Show HN Today: Discover the Latest Innovative Projects from the Developer Community
 ShowHN Today
ShowHN Today
- Continue with Google
Show HN 今日のトップ:2025-11-14の注目の開発者プロジェクト
SagaSu777 2025-11-15
2025-11-14のShow HNで最も注目を集めている開発者プロジェクトを探索。革新的な技術やAIアプリケーションなど、エキサイティングな新発明をご覧ください!
今日の内容まとめ
トレンドインサイト
今日のShow HNからは、開発者が直面する「複雑さ」を解消し、「創造性」に焦点を当てるための技術革新が数多く見られます。特に、AIの活用は単なる補助ツールに留まらず、コード生成、インフラ構築、データ分析、さらにはゲーム開発に至るまで、その応用範囲は驚くほど広いです。Encoreのようなバックエンドフレームワークがコードからインフラを自動生成するアプローチは、開発者がインフラ管理の煩雑さから解放され、本来注力すべきアプリケーションロジックに集中できる未来を示唆しています。また、ChirpやTalkiToのように、ローカル実行にこだわり、プライバシーとセキュリティを確保しながら音声認識やAIエージェントとの連携を強化する試みは、ユーザーの信頼を得る上で不可欠な要素となっています。ChirpのWindows環境でのローカル音声入力、TalkiToのターミナルエージェントへの音声インターフェース提供は、既存のワークフローをより自然で効率的なものに変えようとするエンジニアの情熱の表れです。さらに、ZingleのようなAIコードレビューアは、データチーム特有の課題(コスト、データ品質、ダウンストリームの依存関係)を解決し、開発サイクルの高速化とリスク低減に貢献しています。これらのプロジェクトに共通するのは、既存のツールやプラットフォームの「隙間」を埋め、開発者やユーザーの「ペインポイント」を技術力で解決しようとする、まさにハッカースピリットそのものです。今後、開発者はAIをより深く理解し、その能力を「コードを実行する」「インフラを自動生成する」「プライベートな空間でAIを利用する」といった形で、より創造的かつ効率的な開発プロセスを追求していくことになるでしょう。スタートアップの創業者やエンジニアは、こうした技術トレンドをいち早く捉え、ユーザーの真の課題解決に繋がるプロダクトを創出することで、市場での競争優位性を確立できるはずです。
今日の最も人気のある製品
名前
Encore – Type-safe back end framework that generates infra from code
ハイライト
このプロジェクトは、バックエンド開発の複雑さを大幅に軽減する革新的なフレームワークです。コードからインフラストラクチャ(インフラ)を自動生成するという点で、開発者はインフラ管理の負担から解放され、より迅速かつ安全にアプリケーションを構築できます。特に、型安全性を重視している点は、コードの堅牢性を高め、バグの早期発見に貢献します。開発者は、インフラのプロビジョニングや設定といった煩雑な作業を省略し、アプリケーションロジックの開発に集中できるようになります。これは、バックエンド開発における「コードを書く」という本来の楽しさを取り戻すための強力なアプローチと言えるでしょう。
人気のあるカテゴリ
バックエンド開発
インフラ自動化
AI/ML
開発者ツール
クロスプラットフォーム
プライバシー重視
オープンソース
人気のあるキーワード
API
AI
コード生成
ローカル実行
オープンソース
デバッグ
自動化
フレームワーク
プライバシー
Kubernetes
技術トレンド
AI駆動型開発
コードからインフラ生成
ローカル実行可能なAI/MLモデル
プライバシー重視のSaaS
開発者体験向上ツール
クロスプラットフォーム開発
WebAssembly (WASM)
eBPF
データ構造とアルゴリズムの応用
GitOps
Agentic Workflow
プロジェクトカテゴリ分布
開発者ツール/フレームワーク (25%)
AI/ML関連 (20%)
ユーティリティ/生産性向上 (18%)
データ管理/データベース (10%)
教育/学習 (7%)
クロスプラットフォーム/モバイル (10%)
その他 (ゲーム、エンタメ、情報集約など) (10%)
今日の人気製品リスト
| ランキング | 製品名 | いいね | コメント |
|---|---|---|---|
| 1 | エプスタイン事件ファイル整理・検索システム | 277 | 45 |
| 2 | Encore: コードからインフラを生成する型安全なバックエンドフレームワーク | 71 | 47 |
| 3 | 欧陆引擎 - 跨语言技术洞察聚合器 | 42 | 39 |
| 4 | Pegma 創遊記 | 32 | 48 |
| 5 | 愚かなビジネスアイデア発掘プラットフォーム | 33 | 30 |
| 6 | Chirp: ローカルAI音声入力 | 29 | 15 |
| 7 | 柔術視覚学習ガイド | 7 | 10 |
| 8 | spymux - リアルタイムtmuxビューア | 9 | 3 |
| 9 | TalkiTo: 音声操作コーディングエージェント | 5 | 5 |
| 10 | DataGuardian AI | 6 | 4 |
1
エプスタイン事件ファイル整理・検索システム
著者
searchepstein
説明
このプロジェクトは、公開されているエプスタイン事件に関連する膨大なファイルを、より透明性高く、研究者が調査しやすいように整理・検索可能にしたものです。技術的には、データの構造化と検索機能の最適化に重点を置いています。これにより、これまで埋もれていた情報にアクセスしやすくなり、事件の全体像理解や新たな洞察の発見に貢献します。
人気
ポイント 277
コメント 45
この製品は何ですか?
これは、インターネット上で公開されているエプスタイン事件に関する様々な文書や記録を、コンピューターが理解しやすいように整理し、キーワードで簡単に検索できるようにしたシステムです。単なるファイルの集まりではなく、それぞれのファイルがどのような組織や人物に関連しているのかを明確にし、関係性を分かりやすくしています。これにより、情報が整理されていないために見つけにくかった事実や、関係者の繋がりなどを効率的に発見できるようになります。これは、膨大な情報の中から必要なものを見つけ出すという、まさに「ハッカー精神」を具現化した、コードで問題を解決する創造的なアプローチと言えます。
どのように使用しますか?
開発者は、このシステムをAPI経由で利用したり、公開されているデータセットをダウンロードして自身の分析ツールに組み込むことができます。例えば、特定の人物や組織名で検索を実行したり、関連する文書群を抽出したりすることが可能です。APIを利用すれば、リアルタイムで最新の整理済みデータにアクセスし、独自の分析プラットフォームや可視化ツールを構築することができます。これは、事件の調査や分析を行う研究者、ジャーナリスト、あるいはデータサイエンティストにとって、時間と労力を大幅に削減し、より深い洞察を得るための強力な基盤となります。
製品の核心機能
· ファイルデータの構造化: 関連する情報(人物、組織、日付など)をメタデータとして付与し、コンピューターが理解できる形式に整理します。これにより、単なるテキストファイル以上の意味を持つデータとして扱え、検索精度が向上します。
· 強力な検索機能: キーワード検索だけでなく、関連人物や組織を軸とした複合検索も可能です。これにより、特定の人物が関与した全ての文書を瞬時に特定し、複雑な人間関係や出来事の繋がりを明らかにできます。
· 透明性の向上: 公開されている情報を整理することで、これまでブラックボックス化されていた情報へのアクセスを容易にします。これにより、事実関係の確認や、事件の全体像を客観的に把握するのに役立ちます。
製品の使用例
· 事件の主要関係者の関与を特定する: 特定の人物名で検索することで、その人物が関わった全ての文書をリストアップできます。これにより、その人物の言動や影響力を多角的に分析することが可能になります。
· 組織間の繋がりを可視化する: 複数の組織名を指定して検索し、それらの組織が共同で関与した文書を抽出します。これにより、事件の背後にある複雑な組織構造や協力関係を明らかにする手助けとなります。
· 時系列での出来事を追跡する: 特定の期間や出来事に関連するキーワードで検索し、関連文書を時系列に並べ替えます。これにより、事件の進行状況や、各段階での重要な出来事を正確に把握することができます。
2
Encore: コードからインフラを生成する型安全なバックエンドフレームワーク
著者
andout_
説明
Encoreは、サーバーサイド開発の複雑さを劇的に軽減する革新的なバックエンドフレームワークです。コードを書くだけで、データベース、API、キューなどのインフラストラクチャ全体を自動生成します。これにより、開発者はインフラ管理の手間から解放され、アプリケーションロジックに集中できます。型安全性が保証されているため、開発中に多くのバグを防ぐことができます。
人気
ポイント 71
コメント 47
この製品は何ですか?
Encoreは、開発者がTypeScript/JavaScriptでビジネスロジックを書くことに集中できるように設計された、次世代のバックエンドフレームワークです。従来のフレームワークとは異なり、Encoreはコード定義から直接、インフラストラクチャ(データベース、APIエンドポイント、メッセージキューなど)を自動的にプロビジョニング・設定します。この「コード・イズ・インフラ」のアプローチにより、インフラのデプロイや管理にかかる時間と労力を大幅に削減します。また、TypeScriptの型システムを活用することで、API間の通信やデータ構造における型安全性をコンパイル時に保証し、実行時エラーを減らします。つまり、開発者は「コードを書く」という行為だけで、インフラの構築からアプリケーションの実行までを完結させることができ、開発プロセス全体がより効率的で堅牢になります。
どのように使用しますか?
開発者はまず、EncoreのCLIツールを使用して新しいプロジェクトを作成します。次に、TypeScriptまたはJavaScriptでバックエンドのサービスを定義します。Encoreは、これらのサービス定義(例えば、APIエンドポイントのシグネチャ、データベーススキーマ、イベントリスナーなど)を解析し、必要なインフラストラクチャ(AWS RDS、Lambda、SQSなど)を自動的に生成・デプロイします。開発者は、ローカル開発環境でコードを記述し、Encoreのコマンド一つでステージングや本番環境へデプロイできます。既存のNode.jsプロジェクトとの統合も、徐々にサポートが拡充されています。このフレームワークを使うことで、AWSやGCPといったクラウドプロバイダーの複雑な設定や、TerraformのようなIaCツールを直接扱う必要がなくなり、開発者はコードの記述に集中できます。
製品の核心機能
· 型安全なAPI生成: TypeScriptの型定義に基づいて、APIエンドポイント、リクエスト/レスポンスの型、およびクライアントSDKを自動生成します。これにより、APIの仕様ずれによるバグを防ぎ、クライアントとサーバー間の連携をスムーズにします。開発者はAPIの定義を一度書けば、その仕様が両端で正確に守られることを保証できます。
· 自動インフラストラクチャプロビジョニング: コードで定義されたサービス(データベース、キュー、ファイルストレージなど)に基づいて、クラウドインフラ(AWS, GCPなど)を自動的に設定・デプロイします。開発者はインフラ管理の専門知識がなくても、必要なリソースをコードで宣言するだけで利用できます。これにより、インフラ構築のハードルが下がり、迅速な開発が可能になります。
· サービス間通信の型安全化: Encoreは、異なるサービス間のAPI呼び出しやメッセージングも型安全に扱えるようにします。これにより、サービス連携時のデータ形式の不整合によるエラーを早期に発見し、システム全体の信頼性を向上させます。開発者は、システム内のどこでデータがどのようにやり取りされるかを明確に把握できます。
· ローカル開発環境と本番環境の同期: EncoreのCLIは、ローカルでの開発体験と本番環境でのデプロイメントをシームレスに連携させます。開発者はローカルでテストしたコードを、簡単なコマンドで本番環境に反映させることができます。これにより、開発からデプロイまでのサイクルが大幅に短縮され、迅速なフィードバックループを実現します。
· 開発者体験の向上: コーディング、テスト、デプロイのプロセス全体を簡素化し、開発者がインフラの複雑さに悩まされることなく、創造的な作業に集中できる環境を提供します。これにより、開発効率が向上し、より多くの時間を価値ある機能開発に費やすことができます。
製品の使用例
· マイクロサービスアーキテクチャにおけるサービス間API開発: 複数のマイクロサービスが連携するシステムで、各サービスのAPI定義をTypeScriptで記述するだけで、セキュアで型安全なAPIエンドポイントとクライアントSDKが自動生成されます。これにより、サービス間の連携ミスによるバグを減らし、開発速度を向上させます。
· リアルタイムデータ処理バックエンド: EventBridgeのようなイベント駆動型アーキテクチャを構築する際に、Encoreはイベントリスナーやメッセージキューをコードで定義し、それらを自動的にセットアップします。これにより、リアルタイムデータの取り込みと処理パイプラインの構築が容易になり、イベント駆動型アプリケーションの開発を加速します。
· データ集計・分析API開発: データベーススキーマをコードで定義し、それに基づいてAPIを構築することで、データ集計や分析のためのエンドポイントを迅速に作成できます。Encoreがデータベースへの接続やクエリ実行部分を抽象化してくれるため、開発者は分析ロジックに集中できます。
· サーバーレスアプリケーションのバックエンド構築: Lambda関数やAPI Gatewayといったサーバーレスコンポーネントを、Encoreのフレームワーク内でコードとして定義することで、インフラのセットアップとデプロイを自動化できます。これにより、インフラ管理の手間を省き、スケーラブルなサーバーレスアプリケーションを効率的に構築できます。
3
欧陆引擎 - 跨语言技术洞察聚合器
著者
Merinov
説明
这个项目是一个为欧洲科技领域打造的多语言新闻聚合器,支持六种语言(英语、德语、法语、西班牙语、意大利语、荷兰语)。它通过分析受众(消费者、企业、政府)来帮助用户发现相关的欧洲技术替代方案。创新的关键在于其独特的图像生成方式、针对新网站的渐进式站点地图增长策略、以及利用AI驱动的自动化翻译流程,旨在解决信息孤岛和跨语言沟通的挑战。
人気
ポイント 42
コメント 39
この製品は何ですか?
这是一个智能化的欧洲科技新闻聚合平台。它不仅仅是简单地收集新闻,而是运用了多种技术手段来提供更有价值的信息。首先,它使用了基于模式的图像生成技术,这意味着为不同类型的新闻(如融资、安全)生成更具相关性和多样性的视觉内容,避免了AI生成图像的千篇一律。其次,对于新发布的网站,它采用了渐进式的站点地图(sitemap)增长策略,通过逐步增加搜索引擎可见的页面数量,来提高新内容的索引率,让搜索引擎更容易发现和收录信息。最后,它建立了一个自动化的翻译流程,将RSS聚合的内容通过AI进行摘要和翻译,并设置了人工审核环节,以确保多语言内容的质量。这些技术的结合,使得用户能够更高效、更全面地获取和理解欧洲的最新科技动态。
どのように使用しますか?
开发者可以将其作为发现欧洲新兴科技公司、了解竞争对手动态、寻找技术合作机会的工具。通过选择目标语言和受众类型,可以精准地过滤信息。例如,一个专注于B2B服务的开发者,可以选择“企业”作为受众,并查看德语或法语的科技新闻,以了解欧洲在该领域的最新发展和潜在的合作伙伴。集成方面,虽然本项目未直接提供API,但其理念和技术实现思路可以启发开发者在自己的项目中构建类似的智能化信息聚合和分发系统。
製品の核心機能
· 多语言新闻聚合:技术实现上通过RSS订阅和API接口收集来自欧洲多国科技媒体的内容,旨在解决信息获取的地域和语言限制,价值在于提供一个统一的欧洲科技信息入口。
· 受众细分过滤:通过对新闻内容进行分析,将其归类到消费者、企业、政府等受众群体,技术上可能利用了NLP(自然语言处理)技术进行内容分类,价值在于让用户快速定位与自身最相关的信息。
· 模式化AI图像生成:利用预定义的视觉模式库,根据新闻内容(如融资、安全)自动匹配生成图像,避免了AI生成图像的同质化,技术上是一个创新的图像生成策略,价值在于提升内容的可视化吸引力和独特性。
· 渐进式站点地图优化:针对新内容快速增长的网站,动态调整搜索引擎可见的URL数量,以提高新内容的索引率,技术上涉及到动态Sitemap生成和SEO策略,价值在于帮助新网站内容更快地被搜索引擎发现。
· 自动化翻译与摘要:利用AI技术对跨语言内容进行自动摘要和翻译,并辅以人工审核,技术上是NLP和机器翻译的应用,价值在于打破语言障碍,使非母语用户也能理解内容。
製品の使用例
· 一个专注于欧洲市场的AI初创公司,需要了解德国和法国在AI伦理方面的最新政策法规。通过使用该聚合器,设定语言为德语和法语,受众为“政府”,可以快速找到相关的政策文件和新闻报道,帮助公司制定合规策略。
· 一个欧洲的SaaS开发者,希望寻找潜在的合作伙伴或了解竞争对手。他可以选择英语、德语、法语,受众为“企业”,来发现欧洲范围内值得关注的SaaS产品和服务,了解他们的技术特点和市场定位。
· 一个关注可持续技术的投资者,希望找到欧洲在清洁能源领域的新兴企业。他可以选择任意语言,受众为“企业”或“消费者”,来浏览相关新闻,并借助AI翻译功能阅读非母语的新闻,及时发现投资机会。
4
Pegma 創遊記
著者
GlebShalimov
説明
Pegma は、古典的なペグソリテールゲームの無料オープンソース版です。開発者は、ミニマルで洗練されたデザインと、複数のプラットフォームでスムーズなゲームプレイを実現しました。特筆すべきは、開発者自身がデザインしたカスタムフォントと、プラットフォーム間のシームレスな互換性です。これにより、古き良きパズルゲーム体験が、現代のデバイスでより身近なものになりました。これは、オープンソースの精神と、コードで創造性を表現するハッカー文化の体現です。
人気
ポイント 32
コメント 48
この製品は何ですか?
Pegma は、古くから親しまれているペグソリテールという一人用パズルゲームを、誰でも無料で利用できるオープンソースの形で提供するプロジェクトです。開発者は、ゲームの見た目をすっきりとミニマルにし、操作性を滑らかにすることに注力しました。さらに、ゲームのために特別にデザインされたオリジナルのフォントを使用することで、ユニークで記憶に残るビジュアル体験を生み出しています。iOS と Android の両方でプレイできるため、お使いのデバイスを選ばずに、いつでもどこでもこの古典的な知恵比べを楽しむことができます。これは、技術を使って人々に喜びと挑戦を提供することの素晴らしい例です。
どのように使用しますか?
開発者は、Pegma を iOS および Android デバイスにダウンロードしてプレイすることができます。GitHub で公開されているオープンソースコードを閲覧、フォーク、または改善することも可能です。これにより、他の開発者は Pegma のコードを参考にしたり、自身のプロジェクトに組み込んだり、さらに新しい機能を追加してゲームを拡張したりすることができます。このプロジェクトは、クロスプラットフォーム開発の技術、UI/UX デザインの原則、そしてオープンソースコミュニティへの貢献の可能性を示しています。
製品の核心機能
· クロスプラットフォーム対応: iOS と Android の両方でシームレスに動作し、より多くのユーザーがアクセスできるため、開発者は単一のコードベースで複数のプラットフォームをターゲットにできます。これは、開発効率を高め、より広範なリーチを可能にします。
· カスタムフォントデザイン: ゲームのために特別にデザインされたフォントは、視覚的な魅力を高め、ブランドアイデンティティを確立します。これは、デザインと開発の融合がいかに体験を向上させるかを示しており、開発者にデザインへの意識を促します。
· オープンソースコード: GitHub で公開されているソースコードは、透明性とコミュニティによる改善を促進します。開発者はコードを学び、貢献することができ、これはコードによる問題解決と知識共有のハッカー精神を体現しています。
· ミニマルで直感的なインターフェース: ゲームの操作が簡単で、視覚的なノイズが少ないため、ユーザーはゲーム自体に集中できます。これは、シンプルさがユーザー体験を向上させることを示しており、開発者にクリーンな設計の重要性を伝えます。
製品の使用例
· カジュアルゲーム開発者: Pegma のスムーズなクロスプラットフォーム実装とミニマルなUIデザインは、他のカジュアルゲーム開発者にとって、効率的な開発手法と魅力的なユーザーインターフェース設計の参考になります。これにより、開発者はより少ない労力で高品質なゲームをリリースできます。
· オープンソースプロジェクトへの貢献者: Pegma は、GitHub でコードが公開されているため、オープンソースコミュニティに興味のある開発者にとって、実際のプロジェクトに貢献する絶好の機会を提供します。これは、コードを共有し、共同で問題解決を行うことの価値を示しています。
· UI/UX デザイン学習者: Pegma の洗練された、しかし直感的なインターフェースは、UI/UXデザインを学ぶ開発者にとって、どのようにしてユーザーフレンドリーな体験を作り出すかの良い事例となります。これにより、開発者はユーザー中心のデザイン原則を実践的に学べます。
· 古き良きゲーム体験を求めるユーザー: 開発者自身が、古典的なゲームの楽しさを現代の技術で再現しました。これは、技術が単なるツールではなく、人々に喜びや懐かしさを提供する手段にもなり得ることを示しています。
5
愚かなビジネスアイデア発掘プラットフォーム
著者
elysionmind
説明
「これは存在すべきではない」と思える、最高に面白いほどひどいビジネスアイデアを発見するためのプラットフォームです。開発者は、創業の概念のワーストからインスピレーションを得て、友人と共有し、自分自身の愚かなアイデアを提出することができます。技術的には、ユーザー生成コンテンツ(UGC)の管理、タグ付け、検索、およびソーシャル共有機能を備えています。これは、創造性の限界を探求し、既存のビジネスモデルに挑戦するためのツールです。
人気
ポイント 33
コメント 30
この製品は何ですか?
これは、開発者やクリエイティブな人々が、常識にとらわれない、あるいは極端に突飛なビジネスアイデアを共有し、探求するためのウェブサイトです。技術的な原理としては、フロントエンドはReactなどのモダンなJavaScriptフレームワークで構築され、バックエンドはNode.jsやPythonなどのサーバーサイド言語でAPIを提供します。データベースには、アイデア、ユーザー情報、コメント、タグなどを格納します。革新的な点は、意図的に「悪い」アイデアを奨励し、そこから新しい発想やユーモアを生み出すことです。これは、従来のビジネスコンテストとは異なり、失敗や非合理性を創造性の源泉として活用するユニークなアプローチです。つまり、これはあなたの創造的な思考を刺激し、普段考えつかないようなユニークなアイデアを生み出すための遊び場です。
どのように使用しますか?
開発者は、ウェブブラウザを通じてこのプラットフォームにアクセスし、アカウントを作成します。その後、彼らは「愚かなビジネスアイデア」をテキスト形式で投稿したり、既存のアイデアを閲覧、評価、コメントすることができます。タグ付け機能を使ってアイデアを分類したり、検索機能で特定のテーマのアイデアを探すことも可能です。ソーシャル共有機能を使えば、気に入ったアイデアをSNSで簡単に共有できます。これは、開発者が自身のクリエイティブな側面を探求し、他の開発者とアイデアを交換するための、シンプルで直感的なインターフェースを提供します。なので、これはあなたの発想力を広げ、他の人と共有することで、新たなインスピレーションを得るための便利なツールとなります。
製品の核心機能
· アイデア投稿機能:ユーザーは、独自の「愚かなビジネスアイデア」をテキストで簡単に投稿できます。これは、創造性の爆発を捉え、共有するための直接的な手段を提供します。
· アイデア閲覧・評価機能:他のユーザーが投稿したアイデアを閲覧し、評価(おそらく「いいね」や「ひどいね」などのカスタム評価)をすることができます。これは、コミュニティによるフィードバックとエンゲージメントを促進し、アイデアの「面白さ」を測る指標となります。
· コメント機能:投稿されたアイデアに対してコメントを残すことができます。これは、アイデアに対する議論や、さらなる発想の連鎖を生み出すためのインタラクティブなスペースを提供します。
· タグ付け・検索機能:アイデアにタグを付けたり、タグで検索したりできます。これにより、特定のテーマやジャンルのアイデアを効率的に見つけることができます。これは、関連性の高いアイデアを素早く発見するための強力なナビゲーションツールです。
· ソーシャル共有機能:気に入ったアイデアをSNSなどで簡単に共有できます。これは、プラットフォーム外へのアイデアの拡散を促進し、より多くの人々を巻き込むことを可能にします。
· ユーザープロフィール管理:ユーザーは自身のプロフィールを作成し、投稿したアイデアやコメント履歴を管理できます。これは、コミュニティ内での自己表現とアイデンティティの確立を助けます。
製品の使用例
· 新しいアプリのコンセプトを考える際のブレインストーミングツールとして:開発者が、通常なら実現不可能、あるいは馬鹿げていると思われるようなビジネスアイデアを収集し、そこから意外なイノベーションの種を見つけることができます。例えば、「空飛ぶピザ配達ドローン」というアイデアから、ドローン技術の応用範囲や物流の革新の可能性を模索する。これは、固定観念を打ち破るための発想の起点となります。
· スタートアップのピッチイベントでのインスピレーション源として:参加者が、既存のビジネスモデルの「逆」や、極端にニッチな市場を狙うアイデアを生成し、ユニークなアプローチのインスピレーションを得る。例えば、「必ず失敗する投資コンサルタント」というアイデアから、リスク管理の重要性や、顧客が本当に求めているものについて再考する。これは、斬新な視点を提供します。
· 開発者コミュニティ内でのユーモアと交流の促進:単に技術的な議論だけでなく、共有された「愚かなビジネスアイデア」を通じて、開発者同士のユーモアのセンスや創造性を共有し、コミュニティの結束を深める。例えば、SF映画に出てくるような非現実的なガジェットのアイデアを共有し、それを実現するための(あるいは不可能であることを証明するための)技術的な議論を楽しむ。これは、技術的なコミュニティに人間味と楽しさを加えます。
· 教育機関での創造性教育の教材として:学生が、既存のビジネスモデルの限界を理解し、自由な発想を奨励するために、このプラットフォームを活用する。例えば、環境問題解決のために「ごみを喜んで拾うロボット」というアイデアを出し、その実現可能性や倫理的な側面について議論する。これは、批判的思考と創造的思考を同時に育成します。
6
Chirp: ローカルAI音声入力
著者
whamp
説明
Chirpは、Windows環境で動作するローカル音声入力アプリケーションです。クラウドサービスに依存せず、GPUも不要で、Pythonがあれば実行可能です。NVIDIAのParakeetV3モデルを利用し、高精度かつ高速な音声認識を実現します。これは、厳格なセキュリティポリシー下で開発を行わざるを得ない状況や、プライバシーを重視する開発者にとって、画期的なソリューションとなります。
人気
ポイント 29
コメント 15
この製品は何ですか?
Chirpは、あなたの声をテキストに変換する、完全にローカルで動作するWindows用音声入力ツールです。通常、音声認識にはインターネット接続や高性能なGPUが必要ですが、Chirpはこれらの要件を排除しました。NVIDIAのParakeetV3という、比較的小さくても高性能なAIモデルを、CPU上で直接実行できるように最適化されています。ONNX Runtimeという、AIモデルを効率的に実行するための技術を利用しており、必要なのはPython環境だけです。これにより、機密性の高い環境や、リソースが限られている場所でも、プライバシーを保ちながら正確な音声入力を利用できるようになります。なので、これは「インターネットに繋がなくても、あなたのPCだけで高精度な音声入力が使えるようになる魔法の道具」と言えます。
どのように使用しますか?
Chirpの使用は非常にシンプルです。まず、一度だけセットアップコマンドを実行し、ParakeetV3のAIモデルをダウンロードして準備します。次に、バックグラウンドで常時実行されるコマンドを起動します。この間、グローバルホットキー(例えばCtrl+Shift+Vなど、自分で設定可能)を押すだけで、音声認識が開始・停止し、認識されたテキストは現在アクティブなウィンドウに直接入力されます。特別なアプリケーションの起動や、複雑な設定は不要です。まるで、PCに高性能な「声帯」を内蔵させるような感覚で利用できます。例えば、Wordやメモ帳、コーディング中のIDEなどで、キーボード入力の代わりに声で文章を作成したい場合に、このホットキーを押すだけで即座に利用開始できます。
製品の核心機能
· ローカル実行の音声認識(STT):音声データを外部に送信せず、すべてお使いのPC内で処理します。これにより、プライバシーが最大限に保護され、インターネット接続が不安定な環境でも問題なく動作します。CPUでの実行に最適化されているため、特別なハードウェアが不要です。
· 設定駆動型動作:`config.toml`という設定ファイルで、グローバルホットキー、使用するAIモデル、精度と速度のバランス(量子化)、言語、CPU/GPU(利用可能な場合)の使用設定、スレッド数などを細かくカスタマイズできます。これにより、ご自身の環境や好みに合わせてChirpを最適化できます。また、モデルが誤認識しやすい単語を登録し、修正することも可能です。つまり、あなたのPC環境に合わせて「声」の認識精度を調整できる機能です。
· 後処理パイプライン:音声認識後のテキストに対して、「文頭を大文字にする」や「指定した文字を先頭に挿入する」といったスタイルガイドを適用できます。これにより、認識されたテキストをより整った形ですぐに利用できます。例えば、議事録の作成時に、自動的に日付を挿入するなどの作業を効率化できます。つまり、認識されたテキストを「ちょっとお洒落にする」魔法です。
· クリップボード不要の直接入力:Windowsでは、音声認識結果をクリップボードにコピー&ペーストするのではなく、フォーカスされているウィンドウに直接入力します。これにより、ファイルやアプリケーション間のコピー&ペーストの手間が省け、入力作業がシームレスになります。まさに、声が直接キーボードのように機能する体験を提供します。
· 音声フィードバック:録音開始・停止時に設定可能なサウンドが鳴ります。これにより、マイクが正常に動作しているか、いつ録音が開始・終了したかを直感的に把握できます。安心して音声入力を開始・停止できます。つまり、操作が「音」で確認できるので、迷うことがありません。
製品の使用例
· 厳格なセキュリティポリシーを持つ企業環境での利用:外部サービスへの音声データ送信が禁止されている場合でも、Chirpを使えばローカルで安全に音声入力を利用できます。例えば、機密文書の作成中に、キーボード入力の代わりに音声で内容を記録する際に役立ちます。これにより、データ漏洩のリスクを排除しつつ、生産性を向上させられます。
· GPUリソースが限られている開発環境での利用:AI開発などでGPUを頻繁に使用する環境では、音声認識のためにGPUを占有したくない場合があります。ChirpはCPUで快適に動作するため、GPUリソースを他のタスクに専念させることができます。例えば、コードを書きながら、一時的なメモを音声で素早く入力したい場合に、GPUを消費せずに済みます。
· オフライン環境での正確な音声入力が必要な場合:インターネット接続が不安定な、あるいは全く利用できない場所(例:飛行機内、地下、特定の研究施設など)でも、Chirpは問題なく高精度な音声入力を提供します。例えば、オフラインでドキュメントを執筆する際に、声で文章を作成したい場合に、インターネット接続を気にする必要がありません。
· プライベートな音声データをクラウドに送りたくないユーザー:個人の日記や、機密性の高い情報を音声で記録したい場合、ChirpはデータをPCの外に出さないため、安心して利用できます。例えば、個人的なアイデアや、誰にも知られたくない情報を声でメモしたい場合に、プライバシーが守られます。
7
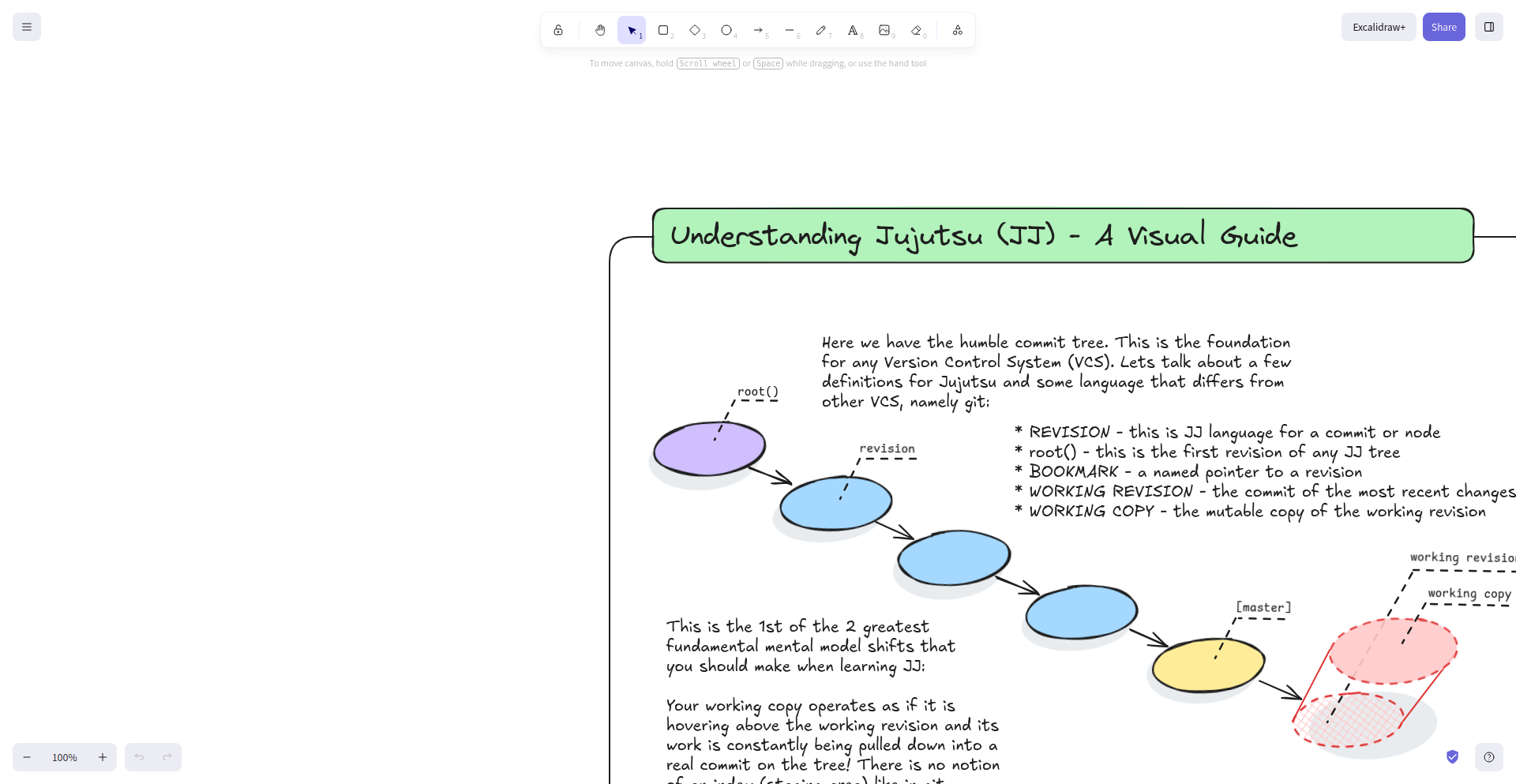
柔術視覚学習ガイド
著者
anavid7
説明
これは、柔術(JJ)の学習を支援するための、視覚的なガイドのドラフト版です。本プロジェクトは、複雑な武道の動きを理解しやすくするために、インタラクティブなビジュアル要素を導入するという技術革新に取り組んでいます。これにより、学習者は抽象的な説明だけでなく、直感的に技を習得することができます。具体的には、アニメーションや図解を用いた解説によって、従来のアプローチでは難しかった動きの分解や、力の伝達経路の可視化を実現しています。
人気
ポイント 7
コメント 10
この製品は何ですか?
これは、柔術の稽古を視覚的にサポートする学習ツールの初期段階です。単なるテキストや静止画の説明にとどまらず、技の各段階をアニメーションで表示することで、動きの軌跡、身体の重心移動、力の方向などを直感的に理解できるように工夫されています。これは、例えばコンピューターグラフィックスやインタラクティブなウェブ技術を応用して、学習者が能動的に情報を探求できるような体験を目指しています。なので、これにより、学習者は言葉だけでは伝わりにくい微妙な体の使い方や、技のキレといった感覚を掴みやすくなります。
どのように使用しますか?
開発者としては、このプロジェクトを参考に、自身の専門分野における複雑な概念やプロセスを視覚化するツールを構築するインスピレーションを得られます。例えば、新しいプログラミング言語の文法解説にインタラクティブなコード例と実行結果の視覚化を組み合わせたり、アルゴリズムの動作をアニメーションで示したりといった応用が考えられます。ウェブ開発者であれば、JavaScriptライブラリやCanvas APIなどを活用して、同様のインタラクティブな学習コンテンツを開発する際の技術的なヒントが得られるでしょう。なので、これは、複雑な技術的概念を視覚的に表現するための新しいアイデアと実装方法を提供してくれます。
製品の核心機能
· 技の動作を段階的にアニメーション表示する機能。これにより、各動作のタイミングや体の使い方を正確に把握できます。だから、動きの習得が格段に速くなります。
· 体の重心移動や力の伝達経路を視覚的に示す機能。これにより、技の効率的なかけ方や、相手を崩すためのポイントを理解できます。だから、より効果的な練習が可能になります。
· インタラクティブな図解による解説機能。学習者は図をクリックしたり、スライダーを操作したりして、技の細部を深掘りできます。だから、受動的な学習から能動的な探求へと変わります。
· 学習進捗を追跡し、フィードバックを提供する機能(将来的には)。これにより、学習者は自分の弱点を把握し、集中的に練習できます。だから、学習効率が最大化されます。
製品の使用例
· プログラミング教育におけるアルゴリズムの可視化。例えば、ソートアルゴリズム(クイックソート、マージソートなど)の各ステップをアニメーションで表示し、データ構造の変化や比較・交換の様子をリアルタイムで確認する。これにより、抽象的なアルゴリズムの動作原理を直感的に理解できる。
· 物理シミュレーションのインタラクティブなデモンストレーション。例えば、質点の運動や衝突の様子を、パラメータを変更しながらリアルタイムで視覚化する。これにより、物理法則の理解を深め、教育現場での活用が期待できる。
· UI/UXデザインにおけるインタラクションフローの設計支援。ボタンクリック時のアニメーション遷移や、画面切り替え時のエフェクトなどをプレビューし、ユーザー体験を視覚的に検証する。これにより、デザインの意図を関係者間で共有しやすくなる。
· 複雑な機械構造や組立工程の解説。例えば、エンジンの内部構造や、家具の組立手順を3Dモデルとアニメーションで解説する。これにより、専門知識がない人でも、複雑な手順や構造を容易に理解できる。
8
spymux - リアルタイムtmuxビューア
著者
crap
説明
spymuxは、複数のtmuxセッションとそのペイン(分割されたウィンドウ)のステータスをリアルタイムで監視するためのツールです。開発者が複数のビルドジョブやテストプロセスを同時に追跡する際に、それぞれの進捗状況を一覧で把握できるように設計されています。これにより、コンテキストスイッチを減らし、生産性を向上させることが期待できます。
人気
ポイント 9
コメント 3
この製品は何ですか?
spymuxは、ターミナルマルチプレクサであるtmuxの、個々のペイン(ウィンドウの分割部分)の実行状態を視覚的に把握できるようにするツールです。開発者は、複数のターミナルセッションを同時に実行している場合、それぞれのターミナルで何が起こっているのか(例:コンパイル中、テスト実行中、サーバー起動中など)を、別のウィンドウやタブを開くことなく、一つの画面で一覧できます。これは、tmuxの内部状態を監視し、各ペインのコマンド実行状況や終了ステータスを検知することで実現されています。これにより、手動で各ペインを確認する手間が省け、全体像を迅速に把握できるようになります。
どのように使用しますか?
開発者はspymuxを、既存のtmux環境に統合して使用します。まず、spymuxのスクリプトをセットアップし、tmuxのグローバル設定ファイル(通常は.tmux.conf)に、spymuxを起動するためのコマンドを追加します。これにより、tmuxセッションを開始する際にspymuxも自動的に起動するか、手動でコマンドを実行して起動できます。spymuxは、バックグラウンドで実行され、各tmuxペインのイベントを検知し、そのステータスを別のウィンドウやパネルに表示します。例えば、ビルドが完了したり、テストが失敗したりした場合、spymuxはその情報を即座に通知してくれます。これは、シェルスクリプトやPythonのようなスクリプト言語で実装されており、tmuxのAPIやイベントシステムを活用しています。
製品の核心機能
· リアルタイムステータス監視 - 各tmuxペインで実行中のコマンドがいつ終了したか、またはエラーが発生したかを即座に検知し、通知する機能。これにより、開発者は待機時間を減らし、問題発生時に迅速に対応できます。
· 集約ビュー - 複数のtmuxペインのステータスを一つの統合されたインターフェースで表示する機能。これにより、開発者は複数のビルド、テスト、サーバープロセスを効率的に管理できます。
· カスタマイズ可能な通知 - 特定のイベント(例:ビルド成功、テスト失敗)に対して、カスタム通知を設定する機能。これにより、開発者は重要なイベントを見逃すことなく、集中して作業を進めることができます。
· 軽量なバックグラウンドプロセス - tmuxのセッションを圧迫しない、軽量なバックグラウンドプロセスとして動作する設計。これにより、既存の開発環境のパフォーマンスに影響を与えずに利用できます。
製品の使用例
· 複数プロジェクトの同時ビルド監視 - 開発者が複数の異なるプロジェクトのビルドを同時に実行している場合、spymuxを使えば、どのビルドが完了し、どれが失敗したかを一目で把握できます。これにより、コンパイルエラーの特定や修正が迅速になります。
· CI/CDパイプラインのデバッグ - CI/CDプロセスの一部として、複数のテストジョブが並行して実行される場合、spymuxは各テストジョブの実行状況と結果をリアルタイムで表示し、問題のあるテストを迅速に特定するのに役立ちます。
· 分散システム開発におけるサーバー監視 - 複数のマイクロサービスやノードをローカルで起動して開発している際、spymuxは各サーバープロセスの起動・停止・エラー状態を一覧表示し、システム全体の健全性を把握しやすくします。
· 長時間のバッチ処理の進捗確認 - 大量のデータを処理するバッチジョブなど、実行に時間がかかるプロセスをtmuxで実行している場合、spymuxはその終了を通知してくれるため、定期的にターミナルを確認する手間が省けます。
9
TalkiTo: 音声操作コーディングエージェント
著者
robbomacrae
説明
TalkiToは、ターミナルベースのコーディングエージェントに音声入出力とSlack/WhatsApp連携を追加するオープンソースプロジェクトです。これにより、コーディング作業をハンズフリーで行い、エージェントの進行状況をリアルタイムで把握できるようになります。BYOK(Bring Your Own Key)哲学に基づき、主要なASR/TTSプロバイダーやローカルモデル(Whisper, Kokoro/KittenTTS)に対応しており、柔軟なカスタマイズが可能です。なので、開発者はより集中してコードを書くことができ、エージェントとのインタラクションが効率化されます。
人気
ポイント 5
コメント 5
この製品は何ですか?
TalkiToは、AIコーディングエージェント(Claude CodeやCodex CLIなど)の入出力を音声で制御できるようにするシステムです。音声認識(ASR)で話した内容をエージェントへのコマンドとして解釈し、エージェントの出力を音声合成(TTS)で読み上げます。これにより、画面に集中しつつ、音声だけでエージェントと対話できるようになります。また、SlackやWhatsApp経由で通知を受け取ることも可能です。技術的な深みとしては、エージェントの標準入出力をラップし、外部の音声認識・合成エンジンと連携する仕組みを採用しています。MCP(Message Queueing Telemetry Transport)サーバーも含まれていますが、これは主に設定管理用で、音声処理の遅延を避けるために直接的な音声送受信には使用されていません。なので、音声でエージェントを操作するという革新的な方法で、開発者の生産性を向上させます。
どのように使用しますか?
開発者はTalkiToをローカル環境にセットアップし、好みのASR/TTSプロバイダー(Google Cloud Speech-to-Text, AWS Transcribe, OpenAI Whisperなど)またはローカルモデル(Whisper, KittenTTS)を設定します。次に、TalkiToをコーディングエージェントの実行プロセスに統合します。例えば、ターミナルで「talkito start」と実行し、その後にコーディングエージェントを起動します。エージェントがコードを生成したり、ユーザーの入力を求めたりする際に、TalkiToがそれを検知し、音声で通知したり、ユーザーの音声入力を受け付けたりします。SlackやWhatsAppのフックを設定することで、エージェントの進捗状況や重要なメッセージをリアルタイムで受け取ることも可能です。なので、開発者はコマンドライン操作から解放され、より自然な対話形式でコーディング作業を進めることができます。
製品の核心機能
· 音声認識によるコーディングエージェントへのコマンド入力:話した内容をテキストに変換し、エージェントへの指示として送信します。これにより、キーボード操作を減らし、思考を直接コードに反映させることができます。
· 音声合成によるコーディングエージェントの出力通知:エージェントのコード生成結果やエラーメッセージなどを音声で読み上げます。これにより、画面から目を離さずにエージェントの状況を把握できます。
· Slack/WhatsApp連携によるリアルタイム通知:エージェントの重要な進捗やメッセージを、普段利用しているコミュニケーションツールで受け取ることができます。これにより、作業の中断を最小限に抑え、通知を見逃すリスクを減らします。
· BYOK(Bring Your Own Key)による柔軟なプロバイダー選択:Google, AWS, OpenAIなどの主要なクラウドASR/TTSサービス、あるいはローカルで動作するWhisperやKittenTTSなど、好みの音声エンジンを自由に選択・設定できます。これにより、コスト、プライバシー、パフォーマンスの要件に合わせて最適な構成を選ぶことができます。
· MCPサーバーによる設定管理:音声入出力の有効/無効切り替えや、TTSエンジンの変更などを、簡単な音声コマンドまたはテキストコマンドで行えます。これにより、実行中に設定を素早く調整できます。
製品の使用例
· ハンズフリーでのコードレビュー:コードレビュー中に、エディタやレビューツールを操作しながら、音声でエージェントに修正案を提示したり、コードの改善点を指摘させたりする。これにより、レビュープロセスがスムーズになり、思考の流れを中断しません。
· マルチタスク環境でのAIコーディング:複数のターミナルウィンドウで異なるタスクを実行している際に、音声でコーディングエージェントに指示を出し、その進捗を音声で確認する。これにより、画面を切り替える手間が省け、集中力を維持できます。
· リモートワークでのコーディング支援:自宅やカフェなど、キーボード操作が難しい環境でも、音声だけでAIコーディングエージェントを活用し、コーディング作業を進める。これにより、場所を選ばずに生産性を維持できます。
· アクセシビリティ向上のためのコーディング:視覚障害のある開発者や、キーボード操作に制約のある開発者が、音声インターフェースを通じてAIコーディングエージェントを効果的に利用できるようになります。これにより、より多くの人々が開発に参加できるようになります。
10
DataGuardian AI
著者
UvrajSB
説明
DataGuardian AIは、GitHubのプルリクエスト(PR)でSQL、dbt、Airflow、Sparkコードの変更を自動的にレビューするAIコードレビュアーです。データチームが本番環境にマージする前に、コストの増加、ロジックの問題、データ品質のギャップ、および下流のパイプラインの破損を検出します。これにより、データエンジニアはコードの品質とコスト効率を確保し、手作業によるレビューの負担を軽減できます。
人気
ポイント 6
コメント 4
この製品は何ですか?
DataGuardian AIは、データエンジニアリングチーム向けのAI駆動型コードレビューツールです。従来のソフトウェアコードレビューとは異なり、SQLやdbtのようなデータ処理コードの変更が、データウェアハウスのコスト、データ品質、および下流の依存関係に与える影響を評価することに特化しています。その革新性は、単にコードの構文をチェックするだけでなく、コードが実行された際の実際のデータとコストへの影響を予測・分析する点にあります。例えば、SQLクエリの変更が意図せず大規模なデータフルリフレッシュを引き起こし、高額な請求につながるリスクを事前に検知します。また、データリネージ(データの流れ)を追跡して、どのダッシュボードやモデルが影響を受けるかを特定し、データ品質の欠陥(例:NULL値の増加、一意性の問題)やガバナンス違反(例:個人情報保護規則の不遵守)も検出します。これは、データチームが直面する特有のリスク、すなわち「コード上は正しく見えても、大規模に実行すると問題が発生する」という課題を解決するための、高度な技術的洞察に基づいています。
どのように使用しますか?
開発者は、GitHubリポジトリとDataGuardian AIを連携させることで、このツールを簡単に利用できます。開発者がSQL、dbt、Airflow、またはSparkコードの変更を含むプルリクエストをGitHubに作成すると、DataGuardian AIはそのPRを自動的にスキャンし、潜在的な問題点を特定します。AIは、コードの変更がデータウェアハウスのコストに与える影響(例:予期せぬクエリ実行によるコスト増)、データ品質に関するリスク(例:データの不整合、欠落)、および下流の依存関係(例:ダッシュボードや他のモデルへの影響)について分析レポートを生成します。このレポートはプルリクエストのコメントとして提供され、開発者はマージ前にこれらの問題点を修正できます。これにより、開発プロセスは迅速化され、本番環境へのデプロイ前に潜在的な問題を回避できます。このツールは、既存のCI/CDパイプラインに統合することも可能です。
製品の核心機能
· コスト増加予測:SQLやdbtの変更が、データウェアハウスの運用コストにどのように影響するかを予測します。例えば、非効率なクエリが生成されることで、データ処理にかかる費用が想定以上に増加するリスクを検知し、開発者にコスト削減のためのコード修正を促します。これにより、予期せぬ高額請求を防ぐことができます。
· ロジックとデータ品質の検出:コードの変更がデータの正確性や整合性に悪影響を与えないかを分析します。例えば、データセットに重複行が混入したり、重要なフィルター条件が欠落したりするリスクを検知し、データの信頼性を維持します。これにより、誤った分析結果やレポートによるビジネス上の誤判断を防ぎます。
· 下流への影響追跡:コードの変更が、依存する他のデータモデル、ダッシュボード、またはアプリケーションにどのような影響を与えるかを特定します。これにより、ある変更が予期せず多数の downstream のシステムを破損させることを防ぎ、システム全体の安定性を保ちます。
· ガバナンスとベストプラクティス enforcement:データガバナンス規則(例:個人情報保護)、コードのドキュメンテーション要件、およびマージキーの定義などのベストプラクティスへの準拠を自動的にチェックします。これにより、組織のポリシー遵守を強化し、コンプライアンスリスクを低減します。
· サンドボックスでのSQL実行とデータ diff 分析:安全な環境で変更されたSQLクエリを実行し、実際のデータとの差分を分析します。これにより、コードレビューでは見落としがちな、実行時特有の問題やデータへの影響を正確に把握できます。これは、テスト環境での実行結果と本番環境での実行結果の乖離を防ぐのに役立ちます。
製品の使用例
· データウェアハウスのコスト削減:ある企業では、DataGuardian AIが、大規模モデルの繰り返しフルリフレッシュをトリガーする可能性のあるPRを検知し、数万ドルに及ぶ不要なコスト発生を未然に防ぎました。これは、開発者がコード変更の影響を事前に把握し、コスト効率の高いクエリを記述することを支援する具体的な例です。
· データインシデントの削減:別のケースでは、ファクトテーブルに重複行が混入して収益データが歪められる可能性のあるPRを検知しました。DataGuardian AIは、この問題を修正するよう開発者に通知し、収益報告の正確性を確保しました。これにより、データインシデントの発生件数が75%削減されたという報告もあります。
· 下流システムへの影響防止:あるPRでは、列名の変更が14個の下流ダッシュボードを破損させる可能性がありました。DataGuardian AIは、この依存関係を追跡し、開発者に警告を発しました。これにより、ユーザーは変更をマージする前に必要な修正を行い、ダッシュボードのダウンタイムを防ぎました。
· パイプラインのパフォーマンス向上:欠落していたフィルター条件により、テーブルサイズが倍増し、パイプラインが遅延するリスクのあるPRを検知しました。DataGuardian AIの指摘により、開発者はフィルター条件を追加し、パイプラインのパフォーマンスを最適化しました。
· コードレビューサイクルの短縮:DataGuardian AIの導入により、レビューサイクルの平均時間が4日から1.5日に短縮されました。これは、AIが多くの一般的な問題を自動的に検出し、開発者がより複雑な問題に集中できるようになるためです。結果として、エンジニアリングチームの生産性が向上します。
11
UnisonDB - 超高速レプリケーションB+ツリーブランチ
著者
ankuranand
説明
UnisonDBは、100以上のノードにサブ秒レベルでレプリケーション可能なB+ツリーベースのデータベースです。分散システムにおけるデータの一貫性とパフォーマンスの課題を、革新的なレプリケーション技術で解決することを目指しています。つまり、大量のデータを複数の場所に瞬時に同期させたい場合に非常に役立ちます。
人気
ポイント 9
コメント 1
この製品は何ですか?
UnisonDBは、データの格納と取得を効率的に行うためのデータベースシステムです。特に、データを複数のサーバー(ノード)に複製(レプリケーション)する際に、非常に高速(サブ秒、つまり1秒未満)で同期を完了させることを得意としています。これは、B+ツリーというデータ構造を基盤とし、それを分散環境で最適に動作させるための独自のレプリケーションメカニズムを組み合わせているためです。これにより、システム全体で常に最新のデータが利用可能になり、高可用性と低遅延を実現できます。だから、システムがダウンしてもデータは失われにくく、どこからアクセスしても速くデータが返ってくるということです。
どのように使用しますか?
