Show HN Today: Discover the Latest Innovative Projects from the Developer Community
 ShowHN Today
ShowHN Today
- Continue with Google
Show HN Today: Top Developer Projects Showcase for 2025-11-14
SagaSu777 2025-11-15
Explore the hottest developer projects on Show HN for 2025-11-14. Dive into innovative tech, AI applications, and exciting new inventions!
Summary of Today’s Content
Trend Insights
The landscape of software development is rapidly evolving, with a clear surge in projects leveraging AI and agent-based architectures to solve complex problems. We're seeing a strong hacker ethos emerge, where developers are not just building tools, but creating solutions that empower others to work smarter and more securely. The emphasis on local-first and privacy-centric tools, like offline dictation apps and encrypted password managers, reflects a growing demand for user control and data sovereignty. For developers, this signals a prime opportunity to dive into the burgeoning field of AI agents, exploring how to build systems that can autonomously manage tasks, analyze data, and even write code. For entrepreneurs, the takeaway is clear: identify specific pain points within niche domains, like data engineering or embedded systems, and apply innovative AI or automation solutions. The open-source community continues to be a fertile ground for rapid iteration and collaborative problem-solving, so contributing to or building upon existing open projects can accelerate innovation and build valuable networks. The future belongs to those who can combine deep technical understanding with creative problem-solving to build tools that are both powerful and ethical.
Today's Hottest Product
Name
Zingle – AI code reviewer for data teams
Highlight
This project tackles the critical problem of ensuring data pipeline integrity and cost efficiency. It uses AI to analyze SQL, dbt, Airflow, and Spark code changes in pull requests, predicting cost regressions, logic issues, and potential data quality gaps. The innovation lies in applying AI to the specific, high-stakes domain of data engineering, where a single incorrect change can lead to significant financial losses. Developers can learn about applying AI to specialized code analysis, understanding the unique risks associated with data infrastructure, and building robust validation systems. The developer's personal anecdote of a $50k Snowflake bill highlights the real-world impact of such a solution.
Popular Category
AI/ML
Developer Tools
Data Engineering
Open Source
Productivity
Popular Keyword
AI
Code Review
Data Teams
Kubernetes
Agents
LLM
Open Source
Local First
Privacy
Technology Trends
AI-Powered Code Analysis
Agent-Based Systems
Local-First and Privacy-Focused Tools
Developer Productivity Enhancements
Infrastructure as Code Automation
AI for Specialized Domains
Open Source Community Collaboration
Efficient Data Handling and Processing
Project Category Distribution
AI/ML Tools & Frameworks (25%)
Developer Productivity & Tools (20%)
Data Management & Analysis (15%)
Open Source Infrastructure (15%)
Utility & Niche Applications (15%)
Educational & Content Tools (10%)
Today's Hot Product List
| Ranking | Product Name | Likes | Comments |
|---|---|---|---|
| 1 | EpsteinFiles Explorer | 277 | 45 |
| 2 | Encore: Type-Safe Backend Infra Generator | 71 | 47 |
| 3 | EuroTech Navigator | 42 | 39 |
| 4 | Pegma: Cross-Platform Peg Solitaire Engine | 32 | 48 |
| 5 | Dumbass Business Idea Generator | 33 | 30 |
| 6 | Chirp: Local Speech-to-Text Injector | 29 | 15 |
| 7 | Jujutsu Visual Navigator | 7 | 10 |
| 8 | spymux: Cross-Pane State Monitor | 9 | 3 |
| 9 | TalkiTo: Voice-Enabled Coding Agents | 5 | 5 |
| 10 | DataSentinel AI | 6 | 4 |
1
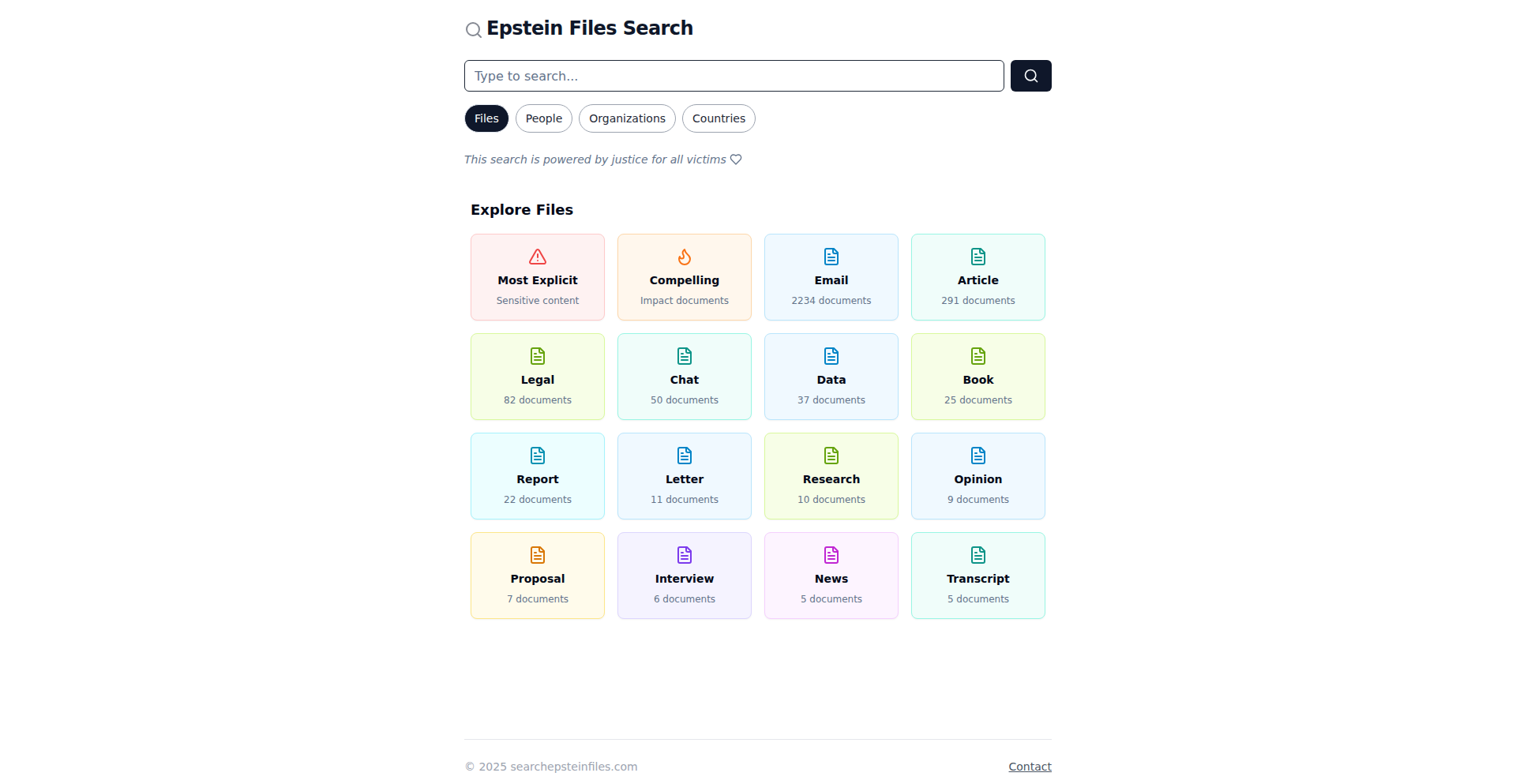
EpsteinFiles Explorer
Author
searchepstein
Description
A project that organizes and makes the Epstein files searchable, leveraging data structuring and search technology to enhance transparency and facilitate research. It transforms raw data into an accessible, navigable resource.
Popularity
Points 277
Comments 45
What is this product?
EpsteinFiles Explorer is a web-based application designed to process and present the publicly available Epstein files in a structured and searchable format. Instead of wading through raw documents, users can interact with organized data, powered by underlying search algorithms and data processing techniques. The innovation lies in transforming a large, complex dataset into a usable research tool, making connections and information more apparent than in the original format. This is useful because it saves significant time and effort for anyone trying to understand the scope and details within these extensive files, offering clarity where there was once just a deluge of information.
How to use it?
Developers can use EpsteinFiles Explorer by accessing the provided web interface. The project's underlying data processing and search mechanisms can potentially be integrated into other research tools or platforms via APIs (though this specific project might be a standalone interface). The core value for developers is understanding how to structure and query large, unstructured datasets effectively. For instance, a developer working on historical archives or investigative journalism tools could learn from the data normalization and indexing strategies employed. This means they can apply similar techniques to their own projects to make disparate information sources more accessible and insightful.
Product Core Function
· Data Structuring: Organizes raw document data into a more coherent format, making it easier to process and understand. This provides a foundation for better analysis, helping researchers avoid missing crucial pieces of information by presenting it in a logical flow.
· Search Functionality: Implements an efficient search engine to quickly find specific information within the organized files. This saves significant time for users trying to locate particular names, dates, or keywords, directly addressing the challenge of sifting through vast amounts of text.
· Information Visualization (Implied): While not explicitly detailed, the organization of data suggests potential for visualizing relationships and patterns, aiding in comprehension and discovery. This can reveal connections that might be overlooked in a linear document review, offering a deeper understanding of the overall context.
Product Usage Case
· Investigative Journalism: A journalist can use EpsteinFiles Explorer to quickly cross-reference names and events across multiple documents, speeding up fact-checking and the identification of leads. This solves the problem of tedious manual searching and correlation.
· Academic Research: A researcher studying social networks or financial transactions can use the searchable database to identify patterns and connections between individuals and organizations. This makes it easier to gather evidence and support hypotheses, overcoming the difficulty of manually piecing together information from scattered sources.
· Public Interest Advocacy: An organization focused on transparency can leverage the organized files to build reports or create accessible summaries for the public. This allows them to communicate complex information more effectively and engage a wider audience with factual data, transforming raw data into understandable insights.
2
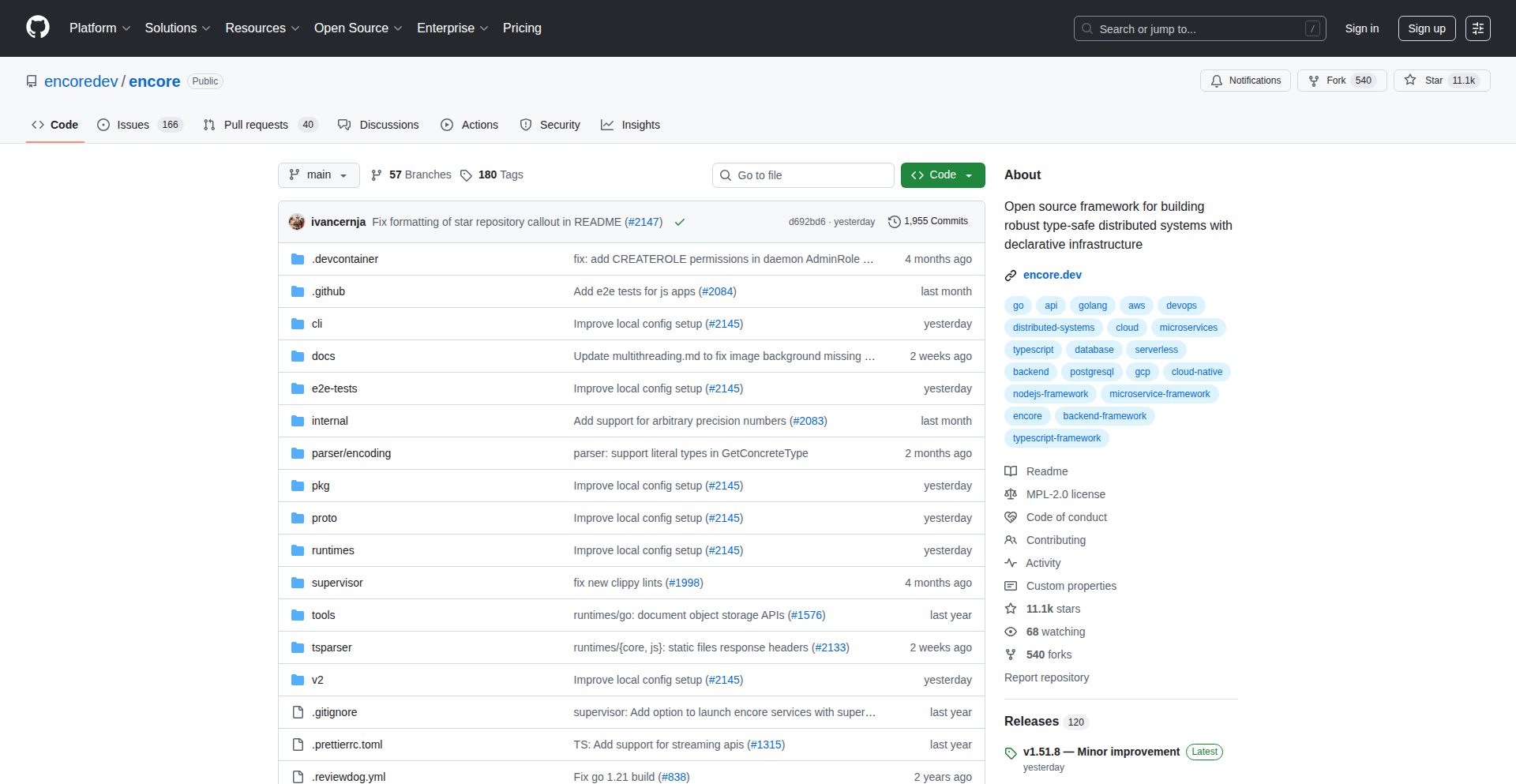
Encore: Type-Safe Backend Infra Generator
Author
andout_
Description
Encore is a novel backend framework that bridges the gap between code and infrastructure. It allows developers to define backend services and their infrastructure requirements directly within their code, which Encore then automatically provisions and deploys. The core innovation lies in its type-safe approach, ensuring that infrastructure configurations match the code's expectations, thereby reducing deployment errors and accelerating development cycles.
Popularity
Points 71
Comments 47
What is this product?
Encore is a backend development framework that generates your cloud infrastructure directly from your code. Imagine writing your API endpoints and database schemas, and Encore automatically creates the necessary servers, databases, and networking configurations in your cloud provider. Its key technical innovation is type-safety. This means that the infrastructure Encore builds is guaranteed to be compatible with your application code. This is a significant leap from traditional methods where infrastructure setup is often a separate, manual, and error-prone process, leading to 'it works on my machine' issues that are hard to debug.
How to use it?
Developers can start using Encore by defining their backend services using Encore's language. Encore handles the rest. For example, if you define a service that needs a PostgreSQL database, Encore will automatically provision and configure a managed PostgreSQL instance for you. You can integrate Encore into your existing CI/CD pipelines. When you push code changes, Encore can automatically update your deployed infrastructure and application. This dramatically simplifies the deployment and management of backend applications, allowing developers to focus on writing business logic rather than wrestling with cloud provider configurations.
