,从而在零风险的情况下掌握 GitOps 的核心技能。
50
指弹乾坤:无垠和弦图生成器
作者
mike_xilo
描述
一款完全免费、无需注册、支持离线使用的定制吉他和弦图生成工具,专为爵士、Bossa Nova等复杂音乐风格设计。它解决了在学习和编排包含大量复杂和弦的乐曲时,标准和弦图难以准确表达和设计的问题。
人气
点赞 2
评论数 0
这个产品是什么?
这个项目是一个为吉他手量身打造的智能和弦图制作器。它的技术核心在于能够灵活地自定义和弦的构成音和指法,而不仅仅局限于常见的和弦形状。例如,对于复杂的爵士和弦,你可以精确地标记出每个音在指板上的位置,并指定用哪个手指按压,甚至可以定义哪些弦不发声(静音)。这就像是给了吉他手一个可以完全掌控和弦视觉表达的画板,解决了传统和弦图在面对非主流或自创和弦时信息不够精确、表现力不足的痛点。
如何使用它?
开发者可以将其作为一个独立的Web应用使用。当你需要创作一段包含特殊和弦的音乐,或者学习一些非常规的和弦时,可以直接打开这个工具。在浏览器中,你可以直观地看到一个吉他和弦的俯视图,通过点击对应的品位和弦格,标记出按弦的手指位置,以及选择哪些弦应该被静音(不弹奏)。完成后,你可以直接将生成的和弦图导出为PDF文件,方便打印、分享或添加到乐谱中。对于音乐制作人、吉他教师或任何想要深入研究和弦理论的吉他爱好者来说,这是一个快速、便捷且高度个性化的工具。
产品核心功能
· 高度自定义和弦指法:允许用户精确选择每个音的品位和弦格,并指定按弦手指,解决了标准和弦图无法表达复杂和弦的限制,为创作提供无限可能。
· 静音弦标记:能够标记出不应发声的弦,这对于构建特定音响效果或简化复杂和弦至关重要,大大增强了和弦图的表现力。
· 无缝离线工作:作为本地运行的Web应用,即便在没有网络连接的情况下也能使用,保证了创作和学习的连续性,解决了网络不稳定带来的不便。
· 无需注册,即时可用:打开即用,无需任何账号信息,极大地提升了用户体验,让用户可以专注于音乐本身。
· PDF导出功能:可以将创建的和弦图以高质量PDF格式导出,便于打印、分享和集成到其他文档中,提供了良好的输出和存档机制。
产品使用案例
· 学习复杂爵士和弦:一位爵士吉他手在学习一首包含大量三全音(Tritone)或属七和弦(Dominant 7th)变体的乐曲时,发现标准和弦图无法清晰展示其指法。他使用该工具精确绘制出每个复杂和弦的指法和音符位置,从而快速掌握并演奏,大大缩短了学习曲线。
· 创作个性化教材:一位吉他教师为学生编写一份关于“非主流和弦构建”的教程。他利用此工具为每个教程中的原创或罕见和弦创建了专属的和弦图,并精确标注了指法和静音弦,使教程更加直观易懂,提升了教学效果。
· 编排Bossa Nova乐曲:一位音乐制作人在编排一首Bossa Nova曲目时,需要使用到一些带有挂留音(Suspended Chords)或琶音(Arpeggiated)感觉的和弦。他使用该工具设计出符合特定音响效果的和弦图,并通过PDF导出,将其作为参考集成到DAW(数字音频工作站)的项目文件中,为音乐创作提供了有力支持。
· 吉他Solo的即兴助手:一位吉他手在尝试即兴演奏一段旋律时,需要快速找到一个能够匹配旋律特定音符的和弦。他使用该工具,通过标记旋律中的目标音符,反向查找并设计出能够包含这些音符的自定义和弦指法,从而实现了流畅的即兴演奏。
51
Embedr: 嵌入式AI工程助手
作者
sinharishabh
描述
Embedr 是一个专为嵌入式工程师设计的AI助手,它能理解你的硬件项目结构、芯片配置(如ESP32、STM32、RP2040等),并能帮助你解释复杂的寄存器、外设配置、链接器问题、构建错误,甚至提出硬件故障和集成问题的解决方案。它的目标是让你在接线、刷写代码、调试硬件时,感觉就像拥有一个更智能、更懂你的IDE。
人气
点赞 2
评论数 0
这个产品是什么?
Embedr 是一个AI驱动的工具,专门为从事嵌入式系统开发(就是那些控制微控制器的小电脑,比如物联网设备、遥控器里的小芯片)的工程师们打造。它不像普通的AI写代码助手那样什么都管,而是深入研究嵌入式开发的具体流程。比如,它能看懂你的项目文件,知道你用的是哪种芯片,还能解释芯片内部的各种“开关”(寄存器)是干什么用的,为什么你的代码编译不过,甚至能帮你找出硬件接线出了什么问题。它的创新之处在于,它不是简单地生成代码,而是真正理解硬件的工作方式,并提供针对性的帮助,就像一位经验丰富的“老司机”在你旁边指导你一样,让你少走弯路。
如何使用它?
开发者可以将Embedr集成到他们的开发流程中,通过访问Embedr网站或未来的IDE插件。当你遇到构建错误、不理解某个硬件配置、或者怀疑硬件出了问题时,可以直接向Embedr提问,提供你的项目信息和错误日志。Embedr会分析这些信息,给出解释和具体的解决方案建议。例如,你可以问它“为什么我的ESP32串口通信不稳定?”,Embedr可能会分析你的代码和芯片手册,指出可能是某个外设配置不当,并提供修改建议。它还可以帮助你生成项目构建脚本,让你更轻松地开始新项目。
产品核心功能
· 智能理解项目结构和硬件配置:Embedr能分析你的项目文件,识别你使用的微控制器(如ESP32, STM32, RP2040等)及其关键配置,帮助你快速掌握项目概况,节省时间。
· 解释和解决低级硬件问题:提供对寄存器、外设配置、链接器脚本等底层概念的清晰解释,并能诊断和提出解决构建错误、硬件故障、外设不响应等难题的方案,减少工程师的调试时间。
· 辅助硬件调试和上手:引导开发者完成硬件的初始设置(bring-up)过程,并能协助进行驱动层级的调试,让你更有效地处理硬件层面的复杂问题。
· 自动化构建系统生成:能够根据你的项目需求,自动生成适合的构建系统或工具链配置,简化开发者的环境搭建过程,让他们更快地开始编码。
· 硬件故障排除建议:通过分析问题描述和项目上下文,提出可能导致硬件故障的原因,并提供修复建议,尤其在处理一些“玄学”般的硬件问题时,能提供有价值的思路。
产品使用案例
· 在一个物联网设备项目中,开发者遇到了ESP32 Wi-Fi连接不稳定的问题。通过向Embedr描述情况并提供部分代码,Embedr分析了可能的无线配置参数和电源管理设置,建议调整某些低功耗模式的配置,从而解决了连接稳定性问题,使产品能够可靠工作。
· 一个嵌入式工程师在尝试为STM32芯片开发一个自定义外设驱动时,遇到了链接器错误,导致程序无法正确加载。Embedr帮助分析了链接器脚本和内存映射,解释了符号解析的失败原因,并提供了修改链接器脚本以正确分配内存的指导,使驱动程序得以成功集成。
· 一位开发者正在为RP2040开发一个新的传感器模块接口,但他对如何正确配置SPI接口的时序感到困惑。Embedr解释了SPI的时钟极性、相位等参数,并根据传感器的数据手册,给出了具体的SPI配置建议,帮助开发者快速实现了与传感器的正确通信。
· 当一个团队在调试一个复杂的嵌入式系统时,发现一个关键的外设(如ADC)总是返回异常读数。Embedr通过分析该外设的寄存器手册和可能的硬件连接问题,帮助团队排查了由于时钟频率不匹配或某个控制寄存器设置错误导致的问题,最终成功还原了外设的正常功能。
52
多通道支付模拟器
作者
g-sudarshan
描述
这是一个旨在简化支付集成开发的SaaS工具,它提供了一个统一的测试环境,模拟了多家主流支付网关(如Stripe、Razorpay等)的API行为和真实世界中的各种支付场景,例如退款、争议、延迟支付和不同的Webhook响应。解决了开发者需要创建多个支付账号、处理不同网关不一致行为以及难以测试边缘场景的痛点,让集成和测试支付流程变得更高效、更可靠。
人气
点赞 2
评论数 0
这个产品是什么?
这个项目是一个“多通道支付模拟器”,本质上是一个虚拟的支付环境。想象一下,当你开发一个需要收款的App或网站时,你需要测试支付功能。现实中,每个支付公司(比如Stripe、支付宝、微信支付)都有自己的测试账户和测试方法,而且它们表现可能不一样,有时候还会出问题,测试起来特别麻烦。这个模拟器就像一个“万能测试台”,你只需要连接它一次,它就能假装成很多不同的支付公司,并且能模拟出各种真实世界可能发生的支付情况,比如用户退款、商家收到争议、支付延迟等等。它的创新之处在于,它把这些分散的、零散的测试场景集中到一个地方,而且可以通过设置来模拟各种“不正常”但真实会发生的情况,大大降低了测试的复杂性,让开发者可以更专注于核心业务逻辑。
如何使用它?
开发者可以将这个模拟器集成到他们的开发流程中。最直接的使用方式是,在本地开发或CI/CD(持续集成/持续部署)环境中,用模拟器代替真实的支付接口。比如,你可以配置好你的应用,让它向模拟器发送支付请求。当需要进行更真实的测试时,只需切换配置,将支付请求指向真实的支付网关。它还可以通过API调用来触发各种支付场景,或者设置规则让它随机模拟延迟、失败或不同的Webhook通知。这样,即使在没有真实支付账户的情况下,或者在自动化测试中,也能全面地测试支付流程,包括各种异常和边缘情况,从而提高代码质量和交付速度。
产品核心功能
· 模拟主流支付网关API: 让你不用为Stripe、Razorpay等每个支付平台都去申请和管理独立的测试账号,一次性提供统一的接口,方便快捷。
· 模拟复杂支付场景: 能够模拟处理捕获、全额/部分退款、拒付、争议、结算延迟、支付失败等真实交易流程,让你可以在开发阶段就发现和修复潜在问题。
· 模拟 webhook 行为: 支付系统通常会通过Webhook通知你的应用支付状态。这个模拟器可以模拟Webhook的延迟、丢失甚至重复发送,让你能更健壮地处理异步通知。
· 网络异常模拟: 可以模拟网络延迟、断网等情况,测试你的应用在不稳定网络环境下的表现,避免用户在实际使用中遇到卡顿或失败。
· 3-D Secure / OTP 模拟: 模拟银行验证过程中的二次验证页面(如短信验证码),让你测试完整的支付流程,而不是半成品。
· UPI 模拟: 针对UPI等支付方式,模拟支付超时或处理中等状态,应对不同的支付交互。
· 交易生命周期控制: 提供一个控制面板,可以查看模拟的交易,并手动触发或按时触发各种交易状态变化,方便调试。
· 自定义网关规则: 允许开发者设置模拟网关的行为规则,例如设置一定比例的失败率、模拟不同的延迟时间或Webhook的乱序,以测试各种“坏情况”。
产品使用案例
· 在开发一个电商网站的支付环节时,开发者可以使用这个模拟器来快速测试用户从选择商品到支付完成的整个流程,而无需等待真实的支付账户批准或配置。当模拟器模拟支付成功时,应用会像真实支付一样响应,反之亦然,这样可以快速迭代功能。
· 一个大型企业应用需要集成多个支付选项,并且需要保证在各种网络条件下都能稳定运行。开发者可以使用模拟器来测试应用在网络延迟或间歇性断网时的表现,确保支付流程不会中断,或者能够正确处理重试逻辑。
· 在进行CI/CD自动化测试时,可以将这个模拟器集成到测试流程中。每次代码提交后,自动化测试可以调用模拟器来模拟支付交易,然后验证应用的响应是否正确,甚至模拟退款或争议场景,确保支付逻辑在代码集成前就是可靠的,避免上线后出现问题。
· 对于需要处理复杂的支付退款和争议流程的金融科技公司,他们可以使用模拟器来模拟这些极少发生但可能造成重大损失的场景。例如,模拟一个用户发起争议,然后测试客服系统和支付系统如何协同处理,确保流程正确无误。
53
Reddit数据洞察管道:英国签证时间提取器
作者
hnarayanan
描述
这是一个通过处理Reddit评论数据,提取英国签证申请时间线的技术项目。它利用自然语言处理(NLP)和数据管道技术,自动化地从海量的用户分享中挖掘有价值的签证申请进度信息,解决了人工分析耗时且容易遗漏的问题。技术创新点在于构建了一个高效的数据提取和分析流程,为潜在的英国签证申请者提供了快速、可靠的信息参考。
人气
点赞 2
评论数 0
这个产品是什么?
这个项目是一个专门设计用来分析Reddit社区中关于英国签证申请讨论的工具。它的核心技术是一个数据处理流程(pipeline),就像一个自动化的工厂流水线。首先,它会从Reddit抓取相关的评论数据。然后,利用自然语言处理(NLP)技术,特别是其中的文本分析能力,来识别和提取评论中提到的签证申请的具体时间点信息,比如提交申请日期、收到回复日期、获批日期等等。最后,将这些提取出的时间信息整理成一个有用的时间线,方便大家查看。这种方法的创新之处在于,它能自动化地从非结构化的、口语化的Reddit评论中,精准地提取出结构化的时间信息,这在之前是很难通过人工高效完成的。所以,它能帮助我们更快速、更准确地了解英国签证的申请流程和大概的耗时,这对于准备申请的人来说非常有价值。
如何使用它?
对于开发者来说,这个项目提供了一个关于如何从社交媒体数据中提取特定类型信息的实用框架。你可以将其视为一个模板,用来处理其他类似的数据分析需求。例如,你可以修改或扩展这个管道,去分析其他平台的讨论,提取关于产品发布时间、项目进度反馈、或者甚至是特定事件发生的时间线。具体使用上,你可以参考其代码实现,学习如何集成Reddit API来获取数据,如何运用NLP库(如spaCy或NLTK)进行文本解析,以及如何构建数据存储和展示的后端逻辑。这个项目展示了如何用代码自动化地从网络信息中挖掘出有价值的洞察,非常适合那些想要处理大量文本数据并从中提取关键信息的开发者。所以,它能让你学会如何用代码将杂乱的网络信息变成有用的结构化数据,这在很多领域都有应用潜力。
产品核心功能
· Reddit评论数据抓取:自动从Reddit上获取与英国签证相关的用户评论,解决了信息分散、难以收集的问题。
· 自然语言处理(NLP)进行时间信息提取:利用先进的文本分析技术,精准识别评论中的日期、月份、年份等时间标记,并将其与签证申请流程中的关键节点(如提交、回复、获批)关联起来,实现了自动化、高精度的信息提取。
· 签证时间线构建与整理:将提取到的零散时间信息整合成清晰、易于理解的签证申请时间线,方便用户快速了解大致的处理周期,解决了人工整理信息繁琐且容易出错的问题。
· 数据管道化处理:将数据抓取、文本分析、信息提取和整理串联起来,形成一个高效、可重复的数据处理流程,体现了黑客文化中用自动化解决问题的创造力。
产品使用案例
· 一个准备申请英国工作签证的用户,可以通过查询这个项目整理出的时间线,了解不同申请类别、不同递签地点的大致处理时间,从而更合理地规划自己的出行和工作安排。
· 一个正在进行英国学生签证申请的用户,发现Reddit上有人分享了近期申请的进度,这个项目能够快速抓取并识别出其中的关键时间点,帮助该用户评估自己当前申请的进度是否在正常范围内,减轻焦虑。
· 一个研究英国移民政策的学者,可以使用这个项目作为数据源的初步参考,通过分析大量用户分享的签证时间数据,了解实际申请过程中可能遇到的时间延迟或效率变化,为政策研究提供现实依据。
54
零成本信任中心
作者
gamalinosqui
描述
一个免费、极简的信任中心,用于帮助开发者轻松管理和展示其产品的隐私政策、服务条款等合规性文件。它通过简单的配置,为你的项目生成一个可信的在线入口,解决了中小团队在合规性展示上的痛点,让用户更放心地使用你的产品。
人气
点赞 2
评论数 0
这个产品是什么?
这是一个什么项目?它是一个由开发者 gamalinosqui 创建的、完全免费且非常易于使用的“信任中心”。想象一下,当你的产品需要告诉用户你的隐私政策在哪里,你的服务条款是什么,或者提供一个联系方式来处理疑虑时,你就需要一个这样的地方。这个项目通过预设的模板和简单的配置,让你无需懂复杂的网页开发,就能快速搭建起一个看起来专业、可信的合规性信息展示页面。它的技术创新在于,它把原来可能需要聘请专业人士、花费大量时间和金钱才能完成的事情,变成了一个简单的配置过程,让开发者可以专注于产品本身,而不是被合规性问题困扰。所以这对我有什么用?它让我能快速、免费地满足用户对产品合规性的基本需求,提升用户对产品的信任度。
如何使用它?
开发者怎么使用这个项目?很简单,你只需要 fork 这个项目到你的 GitHub 仓库,然后根据项目提供的说明,修改其中的配置文件,比如填入你的产品名称、隐私政策的链接、服务条款的链接,以及联系方式等信息。你可以根据自己的需求,再做一些简单的样式调整。生成的内容可以直接托管在 GitHub Pages 上,或者集成到你现有的网站中。它提供了一个基础的框架,你可以根据需要进行扩展。所以这对我有什么用?你可以快速拥有一个专业的合规性展示页面,让用户知道你的产品是靠谱的,而且几乎不需要成本。
产品核心功能
· 极简配置生成信任中心页面:通过简单的配置文件,自动生成一个包含隐私政策、服务条款、联系方式等核心信息的页面,大大降低了合规性信息展示的技术门槛。所以这对我有什么用?我可以快速搭建一个可信的页面,提升用户对产品的信任。
· 免费且开源:项目完全免费,并且是开源的,开发者可以自由地修改和使用,无需担心授权问题。所以这对我有什么用?我可以节省大量的开发和合规成本,并且可以根据自己的需求进行定制。
· GitHub Pages 集成:非常适合与 GitHub Pages 集成,实现零成本的在线托管。所以这对我有什么用?我可以轻松地将我的信任中心部署到线上,并且完全免费。
· 可扩展性:项目提供了基础框架,开发者可以根据自身需求进行定制化扩展,例如添加更多的法律文件链接,或者集成反馈表单。所以这对我有什么用?我可以随着业务的发展,让信任中心也随之变得更强大,满足更多场景的需求。
· 专注于技术实现的简洁性:该项目强调的是用最少的代码和最直接的方式解决问题,体现了黑客精神。所以这对我有什么用?它让我看到,解决复杂问题不一定需要复杂的方案,简洁高效的实现同样强大。
产品使用案例
· 初创公司需要快速上线一个新产品,但苦于没有预算聘请法务顾问来撰写和展示隐私政策。使用这个信任中心,他们可以快速生成一个基础的合规性页面,满足上线基本要求,并在后续迭代中完善。所以这对我有什么用?即使预算有限,我也可以让我的产品看起来更专业、更合规。
· 一个个人开发者开发了一个小工具,希望给用户一个明确的联系方式和使用说明。通过这个信任中心,开发者可以轻松展示这些信息,避免用户产生不必要的误解和纠纷。所以这对我有什么用?我无需花费大量时间学习如何制作复杂的网站,就能给用户一个清晰的信息入口。
· 一个开源项目需要向贡献者和用户展示其代码使用协议和社区行为准则。这个信任中心可以作为一个集中的入口,方便大家查阅。所以这对我有什么用?我可以更方便地管理和传达开源项目的规章制度,维护社区秩序。
· 一个SaaS产品需要满足GDPR等数据隐私法规的要求,展示其数据处理方式。虽然这个项目不替代专业的法律意见,但它可以作为初步展示合规信息的一个便捷工具。所以这对我有什么用?我可以先有一个展示的平台,方便向用户传递我们的数据处理理念。
55
GreasePanda:网站个性化注入引擎
作者
sudosoft
描述
GreasePanda 是一个允许用户通过编写简单的脚本(称为 userscripts)来修改任何网站外观和功能的浏览器扩展。它解决了用户希望个性化网页体验,例如去除广告、调整布局、自动填充信息,但又不想依赖网站本身提供这些功能的问题。其创新之处在于提供了一个统一的平台,让开发者能够轻松地为不同网站创建和管理这些功能强大的脚本。
人气
点赞 2
评论数 0
这个产品是什么?
GreasePanda 是一个浏览器插件,它让你能用代码(userscripts)来“改造”你看到的任何网页。想想看,就像给你的浏览器装了个“超级开关”,可以控制网页变成你想要的样子。它的核心技术原理是,当你在浏览网页时,GreasePanda 会悄悄地检查你有没有给这个网站编写过脚本,如果有,它就会把你的脚本加载到网页里执行。这样,你就可以改变网页的样式(比如换个颜色、隐藏某个不喜欢的区域),或者让网页做一些自动化的事情(比如自动点击按钮、填入默认值)。它最厉害的地方在于,不需要网站作者同意,你就可以自由地为自己定制网页,这是一种非常直接的代码驱动的个性化。
如何使用它?
开发者可以通过安装 GreasePanda 浏览器扩展来开始使用。一旦安装好,你就可以在 Greasy Fork、OpenUserJS 等用户脚本托管网站上找到别人写好的脚本,或者自己动手编写。编写脚本通常使用 JavaScript 语言,你可以通过浏览器开发者工具来查看网页的结构,然后编写 JavaScript 代码来操纵这些元素。例如,你可以写一段代码让某个广告区域消失,或者让某个按钮点击后自动跳转到另一个页面。这些脚本可以被组织和管理在 GreasePanda 的界面里,你可以选择启用或禁用它们,或者为不同的网站设置不同的脚本。这让你能够将特定的代码片段快速应用到日常的网页浏览中,解决你在使用特定网站时遇到的不便。
产品核心功能
· 用户脚本的注入和执行:GreasePanda 能够在任何网页加载时,根据用户设定的规则自动加载并执行对应的 JavaScript 脚本,这意味着你可以让自定义的代码控制网页的行为,解决你遇到的具体网页问题。
· 脚本的分类与管理:提供一个集中的界面来组织、启用、禁用和更新你添加的或从社区获取的用户脚本,让你能够方便地管理你的网站定制化工具,确保每个网站都能按照你的意愿呈现。
· 跨浏览器兼容性:GreasePanda 通常会支持主流的浏览器,这意味着你编写或使用的脚本可以在不同的浏览器环境下运行,极大地提高了脚本的通用性和实用性。
· 社区脚本的发现与安装:通过连接到用户脚本托管网站,GreasePanda 让你能够轻松发现并一键安装成千上万个由社区贡献的脚本,快速解决常见网站问题或增强网站功能,无需从零开始编写。
· 自定义样式注入:除了功能性的 JavaScript 脚本,用户还可以注入 CSS 样式,直接修改网页的视觉呈现,比如改变字体大小、背景颜色或隐藏不喜欢的元素,让网页更符合你的审美。
产品使用案例
· 当你在浏览一个充满广告的论坛时,你可以使用 GreasePanda 安装一个脚本,这个脚本会自动识别并隐藏所有的广告区域,让你获得一个清爽的阅读体验,解决了广告干扰的问题。
· 在某些电商网站上,你可能需要重复点击同一个按钮才能完成一系列操作,你可以编写一个简单的 GreasePanda 脚本,让这个按钮在被点击后自动触发一系列预设的操作,极大地提高了效率,解决了重复性操作的痛点。
· 对于一些你经常使用的在线文档编辑器,你可能希望添加一些额外的快捷键或格式化工具,你可以使用 GreasePanda 编写脚本来注入这些自定义功能,让编辑过程更顺畅,解决了功能不足的问题。
· 如果你发现某个网站的某个功能使用起来非常不方便,比如某个信息显示的位置不合理,你可以编写一个 GreasePanda 脚本来移动这个信息显示区域,或者改变它的样式,让它更符合你的使用习惯,解决了交互不友好的问题。
· 在学习编程时,你可能会遇到一些网站的控制台输出信息杂乱,你可以使用 GreasePanda 脚本来美化和过滤控制台的输出,使其更容易阅读和分析,帮助你更快地理解和调试代码,解决了信息混乱的问题。
56
函数寻址存储:Ouveture.py
作者
amirouche
描述
Ouveture.py 是一个创新的 Python 库,它提供了一种“内容寻址”的存储方式来管理多语言函数。简单来说,就像你用文件的内容而不是文件名来查找文件一样,Ouveture.py 使用函数的“内容”(即函数代码本身)来生成一个唯一的地址,然后将函数存储在这个地址下。这使得函数查找和复用变得更加高效,尤其是在需要处理大量不同语言函数(比如 Python, JavaScript, WebAssembly 等)的场景下,能够显著提升开发效率和代码的可维护性。
人气
点赞 2
评论数 0
这个产品是什么?