開発者は、APIやSDKを通じてUnisonDBをアプリケーションに組み込むことができます。標準的なデータベース操作(データの挿入、更新、削除、検索)に加え、ノードの追加や削除、レプリケーション設定の管理なども行えます。例えば、マイクロサービスアーキテクチャを採用している場合、各サービスが独立したデータストアを持つのではなく、UnisonDBを共有のデータ基盤として利用し、データの整合性を保ちながら、サービス間の連携をスムーズに行うことができます。つまり、アプリケーションのバックエンドでデータを管理する際に、このUnisonDBを使うことで、データの同期の手間を省き、開発のスピードを上げることができます。
製品の核心機能
· B+ツリーベースのデータ構造: データの検索、挿入、削除といった操作を高速化し、大量のデータを効率的に扱えます。だから、データベースの応答速度が速くなります。
· サブ秒レベルのレプリケーション: 100以上のノードにデータをほぼリアルタイムで同期させます。これにより、データの冗長性を高め、障害発生時にもサービスを継続できます。なので、システムが止まるリスクを減らせます。
· 分散トランザクションサポート(将来的に期待): 複数のノードにまたがる操作でも、データの整合性を保証します。だから、複雑なデータ操作でも安心して実行できます。
· スケーラビリティ: ノード数を増やすことで、システム全体の容量とパフォーマンスを拡張できます。なので、ユーザーが増えてもシステムが遅くなる心配がありません。
· 高可用性: レプリケーションにより、一部のノードがダウンしても、他のノードでサービスを提供し続けることができます。だから、常時稼働が求められるシステムに適しています。
製品の使用例
· リアルタイム分析プラットフォーム: 大量のイベントデータを収集し、即座に分析結果をユーザーに提供する必要がある場合。UnisonDBの高速レプリケーションにより、データソースからの取り込みと分析システムへの同期が遅延なく行われます。だから、最新のデータに基づいた意思決定が可能です。
· グローバルなeコマースサイト: 世界中のユーザーからの注文や在庫情報をリアルタイムで管理する必要がある場合。UnisonDBは、各地域のサーバーにデータを分散させつつ、常に一貫した在庫情報を提供できます。だから、顧客はどこからでも最新の在庫状況を確認でき、購入体験が向上します。
· IoTデバイス管理: 数万、数百万のIoTデバイスから送信されるセンサーデータを効率的に収集・処理する場合。UnisonDBは、大量の書き込みリクエストを分散処理し、リアルタイムでデバイスの状態を把握することを可能にします。だから、デバイスの監視や制御が迅速に行えます。
12
KeeprCLI
著者
bsamarji
説明
KeeprCLIは、開発者がローカル環境とターミナル操作を重視し、オフラインで利用できるシンプルなコマンドラインパスワードマネージャーです。機密情報をネットワークに一切触れさせず、ローカルの暗号化されたデータベースに安全に保管します。これにより、開発者は安心してパスワードなどの機密情報を管理できます。
人気
ポイント 6
コメント 2
この製品は何ですか?
KeeprCLIは、パスワードなどの機密情報をローカルのSQLCipherデータベースに暗号化して保存する、オフラインで動作するコマンドラインインターフェース(CLI)のパスワードマネージャーです。マスターパスワードでデータベース全体を保護し、作業中は一時的なセッションファイルを利用して、パスワードの再入力を頻繁に求められることなく安全にアクセスできます。AES-256暗号化と強力なパスワード派生関数(PBKDF2-HMAC-SHA256)を使用しており、ネットワーク通信を行わないため、外部からの不正アクセスリスクを大幅に低減します。これは、セキュリティを重視し、クラウドサービスに依存したくない開発者にとって、究極のプライバシーとコントロールを提供するソリューションです。
どのように使用しますか?
開発者はPython環境にKeeprCLIをインストールし(PyPI経由)、ターミナルからコマンドを実行して使用します。例えば、`keepr add`で新しいパスワード情報を追加し、`keepr search <キーワード>`で検索、`keepr view <エントリ名>`で表示、`keepr update`で更新、`keepr delete`で削除できます。パスワード生成機能やクリップボードへのコピー機能も備わっています。開発者は、APIキー、データベース認証情報、SSHキーのパスフレーズなど、機密性の高い情報をプロジェクトごとに整理して管理できます。これにより、コードに直接機密情報をハードコーディングするリスクを回避し、安全な開発ワークフローを構築できます。
製品の核心機能
· ローカル暗号化データベースへの安全なパスワード保存:AES-256暗号化により、機密情報がローカルストレージに安全に保管され、外部からの不正アクセスを防ぎます。これは、クラウド同期による情報漏洩のリスクを心配する開発者にとって安心材料となります。
· オフライン操作によるネットワークリスクの排除:インターネット接続なしで完全に動作するため、ネットワーク経由での情報漏洩や傍受の心配がありません。特に、セキュリティが厳格な環境や、頻繁にオフラインで作業する開発者にとって非常に有用です。
· 時間制限付きセッション管理:マスターパスワードの入力を最小限に抑えつつ、一定時間セッションを維持することで、利便性とセキュリティのバランスを取ります。これにより、頻繁なパスワード入力を避けつつ、セッション終了時には自動的にロックされ、安全性が保たれます。
· CLIベースの直感的な操作:コマンドラインインターフェースを通じて、パスワードの追加、表示、検索、更新、削除といった基本操作を効率的に行えます。開発者は、普段使い慣れたターミナル環境で、迅速に機密情報を管理できます。
· セキュアなパスワード生成機能:強力で推測されにくいパスワードを自動生成する機能を提供します。これにより、弱いパスワードの使用によるセキュリティリスクを低減し、パスワード管理の質を向上させます。
· クリップボードへの安全なコピー機能:生成または表示されたパスワードを、一時的にクリップボードにコピーする機能を提供します。これにより、パスワードの入力作業を簡素化しつつ、クリップボードからの意図しない漏洩を防ぐための考慮がなされています。
製品の使用例
· APIキーや認証情報管理:Web開発者が、外部APIの利用に必要なAPIキーや、データベース接続のための認証情報をKeeprCLIに保存・管理します。これにより、コードリポジトリに機密情報が混入するリスクを防ぎ、CI/CDパイプラインでの安全な利用を可能にします。
· SSHキーのパスフレーズ管理:リモートサーバーへのSSH接続に使用する秘密鍵のパスフレーズをKeeprCLIで管理します。これにより、パスフレーズを覚える手間が省け、かつ安全に管理できます。頻繁にサーバーにアクセスする開発者にとって、作業効率が向上します。
· ローカル開発環境での機密情報管理:ローカルのデータベースや開発ツールにアクセスするためのパスワードやシークレットをKeeprCLIに集約します。これにより、複数のパスワードを管理する負担を軽減し、一元化された安全な管理体制を構築できます。
· セキュリティ意識の高い開発者のためのプライベートパスワード管理:クラウドベースのパスワードマネージャーに抵抗がある開発者が、自身の機密情報を完全にローカルで、かつ暗号化された状態で管理するためのソリューションとして利用します。これにより、プライバシーを最大限に保護します。
13
Canvas AI 家具ビジュアルワークスペース
著者
kar_t
説明
Canvasは、AIを活用した家具選びのためのビジュアルワークスペースです。300万点以上の商品カタログから商品をドラッグ&ドロップしたり、インスピレーション画像をアップロードして自動的に購入可能な商品にリンクさせたり、AIで部屋のレンダリング画像を生成したりできます。家具選びの煩雑さを解消し、購入決定を支援します。
人気
ポイント 8
コメント 0
この製品は何ですか?
Canvasは、AIの力を使って家具選びをもっと簡単で楽しいものにするためのデジタル空間です。たとえば、Pinterestで見つけた素敵なソファの画像をアップロードすると、Canvasがそのソファに似た購入可能な商品を見つけてきてくれます。さらに、部屋の写真をアップロードすれば、AIがその部屋に家具を配置したイメージを生成してくれます。これにより、複数のウェブサイトをタブで開いたり、スクリーンショットを撮ったりする手間が省け、購入の意思決定がしやすくなります。
どのように使用しますか?
開発者は、CanvasのAPIを利用して、自社のECサイトに統合したり、家具提案ツールを構築したりできます。例えば、ユーザーが閲覧している商品の画像からインスピレーションを得て、類似商品をCanvas上で提案する機能を追加できます。また、AIによる部屋のレンダリング機能を組み込むことで、ユーザーが購入前に家具が部屋にどのように見えるかを確認できるようになります。
製品の核心機能
· 商品カタログ統合:数百万点の商品をシームレスに統合し、検索、閲覧、追加を可能にします。これにより、開発者は自社で膨大な商品データベースを管理する手間を省けます。
· 画像からの商品検索:ユーザーがアップロードした画像から、購入可能な類似商品をAIが自動で検出します。これは、ユーザーが「こんな雰囲気の家具が欲しい」と思ったときに、具体的な商品を見つける強力な手段となります。
· AIによる部屋のレンダリング:ユーザーの部屋の写真や間取り図をもとに、AIが家具を配置したrealisticなレンダリング画像を生成します。これにより、購入前に家具が部屋にどのようにフィットするかを視覚的に確認でき、失敗のない家具選びを支援します。
· 無限キャンバスインターフェース:家具の配置やインスピレーション画像の整理を自由に行える、広々とした作業スペースを提供します。これは、複雑な家具選びのプロセスを直感的に管理するためのUI/UXの進化です。
· インスピレーションと購入の連携:PinterestなどのSNSで見つけたデザインアイデアを、直接購入可能な商品へと繋げます。これにより、インスピレーションから購入までのプロセスがスムーズになり、ユーザーの購買意欲を高めます。
製品の使用例
· 家具ECサイトでの「あなたへのおすすめ」機能強化:ユーザーの閲覧履歴や「いいね」した商品画像をもとに、AIがCanvas上で関連性の高い家具を自動で抽出し、パーソナライズされた提案を行います。これにより、ユーザーはより自分好みの商品に出会いやすくなり、エンゲージメントが向上します。
· インテリアコーディネートアプリへの統合:ユーザーが部屋の写真をアップロードし、AIに家具の提案を依頼する機能を提供します。CanvasのAIレンダリング機能を使うことで、ユーザーは自宅に家具を配置した際のイメージを具体的に把握でき、購入へのハードルが下がります。
· 不動産業界での物件紹介ツール:内装デザインのオプションとして、AIが生成した家具配置イメージを物件のバーチャルツアーに含めることで、購入希望者に物件の魅力をより効果的に伝えることができます。これにより、物件の成約率向上に貢献します。
· デザインコンサルタント向けのクライアント提案ツール:クライアントの要望やインスピレーション画像を元に、Canvas上で迅速に家具のレイアウト案やレンダリングを作成し、提案することができます。これにより、デザインプロセスが効率化され、クライアント満足度を高めることができます。
14
Vibe Capsule - 音楽の宝箱アプリ
著者
hunterirving
説明
Vibe Capsuleは、あなたのMP3ファイルを、友達と共有できるオフラインで動作するWebアプリケーションに変換するプロジェクトです。かつてカセットテープやCDで音楽を共有していた頃のように、自分だけの音楽コレクションを「デジタルギフト」として贈れるようにすることを目指しています。これにより、サブスクリプションサービスや地域制限に縛られず、いつでもどこでも音楽を楽しめます。
人気
ポイント 5
コメント 2
この製品は何ですか?
Vibe Capsuleは、Pythonスクリプトを使って、あなたが提供したMP3ファイルをWebアプリケーション(Progressive Web App - PWA)にパッケージ化するツールです。このPWAは、一度ダウンロードすればインターネット接続なしで、スマートフォンやPCなどのあらゆるデバイスでオフライン再生が可能です。これにより、音楽データがユーザー自身の手元に置かれ、サービス提供者の都合や地域制限に影響されなくなります。これは、所有するデジタルコンテンツを、単なるリンクではなく、永続的な「ギフト」として共有するための革新的なアプローチです。
どのように使用しますか?
開発者は、Vibe CapsuleのGitHubリポジトリからPythonスクリプトをダウンロードし、共有したいMP3ファイルを指定のフォルダに置きます。その後、スクリプトを実行すると、「mixapp」と呼ばれるWebアプリケーションファイルが生成されます。このファイルをHTTPSに対応したWebサーバーにアップロードすれば、誰でもそのURLにアクセスし、ホーム画面にインストールしてオフラインで音楽を聴くことができるようになります。つまり、数クリックで自分だけの音楽プレイヤーアプリを作成し、共有できるのです。
製品の核心機能
· MP3ファイルをPWAとしてパッケージ化する機能:あなたの音楽コレクションを、プラットフォームに依存しない独立したWebアプリケーションとして提供します。これにより、友人や家族は特別なアプリをインストールすることなく、あなたの選んだ音楽をすぐに楽しめます。
· オフライン再生機能:一度ダウンロードすれば、インターネット接続がない場所でも音楽を聴くことができます。旅行中や電波の届かない場所でも、あなたの選んだ音楽が途切れることはありません。
· ホーム画面へのインストール機能:PWAはスマートフォンのホーム画面にアイコンとして追加でき、ネイティブアプリのように手軽に起動できます。これにより、お気に入りの音楽へのアクセスがさらに便利になります。
· 地域制限やサブスクリプションからの解放:音楽データはユーザー自身が管理するため、特定の地域でしか聴けなくなったり、サービスが終了したりする心配がありません。あなたの音楽は、あなたが管理する限り永遠に聴き続けることができます。
製品の使用例
· 友達への誕生日プレゼントとして、思い出の曲を集めたカスタムプレイリストアプリを作成する:単に曲名を伝えるのではなく、友達がすぐに聴ける形でプレゼントでき、特別な体験を提供できます。
· 家族旅行のために、皆で楽しめるオフライン対応の音楽アプリを作成する:インターネット接続が不安定な場所でも、家族全員で音楽を共有し、旅行の雰囲気を盛り上げることができます。
· 自身のDJミックスや楽曲を、ファンに配布するための独立したアプリケーションとして提供する:アーティストは、プラットフォームの制約を受けずに、自身の作品を直接ファンに届け、ファンはオフラインでいつでも作品を楽しめます。
15
バブルラボ:コード駆動型エージェントワークフロープラットフォーム
著者
hkselinali
説明
Bubble Labは、コードで定義された自己判断能力を持つエージェントが、一連のタスクを自律的に実行するワークフロープラットフォームです。複雑なビジネスプロセスやデータ処理を、人間が指示するだけでなく、エージェント自身が状況に応じて判断し、次のステップに進むように設計されています。これは、まるでAIアシスタントが自分で考えて仕事を進めてくれるようなイメージです。
人気
ポイント 5
コメント 2
この製品は何ですか?
Bubble Labは、開発者がコードを使って「エージェント」を作成し、それらが連携して自動化されたワークフローを構築できるプラットフォームです。各エージェントは、特定のタスクを実行するための指示(コード)と、状況を判断するためのロジックを持ちます。例えば、あるエージェントが「顧客からの問い合わせメールを解析する」というタスクを実行し、その結果を別のエージェントに渡して「関連するFAQを検索する」といった連携が可能です。これにより、従来は人間が手作業で行っていたり、単純な自動化ツールでは対応できなかった、より複雑で動的なプロセスを自動化できます。技術的な核心は、エージェント間の情報伝達と、各エージェントが自身のタスクを完了するために必要な判断能力をコードで定義する点にあります。
どのように使用しますか?
開発者は、Pythonなどのプログラミング言語でBubble Labのエージェントを定義します。各エージェントは、入力データを受け取り、実行すべき処理(API呼び出し、データベース操作、テキスト処理など)をコードで記述し、その結果や次のアクションを決定するロジックを組み込みます。これらのエージェントを組み合わせて、一連のワークフローを構築します。例えば、Webアプリケーションに組み込んで、ユーザーの操作に応じてバックエンドで複雑なデータ処理を自動化したり、データ分析パイプラインの一部として利用したりできます。API経由での統合や、CLI(コマンドラインインターフェース)での実行も可能です。
製品の核心機能
· エージェント定義:開発者はPythonコードで個々のエージェントの振る舞いを定義します。これにより、特定のタスクを実行する自律的な処理単位を作成でき、再利用性や保守性を高めます。
· ワークフロー構築:定義したエージェントを組み合わせて、一連の自動化されたプロセス(ワークフロー)を設計します。これにより、複雑なビジネスロジックやデータ処理パイプラインを効率的に構築できます。
· 動的実行:エージェントは、実行中に得られる情報に基づいて次のステップを判断できます。これにより、固定的な手順では対応できない、状況に応じた柔軟な処理を実現し、より高度な自動化を可能にします。
· 外部システム連携:API呼び出しやデータベースアクセスなどのコードをエージェントに組み込むことで、様々な外部システムと連携できます。これにより、既存のシステムと統合された強力な自動化ソリューションを構築できます。
· オープンソース:プロジェクトがオープンソースであるため、開発者は自由にコードを閲覧、修正、拡張できます。これにより、コミュニティによる改善や、特定のニーズに合わせたカスタマイズが促進され、技術革新のスピードが加速します。
製品の使用例
· 顧客サポート自動化:顧客からの問い合わせメールを解析し、FAQから関連情報を検索して回答を生成するエージェントフローを構築。これにより、サポート担当者の負担を軽減し、応答時間を短縮できます。
· データ分析パイプライン:Webスクレイピングでデータを収集し、クリーニング、変換、そして機械学習モデルでの分析までの一連のプロセスをエージェントの連携で自動化。これにより、データサイエンティストは分析自体に集中できます。
· ソーシャルメディア管理:指定されたキーワードに基づき、ソーシャルメディアから関連投稿を収集・分析し、レポートを自動生成するシステムを構築。これにより、マーケティング担当者は市場の動向を迅速に把握できます。
· IoTデバイス管理:複数のIoTデバイスからのセンサーデータをリアルタイムで収集・監視し、異常を検知した場合にアラートを発令するエージェントフローを構築。これにより、システム運用者は迅速な対応が可能になります。
16
タイムカード計算ロジック抽出エンジン
著者
atharvtathe
説明
このプロジェクトは、複雑なタイムカードの計算ロジックを、よりシンプルで理解しやすい形式に抽出・再構築するツールです。開発者がタイムカードシステムを構築する際の、時間計算の曖昧さや、さまざまな労働時間規則(残業、深夜手当など)の複雑さを解消し、迅速かつ正確な実装を支援します。
人気
ポイント 5
コメント 0
この製品は何ですか?
これは、タイムカードの計算、つまり、いつ働いて、いつ休憩を取り、いつ終業したかという記録から、正確な労働時間、残業時間、深夜手当などを自動で計算するための「頭脳」部分を、より分かりやすく、再利用しやすい形に整理するプロジェクトです。従来のタイムカードシステムでは、この計算ロジックが複雑で、バグが発生しやすかったり、新しい規則への対応が大変でした。このプロジェクトは、その計算の「ルールブック」を明確に抽出し、コードとして扱いやすくすることで、開発者がより早く、より正確なタイムカードシステムを構築できるようにします。
どのように使用しますか?
開発者は、既存のタイムカード計算ロジック(例えば、特定の言語やフレームワークで書かれたもの)をこのエンジンに渡します。エンジンは、そのロジックを解析し、基本的な時間計算、休憩時間の考慮、残業時間の計算、休日出勤、深夜労働などのルールを、汎用的な形式で出力します。これにより、開発者は、これらの抽出されたロジックを、新しいシステムに組み込んだり、既存のシステムを改修したりする際に、ゼロから計算ロジックを記述する手間を省き、バグのリスクを減らすことができます。例えば、Pythonで書かれたタイムカード計算モジュールを解析し、それをJavaScriptのプロジェクトで再利用する、といったことが可能になります。
製品の核心機能
· 時間計算ロジックの構文解析と抽象化:複雑な時間計算のコードを読み解き、その計算の「意図」を汎用的なルールとして抽出します。これにより、さまざまなプログラミング言語やシステムで利用できる基盤となります。
· 労働時間規則のルール化:休憩時間、残業時間、休日出勤、深夜労働といった、タイムカード計算で重要な様々な規則を、明確なルールセットとして定義・抽出します。これにより、規則の変更にも柔軟に対応できるようになります。
· 計算ロジックの可視化と検証:抽出された計算ロジックを、開発者が理解しやすい形式で表示します。これにより、意図した通りに計算が行われているかを確認しやすくなります。
· 既存ロジックの再利用性向上:既存のタイムカード計算コードを、よりモジュール化され、再利用しやすい形に変換します。これにより、開発者は、共通の計算ロジックを複数のプロジェクトで効率的に利用できます。
· 新規開発の高速化:タイムカード計算の基礎となるロジックが提供されるため、新規開発者は、計算部分をイチから作る必要がなく、よりビジネスロジックやUIの設計に集中できます。
製品の使用例
· 新しい勤怠管理システムの開発:開発者は、このエンジンを使用して、多様な残業・深夜手当の計算ルールを迅速にシステムに組み込むことができます。これにより、複雑な労働法規への対応が容易になります。
· 既存のタイムカードシステムの改修:例えば、法改正によって残業時間の定義が変わった場合、このエンジンで抽出したロジックを元に、影響範囲を特定し、効率的に改修作業を行うことができます。
· アルバイト・パートタイム従業員のシフト管理ツールの作成:個々の従業員の勤務形態や契約条件に合わせた、柔軟な時間計算ロジックを実装する際に役立ちます。
· フリーランス向けの請求書作成ツールの開発:フリーランスが自身の労働時間を正確に記録し、クライアントに請求するためのツールにおいて、正確な労働時間計算機能を提供するために利用できます。
· HRテック分野での応用:人事・労務管理の効率化を目指すサービスにおいて、従業員の出勤・退勤記録から給与計算に必要な正確な労働時間を算出するバックエンド機能として活用できます。
17
StoryMotion: アニメーション図解ジェネレーター
著者
chunza2542
説明
StoryMotionは、コードの変更履歴やUIの操作手順などを、アニメーションとしてステップバイステップで分かりやすく説明できるツールです。技術的な概念や複雑なプロセスを視覚化することで、開発者間のコミュニケーションやドキュメンテーション作成を劇的に改善します。
人気
ポイント 1
コメント 4
この製品は何ですか?
StoryMotionは、開発者がコードの進化、アルゴリズムの動作、またはユーザーインターフェースの操作フローといった、時間軸を伴う動的なプロセスをアニメーションで表現するためのツールです。その核となる技術は、JavaScriptとSVG(Scalable Vector Graphics)の組み合わせにあります。SVGはベクターベースの画像フォーマットであり、拡大縮小しても画質が劣化しないため、どのような画面サイズでも鮮明に表示されます。StoryMotionは、これらのSVG要素をJavaScriptで動的に操作し、描画タイミングや位置、形状の変化を制御することで、滑らかなアニメーションを生成します。これにより、静的な画像では伝えきれない「どのように変化していくか」「どのような順序で進むか」といった情報を、直感的かつ効率的に伝えることが可能になります。これは、従来の静的な図解に比べて、学習コストを大幅に削減し、理解を深める強力な手段となります。
どのように使用しますか?
開発者は、StoryMotionのWebインターフェースまたはAPIを使用して、アニメーションを作成します。例えば、コードの特定のバージョン間での変更点を可視化したい場合、コードスナップショットとその差分を入力としてStoryMotionに与えると、コードがどのように変化したかを示すアニメーションが生成されます。UI操作の説明では、画面遷移やボタンクリック、入力フィールドへの文字入力といった一連のユーザーアクションを定義することで、チュートリアル動画のようなアニメーションを作成できます。生成されたアニメーションは、Markdownファイルに埋め込んだり、Webサイトに直接組み込んだりすることが可能です。これにより、READMEファイル、開発者向けドキュメント、ブログ記事、さらにはプレゼンテーション資料など、様々な場面で活用できます。
製品の核心機能
· コード変更履歴のアニメーション化: Gitのコミット履歴やコードの差分を基に、コードが時間とともにどのように変化していくかを視覚的に表現します。これにより、コードレビューや過去の変更点の追跡が容易になります。
· UI操作フローのアニメーション化: アプリケーションのUIにおけるユーザー操作の流れをステップごとにアニメーション化します。これにより、チュートリアルやオンボーディング資料の作成が効率化され、ユーザーの学習を促進します。
· アルゴリズム動作の可視化: 複雑なアルゴリズムの各ステップでのデータ構造や処理の流れをアニメーションで示します。これにより、アルゴリズムの理解を助け、デバッグや教育に役立ちます。
· インタラクティブなアニメーション生成: 特定のイベント(例: ボタンクリック)に応じてアニメーションが進行するように設定できます。これにより、より動的でエンゲージメントの高い説明が可能になります。
· 埋め込み可能な出力形式: 生成されたアニメーションをGIF、MP4、またはWebP形式でエクスポートし、簡単にドキュメントやWebサイトに埋め込むことができます。これにより、コンテンツの共有と普及が容易になります。
製品の使用例
· ある開発者が、新しい機能のUIデザインをチームに説明する際にStoryMotionを使用しました。従来のワイヤーフレームではなく、操作フローをアニメーションで示したことで、チームメンバーは機能の使い勝手を直感的に理解でき、フィードバックの質が向上しました。
· オープンソースプロジェクトのメンテナーが、過去の複雑なコードリファクタリングの過程をStoryMotionでアニメーション化し、READMEファイルに埋め込みました。これにより、新しくプロジェクトに参加する開発者が、コードベースの進化の歴史を容易に把握できるようになり、貢献へのハードルが下がりました。
· 機械学習エンジニアが、特定のアルゴリズムの学習プロセスにおける中間状態をStoryMotionで可視化しました。これにより、学習の進捗やモデルの挙動を詳細に分析できるようになり、チューニングの効率が向上しました。
18
ByteSync - 透かし検出型エンドツーエンド暗号化ハイブリッド同期
著者
paulfresquet
説明
ByteSyncは、ローカルとリモートの同期のギャップを埋めるオープンソースのファイル同期、バックアップ、重複排除ツールです。FreeFileSyncに似ていますが、統合されたネットワークレイヤーとエンドツーエンド暗号化を備えています。これにより、VPNやファイアウォール設定なしで、LAN上またはインターネット経由でコンピューター間でファイルを同期できます。すべてが同じインターフェイスで透過的に機能します。
人気
ポイント 3
コメント 2
この製品は何ですか?
ByteSyncは、コンピューター間でファイルを安全かつ効率的に同期するための革新的なツールです。従来の同期ツールと異なり、VPNや複雑なネットワーク設定が不要で、エンドツーエンド暗号化によりプライバシーが保護されます。ファイルが変更された部分のみを検出して同期するため、大量のデータでも高速に処理できます。また、ファイル名だけで比較するモードもあり、柔軟な使い方が可能です。これは、開発者がコードで問題を解決するというハッカー精神を体現しており、誰でも利用できるプライバシーを尊重したハイブリッドファイル同期の代替手段を目指しています。
どのように使用しますか?
開発者は、ByteSyncをインストールして、同期したいローカルフォルダとリモートリポジトリ(サーバーやNASなど)を設定します。GUIインターフェイスで、同期セッションに参加するノード(コンピューター)とデータソース(同期対象のフォルダやファイル)を指定します。ByteSyncは、指定されたノード間でファイルの変更を自動的に検出し、暗号化して転送します。CLI統合も計画されており、将来的には自動化やスクリプトからの利用も可能になります。Windows、macOS、Linuxで動作します。
製品の核心機能
· エンドツーエンド暗号化によるセキュアなファイル同期:通信内容が第三者に傍受される心配がなく、機密性の高いファイルを安全に同期できます。これにより、インターネット経由でのファイル共有でもプライバシーが保護されます。
· VPN不要の直接的なLANおよびインターネット同期:複雑なネットワーク設定をせずに、LAN内はもちろん、インターネットを介して離れた場所にあるコンピューター間でも直接ファイルを同期できます。これにより、セットアップの手間が大幅に削減されます。
· 差分検出と効率的な転送:ファイル全体ではなく、変更された部分のみを特定して転送します。これにより、大量のファイルでも同期時間が短縮され、帯域幅の使用量も最適化されます。
· 重複排除機能:同じファイルが複数箇所に保存されている場合、重複分を検出し、ストレージ容量を節約します。バックアップやアーカイブの際に特に役立ちます。
· 柔軟な同期モード(フラットモード):ファイル構造を無視し、ファイル名だけで比較・同期するモードも提供します。これにより、特定のディレクトリ構造に依存せず、ファイル名のみで管理したい場合に柔軟に対応できます。
製品の使用例
· リモートワーク環境でのチームファイル共有:離れた場所にいるチームメンバー間で、最新のプロジェクトファイルをVPNなしで安全に共有し、共同作業を促進します。
· 個人所有の複数デバイス間でのデータ同期:デスクトップPC、ラップトップ、タブレットなど、複数のデバイス間で写真、ドキュメント、コードなどを常に最新の状態に保ちます。
· 自宅サーバーやNASへの自動バックアップ:重要なデータを自宅のNASやサーバーに定期的にバックアップし、PCの故障や紛失に備えます。インターネット経由でも安全にバックアップできます。
· 開発環境の同期:開発者は、ローカルの開発環境とリモートのテストサーバー間でコードや設定ファイルを同期し、開発ワークフローを効率化します。
19
予測市場データ統合ハブ
著者
ritzammm
説明
このプロジェクトは、複数の予測市場プラットフォームからデータを収集・集計し、分析可能な単一のデータソースを提供する、革新的なデータ集約ツールです。技術的な洞察として、分散型の予測市場における情報のサイロ化という問題を解決し、より包括的な市場分析を可能にします。開発者にとっては、複雑なAPI統合の手間を省き、迅速なデータアクセスと分析基盤の構築を支援します。
人気
ポイント 5
コメント 0
この製品は何ですか?
これは、様々な予測市場(例えば、特定のイベントの結果に賭けることができるプラットフォーム)から、それぞれの市場で提示されている「価格」(これは確率を示唆する)や取引量といったデータを自動的に集めて、一つにまとめるシステムです。革新的な点は、これまでバラバラだった各プラットフォームのデータを、開発者が簡単に扱えるように標準化された形式で提供する点にあります。つまり、市場の全体像を把握しやすく、より賢い投資判断や分析を可能にするための土台を提供します。なので、これは市場の「声」を一つの強力なデータストリームに集約する技術と言えます。
どのように使用しますか?
開発者は、このプロジェクトが提供するAPI(プログラムでこのシステムに指示を送るための窓口)を通じて、リアルタイムまたはバッチで予測市場のデータを取得できます。例えば、機械学習モデルを構築するために、過去の予測市場データを集めたい場合、このハブを使えば、個々のプラットフォームのAPIを一つ一つ調べる必要がなく、このハブからまとめてデータをダウンロードできます。これにより、データ収集の時間を大幅に短縮し、分析やモデル開発に集中できます。なので、AI開発者やデータアナリストが、手軽に多様な市場のインサイトを得るために使えます。
製品の核心機能
· 複数プラットフォームからのデータ自動収集: 予測市場プラットフォームごとに異なるAPI仕様を吸収し、開発者は単一のインターフェースでデータにアクセスできます。これにより、データソースの多様性を活かした分析が可能になります。
· データ正規化と標準化: 集められたデータを、どのプラットフォーム由来であっても統一された形式に変換します。これにより、データの比較や集計が容易になり、分析の精度と効率が向上します。
· リアルタイムデータストリーミング: 市場の動向を迅速に捉えるため、データの更新をリアルタイムで提供します。これにより、刻々と変化する市場の状況に即応した意思決定が可能になります。
· 集計および分析機能: 収集・正規化されたデータを基に、市場全体の確率の加重平均やボラティリティなどを算出する機能を提供します。これにより、個々の市場だけでは見えない全体的な市場センチメントを把握できます。
製品の使用例
· 政治イベントの結果予測: 選挙の行方や特定の政策の通過確率など、政治イベントの結果を予測する市場のデータを集約し、どの候補者や政策が有利か、市場がどのように評価しているかを分析する際に利用できます。これにより、メディアの報道とは異なる、市場参加者の集合知に基づいた予測が可能になります。
· 仮想通貨市場のセンチメント分析: 特定の仮想通貨の将来的な価格変動や、プロジェクトの成功確率などを予測する市場のデータを収集し、市場全体のセンチメントを把握します。これにより、投資判断の補助や、アルゴリズム取引戦略の構築に役立てることができます。
· スポーツイベントの結果予測: サッカーの試合結果や、特定の選手が記録するスコアなどを予測する市場のデータを分析し、オッズの乖離や市場の偏りを見つけ出すことで、より有利な賭け方や投資機会を発見できます。
· 学術研究における市場データ活用: 経済学や行動科学の分野で、予測市場がどのように意思決定に影響を与えるか、あるいは情報伝達のメカニズムを研究する際に、このハブが提供する統合データセットは貴重なリソースとなります。
20
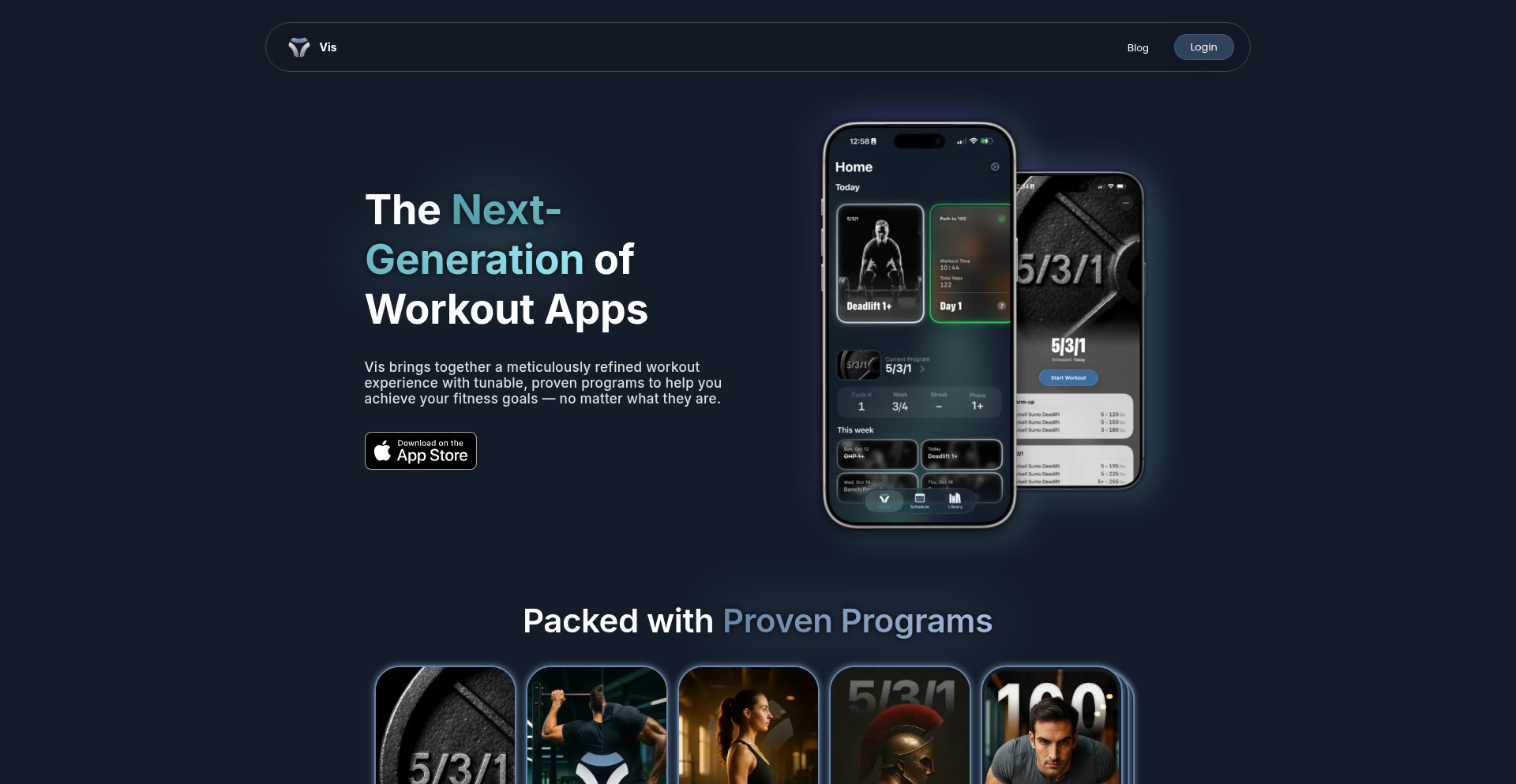
Vis – 進化型ワークアウト・プランナー
著者
strongpigeon
説明
Visは、単なるトレーニング記録アプリではありません。あなたの1RM(最大挙上重量)などのパラメーターに基づいて、パーソナライズされたトレーニングプログラムを動的に生成する革新的なワークアウト・プランナーです。以前の5/3/1アプリの成功から派生し、ユーザーが独自のプログラムを作成できる柔軟性を重視して開発されました。特に、直感的なインターフェースと、ライブアクティビティ機能を活用したワークアウト体験が特徴です。このアプリは、あなたのフィットネス目標達成を、よりスマートで効率的な方法でサポートします。
人気
ポイント 5
コメント 0
この製品は何ですか?
Visは、あなたのトレーニングの目標と現在の能力(例:最大挙上重量)に基づいて、最適なトレーニングプログラムを自動的に計算・生成する次世代のワークアウトアプリです。従来の表計算のようなUIではなく、今行っているトレーニングに集中できる、より直感的でアクティブな体験を提供します。さらに、トレーニングのスケジュール変更も「ジグルモード」のようなインターフェースで簡単に行えます。これは、最新のSwiftUI技術を使用して構築されており、ロック画面からワークアウトを追跡できるライブアクティビティのような機能も統合されています。つまり、Visは、あなたのフィットネスジャーニーを、よりパーソナライズされ、より効率的で、より楽しいものに変えるためのスマートなツールです。
どのように使用しますか?
開発者は、VisをiOSアプリとしてApp Storeからダウンロードして利用できます。主要なプログラム(例:5/3/1)がプリセットされており、すぐにトレーニングを開始できます。将来的には、独自のプログラムを、アプリの強力なエンジンを使って作成できるようになります。これは、API連携やカスタム機能開発の可能性を示唆しており、フィットネス・トラッキング、パフォーマンス分析、またはパーソナライズされたフィットネス体験を提供する他のアプリとの統合の基盤となり得ます。例えば、フィットネスAPIと連携して、Visで生成されたワークアウトプランを他のフィットネスデバイスやプラットフォームに同期させるといった応用が考えられます。
製品の核心機能
· 動的プログラム生成:ユーザーの1RMなどのデータに基づいて、トレーニングの負荷とボリュームを自動的に調整するプログラムを生成します。これにより、常に最適なトレーニング強度を維持し、成長を最大化できます。これは、個々の進捗に合わせたトレーニング計画の自動調整という価値を提供します。
· 直感的ワークアウトインターフェース:現在のワークアウトに集中できる、シンプルで分かりやすいUIを提供します。これにより、トレーニング中の迷いを減らし、集中力を高めることができます。これは、トレーニング体験の質を向上させるという価値があります。
· 容易なスケジュール変更:トレーニングのスケジュールを簡単に調整できる「ジグルモード」のようなインターフェースを採用しています。これにより、予期せぬ予定変更にも柔軟に対応でき、トレーニングの継続性を確保します。これは、ワークアウトの柔軟性を高めるという価値を提供します。
· ライブアクティビティ統合:iOSのライブアクティビティ機能を活用し、ロック画面からワークアウトの進捗状況をリアルタイムで確認できます。これにより、トレーニング中の利便性が向上し、スマートフォンの操作を最小限に抑えられます。これは、ワークアウト中のユーザーエクスペリエンスを向上させるという価値があります。
· カスタムプログラム作成(将来予定):ユーザーが独自のトレーニングプログラムを定義し、Visのエンジンで管理できるようになります。これにより、より高度なパーソナライゼーションが可能になり、多様なトレーニングニーズに対応できます。これは、トレーニングの自由度とカスタマイズ性を高めるという価値があります。
製品の使用例
· フィットネスコーチが、クライアント一人ひとりの進捗状況と目標に合わせて、 Vis を使用してパーソナライズされたトレーニングプログラムを迅速に作成・提供できます。これにより、コーチングの効率が向上し、クライアントの満足度も高まります。
· パワーリフターが、自身の1RMを Vis に入力することで、5/3/1 のような実績のあるプログラムを、自身の能力に合わせて最適化された形で実行できます。これにより、怪我のリスクを抑えつつ、着実に記録を伸ばしていくことが期待できます。
· ランニング愛好家が、来たるマラソン大会に向けて、Vis のプログラム生成機能を活用して、持久力向上と疲労回復のバランスを考慮したトレーニングプランを立てることができます。これにより、より計画的で効果的なトレーニングが可能になります。
· フィットネスアプリ開発者が、Vis のコアエンジンやAPI(将来的に公開される場合)を活用し、自社アプリに高度なプログラム生成機能やインテリジェントなワークアウト追跡機能を追加することができます。これにより、製品の差別化と競争力強化につながります。
21
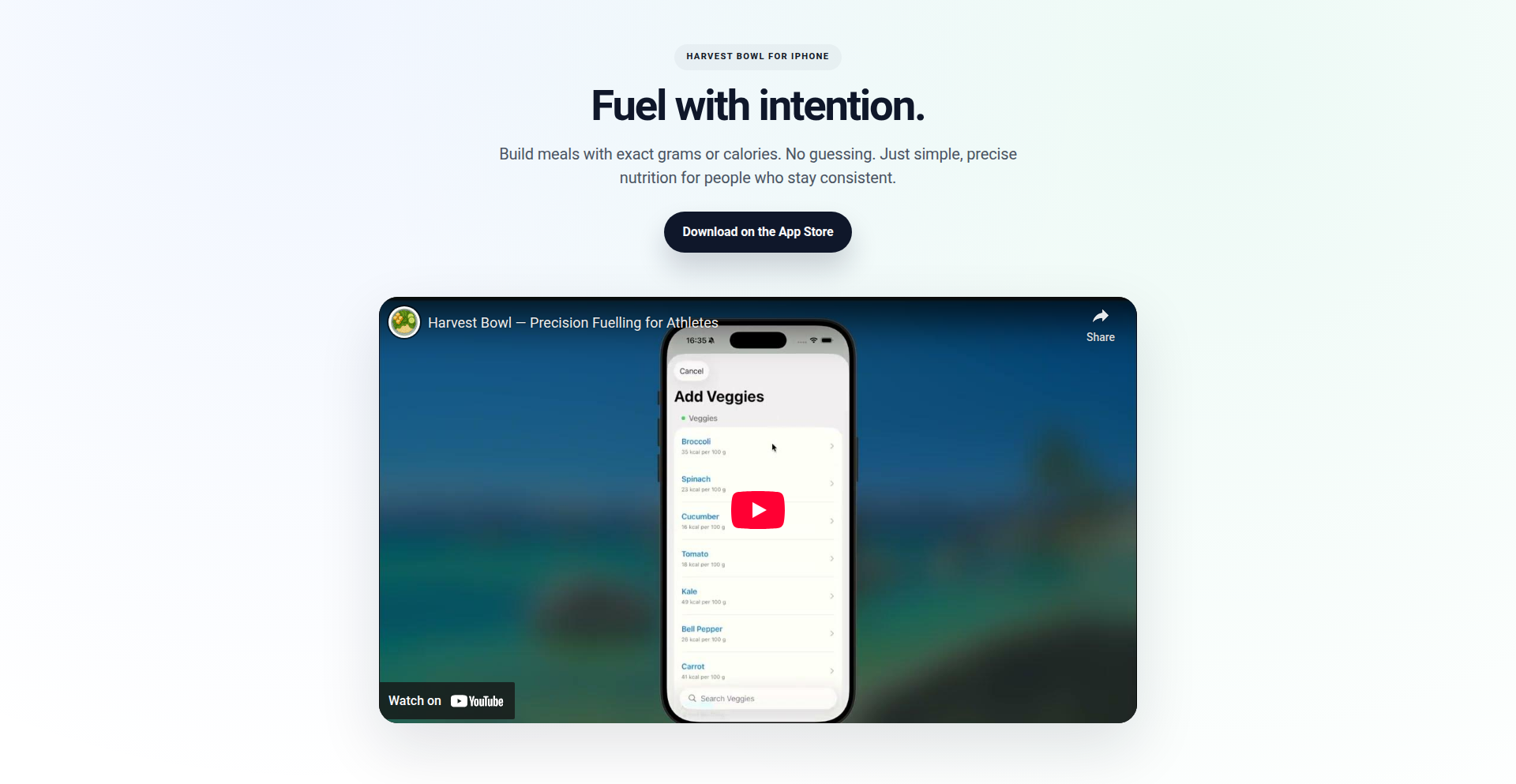
Harvest Bowl - 直感的なマクロ計算アプリ
著者
harvest_bowl
説明
Harvest Bowlは、食事をグラム単位またはカロリー単位で正確に構築し、ポーションを調整するたびにマクロ(タンパク質、脂質、炭水化物)を即座に表示するシンプルなiPhoneアプリです。煩雑な食品データベースやフル機能のトラッキングアプリを使わずに、手軽に食事プランを立てたいというニーズに応えるために開発されました。直感的なスライダー操作で、材料のポーションを調整するだけで、栄養素の数値がリアルタイムで更新されるのが革新的な点です。
人気
ポイント 3
コメント 2
この製品は何ですか?
Harvest Bowlは、食材を選んでポーションサイズ(グラムまたはカロリー)をスライダーで調整するだけで、その食事のタンパク質、脂質、炭水化物のバランス(マクロ栄養素)をリアルタイムで把握できる、非常にシンプルで使いやすい食事構築アプリです。従来の栄養追跡アプリのような煩雑な食品検索や入力作業を省き、「この材料をこれくらい食べたら、栄養素はどうなる?」という疑問に即座に答えることを目指しています。技術的な工夫としては、ユーザーの直感的な操作(スライダー)に即座に反応するUI/UX、そしてバックエンドでの効率的な栄養計算ロジックが挙げられます。これにより、ユーザーは迷うことなく、目的の栄養バランスに合った食事を素早く組み立てることができます。だから、これはあなたが複雑な栄養計算に時間を費やすことなく、健康的な食事を簡単に計画できるということです。
どのように使用しますか?
開発者は、iOSデバイス上でHarvest Bowlアプリをダウンロードして利用できます。アプリを開き、まずリストから食材を選択します。次に、各食材のポーションサイズを、画面上のスライダーをドラッグしてグラムまたはカロリー単位で調整します。ポーションを調整するたびに、画面上部に表示されるタンパク質、脂質、炭水化物、総カロリーの数値が瞬時に更新されます。よく使う食事(ボウル)は保存しておくことも可能です。技術的な統合というよりは、個人の健康管理や栄養プランニングのためのツールとして、日々の食事作成に直接活用できます。例えば、特定のタンパク質量を目指したい場合、スライダーを操作して目標値を達成する食材の組み合わせを見つけるといった使い方です。だから、これはあなたが減量、増量、または特定の栄養目標達成のための食事を、煩雑な入力なしに、視覚的かつ直感的に管理できるということです。
製品の核心機能
· グラム/カロリー精度のスライダー: 食材のポーションをミリグラム単位またはカロリー単位で微調整できる機能です。これにより、ユーザーは非常に正確に食事量をコントロールでき、栄養目標達成の精度を高めます。応用シーンとしては、厳密な食事制限を必要とするアスリートや、特定の栄養素摂取量を管理したいユーザーが挙げられます。
· インスタントマクロ表示: 食材のポーションを変更するたびに、タンパク質、脂質、炭水化物の各マクロ栄養素と総カロリーがリアルタイムで更新される機能です。これにより、ユーザーは食事を構築しながら、その栄養バランスを瞬時に把握でき、目標とする栄養比率に調整しやすくなります。応用シーンとしては、ダイエット中や筋肉増強を目指すユーザーが、手軽に食事の栄養バランスを確認し、調整する際に役立ちます。
· クリーンな食材リスト: ユーザーが食事に含めたい食材を、シンプルで整理されたリストから素早く選択できる機能です。煩雑な検索フィールドや長いリストに悩むことなく、目的の食材にたどり着けます。応用シーンとしては、忙しい日常の中で迅速に食事プランを立てたいユーザーや、特定の食材を頻繁に使用するユーザーに便利です。
· クイックベジタブルプリセット: 健康的な食事に不可欠な野菜類を、よく使われるプリセットから素早く追加できる機能です。これにより、栄養価の高い食事を簡単に構成できます。応用シーンとしては、手軽に栄養バランスの取れた食事を意識したい一般ユーザーや、食事に野菜を積極的に取り入れたいと考えているユーザーに役立ちます。
· お気に入りのボウル保存: ユーザーが作成したお気に入りの食事(ボウル)を保存しておき、後で簡単に再利用できる機能です。これにより、毎回同じような食事をゼロから作る手間が省け、時間効率が向上します。応用シーンとしては、ルーティン化したい健康的な食事や、特定の栄養目標を達成するための定番メニューを登録する際に便利です。
製品の使用例
· 開発者Aは、減量目標のために毎日のタンパク質摂取量を150gに設定したいと考えています。Harvest Bowlを使えば、鶏むね肉や魚などのタンパク質源となる食材をスライダーで調整し、タンパク質量が150gに近づくまでリアルタイムで確認できます。これにより、煩雑なカロリー計算アプリで一つ一つ食材を検索・入力する手間が省け、目標達成に向けた食事を素早く組み立てられました。
· 開発者Bは、筋肉増強のために、1食あたりの炭水化物とタンパク質の比率を2:1に保ちたいと考えています。Harvest Bowlで食材を選び、ポーションを調整しながら、表示されるマクロ栄養素の比率を確認することで、理想的な栄養バランスの食事を視覚的に構築できます。これにより、栄養士の指導がなくても、自身のトレーニング目標に合った食事プランを効率的に作成できます。
· 開発者Cは、忙しい日のランチを健康的に済ませたいと考えています。Harvest Bowlで、あらかじめ保存しておいた「クイックサラダボウル」のプリセットを呼び出し、野菜のポーションを少し調整するだけで、栄養バランスの取れたランチがすぐに完成します。これは、外食で栄養バランスの偏った食事を選んでしまうリスクを減らし、健康的な食生活を維持するのに役立ちます。
22
Android 無制限 eBPF ホットスポット
著者
Gave4655
説明
Android デバイスで eBPF (Extended Berkeley Packet Filter) を活用し、実質的に無制限なテザリング(ホットスポット機能)を提供する革新的なプロジェクトです。従来の Android のテザリング制限を回避し、より自由なインターネット共有を可能にします。これは、ネットワークパケットをカーネルレベルで直接操作する eBPF の強力な機能を利用することで実現されており、OS の深い部分にアクセスして柔軟なネットワーク制御を可能にする、まさにハッカー精神の具現化と言えます。
人気
ポイント 3
コメント 2
この製品は何ですか?
これは、Android デバイスのカーネルに直接介入できる eBPF という技術を使って、本来 OS によって制限されているはずのホットスポット(テザリング)の利用可能データ量や接続数といった制約を解除してしまう、高度なネットワークユーティリティです。eBPF は、Linux カーネルの内部で安全かつ効率的にカスタムコードを実行できる仕組みで、これにより、OS のネットワークスタックの挙動を細かく制御し、テザリングの制限を迂回させることが可能になります。この技術を用いることで、従来の Android では難しかった、より自由で柔軟なインターネット共有が実現します。なので、これはあなたの Android デバイスを、より強力で制限のないインターネット共有ハブに変えるための技術的なブレークスルーです。
どのように使用しますか?
このプロジェクトは、root 化された Android デバイス上で動作します。開発者は、eBPF プログラムを Android カーネルにロードし、ネットワークトラフィックを管理するように設定します。具体的には、ADB (Android Debug Bridge) などを介して eBPF プログラムをデプロイし、テザリング機能を有効化します。このプロジェクトのソースコードをビルドし、ターゲットデバイスに適用することで、テザリングの制限を解除したホットスポット機能を利用できるようになります。したがって、これは、あなたの Android デバイスを、より広範なインターネット共有シナリオに対応させるための、開発者向けの高度なカスタマイズツールです。
製品の核心機能
· eBPF によるネットワークトラフィックの制御: カーネルレベルでパケットを直接処理し、テザリングの制限を回避する技術。これにより、データ使用量や接続数の制限を事実上なくすことが可能になり、より長時間の、またはより多くのデバイスへのインターネット共有を実現できます。
· OS 制限のバイパス: Android OS のテザリングに関する組み込み制限を、eBPF プログラムによって動的に変更・無効化します。これは、OS の意図しない挙動を利用して、ユーザーの自由度を高めるハッカー的なアプローチであり、これまで不可能だったテザリングの利用シナリオを開拓します。
· 柔軟なネットワーク設定: eBPF のプログラム可能性により、将来的にさらに高度なネットワーク設定やトラフィック管理機能の追加が期待できます。これは、開発者が独自のネットワークポリシーを実装したり、特定のアプリケーションの通信を優先したりといった、よりパーソナライズされたネットワーク体験を構築できる可能性を示唆します。
製品の使用例
· 旅行先や出張先で、ホテルの Wi-Fi が不安定な場合や、複数のデバイスでインターネットを共有したいときに、Android スマートフォンを強力なモバイル Wi-Fi ルーターとして活用する。eBPF により、データ通信量を気にせず、長時間のインターネット共有が可能になります。
· 開発者が、デバッグやテストのために、複数台のデバイスに一貫したネットワーク環境を提供する必要がある場合。このプロジェクトを利用することで、制限のないテザリングにより、容易にネットワーク環境を構築・管理できます。
· データ通信量の上限がない、または非常に大きいモバイルデータプランを持っているユーザーが、その恩恵を最大限に活用し、自宅のインターネット回線としても Android デバイスのテザリングを利用する。これにより、固定回線に依存しない柔軟なインターネット環境が実現できます。
23
ウィキダイブ:AIでWikipediaを深掘り

著者
atulvi
説明
このプロジェクトは、AI(人工知能)を活用してWikipediaの膨大な情報の中から、ユーザーが本当に知りたい情報へと深く潜っていくためのツールです。単なる検索ではなく、AIがユーザーの意図を理解し、関連性の高い情報を自動的に提示することで、情報探索の体験を劇的に向上させます。
人気
ポイント 3
コメント 2
この製品は何ですか?