Product Core Function
· Type-safe service definition: Allows developers to define backend services and their dependencies using a type-safe language. The value is that it prevents runtime errors caused by mismatches between code and infrastructure, making deployments more reliable and predictable. This is useful for any backend developer who wants to avoid tedious debugging of infrastructure-related issues.
· Automatic infrastructure generation: Automatically provisions and configures cloud infrastructure (like databases, queues, APIs) based on code definitions. The value is that it drastically reduces the manual effort and expertise required for cloud deployment, enabling faster iteration and time-to-market. This is particularly valuable for startups and small teams who need to deploy quickly without dedicated DevOps personnel.
· Integrated deployment pipeline: Seamlessly integrates with CI/CD workflows to deploy code and infrastructure updates. The value is that it automates the entire release process, from code commit to production deployment, minimizing human error and ensuring consistent deployments. This is beneficial for all development teams looking to streamline their release management.
· Built-in observability: Provides out-of-the-box logging, tracing, and metrics for applications and their infrastructure. The value is that it gives developers immediate insights into how their application and infrastructure are performing, making it easier to identify and resolve issues. This is essential for maintaining healthy and performant applications.
· Language flexibility: Supports multiple popular programming languages for backend development. The value is that developers can use their preferred language while still benefiting from Encore's infrastructure automation. This makes adoption easier and doesn't force developers into a new, unfamiliar language just for infrastructure management.
Product Usage Case
· Building a new microservice: A developer building a new microservice can define their API endpoints and specify a Redis cache. Encore will automatically set up the API gateway, server instances, and provision and connect the Redis cache, all without the developer needing to interact with AWS, GCP, or Azure consoles directly. This speeds up the development and deployment of individual services.
· Migrating a monolithic application: A team can break down a monolith into smaller services. For each new service, they can define its database requirements (e.g., a new SQL table). Encore will manage the creation of new database instances or schemas, making the migration process smoother and less risky. This helps in gradually refactoring legacy systems.
· Rapid prototyping: A developer needs to quickly build a prototype that involves a web API and user authentication. By using Encore, they can define these components in code, and Encore will provision the necessary backend services and database to support authentication, allowing them to focus on the core functionality of the prototype.
· Serverless function deployment: Defining a set of serverless functions and their triggers (e.g., HTTP requests, queue events). Encore will configure the serverless platform, set up the triggers, and manage the deployments, abstracting away the complexities of serverless orchestration. This is useful for building event-driven applications efficiently.
3
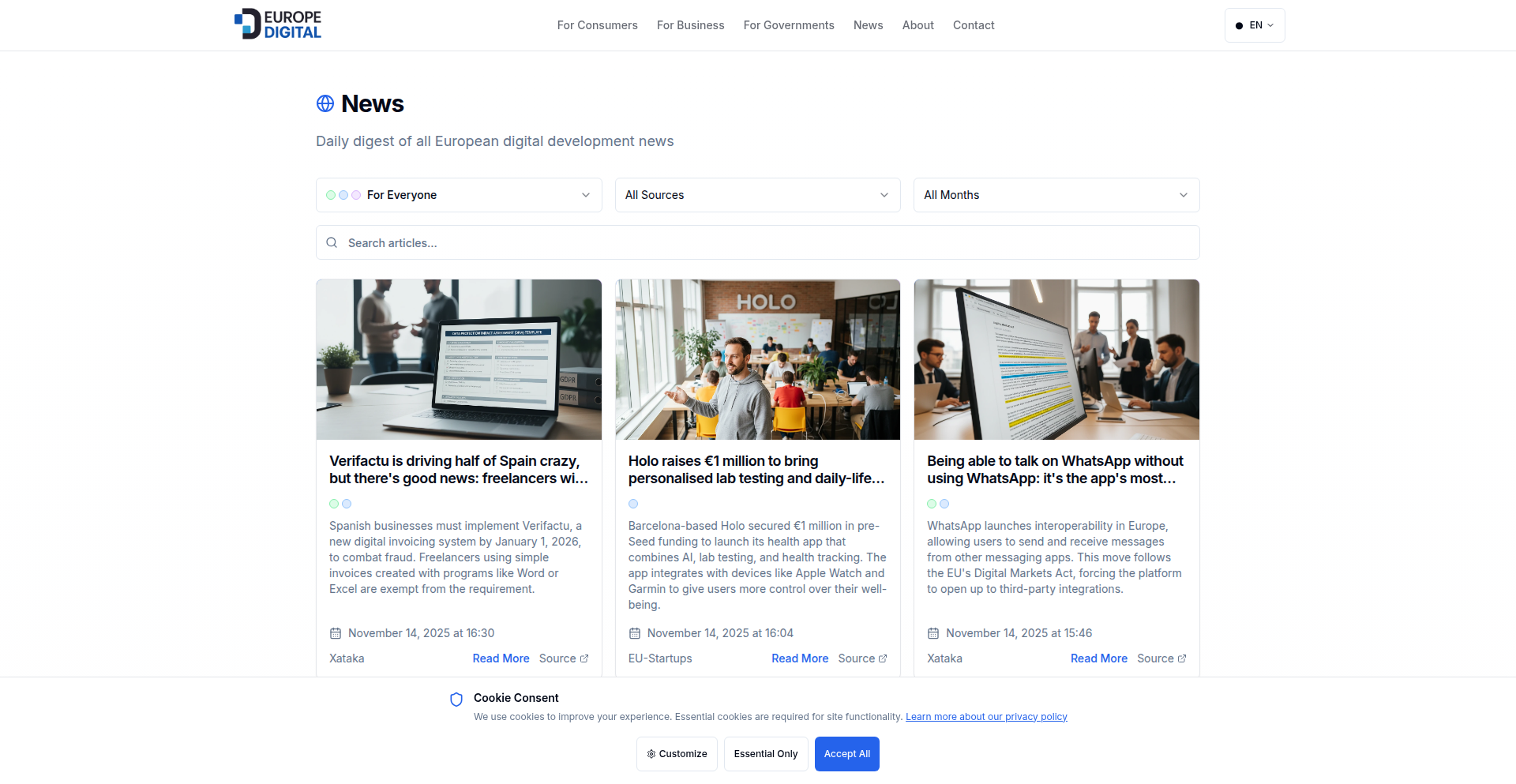
EuroTech Navigator
Author
Merinov
Description
A multilingual news aggregator focusing on European tech, offering content in 6 languages and filterable by audience type (consumers, businesses, government). It tackles common challenges like generic AI image generation by using context-aware visual patterns, improves search engine indexing for new sites with a gradual sitemap growth strategy, and employs an automated translation pipeline with human review for quality assurance. This project aims to make it easier to discover relevant European technological alternatives and innovations.
Popularity
Points 42
Comments 39
What is this product?
EuroTech Navigator is a specialized news platform designed to surface technology news originating from Europe. Instead of generic AI-generated images that all look the same, it uses a database of over 60 specific visual patterns that are contextually chosen. For example, news about funding might show coins or contracts, while security news might feature locks or shields, leading to much richer visual diversity. For newly launched websites, it addresses the slow indexing problem by gradually increasing the number of articles submitted to search engines over time, rather than overwhelming them at once. This ensures more content gets discovered by users. The platform also automates the process of summarizing and translating news articles from various RSS feeds using AI, with a human review step to maintain high translation quality. Essentially, it's a smart system for discovering and understanding European tech news.
How to use it?
Developers can use EuroTech Navigator as a valuable resource for staying updated on European technology trends, potential competitors, or collaboration opportunities. It can be integrated into research workflows by subscribing to curated feeds or using its API (if available in the future) to pull specific types of news into internal dashboards or analysis tools. The audience filters (consumers, businesses, government) allow for highly targeted information retrieval, making it efficient for product managers, market researchers, and investors. For those building multilingual applications or services, the project's approach to translation and multilingual SEO offers valuable insights and potential inspiration for their own strategies.
Product Core Function
· Multilingual News Aggregation: Aggregates tech news from European sources in English, German, French, Spanish, Italian, and Dutch. This is valuable for developers who need to understand global tech landscapes beyond their primary language and for companies looking to expand into European markets.
· Audience-Specific Filtering: Allows users to filter news based on whether it's most relevant to consumers, businesses, or government. This saves time by cutting through noise and delivering information tailored to specific professional interests or research goals.
· Context-Aware Visual Pattern Generation: Creates unique and relevant images for news articles based on their content, avoiding generic AI art. This enhances user engagement and makes content more memorable and impactful, useful for content creators and designers.
· Gradual Sitemap Growth Strategy: Implements a dynamic sitemap that slowly increases the number of URLs submitted to search engines. This improves the indexing rate for new content, ensuring that newly featured European innovations are discoverable by a wider audience over time.
· Automated Translation Pipeline: Uses AI for summarizing and translating news articles, followed by human review for accuracy. This provides accessible content across languages and sets a benchmark for quality in automated translation workflows, beneficial for developers working with international audiences.
· Discovery of European Tech Alternatives: Specifically highlights European companies and their products, providing valuable insights for developers seeking European-based solutions or looking to benchmark against regional players.
Product Usage Case
· A developer working on a new fintech product needs to understand the competitive landscape in Europe. By using EuroTech Navigator and filtering for 'businesses,' they can quickly identify emerging European fintech companies, their funding rounds, and key technological advancements, helping them refine their product strategy and identify potential partners.
· A marketing manager for a European software company wants to track news that might impact their target audience (both consumers and businesses). They can use the platform to see which European tech trends are gaining traction among different segments, informing their campaign messaging and product positioning.
· A researcher studying AI adoption in Europe can leverage EuroTech Navigator to discover news related to AI startups and government initiatives, benefiting from the context-aware image generation that makes the articles more visually engaging and the multilingual support that ensures comprehensive coverage.
· A developer building a global platform wants to improve their multilingual SEO strategy. By observing how EuroTech Navigator implements gradual sitemap growth and its approach to translation quality, they can gain practical ideas for optimizing their own site's discoverability and user experience in different languages.
4
Pegma: Cross-Platform Peg Solitaire Engine
Author
GlebShalimov
Description
Pegma is an open-source reimplementation of the classic Peg solitaire game, focusing on a clean, minimal design and smooth cross-platform gameplay. Its innovation lies in its accessibility as a fully open-source project, allowing for community contributions and transparency. The project demonstrates a developer's ability to take a well-known puzzle and make it readily available and customizable for modern platforms, showcasing clean UI/UX principles and efficient cross-platform development.
Popularity
Points 32
Comments 48
What is this product?
Pegma is a reimplementation of the traditional Peg solitaire game, a logic puzzle where the objective is to remove all but one peg from a board by jumping pegs over adjacent ones. The core technical innovation here is the development of a lightweight, cross-platform application that runs seamlessly on iOS and Android. This is achieved by leveraging modern mobile development frameworks that allow code to be written once and deployed across multiple operating systems, reducing development time and ensuring a consistent user experience. The 'open-source' aspect is a key differentiator, meaning anyone can view, modify, and contribute to the game's code, fostering transparency and potential for future enhancements by the developer community. It's about making a classic game accessible and adaptable using modern engineering practices.
How to use it?
Developers can use Pegma as a foundation or inspiration for their own game development projects. The open-source nature means you can fork the GitHub repository and customize it. For example, you could integrate Pegma's game logic into a larger application, experiment with different board layouts, or even adapt the rendering engine for unique visual styles. For end-users, it's a simple, enjoyable puzzle game available on iOS and Android app stores, offering a distraction and a mental workout with its timeless mechanics.
Product Core Function
· Cross-platform mobile deployment: The ability to run on both iOS and Android from a single codebase demonstrates efficient use of cross-platform development tools, reducing the effort needed to reach a wider audience.
· Open-source game logic: The entire game's rules and mechanics are available for inspection and modification. This allows developers to understand how a classic puzzle is implemented and to learn from the code, fostering knowledge sharing within the community.
· Minimalist UI/UX design: The focus on a clean and intuitive interface ensures that the game is easy to pick up and play, regardless of the user's technical background. This highlights the value of user-centered design in application development.
· Custom font integration: The developer designed a unique font to enhance the game's aesthetic. This shows attention to detail and a commitment to creating a distinct visual identity for the product, a common practice in app development to stand out.
· High-performance gameplay: Smooth animations and responsive controls are crucial for a good gaming experience. The project likely employs efficient rendering techniques and game loop management to ensure a fluid and enjoyable play session.
Product Usage Case
· A developer wants to create a collection of classic puzzle games for mobile. They can leverage Pegma's existing, well-tested game logic as a starting point, significantly speeding up their development process and focusing on building other puzzles.
· An educational technology company could integrate Pegma into a learning platform to teach logic and problem-solving skills. The open-source nature allows them to potentially modify the game to include specific educational objectives or track player progress.
· A game designer looking to experiment with different puzzle mechanics could analyze Pegma's implementation. By understanding how the peg jumping and removal logic works, they can gain insights into designing their own unique puzzle interactions.
· A hobbyist developer interested in open-source projects can explore Pegma's codebase on GitHub to learn about mobile game development best practices, cross-platform strategies, and C# scripting within a game engine context.
5
Dumbass Business Idea Generator
Author
elysionmind
Description
A web application that generates hilariously bad business ideas, sparking creativity by exploring the absurd. It tackles the problem of creative block and the need for unconventional inspiration by presenting deliberately flawed startup concepts, encouraging users to think outside the box.
Popularity
Points 33
Comments 30
What is this product?
This is a fun and experimental web application designed to generate intentionally terrible business ideas. It uses a combination of predefined templates and randomized elements to construct absurd startup concepts. The innovation lies in its deliberate subversion of typical business idea generation, aiming to provoke laughter and unconventional thinking rather than practical solutions. Think of it as a 'reverse brainstorming' tool to break through creative ruts.
How to use it?
Developers can use this project as a source of unexpected inspiration for creative coding challenges, quirky side projects, or even as a humorous icebreaker in team meetings. It can be integrated into other applications to add a layer of serendipitous silliness, perhaps by suggesting absurd features for a product or random plot points for a game. The core idea is to leverage the unexpected output for creative exploration.
Product Core Function
· Randomized Business Idea Generation: Leverages a templating system combined with a curated list of absurd product/service categories and target demographics to create unique and nonsensical business concepts. This helps users overcome blank page syndrome by providing a starting point, even if it's a ridiculous one.
· Humorous Presentation: Presents generated ideas with a witty and self-deprecating tone, enhancing the entertainment value and making the experience engaging. This makes the act of 'failure' in business idea generation enjoyable and memorable.
· User Submission Platform: Allows users to submit their own terrible business ideas, fostering a community around creative absurdity and expanding the pool of humorous concepts. This democratizes the generation process and turns it into a collaborative game.
· Sharing Functionality: Enables users to easily share their favorite (or least favorite) business ideas with friends, facilitating word-of-mouth spread and increasing engagement. This turns a personal creative exercise into a social activity.
Product Usage Case
· Creative Coding Challenge: A developer needs to build a small, fun web application for a hackathon. They can use this project's codebase as a base or inspiration to create a similar generator for other absurd themes (e.g., 'Dumbest Inventions,' 'Worst Pet Ideas'). It solves the problem of finding a unique and engaging project theme quickly.