Ouveture.py 是一个基于 Python 的内容寻址存储系统,专门用于管理和查找多语言函数。它的核心技术在于“内容寻址”这一概念。通常情况下,我们通过文件名来找到一个文件,但内容寻址则通过文件的具体内容来生成一个唯一的标识符(比如一个哈希值)。Ouveture.py 就是将这个思想应用到了函数上。它会计算函数的代码内容的哈希值,并将这个哈希值作为函数的地址。这样一来,即使函数被存储在不同的地方,或者有相同的代码但文件名不同,只要内容一样,它们就会指向同一个地址。这解决了在复杂项目中,查找和管理各种语言编写的同功能函数的痛点,并且使得代码的复用更加安全可靠,因为你查找的是函数的实际内容,而不是一个可能指向错误代码的名称。这就像你找一个“打印‘Hello World’”的指令,无论它写在哪个文件里,只要内容是打印“Hello World”的代码,Ouveture.py 都能找到它。
如何使用它?
开发者可以将 Ouveture.py 集成到自己的项目中,通过一个简单的 Python API 来注册、存储和检索函数。你可以用它来构建一个函数注册表,或者在一个项目中动态地加载和执行来自不同源(例如,不同脚本文件、甚至可能是远程服务)的函数,而无需关心它们的原始位置或文件名。对于需要执行由不同技术栈(如 Python 脚本、JavaScript 片段、Wasm 模块)生成的函数,Ouveture.py 提供了一个统一的管理接口。比如,你可以在一个 Python 项目中,存储和调用一个用 JavaScript 编写的函数,或者一个用 WebAssembly 编译的代码片段,Ouveture.py 会处理底层的存储和查找,你只需要通过其提供的唯一内容地址来访问这些函数。这就像有一个万能的函数调度中心,你告诉它你想要执行的“功能是什么”,它就能帮你找到并执行对应的代码。
产品核心功能
· 内容寻址存储:通过计算函数代码的哈希值来生成唯一的存储地址。这意味着,只要函数的代码内容相同,无论其来源或文件名如何,都会被映射到同一个地址,大大简化了函数查找和管理,尤其在代码库庞大时,这能节省大量查找时间。
· 多语言函数支持:能够存储和管理使用不同编程语言编写的函数,包括 Python、JavaScript、WebAssembly 等。这解决了在跨技术栈开发中,集成和调用不同语言函数的复杂性,为开发者提供了一个统一的接口。
· 函数注册与检索:提供 API 来注册新的函数及其内容,以及通过其内容地址快速检索并执行这些函数。这使得动态加载和执行函数成为可能,增加了应用的灵活性和可扩展性。
· 版本控制与不变性(潜在):由于是基于内容的寻址,一旦一个函数的内容被存储,其地址就是固定的。这为实现一种隐式的函数版本控制提供了基础,保证了特定地址总是指向同一份代码,从而提高了代码执行的确定性和可复现性。
产品使用案例
· 微服务架构下的函数发现:在一个分布式系统中,不同的微服务可能贡献各种功能函数。Ouveture.py 可以作为服务的注册中心,将各个服务提供的函数以内容寻址的方式存储,当需要某个功能时,直接通过功能内容的哈希值去查找,而无需关心具体是哪个服务提供的。
· 插件化系统:开发一个支持插件的应用程序时,Ouveture.py 可以用来管理和加载插件提供的函数。插件的安装和卸载只涉及函数的注册和移除,而应用程序在调用插件功能时,只需知道插件功能的“内容地址”,无需关心插件的具体文件路径。
· 代码审计与复用:在大型代码库中,Ouveture.py 可以帮助开发者发现重复的代码片段(即功能相同的函数),并统一管理,促进代码复用,减少冗余,提升整体代码质量。
· CI/CD 流程中的函数部署:在持续集成和持续部署的流程中,Ouveture.py 可以用于管理和分发不同阶段需要的函数模块。每个函数版本都对应一个唯一的地址,确保部署时使用的是正确的函数版本,避免了因配置错误或文件覆盖导致的问题。
57
RAGSyntheticDataGen
作者
scosman
描述
这是一个用于生成合成数据的工具,专门用来评估那些利用检索增强生成(RAG)技术的AI应用。它通过模拟真实世界的数据场景,帮助开发者更有效地测试和优化RAG系统的表现,解决RAG在真实数据匮乏时的评估难题。
人气
点赞 2
评论数 0
这个产品是什么?
RAGSyntheticDataGen 是一个利用编程方式创造假数据(合成数据)的工具,目的是为了帮助那些使用了检索增强生成(RAG)技术的AI项目。RAG技术就像给AI一个“外部大脑”,让它能通过搜索信息来回答问题,而不是只依赖于自己训练时学到的知识。但问题是,测试RAG的效果需要大量真实世界的数据,而这些数据往往很难获得。这个工具就能自己“编造”出符合各种复杂情况的数据,比如提问方式不同、信息来源多样等,从而更全面地测试RAG AI的“阅读理解”和“信息整合”能力。它的创新之处在于,它不是简单地生成随机数据,而是有针对性地模拟RAG系统可能遇到的各种挑战,让开发者能够提前发现潜在的问题。
如何使用它?
开发者可以将RAGSyntheticDataGen集成到他们的AI开发流程中。首先,他们可以配置生成器的参数,比如指定希望模拟的数据类型(例如,新闻文章、技术文档、客服对话等)、提问的风格(简单直接、复杂含糊、包含歧义等),以及RAG系统需要参考的信息源的特点。然后,工具会根据这些设置生成大量的文本数据对(例如,问题-答案对,或者问题-上下文-答案对)。开发者可以将这些合成数据用于训练、测试和评估他们的RAG模型。比如,可以用来检查RAG在面对错误信息、过时信息或者信息不全时,是否还能给出准确的答案。
产品核心功能
· 定制化数据生成:开发者可以根据RAG应用的具体需求,灵活配置生成数据的类型、主题、复杂度和提问方式,这使得测试数据更加贴近实际应用场景,让测试结果更具参考价值。
· 多样的信息源模拟:工具能够模拟不同来源、不同格式的信息,这有助于测试RAG系统在面对信息来源多样化时的鲁棒性,避免AI在实际应用中因为信息来源问题而表现不稳定。
· 错误和挑战数据注入:可以生成包含错误信息、歧义或不完整信息的数据,帮助开发者发现RAG系统在处理不确定或有缺陷信息时的弱点,提前进行优化,提升AI的可靠性。
· 评估指标生成:除了数据本身,工具还能辅助生成用于评估RAG性能的指标,比如答案的准确性、召回率(是否找到了相关信息)等,量化AI的表现,便于开发者追踪改进效果。
· 可脚本化集成:该工具设计为易于在开发者的自动化测试流程中调用,允许通过脚本执行,这大大提高了测试效率,使得模型迭代和优化过程更加敏捷。
产品使用案例
· 一个开发智能客服AI的团队,他们需要测试RAG系统是否能准确理解用户的各种提问方式,即使提问方式含糊不清或包含一些不相关的词语。他们使用RAGSyntheticDataGen生成了大量带有模糊性、口语化表达的问题,并将其与客服常见问题解答数据库结合,来训练和测试他们的RAG模型,结果发现RAG在面对复杂提问时的准确率显著提升。
· 一家内容推荐平台,希望通过RAG技术让AI能根据用户浏览历史推荐相关文章,但缺乏足够的数据来测试RAG的推荐效果。他们利用RAGSyntheticDataGen模拟不同用户兴趣和浏览行为,生成大量的“用户-文章”关系数据,并用来验证RAG模型能否有效地抓取文章中的关键信息,从而做出更精准的推荐。
· 一个构建法律咨询AI的初创公司,面临着如何测试RAG系统在处理大量专业法律文献中的准确性的挑战。他们使用RAGSyntheticDataGen模拟了不同法律条款、判例和相关概念之间的复杂关联,并生成了大量的法律咨询问题。这使得他们能够在一个可控的环境下,对RAG系统进行严格的压力测试,确保其在真实法律咨询场景下的可靠性。
· 一个AI语言学习工具的开发者,希望确保RAG系统在回答用户语法或词汇问题时,不仅提供正确答案,还能解释背后的原因。他们利用RAGSyntheticDataGen生成了包含多种语法错误和词汇误用的句子,并让RAG系统来识别和解释这些错误,从而提升了AI的教学辅助能力。
58
CodeMode: LLM代码执行模式
作者
juanviera23
描述
CodeMode 是一个新颖的库,它将大型语言模型(LLM)与工具的交互方式从传统的“工具调用”转变为“代码执行”。通过让LLM直接编写和执行TypeScript代码来完成任务,CodeMode显著提高了效率,减少了对Token(LLM处理信息的单位)的消耗,并且让本地部署的LLM也能更稳定可靠地工作。这就像是给了LLM一把万能钥匙,让它自己写程序来开锁,而不是让它去挑选预设的几把钥匙。
人气
点赞 2
评论数 0
这个产品是什么?
CodeMode 是一个创新的库,它改变了LLM(比如AI助手)与外部工具(比如发送邮件、查询天气)交互的方式。传统上,我们会告诉LLM“请使用发送邮件工具,收件人是XXX,主题是YYY”,就像是在给它一份说明书。CodeMode则更进一步,它让LLM自己编写一小段TypeScript代码来完成这个任务。这段代码在安全的沙箱环境里运行,可以访问与工具相同的接口。这样做的好处是,LLM能更精确地理解任务,一次性生成正确的代码来完成,避免了多步沟通和试错,大大降低了AI的“思考成本”(Token消耗),也让本地运行的AI模型表现更出色。
如何使用它?
开发者可以将CodeMode集成到自己的应用中。当你的应用需要LLM执行某个复杂任务,并且可以通过编写代码来完成时,就可以使用CodeMode。例如,你想让一个AI助手能够根据用户指令自动分析数据并生成报告。你不需要给AI一个包含“数据分析工具”和“报告生成工具”的列表,而是提供一个CodeMode的接口,让AI直接编写一段TypeScript代码,这段代码负责读取数据、进行计算,并将结果输出。它非常适合那些任务可以通过编写脚本一步到位的场景,可以作为LLM agent框架的一部分,来增强LLM的任务执行能力。
产品核心功能
· LLM直接生成可执行代码:让AI写代码解决问题,而非仅仅调用预设功能,这是其核心的创新,使得AI能更灵活、精确地完成复杂指令。
· TypeScript沙箱执行环境:提供一个安全的环境来运行AI生成的代码,确保AI的行为可控,防止恶意代码执行,保障了系统的安全性。
· 统一的工具接口访问:AI生成的代码可以访问与传统工具调用相同的接口,这意味着现有的工具和服务仍然可以被LLM通过代码来调用,实现了平滑过渡和功能复用。
· Token消耗优化:通过一次性代码执行替代多步的工具调用和试错,显著减少了LLM在处理任务时消耗的Token,从而降低了运行成本并提高了响应速度。
· 提升本地LLM可靠性:对于在本地运行的AI模型,CodeMode的精确代码生成能力使其能够更稳定、可靠地完成任务,克服了本地模型在理解复杂指令时的局限性。
产品使用案例
· AI助手自动处理日程安排:用户说“帮我预定明天下午两点的会议,参会者是张三和李四”,AI可以直接生成一段TypeScript代码,调用日历API创建会议,并自动添加参会者,而不是需要多次沟通确认。
· 数据分析与可视化脚本生成:在一个数据分析工具中,用户输入“分析这份销售数据,找出同比增长率最高的月份,并生成柱状图”,LLM可以生成一段代码,利用数据分析库进行计算,并调用图表库生成可视化结果。
· 自动化内容生成与发布:一个内容创作平台可以让AI根据用户指定的关键词和风格,生成一篇文章,并直接生成一段代码,将文章发布到博客或社交媒体,全程无需人工干预。
· 构建更智能的AI Agent:开发者可以将CodeMode作为AI Agent的核心组件,让Agent能够根据外部环境的变化,动态生成和执行代码来适应和解决问题,比如自动调整服务器配置以应对流量高峰。
59
Insave Export: 一键导出Instagram收藏
url
作者
qwikhost
描述
Insave Export 是一个简洁的工具,它能让你轻松下载Instagram上所有你收藏(saved)的照片和视频。它的技术核心在于绕过了Instagram复杂的API限制,直接解析用户界面数据,实现了无需复杂操作就能批量导出收藏内容,解决了用户希望永久保存或备份Instagram精彩瞬间的痛点。
人气
点赞 1
评论数 1
这个产品是什么?
Insave Export 是一个技术巧妙的浏览器扩展或独立脚本,它能够自动化地浏览你的Instagram收藏夹,并将里面的图片和视频下载到你的电脑上。普通用户在Instagram上收藏内容后,想要批量下载是很困难的,因为Instagram官方并没有提供这个功能,而且直接使用API下载也需要一定的技术门槛。Insave Export 的创新之处在于,它不是通过官方API,而是通过模拟用户在浏览器中的行为,读取网页上的图片和视频链接,然后进行下载。这种方式非常“黑客”,用最直接、最有效的方式解决了用户的问题。
如何使用它?
开发者可以通过克隆Insave Export的GitHub仓库,然后按照项目中的说明进行安装和配置。如果是浏览器扩展版本,通常是将其加载到Chrome或Firefox等浏览器中,然后登录你的Instagram账号,访问收藏页面即可触发导出。如果是命令行工具,可能需要安装Node.js等运行环境,然后在终端执行相关命令来启动导出过程。它可以集成到你的个人备份脚本中,或者作为你管理社交媒体资产的辅助工具。
产品核心功能
· 一键批量下载Instagram收藏内容:核心技术是解析网页数据,能快速定位并下载所有收藏的图片和视频,解决了手动保存效率低的问题。
· 支持多种媒体格式:能够处理Instagram上的照片(JPEG, PNG)和视频(MP4),确保用户能够获取到所有类型的收藏媒体。
· 无需复杂API操作:利用了非官方的解析技术,避免了开发者需要理解和实现复杂的Instagram API,大大降低了使用门槛。
· 自动化导出流程:通过模拟用户行为,实现自动化下载,省去了用户逐个点击保存的繁琐步骤,提升了用户体验。
产品使用案例
· 个人数字资产备份:当你担心Instagram账号有一天会丢失,或者想要永久保存一些重要的灵感图片和视频时,Insave Export可以帮助你一次性导出所有收藏,妥善备份。
· 内容创作者的素材收集:如果你是内容创作者,经常在Instagram上收藏一些设计灵感、摄影作品或视频素材,Insave Export可以快速帮你收集整理这些素材,为你的创作提供源源不断的灵感。
· 自动化内容管理脚本:有技术经验的开发者可以将Insave Export集成到自己的脚本中,实现定期的Instagram收藏内容自动备份,省时省力。
· 隐私保护和数据所有权:通过导出收藏,用户能够掌握自己数据的真正所有权,不再依赖于平台,即使Instagram修改规则,你的收藏数据依然安全可控。
60
AI管家·云端执行器
作者
trou3
描述
Gumpbox 是一个让AI(比如ChatGPT、Claude)直接管理你的Linux服务器的Mac应用。它解决了开发者需要频繁在本地输入复杂命令行来部署应用、重启服务、检查服务器状态等痛点,让你能像聊天一样,用自然语言和AI沟通,让AI帮你完成这些任务。其核心技术亮点在于 MCP(模型上下文协议),它在本地Mac上运行一个服务器,安全地连接AI和你的服务器,确保敏感信息不外泄,并且通过沙盒技术(systemd-run)保障AI操作的安全性。
人气
点赞 1
评论数 0
这个产品是什么?
Gumpbox是一个Mac应用,它充当了AI智能助手(如ChatGPT、Claude)和你的Linux服务器之间的桥梁。它的技术原理是,在你的Mac上运行一个叫做MCP(模型上下文协议)的小服务器。这个MCP服务器负责理解AI的指令,然后将这些指令转换成能在你的Linux服务器上执行的命令。这样做的好处是,你不需要再费力去记忆和输入那些复杂的Linux命令,可以直接用聊天的方式告诉AI你想要做什么,比如‘部署最新版本的应用到生产环境’,Gumpbox就会自动处理后续的命令执行。最重要的是,MCP服务器是运行在你自己的Mac上的,所以你的服务器登录凭证和敏感信息永远不会离开你的电脑,大大提高了安全性。
如何使用它?
作为开发者,你可以下载Gumpbox应用安装在你的Mac上。首先,你需要配置Gumpbox,告诉它你的Linux服务器的连接信息(IP地址、用户名等),以及允许它访问的AI模型(如OpenAI的ChatGPT或Anthropic的Claude)。一旦配置完成,你就可以打开Gumpbox的聊天界面,用自然语言向AI下达指令。例如,你可以输入‘检查一下API服务的内存使用情况’,Gumpbox就会将这个请求发送给AI,AI理解后通过MCP服务器在你的Linux服务器上执行相应的命令(如`top`或`htop`),并将结果反馈给你。你可以用它来部署新代码、重启宕机服务、查看日志文件、监控服务器健康状况等,就像拥有一个24/7待命的技术助理一样。
产品核心功能
· AI驱动的服务器命令执行:通过自然语言对话,AI可以理解你的意图并执行相应的Linux命令,大大简化了远程服务器管理,让你可以专注于更高层级的开发工作,而不是被琐碎的命令所困扰。
· 模型上下文协议(MCP)服务器:在本地Mac上运行,安全地连接AI与你的服务器,确保服务器凭证等敏感信息绝不离开你的本地机器,解决了远程管理中的关键安全痛点。
· 安全沙盒执行:利用systemd-run等技术,AI执行的命令被限制在安全的沙盒环境中,防止潜在的恶意操作或意外错误影响到你的整个系统,为你的服务器提供了一层额外的安全保障。
· 多AI模型兼容性:支持连接包括ChatGPT和Claude在内的多种主流AI模型,你可以选择你最熟悉或最适合特定任务的AI,增加了灵活性和可选项。
· 一对一代码兑换试用:提供免费的兑换码供用户试用,降低了尝试新技术的门槛,鼓励开发者社区积极探索AI在服务器管理中的应用可能性。
产品使用案例
· 开发场景:一名后端开发者需要在发布新功能前,将最新代码部署到测试服务器。过去,他需要SSH登录服务器,然后手动执行一系列Git拉取、构建和重启服务的命令。现在,他只需要在Gumpbox中输入‘将最新代码部署到staging环境’,Gumpbox就会自动完成这些操作,大大节省了时间,降低了出错的风险。
· 运维场景:服务器突然出现响应缓慢的情况,负责的工程师需要快速定位问题。过去,他可能需要立即登录服务器,使用`top`、`htop`、`dmesg`等命令来排查。现在,他可以直接问Gumpbox‘为什么API服务的CPU占用率这么高?’,AI会理解并执行相应的命令,迅速给出可能的原因,帮助工程师快速诊断和解决问题。
· 远程团队协作:一个小型创业团队负责维护一个网站。团队成员可能分布在不同时区,并且对Linux命令的熟练程度不一。Gumpbox允许任何熟悉自然语言的成员通过AI来管理服务器,即使他们不精通命令行,也能参与到基本的部署和监控工作中,提高了团队的协作效率和灵活性。
61
语境数据探秘者 (Contextual Data Explorer)
作者
mardel
描述
这个项目是一个智能的“对话式商业智能代理”,它能让非技术背景的业务用户直接和他们的数据“对话”。它解决了企业中数据团队花费大量时间准备数据,但业务用户最终看到的仍然是静态报告,并且常常有更多疑问的痛点。通过这个代理,用户可以直接提问,探索数据,发现隐藏的洞察,甚至在返回给数据分析师之前就能迭代想法。对于还没有专门数据团队的公司,它也能帮助他们快速从数据中获益。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个基于自然语言的智能数据分析工具。它的核心技术在于将复杂的数据库查询和数据处理过程,通过一个易于理解的对话界面呈现给用户。它使用了先进的自然语言处理(NLP)技术来理解用户的提问,然后将其转化为数据查询语句,从数据库中提取信息。最创新的地方在于,它不仅仅能回答简单的问题,还能理解上下文,让用户可以进行多轮次的深入探讨,就像和一位数据专家聊天一样。所以,这就像是给你的数据装上了一个“会说话”的翻译官,让你不再需要懂技术也能理解和利用数据。
如何使用它?