このプロジェクトは、AI、特に自然言語処理(NLP)技術と知識グラフの概念を組み合わせた、新しいタイプのWikipedia探索システムです。ユーザーが単語やフレーズを入力すると、AIはその背景にある概念や関連性を理解し、単にリストを返すのではなく、まるで専門家がナビゲートしてくれるかのように、関連する記事やセクションを提示します。これは、従来のキーワード検索の限界を超え、より文脈に沿った、深みのある情報発見を可能にします。 so, this is useful because it helps you find information on Wikipedia more efficiently and discover connections you might have missed with traditional search.
どのように使用しますか?
開発者は、このプロジェクトをAPIとして利用したり、Webアプリケーションやブラウザ拡張機能に組み込んだりすることができます。例えば、自分のブログ記事の執筆中に、関連するWikipediaの情報をAIが自動で提案してくれるようにしたり、学習プラットフォームで、特定のトピックについてより深く掘り下げるためのナビゲーション機能として統合したりできます。 so, this is useful because it allows you to integrate intelligent Wikipedia content discovery into your own applications or workflows.
製品の核心機能
· AIによる意図理解:ユーザーの入力から、単なるキーワードではなく、その背後にある真の関心事をAIが理解します。これにより、より的確な情報へと誘導します。 so, this is useful because it means you get more relevant results even if your initial search term isn't perfect.
· 深層リンク生成:単一の記事だけでなく、関連する他の記事や、記事内の特定セクションへの「深層リンク」をAIが自動生成します。これにより、興味の連鎖をたどることができます。 so, this is useful because it saves you time by showing you related topics without you having to search for them individually.
· 知識グラフ探索:AIがWikipediaの情報を知識グラフとして捉え、概念間の関係性を可視化・探索できるようにします。これにより、情報の全体像を把握しやすくなります。 so, this is useful because it helps you understand how different pieces of information are connected.
· コンテキストアウェアな推薦:ユーザーの過去の探索履歴や現在の文脈を考慮して、次に興味を持ちそうな情報をAIが推薦します。 so, this is useful because it provides a more personalized and engaging learning experience.
製品の使用例
· 学術研究:学生が論文執筆のために、特定のテーマに関するWikipediaの情報を効率的に収集する際に活用できます。AIが関連研究や定義へと導き、情報収集の時間を大幅に短縮します。 so, this is useful because it speeds up research and helps students find authoritative information quickly.
· コンテンツクリエイター:ブロガーやYouTuberが、記事や動画のネタを探す際に、AIが提示する深層リンクをたどることで、ユニークで関連性の高いトピックを発見できます。 so, this is useful because it helps creators discover new content ideas and ensures their content is well-researched.
· 自己学習:新しい分野を学びたい人が、AIのナビゲーションに従うことで、体系的に知識を深めていくことができます。初学者でも迷子にならず、効率的に学習を進められます。 so, this is useful because it makes learning new subjects less daunting and more structured.
· 開発者ツール統合:開発者が、自分のアプリケーション内に「詳細情報はこちら」のような機能を追加したい場合に、Wikidive APIを利用することで、ユーザーをWikipediaの関連情報へとインテリジェントに誘導できます。 so, this is useful because it adds value to your own applications by providing smart, contextual information retrieval for your users.
24
ChatIndex:LLM長期対話履歴ツリーインデックス
著者
LoMoGan
説明
ChatIndexは、大規模言語モデル(LLM)が長文の対話履歴を効率的に参照・活用できるようにするコンテキスト管理システムです。ツリー構造に基づいた階層的なインデックスを作成することで、LLMが過去の対話のどこに重要な情報があるかを素早く見つけ出し、より文脈に沿った回答や一貫性のある対話を実現します。これは、AIチャットボットや対話型AIアプリケーションにおいて、過去のやり取りを忘れてしまうという「記憶喪失」の問題を解決するための革新的なアプローチです。
人気
ポイント 4
コメント 0
この製品は何ですか?
ChatIndexは、AIチャットボットなどが非常に長い対話の履歴を「賢く」覚えるための仕組みです。人間がノートにメモを取るように、過去の会話の重要な部分を整理して保存し、必要になった時にすぐに取り出せるようにします。特に、ツリー構造(階層構造)を使って情報を整理するのが特徴です。例えば、ある話題から別の話題に移った場合、それをツリーの枝分かれとして記録します。これにより、AIは「この話題について話していた時」や「あの時、こんなことを言っていた」といった具体的な文脈を把握しやすくなります。これにより、AIの応答はより自然で、一貫性があり、以前の発言を無視してしまうようなことが少なくなります。これは、AIが対話の「文脈」をより深く理解できるようにするための技術的なブレークスルーと言えます。
どのように使用しますか?
開発者は、ChatIndexを既存のLLMアプリケーションに組み込むことができます。具体的には、LLMがユーザーからの新しい入力を受け取るたびに、ChatIndexはそれを前回の対話履歴と照合し、関連性の高い過去の情報をツリー構造のインデックスから検索してLLMに提供します。これにより、LLMは限られたトークン数(AIが一度に処理できる情報量)の中でも、最も重要な文脈を効率的に利用できるようになります。例えば、LangChainやLlamaIndexのような既存のLLMフレームワークと連携させることで、より簡単に導入できます。APIを通じてアクセスしたり、ライブラリとして直接コードに組み込んだりすることが可能です。
製品の核心機能
· 階層型ツリーインデックス構築:過去の対話内容をツリー構造で整理し、重要な情報を素早く見つけ出すための基盤となります。これにより、AIは長時間の対話でも文脈を失いません。
· 効率的なコンテキスト検索:ユーザーの現在の発言や質問に関連する過去の対話部分を、ツリー構造を辿って素早く特定します。これにより、AIは無関係な情報に惑わされず、的確な応答を生成できます。
· LLMとの連携インターフェース:LLMがツリーインデックスから取得した文脈情報を、理解しやすい形式で渡すための仕組みを提供します。これにより、LLMはより正確で一貫性のある回答を生成できるようになります。
· 対話履歴の長期保持:従来のLLMが抱える「すぐに過去を忘れる」という問題を根本的に解決し、長期間にわたる複雑な対話も記憶・参照可能にします。これにより、より人間らしい、継続的な対話が実現します。
製品の使用例
· カスタマーサポートボット:長期間にわたる顧客とのやり取りから、顧客の過去の問い合わせ履歴や解決済みの問題を迅速に参照し、よりパーソナライズされたサポートを提供します。
· AIアシスタント:ユーザーの複雑な要望や過去の指示を正確に記憶し、一貫性のあるタスク実行や情報提供を行います。例えば、個人の好みや設定を長期的に学習し、それを反映した応答を生成します。
· 対話型学習プラットフォーム:学習者が過去に質問した内容や理解度を記録し、個別最適化された学習パスやフィードバックを提供します。これにより、学習効果を最大化します。
· コンテンツ生成AI:クリエイティブな執筆やストーリーテリングにおいて、過去のプロットポイントやキャラクター設定を保持し、物語の一貫性と深みを保ちながらコンテンツを生成します。
25
デジタル暖炉ウィジェット
著者
kingofspain
説明
このプロジェクトは、iOSデバイス(iPhoneやApple Watch)向けに、ピクセルアートで表現された心地よい炎を表示するシンプルなアプリケーションです。寒い冬でも、視覚的な暖かさを提供することを目的としています。特に、ウィジェット機能とウォッチアプリ機能が特徴で、いつでもどこでも手軽に炎を楽しめます。技術的な視点では、リソースを最小限に抑えつつ、視覚的な体験を向上させるための工夫が施されています。
人気
ポイント 4
コメント 0
この製品は何ですか?
これは、iPhoneやApple Watchのホーム画面やロック画面、あるいはウォッチフェイスに、本物そっくりのピクセルアートの炎を表示するアプリです。単なる画像ではなく、炎の揺らぎや色をリアルタイムで生成・表示することで、視覚的な暖かさとリラックス効果を提供します。技術的には、低消費電力で滑らかなアニメーションを実現するために、最適化された描画アルゴリズムが使用されていると考えられます。これにより、バッテリー消費を抑えつつ、美しい炎の表現を可能にしています。開発者の工夫は、限られたリソースで最大限の視覚体験を提供することにあります。
どのように使用しますか?
開発者は、このアプリをApp Storeからダウンロードし、iPhoneやApple Watchにインストールするだけで利用できます。iPhoneでは、ホーム画面やロック画面にウィジェットとして追加することで、アプリを開かずに炎の暖かさを楽しめます。ウィジェットのサイズも複数用意されており、好みに合わせて配置できます。Apple Watchでは、コンパニオンアプリとして、手首につけたデバイス上で小さな炎を表示できます。炎の色や揺らぎは、アプリ内でカスタマイズすることも可能です(一部機能はアプリ内課金)。
製品の核心機能
· ホーム画面ウィジェット表示: iPhoneのホーム画面に炎のウィジェットを設置できます。これにより、アプリを開く手間なく、いつでも視覚的な暖かさを感じられます。実用面では、視覚的な癒やしや、デバイスのカスタマイズ性を高めることに貢献します。
· ロック画面ウィジェット表示: iOSのロック画面にもウィジェットとして炎を表示できます。これにより、デバイスを手に取るたびに、穏やかな炎の光景を楽しむことができます。ユーザー体験の向上と、デバイスのパーソナライズに役立ちます。
· Apple Watchコンパニオンアプリ: Apple Watch上で炎を表示する機能です。手首につけたデバイスで、いつでもどこでも炎の暖かさに触れることができます。場所を選ばずにリラックスできる、ユニークな体験を提供します。
· 炎と色のカスタマイズ: 炎の揺らめき方や色合いを、ユーザーの好みに合わせて調整できます。これにより、個々のユーザーが自分だけの特別な炎を作り出すことができます。視覚的な満足度を高め、飽きさせない工夫が施されています。
· ミニマルなリソース消費: 低消費電力で滑らかなアニメーションを実現する描画技術が用いられています。これにより、バッテリーへの影響を最小限に抑えながら、快適な視覚体験を提供します。デバイスのパフォーマンスを損なわずに、心地よい雰囲気を作り出します。
製品の使用例
· 寒い冬の夜、iPhoneのホーム画面に炎のウィジェットを設置し、視覚的な暖かさでリラックスしたい。このアプリを使えば、火をつけなくても炎の癒やしを得られます。
· Apple Watchで会議中など、静かにリラックスしたい時に、手首の小さな画面で炎を表示させたい。このアプリは、場所を選ばずに穏やかな雰囲気を作り出すのに役立ちます。
· デスクワーク中に、PCの隣のiPhoneで、炎の揺らめきを眺めて気分転換したい。ウィジェット機能は、作業を中断せずに手軽に癒やしを提供してくれます。
· ホーム画面を自分好みにカスタマイズしたいが、実用性も兼ね備えたい。炎のウィジェットは、見た目の美しさと、視覚的な快適さという新しい価値を提供します。
26
Beatdelay.co: 賢い先延ばし克服アシスタント
著者
ivanramos
説明
このプロジェクトは、緊急のタスクから逃避してしまうという、多くの開発者が経験する普遍的な問題に対処します。従来の「とにかく始めろ」や「休憩を取れ」といった一般的なアドバイスとは異なり、Beatdelay.coは、ユーザーがタスクを先延ばしにする具体的な理由を分析し、即座に実行可能な、パーソナライズされたステップを提供します。これは、AIを活用して、ユーザーの先延ばしのタイプに合わせた、具体的で実用的な解決策を提供する技術的なアプローチが革新的です。
人気
ポイント 2
コメント 2
この製品は何ですか?
Beatdelay.coは、AIを活用した、先延ばし対策のためのスマートなツールです。ユーザーがタスクを避けてしまう理由を入力すると、AIがその理由を理解し、すぐに実行できる具体的な行動ステップを生成します。例えば、「タスクが複雑すぎる」と入力すれば、「まずは最初の15分だけ、最も単純な部分に集中しよう」といった具合です。これは、単なる励ましではなく、ユーザーの心理状態とタスクの性質を分析し、行動を促進するための技術的な洞察に基づいています。これにより、開発者は、茫然自失とすることなく、次の一歩を踏み出すことができます。
どのように使用しますか?
開発者はBeatdelay.coを、ウェブサイト(beatdelay.co)にアクセスし、現在取り組んでいる緊急のタスクと、なぜそれを先延ばしにしているかの理由を入力することで利用できます。例えば、新しい機能の実装でコードが複雑すぎて進まない場合、「コードが複雑すぎてどこから手をつけるべきかわからない」と入力します。すると、Beatdelay.coは「まずは、最も理解しやすいモジュールから始めて、その周りのテストケースを書き出してみよう」といった具体的な指示を生成します。これは、開発ワークフローに直接統合でき、日々のコーディングやプロジェクト管理における生産性のボトルネックを解消するのに役立ちます。
製品の核心機能
· 先延ばし理由分析機能: ユーザーが入力した先延ばしの理由をAIが解析し、その根本原因を特定します。これにより、漠然とした不安を具体的な問題に落とし込むことができ、開発者は問題解決への糸口を見つけやすくなります。
· 個別化された行動ステップ生成: 分析結果に基づき、AIが実行可能で、その瞬間に取り組める具体的な行動ステップを生成します。これは、曖昧な指示ではなく、明確な指示であるため、開発者は迷うことなく作業を進めることができます。例えば、デバッグが苦手な場合、「エラーメッセージをコピーして、Stack Overflowで類似の問題を検索しよう」といった具体的な手順が提示されます。
· 適応型先延ばしタイプ対応: ユーザーの過去の入力やフィードバックから、AIがユーザーの先延ばしのパターン(完璧主義、恐怖、興味の欠如など)を学習し、よりパーソナライズされたアドバイスを提供します。これにより、一貫した先延ばし対策が実現し、開発者は自身の弱点を克服していくことができます。
· モチベーションに依存しないアプローチ: 感情的な励ましではなく、論理的かつ構造化されたステップを提供することで、気分に左右されずにタスクを進めることを可能にします。これは、開発者が集中力を維持し、持続的に成果を出すために不可欠です。
製品の使用例
· 例1:新しいAPI統合で、ドキュメントが難解で実装が進まない場合。ユーザーが「APIドキュメントが複雑すぎて理解できない」と入力すると、Beatdelay.coは「まずは、最も基本的なエンドポイントの例を一つだけ、最小限のパラメータで試してみよう。そして、そのリクエストとレスポンスを詳細に観察しよう。」といったステップを提示します。これにより、開発者は最初の一歩を踏み出し、徐々にAPIの理解を深めることができます。
· 例2:バグ修正で、原因特定が困難で、コードのどこを修正すべきかわからない場合。ユーザーが「バグの原因が特定できず、どこから手をつけるべきかわからない」と入力すると、Beatdelay.coは「まずは、バグが発生する直前のコードの特定部分にログ出力(console.logやprint文)を仕込み、変数の値の変化を追跡してみよう。さらに、関連するテストケースを全て実行して、どこで失敗しているか特定しよう。」といった具体的なデバッグ手法を提案します。これにより、開発者は効率的にバグの原因を突き止めることができます。
· 例3:デザインレビューで、フィードバックの量が多すぎて、どこから修正すれば良いか混乱している場合。ユーザーが「レビューコメントが多くて、何から手をつけるべきか途方に暮れている」と入力すると、Beatdelay.coは「まずは、最も重要度の高い(あるいは、修正が容易な)コメントを3つ選び、それらに集中して対応しよう。残りは後でまとめて見直すこと。」といった、タスクの優先順位付けと分割を促すアドバイスを生成します。これにより、開発者は圧倒されずに、段階的に改善を進めることができます。
27
ローカルPythonドキュメンテーション自動生成アシスタント (SLM)
著者
party-horse123
説明
これは、Pythonコードのためのドキュメンテーション(Docstrings)を自動生成するツールです。Qwen3 0.6Bという比較的小さな言語モデル(SLM)を使用し、ローカル環境で実行されるため、機密性の高いコードを外部に送信することなく、Googleスタイルに準拠した完全なDocstringsを生成できます。これにより、開発者はドキュメンテーション作成の手間を大幅に削減し、コードの可読性と保守性を向上させることができます。
人気
ポイント 4
コメント 0
この製品は何ですか?
このプロジェクトは、PythonコードのDocstringsを自動生成するスマート言語モデル(SLM)アシスタントです。具体的には、Qwen3 0.6Bという、比較的小さく、ローカル環境で効率的に動作するように設計された言語モデルを活用しています。このモデルは、Pythonスクリプトのコードを解析し、その機能、引数、戻り値などを説明するDocstringsを、広く採用されているGoogleスタイルで自動生成します。この技術の革新性は、大規模なモデルに匹敵する生成能力を持ちながら、ローカルで実行できる点にあります。これにより、開発者は機密情報を含むコードを外部のクラウドサービスにアップロードする必要がなく、セキュリティを確保しながらドキュメンテーション作成の負担を軽減できるのです。
どのように使用しますか?
開発者は、Pythonの実行環境があれば、このツールを簡単に利用できます。まず、`localdoc.py`というスクリプトをダウンロードします。次に、ターミナルまたはコマンドプロンプトを開き、以下のコマンドを実行します。「`python localdoc.py --file your_script.py`」。ここで、「`your_script.py`」の部分を、ドキュメンテーションを生成したい実際のPythonファイル名に置き換えてください。スクリプトは、指定されたPythonファイルを解析し、Docstringsが生成された新しいファイル、または元のファイルにインラインでDocstringsを追加して出力します。これは、IDE(統合開発環境)のプラグインとして組み込んだり、CI/CDパイプラインに統合したりすることで、開発ワークフローにスムーズに組み込むことができます。これにより、コードを記述するたびに手動でDocstringsを作成する時間を節約し、常に最新で質の高いドキュメントを維持することが可能になります。
製品の核心機能
· Pythonコードの解析とDocstrings生成: Pythonコードの構造や意味を理解し、それに合わせたDocstringsを生成する能力。これにより、コードの意図が明確になり、他の開発者がコードを理解しやすくなります。
· GoogleスタイルDocstringsの自動フォーマット: Docstringsの標準的なフォーマットであるGoogleスタイルに準拠した出力を提供。これにより、チーム内やコミュニティでのコード共有において、統一されたドキュメンテーション形式を維持できます。
· ローカル実行によるコードセキュリティの確保: 外部サービスにコードを送信することなく、開発者のマシン上で直接処理を実行。機密情報や知的財産を含むコードでも、安心してドキュメンテーションを作成できます。
· Qwen3 0.6B SLMの活用: 比較的小さなモデルで高い精度を実現。これにより、高性能なハードウェアがなくても、迅速かつ効率的にDocstringsを生成できます。
· コマンドラインインターフェース (CLI) による簡単な操作: `python localdoc.py --file your_script.py`のようなシンプルなコマンドで実行可能。開発者は複雑な設定なしに、すぐに利用を開始できます。
製品の使用例
· 新規プロジェクトの初期開発段階: コードの全体像や各関数の役割を迅速に文書化し、チームメンバー間の理解を促進。例:新しいAPIエンドポイントのPythonバックエンドコードを作成し、各エンドポイントの機能、リクエストパラメータ、レスポンス形式を自動生成されたDocstringsで明確にする。
· 既存コードベースのリファクタリング: コードを改善する過程で、失われたり不十分だったりするDocstringsを補完。例:レガシーなPythonモジュールのコードをリファクタリングする際に、各関数やクラスの動作を正確に説明するDocstringsを自動生成し、保守性を向上させる。
· オープンソースプロジェクトへの貢献: コードの品質と可読性を高めるために、貢献するコードに標準化されたDocstringsを付与。例:OSSプロジェクトに機能追加のプルリクエストを出す際に、追加したコード部分のDocstringsを自動生成し、レビュー担当者の負担を軽減する。
· 社内ツールの開発と共有: チーム内で使用するPythonベースのツールやライブラリのドキュメントを迅速に作成し、共有。例:データ分析チームが共有するPythonユーティリティライブラリの関数群に対して、自動生成されたDocstringsを適用し、チームメンバーが容易に利用できるようにする。
· セキュリティ要件の高い環境での開発: 機密性の高い金融システムや医療システムなどのPythonコードのドキュメントを作成。外部への情報漏洩リスクを排除しつつ、必要なドキュメンテーションを確保。
28
SchemaSync Rust
著者
amirfarzamnia
説明
このプロジェクトは、JSON SchemaをLuaの型定義言語であるLuauの型に自動変換するRust製ツールです。これにより、異なるシステム間でのデータ構造の整合性を保ち、開発者が手作業で型定義を作成する手間を省きます。特に、ゲーム開発などでLuauが使われる場面で、APIや設定ファイルの定義を効率化します。
人気
ポイント 3
コメント 1
この製品は何ですか?
これは、JSON Schemaという、データがどのような構造であるべきかを定義する標準的な形式を、LuauというLuaの型チェックを強化した言語の型定義に自動で変換してくれるツールです。例えば、APIから受け取るデータや設定ファイルの内容を、Luauで安全に扱えるようにするための型定義を、人間が書く代わりにプログラムが生成してくれる、というイメージです。これにより、意図しないデータ形式によるエラーを防ぎ、開発の安全性を高めます。Rustで書かれているため、高速で信頼性の高い動作が期待できます。
どのように使用しますか?
開発者は、JSON Schemaの定義ファイルを用意し、このRust製ツールをコマンドラインで実行します。ツールはJSON Schemaファイルを読み込み、対応するLuauの型定義ファイルを出力します。この生成されたLuauの型定義ファイルを、Luauで書かれたコード(例えば、Robloxのゲーム開発など)でインポートして使用します。これにより、データ検証やコード補完がLuauの型システムを通じて行われるようになり、開発効率とコードの品質が向上します。
製品の核心機能
· JSON SchemaからLuau型への自動変換。これにより、開発者は手作業で型定義を書く時間を節約でき、定義の誤りを減らせます。API連携やデータバリデーションの効率が向上します。
· Rustによる高速な実行。大規模なスキーマでも迅速に変換できるため、ビルドプロセスや開発ワークフローにスムーズに組み込めます。開発サイクルの短縮に貢献します。
· クロスプラットフォーム対応。Rustで書かれているため、様々なオペレーティングシステムで動作し、多様な開発環境で利用可能です。開発者の環境選択の自由度を高めます。
製品の使用例
· ゲーム開発におけるAPIレスポンスの型定義。ゲームクライアントがサーバーから受け取るJSON形式のデータをLuauの型として定義し、型安全なデータアクセスを実現します。これにより、データ構造の変更によるバグを早期に発見できます。
· 設定ファイルのバリデーションと型安全な読み込み。アプリケーションやゲームで使用する設定ファイル(JSON形式)のスキーマを定義し、Luauの型で安全に読み込めるようにします。意図しない設定値によるエラーを防ぎ、アプリケーションの安定性を高めます。
· 異なるサービス間でのデータ交換の標準化。API仕様(JSON Schema)をLuauの型に変換することで、複数の開発チームやマイクロサービス間でのデータ連携を容易にし、データの一貫性を保ちやすくします。コミュニケーションコストを削減します。
29
漢字タイパー (Kanji Typer)
著者
yourladybug
説明
これは、日本語学習者向けに、タイピングゲーム「Monkeytype」のように楽しく漢字や語彙を習得できる、完全無料・オープンソースの学習プラットフォームです。サブスクリプションや有料壁にうんざりした開発者が、コミュニティ主導で、 profit ではなく 学習体験そのものを重視して作られています。
人気
ポイント 3
コメント 0
この製品は何ですか?
漢字タイパーは、日本語の漢字と語彙を、まるでゲームのように楽しみながら覚えるためのウェブアプリケーションです。タイピングゲームでスコアを競うように、表示される漢字や単語を正確かつ素早く入力することで、学習が進みます。技術的には、フロントエンドはReactなどのモダンなJavaScriptフレームワークで構築され、サーバーサイドではNode.jsなどが使われている可能性があります。学習データはローカルストレージやシンプルなデータベースに保存され、パフォーマンスとアクセシビリティを重視しています。従来の有料アプリのような複雑な機能よりも、シンプルで効果的な「反復学習」と「ゲーミフィケーション」に焦点を当てた点が革新的です。つまり、これは「飽きずに楽しく日本語の漢字や単語を覚えられる、あなたのための無料の学習マシン」なのです。
どのように使用しますか?
開発者は、このプラットフォームをブラウザで直接利用できます。特定の漢字や語彙のリストを作成したり、学習の難易度やタイピング速度を設定したりして、自分に合った学習環境をカスタマイズできます。また、GitHubでソースコードが公開されているため、開発者はコードをフォークして独自の機能を追加したり、バグを修正したりすることも可能です。例えば、個人の学習進捗を記録する機能を追加したり、特定のJLPTレベルに特化した問題集を作成したりといった応用が考えられます。つまり、これは「あなたの学習スタイルに合わせてカスタマイズでき、さらに自分で改良することも可能な、自由度の高い日本語学習ツール」です。
製品の核心機能
· 漢字・語彙タイピング練習: 表示される日本語の文字や単語をタイピングすることで、記憶と入力スキルを同時に向上させます。これは、文字認識とタイピング速度という二つの重要な学習要素を効率的に鍛えるための技術的アプローチです。
· カスタマイズ可能な学習設定: 学習する漢字のレベル(例: 小学漢字、JLPT N5など)、タイピング速度、制限時間などを自由に設定できます。これにより、学習者は自身のレベルや目標に合わせた最適な学習体験を得られます。これは、ユーザーの個別ニーズに応えるための柔軟なデータ管理とUI設計の価値です。
· 進捗トラッキングと統計: 学習時間、正答率、得意な漢字・苦手な漢字などの統計情報を表示し、学習の進捗を可視化します。これにより、学習者は自身の弱点を把握し、効果的な学習計画を立てることができます。これは、データ分析と可視化技術による学習効果の最大化です。
· オープンソースとコミュニティ貢献: ソースコードが公開されており、誰でもコードを閲覧、改善、または自身のプロジェクトに組み込むことができます。これは、技術コミュニティ全体での知識共有と、より良い学習ツールの共創を促進する価値です。
製品の使用例
· JLPT N2レベルの漢字を効率的に覚えたい学習者が、漢字タイパーでN2レベルの単語リストを設定し、毎日30分タイピング練習を行うことで、数週間で語彙力を大幅に向上させる。これは、特定の学習目標達成のために、ターゲットを絞った反復学習とゲーミフィケーションが有効であることを示す技術的応用例です。
· プログラミング学習者が、日本語の技術用語を覚えるために、独自の語彙リストを作成して漢字タイパーで練習する。これにより、技術文書の読解力と、関連する日本語の語彙力を同時に高める。これは、既存のツールを応用して、専門分野の学習ニーズに応える黒客文化的な問題解決の例です。
· 教育機関が、学生向けの日本語学習補助ツールとして漢字タイパーを導入し、学生が自宅で自主的に漢字学習を進めることを奨励する。学校側は、学生の学習進捗を把握するためのカスタム機能開発をコミュニティに依頼することも可能。これは、教育現場での応用と、オープンソースコミュニティとの連携による拡張性の実証です。
30
SES Template Manager - ローカルMac版AWS SESテンプレート管理ツール
著者
gtlsgamr
説明
AWS SES (Simple Email Service) のメールテンプレート管理を、APIリクエストの煩雑さから解放するmacOSネイティブアプリです。JSON、HTML、コンソール、CLIスクリプト間の切り替えによる複雑な作業を、直感的なローカル環境での編集、テスト、管理に置き換えます。AWS認証情報はローカルで保持され、サーバーへの送信は一切ありません。
人気
ポイント 3
コメント 0
この製品は何ですか?
これは、Amazon SESでメールテンプレートを管理するためのMac用ネイティブアプリケーションです。通常、SESのテンプレートを操作するには、AWSのウェブコンソールにアクセスするか、複雑なAPIリクエストやCLIコマンドを叩く必要があります。このアプリは、そういった手間を省き、Macのテキストエディタのように、ローカルで直接テンプレートを編集、作成、テスト、そしてAWSアカウントと同期できるようにします。APIキーなどのAWS認証情報はあなたのMac上に安全に保持され、外部サーバーに送信されることはありません。つまり、インターネット接続がなくても(同期時を除く)テンプレートの作成や編集ができ、セキュリティ面でも安心です。技術的には、macOSのネイティブUIフレームワーク(Cocoaなど)を使用して開発されており、AWS SDK for Mac/iOS(もしあれば)または汎用的なAWS SDKを利用して、ローカルのAWS認証情報を使ってAWS SES APIと通信します。
どのように使用しますか?
開発者は、まずMac App Storeまたは開発者のウェブサイトからSES Template Managerをダウンロード・インストールします。次に、Macに設定されているAWS認証情報(IAMユーザーのアクセスキーIDとシークレットアクセスキーなど)をアプリに安全に読み込ませます。これにより、アプリはあなたのAWSアカウントと連携できるようになります。あとは、アプリ内で直接新しいSESテンプレートを作成したり、既存のテンプレートを編集したり、テストメールを送信したりすることが可能です。コンソールやCLIを行き来することなく、ローカルで効率的に作業を進めることができます。例えば、開発中のウェブアプリケーションで利用するメールテンプレートの変更を素早く行いたい場合や、新しいキャンペーン用のテンプレートを設計したい場合に、このアプリを使えば、数クリックで作業が完了します。
製品の核心機能
· ネイティブテキストエディタでのSESテンプレート編集: ローカルの使い慣れたテキストエディタ感覚で、HTMLとプレーンテキストのメールテンプレートを快適に編集できます。これにより、コーディングミスを減らし、テンプレート作成のスピードを向上させます。
· ローカル認証情報によるAWSアカウント同期: 独自のAWS認証情報をMac内に保持し、安全にAWS SESと同期します。外部サーバーへの情報送信がないため、セキュリティリスクを最小限に抑えつつ、最新のテンプレート状態を維持できます。
· コンソール操作不要でのテンプレート作成: AWSマネジメントコンソールを開く手間なく、アプリ上で直接新しいSESテンプレートを素早く作成できます。これにより、テンプレート作成のワークフローを大幅に簡略化します。
· 直接的なテストメール送信機能: 作成・編集したテンプレートを使って、すぐにテストメールを送信できます。これにより、メールがどのように表示されるかをリアルタイムで確認し、意図した通りのデザインと内容であることを迅速に検証できます。デバッグ時間を短縮します。
· サインアップ・クラウドバックエンド不要、完全ローカル処理: ユーザー登録や外部サーバーとの連携が一切不要です。あなたのMac上で全てが完結するため、セットアップが容易で、プライバシーも保護されます。すぐに使い始められ、余計な依存関係がありません。
製品の使用例
· ウェブアプリケーションのユーザー登録確認メールテンプレートの迅速な更新: 開発中のEコマースサイトで、ユーザー登録時の確認メールの文言を修正する必要が生じた場合、SES Template Managerを使えば、AWSコンソールにログインしてテンプレートを検索し、編集・保存するという一連の操作を、Mac上で数分で完了できます。これにより、ユーザー体験の低下を防ぎ、迅速なサービス改善が可能になります。
· マーケティングキャンペーン用HTMLメールテンプレートのローカルでのデザインとテスト: 新しい製品プロモーションのために、リッチなHTMLメールを作成したいマーケターや開発者が、SES Template Manager上でデザインを調整し、テストメールを送信してPCやスマートフォンのメーラーでの表示を確認できます。これにより、複雑なメール配信ツールの操作を覚える必要がなく、デザインのイテレーションを高速化できます。
· API連携が苦手な開発者によるSESテンプレート管理: CLIツールやAPIリクエストでのテンプレート操作に不慣れな開発者でも、SES Template Managerを使えば、GUI(グラフィカルユーザーインターフェース)で直感的にテンプレートを管理できます。AWS SDKの細かいパラメータを気にすることなく、テンプレートの作成・編集・同期ができるため、開発者は本来のアプリケーション開発に集中できます。
· オフライン環境でのテンプレート編集と後続同期: インターネット接続が不安定な環境や、出張先などでも、SES Template Managerを使えばローカルでテンプレートの編集作業を進めることができます。接続が回復した際に、まとめてAWSアカウントと同期できるため、場所を選ばずに作業効率を維持できます。
31
空間認知型CAPTCHA(Spatial CAPTCHA)
著者
Shining_S
説明
このプロジェクトは、AIボットによる自動アクセスを防ぐために、3D空間認識能力を試す新しいタイプのCAPTCHAです。従来の文字や画像認識CAPTCHAがAIの進化によって突破されやすくなっている課題に対し、人間特有の空間理解能力を応用することで、より高度なセキュリティを提供します。
人気
ポイント 1
コメント 2
この製品は何ですか?
これは、AIボットが簡単に解けない、人間向けの3D空間認識テストを提供するCAPTCHAシステムです。従来のCAPTCHAは、画面上の文字を読み取ったり、特定の画像を選んだりするものでしたが、AIはこれらのパターンを学習して突破できるようになってきました。Spatial CAPTCHAは、3D空間におけるオブジェクトの配置や回転、移動といった、より複雑で人間的な推論能力を必要とするタスクを提示します。例えば、いくつかのオブジェクトが3D空間に配置されており、それを特定の角度から見たときにどう見えるかを推測させる、といった形式です。これにより、AIボットにとっては学習が困難な、高度な知能を要求することで、不正アクセスを効果的にブロックします。これは、AIの弱点である「真の空間理解」を突いた、創造的なセキュリティ対策と言えます。
どのように使用しますか?
開発者は、ウェブサイトやアプリケーションにこのSpatial CAPTCHAを組み込むことで、ユーザー認証のセキュリティを強化できます。APIを通じてCAPTCHAの生成と検証機能を利用し、ユーザーがCAPTCHAを解いた後に、その正誤をサーバー側で判定します。例えば、ログインフォームや新規登録ページなどに配置し、ボットによる自動的なフォーム送信やアカウント作成を防ぐために使用できます。WebサイトのフロントエンドにJavaScriptライブラリとして導入したり、バックエンドの認証フローに組み込んだりすることが考えられます。これにより、貴社のサービスは、人間による正当なアクセスのみを受け付け、ボットによる攻撃から保護されるようになります。
製品の核心機能
· 3D空間認識ベースのCAPTCHA生成: ユーザーに3D空間における論理的な推論を求めるタスクを動的に生成します。これは、AIが苦手とする高度な空間認知能力を試すことで、ボットによる自動解答を困難にします。
· AIボット検出能力: 従来のCAPTCHAよりも高度なAIボットの侵入を効果的に防ぎます。人間特有の視点や思考プロセスを必要とするため、学習ベースのAIでは対応しきれない不正アクセスをブロックします。
· 柔軟な統合インターフェース: ウェブサイトやアプリケーションへの容易な組み込みを可能にするAPIやSDKを提供します。開発者は、既存のシステムに最小限の変更で統合でき、迅速にセキュリティを向上させることができます。
· ユーザーエクスペリエンスへの配慮: 複雑すぎず、しかしAIには解けないような、人間にとって直感的で理解しやすい問題形式を提供することを目指します。これにより、ユーザーの離脱率を抑えつつ、セキュリティを確保します。
製品の使用例
· ECサイトでの不正注文防止: ボットによる大量の不正注文やアカウント乗っ取りを防ぐために、決済ページやアカウント作成時にSpatial CAPTCHAを導入します。これにより、正規の顧客のみがサービスを利用できるようになります。
· オンラインゲームでのチート対策: ゲームアカウントの作成や、ゲーム内での重要なアクション実行時にCAPTCHAを挟むことで、ボットによる不正行為やアカウントハックを防ぎ、公平なゲーム環境を維持します。
· APIアクセスの保護: 悪意のあるボットによるAPIの大量リクエストや、データスクレイピングを防ぐために、APIエンドポイントへのアクセス認証にSpatial CAPTCHAを利用します。これにより、APIリソースの不正利用を最小限に抑えます。
· 会員登録フォームのスパム対策: 偽のアカウント作成やスパム投稿を防ぐため、新規会員登録プロセスにSpatial CAPTCHAを組み込みます。これにより、質の高いユーザーベースを維持し、コミュニティの健全性を保ちます。
32
curAIted.dev: AIニュースの知見をAIが要約するキュレーター
著者
mmntns
説明
AI分野の最新動向を把握するのは大変です。curAIted.devは、AIによって高品質なAI関連コンテンツの要約を生成し、開発者向けに分かりやすく配信するブログ形式のニュースアグリゲーターです。製品そのものよりも、AIの基礎となる技術や概念に焦点を当て、エンジニアがAIの進化を効率的に追跡できるよう支援します。
人気
ポイント 2
コメント 1
この製品は何ですか?
curAIted.devは、AI分野の技術記事や研究論文の膨大な情報の中から、AI(大規模言語モデル:LLM)が自動で質の高い要約を生成し、開発者にとって理解しやすい形で提供するサービスです。人間が手作業で選定した信頼できる情報源を基に、AIが内容を咀嚼して簡潔にまとめてくれるため、最新のAI技術のキャッチアップにかかる時間を大幅に削減できます。これは、AIの進化のスピードに追いつきたい開発者にとって、効率的な情報収集手段となります。
どのように使用しますか?
開発者は、curAIted.devのウェブサイトにアクセスするだけで、AI分野の最新情報に触れることができます。ブログ形式で提供される記事は、AIが生成した要約が付いているため、概要を素早く掴むことができます。興味を持った記事は、元のソースにアクセスして詳細を確認することも可能です。例えば、新しいAIモデルの発表や、特定のAI技術に関する深い解説記事に触れたい場合に、そのエッセンスを短時間で理解するために利用できます。PythonのパイプラインでAIがコンテンツを収集・要約するという技術的背景も、技術愛好家にとっては興味深い点です。
製品の核心機能
· AIによるコンテンツの自動収集と要約: PythonとLLMを活用し、AI関連の最新情報を効率的に収集し、その内容をAIが自動で分かりやすく要約します。これにより、開発者は膨大な情報の中から必要な知識を素早く見つけ出すことができます。
· 厳選された情報源に基づくキュレーション: 提供される情報の元となるソースは、人間が厳選しています。これにより、AIによる要約の質と信頼性が保証され、開発者は信頼できる情報に基づいて学習を進めることができます。
· 開発者中心のコンテンツフィルタリング: 製品やサービスそのものではなく、AIの基礎技術や原理に焦点を当てたコンテンツを提供します。これにより、AI技術の深い理解を求める開発者にとって、より価値の高い情報が得られます。
· Astroフレームワークによる高速なウェブサイト表示: Astroというモダンなウェブサイト構築フレームワークを使用しており、コンテンツの読み込みが高速です。これにより、開発者はストレスなく情報にアクセスできます。
製品の使用例
· 新しい機械学習アルゴリズムの発表に関する記事で、curAIted.devのAI要約を読むことで、そのアルゴリズムの核心的なアイデアと、それがどのような問題を解決するのかを数分で理解できます。もし詳細を知りたければ、元の論文や記事に飛べます。これにより、夜遅くまで最新論文を読む必要がなくなります。
· ある特定のAI分野(例:生成AIの最新動向)について、curAIted.devを定期的にチェックすることで、その分野の技術的なブレークスルーや重要な進展を効率的に把握できます。例えば、新しい画像生成モデルの登場や、自然言語処理における大規模モデルの進化などを、網羅的に、かつ簡潔に知ることができます。
· 開発者が、自身のプロジェクトで利用できる新しいAIライブラリやツールに関する情報を探している場合、curAIted.devで関連キーワードで検索したり、最新の投稿を眺めたりすることで、効率的に有用な情報を発見できます。これは、情報収集の時間を減らし、実際の開発に集中するための強力なサポートとなります。
33
AIエージェント開発スタジオ(Agent Playbook)
著者
orlevii
説明
AIエージェントを開発する際に、プロンプトやツールの小さな変更をテストするために、アプリケーション全体を実行したり、一時的なスクリプトを書いたりする必要があるという繰り返しの問題に対処するオープンソースのプレイグラウンドです。UIコンポーネント開発で使われるStorybookのように、AIエージェントを分離して開発・デバッグできるように設計されています。ローカルでWeb UIを起動し、エージェントとの対話、推論ステップの確認、ホットリロードによる迅速なイテレーションを可能にします。
人気
ポイント 3
コメント 0
この製品は何ですか?
これは、AIエージェントを開発・デバッグするための、Storybookのような分離された環境を提供するオープンソースのツールです。AIエージェント開発では、プロンプトやツールに少し変更を加えただけでも、全体のアプリケーションを動かしてテストするか、一時的なスクリプトを作成する必要があり、これが開発のフローを妨げていました。Agent Playbookは、この問題を解決するために、エージェントを個別にテストできる環境を提供します。自動的にエージェントを発見し、ローカルでWeb UIを起動して、対話形式でエージェントの振る舞いを検証できます。特に、pydantic-aiで構築されたエージェントをサポートしており、開発者はエージェントの思考プロセスをステップごとに確認し、迅速に改善を繰り返すことができます。これは、AIエージェント開発の生産性を劇的に向上させるための、創造的なコーディングによる問題解決の好例です。
どのように使用しますか?
開発者は、GitHubからAgent Playbookのコードをクローンし、ローカル環境にセットアップします。pydantic-aiなどで構築したAIエージェントのコードをAgent Playbookと連携させます。Agent Playbookは、設定されたエージェントを自動的に検出し、ブラウザでアクセス可能なWeb UIを起動します。このUIを通じて、開発者はエージェントに対して直接指示を与えたり、質問を投げかけたりすることができます。エージェントがどのように思考し、応答を生成しているかの推論プロセスをリアルタイムで確認できるため、問題のある箇所を特定しやすくなります。コードを修正すると、UIに自動的に反映される(ホットリロード)ため、試行錯誤のサイクルを高速化できます。これにより、個々のエージェントの挙動を理解し、デバッグする手間が大幅に省かれ、開発者はより創造的な部分に集中できるようになります。
製品の核心機能
· AIエージェントの自動検出とローカルUI起動: 開発中のAIエージェントを自動的に見つけ出し、インタラクティブなWeb UIをローカルで起動します。これにより、複雑なセットアップなしに、すぐにエージェントのテストを開始できます。開発者は「これは私にとって、すぐにAIエージェントの挙動を確認できる便利なツールだな」と感じられます。
· 対話型エージェントテスト環境: Web UIを通じて、AIエージェントと直接チャットや対話ができます。これにより、エージェントがユーザーの意図をどう理解し、どのように応答するかをリアルタイムで確認できます。開発者は「エージェントが期待通りに動いているか、すぐに試せる」というメリットを得られます。
· 推論ステップの可視化: エージェントが応答を生成するまでの思考プロセスや、内部で実行されているステップを詳細に確認できます。これにより、エージェントの「なぜ」という部分を理解し、デバッグや改善の糸口を見つけやすくなります。開発者は「エージェントがなぜそう答えたのか、その理由がわかる」と、問題解決の精度が上がります。
· ホットリロード機能: コードを変更すると、Web UIに即座に反映されます。これにより、試行錯誤のサイクルが劇的に短縮され、開発者は迅速にアイデアを試すことができます。開発者は「コードを変えたらすぐ結果が見えるから、どんどん試せる!」と、開発スピードの向上を実感できます。
· pydantic-aiエージェントとの統合: 現在、pydantic-aiで構築されたエージェントをサポートしています。このフレームワークとの親和性が高く、スムーズな連携が可能です。開発者は「私が使っているpydantic-aiのエージェントで、すぐに試せる」という利便性を享受できます。
製品の使用例
· AIチャットボットの応答品質改善: AIチャットボットが特定の質問に対して不適切な回答をする場合、Agent Playbook上でその質問を繰り返し行い、エージェントの推論ステップを追跡します。これにより、どの判断で誤りが生じているかを特定し、プロンプトの修正やツールの改善につなげます。開発者は「ボットの変な返答の原因がすぐにわかった!」という状況で活用できます。
· AIエージェントの機能追加とテスト: 新しい外部ツールをAIエージェントに連携させた際、そのツールが意図通りに機能するかをAgent Playbook上でテストします。エージェントがツールを呼び出すコマンドの生成や、ツールの結果をどう解釈しているかを確認できます。開発者は「新しい機能がちゃんと動くか、個別に確認できて安心」という状況で役立ちます。
· 複雑なAIワークフローのデバッグ: 複数のAIエージェントが連携する複雑なワークフローにおいて、各エージェントの入出力や意思決定プロセスを個別に検証します。これにより、ワークフロー全体の問題箇所を特定しやすくなります。開発者は「複雑なAIの動きも、一つずつ追いかけていける」という状況で、原因究明に貢献します。
· プロンプトエンジニアリングの高速化: 様々なプロンプトを試して、AIエージェントの応答を最適化する際に、Agent Playbookのホットリロード機能と対話型テスト環境を最大限に活用します。これにより、効果的なプロンプトを短時間で見つけ出すことができます。開発者は「色々なプロンプトを試すのが、こんなに速くできるなんて!」と、効率化を実感できます。
34
漢字タイピングマスター (Kanji Typing Master)
著者
aladybug
説明
これは、Monkeytypeのようなタイピング練習ツールに着想を得た、楽しくてオープンソースの日本語学習プラットフォームです。特に漢字と語彙の練習に焦点を当て、サブスクリプションや有料壁にうんざりした長年の日本語学習者によって開発されました。このプロジェクトの核心は、学習体験を収益化するのではなく、コミュニティ主導で、誰もが無料でアクセスできる高品質な学習ツールを提供することです。
人気
ポイント 3
コメント 0
この製品は何ですか?
漢字タイピングマスターは、日本語の漢字と語彙を練習するための、無料でオープンソースのWebアプリケーションです。タイピングゲームの楽しさを日本語学習に取り入れ、ユーザーはタイピングスキルを向上させながら、新しい漢字や単語を効率的に覚えることができます。通常のフラッシュカードやドリルとは異なり、タイピングというゲーム性を取り入れることで、学習へのモチベーションを維持しやすく、飽きずに続けられるように設計されています。これは、高額なサブスクリプションモデルが一般的な日本語学習アプリ市場において、革新的なアプローチです。
どのように使用しますか?
開発者は、Webブラウザを開き、漢字タイピングマスターのウェブサイトにアクセスするだけで、すぐに利用を開始できます。特別なソフトウェアのインストールは必要ありません。学習者は、表示される漢字や単語をキーボードで正確かつ迅速に入力することで練習します。難易度や学習したい漢字の範囲、語彙の種類などをカスタマイズできるため、自身のレベルや目標に合わせた学習が可能です。また、オープンソースであるため、コードをフォークして、特定のニーズに合わせて機能を拡張したり、学習データを分析したりすることもできます。例えば、自分の学習進捗を可視化するカスタムダッシュボードを作成したり、特定の難易度の漢字セットを自動生成するスクリプトを作成したりするなどが考えられます。
製品の核心機能
· 漢字入力練習: 画面に表示される漢字をタイピングすることで、その読み方と書き方を習得します。これにより、記憶への定着を促進し、タイピング速度と漢字認識能力を同時に向上させることができます。
· 語彙タイピング練習: 日本語の単語をタイピングすることで、語彙力を強化します。文脈の中で単語を正確に入力する練習は、実際のコミュニケーション能力の向上に役立ちます。
· カスタマイズ可能な学習セッション: 学習者は、練習したい漢字のレベル(JLPT N1-N5など)、学習したい語彙のカテゴリ、タイピングの難易度などを自由に設定できます。これにより、個々の学習ニーズに合わせたパーソナライズされた学習体験が提供されます。
· 進捗トラッキングと分析: 学習の進捗状況を記録し、分析する機能を提供します。これにより、ユーザーは自身の強みと弱みを把握し、効果的な学習計画を立てることができます。
· オープンソースとコミュニティ開発: ソースコードが公開されており、誰でも貢献できます。これは、バグ修正、新機能の追加、学習コンテンツの拡充など、プラットフォーム全体の品質向上をコミュニティの力で推進することを可能にします。
製品の使用例
· 外国語学習者が、JLPT(日本語能力試験)の漢字と語彙の準備にこのプラットフォームを利用する。表示される漢字をタイピングすることで、試験で必要とされる膨大な量の漢字の読み方と意味を効率的に覚えることができる。具体的なシナリオとしては、JLPT N2レベルの漢字リストを選択し、タイピング練習を1日30分行うことで、数ヶ月で漢字の認識率とタイピング速度が大幅に向上する。
· プログラマーが、日本語の技術文書を読むために必要な語彙と漢字を習得する目的で利用する。このプラットフォームは、専門用語や技術関連の漢字に特化したカスタムリストを作成できるため、実用的な語彙を効率的に学習できる。例えば、AIや機械学習に関連する日本語の専門用語リストを作成し、タイピング練習を行うことで、関連文献の読解速度が向上する。
· 教育機関が、日本語クラスの補助教材としてこのプラットフォームを導入する。教師は、授業で扱った漢字や語彙のリストを共有し、学生は自宅でゲーム感覚で復習できる。これにより、学生の学習意欲を高め、クラスでの理解度を深めることができる。例えば、学校のカリキュラムに沿った漢字リストを教師が作成し、学生はそれをタイピングすることで、授業内容の定着を図る。
35
MCPエージェントJITコンパイラ
著者
ardmiller
説明
このプロジェクトは、MCP(Microscopic Coupled Processes)エージェントを、実行時にコードに変換する(JITコンパイル)という斬新なアプローチを提案します。これにより、従来はパフォーマンスのボトルネックとなっていたエージェントのシミュレーション速度を劇的に向上させ、より複雑で大規模なシステムモデリングを可能にします。これは、計算リソースの制約を克服し、科学研究やエンジニアリング分野における革新的な問題解決への道を開くものです。
人気
ポイント 3
コメント 0
この製品は何ですか?
MCPエージェントJITコンパイラは、マイクロスコピックに結合されたプロセスのシミュレーションにおいて、個々のエージェントの振る舞いを定義するコードを、プログラムの実行中に直接、最適化された機械語コードへと変換する技術です。通常、エージェントベースのシミュレーションでは、各エージェントのロジックを逐次解釈・実行するため、エージェント数が増えると計算負荷が指数関数的に増加します。このプロジェクトでは、JITコンパイル技術を応用することで、エージェントのコードをその場でコンパイルし、ネイティブコードに近い速度で実行します。これにより、シミュレーションの高速化と、これまで扱えなかったような大規模・高精度なモデリングが可能になります。これは、限られた計算資源でより多くの情報を引き出すための、まさに「ハッカー精神」に基づいた創造的な解決策と言えます。
どのように使用しますか?
開発者は、MCPエージェントの振る舞いを記述したスクリプトやソースコード(例えばPythonやLuaなどのスクリプト言語で記述されたもの)を、このJITコンパイラに渡します。コンパイラは、実行時にこれらのエージェントコードを分析し、プラットフォーム固有の最適化された機械語コードを生成します。生成されたコードは、シミュレーションエンジンに直接組み込まれ、実行されます。これにより、開発者はエージェントのロジックを変更するだけで、パフォーマンスの向上を自動的に享受できます。例えば、既存のシミュレーションフレームワークにモジュールとして組み込んだり、新たなシミュレーションプラットフォームを構築する際のコアエンジンとして利用したりすることが考えられます。
製品の核心機能
· エージェントコードの動的解析とJITコンパイル:エージェントの振る舞いを定義するコードを、実行時に解析し、高効率な機械語コードを生成します。これにより、シミュレーションの処理速度が劇的に向上します。これは、計算資源を効率的に使い、より多くのシミュレーションを実行したい場合に役立ちます。
· プラットフォーム最適化:生成される機械語コードは、実行環境のCPUアーキテクチャに合わせて最適化されます。これにより、特定のマシン上で最高のパフォーマンスを発揮させることができ、大規模な計算タスクの完了時間を短縮します。
· 実行時コード生成と実行:コンパイルされたコードは、メモリ上にロードされ、直接実行されます。これにより、従来のインタプリタ方式に比べてオーバーヘッドが大幅に削減され、シミュレーションの応答性が向上します。リアルタイム性が求められるシミュレーションや、インタラクティブなモデリングに有効です。
· カスタマイズ可能なコンパイルオプション:開発者は、コンパイル時の最適化レベルやターゲットアーキテクチャなどを細かく設定できます。これにより、特定のユースケースやハードウェア環境に合わせた、最高のパフォーマンスチューニングが可能になります。
製品の使用例
· 経済モデリングにおける大規模エージェントシミュレーション:数百万もの消費者エージェントが相互作用する複雑な経済モデルにおいて、個々の消費者行動の計算負荷をJITコンパイルで軽減し、市場全体の動向をリアルタイムに近い速度で予測します。これにより、政策立案者はより迅速な意思決定を行うことができます。
· 交通流シミュレーションにおけるリアルタイム最適化:都市全体の車両エージェントの挙動を、JITコンパイルされたコードで高速に処理します。これにより、交通渋滞の予測や、信号制御のリアルタイム調整が可能になり、都市の交通効率を向上させます。
· 感染症拡大モデリングにおける高精度予測:個々の人物エージェントの感染リスクや移動パターンを詳細にモデル化し、JITコンパイルで高速化することで、パンデミックの早期警告システムや、効果的な封じ込め戦略のシミュレーションを迅速に行えます。公衆衛生当局にとって、迅速な対応策の立案に繋がります。
· ゲームAIにおける複雑な敵行動生成:ゲーム内の多数の敵キャラクター(エージェント)のAIロジックをJITコンパイルすることで、より複雑で多様な敵の行動パターンをリアルタイムで生成し、プレイヤーに没入感のあるゲーム体験を提供します。開発者は、より洗練されたゲームAIを効率的に実装できます。
36
Go-async: Go言語の非同期処理をより直感的に
著者
unkn0wn_root
説明
Go-asyncは、Go言語で非同期処理をより簡単に、そして安全に扱えるようにするためのライブラリです。JavaScriptのasync/awaitのような直感的なAPIを提供し、複雑な並行処理をコードで追いやすくします。これにより、開発者は非同期処理の管理による負担を減らし、より創造的な開発に集中できます。
人気
ポイント 3
コメント 0
この製品は何ですか?