· Game Design Inspiration: A game developer is stuck on creating interesting and quirky non-player characters (NPCs) or quest ideas. By feeding the generated business ideas into a narrative engine, they can create unexpected and memorable game elements. This helps in breaking predictable design patterns.
· Marketing Campaign Brainstorming: A marketing team wants to create a viral social media campaign that's unconventional. They can use this tool to generate a list of outlandish concepts, then pick the most outrageous ones to build a humorous and shareable campaign around. This addresses the need for attention-grabbing content in a crowded digital space.
· Team Building Icebreaker: During a remote team meeting, a facilitator can use this project to generate a few business ideas and have the team vote on the 'worst' one. This injects humor and lightheartedness into the meeting, improving team morale and collaboration. It provides a simple, low-stakes activity to foster connection.
6
Chirp: Local Speech-to-Text Injector
Author
whamp
Description
Chirp is a Windows dictation application designed for locked-down environments where installing new executables is restricted. It leverages NVIDIA's ParakeetV3 model for fast, accurate, and fully local speech-to-text conversion without requiring a GPU. The innovation lies in its Python-based execution managed by `uv`, enabling it to run where traditional `.exe` installations are forbidden, and its direct text injection into active windows, bypassing clipboard limitations.
Popularity
Points 29
Comments 15
What is this product?
Chirp is a local, privacy-focused dictation tool for Windows. Its core innovation is running entirely within a Python environment, meaning you don't need to install any new `.exe` files, making it ideal for restricted corporate networks. It uses the ParakeetV3 speech-to-text model, which is known for its high accuracy (comparable to Whisper-large-v3) but is significantly faster and can run efficiently on your computer's CPU. This means you get fast and accurate transcription without sending your voice data to the cloud or needing a powerful graphics card. The value for you is having a powerful dictation tool that respects your environment's security policies and your data privacy.
How to use it?
To use Chirp, you first perform a one-time setup to download and prepare the speech-to-text model. This involves running a Python command like `uv run python -m chirp.setup`. Once the model is ready, you start a long-running command-line process using `uv run python -m chirp.main`. Chirp then listens for a global hotkey you configure. When activated, it records your voice and automatically types the transcribed text directly into whatever application window is currently active. This offers a seamless dictation experience into your documents, emails, or code editors without manual copy-pasting.
Product Core Function
· Local Speech-to-Text Conversion: Processes audio directly on your machine using ONNX Runtime, ensuring data privacy and compliance with restrictive environments. This is valuable because your sensitive voice data stays on your computer.
· Executable-Free Operation: Runs using Python and `uv`, eliminating the need to install `.exe` files. This is crucial for users in locked-down corporate settings where software installation is heavily controlled.
· Direct Text Injection: Automatically types transcribed text into the active window, simplifying workflow and avoiding manual copy-pasting. This saves you time and effort by directly inputting your dictated text where you need it.
· Configurable Hotkeys: Allows customization of keyboard shortcuts to start and stop recording. This provides flexibility and a personalized user experience, making dictation activation convenient.
· Configurable Behavior: Uses a `config.toml` file to manage hotkeys, model selection, quantization (optimizing model size and speed), language, and threading. This lets you fine-tune Chirp to your specific needs and hardware.
· Post-Processing Styles: Offers optional text styling based on prompts like 'sentence case' or 'prepend: >>'. This enhances the usability of the transcribed text by automatically formatting it according to your preferences.
· Audio Feedback: Provides configurable start/stop sound cues for recording status. This gives you immediate confirmation that the dictation is active or has stopped, preventing missed dictations.
Product Usage Case
· A developer working in a secure corporate environment with strict policies against installing new software can use Chirp to dictate code comments or documentation directly into their IDE. This solves the problem of needing an effective dictation tool without violating IT policies.
· A writer who needs to transcribe notes quickly without sending sensitive manuscript content to cloud services can use Chirp on their Windows laptop. It addresses privacy concerns by keeping all audio processing local, allowing them to dictate comfortably and securely.
· A user who finds built-in Windows dictation inaccurate or cumbersome can use Chirp to achieve faster and more precise speech-to-text. By leveraging the ParakeetV3 model and its efficient CPU usage, they can dictate into any application without needing a GPU.
· A power user who frequently switches between applications and wants to dictate information without alt-tabbing or copying from a separate notepad can benefit from Chirp's direct text injection. This streamlines their workflow by allowing them to dictate directly into forms, chat windows, or any active text field.
7
Jujutsu Visual Navigator
Author
anavid7
Description
A novel visual learning tool designed to demystify the complexities of Jujutsu (JJ) techniques. It leverages interactive diagrams and step-by-step visual progressions to make learning this martial art more accessible and intuitive, addressing the common challenge of understanding nuanced physical movements through static descriptions.
Popularity
Points 7
Comments 10
What is this product?
This project is a visual learning platform for Jujutsu (JJ) that transforms traditional textual instruction into an interactive, graphical experience. Instead of reading lengthy descriptions of techniques, users see them unfold visually. The core innovation lies in how it breaks down complex body mechanics and sequences into digestible visual components, using animated diagrams that illustrate transitions between positions and movements. This approach is particularly effective for kinesthetic learners and for clarifying subtle yet critical aspects of grappling arts where precise body alignment and timing are paramount. Essentially, it turns abstract instructions into a visual narrative, making the learning curve for JJ significantly smoother.
How to use it?
Developers can integrate this visual learning paradigm into various educational platforms, martial arts academy websites, or even within fitness and self-defense apps. The project provides a framework for creating interactive visual content. For instance, an academy could use this to offer online supplementary learning materials for their students, allowing them to review techniques visually before or after class. It can also be a standalone learning resource, accessible via a web browser or a dedicated application, where users can browse through different JJ techniques, explore variations, and practice along with the visual guides. The underlying technology could involve interactive SVG or canvas-based animations, coupled with a content management system for organizing technique libraries.
Product Core Function
· Interactive technique breakdown: Visually dissects complex Jujutsu movements into fundamental steps, showing the progression of each phase with clear graphical representations. This helps users understand the 'why' and 'how' of each movement, not just the 'what'.
· Animated visual sequences: Provides fluid, step-by-step animations of techniques, allowing learners to observe the correct form, timing, and transitions in motion. This is far more effective than static images or text for mastering physical skills.
· Progressive learning modules: Organizes techniques into logical learning paths, starting with basic principles and gradually introducing more advanced maneuvers. This structured approach builds a solid foundation and prevents overwhelm for new practitioners.
· Annotated diagrams: Augments animations with concise annotations highlighting key points, leverage mechanics, and common pitfalls. This adds an extra layer of understanding and reinforces critical details that might be missed in purely visual learning.
· Technique variation exploration: Allows users to explore different variations and counter-techniques for a given move. This expands the learner's tactical understanding and adaptability within Jujutsu.
Product Usage Case
· A martial arts school using the platform to create online refresher courses for its students, allowing them to visually review techniques learned in class, thereby improving retention and skill mastery.
· A self-defense app developer integrating these visual guides to teach practical grappling and escape techniques, offering users a clear and effective way to learn self-preservation skills without requiring a physical instructor.
· A physical therapist designing rehabilitation exercises for individuals recovering from certain injuries, using the visual sequencing to demonstrate safe and controlled movements, aiding in recovery and regaining functionality.
· A game developer exploring ways to incorporate realistic martial arts animations into their fighting game, using this project as a reference for authentic movement and technique execution, enhancing player immersion.
8
spymux: Cross-Pane State Monitor
Author
crap
Description
spymux is a novel tool that allows you to monitor the activity and state of multiple tmux panes from a single, consolidated view. It addresses the common developer pain point of context-switching between different terminal sessions to check on ongoing tasks like builds, tests, or long-running scripts. The innovation lies in its ability to aggregate this information, providing a unified dashboard for efficient workflow management.
Popularity
Points 9
Comments 3
What is this product?
spymux is a lightweight utility designed to enhance the developer's productivity within the tmux terminal multiplexer. Its core technology involves capturing and intelligently displaying key status indicators from various tmux panes. Instead of manually switching between panes to see if a compilation finished or a test suite passed, spymux pulls this information together. Think of it as a real-time, intelligent status board for your terminal sessions. The innovative part is how it extracts relevant information (like exit codes or specific output patterns) from each pane and presents it concisely, saving you significant time and mental overhead.
How to use it?
Developers can integrate spymux into their existing tmux workflows. After installing spymux (typically via a package manager or cloning the repository), you would configure it to watch specific tmux panes. This could involve defining rules for what kind of output or status you're interested in. For example, you might tell spymux to alert you when a `make build` command in one pane finishes, or when a Python test suite in another pane reports failures. It can be run as a separate process that hooks into tmux events or directly within a tmux session, providing a seamless way to keep an eye on multiple concurrent tasks without losing focus.
Product Core Function
· Real-time pane status aggregation: spymux watches multiple tmux panes simultaneously, collecting their output and exit status. This means you get an immediate overview of what's happening across your entire terminal workspace, eliminating the need for constant manual checking. The value is in saving time and reducing the cognitive load of tracking multiple operations.
· Customizable monitoring rules: Developers can define specific patterns or exit codes to monitor within each pane. This allows for tailored alerts and notifications, ensuring you only focus on what's critical to your workflow. The value here is in personalized efficiency, receiving notifications only for events that matter to your specific task.
· Unified status dashboard: spymux presents the monitored information in a clear, consolidated interface. This provides an instant snapshot of your tasks' progress, helping you quickly identify bottlenecks or successful completions. The value is in improved situational awareness and faster decision-making.
· Cross-pane communication and alerting: The tool can be configured to trigger actions or send notifications based on the status of observed panes. For instance, it could alert you via a desktop notification when a long-running compilation job completes successfully. The value is in proactive workflow management and ensuring you don't miss important task outcomes.
Product Usage Case
· Continuous Integration/Continuous Deployment (CI/CD) pipelines: A developer can use spymux to monitor multiple build and test jobs running in different tmux panes. Instead of manually checking each job’s progress, spymux provides a single view. If a build fails in one pane, the developer is immediately alerted and can investigate without having to switch context. This directly addresses the problem of managing parallel development tasks efficiently.
· Long-running data processing or simulations: When running lengthy data analysis scripts or scientific simulations in tmux, spymux can track their completion or detect errors. This allows the developer to step away from the terminal knowing they will be notified when the task is done or if something goes wrong. The value is in reclaiming time and reducing anxiety about unattended processes.
· Automated testing suites: For projects with extensive test suites executed across multiple parallel processes in tmux, spymux can consolidate the pass/fail status of each test run. This gives a quick overview of the overall test health and helps pinpoint specific failing tests. The value is in faster feedback loops and more streamlined debugging.
9
TalkiTo: Voice-Enabled Coding Agents
Author
robbomacrae
Description
TalkiTo is an open-source project that adds voice input (ASR) and voice output (TTS) capabilities to terminal-based coding agents. It allows developers to interact with their coding assistants hands-free, improving multitasking and workflow efficiency. The project supports various ASR/TTS providers, including local options like Whisper and Kokoro/KittenTTS, and integrates with communication platforms like Slack and WhatsApp.
Popularity
Points 5
Comments 5
What is this product?
TalkiTo is a middleware that sits between you and your terminal-based coding agents (like Claude Code or Codex CLI). It uses Automatic Speech Recognition (ASR) to convert your spoken commands into text that the coding agent can understand, and Text-to-Speech (TTS) to read out the agent's responses. This means you can talk to your coding assistant instead of typing, making it feel more like a natural conversation and allowing you to do other things while the agent works. It's designed to be highly configurable, letting you choose which ASR and TTS services to use, including private, local options for better control and privacy.
How to use it?
Developers can integrate TalkiTo into their workflow by installing the project and configuring it to work with their preferred coding agent and ASR/TTS providers. Once set up, they can start using voice commands to interact with the coding agent. For instance, instead of typing a command to the agent, they can simply speak it. The project also allows for in-session configuration changes via voice commands, such as disabling ASR or switching TTS engines. This enables a truly hands-free coding experience, especially useful when multitasking or when direct keyboard input isn't feasible.
Product Core Function
· Speech-to-Text (ASR) Input: Converts spoken commands into text for coding agents, enabling hands-free operation and faster command input.
· Text-to-Speech (TTS) Output: Reads out coding agent responses aloud, allowing developers to stay informed without constantly looking at the terminal.
· Provider Agnosticism: Supports major cloud-based ASR/TTS services and local, private options like Whisper and KittenTTS for flexibility and cost control.
· Communication Platform Integration: Connects to Slack and WhatsApp, enabling voice-based interactions and notifications from coding agents via these platforms.
· Dynamic Configuration: Allows real-time adjustment of ASR/TTS settings and agent control through simple voice commands, offering a fluid and responsive user experience.
Product Usage Case
· Hands-free Code Generation: A developer can dictate code generation requests to an AI coding agent while performing another task, like reviewing documentation or a design, significantly boosting productivity.
· Remote Pair Programming with Voice: During a remote pair programming session, one developer can use TalkiTo to issue commands and receive verbal feedback from the coding agent, while the other developer focuses on writing code, streamlining collaboration.
· Accessibility for Developers: For developers with physical limitations that make typing difficult, TalkiTo provides a vital alternative for interacting with powerful coding tools, making software development more inclusive.
· Continuous Integration/Continuous Deployment (CI/CD) Monitoring: Developers can receive audible notifications about the status of their CI/CD pipelines through their coding agent, allowing them to stay updated even when away from their keyboard.
· Learning and Experimentation: New developers can use voice commands to explore the capabilities of coding agents and receive explanations in an auditory format, making the learning process more engaging and less intimidating.
10
DataSentinel AI
Author
UvrajSB
Description
DataSentinel AI is an intelligent code reviewer specifically designed for data teams. It automates the process of checking SQL, dbt, Airflow, and Spark code changes in GitHub pull requests before they are merged. Its core innovation lies in its ability to predict and prevent costly data-related issues such as warehouse cost spikes, pipeline breakages, and data quality regressions, which are often overlooked by traditional software code reviewers. This empowers data teams to maintain code integrity and optimize resource utilization efficiently.
Popularity
Points 6
Comments 4
What is this product?
DataSentinel AI is an AI-powered system that acts as a smart guardian for your data pipelines. Think of it as a highly experienced data engineer who meticulously reviews every code change you propose. Unlike general code reviewers that focus on software logic, DataSentinel AI understands the unique risks associated with data-related code. It analyzes SQL, dbt, Airflow, and Spark scripts in your GitHub pull requests to identify potential problems before they impact your production systems. Its innovative approach involves predicting cost impacts, detecting logic flaws, ensuring data quality, and tracing the lineage of your data to prevent downstream failures. The key technical insight is that data code risks are fundamentally different from software code risks, involving aspects like billing behavior, table sizes, lineage, and real-world data interactions, which DataSentinel AI is specifically trained to detect.
How to use it?