开发者可以将这个代理集成到现有的业务系统或内部平台上。通过API接口,可以连接到企业的各种数据源,如数据库(SQL)、数据仓库等。用户就可以通过一个简单的聊天窗口,输入他们想了解的问题,比如“上个季度哪个产品的销量最高?”或者“与去年同期相比,新客户增长了多少?”。代理会解析这些问题,并返回相应的图表、表格或文字解释。所以,这意味着你的团队成员,无论懂不懂编程,都能快速获得他们需要的数据支持,大大提高工作效率。
产品核心功能
· 自然语言查询数据:用户用日常语言提问,系统能理解并转化为数据查询。价值:降低数据获取门槛,让非技术人员也能直接访问数据。场景:业务人员快速了解销售情况、营销效果等。
· 多轮对话与上下文理解:系统能记住之前的对话内容,支持连续提问和深入探索。价值:实现更深层次的数据挖掘,而不是仅停留在表面回答。场景:用户在发现一个趋势后,可以继续追问原因。
· 自动生成洞察与可视化:根据用户的问题,系统不仅能提供数据,还能自动生成图表和提炼关键洞察。价值:让数据分析结果更直观易懂,节省人工制作图表的时间。场景:快速生成月度销售报告的概览。
· 数据准备预处理:对数据进行必要的清洗和整理,使其更易于被查询和理解。价值:提升数据查询的准确性和效率,减少数据质量问题。场景:确保不同来源的数据能够被统一分析。
· 用户引导与推荐:主动推荐可能感兴趣的数据洞察或分析方向。价值:帮助用户发现潜在的价值,激发新的分析思路。场景:系统发现某个地区销售额异常增长,并主动提示用户关注。
产品使用案例
· 一位市场营销经理想要了解某个推广活动的效果。他可以直接问:“这次线上广告活动带来的新增用户有多少?他们主要来自哪些城市?”,而不是等待数据分析师制作报告。这个代理可以直接给出精准的数据和可视化图表。解决了数据获取慢、报告滞后问题。
· 一家电商公司的销售团队想知道哪类产品的库存可能不足。他们可以问:“过去一周哪些产品的销量增长了50%以上,但库存低于100件?”,代理会立刻找出这些产品。解决了需要人工交叉比对多个数据表格的问题。
· 一个新成立的数据团队,还没有完善的BI系统,但需要快速了解业务状况。他们可以将现有的客户数据连接到代理,然后直接通过对话了解客户的地域分布、购买习惯等。解决了数据基础薄弱但急需数据支持的问题。
· 一位产品经理在设计新功能时,想了解用户对现有某个功能的使用频率和反馈。他可以直接提问:“过去一个月,使用‘用户反馈’功能的用户比例是多少?他们最常反馈的问题是什么?”,从而为产品迭代提供数据支撑。解决了传统BI工具无法快速响应产品迭代需求的问题。
62
Crane: macOS 本地化容器管理利器
作者
glsorre
描述
Crane 是一个为 macOS 用户量身打造的本地容器管理应用。它提供了一个直观的图形界面,让开发者能够轻松地管理本地运行的 Docker 容器,而无需深入命令行。其核心创新在于将复杂的容器操作封装在用户友好的界面中,极大地降低了 macOS 用户使用容器技术的门槛,尤其适合那些希望快速上手、高效管理本地开发环境的开发者。
人气
点赞 1
评论数 0
这个产品是什么?
Crane 是一个运行在 macOS 上的原生应用,专门用来管理你的本地 Docker 容器。想象一下,你不用再记住一长串复杂的命令行指令,比如 'docker ps'、'docker stop'、'docker rm' 等等,而是可以通过一个漂亮、简洁的界面来看到你所有正在运行的容器,一键就能启动、停止、删除或者查看容器的日志。它的技术核心是利用 macOS 的原生 UI 框架(如 SwiftUI)来构建用户界面,并通过 Docker 的 SDK (Software Development Kit) 与本地安装的 Docker Desktop 进行通信,实现对容器的控制。这意味着它不是一个 Docker 的替代品,而是 Docker 的一个图形化“遥控器”,让 macOS 用户能够更方便地与 Docker 这个强大的容器化工具互动。所以这对我有什么用?它让你在 macOS 上管理 Docker 容器变得像使用其他 Mac 应用一样简单直观,省去了学习和记忆命令行的麻烦,让你能更快地投入到开发工作中。
如何使用它?
开发者只需要在 macOS 上安装 Crane 应用,并确保你的 Mac 上已经安装了 Docker Desktop。Crane 会自动连接到你的 Docker Desktop 环境。然后,你就可以在 Crane 的界面中看到所有本地正在运行的容器、已停止的容器,以及镜像列表。你可以直接点击按钮来启动、停止、重启容器,查看容器的详细信息和日志输出,甚至可以新建一个容器或者删除不再需要的容器。它还可以帮助你导入或导出容器镜像,方便在不同环境间迁移。所以这对我有什么用?一旦安装,它就像一个智能助手,让你用鼠标点击就能完成之前需要敲很多命令才能实现的操作,极大地提高了开发效率,尤其是在需要频繁管理多个容器进行开发测试时。
产品核心功能
· 容器列表可视化管理:Crane 会以清晰的列表形式展示所有本地容器的状态(运行中、已停止等),并提供简单的图标指示,让你一目了然。这让你无需通过命令就能快速了解当前容器环境的整体情况,减少了信息遗漏的风险。
· 一键式容器操作:对于每个容器,Crane 提供启动、停止、重启等常用操作按钮。这极大地简化了容器生命周期的管理,让你能够快速响应开发需求,例如需要重新启动某个服务进行测试。
· 实时日志查看:你可以直接在 Crane 应用内查看容器的实时日志输出,而无需额外打开终端窗口。这对于排查问题非常有用,能够帮助你快速定位代码错误或者服务异常。
· 镜像管理:Crane 还能帮助你管理本地的 Docker 镜像,包括列出所有镜像、删除不需要的镜像。这有助于清理本地磁盘空间,保持开发环境的整洁。
· 容器网络和端口信息展示:Crane 会清晰地展示容器的网络模式、映射的端口等信息,让你能够清楚地知道容器是如何与其他服务交互的,方便进行网络相关的配置和调试。
· 原生 macOS 用户体验:Crane 遵循 macOS 的设计规范,提供流畅、直观的用户界面,与你常用的 Mac 应用使用感受一致。这意味着它上手简单,学习成本低,能让你更快地投入使用。
产品使用案例
· 在本地开发 Web 应用时,开发者通常需要启动数据库容器、后端 API 容器、前端开发服务器容器等多个服务。使用 Crane,开发者可以一眼看到所有这些容器的运行状态,并可以一键启动所有依赖服务,或者在某个服务出现问题时快速重启它,而无需在多个终端窗口中执行命令。
· 对于刚开始接触 Docker 的 macOS 用户,Crane 提供了极低的入门门槛。他们可以通过 Crane 直观的界面学习和理解容器的基本概念和操作,例如如何运行一个简单的 Nginx 容器,如何查看它的日志,而不用担心记住复杂的命令行语法。
· 在进行 CI/CD (持续集成/持续部署) 相关的本地测试时,开发者可能需要频繁地创建、销毁和管理测试环境中的容器。Crane 的批量操作和快速启动/停止功能,能够显著缩短测试环境的准备和清理时间,提高开发迭代的速度。
· 当一个容器出现异常,日志输出非常重要。Crane 内置的日志查看功能,可以直接在应用内滚动查看实时日志,并方便地复制错误信息,这比在终端中频繁滚动查找日志效率要高得多,能帮助开发者更快地定位和解决 bug。
63
HomeDeck Affirmations
作者
vasanthps
描述
HomeDeck Affirmations 是一个将积极心理暗示(Affirmations)直接展示在iPhone、iPad和Mac主屏幕上的应用。它解决了用户希望日常生活中能持续接收到积极提醒,但又不想被过度打扰的问题。通过在主屏幕上集成动态展示的积极语录,让用户在不打开应用的情况下,随时随地都能获得正能量,提升个人成长。
人气
点赞 1
评论数 0
这个产品是什么?
HomeDeck Affirmations 是一个利用操作系统原生功能(如iOS的“小组件”或macOS的“桌面小组件”)将精心挑选的积极心理暗示语录,直接显示在设备主屏幕上的应用。它的创新之处在于,它不仅仅是提供一个静态的语录列表,而是允许用户自定义刷新频率、选择语录类别,甚至可以设置在特定时间出现特定的语录。这意味着用户无需主动打开应用,就能在日常使用手机、平板或电脑时,潜移默化地接收到积极的心理暗示,帮助用户保持良好的心态,促进个人成长。这就像给你的设备“装上”了一个私人心理教练,随时随地给予你鼓励。
如何使用它?
开发者可以使用HomeDeck Affirmations,通过集成其提供的API或WidgetKit(针对iOS/iPadOS)/AppKit(针对macOS)功能,将积极语录组件添加到他们的应用程序中。用户可以在主屏幕上添加HomeDeck Affirmations小组件,然后通过应用内的设置,选择自己喜欢的语录主题(如自信、感恩、成长等),或者自定义要显示的语录。用户还可以设定语录的更新频率(例如每小时、每天),甚至可以将某个特定语录固定在屏幕上。这意味着,你的用户可以在使用你其他应用的同时,也能不经意间看到激励人心的信息,从而提升用户在整个设备使用过程中的正面体验。
产品核心功能
· 动态展示积极语录:通过操作系统的原生小组件功能,将精选的积极语录实时推送到用户的主屏幕,让用户在日常操作中获得持续的心理正反馈,提升用户体验和情绪状态。
· 语录内容定制:允许用户选择或自定义要展示的积极语录,满足个性化需求,让用户获得更贴合自身情况的心理支持,解决用户“我需要什么样的话来激励我”的困惑。
· 刷新频率控制:用户可以设定语录的更新时间间隔,确保信息的新鲜度和不打扰性,让用户在需要时看到新的鼓励,同时避免信息过载,提升用户控制感。
· 跨平台支持:支持iPhone、iPad和Mac,让用户在不同设备上都能享受到一致的积极心理暗示体验,无论用户使用何种设备,都能获得不间断的精神支持。
· 简洁无干扰设计:应用的界面设计以“无干扰”为核心,确保积极语录的展示不会分散用户的注意力,让用户能专注于当下任务的同时,也能接收到积极的信息,这是对用户注意力宝贵性的尊重。
产品使用案例
· 在健身App中集成,用户在锻炼间隙或开始前,主屏幕就能展示鼓励用户坚持的语录,帮助用户保持运动动力。解决了用户“开始锻炼太难了”、“中途容易放弃”的问题。
· 在学习App中集成,用户在学习过程中,看到关于“坚持”、“成长”的语录,能够帮助用户克服学习疲劳和挫败感,提升学习效率。解决了用户“学习枯燥”、“遇到困难想放弃”的问题。
· 在健康生活App中集成,用户在日常生活中,主屏幕定时弹出关于“感恩”、“自我关爱”的语录,帮助用户培养积极的生活态度,提升幸福感。解决了用户“生活压力大”、“容易焦虑”的问题。
· 作为一款独立的心理健康支持工具,让用户无需记住复杂的口令或打开特定应用,就能在每天的主屏幕上获得持续的积极心理暗示,帮助用户培养健康的心理习惯。解决了用户“没有时间和精力做心理建设”、“希望有一个简单易用的心理支持工具”的需求。
64
视觉辨识:抹茶与沼泽
作者
fragkakis
描述
这是一个利用计算机视觉技术,通过AI模型来区分抹茶和沼泽水颜色外观的趣味项目。它解决了用户在视觉上难以区分这两种容易混淆的绿色液体的问题,展示了AI在图像识别领域的应用潜力。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个基于机器学习的图像识别项目,它训练了一个AI模型来分析图像中特定颜色的模式,从而区分出抹茶和沼泽水。简单来说,就是让电脑学会分辨哪种绿色是美味的抹茶,哪种绿色是令人避之不及的沼泽。其创新之处在于,它将一个看似主观的视觉区分问题,转化为一个可以通过数据和算法解决的技术挑战,并且使用了能够处理细微颜色差异的深度学习技术。
如何使用它?
开发者可以将这个项目作为一个独立的API服务来使用,通过将抹茶或沼泽水的图片上传到这个服务,就可以得到一个判断结果,告诉用户这是抹茶还是沼泽水。也可以将其集成到其他应用中,比如一个健康饮食助手,用来提示用户他们购买的绿色饮品是否真的是抹茶;或者一个户外探险助手,帮助用户识别潜在的危险水源。其使用方式就像调用一个图片分类服务一样简单。
产品核心功能
· 图像颜色分析:核心技术是利用深度学习模型分析输入图片的颜色特征,找出区分抹茶和沼泽水关键的颜色细微差别,其价值在于能够量化主观的视觉判断。
· AI模型训练:项目通过大量带有标签的抹茶和沼泽水图片进行训练,让AI学习区分的模式,价值在于构建了一个能够处理特定视觉识别任务的智能系统。
· 结果输出:根据AI模型的分析,输出明确的判断结果(抹茶或沼泽水),为用户提供直接的答案,价值在于将复杂的AI分析转化为易于理解的输出。
产品使用案例
· 场景:一个线上食品评论App。开发场景:用户上传一杯饮品的图片,想知道它是不是真的抹茶。技术问题:普通用户难以准确判断饮品的色泽,容易被误导。解决方案:集成“抹茶或沼泽水”项目,通过AI分析图片色泽,给出是否为抹茶的建议,避免用户购买到色泽不纯的饮品。
· 场景:一个科普教育网站。开发场景:网站需要一个互动小游戏,让用户测试自己的颜色辨识能力,并了解AI在图像识别方面的能力。技术问题:如何创建一个有趣且具有教育意义的互动体验。解决方案:利用该项目,让用户猜测图片是抹茶还是沼泽水,然后由AI给出正确答案,并通过解释AI的识别原理,提升用户对AI技术的认知。
65
语翼·AI英语炼金师
作者
baursha
描述
一个利用AI技术驱动的个性化英语学习工具,通过分析用户文本,智能生成练习内容,帮你更高效地掌握英语。它解决了传统英语学习中内容枯燥、缺乏针对性等痛点,通过AI的“炼金术”,将普通文本转化为有价值的学习材料。
人气
点赞 1
评论数 0
这个产品是什么?
语翼·AI英语炼金师是一个基于AI的智能英语学习助手。它的核心技术在于利用自然语言处理(NLP)和机器学习模型,能够深入理解用户输入的文本(比如一篇文章、一段对话),然后根据用户的英语水平和学习目标,智能地拆解、重组、解释这些文本中的词汇、语法和表达方式。比如,它可以识别生词,提供多种同义词或近义词;可以分析句子结构,解释复杂的语法点;还可以提炼出地道的表达方式,生成相关的练习题(如填空、选择、改错等),帮助用户在实际应用中巩固和提升。这就好像一个经验丰富的英语老师,但它能7x24小时随时待命,而且能为你量身定制学习方案。
如何使用它?
开发者可以将语翼·AI英语炼金师集成到自己的学习应用、内容平台或者作为独立的学习辅助工具。通过API接口,开发者可以将用户的文本内容(例如,一段来自英文新闻的文章、一段电影台词)发送给语翼。语翼会返回一个包含分析结果和生成练习的结构化数据,开发者再将这些信息展示给用户。这可以极大地丰富现有产品的学习功能,提升用户留存率和学习体验。例如,一个博客平台可以集成语翼,让用户阅读英文文章时,点击不认识的词就能看到AI生成的解释和例句,或者一键生成与文章相关的词汇测试。
产品核心功能
· AI生词本与释义:识别用户文本中的生词,并提供详细的解释、词根词缀分析、多样的同义词/近义词以及原生的例句,让你真正理解词汇的用法,而不仅仅是死记硬背。
· 语法解析与纠错:自动分析句子结构,解释复杂的语法点,并能识别出潜在的语法错误,提供精确的修改建议,帮助你理解为何出错,从而避免重复犯错。
· 地道表达提取与训练:从用户文本中挖掘出地道的英文表达和俚语,并生成相关的练习,让你学会像母语者一样思考和表达。
· 个性化练习生成:根据用户的学习进度和薄弱环节,自动生成多种形式的练习题(如填空、选择、匹配、造句),确保练习内容与用户的实际学习需求高度匹配。
· 文本内容深度挖掘:不仅仅是单词和语法,还能对文章的主题、观点、段落逻辑进行分析,生成相关的阅读理解或讨论话题,锻炼综合语言能力。
产品使用案例
· 为一款面向国际读者的科技新闻App开发一个“智能阅读助手”。用户在阅读英文科技文章时,可以一键调用语翼,实时获得文中专业词汇的精准解释、复杂句子的拆解,以及相关的背景知识提示。这使得非母语用户也能顺畅阅读,解决因为技术术语和复杂句式造成的阅读障碍。
· 为一个语言学习社区构建一个“AI写作教练”。用户提交英文作文后,语翼能对文章的词汇使用、语法准确性、逻辑连贯性进行深度分析,并生成个性化的反馈报告和改进建议,帮助用户提升写作水平。这解决了社区内反馈效率低、缺乏专业指导的问题。
· 集成到一个面向外教的英语教学平台,帮助外教快速备课。外教可以将一段教学素材(如新闻、电影片段)导入语翼,AI会快速生成该素材的词汇表、语法难点解析、以及配套的课堂练习题,极大地节省了外教的备课时间,同时保证了教学内容的专业性和趣味性。
· 为一个出海游戏的客服团队开发一个“英文沟通辅助工具”。客服人员在与海外玩家沟通时,可以将遇到的英文问题或想要表达的内容输入语翼,AI能提供更地道、更准确的英文回复建议,甚至能根据玩家的情绪提供更合适的表达方式,提升沟通效率和用户满意度。
66
PluginScore: WordPress插件代码体检官
作者
blurayfin
描述
PluginScore 是一个创新性的在线工具,它能够对WordPress.org上的任何插件进行快速而深入的代码质量分析。通过一个简单的网址输入,就能生成包含安全、性能、仓库政策和编码标准等维度的详细报告,并提供一个直观的分数。这解决了开发者和用户在评估插件质量时信息不对称、难以直观判断的问题,极大地降低了插件选择和维护的门槛。
人气
点赞 1
评论数 0
这个产品是什么?
PluginScore是一个专门为WordPress插件设计的代码质量分析平台。它利用自动化扫描技术,深入检查插件的源代码,评估其在安全性、性能、是否符合WordPress官方仓库政策以及通用的编码规范等方面的表现。其核心创新在于将复杂的代码分析结果,转化为一个易于理解的0-100分数,并细化为各个类别的错误和警告数量,同时提供详细的问题列表和历史趋势。所以,它让不懂代码的用户也能快速了解一个插件的好坏,让开发者能更精确地定位和修复代码问题。
如何使用它?
开发者或WordPress用户只需访问PluginScore网站,在首页的“Analyze a plugin”框中输入目标插件在WordPress.org上的唯一标识符(slug),例如“akismet”或“woocommerce”。网站将自动启动一次代码扫描。扫描完成后,将生成一个详细的报告页面,展示插件的整体分数、各项具体指标(如安全、性能等)的表现,以及详细的错误和警告列表。用户可以通过查看历史扫描记录和分数变化,追踪插件质量的改进或退化。它还可以方便地集成到开发流程中,作为CI/CD管道的一部分,持续监控插件质量。所以,这就像给插件做了一次体检,让你一眼就知道它健不健康,哪里需要加强。
产品核心功能
· 代码质量整体评分:将复杂的代码分析结果量化为一个0-100的分数,让用户快速感知插件的整体健康度,所以这对我来说,就是插件好坏的直观指标。
· 多维度质量分析:细分安全、性能、仓库政策、通用编码标准和可访问性等关键维度,帮助用户了解插件在不同方面的具体表现,所以这有助于我深入了解插件的优缺点。
· 详细问题列表与根源分析:列出具体的代码错误和警告,附带代码片段、严重程度和相关规则文档链接,方便开发者精准定位和修复问题,所以这能帮我更快地找到并解决代码中的bug。
· 历史扫描与分数趋势:记录插件每次扫描的分数和变化,可视化展示插件质量随时间的变化,帮助开发者追踪改进效果或发现潜在的退化,所以这让我能看到插件的成长轨迹。
· 仓库政策合规性检查:确保插件符合WordPress.org官方插件库的发布要求,减少被拒绝或下架的风险,所以这能保证我的插件能顺利发布上线。
· 性能瓶颈初步诊断:通过代码层面的分析,为插件性能优化提供线索,所以这能帮我提升插件的运行速度。
产品使用案例
· 一个WordPress主题开发者在发布新插件前,使用PluginScore进行代码质量扫描。通过报告发现了一个潜在的安全漏洞和几个影响性能的代码模式,及时修复后,提交到WordPress.org审核,大大提高了插件的通过率和用户体验。所以,这帮助我避免了因为低质量代码而导致的发布延误和用户投诉。
· 一位WordPress网站站长,在选择一个功能复杂的第三方插件时,利用PluginScore查看了几个候选插件的报告。他发现其中一个插件虽然功能强大,但代码质量较差,存在不少安全隐患和性能问题,于是选择了另一个代码质量更高的插件,从而保障了网站的安全性和运行效率。所以,这让我能够做出更明智的插件选择,保护我的网站安全。
· 一家WordPress插件开发公司,将其核心插件的分析报告集成到内部开发流程中。每次代码更新后,会自动触发PluginScore扫描,并记录分数变化。这使得团队能够持续监控代码质量,及时发现并纠正引入的新问题,保持插件的高质量标准。所以,这让我们开发团队能持续保证插件的优秀品质。
67
GrammarFlow: 文本纠错流
作者
GrammarChecker
描述
GrammarFlow 是一个基于算法的文本纠错工具,它不依赖于传统的语法规则库,而是通过深度学习模型来理解文本的上下文,从而提供更精准的语法、拼写、标点甚至是风格建议。它旨在帮助开发者和内容创作者快速提升文本质量,减少因语言错误带来的沟通障碍。
人气
点赞 1
评论数 0
这个产品是什么?
GrammarFlow 是一个智能的文本纠错器,它不像传统的语法检查器那样死板地对照规则,而是像一个真正懂得语言的人一样,通过分析你写的文字的整体意思来找出问题。它使用了先进的机器学习技术,特别是自然语言处理(NLP)中的模型,来理解词语的搭配、句子的结构以及你想表达的含义。所以,它的纠错能力更强,尤其是在处理一些模糊的、非典型的错误时,效果会比传统方法好很多。简单来说,它用‘理解’代替了‘比对’,让纠错更智能,解决的是‘让写出来的东西更地道、更专业’的技术难题。
如何使用它?
开发者可以将 GrammarFlow 集成到他们的应用程序中,比如文本编辑器、内容管理系统、博客平台、甚至是在线表单。你可以通过 API 的方式调用 GrammarFlow 的文本分析功能。例如,当用户在你的应用中输入一段文字后,你可以将这段文字发送给 GrammarFlow 进行分析,然后将返回的建议反馈给用户。这可以提升你产品的内容创作体验,让你的用户在写东西时更自信。比如,你可以把它集成到你的在线写作工具里,用户写完一篇文章,可以一键发送给 GrammarFlow 检查,发现并修正错误,让文章更完美。所以,这能让你为你用户提供一个‘更高质量的内容创作环境’。
产品核心功能
· 智能拼写检查:利用模型预测更可能出现的正确拼写,有效纠正细微的错别字,提高文本的准确性。
· 上下文语法纠错:基于深度学习模型理解句子结构和词语搭配,修正复杂的语法错误,如时态、语态、主谓一致等,让句子更符合语言习惯。
· 标点符号优化:通过分析文本的语气和逻辑,给出更恰当的标点符号使用建议,使文章表达更清晰流畅。
· 风格与流畅度建议:分析文本的整体风格,提供措辞优化、句子重组等建议,让文章读起来更自然、更地道。
· API 集成能力:提供易于集成的 API 接口,允许开发者将其快速嵌入到各种应用场景中,增强现有产品的文本处理能力。
产品使用案例
· 开发一个在线写作助手:用户在输入框输入文字,GrammarFlow 实时提供语法和拼写建议,让用户在写作过程中就能纠正错误,提高内容质量。
· 集成到博客发布平台:作者在发布文章前,通过 GrammarFlow 进行一次深度检查,确保文章没有低级错误,提升博文的专业度。
· 在论坛或社交媒体应用中增加文本优化功能:用户发表评论或帖子时,可以选择使用 GrammarFlow 优化文本,避免因错误表达引起误解,提升交流效率。
· 构建教育类应用:帮助学生练习写作,GrammarFlow 可以提供详细的纠错反馈,引导学生学习正确的语言表达方式,是学习过程中的得力助手。
68
ZenMoment: 极简隐私冥想引擎
作者
951560368
描述
ZenMoment 是一个专注于隐私和简洁的冥想与呼吸练习工具。它解决了市面上许多冥想应用过度收集用户数据、功能臃肿且需要注册登录的问题。该项目采用纯客户端技术,将所有数据存储在本地,不进行任何用户追踪,同时提供核心的冥想计时器和呼吸指导功能。对于开发者而言,它展示了一种在不牺牲用户体验的情况下实现高隐私性的技术思路。
人气
点赞 1
评论数 0
这个产品是什么?