Go-asyncは、Go言語のgoroutineやchannelといった強力な並行処理の仕組みを、async/awaitのようなより現代的で理解しやすい構文で利用できるようにするライブラリです。従来のGoでは、非同期処理の結果を待つためにcallback関数やchannelの送受信を明示的に記述する必要がありましたが、Go-asyncはこれらの複雑さを抽象化し、`await`キーワードを使って非同期処理の完了を待つことができるようになります。これにより、コードの流れが線形的になり、エラーハンドリングも容易になります。これは、JavaScriptやPythonで馴染みのある非同期プログラミングのスタイルをGoにもたらすという点で革新的です。
どのように使用しますか?
開発者はGo-asyncライブラリをGoプロジェクトにインポートし、非同期処理を行いたい関数を`async`でマークします。そして、その非同期関数を呼び出す際には`await`キーワードを使用します。例えば、ネットワークリクエストやファイルI/Oなど、完了まで時間がかかる処理を`await`でラップすることで、その処理が終わるまでプログラムの実行を一時停止し、結果が返ってきたら処理を再開させることができます。これにより、複雑なコールバックの連鎖や、goroutineの明示的な管理といった手間を省くことができます。例えば、複数のAPIからデータを取得して結合するようなシナリオで、各API呼び出しを`await`で並行して実行し、全ての結果をまとめて処理することが容易になります。
製品の核心機能
· async/await構文の提供: 非同期処理を線形的なコードで記述できるようになり、コードの可読性と保守性が向上します。これにより、非同期処理のロジックが把握しやすくなり、バグの発見と修正が容易になります。
· 型安全なタスク管理: 非同期処理の結果が型付けされるため、実行時エラーのリスクを低減し、コンパイラによるチェックで開発初期段階での問題検出を支援します。これにより、予期せぬデータ型の不一致による問題を回避できます。
· エラーハンドリングの簡素化: 非同期処理におけるエラーハンドリングをtry-catchブロックのような直感的な方法で行えるようにし、エラー発生時の処理を容易にします。これにより、堅牢なアプリケーション開発に貢献します。
· 並列実行の容易化: 複数の非同期タスクを同時に実行し、それらの完了を効率的に待つ機能を提供します。これにより、パフォーマンスが重要なアプリケーションで、処理時間を大幅に短縮できます。
製品の使用例
· 複数の外部APIからのデータ取得と集計: 例えば、ユーザー情報を取得するために複数のマイクロサービスに同時にリクエストを送り、全ての結果が揃ってからユーザーインターフェースに表示するような場合に、Go-asyncを使うことで各API呼び出しを`await`で非同期に実行し、結果を効率的に集約できます。これにより、ユーザーはより迅速に情報を受け取ることができます。
· 大量のファイル処理: 多数のファイルを読み込み、それぞれに対して何らかの処理(例えば、データ抽出や変換)を行う場合、Go-asyncを利用して各ファイル処理を並列実行することで、全体の処理時間を大幅に短縮できます。これは、データ分析やバッチ処理のシナリオで特に有効です。
· リアルタイムデータストリームの処理: 複数のデータソースからリアルタイムで受信するデータを処理する場合、Go-asyncは各データソースからの受信と処理を効率的に非同期で行うための強力なツールとなります。これにより、遅延を最小限に抑えたアプリケーションを構築できます。
37
OpEx: Elixirのためのエージェント型LLMツールキット
著者
kenforthewin
説明
OpExは、Elixir開発者が大規模言語モデル(LLM)をより効果的に活用できるように設計された、エージェント型LLMツールキットです。API呼び出しの抽象化、非同期処理、状態管理などを簡素化し、LLMを組み込んだアプリケーション開発を加速させます。
人気
ポイント 3
コメント 0
この製品は何ですか?
OpExは、Elixirというプログラミング言語で、AI(大規模言語モデル)を使ったアプリケーションを簡単に作るための道具箱のようなものです。AIは、まるで人間のように文章を理解したり、生成したりすることができますが、それをプログラムで使うには、AIとのやり取りを細かく制御する必要があります。OpExは、そのAIとのやり取りを、Elixirの得意な非同期処理や並行処理の仕組みを使って、よりスムーズに、そして効率的に行えるようにしてくれる革新的なツールキットです。例えば、AIに質問して回答を得るだけでなく、AIが自ら複数のステップを踏んで問題を解決するような「エージェント」としての振る舞いをElixirで実現しやすくなります。
どのように使用しますか?
ElixirプロジェクトにOpExライブラリを追加することで利用できます。例えば、LLMに特定のタスク(文章の要約、コード生成、質問応答など)を実行させたい場合、OpExが提供する抽象化されたインターフェースを通じて、LLMへのリクエストを送信し、その結果を非同期で受け取ることができます。これにより、開発者はLLMの内部的な複雑さを気にすることなく、アプリケーションのビジネスロジックに集中できます。また、複数のLLM呼び出しを連携させて、より複雑なワークフローを構築することも容易になります。
製品の核心機能
· LLM API抽象化: 様々なLLMプロバイダー(OpenAI、Anthropicなど)のAPI呼び出しを統一された方法で扱えるようにし、開発者は特定のAPIに依存せずに済みます。これにより、将来的なLLMの選択肢が広がります。
· 非同期・並行処理: Elixirの強力な非同期・並行処理モデルを活用し、LLMとの対話を効率的に行います。これにより、アプリケーションの応答性が向上し、多数のユーザーからのリクエストにもスムーズに対応できます。
· エージェント型ワークフロー構築: LLMが複数のステップを踏んで問題を解決する「エージェント」の振る舞いを定義し、実行する機能を提供します。これにより、より高度で自律的なAIアプリケーションの開発が可能になります。
· 状態管理とパーシステンス: LLMとの対話履歴や、エージェントが生成した中間結果などの状態を管理し、必要に応じて永続化する機能を提供します。これにより、複雑な対話や長期的なタスクの実行が容易になります。
· プロンプトエンジニアリング支援: 効果的なプロンプト(AIへの指示文)を作成・管理するためのヘルパー機能を提供し、LLMの性能を最大限に引き出すことを支援します。
製品の使用例
· チャットボット開発: OpExを使用することで、ユーザーからの自然言語の質問に対して、LLMが適切な回答を生成するチャットボットをElixirで効率的に開発できます。複数の質問にまたがる文脈を保持する対話も実現可能です。
· コンテンツ生成: ブログ記事のドラフト作成、メールの自動生成、SNS投稿のアイデア出しなど、LLMによるコンテンツ生成タスクをプログラムから実行するアプリケーションを構築できます。OpExを使えば、生成プロセスを細かく制御できます。
· コードアシスタント: 開発者が書くコードを分析し、バグの検出、リファクタリングの提案、あるいはコードスニペットの生成といった、AIによるコーディング支援ツールをElixirで実装できます。OpExは、コード分析とLLMの連携をスムーズにします。
· データ分析・要約: 大量のテキストデータやドキュメントをLLMに読み込ませ、その内容を要約したり、特定の情報を抽出したりするタスクを自動化できます。OpExは、データ処理とLLMによるインテリジェントな分析を可能にします。
· ゲームAI: ゲーム内のNPC(ノンプレイヤーキャラクター)の対話生成や、ゲーム世界の状況に応じた動的な意思決定を行うAIをElixirで構築する際に、OpExを利用できます。これにより、より没入感のあるゲーム体験を提供できます。
38
SpeedyShare
著者
benjohnson8
説明
SpeedyShare は、プラットフォームを問わないファイル共有を劇的に簡素化する革新的なWebアプリケーションです。これまで、AndroidからMac、iPhoneからWindowsといった異なるOS間でのファイル共有は、AirDropのAppleエコシステム限定、WeTransferのファイルサイズ制限やアカウント登録、または両端末でのアプリインストールといった制約に悩まされてきました。SpeedyShareは、これらの問題を解消し、ブラウザさえあればどんなデバイスからでも、アカウント登録やトラッキングなしで、一時的にファイルを共有できるソリューションを提供します。ファイルは30分で自動削除されるため、プライバシーも保護されます。
人気
ポイント 2
コメント 0
この製品は何ですか?
SpeedyShareは、Webブラウザを通じて、OSやデバイスの種類を問わず、誰とでも簡単にファイルを共有できるサービスです。革新的な点は、特別なアプリのインストールが不要で、アカウント登録も不要なため、すぐに利用を開始できることです。ファイルは、アップロード後に発行されるQRコードまたは6桁のコードを通じて共有され、受信者はブラウザからファイルを受け取ることができます。技術的には、WebRTCやWebSocketsといったWeb技術を活用して、ブラウザ間で直接(またはサーバー経由で)ファイルを転送する仕組みを実装していると考えられます。これにより、従来のような複雑な設定や互換性の問題を回避し、手軽なファイル共有を実現しています。ファイルは30分後に自動的にサーバーから削除されるため、機密情報の長期保存リスクもありません。
どのように使用しますか?
開発者は、SpeedyShare.appにアクセスし、ファイルをアップロードするだけで、共有用のQRコードまたは6桁のコードが生成されます。このコードを相手に伝えるだけで、相手はそのコードを使ってブラウザからファイルを受け取ることができます。例えば、開発中のWebアプリケーションのスクリーンショットを、すぐに同僚の異なるOSのPCに共有したい場合や、モバイルデバイスで撮影した動画をPCに素早く転送したい場合などに利用できます。また、Webアプリケーションのプロトタイプをクライアントに素早く見せたい場合にも、アカウント登録やアプリインストールの手間なく、ブラウザ経由で共有できるため、非常に効率的です。
製品の核心機能
· プラットフォーム横断ファイル共有: どのようなOS(Android, iOS, Windows, macOSなど)やデバイス(PC, スマートフォン, タブレット)間でも、Webブラウザを通じてファイルを共有できます。これにより、OS間のファイル転送の障壁がなくなります。
· アカウント不要・トラッキングなし: ユーザー登録やログインが一切不要なため、プライバシーを重視するユーザーや、一時的なファイル共有をしたい場合に最適です。匿名での利用が可能で、ユーザーの活動を追跡することはありません。
· QRコード/コードによる共有: ファイル共有は、生成されたQRコードをスキャンするか、6桁のコードを伝えるだけで完了します。これにより、誰でも直感的にファイル共有を開始できます。
· 一時的なファイル保存: アップロードされたファイルは、30分後に自動的にサーバーから削除されます。これにより、不要なファイルが残り続けることを防ぎ、セキュリティとプライバシーを確保します。
· ブラウザベースの利用: 専用アプリのインストールは不要で、Webブラウザが利用できる環境であれば、どのデバイスからでもアクセス・利用できます。これにより、導入のハードルが極めて低くなっています。
製品の使用例
· 開発中のWebサイトのスクリーンショットを、異なるOSを使用しているチームメンバーに素早く共有し、フィードバックを得る。PCからスマートフォンへの画像転送が簡単に行えます。
· 旅行中にスマートフォンで撮影した動画を、PCに転送して編集したいが、ケーブル接続やクラウド同期の手間を省きたい場合に利用する。ブラウザだけで完結します。
· 一時的に大きなファイルをクライアントに共有したいが、アカウント登録やファイルサイズ制限を避けたい場合に活用する。WeTransferよりも手軽に利用できます。
· 公共のWi-Fi環境で、セキュリティを気にせずに一時的なファイル交換を行いたい場合に利用する。アカウント不要かつファイルが自動削除されるため、リスクを低減できます。
· 開発者会議などで、プレゼンテーション資料やデモ用のファイルを、参加者の様々なデバイスに素早く配布したい場合に利用する。参加者はURLやQRコードだけでファイルを受け取れます。
39
Martillo - Lua駆動のmacOSワークフロー自動化ハック
著者
sjdonado
説明
Martilloは、macOSのシステムAPIに深くアクセスできるHammerspoonを基盤とした、純粋なLuaで構築されたカスタマイズ可能なワークフロー自動化ツールです。Raycastのようなコマンドパレット機能を提供し、プロセスの管理、ウィンドウ操作、クリップボード履歴、ネットワークユーティリティなど、60種類以上の組み込みアクションを備えています。設定はLuaファイルで行い、依存関係なしで即座に利用開始できるのが特徴です。
人気
ポイント 2
コメント 0
この製品は何ですか?
Martilloは、macOSの自動化とタスク管理を劇的に効率化するオープンソースツールです。Hammerspoonという強力なmacOSシステムAPIにアクセスできるLuaフレームワーク上で動作するため、開発者はLuaスクリプトを書くだけで、macOSのあらゆる操作を自動化できます。例えば、特定のアプリケーションを起動したり、ウィンドウのサイズや位置を瞬時に変更したり、クリップボードにコピーした画像やファイルを管理したりすることが可能です。特筆すべきは、その「ハッカブル」な性質であり、コードを直接編集することで、既存の機能を拡張したり、全く新しいワークフローをゼロから作成したりできます。これは、決まった機能しか使えない市販ソフトとは一線を画す、開発者による開発者のための創造的なアプローチです。なので、あなたは「自分のPCを、まるで魔法のように思い通りに動かせるようになる」という価値を得られます。
どのように使用しますか?
開発者は、`store/`ディレクトリに任意のLuaファイルを追加するだけで、Martilloは自動的にそのファイルを読み込み、新しいワークフローやアクションとして利用可能になります。設定ファイル(こちらもLua)で、キーボードショートカット、エイリアス(コマンドの別名)、そして複数のアクションを組み合わせた複雑なコンポジションを宣言的に定義できます。HammerspoonのシステムAPIへのアクセスが容易なため、開発者はmacOSの深い機能に簡単にアクセスし、それをLuaスクリプトで制御できます。例えば、特定のアプリケーションにフォーカスを移動させる、複数のアプリケーションウィンドウを整列させる、特定のウェブサイトへのURLリダイレクトを設定するといった、日常的なPC作業を劇的に効率化するカスタムワークフローを構築できます。これは、開発者が日々のルーチンワークを自動化し、より創造的な作業に集中するための強力な手段となります。だから、あなたは「面倒なPC操作から解放され、仕事のスピードが格段に上がる」というメリットを享受できます。
製品の核心機能
· コマンドパレットとファジー検索:キーボードショートカットでコマンドパレットを呼び出し、アプリ名やアクション名を曖昧検索で素早く見つけることができます。これは、多数のアプリや機能を効率的に起動・実行するのに役立ちます。
· 純粋なLuaでの拡張性:Martilloは完全にLuaで書かれており、コードを直接編集して機能を追加・変更できます。これにより、開発者は自分のニーズに完全に合わせたカスタムワークフローを自由に作成できます。これは、既製品では満足できない開発者にとって、無限の可能性を提供します。
· HammerspoonによるシステムAPIアクセス:Hammerspoonの強力なAPIを利用して、macOSのファイルシステム、ウィンドウ管理、プロセス操作、ネットワーク設定などにプログラムからアクセスできます。これは、macOSの高度な機能を活用した自動化を実現するための基盤となります。だから、あなたは「macOSの隠れた力を引き出し、PCを自在に操る」ことができます。
· 宣言的な設定ファイル:キーボードショートカット、エイリアス、アクションの組み合わせなどを、一つの設定ファイルで分かりやすく定義できます。この整理された設定は、開発者間で共有しやすく、再現性の高い自動化環境を構築するのに役立ちます。これにより、チームでの効率化や、個人的な設定のバックアップも容易になります。
· 豊富な組み込みアクション:クリップボード履歴(画像・ファイル対応)、プロセス管理、25種類のウィンドウ位置設定、スマートコンバーター、ネットワークユーティリティ、画面ルーラー、Safariタブ管理、カレンダーメニューバー表示など、60種類以上の実用的なアクションが最初から利用可能です。これにより、多くの日常的なタスクをすぐに自動化でき、生産性が向上します。だから、あなたは「すぐに使える便利な機能で、PC作業のストレスを軽減できる」のです。
製品の使用例
· 開発者が、特定のIDE(例:VS Code)を起動し、同時にデバッグ用のターミナルウィンドウを特定のレイアウトで開くワークフローを自動化する。これにより、開発環境のセットアップ時間を短縮し、すぐにコーディングを開始できる。これは、日々の開発作業の効率を直接向上させる。
· コーダーが、クリップボードにコピーしたURLを自動的にブラウザの新しいタブで開くカスタムアクションを作成する。さらに、そのURLから取得した情報を解析して、別のタスク(例:チケット管理システムへの登録)をトリガーする。これは、情報収集とタスク管理のプロセスをシームレスに統合する。
· デザイナーが、画面上の特定領域のピクセル情報を取得し、それをカラーコードとしてクリップボードにコピーするアクションを作成する。さらに、そのカラーコードを基に、デザインツールの特定の色設定を自動的に更新する。これは、デザイン作業における色の管理と一貫性を保つ上で役立つ。
· システム管理者が、特定のプロセスがCPUを過剰に消費している場合に、自動的にそのプロセスを終了させ、ログに記録する監視スクリプトを作成する。これにより、パフォーマンスの問題を迅速に検出し、システムを安定稼働させることができる。これは、サーバーやPCの安定運用に不可欠である。
40
X-Macros CLI パーサー
著者
tyk001
説明
これは、C言語で書かれた、ヘッダーファイルのみで完結するシンプルなコマンドライン引数解析ツールです。X-Macrosというテクニックを使い、最小限のコードでフラグ(例: -h)や引数付きオプション(例: --port 8080)を簡単に解析できます。複雑な設定やサブコマンドはまだ対応していませんが、小~中規模のCプロジェクトに手軽に組み込めるように設計されています。なので、これはあなたのCプロジェクトのコマンドライン引数処理を劇的に簡単にするのに役立ちます。
人気
ポイント 2
コメント 0
この製品は何ですか?
これは、C言語でコマンドラインから渡される引数(例えば、プログラムを実行する際に「--input file.txt」や「-v」のように指定する情報)を、プログラム内で扱いやすい形に整理してくれるツールです。特に、X-Macrosという「コードを賢く再利用するテクニック」を使っているのが革新的です。これにより、ヘッダーファイル一つだけで、追加のライブラリをインストールする手間なく、手軽に導入できます。なので、これはC言語での開発において、コマンドライン引数処理の負担を大幅に減らし、開発効率を向上させます。
どのように使用しますか?
開発者は、このヘッダーファイルを自分のCプロジェクトにインクルードし、解析したいコマンドライン引数を定義するだけで利用できます。例えば、プログラムのエントリポイント(main関数)で、定義した引数構造体とコマンドライン引数を渡して関数を呼び出すことで、引数の解析が完了します。なので、これは既存のCプロジェクトに数行のコードを追加するだけで、コマンドライン引数処理の仕組みを実装できることを意味します。
製品の核心機能
· フラグ解析: `-h` のような単純なフラグ(オプション)を検出し、プログラム内でその存在を認識できるようにします。これは、ヘルプ表示などの機能で役立ちます。なので、これはユーザーがプログラムのヘルプ情報を簡単に確認できるようになります。
· 引数付きオプション解析: `--port 8080` や `--name "John Doe"` のように、オプション名に続いて値(数値や文字列)を渡す形式の引数を解析します。これにより、プログラムの動作を細かく制御できます。なので、これはプログラムに外部から設定値を渡して、柔軟な動作を実現できます。
· ヘッダーファイルのみの実装: 外部ライブラリの依存関係がなく、単一のヘッダーファイルをインクルードするだけで利用できます。これは、ビルドプロセスを簡素化し、環境依存性を減らします。なので、これはプロジェクトのセットアップと管理が非常に簡単になります。
· X-Macrosによるコード生成: X-Macrosというテクニックを用いて、定義された引数リストから必要なコードを自動生成します。これにより、コードの重複を減らし、保守性を向上させます。なので、これは引数定義の変更が容易になり、バグの発生リスクを低減します。
製品の使用例
· シンプルなコマンドラインツール開発: ログレベルを設定したり、入力ファイルを指定したりするような、小規模なC製コマンドラインツールの開発において、コマンドライン引数を効率的に処理するために使用します。なので、これは開発者が引数解析の煩雑さから解放され、ツールのコア機能に集中できるようになります。
· 組み込みシステムでの設定: 組み込み機器で、起動時に特定のパラメータ(例: IPアドレス、モード)をコマンドライン経由で渡したい場合に利用します。なので、これは限られたリソースの環境でも、柔軟な設定変更が可能になります。
· 既存Cプロジェクトへの機能追加: 既存のCプロジェクトに、コマンドラインから操作できる新しい機能を追加したい場合、このパーサーを使えば素早く実装できます。なので、これは既存コードへの影響を最小限に抑えつつ、機能拡張を実現できます。
41
WebAPIForge (ウェブAPIフォージ)
著者
valliveeti
説明
WebAPIForgeは、あらゆるウェブサイトをAPIに変換する革新的なブラウザエージェントです。Gemini 2.5 ProとFlashを組み合わせた効率的な技術により、最小限のトークン消費でウェブサイト上のあらゆる操作を自動化し、APIとして利用可能にします。これにより、従来はコストが高すぎて実現困難だったウェブ自動化タスクを、低コストかつ高精度で実行できるようになります。
人気
ポイント 2
コメント 0
この製品は何ですか?
WebAPIForgeは、ウェブサイトをプログラムから操作・データ抽出できるようにするAPIを生成するサービスです。その核心には、GoogleのGemini 2.5 Proという高度なAIモデルと、高速な処理を可能にするFlash技術が組み合わさっています。従来のブラウザエージェントは、操作を実行するたびに大量の情報をAIに読み込ませる必要があり、コストがかさむという課題がありました。WebAPIForgeは、必要な情報だけを厳選してAIに渡す「コンテキストの最小化」という技術で、この問題を解決しました。これにより、精度を維持しながらも、大幅にコストを削減し、より多くのウェブ自動化タスクを実現可能にしています。つまり、ウェブサイトの操作をコードで自在に操れるようになる、魔法の杖のようなものです。
どのように使用しますか?
開発者は、Lindraのチャットアプリケーションを通じて、自動化したいウェブサイトのURLと実行したい操作(例:「このECサイトから商品の価格をすべて取得したい」「このニュースサイトの最新記事のタイトルをリストアップしたい」など)を指示するだけで、そのウェブサイトのためのAPIエンドポイントを生成できます。生成されたAPIは、Python、JavaScriptなど、お好みのプログラミング言語からHTTPリクエストを通じて呼び出すことができます。例えば、Pythonなら`requests`ライブラリを使って簡単にAPIを叩き、返ってきたデータを加工して利用するといったことが可能です。これにより、スクレイピングツールの開発や、複数のウェブサイトの情報を集約するシステム構築などが、驚くほど容易になります。まるで、ウェブサイトがあなたのための専用データポートを提供してくれるような感覚です。
製品の核心機能
· ウェブサイト操作のAPI生成: 複雑なウェブサイトの操作(クリック、入力、スクロールなど)を、外部から呼び出し可能なAPIエンドポイントに変換します。これにより、プログラムからウェブサイトを自動操作する開発が容易になります。
· 最小コンテキストAI処理: Gemini 2.5 ProとFlashの組み合わせにより、AIが処理する情報量を最小限に抑え、処理速度の向上とコスト削減を実現します。高精度を維持しながら、効率的な自動化を可能にします。
· 汎用的なデータ抽出: ウェブサイト上のテキスト、画像、リンクなど、あらゆる種類のデータをプログラムで取得するためのAPIを提供します。これにより、ウェブサイトからの情報収集が劇的に効率化されます。
· タスク自動化API生成: 特定のウェブサイト上での一連のタスク(例:ログイン、フォーム送信、購入手続きなど)を自動化するAPIを生成します。これにより、反復的な作業の自動化や、ボット開発などが容易になります。
製品の使用例
· ECサイトの価格監視ボット: 特定のECサイトの商品価格を定期的にチェックし、価格変動があった際に通知するボットを開発。WebAPIForgeで商品ページから価格情報を取得するAPIを生成し、Pythonスクリプトで実行する。
· ニュースアグリゲーター: 複数のニュースサイトから最新記事のタイトルとURLを収集し、独自のニュースフィードを作成するシステムを構築。各ニュースサイトに対応するデータ抽出APIをWebAPIForgeで生成し、集約する。
· 競合分析ツール: 競合他社のウェブサイトから製品情報や価格設定を自動収集し、分析レポートを作成するツールを開発。WebAPIForgeでウェブサイトからの情報取得APIを生成し、データ分析基盤と連携させる。
· フォーム自動入力サービス: ユーザーが提供した情報に基づいて、オンラインフォームに自動で入力を行うサービスを開発。WebAPIForgeでフォーム入力と送信操作をAPI化し、フロントエンドから呼び出して利用する。
42
Claude.ai 画像生成器
著者
sahli
説明
这个项目是一个展示,演示了如何在 Claude.ai 这个强大的 AI 语言模型中生成图像。其技术创新在于利用了 Claude.ai 的文本理解和生成能力,通过文本描述来驱动图像的创作,解决了传统图像生成需要复杂专业工具的问题,让创意更容易落地。
人気
ポイント 2
コメント 0
この製品は何ですか?
这是一个利用 AI 语言模型 Claude.ai 来创造图像的项目。它的核心技术在于,你只需要用文字描述你想要的画面,Claude.ai 就能理解你的意图,并将其转化为一张图像。这不像传统的图像编辑软件需要精通各种参数和工具,而是通过自然语言进行沟通,就像和艺术家对话一样。它的创新之处在于,将强大的文本理解能力与图像生成能力相结合,大大降低了图像创作的门槛。
どのように使用しますか?
开发者可以将 Claude.ai 的图像生成能力集成到自己的应用程序中。例如,可以构建一个允许用户输入故事梗概,然后自动生成插图的应用。或者,在游戏开发中,可以快速生成游戏角色的概念图。通过 API 调用 Claude.ai,开发者可以发送文本提示,然后接收生成的图像,将其用于各种创意和应用场景。
製品の核心機能
· 文本到图像生成:通过输入的文字描述,AI 能够生成对应的图像,这使得任何有创意想法的人都可以轻松创作视觉内容,而无需掌握专业的绘画技巧。
· 自然语言交互:用户可以通过日常语言与 AI 交流,描述想要的图像风格、内容和细节,大大简化了创作过程,让创意表达更直接。
· AI 驱动的创意辅助:AI 能够理解复杂的描述,并生成具有艺术感和细节的图像,为设计师、作家、游戏开发者等提供强大的创意灵感和素材。
· API 集成能力:开发者可以通过 API 将图像生成功能嵌入到自己的软件或服务中,为用户提供更丰富的互动体验和个性化内容创作工具。
製品の使用例
· 博客文章配图生成:内容创作者输入文章主题或关键句,即可快速生成吸引人的配图,提升文章的视觉吸引力和阅读体验。
· 游戏概念艺术设计:游戏开发者描述角色、场景或道具,AI 快速生成概念图,加速游戏美术设计的早期探索和迭代。
· 个性化头像定制:用户输入对自己的描述,AI 生成独一无二的个性化头像,满足用户在社交媒体等平台上的个性化需求。
· 教育内容插画绘制:教育工作者描述教学内容或概念,AI 生成相关的插画,帮助学生更直观地理解抽象知识。
43
ImgExtender: 超速AI画像拡張&編集
著者
olivefu
説明
ImgExtenderは、AI生成画像の不自然な境界線、ぼやけたスクリーンショット、圧縮による劣化、複雑な背景編集などを、Photoshopのような専門知識や重いソフトウェアなしで、ブラウザ上で手軽に解決できる軽量ウェブツールです。AIによる自然な画像拡張(アウトペインティング)や、鮮明さを損なわずに画像を拡大・鮮明化する機能、簡単な画像編集まで、日常的な画像の問題を迅速かつ予測可能に修正します。
人気
ポイント 2
コメント 0
この製品は何ですか?
ImgExtenderは、AI画像拡張(アウトペインティング)、画像鮮明化、高解像度化、背景除去・変更、そして基本的な画像編集(切り抜き、リサイズ、テキスト追加、フィルターなど)といった、日常的な画像編集の課題を解決するために開発された、ブラウザ上で動作する多機能な画像編集ツールです。技術的な側面では、アウトペインティングには境界領域を自然に馴染ませるファインチューニングされた拡散モデルを使用し、ぼかし解除には多段階のシャープネス復元パイプラインを採用しています。高解像度化には、ディテールの復元に最適化された軽量なESRGANバリアントが使われています。これらの処理はバックエンドでGPUアクセラレーションされていますが、フロントエンドは高速動作のために最適化されています。これは、複雑なグラフィックソフトウェアを必要とせず、誰でも直感的に画像の問題を解決できることを目指した、まさに「コードで問題を解決する」というハッカー精神の具現化です。
どのように使用しますか?
開発者は、ImgExtenderのウェブサイト(imgextender.com)にアクセスし、サインアップなしで直接利用できます。例えば、AIで生成した画像のアスペクト比が合わない場合、ImgExtenderの「画像拡張(アウトペインティング)」機能を使って、境界に不自然な継ぎ目なくキャンバスを自然に広げることができます。また、SNS投稿用の画像を準備する際に、アスペクト比の調整や、ぼやけたスクリーンショットを鮮明にするために「ぼかし解除」や「高解像度化」機能を使ったり、製品写真の背景をきれいに削除・変更するために「背景除去・変更」機能を利用したりできます。これらの機能は、API連携を想定した将来的な開発も計画されており、開発ワークフローに簡単に組み込むことが可能です。簡単な画像編集は、コーディングすることなく、ウェブインターフェースから直接行うことができます。
製品の核心機能
· 画像拡張(アウトペインティング):AIが自然な生成で画像の境界を拡張し、継ぎ目のないシームレスな結果をもたらします。これにより、AI生成画像の意図しないアスペクト比の問題や、単に画像を大きくしたい場合に、不自然な余白なく対応できます。
· 画像鮮明化・高解像度化:ディープラーニング技術を用いて、ぼやけた画像を鮮明にし、低解像度の画像を滑らかなディテール復元と共に2倍から8倍まで拡大します。これにより、古い写真の修復や、圧縮されて劣化してしまった画像の品質を向上させることができます。
· 背景除去・変更:毛髪や柔らかいエッジにも対応したセグメンテーションモデルにより、画像から背景をクリーンに除去したり、新しい背景に変更したりできます。これにより、製品写真の合成や、ポートレート画像の背景差し替えなどを、専門的なスキルなしで迅速に行えます。
· 基本的な画像編集(切り抜き、リサイズ、テキスト追加、フィルター):これらの標準的な編集機能も提供されており、専門的なソフトウェアを開くことなく、ウェブ上で素早く画像サイズ調整や簡単な装飾が可能です。
· 画像圧縮:画質を損なわずに画像ファイルを軽量化します。ウェブサイトのロード速度改善や、メールでの画像共有に便利です。
製品の使用例
· AIアーティストがMidjourneyやDALL-Eで生成した画像の、意図しないアスペクト比や不自然な拡張部分を修正するために、ImgExtenderの「画像拡張(アウトペインティング)」機能を使用する。
· Etsyの出品者が、商品写真の背景をプロフェッショナルに見えるように、ImgExtenderの「背景除去」と「背景変更」機能を使って編集する。
· 開発者が、ゲームアセットやUI要素として使用する画像を、Photoshopを開かずに、ImgExtenderで迅速に切り抜き、リサイズ、またはAIで拡張して必要なサイズや形状に整える。
· 学生や教員が、プレゼンテーション資料やPDFの図を、ImgExtenderの「ぼかし解除」や「高解像度化」機能を使って、より鮮明で分かりやすいものに修正する。
· Web開発者が、ウェブサイトのパフォーマンス向上のために、ImgExtenderの「画像圧縮」機能を使用して、画質を保ったまま画像ファイルサイズを最適化する。
44
ブラウザで動く組み込みシステム・シミュレーター (Simulator86)
著者
grog6
説明
Simulator86は、ウェブブラウザ上で動作する革新的な組み込みシステムシミュレーターです。物理的な配線やハードウェアを用意することなく、STM32F4マイクロコントローラー向けのRustファームウェアを記述し、その動作をリアルタイムでシミュレーションできます。これにより、開発者は試行錯誤のサイクルを劇的に短縮し、コストを削減し、より迅速にアイデアを検証することが可能になります。
人気
ポイント 2
コメント 0
この製品は何ですか?
Simulator86は、ソフトウェア開発者が物理的なハードウェアに接続することなく、組み込みシステム(コンピューターの心臓部となる小さなコンピューター)のファームウェア(ハードウェアを動かすための基本的なプログラム)を開発・テストできるウェブベースのツールです。特にSTM32F4という種類のマイクロコントローラーと、Rustというプログラミング言語に特化しています。その革新性は、実際のハードウェアがない状態でも、まるで実機があるかのようにファームウェアの動作を正確に再現できる点にあります。これにより、開発者は開発環境のセットアップにかかる時間やコストを大幅に削減し、コードのバグを早期に発見・修正できるようになります。
どのように使用しますか?
開発者はSimulator86のウェブサイトにアクセスし、ブラウザ上でRust言語を使ってファームウェアコードを直接記述します。コードが完成したら、シミュレーター上で実行ボタンを押すだけで、ファームウェアがどのようにマイクロコントローラー上で動作するかを確認できます。例えば、LEDを点滅させるコードを書いた場合、シミュレーター上でLEDが点滅する様子を視覚的に確認できます。また、センサーからの入力を模倣したり、モーターの回転をシミュレーションしたりといった、より複雑なインタラクションも可能です。将来的には、より多くの種類のマイクロコントローラーに対応する予定です。
製品の核心機能
· ブラウザ上でのファームウェア記述と編集: 開発者は好きな時に好きな場所で、特別なソフトウェアのインストールなしにコードを書くことができます。これは、どこからでも開発を始められる柔軟性を提供します。
· リアルタイムシミュレーション: 記述したコードが実際のハードウェアでどのように動作するかを即座に確認できます。これにより、迅速なフィードバックループが実現し、開発効率が向上します。
· STM32F4マイクロコントローラーのサポート: 特定の人気のマイクロコントローラーアーキテクチャをサポートすることで、関連する開発者がすぐに利用を開始できます。
· Rust言語のサポート: 安全で高速なシステムプログラミングに適したRust言語をサポートすることで、モダンな開発手法を組み込み分野にもたらします。
· 仮想ハードウェアコンポーネントのシミュレーション: LED、ボタン、センサーなどの仮想的なハードウェア要素とインタラクションさせることで、実機に近い感覚でテストできます。これは、物理的なテストセットアップが不要になるため、時間とコストを節約できます。
製品の使用例
· 新製品のプロトタイピング: 新しい組み込みデバイスを開発する際、初期段階でハードウェアが完成していなくても、Simulator86上でファームウェアの基本的なロジックを検証できます。これにより、製品化までの時間を短縮できます。
· 教育目的での組み込みシステム学習: 大学や専門学校で組み込みシステムを学ぶ学生は、高価な開発ボードや機材を購入しなくても、ブラウザだけでファームウェア開発の基本を習得できます。これは、学習の敷居を下げ、より多くの学生に機会を提供します。
· ファームウェアのデバッグとテスト: 既存の組み込みシステムで発生したバグを、再現性の高い環境で特定・修正するのに役立ちます。物理的なデバッグが困難な場合でも、シミュレーションで問題を特定しやすくなります。
· リモートでの共同開発: チームメンバーが地理的に離れていても、Simulator86上で同じファームウェアコードを共有し、共同で開発・テストを進めることができます。これは、分散チームの生産性を向上させます。
45
O(1) シミュレーションタイムマシン (履歴バッファなし)
著者
0_of_1
説明
このプロジェクトは、シミュレーションの状態をO(1)(一定時間)で過去に巻き戻せる画期的なツールです。従来の履歴バッファ方式とは異なり、メモリを大量に消費せずに高速なタイムトラベルを実現します。これは、複雑なシミュレーションにおけるデバッグや分析を劇的に効率化します。
人気
ポイント 1
コメント 1
この製品は何ですか?
これは、シミュレーションの状態を記録・復元する際に、履歴をすべて保存するのではなく、特定のアルゴリズムを用いて、どんな時点の状態も一定時間(O(1))で計算して復元できる技術です。これにより、メモリ使用量を劇的に削減しながら、高速に過去の状態へジャンプできます。従来の「すべてを記録しておく」方法では、シミュレーションが長くなるとメモリがすぐにいっぱいになってしまいましたが、この技術はそれを根本から解決します。なので、この技術は、大規模なシミュレーションでもメモリ不足を気にすることなく、過去の状態を瞬時に確認できるというメリットがあります。
どのように使用しますか?
開発者は、このライブラリを自身のシミュレーションコードに組み込むことで利用できます。シミュレーションの各ステップで状態を更新する代わりに、このタイムマシンのAPIを呼び出して状態を管理します。これにより、デバッグ時に任意の時点にジャンプして、問題の原因を特定したり、特定のシナリオを再実行したりすることが容易になります。例えば、ゲーム開発でバグを見つけたいとき、シミュレーションがクラッシュした直前の状態をO(1)で再現して、何が起きたのかを調べる、といった使い方ができます。なので、開発者は、バグの原因究明にかかる時間を大幅に短縮できます。
製品の核心機能
· O(1)時間での状態復元: どのような過去の時点でも、計算によって状態を一定時間で再現します。これは、シミュレーションのデバッグや分析において、目的の状態に素早く到達できることを意味します。
· メモリ効率の高い状態管理: 履歴バッファを必要としないため、メモリ使用量が大幅に削減されます。これにより、メモリ制限のある環境や、長期間のシミュレーションでも安定した動作が可能になります。
· シミュレーションの効率的な分析: 過去の特定時点の状態を瞬時に確認できるため、シミュレーション結果の分析や、改善点の発見が容易になります。例えば、あるパラメータを変更したときの効果を、過去の時点と比較して評価できます。
· インタラクティブなデバッグ体験: 開発者は、シミュレーションを一時停止し、過去の状態にジャンプして、コードの実行をステップごとに確認できます。これにより、問題のある箇所をピンポイントで特定することが可能になります。
製品の使用例
· ゲーム開発におけるデバッグ: ゲームで予期せぬバグが発生した際、クラッシュした時点の数秒前や数分前の状態にO(1)で戻り、何が問題を引き起こしたのかを正確に調査できます。これにより、バグ修正にかかる時間が短縮されます。
· 科学技術シミュレーションの分析: 物理現象や化学反応などの複雑なシミュレーションで、特定のイベントが発生した時点の状態を高速に再現し、その原因や影響を詳細に分析できます。これにより、研究開発のスピードが向上します。
· リアルタイムシステムの検証: ネットワークシミュレーションや金融取引シミュレーションなどのリアルタイムシステムで、過去の特定のイベントが現在のシステム状態にどう影響したかをO(1)で確認し、システムの堅牢性を検証できます。
· 機械学習モデルのトレーニング追跡: 機械学習モデルのトレーニング過程で、特定のイテレーション時点の状態を復元し、学習の進捗や問題点を把握することができます。これにより、モデルのチューニングが効率化されます。
46
永遠のワンタイムツール (Eien no Wan-Taimu Tsuuru)
著者
mddanishyusuf
説明
「永遠のワンタイムツール」は、一度購入すれば無期限に利用できるユニークなソフトウェアコレクションです。複雑なサブスクリプションモデルにうんざりしている開発者やクリエイターのために、簡潔で永続的な価値を提供するという、黒魔術的な発想で生み出されたプロジェクトです。このプロジェクトの核となるのは、ソフトウェアライセンス管理と配布の課題に対する、 hacker spirit を反映した創造的なアプローチです。
人気
ポイント 2
コメント 0
この製品は何ですか?
「永遠のワンタイムツール」は、サブスクリプションモデルとは対照的に、一度支払えば永続的に利用権が得られる、開発者向けのユーティリティツールの集まりです。技術的な革新性としては、複雑なライセンスサーバーや定期的な更新料を必要としない、シンプルかつ自己完結型のライセンス認証メカニズムにあります。これは、ソフトウェアの配布と収益化における、従来のモデルに疑問を投げかける、 hacker culture の精神に基づいた、いわば「スマートな」解決策と言えます。つまり、これは「一度買えば、ずっと使える」という、開発者にとって非常に魅力的な、シンプルで持続可能なソフトウェア利用の形を提供します。
どのように使用しますか?
開発者は、このプロジェクトで提供される個別のツールを、その機能に応じてダウンロードし、ローカル環境や開発サーバーに統合します。ライセンス認証は、購入時に提供されるシンプルなキーや、ローカルファイルに基づくものなど、ツールごとに異なる、しかし極めて軽量な仕組みを採用しています。API連携やCLI(コマンドラインインターフェース)での利用が想定されており、既存の開発ワークフローに容易に組み込めます。例えば、特定のデータ処理ツールをCI/CDパイプラインに組み込んだり、ウェブアプリケーションのバックエンドで画像変換ツールとして利用したりすることが考えられます。これは、開発者が自身のツールチェインを、コストと管理の手間を最小限に抑えながら、強力にカスタマイズできることを意味します。
製品の核心機能
· 永続ライセンス認証: サブスクリプション料や再購入なしに、一度購入したツールを無期限に利用できる仕組み。これは、ソフトウェアの権利と利用のシンプルさを追求する hacker の発想です。何より、長期的なコスト削減と予測可能性が実現します。
· 軽量なユーティリティ: 特定のタスクに特化した、シンプルで効率的なツールの提供。例えば、高速なファイル変換、データ解析、コード生成などの機能が含まれる可能性があります。これにより、開発者は、特定の作業を迅速かつ効率的に完了させることができます。
· クロスプラットフォーム対応(想定): 主要なオペレーティングシステムで動作するよう設計されることで、より多くの開発者が利用可能になります。これにより、利用シーンが広がり、開発の柔軟性が向上します。
· API/CLIインターフェース: 他のプログラムやスクリプトから容易に呼び出せるインターフェースを提供。これは、開発者が既存のシステムにツールを統合し、自動化を進める上で非常に役立ちます。作業の自動化と効率化を加速させます。
· オープンソース(一部または全体): プロジェクトの透明性を高め、コミュニティによる貢献を促進する可能性があります。これにより、ツールの改善や機能拡張が迅速に進み、より堅牢なエコシステムが構築されます。開発者は、ツールの内部構造を理解し、必要に応じてカスタマイズできます。
製品の使用例
· API開発者: 頻繁に利用するデータ形式変換ツール(例: JSON to CSV)を一度購入し、APIレスポンスの処理に組み込む。これにより、毎月のサブスクリプション費用を節約し、開発プロセスを効率化できます。
· ウェブ開発者: 画像最適化ツールを、バックエンドでアップロードされた画像を自動的に圧縮するために使用する。これにより、ストレージコストを削減し、ユーザーエクスペリエンスを向上させることができます。
· データサイエンティスト: 特定のデータクリーニングや前処理ツールを、分析ワークフローに統合する。これにより、高価な商用ツールの代替となり、研究開発のコストを抑えることができます。
· DevOpsエンジニア: CI/CDパイプライン内で、コードの静的解析やデプロイメント前チェックを行うためのユーティリティとして活用する。これにより、パイプラインの安定性と効率性を高め、迅速なデプロイメントを支援します。
47
RunOS:Kubernetes即時展開プラットフォーム
著者
dib85
説明
RunOSは、5-10分で本番環境に対応したKubernetesクラスターを、データベース、メッセージキュー、オブザーバビリティ、AIツールまで設定済みで迅速に展開できるプラットフォームです。複雑なインフラ構築の手間を省き、開発者が本来集中すべきアプリケーション開発に注力できるよう支援します。KVMによるVMプロビジョニングと、エージェント主導のgRPCストリーム通信という革新的なアーキテクチャにより、ファイアウォール設定やパブリックIP不要で、セキュアかつ迅速な展開を実現します。
人気
ポイント 2
コメント 0
この製品は何ですか?
RunOSは、Kubernetesクラスターの構築と管理を劇的に効率化するプラットフォームです。従来、Kubernetesクラスターを本番環境で利用するには、ネットワーク設定、証明書管理、監視システム、データベース、ストレージなどのインフラをゼロから構築する必要があり、多大な時間と専門知識が必要でした。RunOSはこの課題を解決するため、KVM(Kernel-based Virtual Machine)という技術を用いて仮想マシンを高速にプロビジョニングし、その上にKubernetesを自動でセットアップします。さらに、サーバーエージェントとノードエージェントという2種類のエージェントを活用し、gRPCの双方向ストリーム通信でバックエンドと連携します。このエージェント主導の通信方式により、外部からクラスターへアクセスするためのファイアウォール設定やパブリックIPアドレスが不要になり、セキュリティを確保しつつ、導入の手間を大幅に削減します。つまり、「面倒なインフラ構築」から「すぐに使えるKubernetes」へと、開発体験を根本から変革します。
どのように使用しますか?
開発者はRunOSのウェブサイト(runos.com)でアカウントを作成し、無料トライアルクレジットを利用してクラスター作成を開始できます。「クラスター作成」ボタンをクリックするだけで、バックエンドが空いているサーバーエージェントに指示を送り、KVMで仮想マシンをプロビジョニングします。仮想マシンが起動したら、ノードエージェントがインストールされ、Kubernetesが自動でブートストラップされます。その後、WireGuardによるセキュアなノード間通信、ストレージ設定(OpenEBS + Longhorn)、そしてPostgreSQL、Kafka、Prometheusなどの各種ミドルウェアやAIツール(Ollama、LiteLLMなど)が自動でインストール・設定されます。この全プロセスはわずか5~10分で完了します。構築されたクラスターは、API経由やkubectlコマンドラインツールで操作でき、アプリケーションのデプロイや管理が可能です。また、「Bring Your Own Node」モデルを選択すれば、自身で用意したハードウェア上でRunOSのエージェントを実行することも可能です。
製品の核心機能
· Kubernetesクラスターの自動プロビジョニング: KVMとエージェント技術を組み合わせ、数分で本番環境レベルのKubernetesクラスターを構築。これにより、インフラ構築の時間を大幅に短縮し、開発者はアプリケーション開発に集中できます。
· 統合されたミドルウェアとAIツールの提供: PostgreSQL, Kafka, Prometheus, Ollamaなどの人気のあるデータベース、メッセージキュー、監視ツール、AI関連ツールをワンクリックでインストール可能。開発者は必要なツールを迅速に利用でき、開発サイクルの高速化に貢献します。
· エージェント主導のセキュアな通信: gRPC双方向ストリーム通信により、ファイアウォール設定やパブリックIPアドレスが不要。外部からの不要なアクセスを防ぎ、セキュアな環境でクラスターを運用できます。
· WireGuardによるOSレベルのセキュアネットワーキング: Kubernetesのトラフィックだけでなく、SSHアクセスも保護するOSレベルのWireGuardメッシュネットワークを構築。クラスターの安定性とセキュリティを強化し、トラブルシューティングを容易にします。
· 柔軟なデプロイメントモデル(Cloud/BYON): RunOS Cloudマネージドサービス、または自身のインフラ上でRunOSエージェントを実行する「Bring Your Own Node」モデルを選択可能。様々な運用ニーズに対応します。
製品の使用例
· スタートアップ企業が、限られたリソースで迅速に開発環境を構築したい場合。RunOSを利用することで、インフラ構築の専門家がいなくても、数分でKubernetesクラスターと必要なミドルウェア(データベース、キャッシュ、キューなど)を準備でき、プロダクト開発にすぐに着手できます。
· AIモデルの開発・デプロイを迅速化したい開発者。RunOSはGPUパススルーに対応したKVMを利用し、OllamaやLiteLLMといったAIツールを容易にセットアップできるため、ローカル環境でのモデル開発から本番デプロイまでをスムーズに行えます。
· 複数のマイクロサービスを開発・運用するチーム。RunOSは、各サービスが必要とするインフラ(データベース、メッセージキュー、オブザーバビリティツールなど)をクラスター内に統合して提供するため、サービス間の連携や運用管理が容易になり、開発効率が向上します。
· 既存のオンプレミス環境でKubernetesを導入したいが、複雑なネットワーク設定に頭を悩ませている担当者。RunOSの「Bring Your Own Node」モデルを利用すれば、既存のハードウェアを活用しつつ、エージェント主導のセキュアな通信と自動化されたKubernetes構築により、導入のハードルを低く抑えられます。
48
GitHub チーム活動分析ダッシュボード
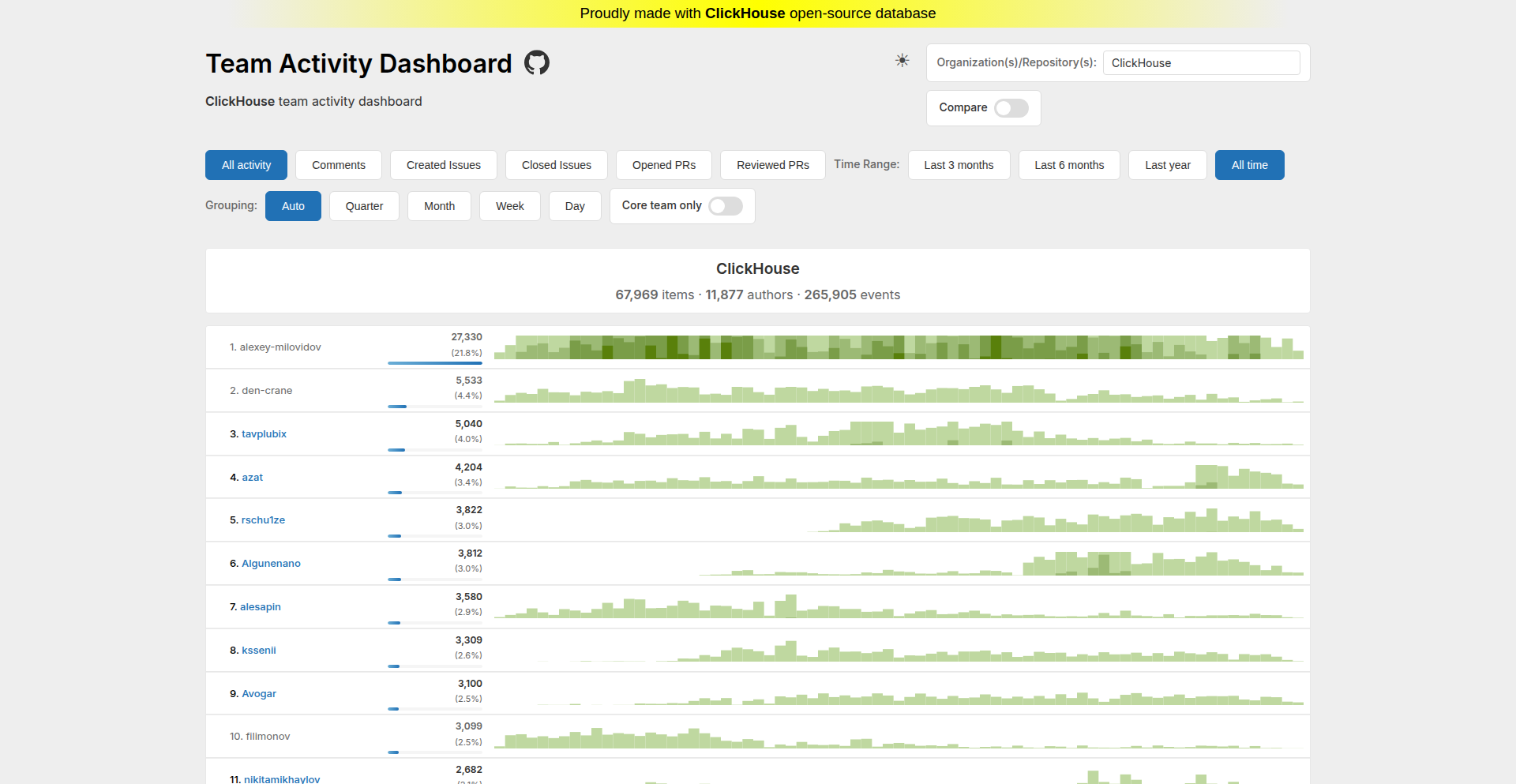
著者
AlexClickHouse
説明
GitHub リポジトリ間のチーム活動を比較し、主要メンバーとその貢献パターンを特定できるウェブサイト。単一のレポートから始まり、開発者の貢献を可視化し、チームの生産性向上に役立つ洞察を提供する。
人気
ポイント 2
コメント 0
この製品は何ですか?