Developers can integrate DataSentinel AI seamlessly into their GitHub workflow. When a data engineer creates a pull request with changes to SQL, dbt, Airflow, or Spark code, DataSentinel AI automatically scans these changes. It connects to your GitHub repository and performs a deep analysis. The system provides actionable feedback directly within the pull request, highlighting potential cost increases, logical errors, data quality issues, or dependencies that might break. This allows developers to address these problems proactively before merging the code, significantly reducing the risk of costly errors and pipeline disruptions. You can try it for free on your top 100 pull requests at getzingle.com.
Product Core Function
· Cost Regression Prediction: Analyzes code changes to forecast potential increases in data warehouse expenses, enabling proactive cost optimization and preventing unexpected bills. This helps you understand if a proposed change will make your data operations more expensive.
· Logic Issue Detection: Identifies subtle logical errors in SQL or dbt code that might lead to incorrect data processing or skewed results, ensuring the accuracy and reliability of your data. This means your data calculations will be correct.
· Data Quality Gap Analysis: Flags missing data quality checks (like null or uniqueness tests) or redundant ones, promoting robust data integrity and preventing bad data from entering your systems. This ensures the data you rely on is trustworthy.
· Downstream Breakage Tracing: Maps the lineage of data to predict which dashboards, models, or other downstream processes will be affected by the code change, alerting owners and preventing unexpected failures. This prevents your reports and models from suddenly breaking.
· Governance Rule Enforcement: Ensures adherence to data governance policies, including PII masking, documentation requirements, and ownership rules, maintaining compliance and control over your data assets. This helps keep your data secure and compliant with regulations.
· Real-time Sandbox Execution: Safely runs new SQL queries in a controlled environment to analyze actual data differences and identify potential issues that might only appear at scale. This simulates how the code will perform with real data without risking your live environment.
Product Usage Case
· Preventing a $50k Snowflake Bill: A data team used DataSentinel AI and it flagged a PR that would have caused repeated full refreshes on a large model, an error that would have resulted in a $50,000 increase in their Snowflake bill. This is a clear example of how it saves significant financial resources.
· Avoiding Data Distortion: DataSentinel AI identified duplicate rows being introduced into a critical fact table. Without this detection, these duplicates would have distorted revenue reporting, leading to flawed business decisions.
· Optimizing Pipeline Performance: The system caught missing filters that would have doubled table sizes and significantly slowed down data pipelines. By flagging this, the team was able to optimize their queries and maintain efficient processing.
· Ensuring Dashboard Integrity: A simple column rename was proposed that, according to DataSentinel AI's lineage tracing, would have broken 14 downstream dashboards. This prevented a widespread impact on reporting and business intelligence.
· Mitigating Exploding Joins: DataSentinel AI detected potential 'exploding joins' arising from low-cardinality dimensions, a common cause of performance degradation and excessive resource consumption in data queries. This allows for query optimization before performance issues arise.
· Enforcing Documentation Standards: The tool flagged undocumented models that were feeding crucial finance metrics, ensuring better transparency and maintainability of the data infrastructure. This improves collaboration and understanding within the team.
11
UnisonDB: Sub-Second Replication B+Tree
Author
ankuranand
Description
UnisonDB is a highly experimental distributed database that leverages B+Trees for its core data structure and achieves sub-second replication latency across over 100 nodes. It tackles the challenge of fast data synchronization in large-scale, distributed systems, making real-time data access across many machines a practical reality.
Popularity
Points 9
Comments 1
What is this product?
UnisonDB is a novel distributed database system. Instead of relying on traditional disk-based B-Trees, it focuses on optimizing B+Trees for in-memory operations and then applying a clever replication strategy. The innovation lies in its ability to synchronize data changes across a large cluster of nodes (100+) in less than a second. This is achieved through a specialized replication protocol that minimizes overhead and maximizes parallelism, essentially allowing data to be almost instantly available everywhere it's needed, even with a vast number of servers. This means when you update data on one server, it appears almost immediately on all others.
How to use it?
Developers can integrate UnisonDB into applications requiring high availability and low-latency data access across distributed environments. This could involve building real-time dashboards, collaborative applications, or microservices architectures where data consistency and speed are paramount. The integration would typically involve setting up a cluster of UnisonDB nodes and then connecting application clients to this cluster. The database exposes an API (likely SQL-like or a custom query language) that applications use to read and write data. The sub-second replication means that even if a node fails, another node can immediately take over with up-to-date data, ensuring uninterrupted service. Think of it like having your data instantly copied to dozens of backup locations, so if one is destroyed, the others are already ready to go.
Product Core Function
· B+Tree Optimized for Distributed Performance: This core data structure allows for efficient querying and data management, while modifications are designed to be quickly propagated across the network. The value is in making data retrieval fast and consistent, even as the data scales.
· Sub-Second Cross-Node Replication: This is the killer feature. It ensures that data changes are visible on all connected nodes almost instantaneously. The value is in enabling real-time applications that depend on up-to-the-minute data across a large number of servers, preventing stale data issues.
· High Node Count Scalability: Designed to handle over 100 nodes, this demonstrates its capability to scale horizontally for large deployments. The value is in the ability to build robust systems that can grow to accommodate massive amounts of data and users without sacrificing performance.
· Fault Tolerance through Fast Replication: The rapid replication minimizes the window of inconsistency in case of node failures. The value is in building highly available systems where downtime is unacceptable, as data is quickly mirrored, allowing for seamless failover.
Product Usage Case
· Real-time Analytics Dashboards: Imagine a dashboard showing live stock market data or website traffic. UnisonDB's rapid replication ensures that all users viewing the dashboard see the most current information simultaneously, regardless of which server is serving their request. This solves the problem of users seeing outdated numbers.
· Collaborative Editing Platforms: In applications like Google Docs or online whiteboards, multiple users edit content concurrently. UnisonDB can ensure that changes made by one user appear on another user's screen with minimal delay, providing a smooth and responsive collaborative experience. This addresses the lag often experienced in real-time collaboration tools.
· Distributed Microservices with Shared State: When different microservices need to access and update shared data, maintaining consistency across them can be a challenge. UnisonDB provides a fast, consistent data layer, allowing these services to operate on near real-time data, improving overall system responsiveness and reducing coordination headaches. This tackles the complexity of managing data consistency in a microservices architecture.
12
Keepr CLI Vault
Author
bsamarji
Description
Keepr is an offline, command-line interface (CLI) password manager designed for developers. It prioritizes local storage and terminal-based operation, encrypting all sensitive data in an SQLCipher database secured by a master password. A time-limited session feature allows for convenient access without constant re-authentication. This project showcases a strong emphasis on data privacy and security by never connecting to the network.
Popularity
Points 6
Comments 2
What is this product?
Keepr is a command-line tool that securely manages your passwords and secrets locally on your machine. Instead of relying on cloud services, it uses an encrypted SQLite database (SQLCipher) to store your information. The encryption uses AES-256, a robust standard. To access your vault, you set a master password. Keepr then uses this master password, combined with a strong key derivation function (PBKDF2-HMAC-SHA256 with 1.2 million iterations) to create an encryption key. This key decrypts another key (PEK) which is then used to encrypt your actual vault data. For convenience, Keepr offers a temporary session, meaning you don't have to re-enter your master password every single time you need to access a password within a certain timeframe. The core innovation lies in its absolute offline nature and its focus on developer workflows within the terminal, providing a secure alternative to cloud-based password managers for those who prefer to keep sensitive data entirely local. So, this is for you if you want your passwords managed securely without any risk of them being accessed over the internet.
How to use it?
Developers can use Keepr by installing it via pip (Python Package Index): `pip install Keepr`. Once installed, you can interact with it directly from your terminal. You'll start by initializing a new vault and setting your master password. Common commands include `keepr add` to add new entries (like website URLs, usernames, and passwords), `keepr view <entry_name>` to retrieve an entry, `keepr search <keyword>` to find specific secrets, `keepr update <entry_name>` to modify existing entries, and `keepr delete <entry_name>` to remove them. Keepr also features a secure password generator (`keepr generate`) and can copy generated passwords directly to your clipboard for seamless integration into login forms. This allows you to manage all your API keys, database credentials, SSH keys, and website logins directly from your command line, enhancing your development workflow and security posture. So, you can use this to quickly and securely retrieve credentials for your development projects without leaving your terminal.
Product Core Function
· Offline password storage: All your secrets are stored locally on your machine in an encrypted database, ensuring no sensitive data leaves your system. This is valuable because it eliminates the risk of cloud breaches affecting your personal or work credentials.
· AES-256 encryption: Your data is protected using a strong, industry-standard encryption algorithm, making it extremely difficult for unauthorized parties to read. This is valuable because it provides a high level of security for your most sensitive information.
· Master password protection: Access to your encrypted vault is controlled by a master password, which you set. This is valuable because it acts as the primary gatekeeper to your secrets.
· Time-limited session: Once you unlock your vault with your master password, it remains unlocked for a configurable period, allowing you to quickly access multiple passwords without repeated authentication. This is valuable because it improves workflow efficiency without significantly compromising security.
· Secure password generation: Keepr can generate strong, random passwords for you, reducing the likelihood of weak or reused passwords. This is valuable because it helps you create more secure accounts across different services.
· Clipboard integration: Generated passwords or retrieved stored passwords can be automatically copied to your clipboard, making it easy to paste them into applications or websites. This is valuable because it speeds up the process of logging in and reduces the chance of typing errors.
· CLI-based operations: All management tasks (adding, viewing, searching, updating, deleting) are performed via simple commands in your terminal. This is valuable for developers who prefer working in a terminal-centric environment and want to integrate password management into their existing workflows.
Product Usage Case
· Managing API keys for multiple cloud services (AWS, Google Cloud, Azure) directly from your development machine. Instead of storing these keys in plain text files or unsecured configuration, Keepr encrypts them locally, and you can retrieve them via a simple command when needed for your scripts or applications. This solves the problem of insecurely handling sensitive API credentials.
· Storing and retrieving database connection strings and credentials for local development environments. When working on different database projects, you can quickly pull the necessary credentials without having to remember them or risk exposing them in code. This streamlines development by providing quick, secure access to database secrets.
· Keeping SSH private keys and their associated passphrases secure. For developers who frequently connect to remote servers, Keepr can store these sensitive keys offline, preventing them from being accidentally exposed. This enhances security for remote access operations.
· Securing credentials for various online development tools and platforms like GitHub, GitLab, Docker Hub, or SaaS applications. You can easily add and retrieve login details, ensuring you are not relying on browser autofill or less secure methods for managing these important accounts. This addresses the need for a centralized and secure way to manage online service credentials.
13
VisualShop Canvas
Author
kar_t
Description
VisualShop Canvas is an AI-powered visual workspace designed to revolutionize furniture shopping. It addresses the frustration of scattered inspiration and disconnected purchasing platforms by consolidating product discovery, visualization, and decision-making into a single, intuitive interface. The core innovation lies in its intelligent search and AI rendering capabilities, which streamline the complex process of furnishing a space.
Popularity
Points 8
Comments 0
What is this product?
VisualShop Canvas is an AI-powered visual workspace that acts as a central hub for furniture shopping. It leverages advanced AI to understand user inspiration, match it with products from a vast catalog, and generate realistic room renderings. Think of it as a smart digital mood board combined with a powerful shopping assistant. The innovation isn't just the canvas itself, but the underlying AI systems that power product matching and AI-driven room visualization, solving the problem of fragmented and time-consuming furniture research.
How to use it?
Developers can integrate VisualShop Canvas into their platforms or use it as a standalone tool. For e-commerce businesses, it can enhance product discovery and visualization, allowing customers to easily explore furniture options and see how they'd look in their own spaces. For interior designers, it provides a more efficient way to create mood boards and present design concepts to clients. Integration could involve using APIs to pull product catalogs or embed the canvas directly into existing websites. The core idea is to provide a seamless flow from inspiration to informed purchase decisions.
Product Core Function
· AI-powered product matching: This function uses artificial intelligence to find furniture items that match inspiration images or user preferences. The value is in significantly reducing the time and effort spent searching for the right products, offering highly relevant suggestions from a massive catalog. This is applicable in any e-commerce or design context where product discovery is key.
· Generative AI room renderings: This feature utilizes AI to create realistic visualizations of how furniture items would appear in a room. The value lies in allowing users to 'see' the final look before committing to a purchase, reducing uncertainty and improving decision-making confidence. This is incredibly useful for both consumers and designers wanting to preview design outcomes.
· Infinite canvas workspace: This provides a flexible and expandable digital area where users can arrange products, upload inspiration images, and organize their ideas. The value is in centralizing all aspects of the furniture shopping process in one manageable space, preventing information overload and streamlining the entire journey. This is beneficial for anyone managing multiple design ideas or product options.
Product Usage Case
· A user uploads a photo of a stylish living room they saw on social media. VisualShop Canvas analyzes the image and automatically identifies similar furniture pieces from its catalog, presenting them on the canvas. This solves the problem of finding specific items from inspiration photos, making it easy to recreate a desired look.
· An e-commerce furniture retailer embeds VisualShop Canvas on their website. Customers can drag and drop furniture items onto their own uploaded room photos or use the AI rendering feature to visualize how different sofa styles would fit in their living room. This directly addresses customer hesitation by providing a realistic preview, potentially boosting conversion rates.
· An interior designer uses VisualShop Canvas to create a presentation for a client. They can drag and drop selected furniture pieces, upload inspiration images for color palettes, and generate AI renderings of the proposed room layout. This streamlines the design process, allowing for faster iterations and clearer communication of design intent.
14
Vibe Capsule: Offline Music App Weaver
Author
hunterirving
Description
Vibe Capsule transforms your music collections into installable Progressive Web Apps (PWAs) that work entirely offline. It solves the problem of shared digital content becoming ephemeral and dependent on external platforms, enabling creators to gift truly self-contained digital experiences, much like old-school mix CDs.
Popularity
Points 5
Comments 2
What is this product?
Vibe Capsule is a tool that takes your MP3 files and uses Python scripts to package them into a Progressive Web App. This PWA, referred to as a 'mixapp', can then be hosted on any HTTPS-enabled server. The innovation lies in its ability to create offline-first applications. Unlike streaming services or cloud-based playlists, these mixapps store the music files directly on the user's device after an initial download. This means they function without an internet connection and are free from regional restrictions or content availability issues, truly putting the 'files in the computer' and restoring the practice of giving tangible digital gifts.
How to use it?
Developers can use Vibe Capsule by organizing their music files (.mp3s) into a designated folder. They then run the provided Python scripts from the Vibe Capsule GitHub repository. The script will generate a self-contained 'mixapp' folder. This folder can be uploaded to any web server that supports HTTPS. Once hosted, anyone can access the mixapp through a web browser on their device (iOS, Android, or desktop). They will be prompted to 'install' it, which adds an icon to their home screen. After the initial download, the music playback will be fully functional offline, making it a personal, portable music experience.
Product Core Function
· MP3 to PWA conversion: Enables the transformation of standard audio files into installable web applications, offering a novel way to distribute music.
· Offline-first functionality: Ensures that once downloaded, the music is accessible and playable without any internet connection, providing a robust and reliable listening experience.