ZenMoment 是一个完全运行在用户设备上的免费冥想应用,它的核心理念是“简单、隐私、无干扰”。与许多需要注册、收集个人数据、充满广告或订阅限制的冥想App不同,ZenMoment 让你打开就能用,所有冥想数据(如时长、完成次数)都只保存在你自己的浏览器本地存储里,没有任何服务器端数据收集。它通过Next.js 14实现了极快的首次加载速度(静态导出),即使在网络不佳的情况下也能快速启动。其技术亮点在于完全的客户端渲染和数据存储,这意味着你的冥想习惯永远是你的隐私,无需担心数据泄露或被用于分析。它还符合WCAG AAA无障碍标准,确保更多人能够轻松使用。
如何使用它?
开发者可以直接访问 zenmoment.net 来使用这个冥想工具。它提供了多种预设的冥想时长(1/3/5/10/15分钟),以及一个直观的4-7-8呼吸练习引导,通过视觉提示帮助用户调整呼吸节奏。应用还支持暗色模式,适合夜间使用。由于其设计理念,它在首次加载后即可离线使用,并且不会弹出任何通知打扰你的冥想过程。对于希望在自己的项目中集成类似隐私友好型功能的开发者,可以参考其使用Next.js 14、TypeScript、Tailwind CSS、Zustand(一个轻量级的状态管理库)以及Framer Motion(用于流畅动画)的技术栈。
产品核心功能
· 冥想计时器:提供多种预设时长,用户可快速选择开始冥想。技术实现价值在于其响应速度极快,用户无需等待加载即可进入冥想状态,解决用户急需进行冥想时却被App卡顿或登录流程耽误的问题。
· 4-7-8呼吸练习引导:带有视觉动画提示,帮助用户掌握特定的呼吸节奏。技术实现价值在于利用客户端渲染实现平滑的动画效果,让用户直观感受呼吸的配合,这对于需要练习正念呼吸的用户来说,提供了有效的指导,解决了用户难以自行掌握呼吸技巧的痛点。
· 每日统计跟踪:用户可以在本地查看自己的冥想时长和次数。技术实现价值在于将数据安全地存储在localStorage中,无需服务器,保证了用户数据的绝对隐私,解决了用户对数据安全和隐私的担忧,同时提供了基本的进度反馈。
· 暗色模式:提供夜间模式,减少屏幕光线对眼睛的刺激。技术实现价值在于通过CSS变量或主题切换实现,改善了用户在弱光环境下的使用体验,尤其是在睡前冥想时,让眼睛更舒适。
· 静态导出和离线访问:应用被构建为静态文件,首次加载后即可离线使用。技术实现价值在于优化了网站性能,实现了极低的加载延迟(<1s)和Core Web Vitals的优秀表现,提升了用户体验,解决了网络不稳定或无网络环境下无法使用冥想工具的限制。
· 无追踪和无账户:完全不使用Cookies、第三方分析工具,不要求用户注册。技术实现价值在于彻底践行隐私至上原则,对用户数据进行最高级别的保护,消除了用户对数据被收集、分析甚至滥用的顾虑,这是其最核心的价值所在。
产品使用案例
· 场景:某开发者在工作间隙需要快速进行一次短暂的冥想以缓解压力,但不想打开复杂的App或处理登录流程。解决方案:打开ZenMoment,选择5分钟冥想,立即开始,效率极高。解决的技术问题:快速启动和无干扰的冥想体验。
· 场景:用户对市面上大部分冥想App的数据收集政策感到担忧,希望找到一个绝对尊重隐私的工具。解决方案:使用ZenMoment,了解其完全在本地存储数据、无服务器端收集的机制,安心进行冥想练习。解决的技术问题:用户对个人数据隐私的担忧。
· 场景:用户在旅行途中,网络连接不稳定,但仍想保持冥想习惯。解决方案:ZenMoment在首次加载后即可离线使用,即使在飞机上或信号不好的地方,也能继续进行冥想。解决的技术问题:离线可用性,不受网络限制。
· 场景:一位刚接触冥想的新手,不熟悉呼吸技巧,需要一个简单易懂的指导。解决方案:ZenMoment的4-7-8呼吸练习引导,通过直观的动画帮助其掌握正确的呼吸方法,辅助冥想。解决的技术问题:冥想初学者对呼吸技巧的掌握困难。
· 场景:有开发者希望构建一个注重隐私、性能极佳的Web应用,作为其技术实践或个人项目。解决方案:研究ZenMoment的技术实现,学习如何利用Next.js 14的静态导出、纯客户端渲染和本地存储来构建高隐私、高性能的应用。解决的技术问题:为开发者提供了一个实际可用的、关于隐私优先和性能优化的技术案例。
69
AI-First Web BP - 让AI助手读懂你的网站
作者
kure256
描述
这是一个旨在让AI助手(如ChatGPT、Gemini、Copilot)更好地理解、索引和引用网站内容的指南集。它提供了一套简单、开放的实践方法,让你的网站在AI时代也能被有效访问和利用,如同过去的SEO帮助搜索引擎一样。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个指导性项目,提供一套实用的、不依赖特定框架的网站建设最佳实践。核心思想是让网站内容对AI系统来说更加“友好”和“可读”。想象一下,搜索引擎优化(SEO)让网站对Google等搜索引擎友好,而这个项目就是为AI助手打造的“AI搜索引擎优化”。它通过结构化和语义化的方式组织信息,让AI能够更准确地抓住网站的核心信息、来源和上下文,避免AI助手在引用信息时出现偏差或无法找到出处。这解决了AI助手在获取和利用网络信息时面临的“理解鸿沟”问题。
如何使用它?
开发者可以将这些指南融入到网站的设计和开发流程中。这通常意味着在网站的HTML结构、元数据(metadata)和内容组织上做出一些调整。例如,使用语义化的HTML标签(如`<article>`, `<aside>`, `<nav>`)来明确内容的类型和关系;添加结构化数据(structured data),如JSON-LD格式,来描述网站上的实体(如文章、产品、人物)及其属性;确保内容清晰、逻辑性强,并附带明确的引用来源。这可以通过在网页的`<head>`部分添加`<script type="application/ld+json">`标签,或者在内容中使用更规范的标记语言来实现。最终目标是让AI助手在抓取信息时,能够轻松识别出关键信息点,并正确地回溯到你的网站。
产品核心功能
· 网站结构语义化:通过使用恰当的HTML5语义标签,帮助AI区分页面的不同部分(如主内容、导航、侧边栏),从而更精准地提取核心信息。这就像给AI提供一张清晰的地图,指引它找到最重要的地方。
· 结构化数据标记:利用JSON-LD等格式为网站内容添加机器可读的描述(例如,文章的标题、作者、发布日期,产品的价格、描述)。这让AI能够直接读取并理解内容的结构和属性,就像AI能读懂一本按类别分类的书。
· 引用和溯源机制:鼓励在内容中明确标注信息来源和引用关系。这确保AI在生成内容时,能够准确地引用原始信息来源,提升AI生成内容的可靠性和透明度。这解决了AI“一本正经地胡说八道”的问题,让AI引用信息时能给出“证据”。
· AI友好内容组织:指导开发者以清晰、逻辑化的方式组织文本内容,使用小标题、列表等,让AI更容易理解长篇文章的脉络。这让AI阅读长文不再是“大海捞针”,而是有清晰的路径可循。
· 元数据优化:建议在HTML的`<meta>`标签中提供更具描述性的信息,帮助AI快速了解网页的主题和内容概要。这相当于给AI一个简洁的“摘要”,让它快速了解网页内容。
· 开放性指南:不依赖任何特定技术框架,提供一套通用的、可演进的实践原则。这意味着开发者可以灵活地将其应用到现有的任何技术栈中,无需大规模重构。这给了开发者极大的自由度,可以“就地取材”,逐步改进。
产品使用案例
· 新闻网站:为一个新闻网站实施AI-First Web BP,通过结构化数据标记新闻的标题、作者、发布时间、事件地点等信息,并使用HTML5语义标签区分新闻正文和相关链接。这样,AI助手在引用新闻时,就能准确地给出新闻的来源、发布时间和关键事实,避免信息失真。
· 电商网站:为电商网站的商品详情页添加结构化数据,描述商品的名称、价格、规格、库存、用户评价等。AI助手在回答用户关于商品的问题时,可以直接调用这些结构化信息,提供准确的商品信息,提升用户购物体验。
· 博客或技术文档:为技术博客或文档添加清晰的目录结构和代码块标记,并使用`<article>`和`<aside>`标签区分主要内容和补充说明。AI助手在解释技术概念或提供代码示例时,能够准确地定位和引用信息,帮助开发者更快地解决技术问题。
· 个人作品集:为一个创意工作者的个人作品集网站添加作品的描述、使用的技术、创作背景等结构化信息。AI助手在被问及该创意工作者时,能够提供更全面、准确的作品介绍,帮助其获得更多关注。
· 研究论文或学术报告:为学术内容添加更规范的引用和交叉引用标记,使用`<blockquote>`明确引用的内容。AI助手在处理学术信息时,能够更好地理解研究的上下文和依赖关系,帮助学生或研究人员进行文献梳理和研究分析。
70
WikiParser-JSONizer
作者
zeronex
描述
这是一个将海量维基百科数据(特别是法文维基百科)转化为易于使用的JSON格式的项目。它解决了原始维基百科数据(XML和Wiki文本)难以直接用于现代人工智能(如自然语言处理NLP和大型语言模型LLM)研究和开发的痛点,通过自定义的解析流程,将每个维基百科文章都变成一个独立的、结构化的JSON文件,方便开发者进行数据分析和模型训练。
人气
点赞 1
评论数 0
这个产品是什么?
WikiParser-JSONizer是一个自己开发的工具集,它能够读取非常庞大的法文维基百科数据(原始的XML和Wiki文本格式),然后一步步地将其清洗、整理,并最终将每一篇文章转换成一个单独的JSON文件。它就像一个数据炼金术士,把原始、混乱的维基百科信息,提炼成干净、规整、可以直接拿来做事的JSON格式。创新点在于它是一个完全自研的解析管道,针对维基百科的复杂结构进行了深度优化,特别是能够将维基百科的“信息框”(Infobox)解析成标准的JSON对象,并且还能提取文章的分类和内部链接等重要信息。这样做的好处是,开发者不再需要花费大量时间去处理复杂的Wiki标记语言,可以直接拿到已经结构化好的数据,极大地提高了工作效率。所以这对我有什么用?如果你想做关于法文维基百科内容的AI研究,比如训练一个懂法语知识的模型,或者分析法文世界的流行话题,这个项目能让你省去一大堆繁琐的数据预处理工作,直接开始你的创新。
如何使用它?
开发者可以通过下载这个项目提供的2.7 million(270万)个法文维基百科文章的JSON数据集来使用。每个JSON文件对应一篇维基百科文章。你可以将这些JSON文件加载到你的开发环境中,无论是Python、Java还是其他语言,都可以轻松地读取和解析。对于NLP或LLM开发者来说,你可以直接将这些JSON文件作为训练数据。例如,如果你想训练一个模型来回答关于法国历史的问题,你可以直接使用包含法国历史文章的JSON文件。如果想分析维基百科文章中的链接关系,也可以方便地从JSON文件中提取链接信息。这种方式就像直接获得了一本排版好、分类清晰的百科全书,可以直接查阅和引用。所以这对我有什么用?你可以快速地获取大量结构化的法文知识数据,用于AI模型的训练、数据分析、知识图谱构建等多种场景,大大缩短项目开发周期。
产品核心功能
· XML数据流读取与文章提取:能够高效地从巨大的XML文件中逐一读取维基百科的文章,保证数据完整性。
· Wiki文本清洗与标记移除:去除维基百科特有的标记语言(如Markdown的变种),还原文章的纯文本内容,为后续解析打下基础。
· 章节结构重建:智能地识别和重建文章的章节结构,使得数据更有条理,便于理解和分析。
· 信息框(Infobox)JSON化:将维基百科文章中包含的结构化信息框(例如人物的出生日期、地点、职业等)精确地解析成标准的JSON对象,方便直接读取关键信息。
· 分类与链接信息提取:自动提取文章所属的分类以及文章内部链接,为构建知识关联和分析话题热度提供数据支持。
· 单文章JSON文件输出:将每一篇维基百科文章的内容和元数据打包成一个独立的JSON文件,方便管理和按需加载,提高数据处理的灵活性。
产品使用案例
· NLP模型训练:一个AI研究者希望训练一个能够理解和生成法文文本的模型。他可以下载WikiParser-JSONizer生成的法文维基百科JSON数据集,将其作为大规模的训练语料。模型可以直接从JSON文件中读取文章内容,学习法文的语法、词汇和世界知识,从而提升模型的语言理解和生成能力。解决了从原始Wiki数据中提取高质量训练语料的难题。
· 知识图谱构建:一个开发者想为法文维基百科创建一个知识图谱。他可以使用WikiParser-JSONizer提取的JSON数据,从中解析出实体(如人物、地点、概念)及其之间的关系(通过链接和信息框解析)。例如,可以提取出“埃菲尔铁塔”是“巴黎”的“景点”,这个过程将比手动解析Wiki文本高效得多。解决了从非结构化文本中提取结构化知识关系的问题。
· 数据分析与话题挖掘:一个市场分析师想了解法国网民关注的热点话题。他可以利用WikiParser-JSONizer处理后的JSON数据集,通过分析文章的标题、内容和分类,来识别出当前讨论度高、内容丰富的话题。例如,他可以统计关于“法国大选”、“气候变化”、“某位法国明星”的文章数量和被引用情况,从而洞察流行趋势。解决了从海量文本中快速发现和量化热门话题的挑战。
· 信息提取与问答系统:一个开发者正在构建一个基于法文维基百科的问答系统。他可以利用WikiParser-JSONizer解析出的JSON,特别是信息框中的结构化数据,来快速准确地回答用户关于特定人物、事件或概念的问题。例如,用户问“谁是路易十四?”,系统可以直接从路易十四的文章JSON中提取他的生卒年份、主要事迹等关键信息,并给出答案。解决了从零散的维基百科信息中快速提取事实性答案的难题。
71
DNA压缩:AI的语义智能增强器
作者
bruinmeister
描述
这是一个受DNA启发的技术,用一种巧妙的方式“压缩”AI处理的信息,让AI能够一次性理解更多内容,解决AI在处理长文本或复杂信息时“记不住”或“理解不全”的问题。它通过识别信息中的关键模式,像DNA一样高效编码,大大拓展了AI的“记忆力”。
人气
点赞 1
评论数 0
这个产品是什么?
这个项目是一种名为“DNA-Inspired Semantic Compression”(DNA启发式语义压缩)的技术。它借鉴了DNA存储信息的高效性和结构性。简单来说,AI在处理大量文本时,就像人脑一样,有“记忆上限”。当信息太多时,AI可能会遗忘前面的内容,或者抓不住重点。这个项目通过提取信息中最核心、最有代表性的“模式”(类似于DNA中的基因序列),然后用一种更紧凑、更有效的方式来编码和存储这些信息。这样,AI就能在有限的“记忆空间”内,存储和检索更多的关键信息,从而在理解长篇对话、文档或代码时表现得更好。它的创新之处在于将生物学的DNA编码思想巧妙地应用到AI的语义理解和信息存储上,解决AI模型在处理上下文窗口(Context Window)限制时的瓶颈。
如何使用它?
开发者可以将这项技术集成到现有的AI模型中,特别是那些处理文本、代码或对话的应用。比如,在构建大型语言模型(LLM)的应用时,可以通过在输入数据前先经过DNA压缩处理,再喂给AI模型。AI模型接收到的信息虽然经过压缩,但其核心语义被保留了下来。这样,AI就能在处理长对话、阅读冗长的文档(如法律文件、技术报告)或理解庞大的代码库时,保持更好的连贯性和理解力。这就像给AI配备了一个超级摘要和记忆系统。
产品核心功能
· 语义模式提取:自动识别文本或数据中的核心含义和模式,就像DNA中的功能基因一样,是信息的关键组成部分。
· 高效信息编码:将提取出的关键模式以更紧凑、更易于AI处理的方式进行编码,从而节省宝贵的计算资源和“记忆空间”。
· 上下文信息扩展:通过优化信息表示,让AI在有限的“上下文窗口”内能感知和处理更多有用的信息,显著提升AI对长文本或复杂对话的理解能力。
· 智能信息检索:支持AI快速准确地检索压缩信息中的关键细节,确保AI在需要时能回忆起重要信息,而不是一片模糊。
产品使用案例
· 构建更聪明的聊天机器人:使用DNA压缩技术,聊天机器人能更好地记住用户之前的对话内容,即便对话很长,也不会显得“健忘”或“答非所问”。
· 智能文档分析助手:帮助AI快速阅读并理解大量法律合同、研究论文或技术手册,从中提取关键条款、结论或解决方案,大大提高信息处理效率。
· 代码理解与生成工具:让AI能够更好地理解复杂的代码库,帮助开发者进行代码重构、bug检测或生成更符合上下文的代码片段,因为AI能“记住”更多的代码逻辑。
· AI内容摘要与生成:在生成长篇内容(如文章、报告)时,AI能更好地保持主题连贯性和信息完整性,因为其内部对核心概念的“记忆”更深刻。
72
CBK Agent SDK: 智能终端的AI驱动助手
作者
_pdp_
描述
CBK Agent SDK 是一个专为智能终端(如手机、IoT设备)设计的,集成了先进AI能力的开发工具包。它允许开发者为终端设备构建智能代理,能够理解自然语言指令,执行复杂任务,并提供个性化服务。其创新点在于将大型语言模型(LLM)的能力高效地部署到资源受限的终端设备上,实现离线AI交互,从而保护用户隐私并减少网络延迟。
人气
点赞 1
评论数 0
这个产品是什么?
CBK Agent SDK 是一个让你能在手机、智能手表、智能家居设备等终端上,为用户打造智能助手(Agent)的工具箱。想象一下,你的设备不仅仅是执行你发出的简单命令,而是能理解你说的话,帮你完成一系列复杂的事情,比如帮你写一封邮件,或者规划一次旅行。它之所以特别,是因为它能把那些非常“聪明”但又很“占地方”的大型语言模型(LLM)的技术,巧妙地塞进性能有限的设备里,而且不需要联网就能工作。这意味着你的设备更懂你,而且你的个人信息更安全,反应速度也更快。
如何使用它?
开发者拿到CBK Agent SDK后,就可以在自己的App或设备固件中集成AI能力。通过SDK提供的API,你可以定义Agent能够识别的指令类型、能够执行的任务(如调用设备上的功能、访问网络数据等),以及如何与用户进行多轮对话。例如,你可以开发一个应用,让用户通过语音告诉Agent:“帮我预订明早去上海的机票,头等舱,不要太早的航班”,Agent就能理解并帮你完成预订流程。这就像给你的App或设备增加了一个“大脑”,让它能主动思考并为你服务。
产品核心功能
· 离线自然语言理解:即使没有网络,设备也能听懂你说的话,比如你对智能音箱说“关灯”,它能立刻响应,这避免了网络不好的时候指令失效的尴尬,并保护了你的语音隐私。
· 任务执行与自动化:Agent不仅能听懂,还能帮你做事。比如你可以让它帮你把今天拍的照片整理成一个相册,或者根据你设置的条件自动帮你购买打折商品,这极大地提高了你的生活效率。
· 个性化智能响应:Agent会学习你的使用习惯,并根据你的偏好提供服务。例如,它知道你喜欢某个咖啡品牌,下次你问“附近有什么好喝的咖啡”,它就会优先推荐你喜欢的品牌,让体验更贴心。
· 跨平台设备集成:SDK支持多种终端平台,这意味着你开发的功能可以在你的手机、平板甚至是智能家电上运行,实现设备间的无缝智能联动。
· 低功耗AI模型部署:通过特有的技术,让AI在不耗费大量电力的前提下运行,这对于续航有限的移动设备和IoT设备来说至关重要,让智能体验不打折。
产品使用案例
· 一个面向老年人的智能助手App:通过语音指令,老年人可以轻松地设置闹钟、查询天气、联系家人,甚至报告身体不适,SDK保证了即使在信号不好的情况下也能响应,并且保护了他们的健康数据隐私。
· 一款智能家居控制App:用户可以通过自然语言控制家里的灯光、空调、电视等设备,SDK让这些控制指令无需发送到云端,响应速度更快,用户体验更流畅,而且无需担心家庭设备被外部攻击。
· 一款针对摄影爱好者的App:用户可以对着手机说“找出我上周拍的风景照,并且把天空P蓝一点”,SDK能够理解指令,并在本地完成图片识别和简单的图像处理,省去了用户手动操作的麻烦,同时保护了照片不被泄露。
· 一款教育类App,支持儿童语音交互:孩子们可以通过和App里的虚拟角色对话来学习知识,SDK的离线能力确保了教学过程的稳定进行,同时避免了儿童在使用过程中暴露个人信息的风险。
73
Neo4j 协程感知 Kotlin 驱动
作者
morisil
描述
这是一个为 Kotlin 开发者设计的 Neo4j 数据库驱动,它引入了一种全新的方式来与 Neo4j 交互。其核心创新在于极大地降低了语言模型(LLM)的认知负担,让 AI 代理在处理数据库操作时更高效、更智能。它通过提供简洁的 DSL(领域特定语言)和自动化的数据映射,使得开发者(或 AI 代理)无需过多关注底层细节,就能流畅地读写 Neo4j 中的知识图谱。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个 Neo4j 数据库的 Kotlin 驱动程序,它特别关注如何在 Kotlin 的协程(coroutines)环境下实现异步操作,并且目标是让大型语言模型(LLM)在调用这个驱动时感觉非常轻松,就像在写普通的代码一样,不需要花费太多精力去理解复杂的异步概念。它解决了 AI 代理在管理数据库连接、处理数据格式转换等方面的“认知负担”,使得 AI 能够更专注于其核心的推理和决策任务。 简单来说,它就像一个翻译官,把 AI 的想法(比如“从数据库里找找关于某个主题的信息”)准确无误地翻译成数据库能懂的语言,并且把数据库返回的数据再翻译回 AI 能懂的格式,而且这个过程对 AI 来说是无缝衔接的,就像自己写的代码一样。
如何使用它?