このプロジェクトは、GitHub上の複数のリポジトリにおけるチームの活動状況を比較・分析するためのウェブサイトです。具体的には、コミット数、プルリクエストの頻度、コードレビューの参加状況など、開発チームの様々な活動指標を収集・可視化します。これにより、「誰が、いつ、どのような貢献をしているか」を詳細に把握でき、チーム全体の生産性やボトルネックを特定するのに役立ちます。技術的には、GitHub APIを活用してデータを取得し、それを分析・表示するウェブアプリケーションとして構築されています。開発者がGitHubの活動をより深く理解し、チームの改善点を見つけるための強力なツールとなります。
どのように使用しますか?
開発者は、このウェブサイトにアクセスし、分析したいGitHubリポジトリを指定するだけで利用を開始できます。複数のリポジトリを同時に選択し、比較分析を行うことも可能です。例えば、あるプロジェクトの新しいチームメンバーの貢献度を既存メンバーと比較したり、特定の機能開発におけるチーム全体の活発さを評価したりできます。また、個々の開発者のコミットメッセージを追跡することで、彼らがどのような問題解決に取り組んでいるかの傾向を把握することもできます。これは、プロジェクトマネージャーやチームリーダーが、チームの健全な運営と生産性向上を図る上で非常に役立ちます。コードの貢献パターンやコミュニケーションの活発さを可視化することで、より効果的なチームマネジメントが可能になります。
製品の核心機能
· リポジトリ横断での活動指標比較:複数のGitHubリポジトリのコミット数、プルリクエスト数、コードレビュー参加率などの活動指標を並べて比較できます。これにより、プロジェクト間のチームの忙しさや貢献度を客観的に把握でき、リソース配分の最適化に役立ちます。
· 主要メンバーの貢献パターン分析:特定のリポジトリにおける主要な貢献者とその貢献パターン(例:特定の種類のタスクへの集中度)を可視化します。これにより、チーム内のキーパーソンとその得意分野を特定し、スキルの活用や育成計画に役立てることができます。
· チーム活動の時系列分析:特定の期間におけるチームの活動推移をグラフで表示します。これにより、プロジェクトの進捗、イベント(例:リリース、バグ修正)に対するチームの反応、または生産性の変動要因を特定し、将来の計画立案に活かすことができます。
· コミットメッセージの詳細分析:開発者が残したコミットメッセージを収集・表示し、その内容から開発の進捗や問題解決の傾向を読み取ることができます。これは、コードだけでなく、開発者が抱えている課題や思考プロセスを理解するための貴重な情報源となります。
製品の使用例
· 新機能開発プロジェクトにおいて、複数の開発チームの進捗状況と貢献度を比較し、ボトルネックとなっているチームやメンバーを特定する。これにより、早期にリソースを再配分したり、支援を提供したりすることで、プロジェクト全体の遅延を防ぐことができます。
· オープンソースプロジェクトにおいて、コミュニティメンバーの貢献度を可視化し、活発な貢献者や潜在的なリーダーを発掘する。これにより、コミュニティの活性化とプロジェクトの持続的な発展を促進するためのインセンティブ設計や、貢献者への感謝の表明に活用できます。
· コードリファクタリングの効率を評価するために、リファクタリング前後のコミット数やコード変更量、プルリクエストのレビュー状況を比較する。これにより、リファクタリングの効果を定量的に測定し、今後の開発プロセス改善に役立てることができます。
· チームメンバーのオンボーディングプロセスを支援するために、新メンバーが既存メンバーの貢献パターンを参考に、どのようにプロジェクトに貢献していくべきかの指針を提供する。これにより、新メンバーが早期にチームに馴染み、効果的な貢献を開始できるようになります。
49
Kubernetes GitOps Sync Monitor
著者
kunobi
説明
这是一个桌面应用程序,旨在整合Kubernetes资源状态与Flux或ArgoCD的同步状态,从而减少开发者在检查运行状态、同步情况或偏差原因时频繁切换工具的需求。它直接与Kubernetes API服务器通信,读取Flux或ArgoCD发布的信息,并将其与每个集群上的工作负载信息一起呈现,重点关注工作负载的上下文、同步状态、偏差指示、最近的修订以及Helm历史。
人気
ポイント 2
コメント 0
この製品は何ですか?
这是一个本地运行的桌面应用程序,它能让你在一个地方同时看到Kubernetes中运行着什么(比如你的应用程序的服务、部署等),以及像Flux或ArgoCD这样的GitOps工具(它们负责将你的代码自动部署到Kubernetes)是否成功地将这些应用同步到了最新的状态。创新之处在于,它将两种不同的信息源(Kubernetes API和GitOps工具的状态)以直观的方式整合起来,让你一眼就能看出哪些应用是同步的,哪些出现了问题,而无需打开多个命令行窗口或Web界面。这就像是为你的Kubernetes集群和GitOps流程提供了一个统一的仪表盘。
どのように使用しますか?
开发者可以将这个应用程序安装在自己的电脑上。它会连接到你的Kubernetes集群(可以是本地的,也可以是远程的,通过配置kubeconfig文件)。一旦连接成功,你就可以在应用程序的界面中浏览你的Kubernetes资源,并查看Flux或ArgoCD报告的每个资源的同步状态。你可以看到资源之间的差异(diffs),以及应用程序的版本历史(Helm history)。对于不想连接生产集群的开发者,它还包含一个小的本地环境,用于测试GitOps流程。简单来说,就是安装软件,配置集群连接,然后就可以在一个界面里查看所有你关心的事情了。
製品の核心機能
· 一站式Kubernetes资源与GitOps状态查看:整合Kubernetes API提供的工作负载信息与Flux/ArgoCD提供的部署和同步状态,让你无需切换工具即可全面了解集群情况。这对于快速诊断部署问题和监控系统健康状况非常有价值。
· 同步状态和偏差指示:直观地展示哪些Kubernetes资源与GitOps的期望状态一致,哪些存在偏差(drift)。这使得开发者能够快速识别并解决部署不一致的问题,确保生产环境的稳定性。
· 多集群管理:无需频繁切换kubeconfig文件即可在多个Kubernetes集群之间轻松切换和管理。这极大地提高了在多云或混合云环境中工作的开发者的效率。
· 版本历史和变更追踪:查看应用程序的最近修订版本以及Helm部署历史。这有助于理解变更的来源和影响,便于回滚或审计。
· 本地测试环境:内置一个小型本地环境,方便开发者在不连接生产集群的情况下测试GitOps流程。这降低了试错成本,加速了开发迭代。
製品の使用例
· 当部署了一个新版本的应用程序后,发现它没有按预期运行,开发者可以使用该工具快速查看Kubernetes中该应用程序的服务、Deployment等资源的状态,同时查看Flux或ArgoCD报告的同步状态。如果发现同步失败或存在偏差,可以直接在工具中看到具体错误信息,从而迅速定位问题根源。
· 在管理多个Kubernetes集群(例如,一个用于开发,一个用于测试,一个用于生产)时,开发者可以通过该工具在同一个界面中切换查看不同集群的资源和GitOps同步状态,而无需在多个终端窗口或Web浏览器标签页之间来回切换,大大提高了工作效率。
· 当需要了解某个应用程序最近发生了哪些变更时,开发者可以通过查看工具中的版本历史记录,了解每次部署的版本号和对应的Git提交,结合同步状态,可以快速判断是代码变更引起的问题还是部署过程中的故障。
50
コード図メーカー
著者
mike_xilo
説明
ギターのコード図を自由に作成できる無料ツール。ジャズ、ボサノヴァ、複雑なコード進行に最適。サインアップ不要、オフラインで動作し、PDFエクスポートも可能。複雑なコード進行を学ぶ際のフラストレーションを解消するために開発されました。
人気
ポイント 2
コメント 0
この製品は何ですか?
これは、ギタリストが独自のギターコード図を簡単に作成できるウェブツールです。特にジャズやボサノヴァなどの複雑なコード進行を学ぶ際に役立ちます。従来、このようなカスタムコード図を作成するには専門的な知識やソフトウェアが必要でしたが、このツールはブラウザ上で直感的に操作でき、サインアップやインターネット接続なしでも利用できます。PDFでのエクスポート機能も備えており、練習用資料としてすぐに活用できます。技術的には、SVG(Scalable Vector Graphics)などのウェブ標準技術を駆使して、コード図の描画とカスタマイズを実現していると考えられます。これにより、高解像度でスケーラブルなコード図を生成し、様々な用途に対応できます。つまり、複雑なコードを学びたいギタリストにとって、学習のハードルを劇的に下げる革新的なツールと言えます。
どのように使用しますか?
開発者は、このツールをウェブブラウザで直接利用できます。特別なソフトウェアのインストールやアカウント登録は不要です。コードの構成音、フレットの位置、指の押さえ方などを画面上で設定し、コード図を生成します。生成されたコード図は、PDF形式でダウンロードして印刷したり、デジタル資料として共有したりできます。例えば、自分で編曲した楽曲のコード進行をまとめる際や、特定の学習教材のためにカスタムコード図を作成したい場合に、このツールは非常に役立ちます。JavaScriptなどのフロントエンド技術を活用して、ユーザーフレンドリーなインターフェースとインタラクティブな描画機能を提供していると考えられます。つまり、コード図作成のプロセスを簡略化し、ギタリストの創造性を高めるための実践的なツールとして活用できます。
製品の核心機能
· カスタムコード図の生成: ユーザーはコード名、構成音、押弦パターンなどを指定して、独自のコード図を生成できます。これにより、学習者は正確なコードフォームを視覚的に理解できます。
· オフラインでの利用: インターネット接続がなくてもコード図を作成できます。これにより、場所を選ばずに学習や練習に集中できます。
· PDFエクスポート機能: 生成されたコード図をPDF形式で保存できます。これにより、印刷して練習ノートに挟んだり、オンラインで共有したりすることが容易になります。
· サインアップ不要: アカウント作成の手間なく、すぐにツールを利用できます。これにより、ユーザーは迅速に目的を達成できます。
製品の使用例
· ジャズギタリストが、複雑なテンションノートを含むカスタムコード図を作成し、練習用シートとして活用する。これにより、難解なコード進行の理解が深まります。
· ボサノヴァ奏者が、独自のボサノヴァ特有のコードフォームを記録し、友人や生徒と共有するためにPDFでエクスポートする。これにより、学習資料の共有が効率化されます。
· 作曲家が、自身のオリジナル楽曲で使用する特殊なコード進行の図を作成し、楽譜に挿入する。これにより、楽曲の意図がより正確に伝わります。
51
Embedr: 組み込みエンジニアのためのAIナビゲーター
著者
sinharishabh
説明
Embedrは、組み込みエンジニアが直面するハードウェア特有の問題解決を支援するために設計された、AI搭載のコーディングアシスタントです。プロジェクトの構造やボード設定を理解し、ESP32、STM32、RP2040などのマイクロコントローラープロジェクトにおけるレジスタの説明、周辺機器の設定、ビルドエラー、リンクエラーの解決策を提案します。ハードウェアの不具合や統合問題に対する修正案の提示、ツールチェインの選択、ビルドシステムの生成、そして初期設定やドライバレベルのデバッグをサポートします。これにより、開発者は配線、フラッシュ、デバッグの各段階で、よりスムーズで効率的な開発体験を得られます。
人気
ポイント 2
コメント 0
この製品は何ですか?
Embedrは、組み込みエンジニア向けに特化したAIコーディングアシスタントです。一般的なコード生成AIとは異なり、ハードウェア開発のワークフローに深く根ざした機能を提供します。例えば、プロジェクトのファイル構造を解析して、使用しているボードの種類や設定を把握します。ESP32、STM32、RP2040といったマイクロコントローラー(MCU)プロジェクトに特化しており、CPUの内部レジスタが何をしているのか、周辺機器(例:センサーや通信モジュール)の設定方法、コンパイル時に発生する「リンカーエラー」や「ビルドエラー」の原因と修正方法を具体的に教えてくれます。さらに、ハードウェアの配線ミスや、複数の部品を組み合わせた際の統合問題に対する解決策を提案したり、開発に必要なソフトウェアツール(ツールチェイン)の選択や、ビルドシステム(プログラムを動かせる形にまとめる仕組み)の自動生成も行います。起動時の初期設定(ブリングアップ)や、ハードウェアと直接やり取りするドライバレベルのデバッグを段階的にガイドしてくれるため、まるでIDE(統合開発環境)が開発者をサポートしてくれるかのような感覚で作業を進められます。これは、ソフトウェア開発に比べて、ハードウェア開発ではどうしても時間がかかってしまう、プロトタイピングの迅速化、デバッグの効率化、そしてハードウェア特有の複雑な問題への対処を劇的に改善することを目指しています。
どのように使用しますか?
開発者は、Embedrのウェブサイト(embedr.app)にアクセスし、プロジェクトのコードベースをアップロードまたは接続することで利用を開始できます。Embedrは、プロジェクトの構造や依存関係を分析し、使用しているMCU(例:ESP32、STM32、RP2040)やターゲットボードを特定します。その後、開発者は自然言語で質問を投げかけることができます。例えば、「このSPI通信がうまくいかないんだけど、原因は何?」や「このGPIOピンをPWM出力にするためのレジスタ設定を教えて」といった具体的な質問に対して、Embedrはコードの提案、レジスタ設定の解説、ビルドエラーの修正手順などを提示します。また、新しいハードウェアの導入や、複雑なドライバの実装など、特定の開発タスクについても、段階的なガイダンスを受けることができます。これにより、開発者は、マニュアルを読み込んだり、フォーラムで情報を探したりする時間を大幅に削減し、より創造的な開発作業に集中できるようになります。
製品の核心機能
· プロジェクト構造とボード設定の理解: 開発者が使用しているマイクロコントローラーの種類、周辺機器の接続状況、プロジェクトの全体像をAIが把握し、より的確なサポートを提供します。これにより、個別のハードウェア環境に合わせた、カスタマイズされたアドバイスが得られます。
· MCU固有の技術的問題解決: ESP32、STM32、RP2040などの主要MCUに特化し、レジスタ設定、周辺機器(センサー、通信モジュールなど)の初期化、ビルドエラー、リンカーエラーといった、組み込み開発で頻繁に遭遇する専門的な技術的問題の解決策を具体的に提示します。これにより、開発者は、難解な仕様書やドキュメントに費やす時間を削減し、迅速に問題を解決できます。
· ハードウェア不具合と統合問題の診断・修正提案: ハードウェアの配線ミスや、複数のコンポーネントを組み合わせた際の連携問題など、物理的な側面が絡む複雑なトラブルシューティングをAIが支援し、原因特定と修正方法の提案を行います。これにより、デバッグにかかる時間と労力を大幅に軽減し、開発のボトルネックを解消します。
· ツールチェイン選択とビルドシステム生成: プロジェクトに最適なコンパイラ、デバッガなどの開発ツールセット(ツールチェイン)の選択を支援し、さらにはビルドシステム(コードを動くプログラムにまとめる仕組み)を自動生成します。これにより、開発環境の構築や設定の手間が省け、すぐに開発に着手できます。
· 初期設定(ブリングアップ)とドライバデバッグのガイド: 新しいハードウェアを初めて動かす際の初期設定プロセスや、ハードウェアと直接やり取りするドライバソフトウェアのデバッグ作業を、段階的かつ具体的にナビゲートします。これにより、複雑な初期段階の作業もスムーズに進め、開発の立ち上がりを早めることができます。
製品の使用例
· ESP32でWi-Fi通信を実装しようとしているが、接続が不安定で原因が特定できない開発者が、Embedrにプロジェクトコードとエラーログを共有。Embedrは、Wi-Fiモジュールのレジスタ設定の誤りと、競合する可能性のある他の周辺機器の設定について指摘し、具体的な修正コードを提案。これにより、開発者は問題の原因を迅速に特定し、安定したWi-Fi接続を実現できた。
· STM32マイクロコントローラーで、カスタムセンサーからのI2C通信を試みているが、データが正しく読み取れない開発者。Embedrに、I2C周辺機器のレジスタ設定とドライバコードについて質問。Embedrは、I2Cマスターモードの設定、クロック速度、およびACK(Acknowledgement)信号のハンドリングにおける注意点を解説し、デバッグに役立つコードスニペットを提供。開発者はEmbedrのガイダンスに従い、センサーからの正確なデータ取得に成功した。
· Raspberry Pi Pico(RP2040)で、複雑なビルドシステム(CMake)に苦戦している開発者。Embedrに「このプロジェクトのCMakeLists.txtを生成してほしい」と依頼。Embedrは、プロジェクトのファイル構成と使用するライブラリを解析し、RP2040向けの適切なビルド設定を含むCMakeLists.txtファイルを生成。開発者は、ビルド環境のセットアップ時間を大幅に短縮し、すぐにコードのコンパイルと実行を開始できた。
· 組み込みシステムで、原因不明のメモリエラーが発生し、デバッグが困難になっている状況。開発者がEmbedrにメモリダンプと関連コードを提供。Embedrは、メモリレイアウト、リンカー設定、およびスタックオーバーフローの可能性を分析し、特定の関数呼び出しにおけるメモリ破損の兆候を指摘。これにより、開発者は潜在的なバグ箇所を絞り込み、効率的に問題を修正できた。
52
統合決済ゲートウェイシミュレータ
著者
g-sudarshan
説明
これは、開発者が複数の決済ゲートウェイのサンドボックスアカウントを作成したり、一貫性のないモック動作に対処したりすることなく、決済統合をテストできるようにする、開発者向けのSaaSです。実世界のシナリオをシミュレートし、Webhookの遅延やネットワーク障害などのエッジケースをテストできる、単一のUAT環境を提供します。
人気
ポイント 2
コメント 0
この製品は何ですか?
これは、Stripe、Razorpay、Paytmなどのさまざまな決済ゲートウェイのAPIを模倣するSaaSベースのサンドボックス環境です。個別のゲートウェイアカウントを作成する手間を省き、トランザクション、返金、チャージバック、Webhookの遅延や失敗などの現実世界のシナリオをシミュレートできます。これにより、開発者は、実際のライブ環境にデプロイする前に、堅牢で信頼性の高い決済フローを構築できます。
どのように使用しますか?
開発者は、このシミュレータをAPIエンドポイントとして使用して、決済処理をテストできます。ローカル開発環境やCI/CDパイプラインに統合して、自動テストを実行できます。カスタムゲートウェイプロファイルを作成して、特定の失敗率、遅延、Webhookの動作などのルールを定義し、さまざまなシナリオを再現することも可能です。これにより、開発者は、実稼働環境で問題が発生する前に、決済統合のあらゆる側面を検証できます。
製品の核心機能
· 複数の決済ゲートウェイAPIのモック:Stripe、Razorpay、Paytmなど、さまざまな決済ゲートウェイのAPI呼び出しを模倣することで、開発者は個別のテストアカウントを設定する手間なしに、それらのゲートウェイとの統合をテストできます。これは、開発者が異なるゲートウェイの動作を迅速に比較・検証できるため、開発時間を大幅に短縮できます。
· 実世界のシナリオシミュレーション:キャプチャ、返金、チャージバック、Webhookの遅延/スキップ、ネットワーク障害など、現実世界の決済トランザクションで発生しうるさまざまなシナリオをシミュレートします。これにより、開発者は、予期せぬ状況やエッジケースに対するアプリケーションの堅牢性をテストし、実稼働環境での潜在的な問題を回避できます。
· カスタマイズ可能なゲートウェイプロファイル:開発者は、失敗率、遅延、Webhookの順序などを制御するカスタムゲートウェイプロファイルを作成できます。これにより、特定のテスト要件に合わせてシミュレーション環境を調整し、最も重要なシナリオを正確に再現できます。これは、詳細なテストとデバッグに不可欠です。
· ホストされたダッシュボード:モックトランザクションを表示し、ライフサイクルイベントを手動または時間指定でトリガーし、Webhookを再トリガーできるホストされたダッシュボードを提供します。これにより、開発者は、決済フローの実行状況を視覚的に監視し、必要に応じてテストシナリオを操作できます。これは、トランザクションのデバッグと理解を容易にします。
製品の使用例
· 複雑な返金シナリオのテスト:開発者は、部分的な返金、複数回の返金、および返金処理中のさまざまなエラー条件をシミュレートできます。これにより、返金ロジックが正確に機能し、顧客データが整合性を保っていることを保証できます。これにより、混乱を招く返金処理による顧客満足度の低下を防ぎます。
· Webhookの遅延と障害への対応:Webhookの遅延、スキップ、または順序の誤りをシミュレートすることで、開発者は、これらの問題が発生した場合でも、アプリケーションが正しく応答し、状態を維持できることを確認できます。これは、非同期処理が重要なシステムにおいて、データの不整合や処理の遅延を防ぐために不可欠です。
· CI/CDパイプラインへの統合:このシミュレータをCI/CDパイプラインに組み込むことで、コード変更ごとに決済統合の自動テストを実行できます。これにより、新しいバグが早期に発見され、リグレッションが防止され、開発プロセス全体が迅速化します。これは、開発サイクルの迅速化と品質向上に貢献します。
· 3-Dセキュア/OTPフローのテスト:3-DセキュアまたはOTP(ワンタイムパスワード)認証ページを模倣することで、開発者は、これらのセキュリティフローがユーザーエクスペリエンスを損なうことなく、期待どおりに機能することを確認できます。これは、オンライン決済のセキュリティと使いやすさのバランスをとる上で重要です。
53
Redditビザタイムライン抽出パイプライン
著者
hnarayanan
説明
Redditのコメントから英国ビザの申請・承認タイムライン情報を自動で抽出するパイプラインです。自然言語処理(NLP)技術を活用し、大量の非構造化データから特定の情報を効率的に収集・整理することで、ビザ申請プロセスに関心のある人々や関連機関にとって貴重な洞察を提供します。
人気
ポイント 2
コメント 0
この製品は何ですか?
これは、Redditのようなソーシャルメディア上の膨大なテキストデータから、英国ビザ申請に関連する具体的なタイムライン情報(申請日、承認日、結果など)を自動的に見つけ出し、構造化されたデータとして整理するシステムです。革新的な点は、自然言語処理(NLP)の最新技術、特に固有表現認識(NER)や関係抽出(RE)を用いて、人間が読むには手間のかかる無数のコメントの中から、ビザ申請の進捗に関する重要な日付やステータスを正確に識別・抽出できることです。これにより、これまで散在していた個人の体験談が、集計・分析可能な貴重なデータセットへと変換されます。つまり、個々の体験談が持つ断片的な情報が、共通の課題解決や意思決定に役立つ全体像へと進化するのです。
どのように使用しますか?
開発者は、このパイプラインをAPI経由で利用するか、オープンソースとして提供されているコードを自身のプロジェクトに組み込むことができます。例えば、ビザコンサルタントは、このパイプラインを使って最新のビザ申請傾向や平均処理時間を把握し、クライアントへのアドバイスの質を向上させることができます。また、データサイエンティストは、抽出されたタイムラインデータを分析し、ビザ政策の影響や申請プロセスのボトルネックを特定する研究に活用できます。Pythonなどのプログラミング言語で容易に連携でき、分析ツールやデータベースに接続して、さらに高度な分析や可視化を行うことが可能です。これは、手作業での情報収集にかかる時間とコストを劇的に削減し、より迅速かつ正確な意思決定を可能にします。
製品の核心機能
· Redditコメントからのビザタイムライン情報抽出:自然言語処理(NLP)技術、特に固有表現認識(NER)を用いて、コメント本文から申請日、承認日、結果などの日付やステータス情報を自動的に識別・抽出します。これにより、膨大なテキストデータから必要な情報をピンポイントで探し出す手間が省け、関連情報の収集効率が飛躍的に向上します。
· 情報構造化とデータ整理:抽出されたタイムライン情報を、検索・分析しやすい構造化データ(例:CSV、JSON形式)に変換します。これにより、後続の分析や可視化が容易になり、データの二次利用価値が高まります。手作業でのデータ整理にかかる時間とミスを削減し、より信頼性の高いデータセットを構築できます。
· 時系列分析のためのデータ基盤構築:抽出・整理されたタイムラインデータは、ビザ申請プロセスの変化や傾向を時系列で分析するための基盤となります。これにより、申請プロセスのボトルネック特定や、政策変更の影響評価などが可能になり、よりデータに基づいた意思決定が促進されます。
· 情報収集の自動化と効率化:手動での情報収集に比べて、大幅な時間と労力の削減を実現します。これにより、開発者やアナリストは、より創造的で付加価値の高い作業に集中できるようになります。これは、リソースを最適化し、プロジェクトのスピードを加速させることに直結します。
製品の使用例
· ビザコンサルタントが、最新のビザ申請状況や処理時間を把握するために、このパイプラインを使用してReddit上の関連投稿を分析する。これにより、クライアントに対してより正確でタイムリーな情報を提供し、競争優位性を確立する。
· 移民関連の研究者が、英国ビザ申請プロセスのボトルネックや、特定のビザカテゴリーにおける申請傾向を調査するために、抽出されたタイムラインデータを集計・分析する。これにより、政策立案者への提言や学術論文の執筆に役立つ客観的なデータを提供する。
· IT企業が、海外からの優秀な人材採用プロセスを効率化するために、ビザ申請に関する情報を収集・分析する。これにより、採用担当者は、申請プロセスにおける潜在的な遅延要因を事前に把握し、候補者へのスムーズなサポート体制を構築する。
· 個人が、自身と同じような状況にある他の申請者のタイムライン情報を参照し、自身のビザ申請プロセスにおける期待値を管理する。これにより、不確実な状況下での不安を軽減し、より計画的な準備を進めることができる。
54
TrustHub: シンプルな信頼性可視化ツール
著者
gamalinosqui
説明
このプロジェクトは、ウェブサイトやアプリケーションの信頼性を、エンドユーザーにも分かりやすい形で提示するための、シンプルかつ無料のツールです。技術的な側面では、特定のAPIやデータソースと連携し、信頼性に関する情報を集約・分析する仕組みを独自に構築しています。これにより、ユーザーは不明瞭な情報に惑わされることなく、安全なサービスを選択できるようになります。
人気
ポイント 2
コメント 0
この製品は何ですか?
TrustHubは、ウェブサイトやサービスの信頼性を「見える化」するための、非常にシンプルで無料のツールです。技術的な仕組みとしては、例えば、そのサービスが過去にどのようなセキュリティインシデントを起こしたか、プライバシーポリシーは明確か、といった情報を、公開されているデータや連携可能なAPIから自動的に収集・分析します。そして、それを専門用語を使わずに、誰にでも理解できるようなスコアリングやインジケーターで表示します。つまり、複雑な技術情報をかみ砕いて、ユーザーが「このサービスは信頼できるか?」をすぐに判断できるようにする、という技術的な洞察に基づいています。
どのように使用しますか?
開発者は、TrustHubの提供するAPIやウィジェットを自身のウェブサイトやアプリケーションに組み込むことができます。例えば、自社サービスを紹介するページにTrustHubの信頼性スコアを表示することで、ユーザーは安心してサービスを利用できるというメリットがあります。また、開発者自身が、自社サービスの信頼性を客観的に評価し、改善点を見つけるためのツールとしても活用できます。統合は比較的簡単で、数行のコードを追加するだけで利用可能です。
製品の核心機能
· 信頼性スコアリング機能: 複数の信頼性指標(セキュリティ、プライバシー、透明性など)を総合的に評価し、分かりやすいスコアとして表示します。これにより、ユーザーは直感的にサービスの信頼度を把握できます。これは、様々なデータソースからの情報を統合し、独自のアルゴリズムでスコアリングする技術によって実現されています。
· インシデント履歴の可視化: 過去に発生したセキュリティインシデントやデータ漏洩などの履歴を、分かりやすく時系列で表示します。これにより、サービス提供者が過去の失敗から学び、改善を続けているかを確認できます。これは、公開されているセキュリティデータベースやニュースフィードから関連情報を収集・分析する技術に基づいています。
· プライバシーポリシー分析: プライバシーポリシーの条項を分析し、ユーザーにとって不利な条項や、不明瞭な部分をハイライト表示します。これにより、ユーザーは自分のデータがどのように扱われるかを理解しやすくなります。これは、自然言語処理(NLP)技術を用いて、プライバシーポリシーのテキストを解析する仕組みです。
· 透明性レポート生成: サービス提供者が、データ利用状況やセキュリティ対策に関する透明性レポートを生成・公開するのを支援します。これにより、ユーザーはサービス提供者の誠実さを確認できます。これは、データ集計とレポート生成を自動化するバックエンド技術によって支えられています。
製品の使用例
· 新しいSNSアプリをローンチする際に、TrustHubのウィジェットをアプリの紹介ページに表示する。これにより、ユーザーは新しいアプリでも安心してアカウントを作成し、個人情報を共有できると判断できる。
· オンラインショップの決済ページに、TrustHubの信頼性スコアを表示する。これにより、顧客は安心してクレジットカード情報を入力し、購入を完了できる。
· 開発者が、自社が開発・提供するSaaSツールの信頼性を定期的にチェックし、改善すべき点を特定するためにTrustHubを利用する。例えば、セキュリティ対策の脆弱性が指摘された場合、早急に対処することで、顧客からの信頼を維持・向上させることができる。
· ユーザーが、複数のオンラインサービスを比較検討する際に、それぞれのTrustHubの信頼性スコアを確認し、より安全で信頼できるサービスを選択する。
55
GreasePanda: ウェブサイト改造スクリプトエンジン
著者
sudosoft
説明
GreasePandaは、どんなウェブサイトもユーザー定義のスクリプトで即座に変更できる革新的なブラウザ拡張機能です。ウェブサイトのUIをカスタマイズしたり、不要な広告を削除したり、特定の機能を自動化したりといった、開発者が抱える細かな「ちょっとした不便」をコードで解決するための強力なツールです。
人気
ポイント 2
コメント 0
この製品は何ですか?
GreasePandaは、ユーザーが自分で作成したJavaScriptコード(ユーザー スクリプト)を、閲覧しているウェブサイトに適用できるようにするブラウザ拡張機能です。ウェブサイトの見た目を変えたい、特定のボタンをクリックするのを自動化したい、邪魔な広告を非表示にしたい、といった場合に、ウェブサイトのソースコードを直接編集することなく、柔軟にカスタマイズできます。これは、ウェブサイトの限られた機能やデザインに縛られず、ユーザー自身のニーズに合わせてインターネット体験を「ハック」するための、まさに黒客(ハッカー)精神を体現した技術です。
どのように使用しますか?
開発者は、GreasePanda拡張機能をブラウザにインストールした後、.user.jsという拡張子を持つJavaScriptファイルを作成します。このファイルには、どのウェブサイトに適用するか(`@match`ディレクティブ)、そして実行するJavaScriptコードを記述します。例えば、特定のニュースサイトで、長文記事の表示を改善したり、ショッピングサイトで、頻繁に使う検索機能をショートカットしたりといったことが可能です。作成したスクリプトをGreasePandaに読み込ませるだけで、該当するウェブサイトを開いた際に自動的にスクリプトが実行され、ウェブサイトの挙動が変更されます。これにより、開発者は迅速にプロトタイプを作成したり、既存のツールの機能を拡張したり、あるいは日常的なタスクを効率化したりすることができます。
製品の核心機能
· ウェブサイトへのJavaScriptコード注入: 閲覧中のウェブサイトに、ユーザーが作成したJavaScriptコードを直接実行させる機能です。これにより、ウェブサイトの動的な振る舞いを自由に変更し、開発者のアイデアを即座に試すことができます。
· サイトマッチング機能: 特定のURLパターンに一致するウェブサイトでのみスクリプトを実行するように指定できます。これにより、意図しないサイトでスクリプトが動作するのを防ぎ、きめ細やかな制御を可能にします。
· ユーザー スクリプト管理: 作成した複数のユーザー スクリプトを簡単に管理・有効/無効化できます。これにより、様々なカスタマイズを整理し、必要に応じて切り替えることが容易になります。
· 開発者向けデバッグ機能(想定): スクリプトの実行状況を確認したり、エラーを検出したりするための基本的なデバッグ支援機能があると、開発効率がさらに向上します。これにより、問題解決が迅速化され、より洗練されたスクリプト作成に繋がります。
製品の使用例
· 特定のソーシャルメディアサイトで、煩わしい広告を自動的に非表示にするスクリプトを作成し、よりクリーンな閲覧体験を得る。これは、広告ブロック拡張機能では対応できない、サイト固有の広告表示ロジックにも対応できる可能性を示唆します。
· 普段よく利用するオンラインドキュメントサイトで、特定のキーワードをハイライト表示したり、文章の検索を補助する機能を実装する。これにより、情報検索の効率が格段に向上し、生産性を高めることができます。
· 社内開発用のウェブベースツールで、頻繁に行うデータ入力作業を自動化するスクリプトを作成する。これにより、手作業によるミスを減らし、開発者はより創造的な作業に集中できるようになります。
· 学習中の新しいJavaScriptフレームワークの機能を、既存のウェブサイトに簡易的に適用して動作を確認する。これにより、実際に動くコードを素早く試すことができ、学習効果を高めることができます。
56
多言語関数用コンテンツアドレスストレージ:Open თუre.py
著者
amirouche
説明
Open თუre.pyは、多言語の関数をコンテンツアドレスストレージとして管理できるPythonライブラリです。これにより、関数のコードそのものをアドレスとして利用し、変更を検知したり、重複を排除したりすることが可能になります。特に、異なる言語で書かれた関数を統一的に管理したい場合や、バージョン管理をコードの内容に基づいて行いたい場合に革新的なアプローチを提供します。
人気
ポイント 2
コメント 0
この製品は何ですか?
Open თუre.pyは、関数のコードの内容に基づいて一意のアドレスを生成し、そのコードを保存・管理する仕組み(コンテンツアドレスストレージ)をPythonで実現するライブラリです。従来のファイルパスやIDではなく、コードそのものが「住所」になるイメージです。これにより、同じコードが複数箇所にあっても重複なく扱えたり、コードが変更されたらすぐに検知できたりします。例えば、JavaScriptで書かれた関数とPythonで書かれた関数があったとしても、それぞれのコードの内容に基づいてユニークなIDが生成され、管理されます。これは、コードの同一性を厳密に保証し、デプロイメントの信頼性を高めるための新しい方法論です。
どのように使用しますか?
開発者は、Open თუre.pyライブラリをPythonプロジェクトにインストールし、関数のコードを渡すことで、その関数に対応するハッシュ値(アドレス)を取得できます。このハッシュ値を使って、関数のコードをストレージ(例えば、IPFSなどの分散ストレージや、ローカルファイルシステム、クラウドストレージなど)に保存・取得します。これにより、開発者は「このコードは以前にも使ったものだ」「このコードは最新版だ」といったことを、コードの内容に基づいてプログラム的に判断できるようになります。例えば、APIエンドポイントで受け取ったコードのハッシュ値と、登録済みのコードのハッシュ値を比較することで、不正なコードの実行を防いだり、コードの変更があった場合に自動的に再デプロイするようなワークフローを構築できます。
製品の核心機能
· 関数コードのハッシュ化:関数のコード内容を基に、重複のない一意のハッシュ値を生成します。これにより、コードの同一性をプログラムで検証でき、意図しないコードの混入や変更を防ぎます。
· コンテンツアドレスストレージへの連携:生成されたハッシュ値をアドレスとして、IPFSやS3などのストレージにコードを保存・取得する機能を提供します。これにより、コードの永続的な管理と、効率的な取得が可能になります。
· 多言語対応:Pythonだけでなく、JavaScriptやWebAssemblyなど、他の言語で書かれた関数コードも同様にアドレス化して管理できます。これにより、マイクロサービスアーキテクチャなどで異なる言語の関数を統一的に扱う際に、コード管理の複雑さを軽減します。
· 変更検知:保存されているコードと新しいコードのハッシュ値を比較することで、コードの変更を即座に検知できます。これは、CI/CDパイプラインでコードの変更をトリガーとした自動テストやデプロイメントを行う際に非常に役立ちます。
製品の使用例
· サーバーレス関数(AWS Lambda, Google Cloud Functionsなど)のデプロイメント管理:各関数のコードをハッシュ値で管理し、変更があった場合のみ再デプロイをトリガーすることで、デプロイメントの効率化と信頼性の向上を実現します。
· 分散アプリケーション(dApps)におけるスマートコントラクトのバージョン管理:スマートコントラクトのコードをコンテンツアドレスで管理し、過去のバージョンとの比較や、最新バージョンの特定を容易にします。
· コード共有プラットフォーム:開発者がコードスニペットを共有する際に、コードの内容に基づいて一意のIDを付与し、重複するスニペットを自動的に識別・集約します。これにより、コードの再利用性を高め、ストレージ容量を節約できます。
· IoTデバイスでのファームウェア管理:多数のIoTデバイスで動作するファームウェアのアップデートを、コードの内容(ハッシュ値)に基づいて管理します。これにより、どのデバイスがどのバージョンのファームウェアを実行しているかを正確に把握し、安全かつ効率的なアップデートを実現します。
57
RAG評価用合成データ生成器 (RAG Evaluation Synthetic Data Generator)
著者
scosman
説明
このプロジェクトは、Retrieval Augmented Generation (RAG) システムの評価を自動化し、その性能を向上させるための合成データ生成ツールです。RAGは、大規模言語モデル(LLM)が外部知識ベースから情報を取得して回答を生成する技術ですが、その評価には質の高いデータセットが不可欠です。このツールは、現実のユースケースを模倣した多様で高品質な質問と回答のペアを生成することで、開発者がRAGシステムの弱点を発見し、改善するための強力な基盤を提供します。
人気
ポイント 2
コメント 0
この製品は何ですか?
これは、Retrieval Augmented Generation (RAG) システムの性能を評価するために、人工的に質問と回答のペアを生成するプログラムです。RAGシステムは、AIが質問に対して、外部のデータベースやドキュメントから関連情報を検索して、より正確で文脈に沿った回答を生成する仕組みです。しかし、実際の運用では、どのような質問がRAGシステムにとって難しいのか、あるいはどのような情報が不足しているのかを評価するために、多様な質問とそれに対応する正しい回答が必要です。このツールは、そのような評価用データを自動で、かつ大規模に作成することで、RAGシステムの開発・改善プロセスを効率化します。技術的な側面としては、自然言語処理(NLP)の技術、特に質問生成モデルや知識グラフ、あるいは既存のテキストデータから意味的に関連性の高い情報を抽出し、それを基に質問と回答のペアを構築するアルゴリズムが用いられていると考えられます。これにより、手作業でのデータ作成にかかる時間とコストを大幅に削減し、より網羅的な評価を可能にします。
どのように使用しますか?
開発者は、このプロジェクトが提供するライブラリやコマンドラインインターフェース(CLI)を通じて、合成データ生成プロセスをカスタマイズできます。具体的には、評価したいRAGシステムの特性(例:扱うドメイン、質問の複雑さ)に合わせて、生成するデータの種類や量、難易度などを設定できます。例えば、特定の業界に特化したRAGシステムを開発している場合、その業界に関連する用語や概念を含む質問を大量に生成させることが可能です。生成されたデータセットは、既存のRAG評価フレームワークに組み込んだり、直接RAGシステムの入力として使用して、その応答精度、関連性、安全性などをテストするために利用されます。これにより、開発者は、実際のユーザーが遭遇する可能性のある様々なシナリオをシミュレーションし、システムの潜在的な問題を早期に発見し、修正することができます。
製品の核心機能
· 多様な質問生成機能: RAGシステムが遭遇する可能性のある、事実に基づいた質問、推論を必要とする質問、比較を求める質問など、様々なタイプの質問を自動生成します。これにより、システムの理解力と回答生成能力の広範なテストが可能になります。
· 関連回答生成機能: 生成された質問に対し、その質問の意図に合致し、かつRAGシステムが参照するであろう外部知識を反映した、事実に基づいた正確な回答を生成します。これにより、システムの正解率や情報忠実度を評価できます。
· データバリエーション制御機能: 生成されるデータの複雑さ、抽象度、ドメイン特化度などを細かく調整できる機能です。これにより、特定の弱点を持つRAGシステムに対して、集中的なテストデータを提供し、ピンポイントでの改善を促します。
· 評価セットの構造化: 生成された質問と回答のペアを、標準的な評価フォーマット(例:JSONL)で出力します。これにより、既存の評価ツールやパイプラインとの互換性が高まり、開発ワークフローへの統合が容易になります。
製品の使用例
· 医療分野のRAGシステム評価: 新しい病気の診断支援や治療法に関する質問応答システムを開発する際、このツールを用いて、特定の疾患名、症状、治療法に関連する多様な質問と、それに対する専門的な回答を生成します。これにより、医療従事者が求める精度と信頼性を満たしているかを確認できます。
· 法務分野のRAGシステム評価: 契約書や法律条文に関する質問応答システムを構築する際に、このツールで、具体的な条文番号、契約内容、法的解釈に関する複雑な質問とその正確な回答を生成します。これにより、法的な誤解を招くリスクを低減できます。
· カスタマーサポートRAGシステムの性能向上: 製品マニュアルやFAQに基づいた顧客からの問い合わせ対応システムにおいて、このツールで、製品の機能、トラブルシューティング、利用方法に関する様々な質問と、それに対する迅速かつ的確な回答を生成します。これにより、顧客満足度を高め、サポート担当者の負担を軽減できます。
58
CodeMode: LLMコード実行インターフェース
著者
juanviera23
説明
CodeModeは、大規模言語モデル(LLM)が複数のツール連携よりも、少量のコードを生成することに優れているという洞察に基づいたライブラリです。LLMに多数のツールを指示する代わりに、TypeScriptサンドボックスにアクセスできる単一のインターフェースを提供します。LLMがスクリプトを生成し、それが一度実行されるだけで完了するため、トークン使用量を大幅に削減し、実行の失敗や再試行をなくします。ローカルモデルでもより信頼性の高い動作を実現します。
人気
ポイント 2
コメント 0
この製品は何ですか?
CodeModeは、LLMの能力を最大限に引き出すための新しいアプローチを提供するライブラリです。従来のLLMエージェントは、様々な外部ツール(API呼び出しなど)を連携させるのが得意ではありませんでした。しかし、CodeModeでは、LLMが直接TypeScriptコードを生成し、そのコードが安全なサンドボックス環境で実行されます。これにより、LLMは複雑な指示を一度のコード生成で完了させることができ、トークン使用量の削減、実行の安定性向上、そしてローカルLLMでも高度なタスクを実行可能にするという革新的な価値を提供します。
どのように使用しますか?
開発者はCodeModeをライブラリとしてプロジェクトに導入し、LLMに実行させたいタスクを記述します。LLMは、提供されたTypeScriptサンドボックスのインターフェースを使用して、そのタスクを完了するためのコードを生成します。生成されたコードはCodeModeの実行環境で安全に実行され、結果がLLMに返されます。このアプローチは、PythonやJavaScriptなどの既存の開発ワークフローに容易に統合でき、LLMによる自動化の新たな可能性を切り開きます。
製品の核心機能
· LLMによるTypeScriptコード生成: LLMが複雑なタスクを達成するための実行可能なコードを生成する機能。これにより、LLMの創造性を直接コードに変換できます。
· 安全なTypeScriptサンドボックス実行: 生成されたコードを隔離された環境で実行する機能。これにより、潜在的なセキュリティリスクを最小限に抑えつつ、LLMのコード実行能力を活用できます。
· 効率的なトークン管理: 複数ステップのツール連携ではなく、単一のコード実行でタスクを完了させるため、LLMへの指示に必要なトークン数を大幅に削減します。
· 実行の信頼性向上: LLMが直接コードを生成し、それが一度で実行されるため、従来の複数ステップのツール連携で発生しがちな、指示のずれや再試行の必要性がなくなります。
· ローカルLLMの能力拡張: Llama 3.1 8BやPhi-3のようなローカルで動作するLLMでも、CodeModeを介してより複雑で信頼性の高いタスクを実行できるようになります。
製品の使用例
· データ分析パイプラインの自動生成: 開発者は、あるデータセットから特定の分析(例:平均値の計算、グラフの生成)を行いたいとLLMに指示するだけで、CodeModeがそれを実現するTypeScriptコードを生成し、実行します。これにより、分析コードの記述にかかる時間を短縮できます。
· API統合の簡易化: 外部APIからデータを取得し、それを処理してから別のAPIに送信するようなタスクをLLMに任せます。CodeModeは、この一連の操作を行うTypeScriptコードを生成し、開発者はAPIキーなどの設定のみを行うだけで、複雑なAPI連携を自動化できます。
· プロトタイピングの高速化: 新しいアイデアの検証のために、迅速に機能するコードが必要な場合、LLMに概要を伝え、CodeModeでコードを生成・実行させます。これにより、開発者はアイデアの実現可能性を素早く確認できます。
· カスタムツールの動的生成: 特定のジョブを実行するために、その都度カスタムツールを作成する必要がある場合、LLMに要件を伝え、CodeModeでその都度実行可能なTypeScriptコードを生成させることができます。これにより、柔軟でオンデマンドなツール作成が可能になります。
59
インスタ保存投稿エクスポートツール
url
著者
qwikhost
説明
このプロジェクトは、Instagramに保存した写真や動画をワンクリックで簡単にダウンロードできるツールです。IGの「保存済み」機能を活用し、ユーザーが後で見返したいコンテンツを効率的に管理・バックアップできるようにします。技術的には、InstagramのAPIを直接利用するのではなく、ブラウザの自動操作(いわゆる「スクレイピング」に類する手法)を用いて、保存済み投稿にアクセスし、メディアファイルを抽出するという、クリエイティブなアプローチを採用しています。
人気
ポイント 1
コメント 1
この製品は何ですか?
これは、Instagramに「いいね」した投稿とは別に、後で見返したい、または保存しておきたいと思った写真や動画を、まとめてダウンロードするためのツールです。通常、Instagramでは個別にダウンロードする機能しか提供されていませんが、このツールは、あなたが「保存済み」リストに入れた全ての投稿(写真や動画)にプログラム的にアクセスし、それらをあなたのデバイスにダウンロードできるようにします。技術的な面白さは、Instagramが公式に提供していない機能(保存済み投稿の一括ダウンロード)を、直接的なAPI連携ではなく、ブラウザの挙動を模倣することで実現している点にあります。これは、開発者が限られたツールの中で、創造的な方法で問題を解決する「ハッカースピリット」の典型例と言えるでしょう。これによって、あなたの大切なInstagramの思い出を失うリスクを減らし、オフラインでも自由に閲覧できるようになります。
どのように使用しますか?
開発者は、このツールをブラウザ拡張機能やデスクトップアプリケーションとして利用できます。利用方法は非常にシンプルで、Instagramにログインした状態でツールを実行すると、保存済みの投稿リストが表示され、ダウンロードボタンをクリックするだけで、写真や動画がまとめてローカルストレージに保存されます。技術的には、Webブラウザの自動化ライブラリ(例:Seleniumのようなもの)を用いて、Instagramのウェブサイト上で「保存済み」タブを開き、各投稿のメディアURLを取得し、ダウンロード処理を実行するという流れになります。これは、既存のWebサービスを拡張し、より便利な機能を追加する良い例となります。例えば、Instagramのコンテンツを個人的なアーカイブとして保持したい場合や、後で編集・共有したい場合に役立ちます。
製品の核心機能
· 保存済みInstagram投稿の全件取得:Instagramの「保存済み」セクションにアクセスし、ユーザーが保存した全ての投稿(写真、動画)のリストをプログラムで取得します。これにより、後で見返したいコンテンツを網羅的に把握できます。
· メディアファイルの一括ダウンロード:取得した投稿リストから、各写真や動画のメディアファイルを直接ダウンロードします。これにより、個別に保存する手間が省け、大量のコンテンツも効率的にバックアップできます。
· シンプルで直感的なユーザーインターフェース:技術的な知識がないユーザーでも簡単に操作できるよう、分かりやすいインターフェースを提供します。ワンクリックでダウンロードが完了するため、誰でもすぐに利用できます。
· クロスプラットフォーム対応(想定):ブラウザ拡張機能やスタンドアローンアプリとして開発することで、様々なOSや環境で利用可能にし、より多くのユーザーに利便性を提供します。
製品の使用例
· Instagramの旅行写真やレシピをオフラインで保存したい:旅行中に「いいね」や「保存」した現地の風景写真や、後で作りたいレシピの投稿を、まとめてダウンロードしてオフラインでいつでも見返せるようにします。これにより、インターネット接続がない場所でも過去の思い出やインスピレーションにアクセスできます。
· クリエイターが自身のInstagramコンテンツをアーカイブしたい:アーティストやインフルエンサーが、自身の過去の投稿やインスピレーション源となった他ユーザーの投稿を、後々の参考やポートフォリオとして保存しておきたい場合に活用できます。これにより、プラットフォームの変更やアカウント削除のリスクに備え、自身のデジタル資産を保護できます。
· SNSマーケティング担当者が競合分析やインサイト収集を効率化したい:マーケティング担当者が、業界のトレンドや競合他社の成功事例として保存した投稿を、分析のために一括でダウンロードし、レポート作成などに活用できます。これにより、情報収集と分析の時間を大幅に短縮できます。
60
Gumpbox - AIコマンドサーバーブリッジ
著者
trou3
説明
Gumpboxは、AIエージェント(ChatGPTやClaudeなど)をLinuxサーバーに安全に接続するmacOSネイティブアプリです。このアプリを使うと、サーバーへのコマンド入力が不要になり、AIとの会話を通じてアプリケーションのデプロイ、サービスの再起動、サーバーの状態確認などが可能になります。AIはGumpboxのローカルMCP(Model Context Protocol)サーバーを介してこれらの操作を実行するため、機密情報がローカルマシンから漏れる心配がなく、安全にAIの力を活用できます。
人気
ポイント 1
コメント 0
この製品は何ですか?
Gumpboxは、AIアシスタントがあなたのLinuxサーバー上で直接作業できるようにする画期的なmacOSアプリケーションです。従来のコマンドライン操作の代わりに、ChatGPTやClaudeなどのAIに「最新のビルドを本番環境にデプロイして」といった自然言語で指示するだけで、AIがGumpboxのMCPサーバーを通じてサーバーに接続し、その指示を実行します。このMCPサーバーはあなたのMac上でローカルに動作するため、サーバーの認証情報などの機密情報が外部に送信されることはなく、プライバシーが保護されます。さらに、systemd-runという仕組みを使ってAIの操作を安全な環境で実行するため、意図しないシステムへの影響を防ぎます。つまり、AIにサーバー管理を任せることで、開発者はより創造的な作業に集中できるようになります。
どのように使用しますか?
開発者は、まずGumpboxアプリをmacOSにインストールします。次に、接続したいLinuxサーバーのSSH認証情報(ユーザー名、IPアドレス、鍵ファイルなど)をGumpboxに安全に設定します。Gumpboxはこれらの情報を使って、ローカルにMCPサーバーを起動します。その後、ChatGPTやClaudeなどのAIインターフェースを開き、Gumpboxと連携するように設定(通常はAPIキーや特定のプロンプト設定など)した上で、自然言語でサーバーへの指示を与えます。例えば、「APIサービスを再起動して、ログを確認して」とAIに伝えると、Gumpboxがその指示を解釈し、SSH経由でLinuxサーバーにコマンドを実行してくれます。これは、あたかもAIがあなたの専属システム管理者になったような感覚で、開発ワークフローを大幅に効率化します。
製品の核心機能
· AIエージェントとの会話によるサーバー操作:AIに自然言語で指示するだけで、アプリケーションのデプロイ、サービスの再起動、ログの確認などが実行できます。これにより、コマンドライン操作の学習コストが削減され、作業効率が向上します。
· ローカルMCPサーバーによる安全な接続:AIとの通信をあなたのMac上で完結させるMCPサーバーを内蔵しています。これにより、サーバーの認証情報や機密データが外部に送信されるリスクが最小限に抑えられ、プライバシーが保護されます。
· サンドボックス化された安全なAI操作:systemd-runを利用して、AIが実行するコマンドを隔離された安全な環境で行います。これにより、AIの誤操作や意図しないシステムへの影響を防ぎ、サーバーの安定性を保ちます。
· プライバシー重視の設計:すべての認証情報はローカルマシンに留まり、外部のAIモデルに直接送信されません。これにより、機密性の高い開発環境でも安心してAIを活用できます。
· macOSネイティブアプリ:macOSに最適化された設計で、シームレスなユーザーエクスペリエンスを提供します。既存のmacOS環境に容易に統合でき、直感的な操作が可能です。
製品の使用例
· 開発者が新しいWebアプリケーションのビルドを、AIに指示して自動的に本番環境へデプロイするシナリオ:開発者はコードをプッシュするだけで、AIがGumpboxを通じてビルドとデプロイを実行するため、手動での作業が不要になり、リリースサイクルが加速します。
· サーバーで発生したパフォーマンス問題をAIにデバッグさせるシナリオ:「Nginxがメモリを大量に消費しているのはなぜ?」とAIに質問すると、Gumpboxがサーバーに接続して関連ログやシステム情報を収集し、AIが原因を特定する手助けをします。これにより、問題解決までの時間が短縮されます。
· 本番環境のサービスをAIに安全に再起動・監視させるシナリオ:APIサービスに問題が発生した場合、「APIサービスを再起動して、直近10件のログを確認して」とAIに指示するだけで、Gumpboxが安全に操作を実行し、開発者は迅速に対応できます。これにより、ダウンタイムを最小限に抑えられます。
· 複数のマイクロサービスが稼働する複雑なシステムで、AIに全体の状態を把握させるシナリオ:AIに「全マイクロサービスの稼働状況をチェックして」と指示することで、Gumpboxが各サーバーに接続し、整合性の取れた情報をAIに提供します。これにより、システム全体の健康状態を俯瞰的に把握しやすくなります。
61
対話型BIエージェント「データ対話」
著者
mardel
説明
このプロジェクトは、企業が保有するデータを、専門知識のないビジネスユーザーでも直感的に理解し、活用できるようにする対話型のBI(ビジネスインテリジェンス)エージェントです。データ準備に費やす時間を削減し、静的なレポートやダッシュボードでは得られなかった、より深い洞察を即座に引き出せるようにします。データチームがいない小規模チームでも、データの価値をすぐに引き出せるように設計されています。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、企業が蓄積したデータを、まるで人間と会話するように質問し、回答を得られるAIアシスタントです。従来のBIツールでは、データアナリストが事前にレポートやダッシュボードを作成する必要がありましたが、このエージェントを使えば、ビジネスユーザー自身が「昨月の売上は?」「地域ごとの顧客の傾向は?」といった質問を投げかけるだけで、複雑なデータ分析の結果を分かりやすい形で得ることができます。単にデータを見るだけでなく、データと対話することで、隠れたビジネスチャンスや課題を自ら発見できるようになるのが革新的な点です。これにより、データ分析の民主化が実現され、より多くの人がデータに基づいた意思決定を行えるようになります。
どのように使用しますか?