· Cross-platform compatibility: Allows the generated mixapps to be installed and used on a wide range of devices including smartphones (iOS, Android) and desktops, maximizing accessibility.
· Self-contained digital gifting: Facilitates the creation of permanent, self-contained digital gifts, bypassing the limitations of external service dependencies and regional content locks.
· Customizable user interface: Offers a personalized playback environment for the curated music collection, enhancing the user's engagement with the gifted content.
Product Usage Case
· Creating a personalized offline music gift for a friend's birthday: A user can gather a collection of their friend's favorite songs or discover new tracks, package them using Vibe Capsule, and share the hosted mixapp as a unique, lasting present that doesn't rely on streaming services.
· Building a curated music experience for a specific event or mood: An artist or DJ could create a Vibe Capsule mixapp of their latest tracks or a themed playlist for a party, allowing attendees to download and enjoy the music offline, independent of venue Wi-Fi or mobile data.
· Archiving and sharing niche music collections: For enthusiasts of rare or out-of-print music, Vibe Capsule provides a way to bundle these files into an easy-to-distribute and use application, preserving them for a community without relying on potentially unstable online archives.
15
Bubble Lab: Code-Driven Agentic Workflows
Author
hkselinali
Description
Bubble Lab is an open-source platform that allows developers to build and orchestrate agentic workflows using code. It addresses the complexity of managing multiple AI agents that need to collaborate and execute tasks in a structured manner. The core innovation lies in its code-based approach to defining agent interactions and state management, making complex AI systems more accessible and controllable.
Popularity
Points 5
Comments 2
What is this product?
Bubble Lab is an open-source toolkit designed for developers to build intelligent systems where multiple AI agents can work together to achieve a goal. Think of it like a conductor for a team of specialized AI assistants. Instead of just having one AI do a task, Bubble Lab lets you define how different AI agents, each with their own strengths (like a writer, a researcher, or a coder), communicate and pass information between each other. The innovation is in using plain code to define these interactions, making it much more flexible and transparent than traditional visual tools. This allows for complex, multi-step processes that can be automated and iterated upon easily. So, what's in it for you? It means you can build more sophisticated AI applications that can handle intricate problems by breaking them down into manageable steps executed by specialized AI agents, all controlled by your code.
How to use it?
Developers can use Bubble Lab by defining their agentic workflows in Python. This involves specifying the agents, their roles, the tasks they can perform, and the rules for how they communicate and hand off responsibilities. You can integrate Bubble Lab into existing Python projects or use it as a standalone framework. It provides APIs and structures to define the agents, their tools (functions they can call), and the overall orchestration logic. This means you can build custom AI assistants for anything from automating repetitive coding tasks to creating complex data analysis pipelines. So, how does this help you? You can seamlessly weave sophisticated AI capabilities into your applications, automate complex processes with greater control, and experiment with novel AI architectures without being locked into proprietary, black-box solutions.
Product Core Function
· Agent Definition: Allows developers to precisely define individual AI agents with specific capabilities and roles. This provides granular control over AI behavior, enabling the creation of specialized agents for distinct tasks. The value is in building modular and reusable AI components for complex workflows.
· Workflow Orchestration: Provides mechanisms to define the flow of execution between agents, including conditional logic and parallel processing. This ensures that agents collaborate effectively and tasks are completed in the correct sequence, optimizing efficiency and reducing errors in multi-agent systems.
· Tool Integration: Enables agents to interact with external tools and APIs through custom functions. This expands the capabilities of AI agents beyond their inherent knowledge, allowing them to perform actions in the real world or access up-to-date information. The value is in empowering AI to be more versatile and actionable.
· State Management: Handles the tracking and passing of information between agents throughout the workflow. This ensures that agents have the necessary context to perform their tasks, leading to more coherent and effective collaboration. The value is in maintaining continuity and enabling sophisticated decision-making within the workflow.
Product Usage Case
· Automated Code Refactoring: Developers can set up a workflow where one agent analyzes code for potential improvements, another agent suggests specific refactoring steps, and a third agent applies those changes. This automates a time-consuming development task and ensures consistent code quality.
· Content Generation Pipeline: A workflow can be created where one agent researches a topic, another agent outlines the content, a third agent writes the draft, and a final agent reviews and edits it. This accelerates content creation for blogs, articles, or documentation.
· Data Analysis and Reporting: Developers can build a system where agents fetch data from various sources, another agent preprocesses and analyzes it, and a final agent generates reports or visualizations. This automates complex data workflows, saving time and providing timely insights.
16
Effortless TimeCard Calculator
Author
atharvtathe
Description
This project is a straightforward web application designed to simplify the calculation of time cards. It tackles the common and often tedious task of manually computing work hours, breaks, and overtime, providing an automated and accurate solution for individuals and small businesses.
Popularity
Points 5
Comments 0
What is this product?
This is a web-based time card calculator that automates the process of calculating work hours, including regular hours, overtime, and break deductions. The innovation lies in its simplicity and focus on a common pain point for employees and employers. It uses straightforward web technologies (likely HTML, CSS, and JavaScript) to create an interactive interface where users can input their start and end times, as well as break durations. The backend logic, executed client-side or with a minimal server, performs the calculations based on defined work rules, such as standard workdays and overtime thresholds. This means no complex installations or databases are required, making it highly accessible. The value proposition is clear: it saves time and reduces errors in payroll or personal time tracking.
How to use it?
Developers can use this project as a foundational template for building more sophisticated time tracking systems. It can be integrated into existing HR platforms, project management tools, or even as a standalone utility within a company's internal dashboard. For individual users, it can be accessed directly via a web browser, requiring no setup. The typical use case involves entering daily work start and end times, specifying any breaks taken, and the calculator will instantly output the total hours worked and any overtime. The code is likely open-source, allowing developers to fork it, customize it for specific regional labor laws or company policies, or add features like recurring time entries or export options.
Product Core Function
· Automated Time Calculation: This function takes start and end times for a workday and automatically computes the total duration, highlighting the value of saving manual calculation time and minimizing human error in payroll processing.
· Break Deductions: The ability to input and subtract break times ensures accurate total working hours, which is crucial for fair compensation and compliance with labor regulations.
· Overtime Calculation: This feature automatically identifies and quantifies overtime hours based on predefined thresholds, providing clarity on additional pay owed and simplifying payroll management.
· User-Friendly Interface: A clean and intuitive web interface allows anyone to input data easily without prior technical knowledge, making time tracking accessible to all employees.
· Client-Side Processing: By performing calculations directly in the browser, the application offers quick results and enhances privacy as sensitive time data doesn't need to be sent to a server, which is valuable for personal tracking and small businesses concerned about data security.
Product Usage Case
· A freelance developer can use this calculator to accurately track billable hours for multiple clients, ensuring they are paid for all time spent on projects and avoiding manual errors in invoices.
· A small business owner can deploy this calculator on their company intranet for employees to log their daily work hours, simplifying the payroll process and ensuring accurate wage calculation for hourly workers.
· An individual employee can use this as a personal tool to verify their pay stubs by independently calculating their own work hours, providing a sense of control and transparency over their compensation.
· A student working part-time can quickly calculate their earnings for the week by inputting their shifts, making it easier to manage their personal budget and understand their income.
· A developer looking to learn about basic web application development can study the source code of this project to understand how to handle user input, perform calculations with JavaScript, and create interactive web elements.
17
StoryMotion: Visual Narrative Weaver
Author
chunza2542
Description
StoryMotion is an innovative tool designed to transform complex ideas into engaging, step-by-step animated diagrams. It addresses the challenge of explaining intricate processes or concepts effectively, moving beyond static visuals to offer dynamic, narrative-driven explanations. The core innovation lies in its ability to automate the creation of explainer animations from simple inputs, making sophisticated visual storytelling accessible to developers and creators.
Popularity
Points 1
Comments 4
What is this product?
StoryMotion is a project that helps you create animated diagrams and explainer videos without needing advanced animation skills. It works by allowing you to define steps or stages of a process, and the tool then automatically generates a smooth animation that visually guides viewers through each part. Think of it like creating a visual walkthrough for your code, a scientific process, or any step-by-step guide, but with smooth motion and clear transitions. The innovation is in simplifying the animation pipeline, so instead of manually keyframing every movement, you describe the sequence and StoryMotion builds the animation for you. This means you can convey information more effectively and engage your audience more deeply.
How to use it?
Developers can integrate StoryMotion into their workflow to create clear documentation, tutorials, or presentations. You can use it to explain how a particular algorithm works, demonstrate the flow of data in an application, or visualize a complex system architecture. Typically, you would input your sequential steps or key points, and StoryMotion generates an animation that can be exported as a video file or GIF. This is incredibly useful for onboarding new team members, creating marketing materials, or even debugging complex logical flows by visualizing them. It directly translates to better understanding and faster adoption of your technical solutions.
Product Core Function
· Automated Animation Generation: The system takes sequential data inputs and automatically produces animated transitions and movements. This means less manual effort for creators and a smoother, more professional-looking output, enhancing the clarity of explanations.
· Step-by-Step Visualization: Enables the breakdown of complex processes into easily digestible visual steps. This directly helps viewers grasp intricate details without getting overwhelmed, crucial for technical education and product demos.
· Customizable Explainer Flows: Allows users to define the order and timing of visual elements, ensuring the narrative flows logically. This empowers creators to tailor the explanation precisely to their audience's needs, leading to more effective communication.
· Exportable Formats: Supports exporting animations in common video formats (e.g., MP4) or GIFs. This makes it easy to embed these visuals into websites, documentation platforms, or presentations, maximizing reach and accessibility.
· Focus on Clarity and Engagement: The core purpose is to improve understanding through dynamic visuals. This leads to higher audience retention and better comprehension of technical concepts.
Product Usage Case
· Explaining a new API endpoint: A developer can use StoryMotion to visually show the request and response flow, highlighting each parameter and its purpose. This makes API documentation much more interactive and understandable than plain text.
· Demonstrating a data processing pipeline: Visualize how data moves through different stages of an application, from ingestion to transformation to output. This helps stakeholders understand the system's architecture and identify potential bottlenecks.
· Creating a tutorial for a new feature: Walk users through the steps of using a new software feature with animated visuals, making it easier for them to follow along and learn. This reduces support burden and improves user satisfaction.
· Visualizing a machine learning model's inference process: Show how an input is processed by the model layer by layer to produce an output. This demystifies complex AI concepts for a broader audience.
· Onboarding new engineers: Use animated diagrams to explain the setup process for a development environment or the architecture of a core service. This accelerates the learning curve for new team members.
18
ByteSync: Hybrid File Sync Engine
Author
paulfresquet
Description
ByteSync is an open-source tool for synchronizing, backing up, and deduplicating files. Its key innovation lies in its integrated networking layer and end-to-end encryption (E2EE), allowing seamless file syncing between local and remote locations (even over the internet) without complex network configurations like VPNs or firewall adjustments. It intelligently compares and transfers only changed data, making it efficient for large datasets.
Popularity
Points 3
Comments 2
What is this product?
ByteSync is a sophisticated file synchronization and backup solution that works across your local network (LAN) and the internet. Its core technology employs a two-stage inventory process: first, it creates an index of all your files. Then, during synchronization, it only compares and transfers the parts of files that have actually changed. This is a significant technical leap because it drastically speeds up syncing, especially for large collections of files. The integrated networking layer and end-to-end encryption mean your data is securely transferred between devices, whether they're in the same room or on different continents, without requiring you to fiddle with complicated network settings. Think of it as a smart, secure way to keep your files consistent everywhere.
How to use it?
Developers can use ByteSync to keep project codebases in sync across multiple machines or collaborate with remote team members by sharing synchronized repositories. It can be integrated into CI/CD pipelines for automated backups or to distribute build artifacts. For personal use, it's ideal for backing up important documents and media to a home server or cloud storage without exposing data to unauthorized access. Installation is straightforward, and it runs on Windows, macOS, and Linux. While currently focused on interactive use, future CLI integration will enable more automated workflows.
Product Core Function
· End-to-End Encrypted Synchronization: Ensures your files are secure during transfer and storage, protecting privacy and preventing unauthorized access, valuable for sensitive project data or personal backups.
· Integrated Networking Layer: Enables direct syncing between devices over LAN or the internet without VPNs or complex firewall configurations, simplifying remote collaboration and access to your files.
· Two-Stage Inventory and Delta Transfer: Optimizes sync speed by indexing files and then only transferring changed data, making it highly efficient for large datasets and reducing bandwidth usage.
· Data Deduplication: Identifies and stores only unique copies of data, saving storage space and further optimizing backup and sync processes.
· Cross-Platform Compatibility: Runs on Windows, macOS, and Linux, allowing developers to use it across their entire ecosystem of devices.
· Flexible Synchronization Model: Supports multiple participants and data nodes, allowing for complex synchronization setups between various devices and storage locations.
Product Usage Case
· A developer working on a large software project can use ByteSync to automatically keep their local codebase in sync with a remote Git repository or a shared network drive. This ensures they always have the latest code and can collaborate effectively with teammates without manual uploads or downloads.
· A photographer can use ByteSync to back up their RAW image files from a local drive to a NAS (Network Attached Storage) device. The end-to-end encryption ensures the privacy of their work, and the efficient delta transfer means backups are fast and don't consume excessive bandwidth.
· A small team can use ByteSync to share project documents and assets between their home computers and a central server. Without needing a VPN, they can ensure everyone has the most up-to-date versions of files, improving team productivity and reducing the risk of working with outdated information.
· A user wanting to sync their personal media library across multiple devices can use ByteSync to maintain consistency. The tool's ability to handle large amounts of data efficiently and securely makes it a robust solution for personal file management.
19
PredictivePulse Aggregator
Author
ritzammm
Description
This project is a data aggregation tool for prediction markets. It aims to consolidate information from various prediction market platforms into a single, digestible format. The innovation lies in its ability to process and normalize disparate data structures from different markets, providing a unified view for analysis and decision-making. This addresses the challenge of fragmented data in the prediction market space, making it easier for users to gain insights and make informed predictions.
Popularity
Points 5
Comments 0
What is this product?
PredictivePulse Aggregator is a system designed to collect, process, and present data from multiple prediction markets. Think of it like a news aggregator, but instead of news articles, it gathers information about the current odds and outcomes of various future events being bet on across different prediction platforms. The technical innovation is in its data normalization engine. Many prediction markets have their own unique ways of structuring data (e.g., how they list events, probabilities, or trades). This tool automatically figures out these differences and transforms them into a consistent format. This means you don't have to manually visit each market's website and try to understand their specific data presentation; the aggregator does the heavy lifting, providing a unified stream of prediction market intelligence.
How to use it?
Developers can integrate PredictivePulse Aggregator into their own applications or use it as a standalone dashboard. It provides an API (Application Programming Interface) that allows other programs to query the aggregated data. For example, you could build a trading bot that uses this data to identify arbitrage opportunities across different markets. Alternatively, a data scientist could use the aggregated historical data to train machine learning models for forecasting. The integration typically involves making API calls to fetch specific market data, filtering it based on your needs, and then using it within your application logic. This saves developers the immense effort of building individual data connectors for each prediction market they want to monitor.