开发者可以将这个驱动集成到他们的 Kotlin 项目中。如果你在使用 Ktor(一个现代化的 Kotlin 服务器框架)并且希望实现全栈异步,这个驱动配合 Ktor 提供的协程支持会非常方便。 集成方式通常是添加依赖到你的 `build.gradle.kts` 文件中,然后通过简单的代码调用即可连接到 Neo4j 数据库,执行 Cypher 查询(Neo4j 的查询语言),并获取结果。 特别之处在于,你不需要手动管理连接池或者复杂的异步回调,驱动会利用 Kotlin 的协程来处理这些,让你的代码看起来更清晰、更易于管理。 例如,你可以直接在协程函数中调用驱动的方法来查询数据,而无需担心线程阻塞或复杂的异步流程。
产品核心功能
· 简化的数据库操作 DSL:提供一种易于理解和使用的语法,让开发者(或 AI 代理)能够更自然地表达数据库查询意图,减少编写复杂查询语句的认知负荷。 价值:让数据库操作的代码更接近自然语言,提高开发效率。
· 自动化的数据模型映射:能够将 Cypher 查询返回的复杂数据结构,自动转换成 Kotlin 的多平台数据类。 价值:省去了手动解析和转换数据的繁琐工作,减少了出错的可能性,尤其对 AI 代理而言,降低了理解和处理返回数据的复杂性。
· 对 Kotlin 协程的原生支持:充分利用 Kotlin 协程的优势,实现高效的非阻塞 I/O 操作。 价值:在并发和异步场景下,能够更有效地利用系统资源,提高应用程序的响应速度和吞吐量,让 AI 代理的响应更即时。
· 最小化 AI 认知负担:通过以上设计,显著降低了 AI 代理在与数据库交互时需要处理的复杂性。 价值:使 AI 代理能够更专注于其核心的智能任务,如推理、规划和学习,而不是被底层技术细节所困扰,从而提升 AI 的整体表现。
· 类型安全的代码执行:作为编译型语言的一部分,驱动支持强类型检查。 价值:在代码编写阶段就能发现潜在的类型错误,避免运行时出现意想不到的问题,增强代码的健壮性。
产品使用案例
· AI 代理构建个人知识库:AI 代理可以利用这个驱动,将AI的学习、思考过程以及收集到的信息,以知识图谱的形式存储在 Neo4j 中。当AI需要回忆或推理时,能够高效地从这个知识图谱中检索信息,并减少AI在理解和存储过程中所需的“脑力”。
· 智能问答系统优化:开发一个智能问答系统,当用户提出问题时,AI可以通过这个驱动快速从 Neo4j 数据库中检索相关的知识点,并进行整合回答。驱动的低认知负荷设计,能让AI更快地找到答案,并给出更准确的回复。
· 全栈应用中的数据持久化:在基于 Ktor 的全栈应用中,后端可以使用这个驱动来管理用户数据、业务逻辑数据等。前端(如果使用 Kotlin/JS)也可以间接受益于后端更高效的数据处理,提升整体应用体验。异步和结构化并发的结合,让数据读写非常流畅。
· 自主代码生成与执行:AI 代理可以根据任务需求,动态生成与 Neo4j 交互的代码,并通过这个驱动来执行。驱动的简洁性和自动化,使得AI能够更灵活地定义数据处理流程,而无需深入了解数据库操作的细节。
74
Teller: 智能播客“懂你”引擎

作者
tellerbr15
描述
Teller 是一个旨在让播客体验更个性化、更智能化的平台。它通过机器学习技术,深入分析你的收听习惯,主动为你推荐真正感兴趣的播客节目和单集。当前版本 V1 专注于打磨基础体验,包括内容库管理、无缝收听、智能队列以及个性化推荐。未来的 V2 将引入更复杂的自动化技术,让这一切更加自然流畅。
人气
点赞 1
评论数 0
这个产品是什么?
Teller 是一个基于人工智能的播客推荐和收听系统。它通过分析你收听的播客内容(比如你听了多久、跳过了哪些、收藏了哪些),学习你的偏好。然后,它利用这些学习到的信息,像一位懂你的朋友一样,主动向你推荐你可能真正喜欢的播客节目和其中的具体单集。这不仅仅是简单的热门推荐,而是真正根据你的口味进行的“懂你”推荐。它的创新之处在于,它希望让这种智能推荐变得“无感”,也就是说,你不需要刻意去设置,它就能悄悄地为你提供最符合你口味的内容,让你专注于享受播客本身。
如何使用它?
开发者可以通过集成 Teller 的 API,将智能推荐功能引入到他们自己的播客应用或服务中。举个例子,如果你正在开发一个播客聚合应用,你可以调用 Teller 的服务,让你的应用能够为每个用户提供高度个性化的播客推荐列表。用户使用时,就像平时使用其他播客 App 一样,在 App 中就能看到 Teller 精心为你挑选的、最符合你口味的播客节目和单集,大大节省了寻找优质内容的时间。
产品核心功能
· 个性化播客推荐:基于用户收听行为的深度学习,推荐用户可能喜欢的播客节目和单集,让用户发现更多符合自己兴趣的内容,解决“找播客难”的问题。
· 智能收听队列:自动管理播客播放列表,根据用户偏好和收听历史,智能调整播放顺序,确保用户在收听过程中流畅连贯,提升用户体验,解决“听什么”的纠结。
· 无缝内容库管理:提供便捷的内容库组织和管理功能,让用户可以轻松收藏、整理和回顾自己喜欢的播客节目,方便二次收听,提高内容管理效率。
· 细致的收听体验优化:通过对播放、暂停、跳过等行为的分析,不断优化播客的播放流程和交互方式,使得收听过程更加自然顺畅,专注于内容本身,提升用户沉浸感。
· 潜在的未来自动化能力(V2):未来将通过更先进的自动化技术,让播客内容的发现和消费过程更加智能化和个性化,让用户几乎感觉不到技术的存在,一切都恰到好处。
产品使用案例
· 一个小型播客聚合应用的开发者,希望为用户提供比竞争对手更出色的个性化推荐,他可以集成 Teller 的推荐引擎。用户在该应用中收听播客后,Teller 会根据其行为推荐新的、高质量的节目,而无需用户手动搜索,极大地提升了用户粘性。
· 一个播客制作人想要了解哪些听众群体对他制作的播客最感兴趣,以便调整内容方向。通过 Teller 的分析能力(虽然当前 V1 主要侧重推荐),未来版本可以提供更深入的用户洞察,帮助制作人更好地理解听众,从而创作出更受欢迎的内容。
· 一位播客爱好者,每天花大量时间在各个平台寻找感兴趣的内容,但经常感到失望。使用集成了 Teller 的播客 App,他可以快速浏览到由 Teller 精心筛选出的、他极有可能喜欢的节目和单集,大大节省了时间和精力,让他能更高效地享受播客带来的乐趣。
· 一个需要快速启动播客服务的创业团队,他们可能没有足够的资源去开发复杂的推荐算法。集成 Teller 可以让他们快速拥有强大的个性化推荐能力,将精力集中在内容创作和平台的核心体验上,加速产品上线和用户增长。
75
语境阿拉伯语互动学习助手
作者
selmetwa
描述
这是一个开源平台,旨在解决学习阿拉伯语时教材不直观、查词不便捷的问题。它通过互动式平行文本,允许用户即时点击或拖拽阿拉伯语单词,即可在原地看到释义、音标和语法注释。平台还引入了AI生成的阿拉伯语故事和句子,并配备方言(如埃及和摩洛哥阿拉伯语)的音频,让学习者在更贴近实际的语境中练习。特别之处在于,它针对特定阿拉伯语方言定制了大型语言模型(LLM),解决了通用模型在方言处理上的不足,从而填补了现有教育资源的空白。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个为阿拉伯语学习者设计的智能互动学习平台。它的核心技术在于“互动式平行文本”和“定制化AI语言模型”。互动式平行文本就像你在看一本双语对照的书,但更聪明。当你把鼠标悬停在任何一个阿拉伯语单词上,它会像弹窗一样在你眼前显示这个词的意思、发音(音标)以及相关的语法解释,而且这一切都发生在你正在阅读的句子旁边,不会打断你的思路。这就像给教材装上了一个实时翻译和解释的“插件”。
另一个创新点是它使用了“定制化AI语言模型”。我们知道,阿拉伯语有标准语(MSA)和各种地方方言,比如埃及话、摩洛哥话。很多现有的学习工具只教标准语,但大家日常交流用的却是方言。这个项目用AI技术专门学习了埃及和摩洛哥方言,生成的故事和句子更贴近真实生活,而且有地道的方言发音。这就像请了一个懂当地话的AI老师,而不仅仅是学课本上的“普通话”。
如何使用它?
作为开发者,你可以将这个平台集成到你的教育网站、APP或者任何需要阿拉伯语学习功能的项目中。
使用场景包括:
1. **在线教育平台集成**:如果你正在开发一个在线语言学习平台,可以将这个互动文本引擎嵌入你的课程页面,让用户在学习阿拉伯语时享受即时翻译和解释的便利。
2. **APP开发**:在你的语言学习APP中,可以使用它的API来加载和渲染互动式文本内容,并利用AI生成的内容来丰富学习材料。
3. **内容创作者工具**:为阿拉伯语教学内容创作者提供一个工具,让他们能轻松创建带有互动翻译和方言发音的学习材料。
技术上,你可以将其作为一个独立的Web组件,通过JavaScript API调用,或者将其作为后端服务,通过RESTful API提供文本解析和AI内容生成功能。其开源的特性意味着你可以自由地修改和扩展其功能,以适应你特定的开发需求。
产品核心功能
· 互动式平行文本查找:用户在阅读时,只需将鼠标悬停在阿拉伯语单词上,即可即时获取该单词的翻译、音标(转写)和语法注释,极大地提高了学习效率,避免了来回翻阅字典的麻烦。
· AI驱动的阿拉伯语内容生成:利用定制化AI模型生成贴近真实生活场景的阿拉伯语故事和句子,为学习者提供了更自然、更动态的学习材料,而不是僵硬的课本例句。
· 方言特色内容与音频:平台特别关注埃及和摩洛哥等阿拉伯语方言,并提供相应的AI生成内容和地道的方言发音音频。这使得学习者能够接触到实际交流中最常用的语言形式,弥补了传统教材的不足。
· 定制化LLM模型支持方言:针对通用AI模型在处理方言内容上的局限性,该项目训练了专门针对埃及和摩洛哥方言的LLM,确保了AI生成内容的准确性和地道性,为学习者提供了更可靠的学习资源。
· 开源社区驱动:作为开源项目,开发者可以自由地查看、修改和贡献代码,加速了功能的迭代和完善,也为其他开发者提供了学习和借鉴的平台。
产品使用案例
· 在一个在线阿拉伯语课程网站上,将此平台作为课文阅读模块。当学生阅读课文时,遇到不认识的单词,无需离开页面,即可在单词旁看到其释义和发音,学生可以更流畅地理解课文内容,从而提升学习体验。
· 开发一款移动端阿拉伯语学习APP,利用该平台的AI故事生成功能,为用户提供每日一句或小故事,并配有埃及方言的朗读音频。这能让用户在碎片化时间里,接触到生动有趣的方言,增强学习的趣味性。
· 一位阿拉伯语教师希望制作一套更贴近日常生活的教学材料。使用该平台,他可以轻松地将一段摩洛哥日常对话的文本转换为互动式内容,并为每个关键短语添加即时翻译和语法解释,让学生更容易理解和模仿。
· 一家语言技术公司正在研究阿拉伯语方言的自然语言处理。他们可以将该项目中的定制化LLM作为基础模型,进一步研究和优化,以开发更先进的方言识别或翻译工具。
76
GitHub代码行数与目录层级助手
作者
hacker_rob
描述
这是一个浏览器扩展,它能在你浏览GitHub代码库时,实时显示文件的代码行数(LOC)以及目录的子目录数量。它解决了在GitHub上快速评估代码规模和项目结构不直观的问题,让开发者能更高效地理解代码库。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个为GitHub用户设计的浏览器扩展,核心技术是利用JavaScript和浏览器扩展API来解析GitHub网页的DOM结构。当用户浏览GitHub的仓库页面时,它会自动抓取文件列表和目录结构,并计算出每个文件的代码行数(Lines of Code, LOC)和每个目录下一级的子目录数量。传统的GitHub界面需要逐个打开文件才能看到代码行数,或者要手动去统计目录层级,这个扩展通过前端实时计算和展示,极大地提升了信息获取的效率,是代码浏览的“瑞士军刀”。
如何使用它?
开发者只需在浏览器(如Chrome, Firefox)的扩展商店搜索并安装“GitHub LOC/Child Counts Extension”即可。安装完成后,当你访问任何GitHub仓库页面,无论是在文件列表还是在代码浏览界面,它都会自动工作。例如,在查看一个项目的文件列表时,每个文件旁边会直接显示其代码行数;在浏览目录时,每个子目录旁边会显示它包含的子目录数量。这使得开发者无需离开当前页面,就能快速了解代码库的规模和组织结构,从而更快地做出技术判断或进行代码评审。
产品核心功能
· 文件代码行数(LOC)实时显示:在GitHub的文件列表或代码浏览界面,为每个文件计算并展示其代码总行数。这能帮助开发者快速了解单个文件的规模,判断其复杂性,对代码评审和重构非常有价值。
· 目录子目录数量统计:在GitHub的目录浏览界面,为每个子目录统计并显示其下一级包含的子目录数量。这有助于开发者快速理解项目的目录结构深度,判断项目组织的合理性,避免陷入过深的层级。
· 无缝集成GitHub体验:该扩展在浏览器端运行,不改变GitHub本身的界面布局,只是在原有信息基础上增加了新的可视化数据,对用户来说是无感知的增强,不干扰正常使用。
· 轻量级前端计算:所有计算都在用户的浏览器本地完成,不会增加GitHub服务器的负担,也不会泄露用户隐私。这体现了用最小的资源解决问题的黑客精神。
产品使用案例
· 代码评审场景:在进行代码评审时,评审者可以快速看到每个文件的大小,从而判断哪些文件可能需要更细致的审查,提高评审效率。
· 项目快速评估:当新的开发者加入团队或需要快速了解一个陌生项目时,可以通过这个扩展快速浏览仓库,对项目代码量和目录结构有一个宏观的认识,降低学习成本。
· 代码重构决策:在考虑重构某个模块时,可以方便地查看相关文件的代码行数,为重构的范围和工作量提供数据支持。
· 开源贡献者筛选:对于想参与开源项目的开发者,可以通过快速查看项目的文件大小和目录结构,来判断项目是否符合自己的技术偏好和能力范围。
77
LiquiDB:代码驱动的跨数据库统一管理平台
作者
grigoras
描述
LiquiDB是一个开源的、专为开发者设计的跨数据库管理工具。它允许开发者通过代码(SQL)来管理和操作多种不同类型的数据库,比如PostgreSQL、MySQL、SQLite等,而无需学习每种数据库特有的命令。其创新点在于提供了一个统一的API接口,将数据库的操作逻辑抽象化,大大提升了开发效率和灵活性,解决了开发者在多数据库环境下频繁切换工具和学习成本高的问题。
人气
点赞 1
评论数 0
这个产品是什么?
LiquiDB是一个让开发者能够用一套代码风格去管理和操作各种主流数据库的开源软件。它的核心技术思想是‘数据库抽象层’。想象一下,不同的数据库就像是说着不同‘方言’的人,而LiquiDB就像一个‘翻译官’,你用‘通用语’(LiquiDB提供的API)跟它说话,它就能把你的话翻译成各种数据库能听懂的‘方言’。这就像是给所有数据库装上了一个统一的‘操作系统’,开发者只需要掌握LiquiDB这一套‘操作手册’,就能轻松搞定MySQL、PostgreSQL、SQLite等,大大降低了学习成本和开发复杂度。它的价值在于,让开发者把更多精力放在业务逻辑上,而不是被繁杂的数据库细节困扰。
如何使用它?
开发者可以将LiquiDB集成到自己的开发项目或脚本中。通过安装LiquiDB,然后用LiquiDB提供的SDK(软件开发工具包)编写代码来连接数据库、执行查询、创建或修改表结构。例如,你可以编写一个Python脚本,使用LiquiDB连接到一个MySQL数据库,执行一个`SELECT * FROM users`的查询,LiquiDB会返回一个标准化的结果集,无论你实际连接的是MySQL还是PostgreSQL。它特别适合需要与多个数据库交互的后端服务、数据迁移工具、或者需要自动化数据库管理的脚本。
产品核心功能
· 统一的数据库连接管理: LiquiDB提供一个配置中心,让开发者能用一套配置格式管理不同数据库的连接信息,避免了手动输入大量连接字符串和凭证,大大简化了数据库的接入流程,提高了安全性。
· 标准化的SQL执行: 开发者可以用LiquiDB执行标准的SQL语句,LiquiDB会自动将其转换为目标数据库能理解的命令,这意味着你编写一次SQL,就可以在多种数据库上运行,省去了为不同数据库写适配代码的时间,也减少了因语法差异导致的错误。
· 跨数据库数据迁移: LiquiDB可以帮助开发者轻松地将数据从一个数据库迁移到另一个数据库,只需编写简单的脚本,LiquiDB就能处理数据格式的转换和传输,对于需要升级数据库或合并数据源的场景非常有价值。
· 数据库模式(Schema)管理: LiquiDB支持代码化的数据库模式定义和更新,开发者可以用代码来描述数据库的表结构、索引等,并让LiquiDB自动在目标数据库上应用这些变化,这是一种‘基础设施即代码’(Infrastructure as Code)的实践,让数据库结构变更可追溯、可重复,降低了人为失误。
· 简化的查询结果处理: 无论从哪个数据库查询数据,LiquiDB都会返回一种统一的数据结构,开发者无需关心不同数据库返回结果格式的差异,直接使用即可,这大大简化了数据处理的逻辑,提高了开发效率。
产品使用案例
· 一个后端开发者需要开发一个应用,这个应用既要连接到公司的MySQL数据库存储用户信息,又要连接到另一个PostgreSQL数据库存储日志。使用LiquiDB,他只需要学习一套LiquiDB的API,就可以方便地在同一个应用程序中同时操作这两个数据库,而无需为MySQL和PostgreSQL分别学习一套数据库连接和操作方法,极大地提高了开发速度。
· 一家公司决定将老旧的SQLite数据库迁移到更强大的PostgreSQL数据库。使用LiquiDB,他们可以编写一个数据迁移脚本, LiquiDB负责从SQLite读取数据,并将其转换为PostgreSQL可接受的格式进行插入。整个过程只需要一套SQL和LiquiDB的工具,而不需要写复杂的ETL(Extract, Transform, Load)程序,大大缩短了迁移时间,降低了项目风险。
· 一个数据分析师需要定期从生产环境的数据库中提取数据进行分析。使用LiquiDB,他可以编写一个自动化脚本,该脚本连接到生产数据库,执行预定的查询,并将结果导出为CSV文件。即使未来数据库类型发生变化(例如从SQL Server切换到Oracle),他只需要修改LiquiDB的连接配置,而不需要重写整个数据提取脚本,保证了数据提取流程的稳定性。
· 一个小型初创团队在开发初期使用了SQLite数据库以快速迭代。随着业务发展,他们需要将数据库升级为MySQL以支持更多用户。使用LiquiDB,他们在开发和测试阶段就可以用LiquiDB来模拟或连接到MySQL,等到正式上线时,只需将LiquiDB的连接目标切换到MySQL,数据结构和查询逻辑基本无需修改,实现了平滑的数据库升级,避免了重写大量数据访问代码的麻烦。
78
智感Transformer可视化设计器
url
作者
kinderpingui
描述
Wasda AI 是一个创新的可视化工具,它允许开发者直观地设计和测试Transformer神经网络模型,并内置了对文本情感的分析功能。它的核心技术在于提供了一个易于理解的图形界面,让复杂的Transformer模型构建过程变得像搭积木一样简单,同时还能直接评估模型在理解人类情感方面的表现。
人气
点赞 1
评论数 0
这个产品是什么?
Wasda AI 是一个基于Web的可视化Transformer模型设计与分析平台。Transformer模型是当前人工智能领域非常流行的“大脑”,特别擅长处理文本和序列数据,例如语言翻译、文本生成和情感分析。但传统的Transformer模型设计过程非常依赖代码,而且调试起来很困难。Wasda AI 的创新之处在于,它提供了一个可视化的操作界面,开发者可以通过拖拽、连接不同的模块来构建Transformer模型,而无需编写复杂的代码。更重要的是,它集成了一个情感分析引擎,可以直接将设计好的模型应用于文本,并输出文本所蕴含的情感(如喜悦、愤怒、悲伤等)。这就像是给你的AI模型装上了一双“读心术”,可以直接判断用户说的话是开心的还是不开心的。
如何使用它?
开发者可以在浏览器中直接访问Wasda AI。通过可视化界面,你可以选择不同的Transformer组件(比如注意力机制、编码器、解码器等),然后像搭积木一样将它们连接起来,构建出你想要的模型结构。完成模型设计后,你可以输入一段文本,让模型进行预测。例如,你可以输入一条用户评论,然后看看模型能准确判断出这条评论是正面的还是负面的。这对于需要快速验证模型想法、或者对模型结构不熟悉的开发者来说,大大降低了门槛,能让他们更专注于模型的功能和表现。
产品核心功能
· 可视化Transformer架构设计:通过拖拽和连接模块,直观地搭建Transformer模型,无需深入理解底层代码,大大提高了模型设计的效率和灵活性。这让你能够快速尝试不同的模型结构,找到最适合你的任务的模型。
· 内置情感分析功能:可以直接评估设计好的模型在理解文本情感方面的能力,即时反馈模型的情感识别准确度。这使得开发者能够直接验证模型在实际应用场景(如用户评论分析、舆情监控)中的表现,确保模型能准确捕捉用户的情绪。
· 交互式模型测试与调试:设计好的模型可以实时进行测试,输入文本后立即得到情感分析结果,方便开发者快速迭代和优化模型。这就像是有一个实时反馈系统,让你知道你的模型好不好用,并且可以随时进行调整。
· 模块化组件库:提供预设的Transformer核心组件,开发者可以根据需求自由组合,降低了模型设计的复杂度,也提供了丰富的选择。这就像是有了一套标准化的工具箱,你可以根据需要拿取合适的工具来完成你的项目。
· 易于集成的API(潜在):虽然当前产品信息未详细说明,但一个成功的可视化工具通常会提供API,让开发者能将设计好的模型轻松集成到现有的应用中。这将使得Wasda AI 的模型能够实际部署并解决真实世界的问题。
产品使用案例
· 用户评论情感分析:社交媒体运营者或产品经理可以使用Wasda AI快速设计一个模型,分析用户在社交媒体上对产品的评论,了解用户对产品的情感倾向,从而制定更有效的营销策略或改进产品。例如,他们可以输入“这个产品太棒了,我非常喜欢!”,然后看看模型是否能准确识别出这是正面评价。
· 智能客服情感识别:客服团队可以利用Wasda AI构建模型,分析用户在与客服对话中的情感变化,以便更好地理解用户需求,及时安抚情绪激动用户,提升客户满意度。比如,当用户说“我等了半天还没人理我,太糟糕了!”,客服可以提前知道用户情绪不佳,并作出相应的处理。
· 内容推荐系统的情感优化:内容平台可以设计模型来分析用户浏览过的文章或视频的评论,从而更精准地推荐用户可能感兴趣的、并且情感上能产生共鸣的内容。例如,如果用户经常点赞和评论关于“励志故事”的内容,模型就可以推荐更多类似的情感积极的内容。
· 教育领域的情感化学习助手:教育开发者可以设计一个工具,让学习助手能够识别学生在学习过程中的情感反应(如困惑、沮丧、兴奋),并据此调整教学策略,提供更具个性化的学习支持。例如,当学生在做习题时表现出困惑,助手可以提供额外的提示或解释。
79
Java造假数据精灵
作者
barlogg
描述
这是一个Java项目,它能为你生成各种逼真的虚假数据。如果你是开发者,经常需要在开发或测试阶段填充大量数据,这个项目能帮你快速生成,省去手动创建的麻烦,让你专注于核心功能的开发。它的创新之处在于提供了灵活的配置方式,可以根据你的需求定制生成数据的类型和格式。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个Java库,就像一个“数据生产线”,专门用来制造用于开发和测试的假数据。传统的项目在开发过程中,需要用很多数据来模拟真实世界的情况,比如用户列表、订单信息、日志记录等等。手动创建这些数据非常耗时耗力。这个项目通过代码编写,可以自动化地生成这些数据。它的技术原理是利用了Java的反射机制和一些常见的第三方库,可以模拟出各种数据类型,例如随机字符串、数字、日期,甚至复杂的嵌套对象。创新点在于它提供了一种声明式的方式来定义数据生成规则,让你只需告诉它你想要什么样的数据,它就能帮你生成,非常高效。
如何使用它?