開発者は、このエージェントを自社のデータ基盤に連携させることで利用できます。まず、サンプルデータセット(Jaffle Shop)で試してから、自身のデータを接続することができます。APIを通じて、既存のビジネスアプリケーションやチャットツールに組み込むことも可能です。例えば、Slackなどのビジネスチャットツールに連携すれば、チームメンバーはチャット上で直接データに関する質問ができ、リアルタイムで回答を得ることができます。これにより、データ分析のためにわざわざBIツールを開く手間が省け、業務効率が向上します。
製品の核心機能
· 自然言語でのデータ質問機能: ユーザーが日常的な言葉で質問すると、AIがそれを理解して必要なデータを抽出し、分かりやすく回答します。これにより、専門的なクエリ言語を学ぶ必要がなくなり、誰でもデータにアクセスできるようになります。
· インタラクティブなデータ探索: 回答を得た後、さらに深掘りした質問や関連する質問を続けることができます。これにより、ユーザーはデータの中を自由に探索し、予期せぬ洞察を発見する機会を得られます。
· 動的なインサイト生成: 過去のデータだけでなく、将来のトレンド予測や異常値の検出など、より高度な分析結果を生成します。これにより、プロアクティブなビジネス戦略の立案が可能になります。
· データ準備の効率化: データアナリストが手作業で行っていたデータの前処理や整理作業を、エージェントがある程度自動化します。これにより、アナリストはより戦略的な分析業務に集中できるようになり、データチーム全体の生産性が向上します。
· ノーコード/ローコードでの利用: コードを書かずに、直感的なインターフェースでエージェントを設定・利用できます。これにより、ITスキルが限られているユーザーでも、データの活用をすぐに開始できます。
製品の使用例
· 営業チームが、特定の製品の過去数ヶ月の売上トレンドについて質問し、AIがグラフと共に出力。これにより、次のキャンペーン戦略の立案に役立てる。
· マーケティング担当者が、特定の地域における顧客の興味関心について尋ね、AIが関連性の高いキーワードとボリュームを提示。これにより、ターゲット広告の最適化に活用する。
· カスタマーサポートチームが、最近の顧客からの問い合わせ傾向について質問し、AIが主要な問題点をリストアップ。これにより、FAQの更新やサポート体制の改善に繋げる。
· 小規模なEコマース企業が、データアナリストを雇う余裕がないため、このエージェントを導入。在庫管理や売上予測を自身で行えるようになり、事業成長を加速させる。
· 製品開発者が、ユーザーの利用状況に関するデータを分析し、どの機能が最も人気があるかを把握。これにより、次期製品開発の優先順位付けに役立てる。
62
macOSコンテナ管理ネイティブアプリ「Crane」
著者
glsorre
説明
macOS上でDockerコンテナを直感的に管理できるネイティブアプリケーションです。手軽なGUI操作でコンテナの起動、停止、削除、ログ確認などが行えるため、開発者は複雑なコマンドライン操作から解放され、より本質的な開発業務に集中できます。技術的な側面では、macOSのネイティブAPIを活用し、Docker Desktopのような仮想環境に依存しない、軽量かつ高速な操作感を実現している点が革新的です。これにより、macOSユーザーはこれまで以上にスムーズにコンテナ開発環境を構築・運用できます。
人気
ポイント 1
コメント 0
この製品は何ですか?
Craneは、macOS専用のネイティブアプリケーションとして開発された、Dockerコンテナ管理ツールです。従来のコマンドラインインターフェース(CLI)で行っていたコンテナ操作(例:docker run, docker stop, docker ps)を、分かりやすいグラフィカルユーザーインターフェース(GUI)で実行できるようにします。技術的な核心は、macOSのネイティブフレームワーク(Cocoaなど)を直接利用している点にあります。これにより、Docker Desktopが内部で利用する仮想マシン(VM)を介することなく、macOS上で直接Dockerデーモンと通信してコンテナを操作できます。これは、リソース消費の削減、起動時間の短縮、そしてよりスムーズなユーザーエクスペリエンスに繋がります。つまり、macOSでのコンテナ開発体験を格段に向上させるための、軽量で高速なネイティブソリューションと言えます。
どのように使用しますか?
開発者は、macOSにCraneアプリケーションをインストールし、起動するだけで利用を開始できます。アプリケーションを開くと、現在実行中および停止中のDockerコンテナが一覧表示され、各コンテナに対してGUI上で直接操作が可能です。例えば、コンテナ一覧から目的のコンテナを選択し、ボタン一つで起動・停止・削除が行えます。また、コンテナのログをリアルタイムで確認したり、ポートマッピングの設定を視覚的に管理したりすることもできます。CLIコマンドを覚える必要がなく、直感的な操作でコンテナライフサイクル全体を管理できるため、特にDocker初心者や、GUIでの管理を好む開発者にとって非常に便利なツールです。既存のDocker環境ともシームレスに連携するため、導入の手間はほとんどありません。
製品の核心機能
· コンテナ一覧表示とステータス確認:実行中、停止中、一時停止中のコンテナを視覚的に把握できます。これにより、開発中のどのコンテナがアクティブか、あるいは停止しているかを一目で理解でき、管理ミスを防ぎます。
· コンテナの開始・停止・再起動・削除:GUI上のボタン操作で、コンテナのライフサイクルを容易に管理できます。複雑なコマンドを覚える必要がなく、迅速なコンテナ操作が可能になり、開発ワークフローの効率が向上します。
· コンテナログのリアルタイム表示:コンテナから出力されるログを、アプリケーション内でリアルタイムに確認できます。デバッグ作業において、問題箇所を特定するのに役立ち、開発サイクルの高速化に貢献します。
· ポートマッピングの管理:コンテナが公開しているポートとホストマシン上のポートのマッピング設定をGUIで確認・編集できます。外部からのアクセス設定が容易になり、Webアプリケーションなどの開発・テストがスムーズになります。
· イメージ管理機能(将来的な拡張性):コンテナの元となるDockerイメージの管理機能も追加される可能性があります。これにより、イメージのダウンロード、削除、一覧表示などがGUIで行えるようになり、画像管理の手間が軽減されます。
製品の使用例
· Web開発者がローカル環境で複数のマイクロサービスをDockerコンテナとして実行している場合:Craneを使用すると、各サービスのコンテナを個別に、あるいはまとめて迅速に起動・停止・再起動でき、開発環境のセットアップや切り替え時間が大幅に短縮されます。これにより、開発者はコード記述により多くの時間を割けます。
· Docker初心者でCLIコマンドに不慣れな開発者が、開発環境としてDockerを利用したい場合:Craneの直感的なGUI操作により、コマンドを覚えることなくコンテナの基本的な操作を習得できます。これにより、Dockerの学習コストが低下し、より早く開発に着手できるようになります。
· macOS上で頻繁にコンテナをビルド・テストする機会のある開発者:Craneはネイティブアプリであるため、Docker Desktopのような仮想環境を介さず、より高速でリソース消費の少ないコンテナ操作が可能です。これにより、開発者のPCのパフォーマンスを維持しながら、効率的なコンテナ開発が可能になります。
· CI/CDパイプラインのローカルテストで、コンテナの状態を迅速に確認・リセットしたい場合:CraneのGUIでコンテナのログ確認や状態リセットが素早く行えるため、テストのデバッグや再実行が容易になります。これにより、開発者は迅速にフィードバックを得て、問題解決に集中できます。
63
ホーム画面アファメーションウィジェット (Home Screen Affirmation Widget)
著者
vasanthps
説明
iPhone, iPad, Macのホーム画面にポジティブなアファメーション(肯定的な自己暗示)を表示するアプリ。競合よりも質の高いアファメーションを厳選し、集中を妨げない美しいインターフェースで提供。日々の生活にポジティブな思考を取り入れることを目指します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、デバイスのホーム画面に、毎日のモチベーションを高めるためのアファメーション(肯定的な自己暗示の言葉)をリアルタイムで表示するアプリです。技術的な側面としては、iOS/macOSのウィジェット機能を活用し、バックグラウンドでアファメーションを更新・表示しています。これにより、ユーザーはアプリを開くことなく、日常的にポジティブなメッセージに触れることができます。競合アプリと比較して、アファメーションの質と、広告や不要な要素のない洗練されたデザインに注力している点が革新的です。つまり、あなたのスマホやタブレットが、いつもあなたを励ましてくれる、ポジティブなパートナーになるということです。
どのように使用しますか?
開発者は、iOS/macOSのウィジェット機能を利用して、このアファメーション表示機能を自身のアプリやサービスに組み込むことができます。例えば、フィットネスアプリであれば、毎日の目標達成を励ますアファメーションを、瞑想アプリであれば、内面の平和を促すアファメーションを表示させるといった使い方が考えられます。SwiftUIといったモダンなUIフレームワークを使用することで、比較的容易に統合可能です。なので、あなたのアプリに、ユーザーのエンゲージメントを高めるための、さりげないポジティブな要素を追加したい場合に役立ちます。
製品の核心機能
· ホーム画面ウィジェット表示:iOS/macOSのホーム画面に、設定されたアファメーションを定期的に表示します。これにより、ユーザーは常にポジティブなメッセージに触れることができ、日常の気分転換につながります。
· 高品質アファメーションキュレーション:厳選された、質が高く、多様なテーマ(自己肯定、目標達成、感謝など)のアファメーションを提供します。これにより、ユーザーはより効果的な自己啓発を実感でき、精神的な成長をサポートします。
· 集中を妨げないデザイン:広告や複雑なUIを排除し、シンプルで美しいインターフェースを提供します。これにより、ユーザーはアファメーションに集中でき、リラックスした状態でポジティブなメッセージを受け取ることができます。
· クロスプラットフォーム対応(iPhone, iPad, Mac):Appleデバイス間でシームレスに利用できます。これにより、ユーザーはどのデバイスからでも、一貫したポジティブな体験を得ることができます。
製品の使用例
· フィットネスアプリへの統合:毎日のワークアウト目標達成を促すアファメーションをホーム画面に表示し、ユーザーのモチベーションを維持・向上させる。これにより、ユーザーは運動を継続しやすくなります。
· 瞑想・マインドフルネスアプリへの統合:日々のストレス軽減や心の平穏を促すアファメーションをウィジェットに表示し、ユーザーがいつでもマインドフルネスの状態を意識できるようにする。これにより、ユーザーはより穏やかな日々を送れるようになります。
· 生産性向上ツールへの統合:集中力を高める、タスク完了を促すといったアファメーションをホーム画面に表示し、ユーザーが効率的に作業を進められるようにサポートする。これにより、ユーザーは仕事や学習のパフォーマンスを向上させることができます。
· 健康管理アプリへの統合:健康的な生活習慣を促すアファメーション(例:「私は健康的な食事を選びます」)を表示し、ユーザーの健康意識を高める。これにより、ユーザーはより健康的なライフスタイルを実践できるようになります。
64
茶色か沼か?画像認識チャレンジ
著者
fragkakis
説明
このプロジェクトは、抹茶の画像と沼の画像を区別するための画像認識モデルです。人間が見ても紛らわしい「抹茶の色合い」と「沼の色合い」を、機械学習を用いて識別するという、ユニークな問題設定に挑戦しています。技術的には、画像の特徴を学習するニューラルネットワーク(特に畳み込みニューラルネットワーク、CNN)の応用が中心となります。これにより、見た目が似ているが本質的に異なるものを識別する技術の可能性を示しています。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、抹茶と沼の画像をAIが識別するシステムです。人間でも間違えやすい、緑色の濃淡や質感の違いを、AIはどのように学習し、区別するのか。その技術的な核心は、画像から特徴的なパターン(線の太さ、色のムラ、粒子の細かさなど)を自動で抽出し、それらを比較する「畳み込みニューラルネットワーク(CNN)」という仕組みにあります。この技術は、単に色を判断するだけでなく、画像が持つ微妙なテクスチャや形状の特徴を捉える能力に長けています。なので、AIがどうやって「それっぽい」ものを区別するのか、その高度な画像認識の仕組みを体験できるのがこのプロジェクトの革新的な点です。
どのように使用しますか?
開発者は、このプロジェクトのコードを参考に、独自の画像認識モデルを構築する際のアイデアを得ることができます。例えば、類似した色や質感を持つ他の物体(例:アボカドと抹茶、泥水とコーヒーなど)を識別したい場合、このプロジェクトで使われている学習データの前処理方法や、CNNモデルのアーキテクチャ(層の構成など)を応用できます。GitHubで公開されているコードをローカル環境で実行したり、改変して独自のデータセットで学習させたりすることで、画像認識技術の実践的な応用を試すことができます。つまり、あなたもAIに「これが何なのか」を教えるための、基本的なノウハウを学ぶことができるのです。
製品の核心機能
· 抹茶と沼の画像を自動で識別する機能:画像の特徴を学習したAIモデルが、入力された画像が抹茶か沼かを高い精度で分類します。これは、外観が似ているものを識別する技術の応用であり、製品の品質管理やコンテンツの自動分類などに役立ちます。
· 特徴抽出とパターン認識のデモンストレーション:AIが画像の中から、抹茶や沼を識別するために重要となる特徴(色合い、テクスチャ、粒度など)をどのように捉えているかを示します。これにより、複雑な画像データから意味のある情報を抽出する技術の理解を深めることができます。これは、医療画像診断や、不良品の検出など、微細な違いを見分ける必要がある分野で応用可能です。
· 機械学習モデルの構築と評価の例示:画像認識モデルをどのように設計し、訓練し、評価するのかという一連のプロセスを具体的に示します。これは、これから機械学習を学び始める開発者にとって、実践的な学習リソースとなります。これにより、あなたもAI開発の第一歩を踏み出すための具体的な手順を学ぶことができます。
製品の使用例
· 食品業界での品質管理:例えば、抹茶パウダーの品質を、色や粒度の微妙な違いで自動的に検査するシステムに応用できます。このプロジェクトの技術を使えば、人間が見逃しがちなわずかな品質のばらつきをAIが検出し、不良品を早期に発見できます。
· コンテンツモデレーション:SNSなどで投稿された画像が、不適切または誤解を招く可能性のあるコンテンツ(例:過度に茶色く変色した食品画像が、汚いものとして扱われるなど)であるかを自動で判定するシステムに利用できます。これにより、プラットフォームの健全性を保つための効率的なコンテンツ管理が可能になります。
· 教育・エンターテイメント分野:子供向けの教育アプリで、身の回りの物(例:草、葉っぱ、泥)と、それらに似た別のものを区別して学ぶためのゲームに組み込むことができます。このプロジェクトの技術は、視覚的な学習体験を豊かにし、子供たちの知的好奇心を刺激します。
65
英単語学習エンジン「Phrase Weaver」
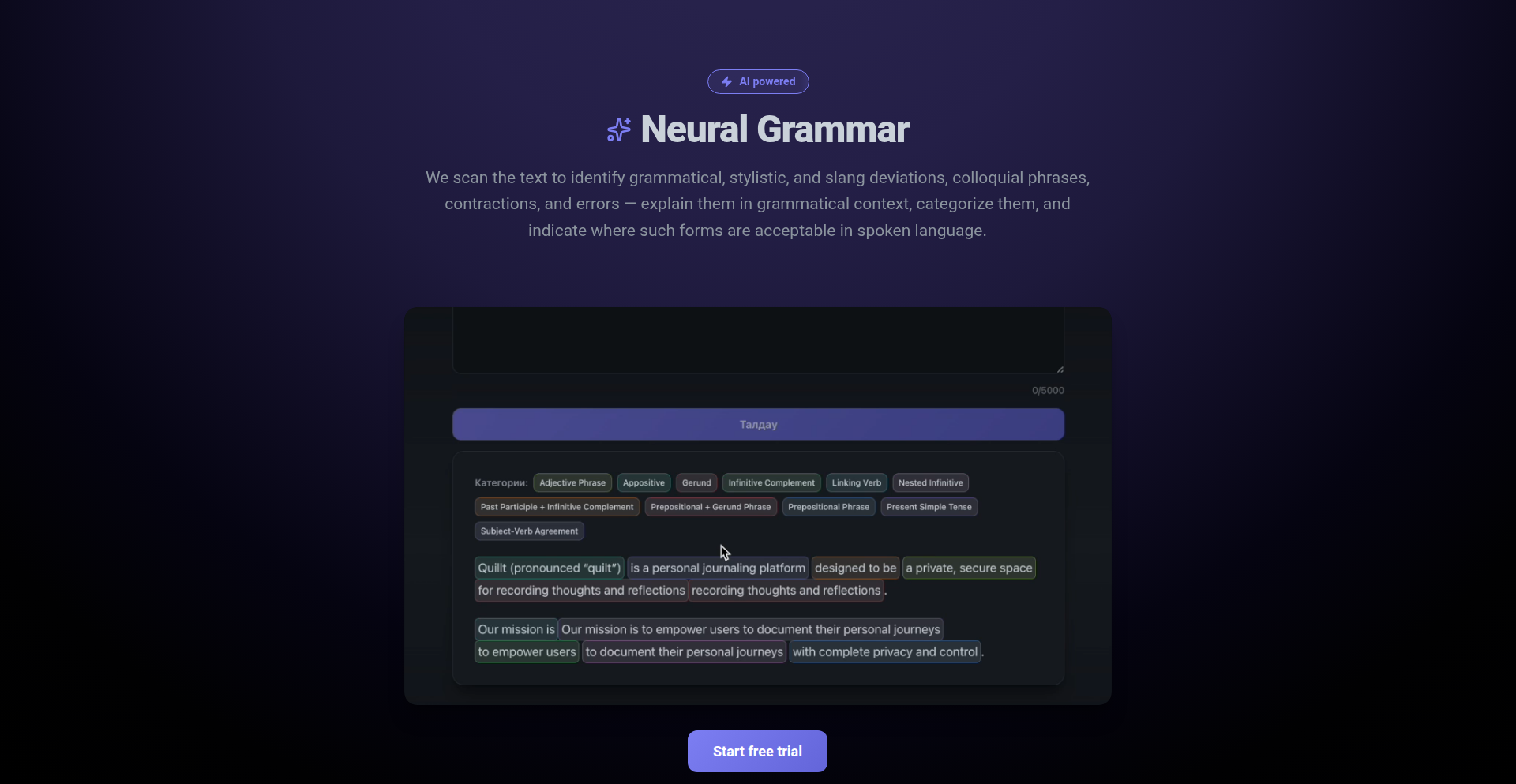
著者
baursha
説明
これは、英語学習者が単語だけでなく、文脈の中で単語がどのように使われるかを理解するのを助けるためのツールです。革新的な点は、自然言語処理(NLP)技術を活用して、ユーザーが興味のあるトピックや読んでいる記事から、関連性の高い単語とその使用例を自動的に抽出し、提示することです。これにより、単なる暗記ではなく、実用的で記憶に残りやすい学習体験を提供します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、AIがあなたの読書や興味に基づいて、新しい英単語とそれを自然な文脈で使う方法を学習するのを助けるツールです。普通の英単語学習アプリは単語リストを提示するだけですが、このツールは、あなたが読んでいるニュース記事や興味のある分野から、関連性の高い単語と、それが実際の会話や文章でどのように使われているかの例文を自動的に見つけ出してくれます。例えば、あなたがSF小説を読んでいるなら、その小説によく出てくるSF関連の専門用語や表現をピックアップし、その単語がどのように使われているか具体的な文章で示します。これは、単語の意味を覚えるだけでなく、その単語がどんな状況で、どのように使われるのかを理解するのに役立ちます。つまり、より自然で実践的な英語が身につくようになります。
どのように使用しますか?
開発者は、このツールをAPIとして、またはライブラリとして自分のアプリケーションに組み込むことができます。例えば、語学学習アプリ、読書支援ツール、またはコンテンツパーソナライゼーションシステムなどに統合できます。ユーザーが特定の記事のURLを提供したり、興味のあるキーワードを入力したりすると、Phrase Weaverはその入力に基づいて、関連する英単語とその使用例のリストを生成します。このリストは、アプリのUIに表示したり、プッシュ通知で送信したり、学習コンテンツの一部として利用したりすることが可能です。APIを使えば、複雑なNLP処理を自分で行う必要がなく、迅速に高度な英語学習機能を追加できます。
製品の核心機能
· 文脈に基づく単語抽出:ユーザーが指定したテキスト(記事、URLなど)から、その文脈で重要と思われる英単語をAIが自動的に抽出します。これにより、学習者は「なぜこの単語が重要なのか」を理解しやすくなり、学習のモチベーションが向上します。
· リアルな例文生成:抽出された単語について、その単語が実際にどのように使われているかを示す、自然で実践的な例文を生成します。これにより、単語のニュアンスや使い分けを肌で感じることができ、より正確な英語表現を習得できます。
· トピック連動学習:ユーザーの興味のあるトピックや読んでいるコンテンツに合わせて、単語リストをカスタマイズします。これにより、学習者は自分にとって意味のある単語を優先的に学習でき、学習効率が大幅に向上します。
· NLP技術による高度な分析:形態素解析、品詞タグ付け、固有表現抽出などの自然言語処理技術を駆使して、単語の重要度や文脈における役割を分析します。これにより、単なるキーワード検索では得られない、深い言語理解に基づいた学習体験を提供します。
製品の使用例
· 教育系アプリ:語学学習アプリに組み込み、ユーザーが読んでいるニュース記事や教材から、難易度や重要度に応じて単語を抽出し、学習コンテンツとして提供します。これにより、受動的な学習から能動的な学習への転換を促進し、学習効果を高めます。
· コンテンツプラットフォーム:オンライン読書プラットフォームやニュースサイトに統合し、ユーザーが閲覧中の記事に含まれる未知の英単語をハイライト表示し、クリックするとその単語の文脈に沿った説明と例文を表示します。これにより、読書体験を損なわずに、自然な形での語彙力強化を支援します。
· 開発者向けライブラリ:プログラミング学習者が英語のドキュメントやチュートリアルを読む際に、専門用語や理解しにくい単語をリアルタイムで解説し、コード例における使われ方を示すツールを開発します。これにより、技術文書の理解を助け、学習の障壁を低減します。
· パーソナライズド学習アシスタント:AIアシスタントに組み込み、ユーザーが日常会話で使った単語や、興味のある分野の最新情報から、語彙の定着を促すための単語と例文を定期的に提案します。これにより、個別最適化された継続的な学習習慣をサポートします。
66
プラグインスコアアナライザー (PluginScore Analyzer)
著者
blurayfin
説明
WordPressプラグインのコード品質を瞬時に把握し、スコアの背後にある問題を深く掘り下げるためのツールです。セキュリティ、パフォーマンス、リポジトリポリシー、コーディング標準といった多角的な観点から、プラグインのスラッグを入力するだけで詳細なレポートを提供します。これは、開発者がコードの健全性を迅速に評価し、改善点を見つけるのに役立つ、まさに「コードで問題を解決する」というハッカー精神の現れです。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、WordPressプラグインのコード品質を自動的に分析し、総合スコアと詳細なレポートを提供するウェブアプリケーションです。WordPress.orgから任意のプラグインのスラッグ(例: akismet, woocommerce)を入力すると、セキュリティ、パフォーマンス、プラグインリポジトリのポリシー、一般的なコーディング標準などのカテゴリー別に、エラーや警告の数、および個々の問題点をリストアップします。内部では、公式のPlugin Check(wp plugin check経由)とWordPress標準に準拠したPHP_CodeSniffer、そしてリポジトリ要件やパフォーマンスに関する追加チェックを組み合わせています。このスコアはあくまで傾向を示すもので、絶対的なセキュリティ保証ではありません。このツールの革新性は、複雑なコードベースの品質評価を、専門知識がなくても一目で理解できる形に抽象化し、開発者が迅速に改善の方向性を見いだせるようにした点にあります。
どのように使用しますか?
開発者は、PluginScore.comのウェブサイトにアクセスし、ホームページにある「Analyze a plugin」ボックスに分析したいWordPressプラグインのスラッグを入力するだけで利用できます。例えば、自分で開発したプラグインのスラッグや、人気のプラグインのスラッグを入力して、そのコード品質を評価できます。レポートは即座に表示されるか、新しいスキャンがキューに追加されます。各プラグインのページでは、全体スコア(0〜100)、カテゴリー別の内訳、具体的な問題点とその深刻度、ルールドキュメントへのリンクを確認できます。さらに、スキャン履歴やスコアの推移、リーダーボード、注目のプラグインの増減といった情報も提供され、開発者は自身のプラグインの進捗状況を追跡したり、他のプラグインと比較したりすることができます。これは、CI/CDパイプラインに組み込むことで、コード変更のたびに自動的に品質チェックを実行し、品質低下を早期に検知するシナリオでも活用できます。
製品の核心機能
· プラグインコード全体のスキャンと品質スコア生成: WordPressプラグインのコードを包括的に分析し、0から100のスコアを生成することで、コードの健全性を直感的に把握できるようにします。これは、開発者がプロジェクトの全体的な品質レベルを迅速に理解するのに役立ちます。
· カテゴリー別品質内訳表示: セキュリティ、パフォーマンス、リポジトリポリシー、コーディング標準などの主要カテゴリーに分けて品質を評価し、それぞれのスコアと問題点を明示します。これにより、開発者はどの領域に焦点を当てて改善すべきかを具体的に特定できます。
· 詳細な問題点リストと解説: 各スキャンで見つかった個々のエラーや警告について、コード、深刻度、関連するルールドキュメントへのリンクを提供します。開発者は、具体的なコードの問題点とその解決策への導線を素早く得ることができます。
· スキャン履歴とスコア推移の追跡: 時間の経過とともにプラグインのコード品質がどのように変化しているかを追跡できる機能です。開発者は、継続的な改善の効果を確認したり、予期せぬ品質低下の原因を特定したりすることができます。
· リーダーボードとトレンド分析: 他のプラグインと比較して、コード品質のランキングや改善・後退のトレンドを確認できます。これは、開発者が業界標準や競合他社の状況を理解し、自身のプラグインをより良くするためのモチベーションやインスピレーションを得るのに役立ちます。
製品の使用例
· 新規WordPressプラグイン開発中の品質チェック: 開発者は、プラグインを公開する前にPluginScoreを使用してコード品質を評価し、セキュリティ脆弱性やパフォーマンスのボトルネック、コーディング標準違反などを早期に発見・修正できます。これにより、より堅牢で高品質なプラグインをリリースできます。
· 既存WordPressプラグインのメンテナンスと改善: 既存のプラグインを運用している開発者やチームが、定期的にPluginScoreでコード品質をチェックし、経年劣化や新たな問題の発生を監視します。スコアの推移を追跡することで、継続的な改善活動の効果を可視化し、品質維持に貢献します。
· サードパーティ製WordPressプラグインの選定支援: WordPressサイトの管理者や開発者が、導入を検討しているサードパーティ製プラグインのコード品質をPluginScoreで事前に評価します。これにより、セキュリティリスクやパフォーマンスへの影響が少ない、信頼性の高いプラグインを選択する際の判断材料となります。
· プラグイン開発チーム内の品質基準の統一: チームで複数のプラグインを開発している場合、PluginScoreのレポートを共有することで、チーム全体でコード品質に対する共通認識を持ち、コーディング標準の遵守を徹底できます。これにより、コードの一貫性と保守性が向上します。
67
単語の魔法使い:書くことを磨くAI
著者
GrammarChecker
説明
これは、文章の誤りを単純なツールで修正するためのHacker NewsのShow HNプロジェクトです。AI技術を駆使して、文法、スペル、句読点の誤りを検出し、より明確で効果的な文章作成を支援します。AIによる自然言語処理(NLP)の力を、日常的なライティングタスクに活用する点が革新的です。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、AI(人工知能)を使って文章の誤りを自動で見つけて直してくれるツールです。AIが文章の構造や単語の意味を理解し、文法の間違い、スペルミス、不自然な表現などを指摘してくれます。まるで、あなたの文章を一位の校閲者がチェックしてくれるようなものです。これにより、複雑な自然言語処理(NLP)の技術が、誰でも簡単に使えるようになり、文章作成の質を格段に向上させることができます。だから、これを使うと、あなたの文章がよりプロフェッショナルで分かりやすくなります。
どのように使用しますか?
開発者は、このツールをAPI経由で自身のアプリケーションに組み込むことができます。例えば、ブログ作成ツール、メールクライアント、チャットアプリケーションなどに統合し、ユーザーがリアルタイムで文章校正の恩恵を受けられるようにします。また、ローカル環境でPythonスクリプトとして実行し、大量のテキストファイルを一括で校正することも可能です。だから、これを導入すると、あなたのアプリのユーザーは、より自信を持って文章を書けるようになります。
製品の核心機能
· 文法チェック:AIが文章の構造や単語の品詞を解析し、文法的に間違っている箇所を特定します。これにより、読者が理解しやすい、自然な文章を作成できます。
· スペルチェック:一般的なスペルミスだけでなく、文脈に合わない単語の誤用も検出します。これにより、文章の信頼性と正確性を向上させます。
· 句読点補正:句読点の使い方を最適化し、文章のリズムや明瞭さを改善します。これにより、読者の可読性が高まります。
· 語彙提案:より適切で多様な単語の選択肢を提案し、文章表現の豊かさを高めます。これにより、あなたの文章がより魅力的になります。
· 文脈理解:単語やフレーズが文脈の中でどのように使われているかをAIが理解し、より精度の高い校正を行います。これにより、表面的な誤りだけでなく、意味の通らない部分も修正できます。
製品の使用例
· 開発中のWebアプリケーションに組み込み、ユーザーが入力したコンテンツの品質をリアルタイムで向上させたい場合。例えば、ブログ記事投稿機能やレビュー作成機能に適用することで、ユーザー体験を向上させ、より質の高いコンテンツを生み出す支援ができます。
· 大量の顧客からのフィードバックやサポートメールを分析する前に、文章の誤りを修正し、分析の精度を高めたい場合。これにより、より正確な顧客ニーズの把握が可能になります。
· プログラミング学習者が書いたドキュメントやコードコメントの品質を向上させたい場合。正確で分かりやすいドキュメントは、学習効率を高めます。
· 自動生成されたテキストの品質を人間が読むレベルに引き上げたい場合。例えば、マーケティングコピーやレポートのドラフト作成に利用し、最終的な仕上げを効率化します。
68
ZenMoment: プライバシー重視の静的瞑想ツール
著者
951560368
説明
ZenMomentは、登録不要で、個人データを一切収集しない、ミニマルな瞑想および呼吸エクササイズアプリです。Next.js 14の静的エクスポートとCloudflare Pagesを活用し、迅速な読み込みとオフライン機能を提供します。プライバシーを最優先し、開発者と瞑想実践者の両方のニーズに応えるために構築されました。これは、複雑な機能やデータ収集にうんざりしているユーザーにとって、シンプルで集中できる瞑想体験を提供します。
人気
ポイント 1
コメント 0
この製品は何ですか?
ZenMomentは、ユーザーのプライバシーを最優先にした、ウェブベースの瞑想および呼吸エクササイズアプリです。従来の瞑想アプリとは異なり、アカウント作成や個人情報の収集は一切行いません。Next.js 14で構築され、静的にエクスポートされているため、初回読み込みが非常に速く、一度読み込めばオフラインでも使用できます。4-7-8呼吸法やタイマー機能、ダークモードなどを備え、WCAG AAAレベルのアクセシビリティにも対応しています。これは、データ追跡や過剰な機能に悩まされることなく、純粋に瞑想に集中したいと考えているユーザーのためのツールです。技術的には、クライアントサイドで動作するZustandによる状態管理、Framer Motionによるスムーズなアニメーション、Tailwind CSSによるスタイリングが採用されており、シンプルさとパフォーマンスを追求しています。
どのように使用しますか?
開発者は、Webブラウザ経由でZenMoment(zenmoment.net)にアクセスするだけで、すぐに瞑想や呼吸エクササイズを開始できます。特別なソフトウェアのインストールやアカウント登録は不要です。例えば、仕事の合間にリラックスしたいとき、寝る前に心を落ち着けたいとき、あるいは集中力を高めたいときに、数クリックで利用できます。また、静的サイトとして構築されているため、インターネット接続が不安定な環境でも、初回読み込み後はオフラインで利用可能です。開発者としては、このプロジェクトのコードベースをGitHubで参照し、プライバシー重視のウェブアプリケーション開発や、静的サイトジェネレーターの活用方法、クライアントサイドでの状態管理やアニメーションの実装方法について学ぶことができます。
製品の核心機能
· シンプルな瞑想タイマー(1/3/5/10/15分):時間管理を容易にし、集中を妨げないタイマー機能は、時間を決めて静かに瞑想したいユーザーに役立ちます。
· 4-7-8呼吸法ガイド:視覚的なガイダンス付きで、リラックス効果の高い呼吸法を実践するのに役立ち、ストレス軽減や睡眠の質の向上をサポートします。
· ダークモード:夜間や暗い環境での使用に配慮したデザインで、目の疲れを軽減し、快適な瞑想体験を提供します。
· デイリー統計トラッキング(ローカルストレージ):ユーザーの瞑想習慣を記録しますが、データはローカルデバイスにのみ保存され、プライバシーが保護されます。これは、自身の進捗を把握したいが、オンラインでのデータ共有は避けたいユーザーに最適です。
· SEO最適化されたブログ:瞑想に関する有益なコンテンツを提供し、ユーザーの知識を深め、精神的な健康への意識を高めます。これは、瞑想を始めたばかりのユーザーや、さらに学びたいと考えているユーザーにとって価値があります。
製品の使用例
· 開発者が仕事の休憩中に、数秒でアプリを開いて5分間の瞑想タイマーを開始し、集中力を回復させる。これは、登録や読み込みに時間がかかる他のアプリでは実現が難しい、即時性とシンプルさを実現した例です。
· ユーザーが就寝前に、ZenMomentの4-7-8呼吸法ガイドを利用してリラックスし、睡眠の質を向上させる。プライバシーが保護されているため、安心して利用できます。
· インターネット接続が不安定な地域にいるユーザーが、事前にZenMomentを読み込んでおき、オフライン状態で瞑想や呼吸エクササイズを行う。これは、技術的な制約がある環境でも、ウェルネスツールを利用できることを示しています。
· プライバシー意識の高い開発者が、個人データが収集されない瞑想ツールを求めてZenMomentを利用する。これは、データ収集に抵抗があるユーザーにとって、信頼できる選択肢となります。
· ウェブ開発者が、Next.js 14の静的エクスポート、Zustand、Framer Motion、Tailwind CSSといった技術スタックを参考に、自身のポートフォリオサイトやミニマルなウェブアプリケーションを構築する。
· アクセシビリティを重視する開発者が、WCAG AAA準拠のZenMomentを参考に、より多くのユーザーが利用できるウェブサイトを設計・開発する。
69
AIファーストWebBP
著者
kure256
説明
AIアシスタント(ChatGPT、Gemini、Copilotなど)が情報を取得する手段として主流になりつつある現代において、従来のSEOのようにAIが理解・インデックス・引用しやすいウェブサイト構築のための、オープンで実践的なガイドラインを提案するプロジェクトです。これは特定のフレームワークではなく、ウェブを再び機械可読にするための、最小限で進化し続けるベストプラクティスの集まりです。
人気
ポイント 1
コメント 0
この製品は何ですか?
これはAIアシスタントがウェブサイトの情報を正確に理解し、参照できるようにするための、新しい「AI向けSEO」のようなものです。従来の検索エンジン最適化(SEO)が人間が検索しやすいようにウェブサイトを調整するのに対し、AIファーストWebBPはAIがウェブコンテンツを解析し、その内容を正しく把握・引用できるようにするための、具体的な方法論やウェブサイトの構造に関する指針を提供します。これにより、AIアシスタントがあなたのウェブサイトの情報を正確に把握し、ユーザーに価値ある情報として提供できるようになります。つまり、あなたのウェブサイトがAI時代においても情報源として活用されるための、新しいルール作りと言えます。
どのように使用しますか?
開発者は、このプロジェクトで提案されているガイドラインを参照し、自身のウェブサイトのHTML構造、メタデータ、コンテンツの構成などを調整します。例えば、意味のあるHTMLタグの使用、構造化データの追加、コンテンツの明確なセクション分けなどが含まれます。これにより、AIボットがサイトをクロールする際に、コンテンツの意図や構造をより正確に理解できるようになります。具体的な技術としては、JSON-LD形式での構造化データの実装、セマンティックHTML5タグの活用、明確な見出し構造の採用などが考えられます。これは、ウェブサイトのバックエンドやフロントエンドのコードに直接影響を与えるものではなく、ウェブサイトの「設計思想」と「マークアップ」の改善に焦点を当てています。
製品の核心機能
· AIが理解しやすいHTML構造の設計:意味のあるHTMLタグ(例:`<article>`, `<nav>`, `<aside>`)を適切に使用することで、AIがコンテンツの各部分の役割を理解しやすくなります。これにより、AIはウェブサイトの全体像を把握し、関連性の高い情報を抽出しやすくなります。
· 構造化データの活用:JSON-LDなどの形式で、コンテンツの内容(記事、製品、イベントなど)に関する詳細な情報(タイトル、著者、公開日、説明など)をマークアップすることで、AIは情報をより正確かつ効率的に解析できます。これにより、AIアシスタントはユーザーの質問に対して、より具体的で的確な回答を生成できるようになります。
· 明確なコンテンツのセマンティクス:見出しタグ(`<h1>`から`<h6>`)を論理的に使用し、段落やリストなどを適切にマークアップすることで、AIはコンテンツの階層構造と重要度を理解しやすくなります。これにより、AIは情報の優先順位を判断し、ユーザーにとって最も重要な情報を提示できるようになります。
· メタデータの最適化:AIが参照する可能性のあるメタデータ(例:`description` meta tag)を、AIが理解しやすいように、より明確で簡潔に記述します。これにより、AIはウェブサイトの概要を素早く把握し、検索結果や回答生成に活用できるようになります。
製品の使用例
· AIチャットボットがブログ記事の内容を正確に要約し、引用する:開発者がAIファーストWebBPに沿ってブログ記事をマークアップした場合、ChatGPTのようなAIアシスタントが記事の内容を詳細に理解し、ユーザーからの要約リクエストに対して、正確な要約と参照元(記事URL)を提示できるようになります。これは、コンテンツ制作者にとって、自身の情報がAIによって正しく評価・拡散される機会を増やすことに繋がります。
· AIアシスタントがeコマースサイトの商品詳細を正確に抽出し、比較検討を支援する:ECサイトの運営者が商品ページに構造化データを適切に適用した場合、AIアシスタントは商品の仕様、価格、在庫状況などを正確に把握できます。これにより、ユーザーはAIに「この商品のスペックを教えて」と質問した際に、正確な情報を得られ、商品比較や購入の意思決定が容易になります。
· AIが技術ドキュメントの特定のセクションを迅速に見つけ出し、開発者の疑問に答える:開発者向けドキュメントサイトがAIファーストWebBPに準拠している場合、AIアシスタントはユーザーからの「特定APIの使い方は?」といった質問に対し、ドキュメント内の関連セクションを素早く特定し、正確な情報を提供できます。これは、開発者が問題を解決する時間を大幅に短縮し、生産性を向上させます。
70
WikiDataCleaner
著者
zeronex
説明
このプロジェクトは、フランス語版ウィキペディアの膨大な生データ(XML/Wikiテキスト形式)を、自然言語処理(NLP)や大規模言語モデル(LLM)の実験に直接利用できる、クリーンなJSON形式に変換したデータセットです。開発者が独自に構築したパイプラインにより、記事ごとに整形されたJSONファイルが約270万個生成されます。これは、生データを扱う際の煩雑さを解消し、研究や開発の初期段階を劇的に効率化することを目指しています。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、ウィキペディアの生データを、AIやデータ分析に使いやすいJSON形式に整理・変換するツール(およびその成果物であるデータセット)です。開発者は、XMLストリームを読み込み、各記事のページを抽出し、ウィキテキストや不要なマークアップを除去し、セクションを再構築し、インフォボックスを構造化されたJSONオブジェクトに解析し、カテゴリやリンクなどを抽出して、記事ごとに1つのJSONファイルとして保存します。このプロセスにより、これまで扱いにくかったウィキペディアのデータが、機械学習モデルの学習やデータ分析にすぐに使える状態になります。つまり、手間のかかるデータ整形作業をスキップして、すぐに分析や開発に着手できるのです。
どのように使用しますか?
開発者は、このプロジェクトで生成された270万件のJSONファイル(各ファイルがフランス語版ウィキペディアの記事を表す)をダウンロードして利用できます。これらのJSONファイルは、Pythonなどのプログラミング言語で簡単に読み込み、構造化されたデータとしてアクセスできます。例えば、特定のキーワードを含む記事を検索したり、記事間のリンク関係を分析したり、各記事のテキストデータを抽出してLLMの学習データとして使用したりできます。また、開発者自身が同様のパイプラインを構築し、他の言語のウィキペディアデータや、類似の構造を持つ他のデータソースに適用することも可能です。これにより、データの前処理に費やす時間を大幅に削減し、本来の研究や開発に集中できるようになります。
製品の核心機能
· XMLストリームからの記事抽出:ウィキペディアの巨大な生データ(XML)から、個々の記事データを効率的に取り出します。これにより、データ解析の対象となる情報を漏れなく、かつ迅速に特定できます。
· ウィキテキスト/マークアップ除去:記事本文に含まれる、表示用・編集用の特殊な記法(ウィキテキスト)やHTMLタグのような不要なマークアップをきれいに取り除きます。これにより、純粋な記事本文のテキストデータだけを取得でき、AIが正確に内容を理解できるようになります。
· セクション再構築:記事の各セクション(導入部、本文、参考文献など)を識別し、構造化された形で整理します。これにより、記事の論理的な構造を保ったままデータを利用でき、特定のセクションだけを分析するなどの高度な活用が可能になります。
· インフォボックスのJSONオブジェクト化:記事の概要情報がまとめられた「インフォボックス」を、キーと値のペアで構成される標準的なJSONオブジェクトに変換します。これにより、記事の基本的な属性情報(人物の生年月日、地理的位置など)をプログラムで容易に取得・利用できるようになります。
· カテゴリ・リンク抽出:記事に付与されたカテゴリ情報や、記事内からリンクされている他の記事へのリンク情報を抽出します。これにより、記事間の関連性を把握したり、特定カテゴリに属する記事群を収集したりすることが容易になります。
· 記事ごとのJSONファイル保存:最終的に、整形された記事データを、1記事につき1つのJSONファイルとして保存します。これにより、必要に応じて個別の記事データにアクセスしたり、大量のデータを並列処理したりすることが容易になり、開発効率が向上します。
製品の使用例
· 大規模言語モデル(LLM)の学習データ生成:フランス語版ウィキペディアの記事データは、LLMがフランス語の文章構造、語彙、知識を学習するための高品質なコーパスとして利用できます。これにより、より高度なフランス語対応のAIモデルを開発できます。
· 自然言語処理(NLP)タスクの研究:固有表現抽出、感情分析、トピックモデリングなどのNLPタスクにおいて、構造化されたウィキペディアデータを活用することで、より正確で意味のある分析結果を得ることが期待できます。例えば、特定の専門用語や人名を正確に識別するモデルの精度向上に貢献します。
· 学術研究におけるデータセット利用:言語学、社会科学、情報科学などの分野の研究者が、ウィキペディアの網羅的な知識ベースを分析対象として利用できます。例えば、特定の時代におけるフランス語の表現の変化を追跡したり、情報伝播のパターンを研究したりするのに役立ちます。
· アプリケーション開発における知識ベース構築:特定のテーマに特化したアプリケーション(例:歴史学習アプリ、フランス文化紹介アプリ)を開発する際に、このデータセットを知識の源泉として利用できます。これにより、ゼロから知識ベースを構築する手間を省き、迅速なプロトタイプ開発やサービスローンチが可能になります。
· データサイエンスにおける異種データ統合:他のデータソースと組み合わせて、よりリッチなデータセットを構築する際に、ウィキペディアの構造化された情報が役立ちます。例えば、製品レビューデータと関連するウィキペディア記事の情報を紐づけることで、より深い洞察を得ることができます。
71
DNA-Inspired Semantic Compression (DNA-SC) for AI
著者
bruinmeister
説明
これは、AIのコンテキストウィンドウの制限を克服するためにDNAの構造から着想を得た、革新的なセマンティック圧縮技術です。AIが一度に処理できる情報量には限界がありますが、この技術は、重要な意味を失わずに情報をよりコンパクトに表現することで、その限界を押し広げます。これにより、AIはより長い会話の履歴を記憶したり、より複雑なドキュメントを理解したりできるようになります。
人気
ポイント 1
コメント 0
この製品は何ですか?
このプロジェクトは、AIが一度に理解できる情報量(コンテキストウィンドウ)の制限を解決するための、新しいデータ圧縮方法です。DNAの構造が情報を効率的に保存する方法からヒントを得て、AIが処理するテキストやデータの意味を保ちながら、それをより小さく、より管理しやすい形に変換します。これにより、AIはまるで人間のように、より多くの過去の情報を参照し、より文脈に沿った応答を生成できるようになります。AIが「物忘れ」をしにくくなると考えると分かりやすいでしょう。
どのように使用しますか?
開発者は、このDNA-SC技術を既存のAIモデルに統合することで、コンテキストウィンドウの制限を緩和できます。例えば、チャットボット開発者は、ユーザーとの会話履歴をより長く保持し、よりパーソナライズされた対話を提供するためにこれを使用できます。また、ドキュメント分析ツールでは、より長いレポートや書籍全体を一度に分析できるようになり、より深い洞察を得ることが可能になります。APIとして提供されるか、ライブラリとして統合されることが想定されます。
製品の核心機能
· 意味を保持したまま情報の冗長性を削減します。これにより、AIはより多くの情報を効率的に処理できるようになり、複雑なタスクでのパフォーマンスが向上します。
· コンテキストウィンドウの制限を実質的に拡張します。AIはより長い会話履歴やドキュメントを記憶できるようになり、より一貫性のある、文脈に即した応答を生成できます。
· DNAの自己組織化原理に触発された圧縮アルゴリズムを採用します。これは、従来の手法とは異なる、新しいアプローチであり、AIの処理能力に革新をもたらす可能性があります。
· 圧縮されたデータは、AIモデルが容易に解釈できる形式で保存されます。これにより、既存のAIインフラストラクチャとの互換性が保たれ、容易な導入が可能になります。
製品の使用例
· 長時間のカスタマーサポートチャットボット: 過去のすべてのやり取りを記憶し、顧客の状況を正確に把握した、よりスムーズでパーソナライズされたサポートを提供します。
· 長文ドキュメントの要約・分析: 数百ページに及ぶレポートや書籍全体を一度に処理し、主要な論点や隠れた関連性を発見する、より包括的な分析を可能にします。
· AIによるコード生成: 以前のコードスニペットやプロジェクト全体の文脈を考慮した、より一貫性のある、機能的なコードを生成します。
· 感情分析: 長いレビューやコメント全体から、より微妙なニュアンスや全体的な感情を正確に捉え、より精度の高い分析結果を提供します。
72
CBK Agent SDK
著者
_pdp_
説明
CBK Agent SDKは、外部APIとの連携を効率化し、複雑なバックエンド処理を簡略化するための、高度なプロキシ・エージェントSDKです。API呼び出しのルーティング、データ変換、エラーハンドリングなどを自動化することで、開発者はビジネスロジックに集中できます。これは、マイクロサービスアーキテクチャや、複数の外部サービスに依存するアプリケーション開発において、開発速度と保守性を劇的に向上させる革新的なアプローチです。
人気
ポイント 1
コメント 0
この製品は何ですか?
CBK Agent SDKは、API呼び出しを仲介し、バックエンドの複雑さを隠蔽するスマートなプロキシ・エージェントです。例えば、複数の外部APIからデータを取得して、それを一つの見やすい形式にまとめるような、面倒な作業を自動で行ってくれます。内部では、APIリクエストのルーティング、リクエストやレスポンスのデータ形式の変換(JSONからXMLに変換したり、特定のフィールドだけを取り出したり)、そしてAPI通信中に発生したエラーを適切に処理する、といった高度な機能が組み込まれています。これらはすべて、開発者が自分でコードを書く手間を省き、API連携のインフラ部分を気にせずに済むように設計されています。つまり、API連携の「面倒くささ」をなくし、開発者が「やりたいこと」に集中できる、魔法のようなツールと言えるでしょう。
どのように使用しますか?
開発者は、まずCBK Agent SDKをプロジェクトに組み込みます。次に、SDKの設定ファイルで、どの外部APIと連携したいのか、そのAPIをどのように呼び出すのか、そして受け取ったデータをどのように加工したいのか、といったルールを定義します。SDKがこれらの設定に基づいて、自動的にAPI呼び出しの実行、データ処理、エラー対応を行います。例えば、Webアプリケーションでユーザーのプロフィール情報を表示したい場合、通常はユーザーAPIとプロフィールAPIを別々に呼び出し、結果を結合する必要があります。CBK Agent SDKを使えば、SDKに「ユーザーIDを受け取ったら、ユーザーAPIとプロフィールAPIを呼び出し、結果を結合して返せ」という設定をするだけで、バックエンドコードは非常にシンプルになります。これは、RESTful API、GraphQL、gRPCなど、様々なAPI通信方式に対応しており、既存のシステムへの統合も容易です。
製品の核心機能
· APIルーティングとプロキシ機能: 外部APIへのリクエストを、SDKが適切にルーティングし、リクエスト・レスポンスの仲介を行います。これにより、サービス間の依存関係を疎結合にし、システム全体の柔軟性を高めます。開発者は、APIエンドポイントの管理に煩わされることなく、サービス開発に集中できます。
· データ変換とマッピング: APIから受け取ったデータを、アプリケーションが必要とする形式に自動で変換します。例えば、APIが返してきたJSONデータを、フロントエンドで使いやすい別のJSON構造に整形したり、不要なフィールドを削除したりすることが可能です。これにより、フロントエンドとバックエンド間のデータ連携のコストを削減し、開発効率を向上させます。
· エラーハンドリングとリトライ: 外部API通信で発生しうる様々なエラー(タイムアウト、サービスダウンなど)をSDKが自動的に検知し、定義されたルールに基づいてエラー処理やリトライを実行します。これにより、アプリケーションの可用性と信頼性を向上させ、堅牢なシステムを構築できます。開発者は、複雑なエラー処理ロジックを記述する必要がなくなります。
· 認証・認可の委譲: 外部APIへのアクセスに必要な認証情報(APIキー、トークンなど)の管理や、アクセス制御をSDKに委譲できます。これにより、認証・認可に関するコードをアプリケーション全体に散らばらせることを防ぎ、セキュリティ管理を集中化させます。開発者は、認証・認可の複雑な実装から解放されます。
· ロギングとモニタリング: API通信のログを自動的に記録し、システムの状態やAPI連携のパフォーマンスを監視するための情報を提供します。これにより、問題発生時の原因特定を迅速化し、システム運用を効率化します。開発者は、デバッグやパフォーマンスチューニングのための貴重な洞察を得られます。
製品の使用例
· マイクロサービス間のAPI連携: 複数のマイクロサービスが互いにAPIを呼び出し合うシステムにおいて、CBK Agent SDKを各サービスのAPIゲートウェイとして使用することで、サービス間通信の複雑さを吸収し、開発速度を向上させます。例えば、注文サービスが在庫サービスと商品サービスを呼び出す際に、SDKがそれぞれのAPI呼び出しを管理し、結果を統合して返します。
· レガシーシステムと最新APIの連携: 既存のレガシーシステムを改修せずに、最新の外部APIと連携させたい場合に、CBK Agent SDKが中間層として機能します。レガシーシステムからのリクエストをSDKが受け取り、外部APIの形式に変換して送信し、レスポンスもレガシーシステムが理解できる形式に変換して返します。
· サードパーティAPIの集約: 複数のサードパーティAPI(決済、認証、SNS連携など)を利用する際に、CBK Agent SDKでこれらのAPIを一つに集約し、自社アプリケーションから統一的なインターフェースでアクセスできるようにします。これにより、将来的にサードパーティAPIを変更する際の影響範囲を最小限に抑えることができます。
· IoTデバイスとクラウドバックエンドの通信: IoTデバイスからのデータ収集や、デバイスへのコマンド送信といった通信を、CBK Agent SDKを介して行うことで、デバイス側のリソースを節約しつつ、セキュアで効率的な通信を実現します。SDKがデバイスの制約(低帯域幅、低電力など)を考慮した通信プロトコル変換やデータ圧縮を行います。
73
xemantic-neo4j-kotlin-driver: LLM向け低認知負荷Neo4jドライバ
著者
morisil
説明
これは、LLM(大規模言語モデル)がNeo4jデータベースとやり取りする際の認知負荷を最小限に抑えるように設計された、Kotlin製のNeo4jドライバです。AIエージェントが知識グラフとしてプライベートな記憶を格納し、それを自動科学的プロセスで研究できるようにします。非同期処理の明示的な記述をなくし、リソース管理のためのDSL(ドメイン固有言語)、Cypherの入出力をマルチプラットフォームデータクラスへ自動マッピングする機能を提供します。これにより、エージェントはアドホックなデータ取り込みと取得スキーマを定義でき、LLMが自身の意図を理解しながら意図をエンコードする二重タスク推論の課題を回避できます。
人気
ポイント 1
コメント 0
この製品は何ですか?