Product Core Function
· Data Source Integration: Connects to various prediction market APIs to fetch real-time data. The value here is in its ability to abstract away the complexities of interacting with multiple, potentially different, APIs, saving developers significant integration time.
· Data Normalization Engine: Transforms data from diverse sources into a standardized format. This is crucial for analysis, as it ensures consistency across all data points, making it easy to compare and combine information without worrying about format discrepancies.
· Real-time Data Streaming: Provides an ongoing stream of updated prediction market information. This is valuable for applications that require up-to-the-minute insights, such as high-frequency trading bots or live dashboards.
· Historical Data Archiving: Stores past prediction market data for retrospective analysis. This allows for backtesting trading strategies, identifying long-term trends, and improving forecasting models.
· API Access: Exposes a clean API for programmatic access to the aggregated data. This empowers developers to build custom tools and applications on top of the prediction market data, fostering innovation and new use cases.
Product Usage Case
· Building an automated trading bot that identifies price discrepancies between different prediction markets to execute profitable trades. This addresses the problem of needing to constantly monitor multiple markets manually, allowing for faster and more efficient trading.
· Developing a predictive analytics dashboard that visualizes the collective sentiment and expected outcomes across various topics being predicted on. This helps users understand the overall market consensus and potential future events without having to aggregate information from scratch.
· Creating a research tool for economists or social scientists to study market dynamics and the accuracy of collective intelligence in predicting real-world outcomes. This provides a unified dataset that was previously difficult to obtain, enabling more robust research.
· Integrating prediction market data into a news aggregation service to gauge public sentiment and expert opinion on upcoming events, thereby enriching news content with foresight. This adds a layer of predictive insight to traditional news consumption.
20
Vis: Formula-Driven Workout Engine
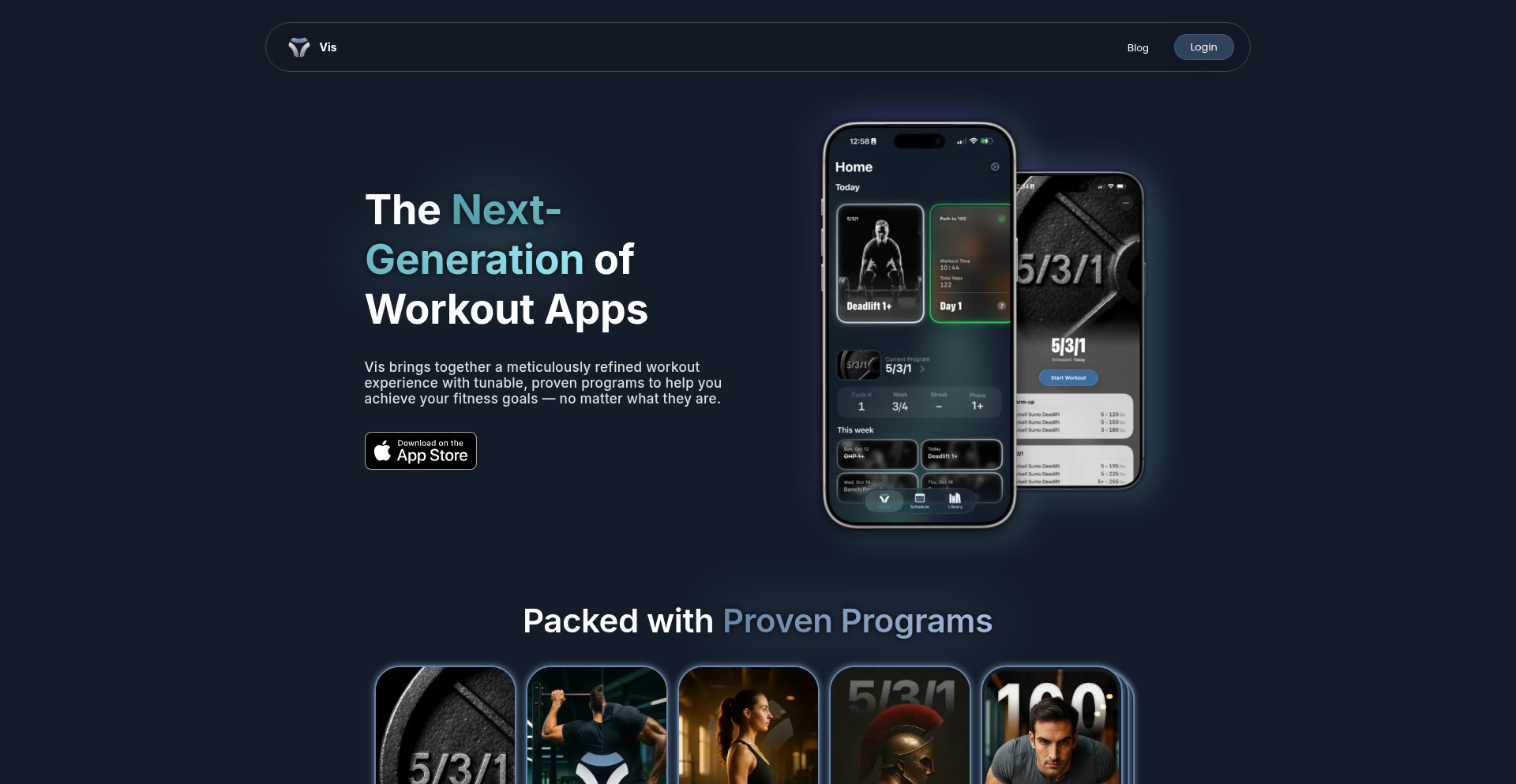
Author
strongpigeon
Description
Vis is a next-generation workout application built on a powerful, formula-driven engine. It started as a platform for gyms and trainers to create custom workout programs defined by mathematical formulas, deriving variables like 1RM (one-rep max) from user inputs. While initially targeting B2B, it has pivoted to a focus on an iOS app that offers a fluid, modern workout experience. The core innovation lies in its ability to generate and adapt workouts dynamically based on user performance and set parameters, moving beyond static, spreadsheet-like interfaces. It leverages native SwiftUI for a seamless iOS experience, including Live Activities integration for on-the-go workout tracking.
Popularity
Points 5
Comments 0
What is this product?
Vis is a workout application that utilizes a unique, formula-based system to create and manage training programs. Instead of just listing exercises, users can define rules and calculations. For example, a program could specify that the weight for an exercise should be 90% of your current 1RM, and the app automatically calculates and adjusts this for you. This innovative approach allows for highly personalized and adaptive training plans that evolve with your progress. The technology behind it allows for a flexible workout editor that can translate complex training methodologies into actionable steps for the user, making sophisticated training principles accessible.
How to use it?
Developers can integrate Vis's core engine into their own applications or platforms. Imagine a fitness wearable that needs to suggest workouts based on a user's real-time heart rate and recovery status. Vis's formula engine can be used to process these data points and dynamically generate appropriate exercises and intensity levels. For mobile app developers, the ability to create highly customizable workout routines without manually defining every single variation saves significant development time. The engine can be exposed as an API or a library, allowing developers to embed this intelligent workout generation capability into their fitness or health-tracking products.
Product Core Function
· Formula-driven workout generation: This allows for dynamic creation of exercises and rep schemes based on user-defined rules and performance metrics. The value is in creating truly adaptive training plans that automatically adjust to user progress, offering a more effective and engaging experience.
· 1RM calculation and progression: The system can calculate and track one-rep maxes, a key indicator of strength. This is valuable for users who want to measure their progress in strength-based training and ensure they are consistently challenging themselves.
· Customizable workout editor: This provides a powerful interface for creating and modifying workout programs. For developers, this means they can offer their users a high degree of personalization without building a complex workout creation system from scratch.
· Native SwiftUI iOS app integration: This enables a smooth and modern user experience on iOS, including features like Live Activities for on-screen workout tracking during a session. The value here is in delivering a polished and integrated user experience that feels intuitive and responsive.
· Jiggle Mode style rescheduling: This offers an intuitive way to adjust workout schedules, making it easy to move workouts around. This enhances user flexibility and adherence to their training plan.
Product Usage Case
· A strength training app developer wants to offer users the ability to create programs based on percentage of 1RM. Instead of manually calculating and updating these percentages, they can use Vis's engine to define the program once, and the app will automatically manage the progression. This solves the problem of complex manual tracking and ensures users are always training at the right intensity.
· A personal trainer wants to create a standardized yet personalized training plan for their clients. They can use Vis's editor to build a template with formulas. When a client starts the program, the app uses their initial assessment data (e.g., a self-reported 1RM) to tailor the weights and reps for each session. This scales the trainer's ability to provide individualized coaching.
· A physical therapy application needs to guide patients through recovery exercises with specific parameters (e.g., hold for X seconds, repeat Y times). Vis's engine can be used to define these parameters and ensure the app provides accurate and safe guidance, adapting the intensity as the patient recovers. This addresses the need for precise exercise prescription and monitoring in rehabilitation.
· A gamified fitness app aims to keep users engaged with evolving challenges. The core workout logic can be powered by Vis's formula engine, allowing challenges to dynamically adjust difficulty based on user performance, making the game more engaging and preventing users from hitting a plateau too quickly.
21
MacroBuilder Pro
Author
harvest_bowl
Description
Harvest Bowl is a minimalist iPhone app designed for effortless meal construction. It empowers users to precisely craft meals by inputting exact gram measurements or calorie targets, with real-time macro nutrient (protein, carbs, fat) updates as portion sizes are adjusted. This addresses the common frustration of overly complex food tracking apps and cluttered databases, offering a streamlined approach to understanding nutritional intake.
Popularity
Points 3
Comments 2
What is this product?
Harvest Bowl is an iPhone application that revolutionizes how individuals approach meal planning by focusing on precise portion control and instant nutritional feedback. At its core, the app utilizes intuitive 'sliders' that allow users to adjust ingredient quantities in grams or calories. As these sliders are moved, the app's underlying engine immediately recalculates and displays the macronutrient breakdown (protein, carbohydrates, and fats) for the entire meal. This approach bypasses the need for tedious manual entry and searching through extensive food libraries, providing a dynamic and highly visual way to understand the nutritional composition of any meal. The innovation lies in its extreme simplicity and focus on immediate, actionable data, making nutritional awareness accessible without the burden of traditional tracking.
How to use it?
Developers can leverage Harvest Bowl's philosophy by integrating similar real-time calculation engines into their own applications. For instance, within a fitness app, a developer could implement a module that allows users to virtually assemble workouts, with exercise intensity and duration sliders instantly updating estimated calorie expenditure or muscle engagement scores. In a recipe app, sliders could adjust ingredient quantities for scaling recipes, with real-time updates to total calories and macronutrients per serving. The core technical idea is to create a reactive UI where user input directly and immediately influences calculated outputs, providing instant gratification and clarity. Integration would involve setting up data models for ingredients, their nutritional values, and a calculation engine that processes slider inputs to derive macro outputs. The 'quick veggie presets' feature suggests a pre-defined data structure for common food items that can be quickly added and adjusted.
Product Core Function
· Precision sliders for grams/calories: This feature provides a technically elegant solution for granular control over ingredient portions. Instead of typing numbers, users interact with a visual slider, which is typically implemented using UI frameworks that map touch gestures to numerical values. This offers a more fluid and immediate user experience, directly translating user intent into precise data points. The value is in reducing friction and increasing the accuracy of nutritional input, which is crucial for users with specific dietary goals.
· Instant macros: The core innovation here is a reactive programming model where changes in portion size trigger immediate recalculations of macronutrient values. This is often achieved using observable patterns or state management libraries where changes to one piece of data (portion size) automatically propagate to dependent data (macro totals). This provides developers with immediate feedback, allowing them to see the nutritional impact of their meal choices in real-time, thus enabling more informed decision-making without delay.
· Clean ingredient lists: This function is about data organization and presentation. Technically, it involves efficient data fetching and rendering of ingredient information. The value lies in a user interface that is uncluttered and easy to navigate, allowing users to quickly see and manage the components of their meals. This can be achieved through optimized list rendering techniques and clear data structuring, ensuring a smooth and intuitive user experience.
· Quick veggie presets: This feature utilizes pre-configured data sets for common vegetable ingredients. Technically, it involves storing a database of frequently used items with their default nutritional information and portion sizes, which can be quickly selected and added to a meal. The value is in accelerating the meal building process for common healthy ingredients, reducing repetitive manual input and making healthy choices more convenient.
· Save your go-to bowls: This function involves data persistence. Technologically, it means implementing a mechanism to save user-defined meal configurations to local storage or a cloud backend. The value for users is the ability to quickly recall and reuse their favorite healthy meal combinations, saving time and ensuring consistency in their dietary habits.
Product Usage Case
· A user trying to hit a specific protein target for post-workout recovery can use Harvest Bowl to assemble a chicken breast and quinoa meal. By adjusting the chicken and quinoa sliders in grams, they can instantly see the protein count rise, ensuring they meet their target without overeating other macros. This solves the problem of guessing portion sizes and the subsequent nutritional inaccuracies.
· A fitness enthusiast managing their carbohydrate intake for a marathon training diet can use Harvest Bowl to build a breakfast smoothie. They can precisely set the amounts of oats, banana, and protein powder, and the app will instantly show the total carbohydrate grams, helping them stay within their daily limits. This addresses the challenge of managing macronutrient ratios for performance.
· Someone looking to reduce their overall calorie intake can use Harvest Bowl to create a balanced lunch. They can experiment with different vegetable and lean protein portions, seeing the total calorie count update with each adjustment, enabling them to find a satisfying yet calorie-conscious meal. This solves the issue of creating filling meals while adhering to a calorie deficit.
· A beginner cook who wants to make a healthy stir-fry can use the 'quick veggie presets' to easily add broccoli, bell peppers, and tofu, then use the gram sliders to adjust their preferred portions. The instant macro display helps them understand the nutritional impact of their cooking choices, making healthy home-cooked meals more approachable.
22
eBPF Android Hotspot
Author
Gave4655
Description
This project leverages eBPF (extended Berkeley Packet Filter) to create an unlimited mobile hotspot for Android devices. It bypasses typical carrier restrictions on hotspot data usage by manipulating network traffic at a low level, offering a technically innovative solution to a common user pain point. The core innovation lies in using eBPF's powerful kernel-level programmability to achieve this without requiring root access or complex modifications to the Android OS.
Popularity
Points 3
Comments 2
What is this product?
This is an Android application that utilizes eBPF, a cutting-edge Linux kernel technology, to enable a mobile hotspot feature that is not limited by data caps imposed by mobile carriers. eBPF allows developers to write small programs that run directly within the Linux kernel, enabling deep inspection and manipulation of network packets. In this case, the eBPF program intercepts and reroutes traffic, effectively masking hotspot usage and making it appear as regular device data usage. This bypasses the artificial limitations often placed on tethering. So, what does this mean for you? It means you can share your phone's internet connection without worrying about hitting data limits or incurring extra charges for hotspot usage.