如果你是一个Java开发者,想要在自己的项目中引入这个“Java造假数据精灵”,你可以将它作为一个依赖库添加到你的项目中(比如使用Maven或Gradle)。一旦引入,你就可以通过编写几行Java代码来调用它。例如,你可以定义一个“用户”对象,然后告诉这个工具你希望生成100个用户数据,并且要求每个用户的名字是随机字符串,年龄是18到65之间的随机数字。工具就会自动为你生成这些数据,你可以直接将这些数据用于你的应用程序测试,比如数据库填充、API接口压力测试等。它就像一个随时待命的数据助手,你需要的时候,它就能立即提供你需要的数据。
产品核心功能
· 自动生成各种数据类型:它可以生成随机的文本、数字、日期、布尔值等基本数据类型,为你的项目填充基础数据,这样你就不用再手动输入,节省了宝贵的时间。
· 支持自定义数据生成规则:你可以精确控制生成数据的格式和内容,比如指定姓名的长度、数字的范围、日期的格式等,这样生成的数据就更贴近你的实际需求,让测试更加真实有效。
· 方便地生成复杂对象:不仅是简单的数据,它还能生成嵌套的对象结构,比如一个订单对象包含多个商品对象,这种能力对于模拟真实世界的复杂数据场景至关重要,可以帮助你更全面地测试系统的处理能力。
· 易于集成到现有项目:作为一个Java库,它可以轻松地添加到你的Java项目中,无需复杂的配置,让你快速开始使用,不会打断你的开发流程。
· 提供多种数据来源:除了随机生成,它还可能支持从预定义列表或基于模板生成数据,增加了数据生成的多样性,使测试覆盖更广。
· 支持多线程生成:对于需要大量数据的场景,它可以利用多线程并行生成,大大缩短了数据准备的时间,让你能够更快地进行性能测试和压力测试。
· 跨平台兼容性:作为Java编写的项目,它可以在任何支持Java的环境中运行,这意味着无论你在Windows、macOS还是Linux上开发,都能方便地使用它。
产品使用案例
· 假设你在开发一个电商网站,需要测试用户的注册功能。你可以使用这个工具生成1000个随机姓名、邮箱地址和手机号码,来填充用户数据库,确保你的注册流程在高并发情况下也能正常工作,不必担心用户数据不够而无法充分测试。
· 你在开发一个社交应用,需要测试用户发布动态的功能。你可以让这个工具生成包含不同长度文本、图片URL(可以是占位符)和时间戳的动态数据,用来模拟用户发布内容,检测应用在处理各种类型动态时的稳定性和性能。
· 你正在做一个内部管理系统,需要一个包含各种权限和角色的用户列表来测试权限控制。你可以定义一个用户模型,要求包含用户名、密码(哈希值)、所属部门、角色列表等,然后生成上百个这样的用户,来全面验证你的权限分配逻辑是否正确。
· 你在进行API性能测试,需要大量的请求体数据。你可以使用这个工具生成符合API接口要求的JSON或XML格式的数据,比如产品信息、订单详情等,来模拟大量的客户端请求,检测你的API在高负载下的响应时间和吞吐量。
· 在开发一个数据分析平台时,你需要一个包含时间序列数据的样本集来开发和测试你的分析算法。你可以让这个工具生成过去一年的每日销售额、访问量等数据,并且可以加入一些随机噪声,来模拟真实的市场波动,使你的分析模型更加鲁棒。
80
数据结构深度探索者
作者
shhabmlkawy
描述
这是一个包罗万象的1600页数据结构学习宝典,内含130个原创的学术级问题,每个问题都附带详尽的解答、证明、摊还分析、图示和深入解释。它不仅是大学课程的得力助手,更是工程师自我提升和技术面试准备的利器,能让你对堆、树、并查集、区间最值查询(RMQ)、哈希、字符串结构等核心概念有透彻的理解。特别之处在于,作者还贡献了两个自创的全新数据结构——分层摘要堆(LSH)和三连堆(Triple-L Heap),并提供详细的解析和应用场景。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个内容极其丰富的在线学习资源,主要是一本关于高级数据结构的深度学习书籍。它不仅仅是知识的堆砌,更侧重于通过大量的原创问题和严谨的解答来帮助读者深入理解各种数据结构的工作原理、性能分析以及实际应用。书中还包含作者自己设计的新型数据结构,这展示了作者在数据结构领域的创新能力和对该领域的热情。这本书就像一个超级工具箱,里面装满了解决复杂计算问题的“零件”和“说明书”,能让你在面对各种技术挑战时,拥有更扎实的理论基础和更巧妙的解题思路。
如何使用它?
对于开发者而言,你可以将这本书作为提升算法和数据结构能力的终极参考。在日常开发中遇到性能瓶颈、需要优化代码时,可以翻阅书中相关章节,找到合适的数据结构来解决问题。对于准备技术面试的开发者,这本书提供了大量与面试题风格相似的挑战性问题,通过解决这些问题,可以系统地训练你的逻辑思维和问题解决能力,从而在面试中脱颖而出。你可以在学习新概念时使用它,也可以在遇到实际开发难题时,将其作为求助的“百科全书”。
产品核心功能
· 提供130个原创学术级数据结构问题及完整解决方案,帮助开发者深入理解并熟练运用各种数据结构,提升解决实际编程问题的能力。
· 包含详细的摊还分析和数学证明,让开发者理解数据结构在不同操作下的性能表现,为编写高效代码提供理论支撑,最终实现性能的飞跃。
· 介绍两种作者原创的新型数据结构(LSH和Triple-L Heap),为开发者提供解决特定问题的创新工具,拓展技术视野,激发新的技术灵感。
· 涵盖堆、树、并查集、RMQ、哈希、字符串结构等核心数据结构,是开发者系统学习和回顾计算机科学基础知识的宝库,构建坚实的计算机科学功底。
· 书中问题设计具有技术面试风格,能帮助开发者有效备战面试,提高在复杂算法和数据结构问题上的应对能力,增加获得心仪Offer的几率。
产品使用案例
· 在开发一个需要频繁插入和删除元素的动态排行榜系统时,开发者可以通过书中关于堆(Heap)的章节,选择最小堆或最大堆来高效地维护排行榜的顺序,避免全量排序的性能损耗,这比使用简单数组的效率高出许多。
· 当需要设计一个能够快速合并不相交集合并查询元素所属集合的系统时,开发者可以参考书中关于并查集(Union-Find)的章节,利用其路径压缩和按秩合并的优化技巧,实现近乎常数时间复杂度的操作,大大提升系统吞吐量。
· 在进行大规模基因序列比对时,开发者可以学习书中关于字符串结构(如后缀树、后缀数组)的知识,利用它们来高效地检索和匹配字符串模式,解决传统暴力匹配的低效问题。
· 当需要实现一个能够快速查找数组中任意区间最大值的查询功能时,开发者可以学习书中关于区间最值查询(RMQ)的数据结构,如线段树或稀疏表,从而在毫秒级内响应查询需求,满足实时分析的需求。
· 在开发需要高效进行批量更新和范围查询的数据库索引时,开发者可以研究书中关于B树和B+树的章节,理解其平衡和分裂机制,从而优化数据库的读写性能,保证大规模数据处理的稳定性。
81
云码协作者Wegent
作者
qdaxb
描述
Wegent是一个开源的云端智能代码代理协作平台,它允许开发者通过简单的YAML配置文件和Web界面,就能组建和运行由AI助手组成的团队。它最大的创新在于,能够将底层的AI代码引擎(如Agno和Claude)与上层的对话和编码模式结合,并且支持独立的沙箱环境,让多个AI团队同时工作。这解决了传统AI开发中协作不便、环境隔离难、以及AI能力难以集成的问题,让AI真正成为开发过程中的得力助手。
人气
点赞 1
评论数 0
这个产品是什么?
Wegent是一个让AI助手像团队一样协同工作的平台。它的核心技术在于:1. 配置驱动的AI团队:你可以用YAML文件(一种易于理解的配置格式)来定义AI助手们的角色、任务和协作方式,就像组建一个真人团队一样,而且还有一个可视化的Web界面来管理。这比自己从头写代码来指挥AI要省事得多。2. 多种AI执行引擎:它底层用了Agno和Claude这样的AI模型,这些模型很擅长理解和生成代码。3. 隔离的沙箱环境:每个AI团队都在一个独立的“沙箱”里工作,这意味着即便你有好几个AI团队在同时处理不同的任务,它们之间也不会互相干扰,就像每个团队都有自己的独立办公室。4. 高级协作模式:AI助手们可以按照不同的模式协作,比如并行处理、有一个“领导者”来协调等,这对于处理像从海量新闻中提取洞察或检索信息这样的复杂任务非常有用。所以,它就像一个为AI助手设计的智能项目管理系统,让它们能够更有效地合作完成任务。
如何使用它?
开发者可以使用Wegent来自动化各种开发流程。最常见的方式是通过YAML文件来定义AI团队。例如,你可以创建一个负责代码重构的AI团队,配置好它的成员(比如一个专门负责查找bug的AI,一个负责提供优化建议的AI)以及它们的协作方式。然后,将你的代码仓库(比如GitHub或GitLab)连接到Wegent,AI团队就会自动开始工作,进行代码审查、重构或者生成单元测试。它还可以用于分析项目需求,生成初步的架构设计,甚至是协助完成AI驱动的功能开发。使用场景非常灵活,可以集成到CI/CD流水线中,也可以作为独立的AI辅助开发工具。
产品核心功能
· AI团队配置与管理:通过YAML配置文件和Web UI定义AI助手及其协作规则,价值在于极大地简化了AI agent的部署和定制,无需编写复杂的二次开发代码,让开发者能快速搭建定制化的AI开发辅助流程。
· 多模式AI执行:支持AI助手在对话和编码模式下工作,价值在于能够适应不同的开发需求,既能进行智能问答、信息检索,也能直接参与代码生成、审查和重构,提供更全面的开发支持。
· 独立沙箱环境:每个AI团队运行在独立的沙箱中,价值在于确保了不同AI团队任务执行的稳定性和安全性,避免了资源冲突和数据污染,允许多个AI团队并行高效地工作。
· 灵活的AI协作模式:支持对话模式下的并行、领导者等协作模式,价值在于能够应对复杂的工作流,如从海量信息中提取关键洞察或进行深度内容检索,提升AI团队解决复杂问题的能力。
· AI驱动的编码集成:整合GitHub/GitLab等代码服务,价值在于实现了AI驱动的开发、代码审查等工作流,将AI的能力直接融入到软件开发的生命周期中,提高开发效率和代码质量。
产品使用案例
· 场景:需要对一个大型代码库进行代码审查,找出潜在的bug和性能瓶颈。使用Wegent,开发者可以配置一个包含代码分析AI、建议优化AI的团队,并将其连接到代码仓库。Wegent会自动运行代码审查,并提供详细的报告和修复建议,解决了人工代码审查耗时耗力的痛点。
· 场景:项目需求文档复杂,需要快速提取关键信息并生成初步的技术方案。开发者可以创建一个信息提取AI团队,配置其阅读和分析需求文档,然后生成摘要和关键技术点列表。这大大缩短了项目启动初期的信息梳理和方案设计时间。
· 场景:需要为现有代码库生成全面的单元测试。Wegent的编码模式可以与GitHub集成,一个专门负责编写测试的AI团队可以分析现有代码,自动生成和编写符合规范的单元测试用例,提高了代码的健壮性和可维护性。
· 场景:开发者在开发过程中遇到技术难题,需要快速获取解决方案。可以通过Wegent的对话模式,组建一个技术问答AI团队,输入问题描述,AI团队会根据其知识库和分析能力,提供相关的技术解决方案或参考资料,帮助开发者快速克服技术障碍。
82
量子投资组合优化器
url
作者
Hellene
描述
一个利用量子计算技术,让没有金融专业知识的普通人也能在几秒钟内构建股票投资组合的工具。它解决了传统投资组合构建过程复杂、需要专业知识的门槛问题,通过先进的量子算法,实现更优化的资产配置。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个基于量子计算的创新项目,旨在 democratize 股票投资组合的构建。它的核心技术在于利用量子计算机的并行计算能力和叠加态特性,来解决复杂的优化问题。简单来说,就像是用一台超级强大的计算器,在海量股票数据中,快速找到最适合你风险偏好和收益目标的投资组合。与传统计算机只能一个一个方案地尝试不同,量子计算机可以同时评估无数种可能性,从而找到更优解。所以这对我有什么用?即使你对金融一窍不通,也能借助这项前沿技术,构建出理论上更科学、更高效的投资方案。
如何使用它?
开发者可以通过集成这个项目提供的API接口,将其嵌入到自己的金融应用、投资平台或者个人理财工具中。用户在你的应用里输入自己的投资目标(例如:风险承受能力、期望收益率、投资期限等),项目就会通过量子计算进行快速分析,并返回一个优化后的股票组合建议。它提供了一种新的、更高效的算法来解决投资组合的优化问题,为开发者提供了构建下一代智能投资工具的可能性。所以这对我有什么用?你可以用它来增强你现有应用的金融服务能力,或者开发全新的、以用户为中心的智能投顾产品。
产品核心功能
· 量子驱动的投资组合优化:利用量子退火(Quantum Annealing)或量子近似优化算法(QAOA)等量子计算技术,在巨大的状态空间中寻找最优的资产配置方案,最大化收益或最小化风险。这意味着它能够比传统算法更有效地发现潜在的最佳组合。所以这对我有什么用?它能帮助你找到比传统方法更可能赚钱或更稳健的投资组合。
· 低门槛金融应用开发:通过封装复杂的量子算法,提供简单易用的API,让开发者无需深入了解量子物理或复杂的金融建模,即可构建出具有前沿技术的投资工具。这大大降低了开发难度。所以这对我有什么用?你可以快速地利用尖端技术开发出创新的金融产品,而不用花费大量时间去学习和实现底层技术。
· 秒级投资组合生成:相较于传统需要数小时甚至数天的计算时间,该项目声称能在几秒钟内完成投资组合的构建,极大地提升了用户体验和响应速度。所以这对我有什么用?用户可以即时获得投资建议,加快决策过程,抓住稍纵即逝的市场机会。
产品使用案例
· 一款个人理财App,用户输入期望的月度投资额和风险等级,App即刻调用量子投资组合优化器,在几秒内生成一个包含股票、债券等资产的多元化投资组合,并解释每种资产的配置原因。这解决了用户不知道如何分散投资、如何平衡风险收益的问题。
· 一个面向机构投资者的交易平台,在其量化交易策略的构建模块中集成量子投资组合优化器,用于快速回测和生成不同市场条件下的最优资产配置方案。这提升了交易策略的发现效率和在复杂市场下的适应性。
· 一个金融教育网站,提供模拟投资功能,学生可以使用量子投资组合优化器来构建自己的虚拟投资组合,并观察其在不同市场情境下的表现。这为学习投资理论的学生提供了一个直观、高效的学习工具,让他们体验前沿技术在实际金融问题中的应用。
83
Journiv: 私有化记忆守护者
作者
swalabtech
描述
Journiv 是一款旨在让你完全掌控自己数字记忆的开源、私有化日记应用。它提供类似 Day One 的功能,如“往日回顾”、“每日提示”和简洁的写作体验,并通过 Docker 轻松部署。核心创新在于将隐私放在首位,让你的日记数据永远属于你自己,而不是存储在第三方云端。
人气
点赞 1
评论数 0
这个产品是什么?
Journiv 是一个让你可以在自己服务器上运行的日记软件,非常注重个人隐私。你可以把所有珍贵的记忆、想法和感受都记录在这里,就像一个私人的数字日记本。它和市面上一些流行的日记应用(比如 Day One)很像,有“往日回顾”的功能,会提醒你去年今天发生的事情,还有每天都会给你一些写作的灵感提示。最厉害的一点是,所有这些数据都存放在你自己控制的服务器上,别人是看不到的,完全不用担心数据泄露。
如何使用它?
开发者可以将 Journiv 作为一个 Docker 镜像来轻松部署到自己的服务器、NAS 或者任何支持 Docker 的设备上。一旦部署成功,就可以通过浏览器访问 Journiv 的 Web 界面进行日记的撰写、管理和查看。它可以集成到现有的个人技术栈中,作为私有的数据存储解决方案。例如,你可以把它部署在树莓派上,随时随地记录生活点滴。
产品核心功能
· 私有化数据存储:将你的所有日记数据安全地保存在你自己的服务器上,杜绝第三方数据泄露风险,让你安心记录,数据永远属于你。
· 往日回顾功能:通过“On This Day”功能,系统会智能地为你展示过去同一天的日记记录,唤醒美好回忆,让你更容易回顾过去,总结经验。
· 每日写作提示:提供每日随机的写作主题或问题,帮助你克服写作障碍,激发思考,让日记记录更丰富,更容易坚持。
· 情绪追踪:内置的情绪记录功能,让你在记录日记的同时,也能标记当下的心情,长期来看可以帮助你分析情绪模式,了解自己的心理健康状况。
· 极简写作界面:提供一个干净、无干扰的写作环境,让你能够专注于表达和记录,提升写作效率和沉浸感。
· Docker 部署:使用 Docker 技术,使得部署过程极其简单快捷,即使是技术新手也能轻松上手,快速搭建自己的私有化日记服务。
产品使用案例
· 个人隐私守护场景:一位注重个人隐私的用户,不想将敏感的个人日记数据上传到云端,他使用 Journiv 部署在自己的家庭服务器上,确保所有回忆都只掌握在自己手中。
· 情感记录与反思场景:一位学生希望记录每天的学习心得和生活感悟,并追踪自己的情绪变化,Journiv 的每日提示和情绪追踪功能帮助他更好地进行自我反思和成长。
· 家庭记忆珍藏场景:一位年轻的父亲,希望记录下孩子成长的点点滴滴,以及家庭的温馨时刻,Journiv 的“往日回顾”功能可以在多年后唤起这些宝贵的回忆,而私有化存储则保证了这些家庭照片和文字的私密性。
· 开发者技术实验场景:一位对自托管和数据所有权感兴趣的开发者,将 Journiv 部署在他的个人 VPS 上,以此来学习和实践 Docker、Web 应用部署等技术,同时解决了自己对隐私日记的需求。
· 长久内容创作场景:一位需要长期积累写作素材和灵感的作家,利用 Journiv 的 prompt 功能和简洁的写作界面,持续创作和管理自己的文学草稿,数据安全且易于访问。
84
意图驱动型客户挖掘与Reddit内容创生器
作者
elephantisfast
描述
该项目是一个集成了AI驱动的客户搜索和Reddit内容创作工具。它通过理解用户意图,智能地从海量信息中筛选出潜在客户;同时,它还能深度分析Reddit上的热门内容,帮助开发者快速生成具有传播潜力的文章。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个利用自然语言处理(NLP)和数据挖掘技术,帮助开发者高效找到潜在客户并创作病毒式内容的工具。它能理解你想要什么样的客户(比如:某个行业、特定职位的决策者),然后像一个专业的搜寻者一样,在公开信息中找到这些线索。更厉害的是,它还能学习Reddit上什么内容能火起来,并模仿这些成功模式帮你写文章,让你事半功倍。所以,这对我意味着,我能更快地找到我的潜在客户,并且用更聪明的方式写出能吸引人的文章。
如何使用它?
开发者可以通过输入清晰的客户画像描述,比如“寻找有AI预算的初创公司CEO”,来启动客户挖掘。AI会解析这些关键词和“信号”(例如公司增长速度、近期融资情况等),快速返回匹配的潜在客户名单。对于内容创作,你只需提供一个主题或类别,系统会自动抓取Reddit上相关的热门帖子,分析其受欢迎的原因,然后基于这些分析结果,为你提供内容创作的框架和灵感,甚至直接帮你生成初稿。你可以将其视为一个AI助手,帮你完成繁琐的市场调研和内容策划工作。所以,这对我意味着,我可以在几分钟内得到一堆有价值的客户线索,并有一份AI生成的、极有可能受欢迎的文章草稿。
产品核心功能
· 基于意图的智能客户搜索:通过自然语言描述,AI能理解并搜索符合特定条件的潜在客户,极大地提高了客户挖掘的精准度和效率。这能为销售和市场团队节省大量研究时间,直接接触更有价值的潜在客户。
· Reddit热门内容分析与模式提炼:系统自动抓取Reddit上的热门帖子,并分析其传播的内在逻辑,帮助开发者理解内容吸引人的核心要素。这使得开发者能够学习到真实有效的病毒式传播规律,用于指导自己的内容创作。
· AI驱动的内容生成助手:基于对Reddit热门内容的分析,该工具能辅助开发者撰写文章,提供创作思路、结构建议甚至初步草稿。这大大降低了内容创作的门槛,让开发者能快速产出高质量、有传播力的内容。
· 多平台内容扩散潜力预测:通过分析Reddit上的内容表现,可以预判其在其他平台(如Twitter、Facebook等)的传播潜力,帮助开发者更有效地规划内容分发策略。这意味着你可以把精力放在最有可能成功的那些内容上。
产品使用案例
· 一个SaaS公司创始人想找到更多企业级客户。他输入“寻找有数据分析需求,并且 recently 进行了B轮融资的科技公司CTO”,工具迅速返回了一份名单,并附带了这些CTO的LinkedIn资料和公司最新动态,大大缩短了销售接触时间。
· 一位内容营销人员想写一篇关于“AI在教育领域的应用”的文章,但他不知道如何吸引读者。工具分析了Reddit上关于此话题的火爆帖子,发现“学生个性化学习路径”和“AI教师助手”是热点。于是,它生成了一个包含这些内容的文章大纲,并提供了几个引人入胜的标题选项,帮助作者快速定位文章切入点。
· 一个初创公司在开发一款新的开发者工具,他们想通过技术博客来吸引早期用户。他们输入“关于提高代码审查效率的工具”,工具挖掘出Reddit上相关讨论中最受欢迎的几个解决方案,并提炼出用户最关心的问题(例如:如何减少人工错误、如何自动化重复性检查),帮助开发者撰写了一篇直击痛点、引发共鸣的技术文章。
· 一位独立开发者想推广他的新App。他利用该工具分析了App Store和Product Hunt上类似产品的成功推广案例,学习了它们是如何利用故事化叙事和用户见证来吸引第一批用户的,从而优化了自己的推广策略。
85
GoLang多租户Agent的开源SDK
作者
tech-aguirre
描述
这是一个用Go语言编写的开源SDK,专门为构建支持多租户的Agent应用而设计。它解决了在Agent(你可以理解为自动化执行任务的智能助手或程序)设计中,如何安全、高效地隔离不同用户的数据和权限的难题。其创新点在于提供了一个轻量级、高性能的架构,让开发者可以更容易地在Agent中实现租户隔离,而无需依赖重量级的Python框架。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个用Go语言开发的、开源的SDK,用于创建能够服务多个不同客户(租户)的Agent程序。在开发Agent时,一个常见的问题是如何让同一个Agent实例能够为多个用户提供服务,同时又要确保每个用户的数据和操作是彼此隔离的,互不干扰。这个SDK提供了一套核心的解决方案,让开发者能够以一种非常高效、安全的方式来实现这种多租户的隔离,而且它全部用Go语言编写,这意味着它会非常快速,并且容易部署,不需要额外安装Python这类环境。
如何使用它?