このプロジェクトは、AIエージェントがNeo4jデータベースをより効率的に利用できるようにするためのKotlinライブラリです。AI、特にLLMは、複雑な情報を処理する際に「認知負荷」、つまり思考や理解にかかる負担が大きいと、パフォーマンスが低下する傾向があります。このドライバは、その負荷を軽減することに特化しています。具体的には、非同期処理をコード上で明示的に「async」と書く必要をなくし、リソース(データベース接続など)の管理をより自然で安全に行えるようにDSL(Domain-Specific Language)を導入しています。さらに、Neo4jのクエリ言語であるCypherでやり取りされるデータを、Kotlinのデータクラス(プログラムで扱いやすい構造化されたデータ形式)へ自動的に変換します。これにより、開発者はデータベースとのやり取りに直接関わる煩雑なコードを書く手間が省け、AIエージェントのロジックに集中できるようになります。まるで、AIが人間のように直感的にデータベースを使えるようになるイメージです。
どのように使用しますか?
開発者は、このライブラリをKotlinプロジェクトに依存関係として追加し、Ktor(KotlinのWebフレームワーク)などのフレームワークと組み合わせて使用することができます。提供されているデモプロジェクトは、Ktorと組み合わせたフルスタックの非同期処理とコルーチン(Kotlinの並行処理機能)を最大限に活用する方法を示しています。LLMを搭載したAIエージェントは、このドライバを介してNeo4jデータベースに接続し、知識グラフとして記憶を保存したり、そこから情報を検索したりできます。例えば、AIエージェントが過去の対話履歴を知識グラフに保存し、必要に応じてその情報を参照して、より文脈に沿った応答を生成するようなシナリオで利用されます。スクリプトのように実行可能でありながら、型安全でコンパイル時のフィードバックが得られるため、自律的なコード実行スタイルのエージェントにも適しています。
製品の核心機能
· LLM向け認知負荷低減: LLMがデータベース操作を理解しやすくすることで、AIエージェントの推論能力と応答品質を向上させます。これにより、AIとの高度な対話や複雑なタスク実行がよりスムーズになります。
· DSLによるリソース管理: データベース接続などのリソースを、より直感的かつ安全に管理するための言語機能を提供します。これにより、リソースリーク(使い終わったリソースが解放されずに残ってしまう問題)を防ぎ、コードの信頼性を高めます。
· 自動データマッピング: Cypherクエリの入出力を、Kotlinのデータクラスへ自動的に変換します。これにより、開発者はデータ変換のための定型的なコードを書く必要がなくなり、開発効率が向上し、バグのリスクも低減します。
· マルチプラットフォーム対応: 様々なプラットフォーム(Web、サーバーサイド、モバイルなど)で動作するKotlinアプリケーションで利用可能です。これにより、一貫したデータベースアクセスロジックを、異なる環境で再利用できます。
· 構造化された並行処理: Kotlinのコルーチンを活用し、非同期処理を効率的かつ管理しやすくします。これにより、多数のデータベース操作を同時に実行しても、プログラム全体のパフォーマンスと安定性が保たれます。
製品の使用例
· AIチャットボットの記憶管理: AIチャットボットが、過去の対話履歴、ユーザーの好み、関連情報をNeo4jに知識グラフとして保存し、このドライバを使って効率的に検索・活用することで、よりパーソナライズされた会話体験を提供します。LLMの推論負荷が減るため、より自然で知的な応答が可能になります。
· AIエージェントの自己学習システム: AIエージェントが、研究結果や生成した知識をNeo4jの知識グラフに蓄積し、そこからパターンや関連性を発見して自己改善するプロセスを構築します。ドライバの低認知負荷設計により、AIエージェントが自身の知識ベースを効率的に探索・更新できるようになります。
· 複雑な関係性データの分析: 複数のエンティティ(人、物、イベントなど)とその間の複雑な関係性をNeo4jでモデル化し、このドライバを用いて分析します。例えば、SNSでの人間関係の分析や、サプライチェーンにおける複雑な依存関係の可視化・分析に利用できます。
· リアルタイム推薦システムのバックエンド: ユーザーの行動履歴や嗜好をNeo4jに格納し、リアルタイムで推薦情報を生成するシステムを構築します。ドライバの非同期処理能力により、多数のユーザーからのリクエストに迅速に対応できます。
· コード生成AIの内部状態管理: コード生成を行うAIエージェントが、生成中のコードの構造、依存関係、開発者の意図などをNeo4jに知識グラフとして保持し、このドライバを使って効率的にアクセス・更新することで、より一貫性のある高品質なコード生成を実現します。
74
Teller - 聴き心地の良いポッドキャスト自動調整体験

著者
tellerbr15
説明
これは、リスナーが本当に気に入るポッドキャスト番組やエピソードを推薦する、革新的なポッドキャスト消費体験を提供するプロジェクトです。現在のV1では、ライブラリ機能、聴取機能、キューシステム、そして推薦機能の完璧な実現に注力しています。V2では、より洗練された自動化技術を導入し、体験をさらに深化させる予定です。
人気
ポイント 1
コメント 0
この製品は何ですか?
Tellerは、AIを活用してあなたの好みを学習し、あなただけのおすすめポッドキャストを提供するサービスです。従来のレコメンデーションシステムは、単に再生履歴に基づいて似たようなコンテンツを提示するにとどまりますが、Tellerはあなたの聴取パターン、スキップ行動、そして直接的なフィードバックを分析し、よりパーソナルで、あなたの「聴きたい」という気持ちに寄り添う体験を生み出します。これにより、膨大なポッドキャストの中から、あなたにとって真に価値のあるコンテンツを簡単に見つけることができます。まるで、あなたの好みを熟知した友人が、最高の番組をそっと教えてくれるかのようです。
どのように使用しますか?
開発者は、TellerのAPIを既存のポッドキャストアプリやウェブサイトに統合することで、ユーザーにパーソナライズされた推薦機能を提供できます。例えば、あなたのアプリでユーザーがポッドキャストを聴き始めると、Tellerはその行動を分析し、次におすすめするエピソードや番組をリアルタイムで生成します。また、ユーザーが特定のジャンルに興味を示したり、あるエピソードを気に入ったりすると、Tellerはその情報を学習し、将来の推薦精度をさらに向上させます。これにより、ユーザーエンゲージメントを高め、コンテンツ発見の障壁を低くすることができます。
製品の核心機能
· パーソナライズされたポッドキャスト推薦 - ユーザーの聴取行動やフィードバックをAIが学習し、好みに合った番組やエピソードを推薦します。これにより、ユーザーは自分だけのお気に入りを見つけやすくなり、コンテンツ探索の時間を節約できます。
· インテリジェントなキューシステム - 次に聴くべきエピソードを自動的に整理し、ユーザーの聴取フローをスムーズにします。これにより、リスニング体験が途切れることなく、より没入感のある体験を提供します。
· 高度なライブラリ管理 - ユーザーが聴いた番組やエピソードを効果的に管理し、後で簡単にアクセスできるようにします。これにより、お気に入りのコンテンツを失う心配がなくなり、いつでも好きな時に聴くことができます。
· シームレスな聴取機能 - ユーザーが中断した箇所から簡単に再開できる機能や、再生速度の調整など、快適な聴取体験を提供します。これにより、ユーザーは自分のペースでポッドキャストを楽しむことができます。
製品の使用例
· 新しいポッドキャストアプリ開発 - 開発者が、ユーザーの好みに合わせた強力な推薦エンジンを迅速に組み込みたい場合。Tellerは、AIによるパーソナライズされた体験を提供することで、競合アプリとの差別化を図り、ユーザーの定着率を高めます。
· 既存のポッドキャストプラットフォームへの機能追加 - 既存のプラットフォームが、ユーザーのコンテンツ発見能力を向上させたい場合。TellerのAPIを統合することで、ユーザーはこれまで以上に自分に合ったコンテンツに出会えるようになり、プラットフォームの利用頻度が増加します。
· 教育コンテンツ配信サービス - 特定の学習目標を持つユーザーに対し、関連性の高い専門的なポッドキャストエピソードを推薦したい場合。Tellerは、ユーザーの学習進捗や興味に合わせてコンテンツを提示し、学習効果を最大化するのに役立ちます。
75
インタラクティブアラビア語学習プラットフォーム「FushaVerse」
著者
selmetwa
説明
このプロジェクトは、アラビア語学習における従来の教科書の使いにくさを解消するオープンソースのプラットフォームです。単語をクリックまたはドラッグするだけで、その場ですぐに意味、転写、文法ノートを表示できるインタラクティブな平行テキストを提供します。さらに、AIが生成したストーリーや文章で、現代標準アラビア語だけでなく、エジプト方言やモロッコ方言といった日常会話で使われる方言にも対応し、自然な文脈での学習を可能にします。個々の学習者のニーズに合わせた、より実践的なアラビア語学習体験を実現します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、アラビア語学習者が教科書をめくる手間なく、単語の意味や文法をその場で確認できる革新的なオープンソース学習プラットフォームです。単語にマウスカーソルを合わせるかドラッグするだけで、ポップアップウィンドウに意味、転写、文法情報が表示されます。この機能は、テキスト解析と辞書/文法データベースの連携によって実現されています。さらに、AIを活用して学習者向けのオリジナルのストーリーや例文を生成し、多様な文脈での語彙や表現の習得を支援します。特に、一般的なAIモデルが苦手とするエジプト方言やモロッコ方言に特化したカスタムLLMをトレーニングし、より実践的な学習コンテンツを提供している点が技術的な強みです。
どのように使用しますか?
開発者は、このプラットフォームをウェブアプリケーションやモバイルアプリに容易に統合できます。APIを通じて単語の意味検索、文法情報の取得、AI生成コンテンツの利用などが可能です。例えば、既存の言語学習アプリにインタラクティブな単語解説機能を追加したり、オリジナルのアラビア語教材作成ツールとして活用したりすることができます。また、オープンソースであるため、プラットフォームの機能を拡張したり、特定の学習ニーズに合わせてカスタマイズしたりすることも可能です。開発者は、学習者が単語の意味を調べるために頻繁に教科書の末尾を参照しなければならないという、学習体験を阻害する根本的な問題を解決できます。
製品の核心機能
· インタラクティブな単語検索機能: 単語の意味、転写、文法ノートをリアルタイムで表示し、学習の中断を防ぎ、理解を深める。これは、テキスト処理と動的なUI表示技術によって実現されており、学習効率を劇的に向上させます。
· AI生成コンテンツ: 自然で多様な文脈での学習を可能にするAI生成ストーリーや例文を提供。これにより、学習者は教科書的な例文だけでなく、より実践的なアラビア語に触れることができます。
· 方言対応学習: エジプト方言、モロッコ方言に特化したカスタムLLMを活用し、地域ごとの日常会話で使われるアラビア語の学習をサポート。これは、特定の言語データセットでファインチューニングされたLLMの活用であり、ニッチな学習ニーズに応えます。
· 音声付きコンテンツ: 各コンテンツに方言ごとのネイティブスピーカーによる音声を提供し、リスニング能力の向上と発音の正確性を促進。これは、音声合成技術とコンテンツ管理の組み合わせです。
· オープンソースコミュニティ: 誰でも自由に利用、改善、貢献できるプラットフォーム。これにより、技術革新が加速し、より多くの学習者にとって価値のあるツールへと進化していきます。
製品の使用例
· 教育系スタートアップが、既存のウェブベースのアラビア語コースにインタラクティブな単語解説機能を統合し、学習者のエンゲージメントと理解度を向上させる。これは、API連携とフロントエンド開発によって実現されます。
· 個人学習者が、自身の学習進捗に合わせてAIが生成するカスタム練習問題を作成し、弱点を克服するための集中的な学習を行う。これは、AI生成機能の活用とパーソナライズされた学習体験の提供です。
· アラビア語教師が、エジプト方言に特化した教材を作成し、学生が日常会話で使われる生きたアラビア語を効果的に学べるようにする。これは、方言特化型LLMによるコンテンツ生成と教育現場への応用です。
· 言語学習コミュニティが、オープンソースプラットフォームを基盤として、新しい方言のサポートや学習機能の追加を共同で開発し、より包括的なアラビア語学習リソースを構築する。これは、オープンソース文化と集合知による開発の典型例です。
76
GitHub LOC/子ディレクトリ数可視化拡張
著者
hacker_rob
説明
GitHubのファイルページを閲覧する際に、各ファイルの行数(LOC)とディレクトリのサブディレクトリ数(子数)をリアルタイムで表示するブラウザ拡張機能です。これにより、コードベースの規模や構造を直感的に把握できるようになり、コードレビューやリファクタリングの効率が向上します。この拡張機能は、開発者がGitHub上でコードをより深く、迅速に理解するための新しい視点を提供します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、GitHubのファイルやディレクトリの情報を、より分かりやすく表示するためのブラウザ拡張機能です。通常、GitHubではファイルの行数やディレクトリ内のサブフォルダの数を直接確認することができません。この拡張機能は、ウェブページを解析し、これらの情報を自動的に抽出し、ユーザーインターフェース上に埋め込みます。具体的には、JavaScriptを使ってGitHubのDOM(Document Object Model)を操作し、必要なデータを取得・計算して表示します。これにより、コードの複雑さやプロジェクトの規模を一目で把握できるようになり、開発者はより効率的にコードを評価できるようになります。つまり、GitHubでのコード探索が格段にスムーズになります。
どのように使用しますか?
この拡張機能は、ChromeやFirefoxなどの主要なブラウザにインストールするだけで使用できます。インストール後、GitHubの任意のリポジトリを開き、ファイルツリーや個々のファイルページを閲覧すると、自動的に行数やサブディレクトリ数が表示されます。特別な設定は不要で、普段通りGitHubを利用するだけで、その恩恵を受けることができます。例えば、コードレビューをする際に、特定のファイルの行数を見てその規模を把握したり、ディレクトリの深さを理解したりするのに役立ちます。これは、既存のワークフローにシームレスに統合されるため、開発者は追加の学習コストなしに利用できます。
製品の核心機能
· ファイルごとの行数(LOC)表示: 各コードファイルの行数を、ファイル名と並んで表示します。これにより、コードの量が一目でわかり、複雑なファイルや大量のコードを持つファイルを特定するのに役立ちます。開発者は、コードの規模感を把握し、レビューやテストの範囲を適切に判断できます。
· ディレクトリごとのサブディレクトリ数表示: 各ディレクトリの直下にあるサブディレクトリの数を表示します。これにより、プロジェクトのディレクトリ構造の深さや構成を素早く把握できます。大規模なプロジェクトで、どこに何があるのかを理解するのに役立ちます。
· リアルタイム更新: GitHubのページを閲覧中に、スクロールやファイル/ディレクトリの展開・折りたたみに応じて、行数やサブディレクトリ数が自動的に更新されます。これにより、常に最新かつ正確な情報を確認でき、ユーザー体験を損ないません。開発者は、ページを再読み込みする手間なく、情報を得られます。
· 軽量なブラウザ拡張: 既存のウェブブラウザの機能として動作するため、別途アプリケーションをインストールする必要がありません。ブラウザのパフォーマンスにほとんど影響を与えず、スムーズなブラウジング体験を提供します。開発者は、パフォーマンスの低下を心配することなく、この便利な機能を利用できます。
製品の使用例
· コードレビューにおける複雑なファイル特定: コードレビュー担当者は、特定のファイルの行数が多い場合、そのファイルが複雑である可能性が高いと判断できます。この拡張機能により、レビューすべき箇所を効率的に絞り込むことができ、レビューの質とスピードを向上させます。
· リファクタリング対象の選定: プロジェクトの構造を把握する際に、ディレクトリの深さが異常に深い箇所や、ファイル数が異常に多いディレクトリなどを特定しやすくなります。これは、リファクタリングの対象を選定する際の貴重な手がかりとなり、コードベースの健全性を保つのに役立ちます。
· 新規プロジェクトの全体像把握: 新しいリポジトリを初めて訪れた開発者は、この拡張機能を通じて、コードベースの規模や構成を短時間で理解できます。これにより、プロジェクトへの参加や貢献がよりスムーズになります。
· ライブラリやフレームワークの構造理解: 依存するライブラリやフレームワークのコードをGitHub上で確認する際に、各モジュールやコンポーネントの規模や、それらがどのように構成されているかを素早く把握できます。これにより、ライブラリの理解を深め、より効果的に利用できます。
77
LiquiDB
著者
grigoras
説明
LiquiDB は、開発者向けのオープンソースのマルチデータベースマネージャーです。複数のデータベースシステム(PostgreSQL、MySQL、SQLiteなど)を単一のインターフェースから管理できる革新的なツールであり、データベース間のデータ移行、スキーマ比較、クエリ実行などの複雑なタスクを簡素化します。これにより、開発者はデータベース管理における煩雑さを軽減し、より本質的な開発作業に集中できるようになります。
人気
ポイント 1
コメント 0
この製品は何ですか?
LiquiDB は、開発者が普段利用する複数のデータベース(例えば、Webアプリケーションで使うPostgreSQLや、ローカル開発で使うSQLiteなど)を、一つの場所からまとめて管理できるようにするソフトウェアです。革新的な点は、様々なデータベースの「方言」や接続方法の違いを吸収し、あたかも一つのデータベースであるかのように操作できる点です。これは、バックエンドで各データベースのAPIを抽象化し、統一されたクエリインターフェースを提供することで実現されています。つまり、データベースの種類を意識せずに、共通のコマンドでデータを操作できるのです。これによって、開発者はデータベースごとに異なるツールを使い分ける手間が省け、開発効率が劇的に向上します。
どのように使用しますか?
開発者は、LiquiDB をローカルマシンにインストールするか、Dockerイメージとしてデプロイします。その後、管理したい各データベースへの接続情報をLiquiDBに登録します。例えば、PostgreSQLデータベースへの接続には、ホスト名、ポート番号、ユーザー名、パスワード、データベース名といった情報を提供します。SQLiteの場合は、データベースファイルへのパスを指定するだけで済みます。一度接続を設定すれば、LiquiDB のWebインターフェースやコマンドラインツールを通じて、登録した全てのデータベースにアクセスし、クエリの実行、データの閲覧・編集、テーブル構造の確認などができるようになります。これは、複数のプロジェクトで異なるデータベースを使っている場合や、開発環境と本番環境でデータベースの種類が違う場合に特に便利です。
製品の核心機能
· データベース接続管理: PostgreSQL, MySQL, SQLiteなど、様々なデータベースへの接続情報を安全に保存・管理します。これにより、データベースごとに別々の接続ツールや設定ファイルを用意する必要がなくなり、管理が容易になります。
· 統一クエリインターフェース: 異なるデータベースシステムであっても、共通のSQLライクな構文でクエリを実行できます。これにより、データベースの種類に依存しないクエリ作成が可能になり、開発者はSQLの学習コストを最小限に抑えつつ、効率的にデータを操作できます。
· データ移行支援: あるデータベースから別のデータベースへデータをコピー&ペーストするような操作をサポートします。スキーマの差異をある程度吸収しながらデータを移行できるため、データベースの乗り換えや、開発環境と本番環境でのデータ同期が容易になります。
· スキーマ比較: 2つのデータベースまたは同じデータベースの異なるバージョン間で、テーブル構造やインデックスなどの違いを視覚的に比較できます。これにより、データベースの変更履歴の追跡や、意図しない変更の検出が容易になり、データの整合性を保つ上で役立ちます。
· データ表示・編集: クエリ結果をテーブル形式で表示し、直接データを編集する機能を提供します。これにより、手軽にデータを修正したり、確認したりすることができ、デバッグ作業の効率が向上します。
製品の使用例
· Web開発者が、バックエンドにPostgreSQL、ローカル開発用にSQLiteを使っている場合、LiquiDB を使えば両方のデータベースを一つの画面で管理できます。新しいテーブルを作成したり、データを検索したりする際に、データベースの種類を意識する必要がなくなり、開発スピードが向上します。
· 複数のマイクロサービスがそれぞれ異なるデータベース(例: AサービスはMySQL、BサービスはPostgreSQL)を使用している場合、LiquiDB を導入することで、運用担当者は一つのツールで全てのデータベースの状態を監視・管理できます。これにより、障害発生時の原因特定や対応が迅速化されます。
· データベースのバージョンアップやスキーマ変更を行う際に、LiquiDB のスキーマ比較機能を使用することで、変更前後の違いを明確に把握できます。これにより、予期せぬデータ破損やアプリケーションの不具合を防ぐことができます。
· データサイエンティストが、様々なソースから集めたデータを分析するために、一時的に複数のデータベースにデータをロードする必要がある場合、LiquiDB を使えば容易にデータをロードし、SQLでクエリを実行できます。これにより、データの前処理や探索的分析のプロセスが簡略化されます。
78
Transformer Visual Designer (Transformer Visual Designer)
url
著者
kinderpingui
説明
これは、Transformerアーキテクチャの設計とテストを視覚的に行うためのツールです。感情分析機能も組み込まれており、複雑なAIモデルの構築プロセスを直感的に理解し、実行できるようにします。だから、これはAIモデルの設計とデバッグがこれまで以上に簡単になるということです。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、Transformerアーキテクチャを視覚的に構築・テストできる革新的なツールです。従来のコーディングベースの設計とは異なり、ブロックをドラッグ&ドロップするような直感的なインターフェースで、モデルの各層(例えば、AttentionメカニズムやFeed-Forwardネットワーク)を配置・接続できます。さらに、感情分析機能を搭載しているため、モデルがテキストから感情をどれだけ正確に読み取れるかをリアルタイムで確認できます。つまり、AIモデルの内部構造を「見て」理解し、その性能を「体感」できるのです。
どのように使用しますか?
開発者は、Webブラウザ上でWasda AIにアクセスします。GUI上で、事前に定義されたTransformerのコンポーネント(エンコーダー、デコーダー、アテンション層など)をドラッグ&ドロップで配置し、それらを接続して独自のアーキテクチャを構築します。構築したアーキテクチャに対して、サンプルのテキストデータを入力し、感情分析の結果を視覚的に確認しながら、モデルのパフォーマンスを評価・改善できます。これは、AIプロジェクトのプロトタイピングやデバッグの時間を大幅に短縮できるということです。
製品の核心機能
· 視覚的なTransformerアーキテクチャ構築:ドラッグ&ドロップで、モデルの構造を直感的に設計できます。これにより、複雑なAIモデルの設計プロセスが格段に容易になり、コーディングなしでもアイデアを形にできます。
· リアルタイム感情分析:設計したモデルがテキストから感情をどれだけ正確に認識できるかを即座に確認できます。これにより、モデルの潜在的な弱点を早期に発見し、精度向上に繋げることができます。
· インタラクティブなテスト環境:構築したモデルに直接データを入力し、その応答を視覚的に確認できます。これにより、モデルの挙動を深く理解し、デバッグ作業を効率化できます。
· コード生成機能(将来的な可能性):構築したアーキテクチャから、実際のプログラミング言語(例:Python)のコードを生成する機能が期待できます。これにより、設計したモデルをすぐに実運用可能な形に移行できます。
製品の使用例
· 自然言語処理(NLP)モデルのプロトタイピング:新しい感情分析モデルやテキスト分類モデルを開発する際、まずWasda AIで基本的なアーキテクチャを視覚的に設計し、その場で感情分析の精度をテストすることで、開発初期段階での方向性を素早く確立できます。これにより、無駄なコーディング作業を減らし、より早く実用的なモデルに到達できます。
· 教育・学習用途:AIやTransformerモデルの学習者が、モデルの内部構造を視覚的に理解し、各コンポーネントがどのように機能するかを実験的に学ぶことができます。これにより、理論だけでは掴みにくい概念が、より実践的に理解できるようになります。
· AIモデルのデバッグと改善:既存のAIモデルで意図しない結果が出た場合に、Wasda AIでそのモデルのアーキテクチャを再現し、視覚的に問題箇所を特定・修正する手助けとなります。これにより、AIモデルのメンテナンスとチューニングが効率化されます。
79
Java フェイクデータ生成器
著者
barlogg
説明
Javaプロジェクト向けのリアルな偽データ生成ツール。開発時に必要なテストデータやダミーデータを効率的に作成し、開発サイクルを加速させます。特に、データベースの初期化やAPIテストにおいて、手作業でのデータ作成の手間を大幅に削減できる点が革新的です。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、Javaアプリケーションの開発やテストに必要な、本物そっくりの偽データ(フェイクデータ)を自動で生成するためのツールです。例えば、ユーザー名、メールアドレス、住所、日付、ランダムな数値などを、設定に基づいて生成できます。これにより、開発者は手作業でテストデータを作成する時間を節約し、より創造的な作業に集中できるようになります。革新的な点は、単なるランダム生成にとどまらず、特定のフォーマットや制約(例えば、有効なメールアドレス形式、日付の範囲など)に沿った、より現実的なデータを生成できることです。
どのように使用しますか?
開発者は、MavenやGradleといったJavaのビルドツールを使用して、このジェネレーターをプロジェクトに依存関係として追加します。その後、Javaコード内でこのライブラリを呼び出し、生成したいデータの種類と数を指定します。例えば、「100件のユーザーデータを作成して、それをデータベースに挿入する」といった指示をプログラムで行います。APIのモックサーバーと連携させて、実際のAPIレスポンスを模倣する際にも活用できます。これにより、開発中のアプリケーションの動作確認が容易になります。
製品の核心機能
· ランダムな文字列生成: ユーザー名やパスワードなど、自由な形式の文字列を生成し、開発中の認証機能テストに利用できます。
· 数値・日付生成: ID、年齢、登録日など、意味のある数値や日付を生成し、データベースの構造や時間経過による挙動のテストに役立ちます。
· メールアドレス・URL生成: 有効な形式のメールアドレスやURLを生成し、入力バリデーションや外部連携機能のテストを効率化します。
· カスタムデータ生成: 特定のビジネスロジックに基づいた、より複雑で現実的なデータセットを定義して生成できます。これにより、実際の運用に近いシナリオでのテストが可能になります。
· Javaオブジェクトへの直接マッピング: 生成したフェイクデータをJavaのPOJO(Plain Old Java Object)クラスのインスタンスとして直接生成し、アプリケーションコードへの組み込みを容易にします。
製品の使用例
· データベースの初期化: 新しいアプリケーションを開発する際に、テスト用のデータベースに大量のサンプルデータを投入したい場合。手作業では時間がかかりすぎますが、このジェネレーターを使えば数秒で完了し、すぐに開発に着手できます。
· APIテスト: 外部APIからのレスポンスを模倣したダミーデータが必要な場合。このジェネレーターで偽のレスポンスボディを生成し、APIクライアントの動作を確認することで、開発中のAPI連携部分のバグを早期に発見できます。
· UI/UXデモンストレーション: プロトタイプのデモンストレーションや、UIデザインの確認のために、画面上に表示するサンプルデータが必要な場合。リアルなユーザーデータでUIの表示を確認でき、より説得力のあるデモが可能になります。
· パフォーマンステスト: 大量のデータに対するアプリケーションのパフォーマンスを測定したい場合。このジェネレーターで生成したデータを使い、データベースのクエリ速度やアプリケーションの応答時間をテストし、ボトルネックを特定できます。
80
マスターデータ構造バイブル
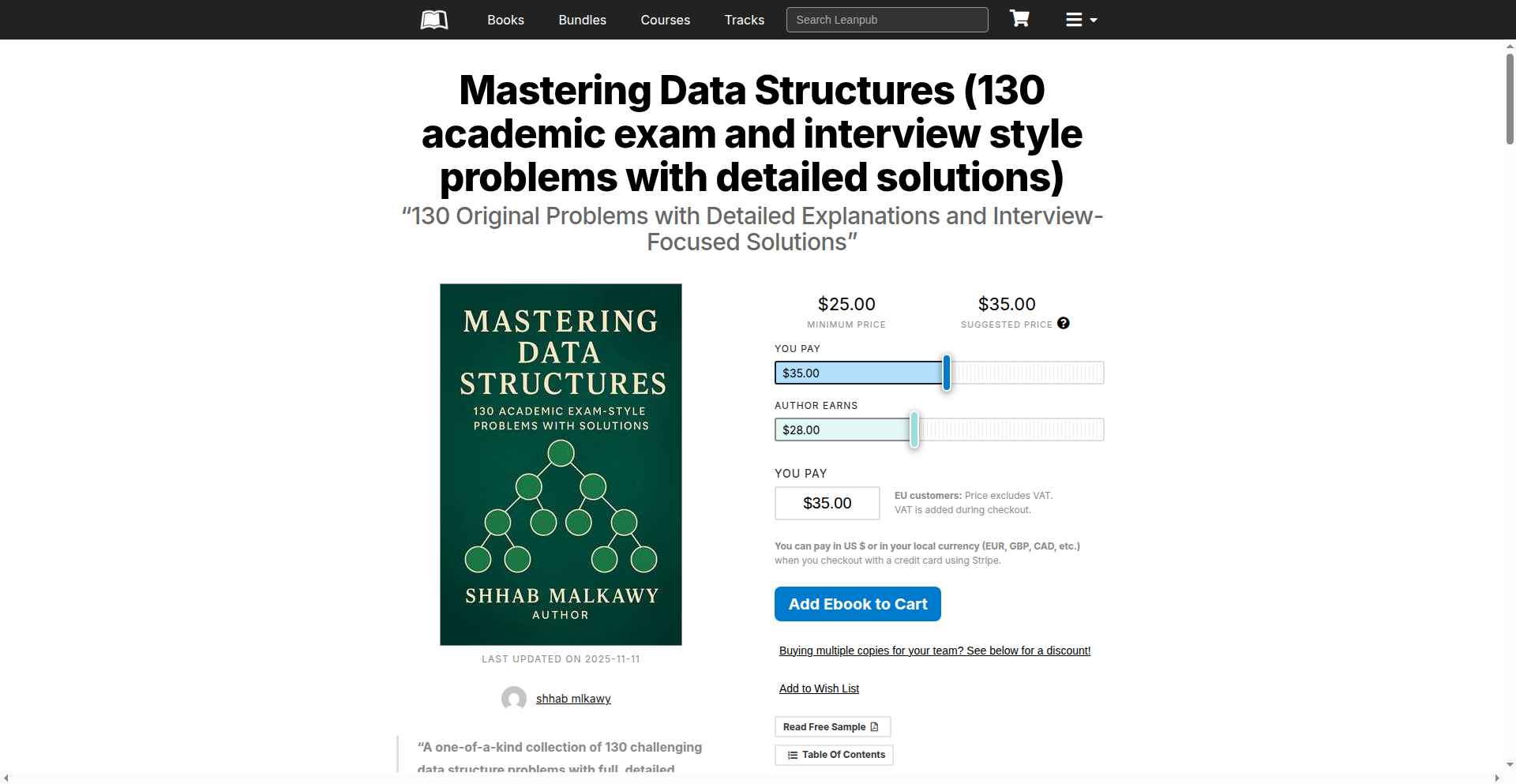
著者
shhabmlkawy
説明
これは、1600ページに及ぶ、130個のオリジナル学術的スタイルの問題とその解答、証明、償却解析、図解、詳細な解説を網羅したデータ構造の書籍です。高度なデータ構造の学習、エンジニアの独学、技術面接対策に特化しており、ヒープ、ツリー、Union-Find、RMQ、ハッシュ、文字列構造などの深い理解を促します。さらに、作者が独自に設計したLayered Summary Heap (LSH)とTriple-L Heapという2つの新しいデータ構造も収録されています。この書籍は、技術的な深さと実践的な応用を兼ね備え、開発者コミュニティに新たな知識と学習リソースを提供します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、データ構造に関する包括的な学習リソースです。単なる入門書ではなく、高度な概念や複雑な問題を掘り下げ、学術的な厳密さで解説しています。特徴的なのは、著者自身が考案した新しいデータ構造であるLayered Summary Heap (LSH)とTriple-L Heapが含まれている点です。これらは、特定のパフォーマンス要件を満たすために設計されており、既存のデータ構造では対応が難しい問題に対する革新的な解決策を提供します。つまり、これはデータ構造の「なぜ」と「どのように」を徹底的に理解するための、まさにバイブルと言えるでしょう。
どのように使用しますか?
開発者は、この書籍を技術面接の準備、自身のデータ構造の知識を深めるための独学、あるいは大学レベルの高度なデータ構造コースの補助教材として活用できます。例えば、面接で特定のアルゴリズムやデータ構造について深く問われた際に、本書の該当箇所を参照すれば、理論的な背景から具体的な実装、さらにはその効率性まで、納得のいく説明ができます。また、新しいプロジェクトでパフォーマンスが重要な場面に直面した際、本書で紹介されているLSHやTriple-L Heapのような革新的なデータ構造が、問題解決の糸口になる可能性があります。
製品の核心機能
· 網羅的なデータ構造問題集: 130個のオリジナル問題と詳細な解答・証明により、様々なデータ構造の理解を深め、応用力を養います。これは、複雑な問題を解くための思考プロセスを訓練するのに役立ちます。
· 高度なデータ構造解説: ヒープ、ツリー、Union-Find、RMQ、ハッシュ、文字列構造などの主要なデータ構造について、基礎から応用まで深く掘り下げて解説します。これにより、これらの構造がどのように機能し、どのような問題に適しているのかを理解できます。
· 著者考案の新規データ構造: Layered Summary Heap (LSH)とTriple-L Heapという、作者独自のデータ構造を紹介します。これらは、既存のデータ構造では効率が悪かったり、実現できなかったりする特定のシナリオに対する、洗練された解決策を提供します。
· 技術面接対策: 問題の多くが技術面接で問われうる形式になっており、実践的なスキルと知識を習得できます。面接で自信を持って質問に答えるための準備ができます。
· 詳細な償却解析: データ構造のパフォーマンスを定量的に評価するための償却解析を丁寧に解説します。これにより、アルゴリズムの効率を正確に判断できるようになります。
製品の使用例
· 開発者が、大規模なグラフ処理タスクにおいて、既存のアルゴリズムではメモリ使用量や処理速度に課題がある場合、本書で紹介されている最適化されたグラフアルゴリズムや、LSHのような新規データ構造を応用して、より効率的なソリューションを開発できます。
· 技術面接で、Union-Findデータ構造の応用について詳細な説明を求められた開発者は、本書の該当セクションを参照することで、その理論的根拠、実装の詳細、およびパフォーマンス特性を完璧に説明でき、面接官に深い理解を示すことができます。
· あるエンジニアが、リアルタイムでのデータ集計とクエリが必要なシステムを構築する際に、標準的なハッシュテーブルではパフォーマンスが不足していると判断しました。本書で紹介されている、より高度なハッシュ技術や、場合によってはLSHのようなデータ構造を検討することで、要求されるパフォーマンスを満たすシステムを設計・実装するヒントを得られます。
· 学生が、データ構造のコースで習得した知識をさらに深めたいと考えた場合、本書の学術的なアプローチと豊富な例題は、理論を実践に結びつけ、より深い洞察を得るための強力なツールとなります。
81
Wegent: クラウドコーディングエージェントプラットフォーム
著者
qdaxb
説明
Wegentは、YAML設定とWeb UIを通じて、コード開発や情報収集のような複雑なタスクを自動化するオープンソースのクラウドコーディングエージェントプラットフォームです。AgnoとClaude Codeエージェントエンジンを基盤とし、対話モードとコーディングモードの両方をサポート。各エージェントチームは独立したサンドボックス環境で動作するため、複数のチームを同時に実行でき、GitHub/GitLabとの連携によるAI駆動開発やコードレビューまで実現します。つまり、開発タスクの自動化と効率化を、特別な開発なしに実現できるツールです。
人気
ポイント 1
コメント 0
この製品は何ですか?
Wegentは、AIエージェントを組み合わせて、複雑なタスクを自動実行できるようにするシステムです。YAMLファイルという設定ファイルで、どんなAIエージェントを、どのような順番で、どのように連携させるかを定義します。Webブラウザからでも設定でき、手軽に始められます。基盤には、会話が得意な「Agno」と、コードを書くのが得意な「Claude Code」という2つの強力なAIエンジンを使っています。これにより、単なるチャットボットとしてだけでなく、実際のコード開発や、GitHubのようなサービスと連携してプログラムを修正したり、レビューしたりすることも可能です。さらに、各エージェントのチームは、互いに干渉しない「サンドボックス」という隔離された空間で動くので、いくつものチームを同時に動かしても安全です。対話モードでは、複数のエージェントが相談しながら仕事を進めるような高度な連携も可能です。つまり、AIに複雑な仕事を任せられる、賢い自動化システムなのです。
どのように使用しますか?
開発者は、YAMLファイルを使ってWegentで実行したいタスクを定義します。例えば、「最新のニュース記事を収集し、その中から特定のトピックに関する洞察をまとめる」といったタスクを定義する場合、ニュース検索エージェント、情報分析エージェント、レポート作成エージェントなどを順番に連携させます。コーディングタスクであれば、「GitHubリポジトリからコードを取得し、単体テストを実行し、結果をレポートする」といった具合です。Web UIからも直感的に設定でき、実行状況の監視や結果の確認が可能です。AIによるコードレビューや、自動化された開発ワークフローに組み込むことで、開発プロセス全体を効率化できます。なので、開発者は複雑な手順を自動化し、より創造的な作業に集中できるようになります。
製品の核心機能
· 設定駆動型エージェントチーム:YAML設定またはWeb UIで、特定のタスクを実行するAIエージェントのチームを定義・実行できます。これにより、複雑なワークフローをコードを書かずに構築・自動化できます。
· マルチ実行エンジン:AgnoとClaude Codeという2つの強力なAIエージェントエンジンを基盤としており、対話による情報収集や、コード生成・修正といったプログラミングタスクの両方に対応します。これにより、多様なニーズに応じた自動化が可能です。
· 分離されたサンドボックス環境:各エージェントチームは独立したサンドボックスで実行されるため、複数のチームが同時に動作しても互いに干渉せず、安全かつ安定した運用が保証されます。これにより、大規模な並列処理も安心して行えます。
· 高度な協調モード:対話モードでは、並列処理やリーダー・フォロワーのような協調パターンをサポートしており、ニュース分析やコンテンツ取得などの複雑なワークフローを、AIエージェントが協力して効率的に解決します。これにより、人間が介在しなくても高度な分析や情報収集が可能です。
· AIコーディング統合:GitHubやGitLabなどのコードサービスと連携し、AIによるコード生成、レビュー、テストなどの開発プロセスを自動化します。これにより、開発者はコーディング作業を効率化し、バグの早期発見や品質向上に貢献できます。
製品の使用例
· 開発シナリオ:新しい機能の単体テストを自動化したい。Wegentを使用し、YAMLファイルでテストコードの生成、実行、結果のレポート作成までをエージェントチームに指示します。これにより、手動でのテスト実行の手間が省け、開発サイクルを速めることができます。
· 情報収集シナリオ:競合他社の最新動向を毎日把握したい。Wegentに、関連ニュースサイトのクロール、記事の要約、重要な情報の抽出、そして週次のレポート作成までをエージェントチームに任せます。これにより、常に最新情報を把握し、ビジネス戦略に活かすことができます。
· コードレビューシナリオ:コードの品質を向上させ、潜在的なバグを早期に発見したい。Wegentに、GitHubリポジトリのコードを自動的に取得させ、静的コード解析ツールや、コードレビューに特化したAIエージェントによるレビューを実行させます。これにより、開発者はレビュープロセスを効率化し、コードの品質を一定に保つことができます。
· データ分析シナリオ:大量のログデータから異常を検知し、原因を特定したい。Wegentに、ログデータの収集・前処理、異常検知アルゴリズムの実行、そして異常発生時の詳細調査をエージェントチームに指示します。これにより、問題の早期発見と迅速な対応が可能になります。
82
量子ポートフォリオ最適化エンジン
url
著者
Hellene
説明
このプロジェクトは、量子コンピューティングを活用して、金融の専門知識がなくても数秒で株式投資ポートフォリオを構築できるツールです。従来のコンピューターでは膨大な時間がかかる複雑な最適化問題を、量子コンピューティングの力で瞬時に解き明かし、個々の投資目標に合わせた最適なポートフォリオを提案します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、量子コンピューティングという最先端技術を使って、株式投資のポートフォリオを賢く作り上げるためのエンジンです。従来のコンピューターでは、たくさんの株の中から「これとこれを組み合わせたら一番リターンが高くてリスクが低い」といった最適な組み合わせを見つけるのに、ものすごく時間がかかります。でも、量子コンピューターは、たくさんの可能性を同時に計算できるという特殊な能力を持っているので、この複雑な計算をあっという間に終わらせることができます。だから、専門家でなくても、誰でも簡単に、自分にぴったりの投資ポートフォリオを作れるようになるのが革新的な点です。つまり、これまで一部の専門家しかできなかった高度なポートフォリオ最適化を、民主化してくれる技術です。
どのように使用しますか?
開発者は、この量子ポートフォリオ最適化エンジンをAPIとして利用できます。例えば、自身の投資アプリやウェブサイトに組み込むことで、ユーザーが希望する投資条件(例えば、リスク許容度、期待リターン、特定のセクターへの投資意向など)を入力するだけで、瞬時に最適化されたポートフォリオの提案を受け取れるようになります。バックエンドで複雑な量子計算を実行し、その結果を分かりやすい形でフロントエンドに返す、といった連携が考えられます。これにより、開発者は高度な金融アルゴリズムを自前で実装する手間を省き、ユーザー体験の向上に集中できます。
製品の核心機能
· 量子最適化アルゴリズムによるポートフォリオ生成: 多数の株式の中から、指定されたリスク・リターンの制約を満たす最適な組み合わせを量子コンピューティングで高速に算出します。これにより、従来では不可能だったレベルの最適化が可能になり、より高いリターンや低いリスクを目指せます。
· リアルタイムポートフォリオ分析: 市場の変動に応じて、ポートフォリオのリスクとリターンをリアルタイムで分析し、必要に応じて再最適化の提案を行います。これにより、変化する市場環境に迅速に対応し、投資効率を最大化できます。
· 投資目標に基づいたカスタマイズ: ユーザーの個別な投資目標(成長重視、配当重視、ESG投資など)に合わせて、ポートフォリオの生成条件を柔軟に設定できます。これにより、画一的な提案ではなく、一人ひとりに最適化されたポートフォリオを提供できます。
· APIによる容易な統合: 開発者向けのAPIが提供されており、既存の投資プラットフォームやアプリケーションに容易に組み込むことができます。これにより、開発者は複雑な量子コンピューティングの知識なしに、高度なポートフォリオ最適化機能をサービスに付加できます。
製品の使用例
· 個人の資産運用アプリへの組み込み: ユーザーが自身の投資目標額、リスク許容度、興味のある産業などを入力すると、量子エンジンが最適な株式の組み合わせと配分を提案します。これにより、投資初心者でもプロのようなポートフォリオを簡単に構築でき、賢い資産運用を始められます。
· フィンテック企業の robo-advisor サービス強化: 既存の robo-advisor が提供するポートフォリオ提案を、量子最適化によってさらに高度化・パーソナライズします。より少ないリスクで高いリターンを目指す、あるいは特定のリスク特性を持つポートフォリオを迅速に生成することで、競合優位性を確立できます。
· 金融機関向けのポートフォリオ分析ツール開発: 投資アドバイザーが顧客に対して、より多様で最適化されたポートフォリオ案を迅速に提示するためのツールとして活用できます。膨大な市場データと顧客の要望を瞬時に照合し、最適な投資戦略を提案することが可能になります。
83
Journiv:あなたの思考と記憶を所有するセルフホスト型プライバシー重視ジャーナリング
著者
swalabtech
説明
Journivは、セルフホスト可能でプライバシーを最優先した美しいジャーナリングアプリです。気分追跡、日替わりプロンプト、有意義な洞察を提供し、あなたの思い出は完全にあなたのものです。Dockerで簡単にホストでき、Day OneやApple Journalのようなモダンでセルフホスト可能な代替手段がないという課題を解決します。
人気
ポイント 1
コメント 0
この製品は何ですか?
Journivは、あなたが書いた日記や思い出を、オンラインサービスに依存せず、自分自身のサーバーで管理できるジャーナリングアプリです。個人情報やプライバシーを重視し、あなたのデータは誰にも見られることなく、あなただけが所有できます。感情の記録、日々の問いかけ、過去の今日を振り返る機能などを通じて、自己理解を深める手助けをします。これは、GitやDockerといった開発者のための技術を使い、現代的で使いやすい形で実現されています。
どのように使用しますか?
開発者は、GitHubからJournivのDockerイメージを取得し、Docker Composeを使って自身のサーバーやローカル環境に簡単にデプロイできます。これにより、すぐにセルフホスト型のジャーナリング環境が構築されます。API連携やカスタマイズの余地もあり、開発者は自身のワークフローに組み込んだり、追加機能開発の基盤として活用したりできます。例えば、外部のイベントトリガーと連携して日記の入力を促す、といった使い方も考えられます。
製品の核心機能
· セルフホスト型ジャーナリング:あなたのデータはあなた自身のサーバーに保存されるため、プライバシーが最大限に保護されます。これは、第三者のデータ侵害のリスクを回避したい開発者にとって重要です。
· 気分追跡機能:日々の気分を記録し、可視化することで、感情のパターンやトリガーを把握できます。これは、メンタルヘルスのセルフケアを重視する開発者にとって、自己管理の強力なツールとなります。
· 日替わりプロンプト:毎日異なる質問やテーマが提供され、ジャーナリングのきっかけとなります。これは、思考の整理や創造的なアイデアの発想を促進したい開発者にとって、インスピレーション源となります。
· 「今日の出来事」機能:過去の同じ日付の投稿を自動的に表示し、時間の経過とともに自分の成長や変化を振り返ることができます。これは、長期的なプロジェクトの進捗や自己成長の記録を重視する開発者にとって、モチベーション維持に繋がります。
· Dockerホスト可能:Dockerコンテナとして提供されるため、セットアップと管理が容易です。これは、インフラ構築や運用に慣れている開発者にとって、迅速な導入と安定した運用を可能にします。
製品の使用例
· 個人開発者が、自身の機密性の高いアイデアやプロジェクトの進捗を記録するためのプライベートなジャーナルとして利用する。これにより、他者に情報が漏れるリスクを排除し、安心して開発に集中できます。
· フリーランスのデザイナーが、日々のデザインのインスピレーション、クライアントとのやり取り、そして自身の学習記録をまとめて管理するために使用する。気分追跡機能でクリエイティブな波を把握し、プロンプト機能で新しいデザインのアイデアを探求します。
· バックエンドエンジニアが、自身の学習した技術スタックや、複雑なシステム設計に関する考察を記録する。開発者向けのセルフホスト型であるため、技術的な詳細も安心して記録でき、将来の参照や共有のための知識ベースとして活用できます。
· リモートワーカーが、日々の業務の振り返り、モチベーションの維持、そしてワークライフバランスの管理のために利用する。日々の感情の変化を記録することで、燃え尽き症候群を防ぎ、生産性を維持するための自己調整に役立てます。
84
リード&コンテンツ・ブースター
著者
elephantisfast
説明
このプロジェクトは、ビジネスのリード獲得とコンテンツ作成を劇的に効率化するAI搭載ツールです。リード獲得においては、あなたが求める顧客像(意図や目標)を入力するだけで、キーワードやその他のシグナルを駆使して最適なリードを自動で検索します。さらに、Redditのトレンドを分析し、バイラルになるコンテンツのパターンを学習して、効果的な記事作成を支援します。これにより、開発者は顧客発見とコンテンツマーケティングの時間を大幅に削減できます。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、AIがあなたのビジネス目標に基づいて、潜在顧客(リード)を素早く見つけ出し、さらにRedditで話題になっているコンテンツのパターンを学習して、バイラルになるような記事作成を支援するツールです。リード獲得では、あなたが「こういう顧客が欲しい」という要望を入力するだけで、AIがインターネット上の情報を調べて、最も可能性の高い顧客候補をリストアップしてくれます。コンテンツ作成では、例えば「AIの最新トレンドについて書きたい」といったトピックを入力すると、Redditでそのトピックに関する人気投稿を分析し、なぜそれが話題になったのかを解き明かします。そして、その成功パターンに基づいて、読者の心をつかむような記事のアイデアや構成を提案してくれるのです。つまり、AIがあなたの代わりにリサーチし、戦略を立ててくれるようなものです。このツールの革新性は、単なる情報検索ではなく、AIが「意図」や「パターン」を理解し、能動的に価値ある情報を提供することにあります。だから、私にとって何が嬉しいかというと、これまで時間のかかっていた顧客探しや、何を書けば良いか悩む時間を、AIが代わりにやってくれるので、より本質的なビジネスの成長に集中できることです。
どのように使用しますか?
開発者は、まず、獲得したいリードの条件(例えば、特定の業界、役職、地域など)を具体的にテキストで入力します。AIはそれを解釈し、ウェブ上から関連性の高い企業や担当者の情報を自動で収集・提示します。次に、コンテンツ作成機能では、記事のトピックやキーワードを入力します。AIはRedditから関連する話題を抽出し、どのような見出し、内容、構成が人々の興味を引くのかを分析します。そして、その分析結果に基づいた記事のドラフトやアイデアを提供します。このツールは、API連携やカスタムスクリプトを通じて、既存のCRMシステムやコンテンツ管理システムに組み込むことも可能です。だから、私にとって何が嬉しいかというと、日々の業務フローに簡単に組み込めて、すぐに効果を実感できることです。
製品の核心機能
· AIによるインテントベースのリード検索:あなたが求める顧客像の意図をAIが理解し、関連性の高いリードを自動でリストアップします。これにより、手作業でのリード開拓にかかる時間を大幅に短縮し、より精度の高い顧客候補を得られます。
· Redditトレンド分析によるコンテンツパターン学習:Redditでバイラルになったコンテンツの共通パターンをAIが学習・分析し、読者の関心を引くコンテンツ作成のヒントを提供します。これにより、エンゲージメントの高いコンテンツを効率的に作成できます。
· AI駆動型コンテンツ生成支援:分析されたパターンに基づき、記事のアイデア、見出し、構成案などをAIが生成します。これにより、コンテンツ作成の初期段階での壁を乗り越え、執筆プロセスを加速させます。
· クロスプラットフォームでのコンテンツ応用提案:Redditで成功したパターンが他のプラットフォームにも波及するという洞察に基づき、生成されたコンテンツが他のSNSなどでも効果を発揮する可能性を考慮した提案を行います。これにより、コンテンツのリーチを最大化できます。
· 迅速な顧客発見とコンテンツ作成:これらの機能により、開発者は顧客発見のスピードを秒単位に、コンテンツ作成の時間を分単位に短縮できます。これは、開発リソースをより戦略的なタスクに集中させることを可能にします。
製品の使用例
· スタートアップ企業が、新しいSaaS製品のターゲット顧客を短時間で見つけたい場合。CEOやCTOといった役職のリードを、特定の技術スタックを使っている企業から抽出することで、営業活動の効率を劇的に向上させられます。
· BtoBマーケターが、自社製品のブログ記事のネタに困っている場合。例えば、「クラウドセキュリティの最新動向」といったトピックを入力し、Redditで関連する議論を分析させることで、開発者が本当に知りたい情報や、未解決の課題に基づいた記事を作成し、専門家としての信頼性を高められます。
· フリーランスのコンテンツクリエイターが、SEOに強く、かつ読者のエンゲージメントが高い記事を迅速に作成したい場合。AIがRedditのトップ投稿から「なぜこの投稿は人気なのか」を分析し、それを基にした構成案と魅力的な見出しを提案してくれるため、執筆時間を短縮しつつ、より効果的なコンテンツを生み出せます。
· アフィリエイトブロガーが、トレンドに敏感なニッチ市場で収益を最大化したい場合。AIがRedditで急上昇しているトピックを発見し、そのトピックでバイラルになりやすいコンテンツの書き方を提案してくれるため、競合よりも早く市場のニーズを捉え、収益機会を最大化できます。
85
GoLangマルチテナントエージェントSDK
著者
tech-aguirre
説明
Pythonを使わずに、Go言語でマルチテナントエージェントを構築するためのオープンソースSDKです。複数のクライアントやユーザーが、互いに干渉することなく、単一のシステムインスタンスを安全に共有できるようなアプリケーション(例えば、SaaSプラットフォームや共有インフラストラクチャ)を開発したい開発者向けに、スケーラブルでセキュアなマルチテナントアーキテクチャの実装を簡素化します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、Go言語で書かれた、複数のテナント(顧客やユーザーグループ)を安全かつ効率的に管理するためのSDK(Software Development Kit)です。従来のシステムでは、各テナントごとに別々のサーバーやインスタンスを用意する必要があり、コストや管理の手間がかかりました。このSDKは、単一のシステムインスタンス上で、各テナントのデータやリソースを論理的に分離し、互いに干渉しないように管理する技術的な仕組みを提供します。これにより、リソースの共有とコスト削減を実現しつつ、各テナントに専用環境のような体験を提供します。Pythonなどの他の言語に依存しないため、Go言語のエコシステム内で完結します。
どのように使用しますか?