How to use it?
The project typically involves installing a custom application on an Android device. This app, when activated, will load an eBPF program into the Android system's kernel. The eBPF program then intelligently manages the network traffic from devices connected to the Android hotspot. The user experience is intended to be straightforward: enable the hotspot feature within the app, and connected devices will have internet access without data restrictions. The advanced eBPF implementation happens in the background. So, how can you use this? You can connect your laptop, tablet, or other devices to your phone's hotspot and use the internet as if you were directly connected to your home Wi-Fi, without concern for data overages on your hotspot plan.
Product Core Function
· eBPF Kernel Module Loading: The core function is the ability to load and execute eBPF programs within the Android Linux kernel. This allows for unparalleled control over network traffic at a fundamental level. The value here is the ability to deeply customize network behavior without modifying core OS files. This is useful for advanced network management and security applications.
· Network Traffic Interception and Redirection: The eBPF program intercepts all outgoing network packets from devices connected to the hotspot. It then intelligently redirects or masks these packets to appear as if they are originating from the Android device itself. The value is in bypassing carrier-imposed data limitations on hotspot usage. This is applicable when you need to share your phone's internet for extended periods or for data-intensive tasks.
· Unlimited Hotspot Data Simulation: By manipulating how network traffic is reported, the eBPF program effectively simulates unlimited hotspot data. It prevents carriers from accurately tracking and throttling hotspot data usage. The value is significant cost savings and freedom from data restrictions. This is extremely useful for remote workers, students, or anyone who relies on their mobile hotspot for primary internet access.
· Rootless Operation: A key technical achievement is performing these network manipulations without requiring root privileges on the Android device. This is possible due to the inherent capabilities of eBPF in modern Linux kernels. The value is increased security and ease of use, as it doesn't compromise the device's security by rooting it. This makes the technology accessible to a wider range of users who prefer not to root their devices.
Product Usage Case
· Remote Work Scenario: A remote worker needs to share their Android phone's internet with their laptop for a full workday. Traditional hotspots might have data limits that are quickly reached. Using this eBPF-based solution, the worker can confidently tether their laptop and access all necessary online resources without worrying about exceeding hotspot data allowances, ensuring uninterrupted productivity.
· Student Project: A student needs to download large datasets or software for a university project using their phone's hotspot. Standard hotspot plans might cap data at a low threshold, making this impossible. With this project, the student can download gigabytes of data without hitting any data limits, enabling them to complete their project effectively.
· Travel and Extended Use: A traveler relies on their phone as their primary internet source in a hotel or during transit. If the hotel Wi-Fi is unreliable or unavailable, a capped hotspot plan becomes a bottleneck. This eBPF solution allows for sustained, high-bandwidth internet sharing for browsing, streaming, and working, making it an indispensable tool for modern travel.
· Emergency Internet Access: In situations where home internet is down, this project provides a reliable and uncapped backup internet solution. Users can connect multiple devices and maintain essential online access for communication, news, and work, turning their smartphone into a robust home internet alternative.
23
WikiDive: AI-Powered Wikipedia Navigator

Author
atulvi
Description
WikiDive is an experimental project that leverages AI to guide users through Wikipedia, enabling 'deep dives' into topics. Instead of traditional linear browsing, it uses AI to understand user intent and suggest relevant related articles, creating a more exploratory and insightful learning experience. It tackles the challenge of information overload on Wikipedia by providing a smarter, context-aware navigation system.
Popularity
Points 3
Comments 2
What is this product?
WikiDive is an AI-driven tool designed to revolutionize how you explore Wikipedia. Instead of just clicking through links, imagine an AI assistant that understands what you're interested in and intelligently surfaces related information, helping you uncover deeper connections and nuances within Wikipedia's vast knowledge base. It uses Natural Language Processing (NLP) to interpret your search queries and the content of Wikipedia articles, then applies graph-based algorithms to map out potential 'dives' and recommend the most relevant next steps. So, what's in it for you? It transforms passive reading into an active discovery process, making learning more engaging and efficient.
How to use it?
Developers can integrate WikiDive into their own applications or use it as a standalone tool for research. The core idea is to take a user's starting point (a Wikipedia page or a search query) and have WikiDive's AI suggest a path of interconnected articles. For developers, this could mean building custom research tools, educational platforms, or even content recommendation engines. It's about providing a smarter way to navigate and understand complex information structures. This would be useful when you need to deeply understand a subject or want to explore tangential information without getting lost.
Product Core Function
· AI-powered topic exploration: Uses NLP to understand user queries and article content to suggest relevant Wikipedia pages, helping users uncover hidden connections. The value is in moving beyond simple keyword searches to understanding semantic relationships, which helps users discover information they might have otherwise missed.
· Contextual navigation: Analyzes the current article and user interest to recommend the most relevant next article to dive into. This provides a tailored browsing experience, ensuring users stay on track with their learning goals and don't get sidetracked by irrelevant links.
· Deep dive path generation: Creates a suggested sequence of articles for in-depth exploration of a topic. This is valuable for researchers or students who need to build a comprehensive understanding of a subject, providing a structured yet flexible learning path.
· Wikipedia knowledge graph mapping: Visualizes or represents the connections between Wikipedia articles based on AI analysis. This helps users understand the structure of knowledge around a topic and identify key influential articles.
Product Usage Case
· A student researching a historical event can use WikiDive to explore not just the main event page, but also related figures, socio-political contexts, and subsequent impacts, leading to a richer and more nuanced understanding than traditional search would yield.
· A developer building an educational app could integrate WikiDive to provide students with guided learning paths through complex subjects, making abstract concepts more concrete by linking them to real-world examples and related historical information.
· A content creator preparing a documentary can use WikiDive to discover unexpected connections and niche details within Wikipedia that can add depth and intrigue to their narrative, going beyond surface-level facts.
· A curious individual wanting to learn about a new scientific concept can input their initial query and let WikiDive guide them through a series of related articles, intelligently explaining prerequisite knowledge and broader implications, making complex topics accessible.
24
ContextWeaver
Author
LoMoGan
Description
ContextWeaver is an open-source system designed to help Large Language Models (LLMs) effectively manage and recall information from lengthy conversation histories. It uses a smart, hierarchical tree-like indexing method to organize and retrieve relevant parts of conversations, allowing LLMs to understand and respond to complex, long-running dialogues without losing track of crucial details. This tackles the common LLM limitation of forgetting earlier parts of a long conversation, making AI interactions more coherent and useful.
Popularity
Points 4
Comments 0
What is this product?
ContextWeaver is essentially a sophisticated memory system for AI chatbots. Think of it like a super-efficient librarian for an AI's brain. When an AI is having a long conversation, it needs to remember what was said before. ContextWeaver organizes all the past messages into a structured tree, like a filing system. When the AI needs to recall something, ContextWeaver quickly finds the most relevant pieces of information from this organized structure. The innovation lies in its hierarchical indexing, meaning it groups related ideas and conversations together, making it much faster and more accurate to find what's needed compared to just sifting through raw text. So, for you, this means AI can remember more, understand complex requests better, and provide more consistent and relevant answers over longer interactions.
How to use it?
Developers can integrate ContextWeaver into their AI applications. If you're building a chatbot that needs to maintain context over many turns, like a customer support bot or a personal assistant AI, you would feed the conversation history into ContextWeaver. It then builds its index. When the LLM needs to respond, instead of feeding it the entire history, you can query ContextWeaver to retrieve only the most pertinent snippets of the conversation. This can be done programmatically through its API. For example, you could use it with popular LLM frameworks like LangChain or LlamaIndex to enhance their existing context management capabilities. This allows your AI to have 'better memory' without needing a fundamentally more powerful (and expensive) LLM for every interaction.
Product Core Function
· Hierarchical Tree Indexing: Organizes conversation history into a multi-level structure for efficient retrieval. This means the AI doesn't have to scan every single message; it can quickly pinpoint relevant sections, saving processing time and improving accuracy.
· Contextual Retrieval: Smartly fetches the most relevant pieces of conversation based on the current query. Instead of just giving the AI the last few messages, it provides the most important past information, ensuring continuity and understanding.
· Long-Context Handling: Specifically designed to manage very long conversation threads, overcoming the memory limitations of standard LLMs. This allows for deeper, more nuanced AI interactions that don't get derailed by forgetting earlier details.
· Open-Source Framework: Freely available for developers to use, modify, and integrate into their own projects. This fosters community development and allows for customization to specific needs, driving innovation faster.
· LLM Integration: Built to work seamlessly with various Large Language Models. It acts as a middleware, enhancing the LLM's ability to process and recall information, making existing AI models more powerful.
Product Usage Case
· A customer support chatbot that can recall previous interactions with a user over multiple support tickets. When a user returns with a new issue, the bot can reference past resolutions and customer information, leading to faster and more personalized support.
· A virtual tutor that needs to remember a student's learning progress, past mistakes, and areas of difficulty across an entire course. ContextWeaver allows the tutor to tailor explanations and exercises precisely to the student's individual needs, making learning more effective.
· A personal AI assistant that manages a user's tasks, reminders, and preferences over months or years. The assistant can recall past requests, context of projects, and user habits, providing more proactive and intelligent assistance without constant re-explanation.
· A collaborative writing tool where an AI assists multiple users in drafting documents. The AI can maintain context on different drafts, user feedback, and project goals, ensuring consistency and efficiency in the collaborative process.
· A research assistant AI that processes vast amounts of documents and research papers. ContextWeaver helps the AI organize and recall specific findings, methodologies, and connections between different sources, enabling more insightful analysis.
25
PixelFlame: Portable Digital Hearth
Author
kingofspain
Description
PixelFlame is a charming iOS application that brings a cozy, pixelated fireplace experience to your iPhone and Apple Watch. It tackles the modern dilemma of digital detachment by offering a visually soothing and ambient digital fire, accessible through widgets and a companion watch app. The innovation lies in its creative use of mobile device capabilities to evoke a sense of warmth and relaxation, transforming mundane digital spaces into comforting virtual environments. This project showcases the hacker spirit of using code to inject a bit of analog comfort into our digital lives.
Popularity
Points 4
Comments 0
What is this product?
PixelFlame is a digital fireplace application designed for iOS devices, including iPhones and Apple Watches. It utilizes advanced graphics rendering techniques to create a dynamic, pixelated fire animation. The core innovation is its ability to translate the comforting sensory experience of a real fireplace into a purely digital medium. Think of it as a visually engaging screensaver with a warm, ambient theme that requires minimal processing power while delivering a pleasant visual output. This addresses the need for digital wellness and mindful tech use by providing a calming visual element to offset the often-hectic nature of smartphone interactions.
How to use it?
Developers can integrate the visual elements of PixelFlame into their own applications to create a unique ambiance, perhaps in games, mindfulness apps, or even productivity tools that aim for a relaxed user experience. For end-users, it's as simple as installing the app and placing the widgets on their home screen or using the watch app for a personal fireside view on their wrist. It's designed for easy integration and immediate enjoyment, offering a 'set it and forget it' kind of comforting background.
Product Core Function
· Home screen widgets: These are small, dynamic visual elements that can be placed on your iPhone's home screen, offering a persistent, warming fireplace view without needing to open the full app. This provides a constant visual cue of relaxation and comfort, directly impacting user mood and focus.
· Companion watch app: A miniaturized version of the fireplace experience is available on your Apple Watch. This allows for portable warmth and a quick moment of digital serenity, no matter where you are, turning your wearable device into a personal comfort zone.
· Customizable flame and color options: The app allows users to personalize the appearance of the digital fire. This technical implementation provides a more engaging and personal user experience, allowing users to tailor the visual output to their aesthetic preferences, enhancing the perceived value and enjoyment of the application.
Product Usage Case
· Imagine a study app that, when a user is in 'focus mode', displays a small PixelFlame widget. The gentle flickering fire can create a cozy atmosphere, subtly reducing stress and promoting a more conducive learning environment. This addresses the problem of sterile digital interfaces by adding an emotional and atmospheric layer.
· A fitness app could incorporate PixelFlame as a cool-down visual. After a strenuous workout, a user could view the calming fire on their watch, signaling a transition to a more relaxed state. This leverages the app's ambient nature to support holistic well-being within a fitness context.
· For developers creating digital art or interactive installations, PixelFlame's rendering engine and animation logic could serve as inspiration or a foundational component for more complex visual effects. It demonstrates how to achieve visually appealing and computationally efficient animations on mobile platforms, solving the challenge of creating engaging visuals without draining battery life.
26
BeatDelay: Procrastination De-railer
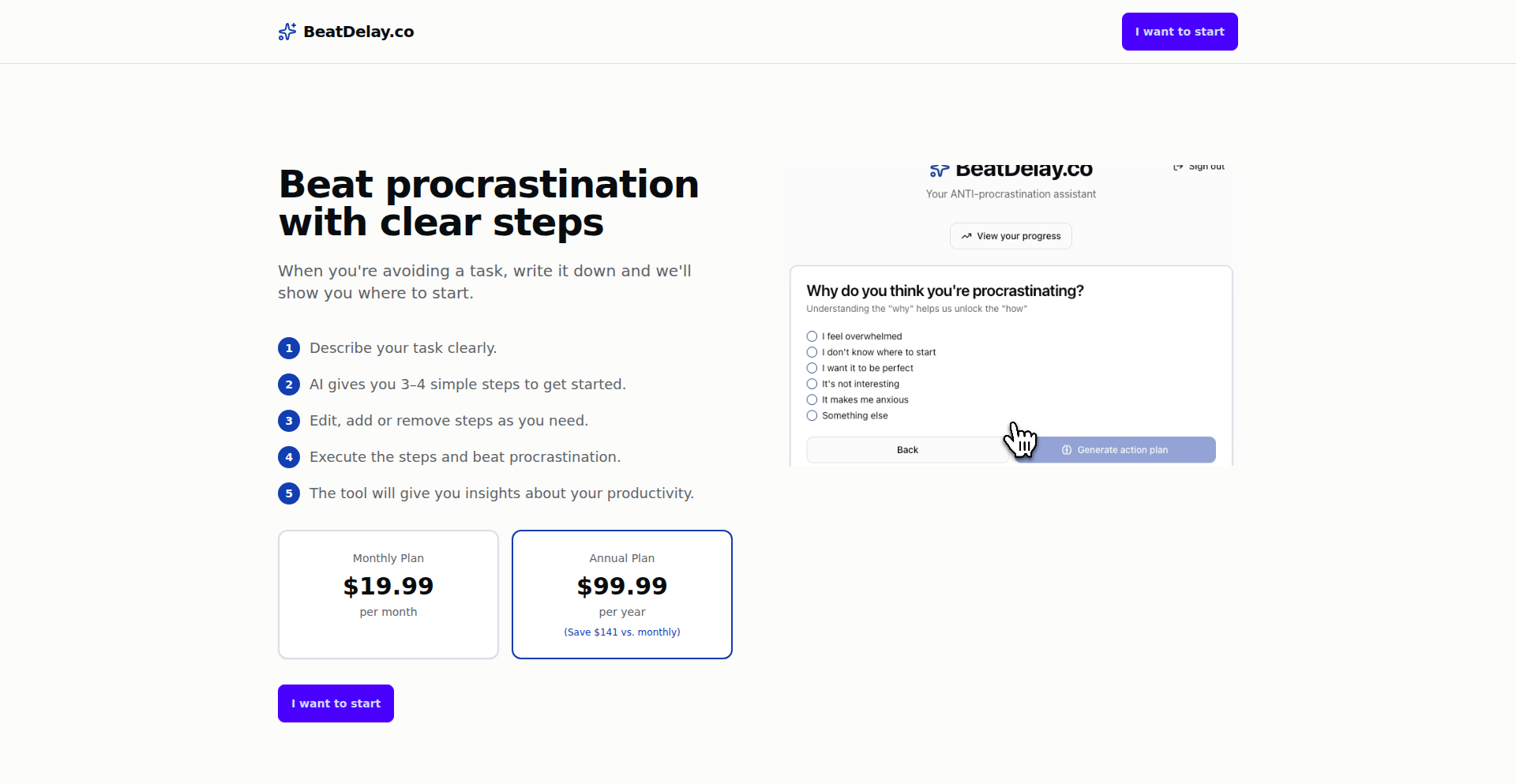
Author
ivanramos
Description
BeatDelay is a web application that tackles procrastination by providing actionable, tailored steps based on the specific reason you're avoiding a task. Instead of generic advice, it analyzes your stated obstacle and generates a micro-plan to get you started immediately. The innovation lies in its adaptive approach to procrastination, moving beyond motivational platitudes to deliver practical, executable guidance.