开发者可以将这个SDK集成到他们正在使用Go语言开发的Agent项目中。举个例子,如果你正在构建一个用于自动化处理用户请求的Agent,比如一个自动回复邮件的Agent,或者一个自动化部署服务的Agent,并且你希望这个Agent能够同时为你的不同客户提供服务,那么你就可以使用这个SDK。通过SDK提供的接口,你可以为每个客户(租户)设置独立的配置、数据存储和访问权限。这样,当Agent收到一个请求时,SDK就能自动识别这个请求属于哪个客户,并只允许它访问该客户的数据和执行相应的操作,确保了数据的安全和隐私。
产品核心功能
· 租户隔离核心逻辑:通过代码级别的机制,确保不同租户的数据和配置是完全独立的,防止数据泄露或被串改,这对于保护用户隐私和商业数据至关重要。
· 高性能处理:利用Go语言的并发特性,实现对大量租户请求的高效处理,让Agent能够快速响应,提升用户体验,适用于对响应速度要求高的场景。
· 无Python依赖:完全使用Go语言编写,简化了项目的部署和维护,开发者无需担心Python环境的兼容性问题,让项目更加轻量和稳定。
· 灵活配置管理:允许开发者为每个租户配置不同的参数和行为,使得Agent能够更好地适应不同客户的个性化需求,例如不同的API密钥、存储路径或处理规则。
· 可插拔式扩展:SDK设计允许开发者方便地集成自定义的存储后端或认证机制,让Agent能够根据具体业务需求进行定制化,满足多样化的应用场景。
产品使用案例
· 为SaaS平台构建多租户的客服机器人Agent:当一个客服机器人需要同时为多个SaaS平台的用户提供服务时,使用此SDK可以确保每个平台的数据(如用户信息、对话记录)不被混淆,并且机器人可以根据不同平台的特定配置(如API接口)来工作,大大简化了多租户机器人的开发。
· 构建支持按需扩展的自动化部署Agent:一个允许不同团队或客户自行部署应用的Agent,可以通过此SDK为每个团队或客户划分独立的部署环境和资源配额,防止一个用户的操作影响到其他用户,确保了部署过程的稳定性和安全性。
· 开发一个面向多个API提供商的聚合查询Agent:如果一个Agent需要同时查询多个不同公司提供的API,并且每个API的使用方式和认证方式可能不同,此SDK可以帮助开发者为每个API提供商(租户)管理独立的API密钥和配置,确保在调用时能够正确地识别和认证,从而聚合不同来源的数据。
86
括号匹配多解引擎
作者
smatthewaf
描述
这个项目展示了解决“有效的括号”(LeetCode #20)这一经典编程问题的四种不同方法。它的技术创新在于,不仅仅提供一个简单的答案,而是深入探讨了多种技术思路,包括使用栈(Stack)、递归(Recursion)以及其他一些不那么直观但同样高效的算法。这对于开发者来说,不仅是学习如何解决一个具体问题,更是理解不同数据结构和算法在实际应用中的权衡与选择。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个用代码实现“有效的括号”问题的项目,它提供了四种不同的解决方案。所谓“有效的括号”,就是指一对一对的括号,比如圆括号()、方括号[]、花括号{},必须是成对出现,而且打开的括号要在关闭的括号之前。比如 '()' 是有效的,'()[]{}' 也是有效的,但 '(]' 就不是有效的,'([)]' 也不是有效的。这个项目厉害的地方在于,它不只给你一种写法,而是用不同的编程技巧,比如利用“后进先出”的栈(Stack)来跟踪开括号,或者用递归(Recursion)的思路去拆解问题。它的技术创新在于,它深入挖掘了这个问题,揭示了不同算法在处理相同问题时的优雅之处和性能差异,让开发者能看到解决同一个问题的多种可能性。
如何使用它?
开发者可以把这个项目当作学习和参考的资源。当你遇到类似需要检查成对出现的元素(比如代码中的标签、API调用等)的问题时,可以来这里看看。你可以直接阅读代码,理解每种解法的逻辑;也可以在自己的项目中,针对特定的性能要求或代码风格,选择最适合的算法实现。比如,如果你需要快速解决问题,可以参考栈的解法;如果想锻炼递归思维,可以研究递归的解法。它是一个学习新算法、巩固旧知识的实用工具。
产品核心功能
· 基于栈(Stack)的括号匹配:利用栈先进后出的特性,将开括号压栈,遇到闭括号时出栈对比,匹配成功则继续,否则视为无效。这个功能的价值在于,它提供了一种最直观、最容易理解的解决这类问题的通用方法,特别适用于需要处理嵌套结构的情况。
· 递归(Recursion)解法:通过将问题分解为更小的子问题来解决。比如,找到一对匹配的括号,然后将它们从字符串中移除,继续处理剩余部分。这个功能的价值在于,它展示了如何用一种函数调用自身的方式来解决问题,能锻炼开发者对递归思维的理解,对于处理具有自相似结构的复杂问题非常有帮助。
· 其他优化解法:可能包含一些更精巧的算法,比如利用特定数据结构或技巧来提高效率。这些解法的价值在于,它们能启发开发者思考如何优化算法,提升程序的性能,找到处理同类问题的更优解。
· 多种算法对比:项目提供了多种解决方案,允许开发者直观地比较它们在实现逻辑、代码复杂度以及潜在性能上的差异。这个功能的价值在于,它能帮助开发者根据实际需求,选择最合适的工具,而不是被单一的解决方案束缚。
产品使用案例
· 在代码编辑器中实现括号高亮和错误提示:当开发者编写代码时,如果括号不匹配,可以通过这个项目的算法实时检测出来,并进行高亮提示,极大地提高了编码效率和减少了语法错误。
· 解析配置文件或数据格式:很多配置文件(如XML、JSON)或数据格式中都有括号或成对的符号,可以使用这些算法来验证格式的正确性,确保数据被正确读取和解析。
· 构建编译器或解释器:在处理编程语言的语法分析阶段,需要检查代码中的各种符号是否正确配对,这个项目中的算法可以作为基础,用于构建更复杂的语法解析器。
· 网络协议数据校验:在某些网络通信场景下,传输的数据包可能包含成对的起始符和结束符,用来标志数据块的边界,可以使用这个项目中的技术来校验这些数据包的完整性和正确性。
87
Shelly Systems: 代码驱动的流程建模引擎
作者
chrisshella2
描述
Shelly Systems 是一个创新的工具,它允许开发者以代码(YAML格式)的方式来描述和设计复杂的系统流程。它最大的亮点在于,你可以像在Excel表格中使用公式一样,在YAML文件中编写逻辑,并自动生成流程图。这解决了传统图形化工具难以处理复杂、变化频繁的系统流程的痛点,提供了一个更高效、可维护的解决方案。
人气
点赞 1
评论数 0
这个产品是什么?
Shelly Systems 是一个将流程和系统建模“代码化”的工具。它的核心技术是将我们熟悉的YAML文件(一种人类可读的数据格式)与电子表格的公式计算能力结合起来。想象一下,你不再需要拖拽方框连线来画流程图,而是通过编写YAML文件来定义流程的步骤、逻辑和它们之间的关系。更厉害的是,它还支持类Excel的公式,这意味着你可以用公式来驱动流程的走向、计算某些值,或者根据数据动态生成流程。最终,这些YAML代码会被解析成清晰的流程图,成为你系统设计的“单一事实来源”。所以,它提供了一种用代码管理系统复杂性的新方式,比传统图形工具更灵活,更容易追踪和更新。
如何使用它?
开发者可以使用Shelly Systems来定义应用程序的业务逻辑、用户交互流程、数据处理管道或者任何需要清晰可视化和逻辑描述的系统组件。你可以编写YAML文件来描述状态转移、条件分支、并行处理等,并利用内置的公式功能实现动态逻辑。例如,在一个电商系统中,你可以用YAML定义用户下单后的各个环节,并用公式判断是否需要触发风控检查。然后,Shelly Systems会将这些YAML代码转化为流程图,方便团队成员理解和审查。它也可以集成到CI/CD流程中,在代码提交时自动生成最新的流程图,确保文档与代码实时同步。所以,当你需要清晰地展示和管理复杂的业务流程,或者需要一个可执行、可版本化的流程描述时,Shelly Systems就能派上用场。
产品核心功能
· YAML驱动的流程定义:使用易于阅读和编写的YAML格式来描述流程图的节点、连接线以及它们之间的逻辑关系,实现流程设计的代码化,便于版本控制和团队协作,解决了流程文档与代码不同步的问题。
· 电子表格式公式支持:在YAML文件中引入类似Excel的公式功能,让流程的逻辑和行为可以通过数据驱动和计算来动态生成,提高了流程设计的灵活性和智能化,使得处理复杂、动态的业务逻辑成为可能。
· 自动流程图生成:将编写的YAML代码解析并自动渲染成可视化的流程图,省去了手动绘制的时间和精力,并保证了图与代码的一致性,提供了清晰的系统视图。
· 单一事实来源:以代码为核心,确保了流程描述的精确性和一致性,成为系统分析和设计的可靠依据,避免了传统工具可能出现的图文不符或信息孤岛。
· 系统建模能力:不仅限于简单的流程图,还可以用于更广泛的系统建模,描述系统组件、状态和交互,为复杂系统的设计和分析提供了强大的工具支持。
产品使用案例
· 在一个微服务架构中,开发者可以使用Shelly Systems来描述不同服务之间的API调用流程和数据流转。通过YAML编写,可以清晰地展示请求如何从前端传递到各个后端服务,以及数据如何在服务间传递和处理。当某个服务接口发生变化时,只需更新YAML文件,流程图会自动更新,保证了文档的实时性,避免了因文档过时导致的服务集成问题。
· 在构建一个复杂的业务流程时,比如订单处理流程,可以使用Shelly Systems来定义订单的各个状态(待支付、已支付、发货中、已完成等)以及状态之间的转移条件。通过公式,可以实现根据订单金额、用户等级等条件触发不同的分支流程,例如高价值订单自动进入人工审核。这使得业务流程的设计更加灵活和自动化,并且易于迭代和优化。
· 对于前端开发者,可以使用Shelly Systems来设计和可视化用户在Web应用中的操作流程。例如,用户注册、登录、填写表单等一系列交互过程。用YAML描述这些流程,可以帮助团队成员更好地理解用户旅程,发现潜在的用户体验问题,并与UI/UX设计师进行高效沟通,从而提升产品用户体验。
· 在数据科学项目中,可以使用Shelly Systems来描述数据ETL(抽取、转换、加载)流程。YAML可以用来定义数据源、数据清洗步骤、特征工程以及模型训练和部署的整个管道。公式可以用于定义数据转换的逻辑或控制流程的执行顺序。这提供了一个清晰、可重现的数据处理流程,便于团队协作和项目复盘。
88
SuperCurate: 知识碎片搜集与组织引擎
作者
superdocs1
描述
SuperCurate 是一个专注于笔记、网页剪辑、图片和PDF文档的快速检索与整理工具。它就像一个智能的数字文件柜,能帮助你高效地找到并组织你的各种信息碎片。其核心创新在于其强大的全文搜索能力,即使是PDF文件内的内容也能快速定位并高亮显示,解决信息过载和查找困难的问题,让你的数字资产触手可及。
人气
点赞 1
评论数 0
这个产品是什么?
SuperCurate 是一个旨在解决信息爆炸时代个人知识管理难题的工具。想象一下,你平时会保存各种各样的信息:网页上的精彩文章、工作中的会议纪要、灵感闪现的笔记、重要的PDF报告,还有一些有用的图片。这些信息分散在不同的地方,当你想找某个具体内容时,往往大海捞针。SuperCurate 通过强大的技术手段,将这些信息汇集起来,并提供超快的搜索功能。它的创新之处在于,不仅能搜索文本内容,还能深入PDF文件中查找文字,并且能直接跳转到特定页面并高亮显示你想找的内容,让你瞬间锁定目标,极大地提升了信息检索的效率和准确性。
如何使用它?
开发者可以通过安装SuperCurate的Chrome扩展程序,轻松地将浏览的网页内容一键保存到你的SuperCurate库中。对于现有的笔记(如Evernote的ENEX文件、Markdown文件)、图片和PDF文档,也可以直接导入。一旦内容被导入,你就可以利用其提供的强大搜索功能,输入关键词来查找。你可以设置各种过滤器,帮助你缩小搜索范围,更快地找到所需信息。此外,你还可以将相关的笔记和剪辑组织到不同的“集合”(Collections)中,方便管理和回顾。举例来说,你可以为某个项目创建一个集合,将所有与之相关的资料都放进去,需要时一搜即得。
产品核心功能
· 强大的跨格式内容导入能力: 支持从Evernote(ENEX)、Markdown、PDF、图片等多种格式导入信息,解决了信息迁移和整合的痛点,让你的所有数字资产都能在一个地方被管理。
· 极速全文搜索与过滤: 能够快速地在海量信息中找到你需要的关键词,并通过多种过滤器(如日期、标签、来源等)精确筛选,大大节省了查找信息的时间,让你不再迷失在信息的海洋里。
· PDF内嵌内容搜索与高亮: 能够搜索PDF文件内部的文字内容,并直接跳转到对应页面高亮显示,这是传统文件管理器难以做到的,解决了阅读PDF时查找特定信息效率低下的问题。
· 内容组织到集合: 允许用户将零散的信息按照项目、主题或任何自定义的逻辑组织成一个个“集合”,方便进行系统性的回顾和管理,让你的知识库更有条理,易于构建个人知识体系。
· 一键网页剪辑工具: 提供类似于Evernote Web Clipper的浏览器扩展,方便用户随时保存有价值的网页内容到SuperCurate库中,不错过任何有用的信息,随时随地捕捉灵感。
产品使用案例
· 学术研究场景: 研究人员需要查阅大量文献资料,SuperCurate可以帮助导入PDF论文,快速搜索其中的关键术语、研究方法或结论,并直接跳转到具体页面,极大地提高了研究效率。
· 项目开发与管理: 开发者在进行项目时,会收集各种技术文档、API参考、用户反馈和会议记录。SuperCurate可以将这些信息统一导入,通过关键词搜索快速找到特定技术细节或解决方案,避免重复造轮子,提高开发效率。
· 个人学习与知识整理: 学生或终身学习者在网上学习时,会保存大量的文章、教程和电子书。SuperCurate能够帮助他们将这些内容有序地管理起来,并通过搜索快速回顾学习过的知识点,巩固记忆。
· 内容创作者的灵感库: 内容创作者在日常生活中会遇到各种激发灵感的素材,如图片、文章片段、网页设计等。SuperCurate可以将这些碎片化信息收集并组织,需要创作时,通过关键词搜索就能快速找到所需素材,激发创作灵感。
89
即时预告片助手 (Instant Trailer Buddy)
作者
naimurhasanrwd
描述
一个浏览器扩展程序,能让你在任何网页上,只需右键点击电影标题,就能立即在弹出窗口中观看预告片,彻底告别手动复制搜索的繁琐,让你不再为选择烂片浪费宝贵时间。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个浏览器扩展程序,它的核心技术是利用了网页内容抓取和YouTube API(或者类似的视频搜索接口)。当你右键点击网页上的某个电影标题时,它会捕捉到这个标题,然后通过一个智能的搜索机制(可能是直接匹配YouTube或者利用一些电影数据库信息)找到对应的电影预告片。最巧妙的地方在于,它不是简单地跳转到YouTube,而是直接在一个小小的弹出窗口里播放预告片。即使是一些禁止右键操作的网站,它也能通过组合键(Alt/Option + 右键)来激活,确保了使用的便捷性。
如何使用它?
开发者可以将这个扩展程序安装到Chrome、Firefox等主流浏览器中。安装完成后,当你在浏览任何一个网页(比如流媒体网站、电影资讯网站、甚至是在线论坛里看到有人讨论电影)时,看到一个电影标题,只需鼠标右键点击该标题,一个包含电影预告片的弹出窗口就会立即出现。如果因为网站限制无法直接右键,可以尝试按住Alt(或Option)键再进行右键点击。此外,你也可以点击浏览器工具栏上的扩展程序图标,手动输入电影名称进行搜索。
产品核心功能
· 电影标题快速识别与预告片检索: 自动识别页面中的电影标题,并实时搜索和关联对应的预告片,解决了手动查找预告片耗时耗力的问题,极大地提升了观影前的决策效率。
· 即时弹出式视频播放: 无需跳转到其他网站,直接在当前页面弹出窗口播放预告片,让信息获取更加流畅,避免了多窗口切换的干扰,优化了用户体验。
· 跨网站右键触发机制: 支持在各种网页上通过右键菜单快速触发预告片播放,并能绕过部分网站的右键限制,确保了功能的普适性和可靠性,适用于各种浏览场景。
· 手动搜索与补充功能: 提供通过扩展程序图标手动搜索电影预告片的功能,作为右键触发的补充,增加了使用的灵活性,即使在特定网页无法有效触发时也能顺利使用。
· 轻量级设计与性能优化: 扩展程序设计简洁,对浏览器性能影响小,确保了流畅的使用体验,不会拖慢网页加载速度,符合黑客文化追求高效简洁的理念。
产品使用案例
· 在本地电影服务器的网页上浏览电影列表时,无需离开当前页面,直接右键点击电影名称即可观看预告片,判断是否值得下载观看,省去了复制标题去YouTube搜索的麻烦,尤其适合时间碎片化的用户。
· 当朋友在聊天群里分享一个电影链接,而你看到的是电影名称时,可以快速右键点击该名称,立即查看预告片,快速了解电影内容,从而做出是否观看的决定。
· 在电影资讯网站或论坛中,看到推荐的电影,可以直接右键点击电影标题观看预告片,快速评估电影质量,决定是否深入了解。
· 一些不支持在线播放预告片的流媒体平台,用户可以通过此扩展程序,将鼠标悬停在电影标题上,通过右键点击立即获取预告片信息,弥补平台功能的不足。
· 开发者在整理或测试电影相关的项目时,可以通过该扩展程序快速获取大量电影预告片,进行视觉素材的收集和参考,提升开发效率。
90
特斯拉车载娱乐屏应用引擎
作者
tesladrivewatch
描述
这是一个为特斯拉车载娱乐系统打造的,允许乘客在驾驶过程中观看YouTube等视频平台的创新应用。它解决了特斯拉车载系统原生不支持第三方视频流媒体服务的痛点,通过巧妙的技术实现,将复杂的视频解码和播放集成到特斯拉的车载环境中,为乘客提供了更丰富的娱乐体验。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个基于特斯拉车载娱乐系统定制的视频播放器应用。它的核心技术在于,能够绕过特斯拉原生的内容限制,直接在车载屏幕上流畅地播放来自YouTube等平台的视频流。这就像是在你的特斯拉车内,安装了一个独立的、功能强大的媒体播放器,而无需任何额外的硬件设备。它的创新之处在于,能够理解并适配特斯拉的车载操作系统,将互联网视频无缝地呈现在驾驶舱内。
如何使用它?
开发者可以将此应用集成到特斯拉的软件生态中。对于普通用户来说,这可能意味着通过特斯拉的应用程序商店(如果未来支持)或者简单的侧载(side-loading)方式来安装。一旦安装完成,乘客只需在停车状态下,通过车载大屏幕的界面选择他们想看的视频,就像使用普通的平板电脑或手机一样方便。它为特斯拉车主提供了一个简单易用的入口,轻松享受在线视频。
产品核心功能
· 视频流解码与播放:能够解析并流畅播放来自互联网的视频数据,这意味着你可以直接在车上看到清晰的视频画面,技术上使用了现代化的编解码器支持。
· 跨平台视频兼容性:支持多种主流视频平台,如YouTube,这意味着你可以观看的内容范围非常广泛,不再受限于特斯拉官方支持的媒体。
· 车载系统集成:完美契合特斯拉的车载操作系统,界面友好,操作直观,确保用户体验流畅,让你可以轻松找到和播放视频。
· 低延迟响应:优化了视频加载和播放的响应速度,减少卡顿,让你在旅途中获得更好的观影感受。
· 免费使用期:提供免费试用到2026年,这意味着你可以无成本地体验这项创新技术,并为开发者提供反馈,共同完善产品。
产品使用案例
· 长途旅行:在长途驾驶中,乘客(非驾驶员)可以通过车载大屏幕观看电影、纪录片或直播,极大地缓解旅途的枯燥,提升乘坐体验。
· 充电等待:在特斯拉充电桩等待充电时,乘客可以利用这段时间观看喜欢的视频内容,将等待时间转化为娱乐时间,提高效率。
· 家庭出行:当家庭成员一同出行时,后座的孩子们可以通过这个应用观看动画片,让父母能更专注于驾驶,同时也能让孩子们乐在其中。
91
WinsleyAI 个人化公关助手
作者
maikop
描述
PitchWell 是一款由 AI 驱动的公关工具,它的核心亮点在于能够学习并模仿你的写作风格,生成高度个性化的公关稿件。它解决了传统公关平台缺乏个性化和无法学习用户独特声音的痛点,通过先进的向量搜索技术,精准匹配合适的媒体和记者,让创始人也能以更低的成本获得专业的公关服务。
人气
点赞 1
评论数 0
这个产品是什么?
WinsleyAI 个人化公关助手是一款智能的公关稿件生成和媒体对接工具。它采用了先进的 AI 技术,特别是自然语言处理(NLP)和向量搜索。'Winsley' 是它的 AI 核心,它通过分析你的写作样本(比如你写的博客、邮件等),不仅仅是理解你喜欢什么样的风格,而是真正学会你说话的‘味道’。然后,它会结合专业的公关稿模板,并且会为你对接的每一位媒体人进行独立的研究。最后,它会使用 Exa 这样的技术进行个性化调整,确保你的公关信息能以最贴切的方式传达给对方。其核心创新点在于,它不是简单地套用模板,而是能‘像你一样’写作,并利用向量搜索技术,找到真正‘对胃口’的媒体联系人,而不是仅仅基于关键词匹配。这就像是拥有了一个懂你、懂媒体的专属公关助理,而且还能以非常实惠的价格提供服务。
如何使用它?