Go言語のプロジェクトにこのSDKを組み込むことで、マルチテナント機能を迅速に実装できます。例えば、新しいテナントを追加する際、SDKが提供するAPIを呼び出すことで、テナント固有の設定やリソースの分離が自動的に行われます。また、APIリクエストがどのテナントからのものかを識別し、そのテナントのデータのみにアクセスできるように権限管理を行うといったシナリオで利用できます。既存のGoアプリケーションに統合することも、新規のマルチテナントアプリケーションをゼロから構築することも可能です。
製品の核心機能
· テナント識別とルーティング: 受信したリクエストがどのテナントからのものかを正確に特定し、適切なリソースや処理にルーティングします。これにより、各テナントは自分専用の環境のように感じられます。
· リソース分離メカニズム: テナントごとにデータストレージ、キャッシュ、あるいは計算リソースなどを論理的に分離します。これにより、あるテナントの活動が他のテナントに影響を与えることを防ぎ、セキュリティと安定性を向上させます。
· テナント管理API: 新しいテナントの追加、既存テナントの設定変更、テナントの削除などをプログラムから簡単に行えるインターフェースを提供します。これにより、テナントのライフサイクル管理が効率化されます。
· セキュアな認証と認可: 各テナントのユーザーが、自分のテナントのリソースにのみアクセスできるように、堅牢な認証と認可の仕組みをサポートします。これにより、データ漏洩のリスクを最小限に抑えます。
製品の使用例
· SaaSアプリケーション開発: 複数の企業顧客にサービスを提供するSaaSプラットフォームで、各企業のデータと設定を分離するために利用できます。これにより、顧客は自分専用の環境のようにサービスを利用でき、事業者はリソースを効率的に利用できます。
· APIゲートウェイ: 異なるAPIキーを持つ複数の開発者やサービスからのリクエストを処理するAPIゲートウェイで、各開発者のAPI使用量制限やアクセス権限をテナントごとに管理するために活用できます。
· 共有バックエンドサービス: 複数のマイクロサービスが共通のデータベースやキャッシュを共有する際に、各サービスインスタンスやリクエスト元がどのテナントのリソースにアクセスすべきかを制御するために使用できます。これにより、データの一貫性を保ちながらスケーラビリティを向上させます。
· IoTプラットフォーム: 多数のIoTデバイスからのデータを収集・処理する際に、デバイスが所属する顧客やグループごとにデータを分離し、管理するために利用できます。
86
括弧の真価: 4つの解答 (LeetCode #20)
著者
smatthewaf
説明
このプロジェクトは、LeetCodeで「有効な括弧」として知られるプログラミング問題を、4つの異なるアプローチで解決するコードを提示します。単純に見えて奥深いこの問題に対し、開発者がどのように考え、コードで表現するかの洞察を提供し、技術的な探求心を刺激します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、プログラミングでよく登場する「有効な括弧」という問題を、4つの異なる方法で解いたサンプルコード集です。括弧が正しく閉じられているか(例:「()」や「()[]{}」はOK、「(]」や「([)]」はNG)を判定する技術的な課題に対し、スタック(積み重ねていくデータ構造)を使ったり、再帰(自分自身を呼び出す関数)を使ったりするなど、様々なプログラミングのテクニックを駆使しています。それぞれの解法には、効率性や考え方の違いがあり、開発者が問題解決のための多様なアプローチを学ぶのに役立ちます。これは、コードの書き方一つで、同じ問題を違う角度から捉え、最適解を見つけ出す創造性を体現しています。
どのように使用しますか?
開発者は、このプロジェクトのコードを参考に、自身のプログラミング学習や、類似の問題解決に応用できます。例えば、新しいプログラミング言語を学ぶ際や、アルゴリズムの理解を深めたい時に、これらの解法を読み解き、実際に試してみることができます。また、コードレビューの際にも、他の開発者の思考プロセスを理解する一助となるでしょう。自身のプロジェクトで、入力された文字列の構造を検証する必要がある場合、これらのテクニックを応用することも可能です。
製品の核心機能
· スタックを用いた括弧整合性チェック: 括弧の開始と終了を一時的に記憶するスタック構造を使うことで、開きっぱなしの括弧や、間違った順序で閉じられた括弧を効率的に検出できます。これは、コードの構造解析や、ツリー構造のような階層的なデータを扱う際に役立ちます。
· 再帰を用いた括弧整合性チェック: 問題をより小さな部分問題に分解し、自己解決させる再帰的なアプローチです。自然言語処理や、複雑なデータ構造の探索において、エレガントな解決策を提供できます。
· その他のオリジナル解法: 特定の条件下で効率を発揮したり、ユニークな発想に基づいたりする解法です。これらの解法は、開発者の「ひらめき」や、既存の枠にとらわれない発想の重要性を示唆しています。
· 各解法のパフォーマンス比較: 4つの解法それぞれについて、速度やメモリ使用量などのパフォーマンスを比較検討しています。これにより、開発者は、どのような状況でどの解法が最適かという実践的な判断を下すことができます。これは、実際のシステム開発において、リソースを効率的に使うための重要な示唆を与えます。
製品の使用例
· プログラミング教育における実践例: 大学のプログラミング入門コースや、オンライン学習プラットフォームで、学生が「有効な括弧」問題を学ぶ際に、このプロジェクトのコードを教材として利用できます。これにより、学生は抽象的なアルゴリズムを具体的なコードで理解し、デバッグ能力を養うことができます。
· API入力検証の応用: ユーザーからの入力データ(例:JSON形式のデータ)に含まれる括弧の整合性を、このプロジェクトのテクニックを使ってリアルタイムで検証することで、APIの堅牢性を高め、予期せぬエラーを防ぐことができます。
· テキストエディタのシンタックスハイライト機能開発: コードエディタなどが、コードの構文を正しく解釈し、色付けするために、括弧の対応関係を把握する必要があります。このプロジェクトの解法は、その基礎となるロジックを提供します。
· コンパイラの構文解析部分への応用: プログラミング言語のソースコードをコンピュータが理解できる形に変換する際、括弧の整合性は基本的なチェック項目です。このプロジェクトの考え方は、コンパイラの構文解析器の設計にヒントを与えます。
87
Shelly Systems: YAMLプロセス・フローチャート・コード
著者
chrisshella2
説明
Shelly Systemsは、YAML形式でシステムやプロセスのモデルをコードとして記述し、スプレッドシートのような数式を使ってフローチャートを生成するツールです。複雑で変更の多いシステム(例えば、進化し続けるWebアプリケーション)の設計やドキュメント化を手動で行う手間を省くことを目指しています。これにより、プロセスの変更管理が容易になり、一貫性のあるドキュメントを維持できます。
人気
ポイント 1
コメント 0
この製品は何ですか?
Shelly Systemsは、システムやビジネスプロセスを「コードとして」モデル化する画期的なアプローチです。従来のVisioのようなグラフィカルツールで手動で設計・文書化する代わりに、YAMLという人間が読みやすいデータ形式でプロセスのロジックや構造を定義します。さらに、Excelのスプレッドシートのように、数式を使ってデータの計算や条件分岐を表現でき、それらの定義から自動的にフローチャートを生成します。これは、UMLやSysMLが提唱する「単一の真実の情報源」という考え方を、よりアクセスしやすく実践的な形で実現しようとするものです。つまり、コードを書くようにプロセスの流れを定義し、視覚的な図を自動生成してくれるのです。これによって、プロセスの変更があった際にも、YAMLファイルを更新するだけで、常に最新のフローチャートが得られるため、ドキュメントと実際のシステムとの乖離を防ぐことができます。
どのように使用しますか?
開発者は、Shelly SystemsのYAMLベースの言語を使って、システムの各ステップ、条件分岐、並列処理などを定義します。このYAMLファイルに、スプレッドシートのセルに数式を入力するのと同じ感覚で、条件(例:「もしユーザーがログインしていれば」)やアクション(例:「メールを送信する」)を記述します。定義が完了したら、Shelly Systemsがこれを解析し、自動的に視覚的なフローチャートを生成します。この生成されたフローチャートは、システムの理解を深めたり、チーム内でのコミュニケーションを円滑にしたりするために活用できます。また、YAMLファイル自体がコードとしてバージョン管理できるため、プロセスの変更履歴を追跡したり、過去のバージョンに戻したりすることも容易です。API連携やCLIツールとして組み込むことで、CI/CDパイプラインの一部としてプロセスの自動検証やドキュメント生成を行うことも将来的には考えられます。
製品の核心機能
· YAMLによるプロセス定義:YAMLという、人間が読み書きしやすい形式で、システムの各ステップやロジックをコードのように記述できます。これにより、プロセスの変更が容易になり、バージョン管理もしやすいため、常に最新の状態を保つことができます。
· スプレッドシート風数式によるロジック記述:Excelのように、数式を使って条件分岐(例:もしAならばB、そうでなければC)やデータ処理を直感的に記述できます。これにより、複雑なビジネスロジックも分かりやすく表現でき、プロセスの自動化や意思決定のロジックを明確にできます。
· 自動フローチャート生成:YAMLで定義されたプロセスと数式を基に、視覚的なフローチャートを自動生成します。これにより、手作業で図を作成する手間が省け、プロセスの全体像を把握しやすくなり、関係者間のコミュニケーションが円滑になります。
· コードとしてのプロセス管理:YAMLファイルはテキストデータなので、Gitなどのバージョン管理システムで管理できます。これにより、プロセスの変更履歴の追跡、以前のバージョンへのロールバック、複数人での共同編集が容易になり、開発プロセス全体の効率化につながります。
製品の使用例
· Webアプリケーションの複雑なユーザーフローのモデリング:例えば、ユーザー登録からプロフィール設定、決済プロセスといった一連の流れをYAMLで定義し、視覚的なフローチャートで確認することで、開発中のエラー箇所や改善点を早期に発見できます。これは、ユーザー体験(UX)の向上に直接貢献します。
· API連携における処理フローの設計とドキュメント化:複数のAPIを呼び出す際の、リクエスト、レスポンス、エラーハンドリングといった複雑な連携処理をYAMLで記述し、フローチャート化することで、開発者間で処理の流れを正確に共有し、実装ミスを防ぐのに役立ちます。
· ビジネスロジックの可視化と共有:例えば、顧客からの注文処理、在庫管理、出荷指示といった一連のビジネスプロセスをYAMLでモデル化し、フローチャートとして関係部署に共有することで、プロセスの誤解を防ぎ、改善点を効率的に見つけることができます。
88
SuperCurate - 知的情報の整理と探求のためのデジタル書斎
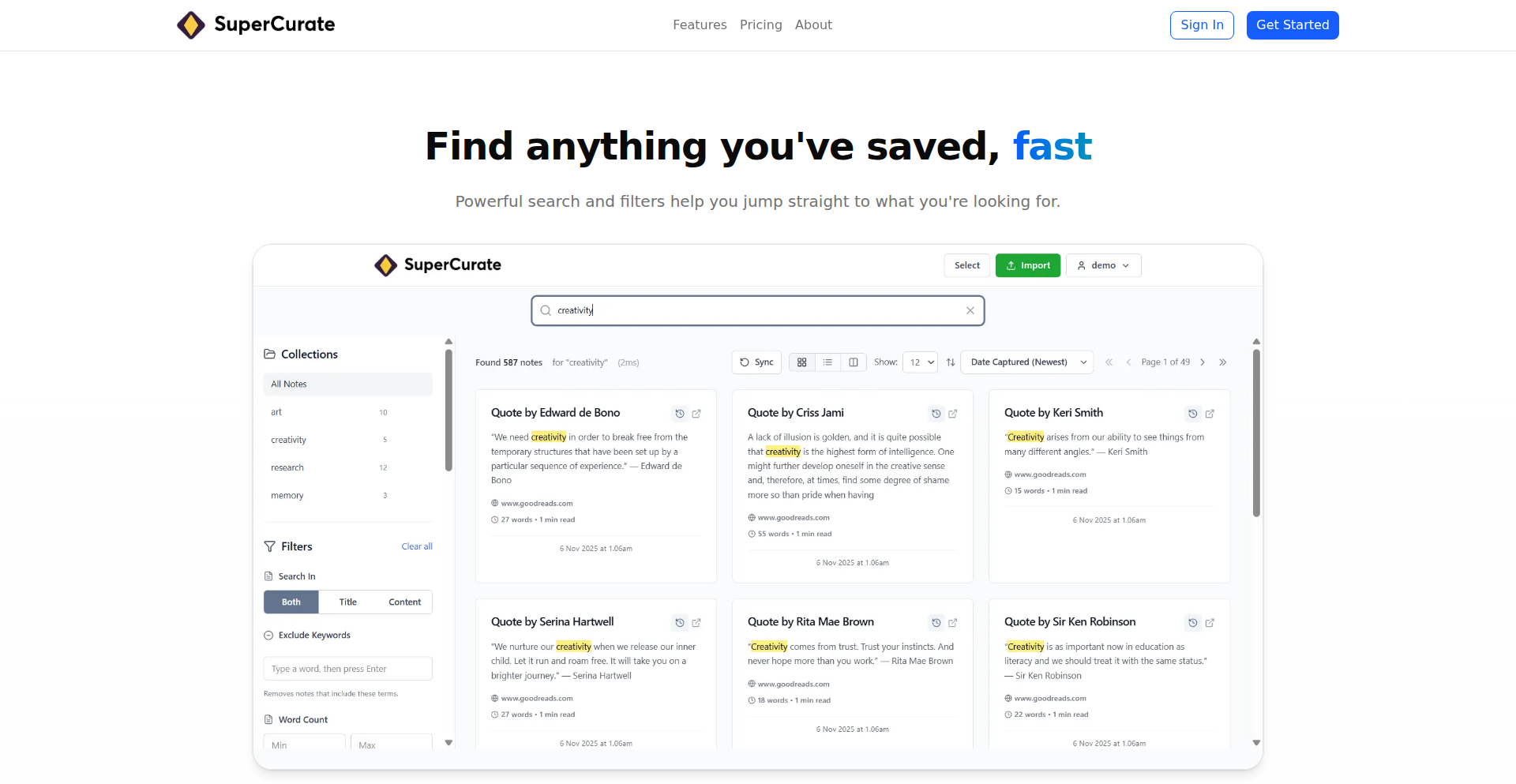
著者
superdocs1
説明
SuperCurateは、Evernote、Markdown、PDF、画像などの多様な形式の情報を、高速な検索と洗練された整理機能で管理できるツールです。特にPDF内のテキスト検索とページジャンプ機能、そしてWebクリッパーによる情報収集の効率化に革新性があり、散在する知識を体系的に活用したい開発者やクリエイターにとって、強力な知的資産管理ソリューションを提供します。
人気
ポイント 1
コメント 0
この製品は何ですか?
SuperCurateは、あなたが日々蓄積するメモ、Web上のクリップ、画像、PDFなどのデジタル情報を、まるで高性能なファイルキャビネットのように整理し、瞬時に探し出せるようにするシステムです。単なる保存場所ではなく、「探す」ことに特化しているのが最大の特徴です。PDFの中に書かれた文字を検索したり、見たいページに直接飛んだり、ハイライトまでできる機能は、従来のツールにはない画期的な点です。これにより、情報が埋もれてしまうことを防ぎ、必要な情報に素早くアクセスできるようになります。つまり、あなたの知識やアイデアを効率的に活用するための強力なパートナーとなるのです。
どのように使用しますか?
開発者は、EvernoteからエクスポートしたENEXファイル、Markdownファイル、PDF、画像などをSuperCurateにインポートすることで、自身の情報ライブラリを構築できます。Chrome拡張機能であるSuperCurate Web Clipperを使えば、Webページ上のテキストや画像をワンクリックでライブラリに保存できます。保存された情報は、キーワードやタグ、ファイルタイプなどのフィルターを使って、驚くほど速く検索できます。例えば、特定のプロジェクトに関するメモや、過去に調査した技術記事などを、瞬時に見つけ出すことができます。この高速な情報検索と整理機能は、開発プロセスにおける情報探索の時間を大幅に削減し、より創造的な作業に集中するための環境を提供します。
製品の核心機能
· 多様なフォーマットからの情報インポート(Evernote ENEX、MD、PDF、画像): 既存の情報を失うことなく、シームレスにSuperCurateへ移行・統合できます。これにより、長年蓄積してきた知識資産を一つの場所で管理できるようになります。
· 高速な全文検索とフィルター機能: キーワードだけでなく、ファイルタイプや日付などの条件で情報を絞り込めます。これにより、膨大な情報の中から目的のものを瞬時に見つけ出すことができ、情報探索の時間を劇的に短縮します。
· コレクションによる情報整理: 関連する情報を「コレクション」としてグループ化できます。プロジェクト別、トピック別など、自分に合った方法で情報を整理することで、知識の構造化が促進され、より深い理解につながります。
· PDF内の検索とページジャンプ、ハイライト機能: PDFファイルを開かずに、その中のテキストを検索し、該当箇所に直接ジャンプしたり、ハイライトを付けたりできます。これは、技術文書や論文を読む際に、必要な情報をピンポイントで把握するのに非常に役立ちます。
· SuperCurate Web Clipper(Chrome拡張): Web上の役立つ情報(記事、画像、リンクなど)を、ブラウザから直接ライブラリに保存できます。これにより、情報収集のフローが簡潔になり、後で参照したい情報を効率的にキャプチャできます。
製品の使用例
· 開発者が新しい技術スタックを学習する際に、関連するWeb記事、ドキュメントPDF、個人的なメモをSuperCurateに集約し、後で「学習したい技術名」などのキーワードで検索することで、効率的に学習リソースにアクセスできる。これにより、学習の停滞を防ぎ、スキルの習得を加速させます。
· 複数のプロジェクトで並行して作業している開発者が、各プロジェクトに関連する要件定義書PDF、設計ドキュメント、過去の議事録などをコレクションとして整理し、プロジェクト名で検索することで、必要な情報に素早くアクセスできる。これにより、コンテキストスイッチの際の情報探索時間を削減し、生産性を向上させます。
· カンファレンスやセミナーで得た資料(PDF、Webクリップ)をSuperCurateに保存し、後で特定のテーマや登壇者名で検索することで、情報を見失わずに再利用できる。これは、知識の定着と応用を促進し、将来的なプロジェクトやアイデア創出に役立ちます。
· バグ報告やカスタマーサポートの記録(テキスト、PDF)をSuperCurateに集約し、問題の種類や発生箇所で検索することで、類似の問題解決策を過去の記録から素早く見つけ出すことができる。これにより、問題解決のスピードを向上させ、ユーザー満足度を高めます。
89
ムービートレーラーポップアップ
著者
naimurhasanrwd
説明
この拡張機能は、ウェブページ上の映画のタイトルを右クリックするだけで、YouTubeの予告編をポップアップで即座に再生できるようにします。これにより、映画のタイトルをコピーしてYouTubeで検索するという手間のかかる作業が不要になり、時間を節約できます。右クリックが無効になっているサイトでも、Alt/Optionキーとの同時押しや、拡張機能アイコンからの手動検索で利用可能です。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、ウェブサイト上の映画のタイトルにマウスカーソルを合わせ、右クリックすると、その映画の予告編を別タブを開かずに、同じ画面上の小さなウィンドウ(ポップアップ)で視聴できるブラウザ拡張機能です。技術的には、ウェブページのコンテンツを解析して映画のタイトルを検出し、そのタイトルを基にYouTubeで予告編を検索し、結果をブラウザの拡張機能として表示する仕組みです。これにより、動画を探す手間が省け、よりスムーズに映画の情報を得られるようになります。つまり、映画選びの時間が劇的に短縮されるのです。
どのように使用しますか?
まず、お使いのブラウザ(Chromeなど)にこの拡張機能をインストールします。インストール後、映画のタイトルが記載されているウェブページ(動画配信サイトのリスト、映画レビューサイトなど)を開きます。興味のある映画のタイトルを見つけたら、そのタイトル上で右クリックしてください。すると、すぐに予告編がポップアップで表示され、視聴できます。もし右クリックが効かないサイトでも、キーボードのAltキー(Macの場合はOptionキー)を押しながら右クリックを試みてください。または、ブラウザのツールバーにある拡張機能のアイコンをクリックして、手動で映画タイトルを検索することも可能です。これは、映画の候補をいくつも見て、どれが面白そうか判断したい場合に非常に便利です。
製品の核心機能
· 映画タイトル検出とYouTube検索:ウェブページ上の映画タイトルを自動的に識別し、YouTubeで関連する予告編を検索します。これにより、ユーザーは手動でタイトルをコピー&ペーストする手間から解放され、目的の動画に素早くアクセスできます。
· インラインポップアップ再生:検出された予告編は、別タブを開くことなく、現在のウェブページ上に小さなウィンドウで表示されます。これにより、ブラウザのタブが増えるのを防ぎ、視聴中に他の情報も確認できるため、効率的な情報収集が可能になります。
· 右クリック無効サイト対応:ウェブサイトが右クリック機能を無効にしている場合でも、Alt/Optionキーとの同時押しで右クリック操作を可能にし、機能を利用できるようにします。これは、技術的な制限を回避してユーザー体験を向上させるハッカー精神の表れです。
· 手動検索機能:拡張機能アイコンをクリックすることで、直接映画タイトルを入力して予告編を検索できます。これにより、自動検出がうまくいかない場合や、特定の映画の予告編をピンポイントで見たい場合に役立ちます。
製品の使用例
· 動画配信サービスの映画リストを閲覧中に、気になる映画の予告編をすぐに確認したい場合。この拡張機能を使えば、タイトルをコピーしてYouTubeを開く必要がなく、リストを見ながら次々と予告編をチェックできます。これにより、映画選びの時間が大幅に短縮されます。
· 映画レビューサイトで、記事を読みながら個々の映画の雰囲気を掴みたい場合。記事中の映画タイトルを右クリックするだけで予告編が再生されるため、記事の内容に集中しつつ、視覚的に映画を評価できます。これは、読書体験を損なわずに映画の魅力を深掘りすることを可能にします。
· ローカルネットワーク上のストリーミングサーバーで映画を閲覧しているが、予告編機能がない場合。この拡張機能は、ウェブページ上の映画タイトルであればどこでも動作するため、ローカルコンテンツであっても、URLがウェブ上の情報と関連付けば予告編を検索・再生できます。これにより、オフライン環境でも映画選びの質を向上させることができます。
· 新しい映画を探しているが、どの映画が良いか分からない時。この拡張機能を使って複数の映画の予告編を連続で視聴することで、直感的に好みの映画を見つけやすくなります。これは、映画のジャンルや俳優だけでなく、予告編の雰囲気で「この映画を観たい」という気持ちを喚起するのに役立ちます。
90
テスラ内蔵映像プラットフォーム
著者
tesladrivewatch
説明
テスラ車両の乗客向けに、YouTubeやその他の動画コンテンツを車載ディスプレイで直接視聴できる、画期的なプラットフォームです。特筆すべきは、テスラのAPIを巧みに利用し、外部デバイスなしでシームレスな体験を実現している点です。これにより、乗客は退屈な移動時間を、エンターテイメントや学習の時間に変えることができます。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、テスラ車の乗客が、YouTubeなどの動画コンテンツを車載ディスプレイで直接楽しめるようにする、非公式のアプリケーションです。技術的な核心は、テスラが提供するAPI(アプリケーション・プログラミング・インターフェース)を解析し、車載システムと連携させている点にあります。これにより、通常は外部デバイス(スマートフォンやタブレット)をミラーリングしたり、別途ストリーミングデバイスを接続したりする必要なく、直接動画を再生できます。これは、開発者がテスラ車の潜在能力を引き出し、ユーザー体験を向上させるという、まさに「ハッカー精神」の表れと言えます。つまり、テスラ車に乗っているだけで、移動中にエンタメや情報にアクセスできるようになる、ということです。
どのように使用しますか?
開発者は、GitHubで公開されているソースコードを基に、自身のテスラ車にこのプラットフォームをデプロイ(実装)することができます。具体的な手順は、プロジェクトのドキュメントに従うことになりますが、一般的には、テスラ車の開発者モードを有効にし、カスタムアプリケーションをインストールする形になります。これにより、車両のナビゲーション画面やエンターテイメントシステムに、YouTubeなどの動画プレーヤーが統合されます。このプロジェクトは、テスラ車を所有している開発者にとって、自身の車両の機能を拡張し、新しいユーザー体験を創造する絶好の機会を提供します。つまり、自分で車載システムに新しい機能を追加して、移動中をもっと楽しくできる、ということです。
製品の核心機能
· テスラ車載ディスプレイへの動画ストリーミング機能:テスラ車のAPIを活用し、YouTubeなどの外部動画サービスからのコンテンツを直接車載ディスプレイにストリーミングします。これにより、長距離移動や充電待ちの時間を有効活用できます。
· シームレスなUI/UX統合:テスラ車の既存のインターフェースと調和するように設計されており、直感的な操作で動画コンテンツにアクセスできます。これにより、複雑な設定なしで誰でも簡単に利用できます。
· オフライン再生機能(将来的な拡張性):現時点ではオンラインストリーミングが主ですが、将来的にはダウンロード機能なども検討される可能性があり、通信環境に左右されない利用も視野に入れています。これにより、電波の届きにくい場所でも動画を楽しめるようになります。
· カスタムコンテンツ対応の可能性:YouTube以外にも、開発者の手によって様々な動画ソースに対応させる拡張性を持たせています。これにより、個々のニーズに合わせた多様なエンターテイメント環境を構築できます。
製品の使用例
· 家族での長距離ドライブ中に、子供たちが車載ディスプレイで好きなYouTube動画を視聴できる。これにより、子供たちの退屈を防ぎ、親の運転への集中を助けます。
· テスラ車での充電待ち時間に、車を降りることなく、NetflixやAmazon Prime Videoなどのコンテンツを視聴できる。これにより、充電時間を有意義なエンターテイメントの時間に変えられます。
· 出張先への移動中に、車内で最新の技術系カンファレンス動画を視聴し、知識をアップデートできる。これにより、移動時間を自己成長の機会に変えられます。
· 開発者が自身のテスラ車にこのプラットフォームを導入し、友人や家族に披露することで、テスラ車のカスタマイズ性の高さをアピールできる。これにより、テスラ車のオーナーコミュニティ内での技術的な話題を提供できます。
91
PitchWell: AIパーソナル広報アシスタント
著者
maikop
説明
PitchWellは、AIを活用して、まるであなた自身が書いたかのような自然なトーンで、メディアやジャーナリストへのピッチ(売り込み)メールを自動生成するツールです。従来のツールと異なり、あなたの実際の文章スタイルを学習し、個々の連絡先を詳細にリサーチすることで、高いパーソナライズを実現し、広報活動の効率と効果を劇的に向上させます。これは、高額な広報代理店に依頼することなく、スタートアップ創業者などがプロレベルの広報ツールを利用できるようにするための革新的なソリューションです。
人気
ポイント 1
コメント 0
この製品は何ですか?
PitchWellは、AI「Winsley」があなたの文章スタイルを学習し、個別のメディア担当者やジャーナリストの情報をリサーチした上で、あなた自身の言葉で語りかけるようなパーソナライズされたピッチメールを作成するサービスです。従来のAIツールのように画一的なスタイルではなく、Exa(検索エンジン)とカスタムベクトル検索を組み合わせることで、関連性の高い連絡先を正確に見つけ出し、あなただけのユニークなピッチを作成します。これにより、メディア掲載の可能性を高めることができます。
どのように使用しますか?
開発者は、PitchWellにあなたの過去の執筆サンプルを提供することで、AIがあなたの声のトーンや表現スタイルを学習します。その後、ターゲットとするメディアやジャーナリストの情報を入力すると、Winsleyがそれらをリサーチし、あなた独自のピッチメールを生成します。生成されたメールはGmail経由で送信でき、フォローアップのスケジュール設定も可能です。これにより、広報担当者でなくとも、効率的かつ効果的にメディアへのアプローチを行えます。
製品の核心機能
· AIによる文章スタイル学習: あなたの実際の執筆スタイルをAIが模倣し、人間味あふれるピッチメールを生成します。これにより、受け取った相手も親近感を持ちやすくなります。
· 個別連絡先リサーチとパーソナライズ: Exaとカスタムベクトル検索を活用し、ターゲットとなるメディア担当者やジャーナリストを正確に特定し、彼らの関心事に合わせたピッチを作成します。これにより、画一的なメールではなく、響くメッセージを届けられます。
· Gmail統合とフォローアップ機能: 生成したピッチメールを直接Gmailから送信でき、フォローアップのスケジュール管理も可能です。これにより、一連の広報活動を一つのプラットフォームで完結させられます。
· 創業者のための手頃な広報ツール: 月額数千ドルの広報代理店費用をかけずに、プロフェッショナルな広報ツールを利用できます。これにより、予算の限られたスタートアップも広報活動を強化できます。
製品の使用例
· スタートアップ創業者が新製品発表のプレスリリースをメディアに送る際、AIが創業者自身の言葉遣いを模倣したパーソナライズされたメールを作成し、ジャーナリストの関心を引くことができた。これにより、メディア掲載の機会が大幅に増加した。
· フリーランスのジャーナリストが、特定のテーマに関する取材記事を執筆するために、関連する専門家や企業へのコンタクトを効率化したい場合。PitchWellは、テーマに合致する専門家を特定し、彼らの専門分野に合わせたアプローチメールを生成することで、迅速な情報収集を支援する。
· 小規模なソフトウェア開発チームが、自社製品のローンチを告知するために、テクノロジー系メディアへの露出を図りたい場合。PitchWellは、開発チームの技術的な強みや製品のユニークな点を捉え、テクノロジーライターに響くようなピッチメールを生成し、メディア露出の可能性を高める。
92
FeatureBranchBox
著者
rida
説明
FeatureBranchBoxは、複数のコーディングエージェントや複数の機能を同時に扱う際に発生する問題を解決するためのツールです。各機能ごとに、Gitワークツリー、開発コンテナ、Dockerネットワーク、データベース、ポート、環境変数などを完全に分離した、自己完結型の開発環境を構築します。これにより、並行開発時のコンテナのポート競合、ワークツリーのずれ、データベースの衝突、環境変数の漏洩といった問題を解消し、安全で管理しやすい開発ワークフローを実現します。
人気
ポイント 1
コメント 0
この製品は何ですか?
FeatureBranchBoxは、開発者が複数の機能やエージェントを同時に扱う際に発生する「環境の衝突」を防ぐためのツールです。従来の開発では、異なる機能の開発中に、データベースの設定が混ざったり、ポートが重複したり、環境変数が意図せず漏れたりすることがよくありました。FeatureBranchBoxは、各機能(フィーチャー)ごとに、あたかも別々のコンピューターで開発しているかのような、完全に独立した開発環境を作り出します。これには、それぞれの機能専用のコードの場所(Gitワークツリー)、開発用のコンテナ、ネットワーク、データベース、そしてポートなどが含まれます。これにより、開発者は他の機能に影響を与える心配なく、安心して作業を進めることができます。これは単なる隔離(サンドボックス)ではなく、実際に動作するコンテナやデータベースを利用しながら、それらを完全に分離し、意図しない干渉を防ぐ点が革新的です。あなたの開発作業を、より安全で管理しやすくします。
どのように使用しますか?
開発者はFeatureBranchBoxを使用して、各機能開発の開始時に専用の開発環境を起動します。例えば、新しい機能Aを開発する場合、FeatureBranchBoxコマンドを実行することで、機能A専用のGitワークツリー、Dockerコンテナ、ローカルデータベースなどが自動的にセットアップされます。これにより、機能Aの開発に必要なすべてのリソースが完全に分離され、既存の機能BやCの開発環境に一切影響を与えません。開発者は、IDE(統合開発環境)やDocker Composeなど、普段使用している開発ツールをそのまま、この分離された環境内で利用できます。また、必要に応じて、他の環境との安全な通信を可能にするトンネリング機能(現在はCloudflare Tunnel、今後ngrokにも対応予定)も設定できます。これにより、複数の開発プロジェクトや、AIコーディングエージェントが同時に動作するような複雑なシナリオでも、混乱なく効率的に作業を進めることができます。
製品の核心機能
· 機能ごとのGitワークツリー分離:各機能開発専用のコードベースを独立させることで、ブランチ間のコードの混同や競合を防ぎ、クリーンな開発状態を維持します。これは、複数の開発者が同じプロジェクトで作業する際や、自動化されたコーディングエージェントが同時にコードを生成する際に非常に役立ちます。
· 独立した開発コンテナ:各機能開発のために専用のコンテナ環境を提供し、依存関係やライブラリのバージョン競合を防ぎます。これにより、異なる機能で必要とされるソフトウェアのバージョンが異なっていても、互いに干渉することなく、それぞれの環境で正しく動作させることができます。
· 専用Dockerネットワーク:各機能開発環境は独自のDockerネットワークを持つため、ポートの衝突やネットワーク設定の干渉が起こりません。これにより、例えば機能Aでポート8080を使用し、機能Bでもポート8080を使用したい場合に、両方の環境を同時に問題なく実行できます。
· 分離されたデータベース:機能ごとに専用のデータベースインスタンスを起動することで、開発中のデータが意図せず他の機能のデータと混ざることを防ぎます。これは、データベーススキーマの変更やデータ操作を安全に行いたい場合に不可欠です。
· 専用ポート管理:各開発環境は独立したポートを持つため、複数のサービスやアプリケーションを同時に実行しても、ポートが競合する心配がありません。これにより、開発者はポート管理の煩雑さから解放されます。
· 環境変数の厳密な分離:各機能開発環境は独自の環境変数を持ち、他の環境に影響を与えることがありません。これにより、APIキーや設定値などの機密情報が意図せず漏洩したり、誤った設定が適用されたりするリスクを低減します。
· 安全な資格情報マウント(オプション):共有が必要な資格情報(例:クラウドサービスへのアクセスキー)を、安全かつ選択的に各環境にマウントできます。これにより、機密情報を安全に管理しつつ、必要な環境でのみ利用できるようにします。
· トンネリング機能(拡張性):Cloudflare Tunnelが現在サポートされており、将来的にはngrokもサポート予定です。これにより、ローカル開発環境を安全に外部と接続し、デモや外部サービスとの連携を容易にします。
製品の使用例
· 複数のAPIエンドポイントを同時に開発・テストするシナリオ:機能Aでユーザー認証APIを、機能Bで商品管理APIを開発している場合、それぞれ専用のデータベースとポートを持つ環境で作業することで、API間の依存関係を気にせず、単体での開発とテストを効率的に進めることができます。これにより、開発者は各APIのロジックに集中できます。
· 異なるデータベース技術やバージョンを併用するプロジェクト:ある機能ではPostgreSQLの最新版を、別の機能ではMySQLの特定のバージョンが必要な場合、FeatureBranchBoxを使えば、それぞれの機能専用のデータベース環境を容易に構築・管理できます。これにより、環境設定の複雑さに悩むことなく、必要な技術スタックで開発を進められます。
· AIコーディングエージェントと人間が共同で開発するワークフロー:AIエージェントがコードを生成し、人間がそれをレビュー・修正するような共同開発において、AIが生成したコードやその環境が、人間の開発環境に予期せぬ影響を与えることを防ぎます。各エージェントの作業を独立した環境で行うことで、コラボレーションをスムーズかつ安全に進めることができます。
· マイクロサービスアーキテクチャにおける各サービスの並行開発:複数のマイクロサービスが連携するシステムを開発する際、各サービスを独立した開発環境で実行・デバッグできます。これにより、サービス間の疎結合性を保ったまま、個々のサービスの開発効率を高め、デプロイメントの頻度を上げることができます。
· 実験的な機能や設定を安全に試したい場合:本番環境や既存の安定した開発環境に影響を与えることなく、新しいライブラリの導入、フレームワークのバージョンアップ、あるいは大規模な設定変更などを、隔離された環境で自由に試すことができます。これにより、リスクを最小限に抑えながら、技術的な探求を進めることができます。
93
ウェブサイトAI知識ベース化プロジェクト
著者
ahmedelhadidi
説明
このプロジェクトは、どんなウェブサイトでもAIエージェントが利用できる知識ベースに変換する革新的なツールです。ワンクリックでデプロイ可能で、無料で利用できます。ウェブサイトの情報をAIが理解・活用できる形式に自動で整形することで、情報収集や分析のプロセスを劇的に効率化します。
人気
ポイント 1
コメント 0
この製品は何ですか?
これは、ウェブサイトのコンテンツをAIが学習・参照できる形に自動で変換するシステムです。通常、AIがウェブサイトの情報を理解するには、HTML構造の解析やテキストの抽出、さらには情報の意味を理解するための複雑な前処理が必要ですが、このプロジェクトでは、これらの手間を省き、ウェブサイトのURLを指定するだけで、AIがすぐに利用できる形式(例えば、構造化されたデータや埋め込みベクトル)に変換する技術を採用しています。これにより、開発者はAIエージェントに特定のウェブサイトの知識を簡単に注入できるようになります。これは、AIの「学習」プロセスを、ウェブサイトという「情報源」に直接結びつける革新的なアプローチです。
どのように使用しますか?
開発者は、このツールのウェブインターフェースやAPIを通じて、知識ベース化したいウェブサイトのURLを指定するだけです。プロジェクトはバックグラウンドでウェブサイトのコンテンツを取得し、AIが理解しやすい形式に変換して、利用可能な知識ベースとして提供します。例えば、LangChainやLlamaIndexといったAIフレームワークと連携させることで、独自のAIエージェントにこのウェブサイトの知識を注入し、質問応答や要約などのタスクを実行させることが可能になります。これは、AIに特定のウェブサイトの専門知識を持たせたい場合に、非常に簡単かつ迅速な解決策となります。
製品の核心機能
· ウェブサイトURLからの自動コンテンツ抽出: 指定されたウェブサイトからテキストや関連情報を自動的に収集する技術。これにより、手動での情報収集の手間が省け、最新の情報も容易に取得できます。
· AI向けデータ形式への変換: 抽出した情報を、AIモデルが直接学習・参照できる形式(例: チャンク化されたテキスト、セマンティック検索に適したベクトル表現)に変換します。これにより、AIが効率的に情報を処理できるようになります。
· ワンクリックデプロイ: 複雑なセットアップなしに、すぐに利用を開始できるデプロイメント機能。開発者は、すぐにAIエージェントに知識を組み込む作業に集中できます。
· 無料利用: 開発コストを抑えながら、高度なAI機能を実現できるため、個人開発者やスタートアップにとって非常に価値が高いです。
· 外部AIフレームワークとの連携: LangChainやLlamaIndexなどの主要なAI開発フレームワークと容易に統合できる設計。これにより、既存のAI開発ワークフローにシームレスに組み込めます。
製品の使用例
· 特定の製品レビューサイトを知識ベース化し、AIチャットボットで製品の長所・短所について質問できるようにする。開発者は、製品のAPIがない場合でも、ウェブサイトの情報を活用して高度な顧客サポートAIを構築できます。
· 企業の公式ブログやドキュメントサイトを知識ベース化し、社内向けAIアシスタントが従業員の質問に的確に回答できるようにする。これにより、情報検索にかかる時間を削減し、生産性を向上させます。
· 学術論文や研究発表のウェブサイトを知識ベース化し、AIで関連研究の要約や新しい研究テーマの発見を支援する。研究者は、最新の研究動向を効率的に把握し、研究の方向性を定めるのに役立ちます。
· ニュースサイトの特定分野の記事を知識ベース化し、AIでその分野の最新動向の要約レポートを自動生成する。これにより、特定分野の専門家は、情報のキャッチアップを効率化できます。
94
tf-dialect: AI時代のTerraform標準化コーチ
著者
iacguy
説明
tf-dialectは、AIコーディングエージェントが生成するTerraformコードを、組織固有の標準や慣習に合わせて自動的に調整するツールです。これにより、AIがTerraform初心者でも、既存のインフラ管理ワークフローにスムーズに統合できるようになります。AIの力でTerraformをより身近にし、チーム全体のインフラ管理の質を向上させます。
人気
ポイント 1
コメント 0
この製品は何ですか?
tf-dialectは、AIが生成したTerraformコード(Infrastructure as Code - IaC)を、あなたのチームが定めた特定のルールや書き方に自動で合わせるための賢いアシスタントです。通常のAIは、Terraformを新しく始める場合には役立ちますが、すでに既存のプロジェクトがある場合、AIが勝手にコードを生成すると、チームのルールから外れてしまうことがあります。tf-dialectは、AIに「うちのチームの書き方」を教え込み、AIが生成するコードが常にチームの標準に沿うようにしてくれる、まさに「Terraformの言葉」をAIに理解させるためのツールです。これにより、AIと人間が協力して、より安全で一貫性のあるインフラを構築できるようになります。
どのように使用しますか?
開発者は、tf-dialectをAIコーディングエージェントのワークフローに組み込みます。例えば、AIに新しいインフラ構成を生成させる際に、tf-dialectに組織のTerraform標準(MCP - Managed Code Policy)を事前に学習させておきます。AIがTerraformコードを生成すると、tf-dialectがそのコードを解析し、MCPに準拠するように自動で修正を加えます。これにより、AIが生成したコードをそのまま利用しても、チームの品質基準を満たすことができます。Terraformの実行前や、コードレビューのプロセスに組み込むことで、コンプライアンスを維持し、手作業での修正コストを削減できます。
製品の核心機能
· AI生成Terraformコードの自動整形:AIが書いたTerraformコードを、チームのコーディング規約(命名規則、インデント、リソースの定義順など)に合わせて自動で綺麗に整形します。これにより、コードの可読性が向上し、レビューも容易になります。
· 組織固有のTerraform標準(MCP)適用:チームが独自に定めたTerraformのベストプラクティスやセキュリティポリシーをAIに学習させ、生成されるコードが常にそれらを遵守するようにします。これにより、インフラのガバナンスを強化し、潜在的なリスクを低減します。
· AIとIaCワークフローの統合支援:AIコーディングエージェントがTerraformコードを生成する際の、組織の標準への準拠を保証します。AIの能力を最大限に活かしつつ、インフラ管理の質を維持・向上させるための架け橋となります。
· Terraformコードのコンテキストアウェアな生成支援:AIが、既存のインフラ構成やチームのルールを理解した上で、より適切なTerraformコードを生成できるよう支援します。これにより、無駄のない、効率的なインフラ構築が可能になります。
製品の使用例
· 新規プロジェクトの立ち上げ:AIにインフラ構成を生成させたいが、チームのTerraform標準に沿わせたい場合。tf-dialectを使えば、AIが生成したコードをそのまま利用でき、手作業での修正時間を大幅に削減できます。
· 既存プロジェクトへの機能追加:AIにTerraformモジュールやリソースの追加を依頼する際。tf-dialectは、既存のコードベースやチームの慣習を考慮したコード生成をAIに促し、一貫性を保ちます。
· Terraformコードレビューの効率化:AIが生成したコードが、tf-dialectによって既に標準化されているため、コードレビューの焦点はロジックの正しさやビジネス要件への適合性に絞りやすくなります。レビュー担当者の負担が軽減されます。
· Terraform学習者の支援:Terraformに不慣れな開発者や、AIの助けを借りたい初心者でも、tf-dialectがチームの標準に沿ったコードを生成するため、安心してTerraformを使い始めることができます。AIによる学習コストを低減させます。
95
エージェント可視化ダッシュボード
著者
ktotheb
説明
このプロジェクトは、AIエージェントの動作を直感的に理解し、デバッグや改善を容易にするための視覚的なダッシュボードです。特にCursorというIDE(統合開発環境)と連携し、AIエージェントがどのような思考プロセスを経て、どのような行動をとっているのかをリアルタイムで追跡・表示します。これにより、AIエージェント開発におけるブラックボックス化を解消し、開発者がより効率的に、そして創造的にAIエージェントを構築できるようになります。
人気
ポイント 1
コメント 0
この製品は何ですか?
これはAIエージェントの「思考の見える化」ツールです。AIエージェントは、プログラムのようにコードを実行してタスクをこなしますが、その内部で何が起きているのか、なぜその結論に至ったのかを理解するのは難しい場合があります。このダッシュボードは、AIエージェントの意思決定プロセス、参照した情報、実行したステップなどを視覚的に表示することで、開発者がAIエージェントの振る舞いを正確に把握できるようにします。これにより、問題の特定や予期せぬ動作の修正が格段に容易になります。革新的な点は、AIエージェントの内部状態をグラフィカルに表現することで、開発者の理解を深め、AI開発のスピードと質を向上させる点です。
どのように使用しますか?
開発者は、Cursor IDE内でこのダッシュボードを有効化します。AIエージェントが実行されると、その活動がリアルタイムでダッシュボードに反映されます。例えば、AIエージェントが特定の情報を検索し、それを元に回答を生成する過程が、ツリー構造やタイムラインで表示されます。これにより、開発者はAIエージェントの思考の断片を追跡し、どこで改善が必要か、あるいはどこがうまく機能しているのかを具体的に把握できます。これは、AIエージェントのデバッグ、パフォーマンスチューニング、そして新しい機能の実験に役立ちます。つまり、AIエージェント開発の「デバッグモード」を視覚的に提供するようなものです。
製品の核心機能
· AIエージェントの思考パスの視覚化: AIがどのようなステップを踏んで意思決定しているかをツリー構造などで表示し、問題箇所や効率的な経路の特定を可能にします。これにより、AIの思考プロセスを理解し、改善策を見つけやすくなります。
· エージェントの内部状態のリアルタイム監視: AIが現在どのような情報にアクセスし、どのような状態にあるかをリアルタイムで把握できます。これにより、AIの挙動を即座に確認し、予期せぬ動作に素早く対応できます。
· Cursor IDEとのシームレスな連携: Cursor IDEの機能と統合されており、追加の設定なしでAIエージェントのデバッグを容易にします。開発者は普段使い慣れた環境で、AIエージェントの内部を深く理解できます。
· エージェントの行動履歴の記録と再生: AIエージェントの過去の実行履歴を保存し、後から分析や再現が可能です。これにより、複雑な問題を追跡し、原因究明や再現性を高めることができます。
製品の使用例
· AIチャットボット開発: ユーザーからの質問に対してAIチャットボットがどのように回答を生成しているのか、どの情報源を参照したのかを視覚的に確認することで、回答の精度向上や不適切な応答の修正に役立ちます。例えば、チャットボットが誤った情報を基に回答した場合、どの情報源が原因かを特定しやすくなります。
· AIによるコード生成ツールのデバッグ: AIがコードを生成する際に、どのようなロジックでコードを組み立てているのかを視覚化することで、生成されるコードの品質を改善し、バグを減らすことができます。例えば、AIが意図しないコードを生成した場合、その思考プロセスを追って原因を突き止められます。
· AIエージェントの自動タスク実行における問題解決: AIエージェントが自動でウェブサイトの情報を収集したり、レポートを作成したりする際に、予期せぬエラーが発生した場合、その原因を視覚的に特定し、タスク実行をスムーズに進めることができます。例えば、AIが特定のウェブサイトから情報を取得できない場合、その原因がネットワークの問題なのか、サイトの構造変化なのかを特定しやすくなります。
96
ThinkReview: プライベートコードレビューAIアシスタント
著者
jkshenawy22
説明
ThinkReviewは、ブラウザ上で動作する軽量なオープンソースのAIアシスタントです。プルリクエスト(PR)やマージリクエスト(MR)のレビューを、コードを外部サービスに送信することなく、ブラウザ内で完結させることができます。特に、ローカル環境でLLM(大規模言語モデル)を実行できるOllamaをサポートしている点が画期的です。これにより、コードのプライバシーを完全に保護しながら、AIによるコードレビューの支援を受けることが可能になります。
人気
ポイント 1
コメント 0
この製品は何ですか?
ThinkReviewは、GitLab、Azure DevOps、GitHub、Bitbucketなどのコードホスティングプラットフォームで、プルリクエストやマージリクエストのレビュープロセスを支援するために設計されたブラウザ拡張機能です。従来の自動コメントを生成するAIツールとは異なり、ThinkReviewはレビュー担当者専用のプライベートチャットウィンドウを提供します。このチャットを通じて、AIにリクエストのロジックについて質問したり、潜在的なバグを特定させたり、レビューコメントのドラフトを生成させたりすることができます。AIが自動的にコメントを投稿することはないため、レビュー担当者は常にコードレビューのプロセスを完全にコントロールできます。特に、コードが外部に送信されることを懸念する開発者や、ローカル環境での作業を好む開発者にとって、プライバシーを保ちながらAIの支援を受けられるという点で革新的なソリューションと言えます。
どのように使用しますか?
開発者は、ChromeウェブストアからThinkReviewブラウザ拡張機能をインストールするだけで利用を開始できます。インストール後、GitLab、Azure DevOps、GitHub、BitbucketなどのプラットフォームでPR/MRを開くと、インターフェースにThinkReviewのチャットウィンドウが表示されます。APIキーの設定は不要で、ローカルLLM(Ollama)を使用する場合は、Ollamaインスタンスのアドレスを指定するだけで設定が完了します。これにより、開発者は普段利用しているコードレビューのワークフローをほとんど変更することなく、AIによるコードレビュー支援の恩恵を受けることができます。例えば、PRの差分を見ながら、「この関数の目的は何ですか?」とか、「この変更によってパフォーマンスに影響はありますか?」といった質問をAIに投げかけることができます。
製品の核心機能
· プライベートAIチャットインターフェース: レビュー対象のコード差分に紐づいたチャットウィンドウを提供し、コードに関する質問や議論をプライベートに行えます。これにより、コードの機密性を保ちながらAIの分析結果を活用できます。
· ローカルLLM(Ollama)サポート: Ollamaを介してローカルで実行されているLLM(Codestral、Llama 3など)に接続できます。これにより、コードがインターネット上に送信されることなく、完全なプライバシーとセキュリティを確保したコードレビューが可能になります。
· 多様なコードホスティングプラットフォーム連携: GitLab(セルフホスト版含む)、Azure DevOps、GitHub、Bitbucketといった主要なプラットフォームのPR/MRインターフェースにシームレスに統合されます。これにより、既存の開発ワークフローに容易に組み込めます。
· AIによるコード分析とコメントドラフト生成: コードのロジック理解、潜在的なバグの発見、レビューコメントのドラフト生成をAIが支援します。これにより、レビュー担当者の負担を軽減し、レビューの質と速度を向上させます。
· ユーザー主導のAIインタラクション: AIが自動的にコードにコメントを投稿するのではなく、ユーザーの指示に基づいて応答します。これにより、レビュー担当者は常にレビュープロセスを完全に制御でき、AIの提案を吟味してから採用することができます。
製品の使用例
· セルフホスト型GitLab環境でのプライベートコードレビュー: 自社でGitLabを運用しており、コードの外部送信を厳しく制限している企業で、ThinkReviewをローカルLLM(Ollama)と組み合わせて利用します。開発者はPRの差分を見ながら、AIに「このコードのセキュリティ上の脆弱性はありますか?」と質問し、ローカルのLLMが回答します。これにより、外部サービスにコードを送信することなく、AIによる高度なレビュー支援を受けられます。
· 機密性の高いプロジェクトにおけるAIコードレビュー: 金融や医療分野など、非常に機密性の高いコードを扱うプロジェクトでThinkReviewを使用します。AIに「この関数の意図と、潜在的なエッジケースについて説明してください」と指示し、ローカルのLLMがコードを分析して回答します。これにより、コードのプライバシーを維持しながら、コードの品質と安全性を高めることができます。
· 個人開発者による効率的なコードレビュー: 個人で開発を進める際、自分自身のコードレビューを効率化したい場合にThinkReviewを活用します。PRを開き、AIに「このコードの可読性を向上させるための提案はありますか?」と質問し、AIからのフィードバックを参考にコードを改善します。これにより、一人でも質の高いコードレビュープロセスを実践できます。
· リモートワーク環境でのコラボレーション支援: チームメンバーがリモートで作業している場合、ThinkReviewを通じてコードレビューに関する質問や懸念事項をAIに投げかけ、その回答を共有することで、非同期のコミュニケーションを円滑に進めることができます。例えば、「この機能のテストカバレッジは十分ですか?」といった質問をAIに投げかけ、その回答をチーム内で議論する材料とします。