开发者可以通过连接自己的 Gmail 账户来使用 PitchWell。你可以上传你的写作样本,让 WinsleyAI 学习你的风格。然后,你可以设定你的公关目标,比如希望向哪些类型的媒体(播客、记者等)进行推广。WinsleyAI 会帮助你搜索和识别最有可能对你的产品或服务感兴趣的媒体人,并根据你和媒体人的特点,生成个性化的推广信。你还可以通过 Gmail 直接发送这些邮件,并设置后续的跟进提醒。这对于需要进行产品推广、寻求媒体报道的初创公司或个人来说,提供了一个高效且成本可控的解决方案,省去了昂贵的公关公司费用。
产品核心功能
· AI 写作风格模仿:通过分析你的写作样本,AI 能够学习并模仿你独特的语言风格,生成听起来像是你本人写的推广信。这让你与媒体的沟通更具真实性和亲和力,大大提高对方的接受度。
· 精准媒体匹配:利用向量搜索技术,AI 能够深入理解你的产品和媒体人的兴趣领域,找到真正匹配的媒体联系人。这比传统的关键词搜索更有效,确保你的推广信息能够触达最相关的受众,节省你的时间和精力。
· 个性化推广信息生成:AI 会结合你的风格、公关模板以及对媒体人的独立研究,为你定制高度个性化的推广信。这意味着每一封发出去的邮件都是为你量身打造的,能有效吸引媒体人的注意力,增加合作机会。
· 一站式推广管理:支持通过 Gmail 直接发送推广信,并且可以设置自动跟进提醒。这让你能够在一个平台上完成从内容创作到发送、再到跟进的整个公关流程,大大提高工作效率。
· 降低公关成本:提供专业级的公关工具,而无需支付高昂的公关公司月费。这使得初创公司和个人能够以更低的成本获得专业的媒体曝光机会,是黑客文化中“用代码解决问题”的体现。
产品使用案例
· 初创公司创始人希望为新产品争取科技媒体的报道。他可以使用 PitchWell 上传他过去发布的博客文章,让 AI 学习他的技术解读风格。然后,他可以输入产品的核心信息,PitchWell 会自动搜索科技记者,并生成一封包含创始人个人风格,且内容针对该记者报道领域进行个性化调整的推广信。这比他手动写邮件、碰运气找记者要高效得多,并且更有可能获得回复。
· 独立播客主希望邀请嘉宾上他的节目。他可以通过 PitchWell 梳理出他理想的嘉宾类型,并上传他过去发布的节目介绍或社交媒体内容。AI 会帮助他找到可能感兴趣的潜在嘉宾,并生成一封用他独特幽默风格撰写的邀请函,增加了嘉宾接受邀请的可能性。
· SaaS 产品经理需要向行业媒体介绍产品更新。他可以使用 PitchWell,上传产品介绍文档和过往的媒体沟通记录。AI 会帮助他定位最关注该类产品更新的媒体记者,并生成一封突出产品创新点、且用他一贯专业但易懂的语言撰写的介绍邮件,提高被媒体采纳的几率。
92
FeatureBox: 独立开发环境管家
作者
rida
描述
FeatureBox 是一个创新的工具,它能为你的每一个开发任务(比如一个新功能或者一个小改动)创建一个完全独立的开发环境。告别不同分支之间互相干扰、端口冲突、数据库混乱等问题,让并行开发变得像在家里的不同房间工作一样清晰有序。它通过隔离 Git 工作区、开发容器、Docker 网络、数据库、端口和环境变量等,确保每个任务都在自己的“安全岛”里运行,极大地提高了开发效率和稳定性。所以,它能让你在同时处理多个项目或功能时,不再担心“这边改动影响了那边”,让你的开发过程更顺畅,减少调试的痛苦。
人气
点赞 1
评论数 0
这个产品是什么?
FeatureBox 是一个能够为你的每一个软件开发分支或任务创建一个完全隔离的开发环境的工具。想象一下,你正在开发一个网站,同时又在做一个新功能,而且还要修复一个紧急的bug。传统情况下,这些任务可能会共享很多资源,比如运行在同一端口的服务器,或者同一个数据库。这就像你一边在厨房做饭,一边在客厅看电视,而且厨房里的调料和客厅里的零食混在了一起。FeatureBox 就像一个智能的“分房间”系统,它为每个任务分配一个独立的“房间”,这个房间里有它自己的工具(比如代码工作区)、自己的基础设施(比如数据库)、甚至自己的网络连接,它们之间是完全隔开的。这样做的好处是,你在一个“房间”里做的任何改动,都不会影响到其他“房间”的工作,这让你能够更加专注于当前的任务,减少了意外的副作用和调试时间。它不是一个简单的模拟环境,而是创建了真实的、独立的运行环境,让你能够安全地并行处理多个开发任务。
如何使用它?
开发者可以使用 FeatureBox 来管理不同功能或修复的开发流程。当你需要开始一个新功能或者修复一个bug时,只需要通过 FeatureBox 命令创建一个新的“分支环境”。这个环境可以包含它自己独立的 Git 代码仓库视图(worktree),一个独立的开发容器(devcontainer)来运行你的代码,一个独立的 Docker 网络来隔离网络通信,一个独立的数据库实例,以及分配专属的端口和环境变量。这样,你可以在同一台电脑上,同时开发多个功能,而不用担心端口冲突(比如,功能A需要8080端口,功能B也需要8080端口,FeatureBox 会为它们分配不同的端口),数据库数据混淆,或者环境变量的互相影响。甚至可以配置安全的隧道(tunnels),让你的独立环境能够安全地与外部通信。这种方式极大地简化了多任务并行开发的复杂性,提高了开发效率,让你可以更自信地同时处理多个开发需求。
产品核心功能
· 为每个功能创建独立的Git工作区(worktree),这意味着每个功能开发时看到的Git历史和状态都是独立的,防止在不同功能之间切换时代码混淆,价值在于确保每次提交和操作都只针对当前功能,避免误操作。
· 为每个功能配置独立的开发容器(devcontainer),运行代码和依赖项,价值在于提供一个干净、一致的运行环境,避免本地开发环境的差异导致的问题,并能快速启动和销毁。
· 为每个功能设置独立的Docker网络,隔离网络通信,价值在于防止不同功能运行的服务之间发生网络冲突,比如端口占用,也提高了安全性。
· 为每个功能提供独立的数据库实例,价值在于确保不同功能的开发和测试不会互相干扰数据,避免数据损坏或混淆,是数据驱动开发的重要保障。
· 为每个功能分配独占的端口,价值在于解决同一应用可能在不同功能中需要使用相同端口号的问题,避免端口冲突,让并行开发成为可能。
· 为每个功能设置独立的环境变量,价值在于避免不同功能对全局环境变量的依赖产生冲突,确保每个功能在正确的配置下运行。
· 可选的安全隧道功能,允许独立环境安全地与外部通信,价值在于即使在隔离环境中,也能方便地进行外部API调用、 webhook接收等操作,同时保证安全性。
产品使用案例
· 场景:开发者需要同时开发一个新功能,并且修复一个紧急的线上bug。使用FeatureBox,可以为新功能创建一个独立环境,为bug修复创建另一个独立环境。这样,开发者可以全身心地投入到bug修复中,而不用担心新功能的代码或数据库状态会受到影响,修复完成后可以无缝切换回新功能开发。
· 场景:团队协作开发大型项目,每个开发者负责不同的模块或功能。使用FeatureBox,每个开发者都可以为自己的功能创建独立环境,这样即使同时开发,也不会因为共享数据库或端口而产生冲突,大大提高了团队的开发效率和协作的顺畅度。
· 场景:需要频繁地在不同的项目或功能之间切换。传统方式下,切换可能意味着要重新配置环境,甚至重启服务。使用FeatureBox,每个功能环境都是独立的,切换就像在不同的应用程序之间切换一样快速,大大节省了开发者等待环境就绪的时间。
· 场景:一个项目有多个并行的开发任务,比如一个后台任务、一个前端功能和一个API接口开发。FeatureBox可以为这三个任务分别创建独立的环境,每个环境都有自己的数据库、端口和依赖,开发者可以同时进行开发和测试,而不会互相干扰,这对于敏捷开发和快速迭代非常有益。
93
AI知识库瞬启器
作者
ahmedelhadidi
描述
这个项目可以将任何网站变成一个可以被AI智能体(比如聊天机器人)使用的知识库。它的创新之处在于提供了一键部署的便捷体验,让开发者无需复杂的配置就能快速为AI创建个性化的知识源。这解决了AI智能体在访问和利用网络信息时,需要大量预处理和结构化才能使用的技术难题。
人气
点赞 1
评论数 0
这个产品是什么?
这个项目是一个工具,它能自动化地将一个普通的网站内容提取出来,并将其转化为AI智能体(例如,你用来问问题或执行任务的AI助手)可以理解和检索的知识格式。它的核心技术在于使用了先进的网页抓取(web scraping)和文本处理(text processing)技术,能够识别网页中的关键信息,过滤掉广告和导航等非核心内容,并将提取到的文本信息组织成一个结构化的数据库。这样,AI智能体就可以像查询自己的内部数据库一样,快速准确地从这个网站知识库中找到答案,而无需重新学习网站上的每一个页面。它的创新之处在于将这个过程极大地简化,用户只需点击一下,就能完成一个网站到AI知识库的转换。
如何使用它?
开发者可以通过简单的几步操作来使用这个项目。首先,你需要指定想要转换为知识库的网站URL。然后,项目会自动抓取该网站的内容,并进行分析和处理。最后,它会生成一个可以直接集成到你现有的AI智能体项目中的知识库文件或API接口。这意味着,你可以把你的AI应用连接到这个由任何网站生成的知识库,让AI能够回答关于该网站内容的问题,或者根据网站信息提供相关服务。比如,你可以让一个AI客服机器人学习某个公司的产品介绍网站,从而能准确回答用户关于产品的问题;或者让一个研究助手连接到一个技术文档网站,以便快速查找技术细节。
产品核心功能
· 网站内容自动抓取:能够智能地从任何网站上提取有用的文本信息,而不仅仅是复制粘贴,它会识别标题、段落、列表等结构,确保信息完整。这使得AI能够访问更广泛、更深层次的信息。
· 知识库结构化处理:将抓取到的非结构化文本转化为AI易于理解的结构化数据,例如通过向量数据库(vector database)进行索引,以便AI能够快速进行语义搜索。这意味着AI的响应速度和准确性将大大提高。
· 一键部署与集成:提供极其简便的部署方式,用户无需编写复杂的代码或进行繁琐的配置,即可快速生成可供AI使用的知识库。这极大降低了AI应用开发的门槛,让更多开发者能享受到个性化知识库的便利。
· AI智能体兼容性:生成的知识库可以轻松与各种主流的AI智能体框架(如LangChain, LlamaIndex等)集成,让你的AI项目能够即插即用地访问网站知识。这使得你的AI应用能够变得更加智能和功能强大。
产品使用案例
· 场景:为AI客服机器人提供最新产品信息。一个电商公司想让他们的AI客服能够回答关于最新款手机的所有问题。使用此项目,他们可以指向手机的官方介绍网站,迅速生成一个包含所有产品细节、规格和功能的知识库。AI客服就可以实时准确地回答用户关于这款手机的疑问,无需人工干预。
· 场景:构建一个特定技术领域的AI研究助手。一个开发者正在研究一个新的编程框架,但官方文档信息量巨大且不易检索。他可以使用此项目将该框架的官方文档网站转换为一个AI知识库。然后,他的AI助手就能快速查询关于特定API用法、配置选项或最佳实践的信息,极大地提高研究效率。
· 场景:为AI内容聚合器添加个性化信息源。一个项目希望创建一个能够总结不同新闻网站信息的AI。通过使用此项目,可以轻松地将多个目标新闻网站转换为AI可用的知识库,然后AI就可以从这些源中提取信息并进行整合、分析,为用户提供个性化的新闻摘要。
94
AI 专属 Terraform 语法助手
作者
iacguy
描述
tf-dialect 是一个旨在让 AI 编程助手理解并遵循团队 Terraform 规范的工具。当 AI 自动生成 Terraform 配置代码时,tf-dialect 能够确保这些代码符合团队的既定标准,从而解决 AI 生成的代码与现有项目不兼容的问题,特别是对于那些不想直接接触 Terraform 但需要 AI 辅助进行基础设施管理的团队来说,这是一个非常有用的桥梁。
人气
点赞 1
评论数 0
这个产品是什么?
tf-dialect 是一个特殊的“翻译器”和“守门员”,它能教会 AI 编程助手,如何按照你团队自己的一套规则来写 Terraform(一种管理云基础设施的代码工具)。通常,AI 写的 Terraform 代码可能很通用,但每个团队都有自己一套特定的命名方式、安全策略或资源组织习惯。tf-dialect 就像一个“方言”教练,让 AI 生成的 Terraform 代码能够说出你团队“专属的语言”,而不是一堆通用的、可能不兼容的代码。它的核心技术在于能够解析和应用自定义的“元配置策略”(MCP),让 AI 生成的代码能够“感知”到你团队的环境和要求。
如何使用它?
开发者可以将 tf-dialect 集成到他们的 CI/CD(持续集成/持续部署)流程中,或者在 AI 生成 Terraform 代码的阶段使用它。例如,当 AI 产出了一段 Terraform 配置后,tf-dialect 会介入,检查它是否符合预设的团队规范。如果不符合,tf-dialect 可以自动修正,或者提供建议。这使得团队成员(包括那些不太懂 Terraform 的人)可以通过与 AI 对话来管理基础设施,而不用担心代码的合规性。它的使用场景可以是在代码提交前的检查,也可以是 AI 代码生成过程中的实时指导。
产品核心功能
· AI 代码规范化:让 AI 生成的 Terraform 代码遵循团队定制的命名、标签、安全配置等标准,价值在于减少人工审查和修改,提升效率,避免因不规范代码带来的潜在问题。
· 上下文感知 IaC 生成:AI 在生成基础设施代码时,能够理解团队现有的基础设施配置和策略,从而生成更准确、更兼容的代码,价值在于降低 AI 生成代码的风险,使其能更好地适应现有环境。
· 自定义元配置策略(MCP)支持:允许团队定义自己的规则集,AI 必须遵循这些规则,价值在于提供了极高的灵活性,让工具能够适应任何团队的独特需求。
· 代码合规性检查与修正:在 AI 生成代码后,自动检查其是否符合团队规范,并在必要时进行修正,价值在于确保基础设施即代码(IaC)的质量和一致性,减少人为错误。
产品使用案例
· 一个初创公司希望使用 AI 辅助来管理他们的 AWS 云资源,但又不希望 AI 生成的代码破坏他们现有的安全组策略和资源命名约定。开发者可以将 tf-dialect 配置好团队的命名规则和安全要求,然后让 AI 生成 Terraform 代码来创建新的服务。tf-dialect 会确保 AI 生成的资源符合这些规则,避免了后期手动调整的麻烦,也让非基础设施专家能够参与管理。
· 一个大型企业需要引入 AI 自动化来部署 Kubernetes 集群,但他们有一套非常严格的 Kubernetes 资源管理和命名规范,以及特定的网络配置要求。通过 tf-dialect,他们可以让 AI 生成部署脚本,并由 tf-dialect 验证脚本是否完全符合企业的内部标准,确保部署过程的可控性和合规性,并且降低了因 AI 生成代码不符要求而导致的部署失败风险。
· 在一个 CI/CD 流水线中,当开发者通过自然语言描述想要什么云资源时,AI 会生成 Terraform 代码。tf-dialect 作为流水线的一部分,会在代码合并前运行,检查生成的 Terraform 是否满足团队关于成本控制、日志记录或访问权限的所有要求,如果发现不符合的地方,就会自动标记出来或者尝试修正,从而保证了所有部署的代码质量。
· 对于那些希望团队成员都能参与基础设施管理的团队,即使他们不是专业的 DevOps 工程师,tf-dialect 也能提供支持。AI 可以帮助他们生成基础设施代码,而 tf-dialect 则充当一个“安全网”,确保他们生成的代码不会出现严重的错误或不合规之处,降低了学习门槛,提高了团队协作效率。
95
Cursor灵感可视化代理仪表盘
作者
ktotheb
描述
这是一个用于AI代码编辑器Cursor的视觉化代理仪表盘。它将AI代理(比如帮你写代码的助手)的思考过程和状态可视化,帮助开发者直观理解AI的工作方式,并能通过拖拽、连接等方式更灵活地控制AI代理,提升开发效率。
人气
点赞 1
评论数 0
这个产品是什么?
这是一个为AI代码编辑器Cursor设计的可视化界面,旨在让AI代理(那些能帮你写代码、查找Bug的智能助手)变得更易于理解和控制。想象一下,AI代理不再是后台默默工作的黑盒子,而是你眼前可以互动、观察的系统。它通过图形化的方式展示AI代理的内部逻辑、当前状态(比如正在做什么、思考什么)、以及它们之间的联系。创新点在于,它不仅仅是展示信息,还提供了一种交互方式,让开发者能够像拼图一样,通过拖拽组件、连接节点来配置和引导AI代理的行为。这就像给AI代理插上了一双可视化和可操作的翅膀,解决了开发者常常遇到的“AI到底在想什么”以及“如何更好地指挥AI”的问题。
如何使用它?
开发者可以使用这个仪表盘来监控和管理集成在Cursor编辑器中的AI代理。当你打开Cursor并加载了可视化代理仪表盘插件后,就可以看到一个独立的面板。在这个面板里,你会看到代表不同AI代理的图形化模块,它们之间用线条连接,表示信息流动或协作关系。你可以点击某个代理模块,查看它的详细状态和正在执行的任务。更重要的是,你可以通过拖拽现有的模块或从工具箱中添加新的模块,来重新组合或创建新的AI代理工作流。例如,你可以将一个“代码生成”代理和一个“代码审查”代理连接起来,让AI先生成代码,然后自动进行审查,并将审查结果反馈给你。这使得开发者能够根据自己的具体需求,快速定制个性化的AI编码助手。
产品核心功能
· AI代理状态可视化:将AI代理的思考过程、工作状态以图形化方式展示,让开发者清楚知道AI在做什么,解决了“AI工作不透明”的问题。
· 代理行为交互配置:允许开发者通过拖拽、连接等直观操作来配置AI代理的行为和工作流程,解决了“AI指挥不灵活”的问题。
· 自定义AI工作流:支持开发者组合不同的AI代理模块,创建个性化的AI编码解决方案,解决了“通用AI助手无法满足特定需求”的问题。
· 实时反馈与调试:提供AI代理执行过程的实时反馈,方便开发者发现和调试AI行为中的问题,解决了“AI错误难以定位”的问题。
产品使用案例
· 快速原型开发:开发者需要快速实现一个新功能,可以使用仪表盘将“需求分析”、“代码生成”、“单元测试”等AI代理串联起来,自动化大部分编码和测试过程,显著缩短原型开发周期。
· 复杂Bug定位:当遇到一个难以解决的Bug时,开发者可以加载一个“代码分析”、“日志解读”、“网络请求追踪”的AI代理组合,让AI代理逐步深入代码,帮助定位问题根源,解决“Bug定位耗时费力”的困境。
· 代码风格统一:团队需要保证代码风格一致,可以配置一个AI代理工作流,在代码提交前自动执行“代码格式化”、“命名规范检查”等任务,确保所有代码符合团队标准,解决了“代码风格不统一的维护难题”。
· AI驱动的代码重构:当需要对现有代码进行重构时,可以利用仪表盘配置“代码结构分析”、“潜在优化点识别”、“重构建议生成”等AI代理,辅助开发者高效地进行代码优化,解决了“代码重构风险高、工作量大”的挑战。
96
ThinkReview: 隐私优先的浏览器代码审查助手
作者
jkshenawy22
描述
ThinkReview 是一款创新的浏览器扩展,它将人工智能(AI)的能力带入你的代码审查流程,而无需将你的敏感代码发送到任何外部服务。它最大的亮点在于支持本地运行大型语言模型(LLMs)通过 Ollama,这意味着你的代码审查过程完全私密,并且你可以完全掌控 AI 的使用。它巧妙地解决了开发者在代码审查时对数据隐私的担忧,同时提供了 AI 辅助的效率提升,是开发者保障代码安全和提升审查效率的利器。
人气
点赞 1
评论数 0
这个产品是什么?
ThinkReview 是一个集成在浏览器中的工具,它能够在你审查代码(比如 GitLab、GitHub、Azure DevOps、Bitbucket 上的 Pull Request 或 Merge Request)时,提供一个私密的 AI 聊天窗口。你可以问 AI 关于代码逻辑、潜在 bug 或者让它帮你生成审查意见草稿。与那些会自动评论的 AI 工具不同,ThinkReview 的 AI 只是你的辅助,所有评论都由你来决定是否发布。它的技术核心在于利用浏览器本身的能力,通过标准的浏览器 API 集成 LLM。最重要的是,它支持 Ollama,让你可以在本地运行各种强大的 LLM 模型,这意味着你的代码完全不会离开你的电脑,保证了极致的隐私和安全。所以,它解决了开发者在享受 AI 辅助带来的效率提升时,对代码隐私泄露的顾虑。
如何使用它?
开发者只需要在 Chrome 或其他兼容的 Chromium 浏览器上安装 ThinkReview 扩展。安装完成后,当你在 GitLab、GitHub、Azure DevOps 或 Bitbucket 等平台上打开代码审查界面(PR/MR 页面)时,ThinkReview 会自动显示出来。你可以通过配置将其连接到你本地运行的 Ollama 服务,或者使用其默认的云端 LLM 服务(如果需要)。然后,你就可以在审查界面的侧边栏或弹出的窗口中,与 AI 进行交互,提出问题、分析代码、生成意见。这个过程就像是在你的代码审查过程中拥有了一个私密的、随时待命的 AI 伙伴。它非常适合那些注重代码隐私、需要在内网环境工作,或者不希望 AI 自动发表评论的开发者。
产品核心功能
· 浏览器内置 AI 聊天窗口:在代码审查界面提供一个私密的聊天区域,让开发者可以随时向 AI 提问,无需离开当前页面,提高了审查效率。
· 本地 LLM 支持(Ollama):允许用户连接本地运行的 Ollama 服务,使用各种开源 LLM 模型进行代码审查,确保代码数据绝不上传,提供了最高级别的隐私保护。
· 支持主流代码托管平台:能够无缝集成到 GitLab、GitHub、Azure DevOps、Bitbucket 等平台,覆盖了绝大多数开发团队使用的代码管理工具,应用场景广泛。
· AI 辅助生成审查意见:可以请求 AI 分析代码逻辑、发现潜在问题,并生成评论草稿,帮助开发者更快地形成有价值的审查反馈,减少思考负担。
· 用户完全控制 AI 输出:AI 生成的内容仅供参考,所有最终评论都由开发者决定是否发布,保证了审查的质量和人类的判断力。
· 轻量级且易于扩展:基于标准的浏览器 API 构建,代码精简,方便开发者进行二次开发和定制,体现了黑客文化中的“用代码解决问题”的精神。
产品使用案例
· 在一个高度敏感的金融科技公司,开发者需要审查包含大量机密数据的代码。使用 ThinkReview 并配置本地 Ollama LLM,他们可以在不违反任何数据安全规定的前提下,利用 AI 辅助发现代码中的潜在漏洞,极大地提高了审查的安全性和效率。
· 一位使用自托管 GitLab 的开发者,因为网络隔离(air-gapped)环境无法使用云端的 AI 代码审查工具。ThinkReview 的 Ollama 支持让他得以在本地运行 AI,像使用云端工具一样方便地进行代码审查,解决了技术限制带来的难题。
· 一个小型创业团队,希望在有限的预算内提升代码审查的质量。通过 ThinkReview,他们可以免费使用本地的开源 LLM 模型,获得 AI 的初步分析和建议,从而让团队成员能够更专注于代码的架构和业务逻辑,而不是纠结于细枝末节的语法错误。
· 一位开发者在审查同事提交的大量改动时,发现代码逻辑复杂难以理解。他使用 ThinkReview 向 AI 提问“这段代码的主要目的是什么?”,AI 快速给出了代码功能的解释,帮助他迅速抓住核心,提高了审查速度。