Popularity
Points 2
Comments 2
What is this product?
BeatDelay is a smart tool designed to help you overcome procrastination. It works by understanding why you're delaying a particular task. You tell it the task and the reason you're avoiding it. The system then uses this information to generate a set of small, concrete steps that you can take right away to break through your inertia. The core innovation is its ability to personalize the advice, recognizing that different procrastination triggers require different solutions. For instance, if you're procrastinating due to feeling overwhelmed, it might suggest breaking the task into minuscule sub-tasks. If it's fear of failure, it might offer steps to reduce the perceived stakes. So, what's in it for you? It's a personalized coach that helps you bypass mental blocks and actually start doing what you need to do, by giving you a clear, immediate path forward.
How to use it?
Developers can use BeatDelay by visiting beatdelay.co. The process is straightforward: 1. Identify an urgent task you're procrastinating on. 2. Go to BeatDelay and input the task. 3. Critically, identify and input the specific reason you're avoiding it (e.g., 'I feel overwhelmed by the scope,' 'I don't know where to start,' 'I'm afraid of making mistakes'). 4. BeatDelay will then generate a series of small, actionable steps tailored to your input. You can integrate this into your workflow by keeping the site open during your work sessions, or by using it as a first step whenever you feel stuck. For developers, this can be particularly useful when facing complex coding challenges, debugging elusive bugs, or starting new project modules. So, how does this help you? It provides an immediate, practical antidote to that paralyzing 'stuck' feeling, helping you maintain momentum and productivity.
Product Core Function
· Task and Procrastination Reason Input: Allows users to specify their task and the underlying cause of their avoidance. This is the foundation for personalized guidance, making the advice relevant and effective. This helps you because it ensures you're not getting generic advice that doesn't address your unique mental roadblock.
· Adaptive Step Generation: Generates a sequence of small, actionable steps based on the user's input. This is the core innovation, translating the 'why' of procrastination into the 'how' of action. This helps you by giving you concrete, bite-sized tasks that are easy to start and complete, building momentum.
· Immediate Action Focus: Designed to provide steps that can be executed instantly, bypassing the need for further planning or motivation speeches. This is key to breaking the procrastination cycle quickly. This helps you by getting you into action immediately, rather than getting stuck in analysis paralysis.
· User-Friendly Interface: Provides a simple and intuitive web interface for quick interaction. This ensures that the tool itself doesn't become another barrier to overcome. This helps you by making it effortless to get the support you need when you need it, without adding complexity to your workflow.
Product Usage Case
· A software developer is procrastinating on writing unit tests for a new feature because they feel it's tedious and they're unsure of the best testing patterns. They input 'Write unit tests for new API endpoint' as the task and 'Unsure of best patterns, feels tedious' as the reason. BeatDelay might then suggest steps like: '1. Research common testing patterns for this API type for 5 minutes. 2. Write a single, simple test case for the most basic input. 3. Refactor that test to follow a chosen pattern.' This helps the developer by providing a clear starting point and reducing the perceived effort, leading to actual test writing.
· A project manager is avoiding starting a complex report because they feel overwhelmed by the amount of data and the need for detailed analysis. They input 'Start Q3 Project Report' and 'Overwhelmed by data and analysis required.' BeatDelay might suggest: '1. Open the data spreadsheet and locate the first required data set. 2. Extract only the first 10 rows of that data. 3. Write down one observation about these 10 rows.' This helps the project manager by breaking down a daunting task into manageable chunks, making it less intimidating and more achievable.
27
LocalDocMaster
Author
party-horse123
Description
A local, privacy-preserving Python documentation generator powered by a small language model (SLM). It automates the creation of comprehensive, Google-style docstrings for your Python code, ensuring your proprietary logic remains secure by running entirely on your machine.
Popularity
Points 4
Comments 0
What is this product?
LocalDocMaster is a smart assistant designed to automatically generate high-quality documentation for your Python code. It uses a lightweight, specifically trained AI model (Qwen3 0.6B parameters) to understand your code's function and output well-formatted docstrings in the widely adopted Google style. The key innovation here is its local execution; unlike cloud-based AI tools, it processes your code directly on your computer. This means your sensitive or proprietary code never leaves your environment, offering significant security and privacy benefits. Think of it as having an AI pair programmer who's an expert in documentation, and they only work on your private codebase, without sending any data out.
How to use it?
Developers can easily integrate LocalDocMaster into their workflow by running a simple Python script. For example, to document a specific Python file named `your_script.py`, you would execute the command `python localdoc.py --file your_script.py` in your terminal. The script will then analyze the provided Python file and automatically generate or update the docstrings for your functions, classes, and modules. This can be used during active development to keep documentation up-to-date, or as a batch process to document an entire project, significantly reducing the manual effort involved in writing clear and consistent documentation.
Product Core Function
· Automatic Docstring Generation: Analyzes Python code to understand its purpose and generates comprehensive docstrings, saving developers significant manual writing time and effort.
· Google Style Formatting: Ensures generated docstrings adhere to the popular and readable Google style, promoting consistency across projects and improving maintainability.
· Local Execution & Privacy: Runs entirely on the developer's machine, guaranteeing that sensitive or proprietary code is never shared with external servers, addressing crucial security and privacy concerns.
· Small Language Model (SLM) Integration: Leverages a compact yet capable AI model for efficient and fast documentation generation, making it accessible even on less powerful hardware.
· Command-Line Interface (CLI) Usage: Provides a straightforward command-line tool for easy integration into existing development workflows and scripting.
Product Usage Case
· During rapid prototyping: A developer is quickly building a new Python library and needs to document functions as they are created. LocalDocMaster can instantly generate a draft docstring for each new function, allowing the developer to focus on the core logic rather than documentation boilerplate, and it keeps the potentially experimental code private.
· For legacy codebases: A project has years of Python code with inconsistent or missing documentation. LocalDocMaster can be run across the entire codebase to automatically generate foundational docstrings, making the code more understandable and easier to onboard new team members, all while ensuring the legacy code's privacy.
· In security-conscious environments: A company deals with highly sensitive financial or intellectual property code. Using LocalDocMaster ensures that no part of this code is ever exposed to cloud AI services, providing peace of mind and compliance with strict data handling policies.
· For open-source contributions: A developer wants to contribute to an open-source Python project but finds the existing documentation lacking. They can use LocalDocMaster locally on their fork to improve the docstrings before submitting a pull request, ensuring their contributions are well-documented without exposing their development environment's details.
28
SchemaTransmuter
Author
amirfarzamnia
Description
A Rust-powered converter that transforms JSON Schema definitions into Luau type annotations. It addresses the challenge of bridging the gap between widely adopted JSON Schema for data validation and Luau's static typing system, commonly used in game development (like Roblox). The innovation lies in its direct conversion, simplifying data handling and improving code safety in Luau environments.
Popularity
Points 3
Comments 1
What is this product?
SchemaTransmuter is a command-line tool built with Rust that takes a JSON Schema file as input and outputs Luau type definitions. JSON Schema is a standard way to describe the structure and constraints of JSON data. Luau is a high-performance Lua dialect with static typing, popular in game development platforms. Traditionally, developers had to manually translate JSON Schema rules into Luau types, which is error-prone and time-consuming. SchemaTransmuter automates this process by parsing the JSON Schema and generating equivalent Luau type annotations, enabling better code completion, compile-time error checking, and overall robustness for applications that ingest JSON data.
How to use it?
Developers can integrate SchemaTransmuter into their build pipelines or use it as a standalone tool. They would typically run the Rust binary, providing the path to their JSON Schema file. The tool then outputs a `.luau` file containing the generated type definitions. This file can be imported into their Luau projects, allowing them to define variables, function parameters, and return types with the generated static types, which are derived directly from the JSON Schema. For example, in a game development context, if you have a JSON configuration file for game items defined by a JSON Schema, SchemaTransmuter can generate Luau types for these items, making it safer and easier to access item properties in your game scripts.
Product Core Function
· JSON Schema Parsing: Understands the structure and constraints defined in a JSON Schema file. This is valuable because it forms the foundation for accurate type generation, ensuring that the generated Luau types reflect the intended data structure.
· Luau Type Generation: Translates parsed JSON Schema constructs into syntactically correct and semantically meaningful Luau type annotations. This provides developers with strong typing for their JSON data, leading to fewer runtime errors and improved code maintainability.
· Cross-Platform Compatibility: Built in Rust, ensuring it can run on various operating systems. This is crucial for developers who work in diverse development environments and need a reliable tool regardless of their platform.
· CLI Interface: Offers a simple command-line interface for easy integration into scripting and build processes. This makes it convenient for automation, allowing developers to generate types automatically whenever their JSON Schema changes.
Product Usage Case
· Game Configuration Loading: A game developer uses JSON to store item stats, level data, or UI configurations. They define these with a JSON Schema. SchemaTransmuter converts this schema into Luau types, allowing the game scripts to safely access and manipulate this data with autocompletion and compile-time checks, preventing errors when reading configuration files.
· API Data Structuring: A developer building a Luau-based application that consumes data from an external API. The API documentation might include a JSON Schema for its responses. SchemaTransmuter can generate Luau types from this schema, ensuring that the application correctly handles incoming API data, reducing the risk of parsing errors and invalid data access.
· Data Validation Integration: When a Luau application needs to validate incoming JSON data against a predefined structure, developers can use the generated Luau types alongside a Luau JSON validator. This creates a robust system where data is not only validated but also strongly typed, enhancing overall data integrity and security within the application.
29
KanjiFlow
Author
yourladybug
Description
KanjiFlow is a fun, open-source and completely free online platform for learning and practicing Japanese Kanji and vocabulary, directly inspired by the popular typing game Monkeytype. It tackles the issue of expensive subscriptions in the Japanese learning app market by offering a user-friendly and customizable experience driven by community contributions. The core innovation lies in its gamified approach to rote memorization, making the often tedious process of learning thousands of Japanese characters engaging and effective.
Popularity
Points 3
Comments 0
What is this product?
KanjiFlow is a web application designed to make learning Japanese characters (Kanji) and vocabulary more enjoyable and effective. It operates on a simple principle: practice makes perfect. The platform uses a game-like interface, similar to typing practice sites, where users are presented with Japanese characters or words and need to type them out correctly. The 'secret sauce' is its approach to spaced repetition and customization. Instead of just presenting information, it actively engages the user through typing challenges. This means it's not just about seeing the character, but actively recalling and writing it, which is crucial for memorization. The open-source nature means developers can inspect its code, suggest improvements, and even contribute features, fostering a community-driven evolution of the learning tools.
How to use it?
Developers can use KanjiFlow by simply visiting the website and starting to practice. For those interested in the underlying technology or contributing, the project is hosted on GitHub. This means developers can clone the repository, experiment with the code, suggest bug fixes, or even add new features. Integration possibilities are broad: a developer could potentially use the project's core logic (e.g., character display and input validation) within their own applications or tools that involve Japanese language processing. The project's open-source nature also allows for self-hosting if desired, giving complete control over the learning environment.
Product Core Function
· Customizable practice sessions: Users can select specific sets of Kanji or vocabulary to focus on, tailoring their learning to their current level and goals. This technical flexibility allows for targeted learning, which is far more efficient than generic study methods.
· Typing-based learning mechanics: The platform uses typing input to reinforce character recognition and recall. This gamified approach leverages muscle memory and immediate feedback to accelerate the learning process, making rote memorization less of a chore and more of an engaging challenge.
· Spaced repetition system: Underlying the practice sessions is an algorithm that schedules reviews of learned characters at optimal intervals. This scientifically proven method ensures long-term retention by revisiting material just before the user is likely to forget it.
· Progress tracking and analytics: Users can monitor their performance, identify areas of weakness, and see their overall improvement over time. This data-driven feedback loop helps learners stay motivated and adjust their study habits for maximum effectiveness.
· Open-source contribution platform: The project's code is publicly available on GitHub, allowing for community collaboration, bug reporting, and feature development. This democratizes the creation of learning tools, ensuring they evolve based on the needs of the users.
Product Usage Case
· A student preparing for the Japanese Language Proficiency Test (JLPT) can use KanjiFlow to specifically practice the Kanji and vocabulary required for their target level. By selecting the appropriate JLPT level in the customizable settings, they can efficiently drill the characters, getting immediate feedback on their typing accuracy and speed, thus solving the problem of having to sift through vast amounts of unfiltered learning material.
· A hobbyist learning Japanese for anime or manga can set up custom practice lists focusing on common characters or vocabulary encountered in their favorite media. The fun, game-like interface makes the learning process feel less like studying and more like playing, keeping them engaged and motivated to continue their language journey without the burden of subscription fees.
· A developer building a Japanese-language game or application might integrate KanjiFlow's character display and input validation logic into their own project. This allows them to leverage robust and well-tested components for handling Japanese text, saving development time and ensuring a higher quality user experience for their Japanese-speaking audience. The open-source nature facilitates this integration by making the code accessible and adaptable.
30
SES Template Maestro
Author
gtlsgamr
Description
A native macOS application designed to streamline the management of AWS Simple Email Service (SES) email templates. It addresses the common developer pain point of juggling API requests, JSON formats, HTML, and command-line scripts by providing a local, intuitive interface for creating, editing, testing, and deploying SES templates directly from your Mac, all while prioritizing local data security and developer workflow efficiency.
Popularity
Points 3
Comments 0
What is this product?
SES Template Maestro is a desktop application for macOS that allows developers to manage their AWS SES email templates offline. Instead of interacting with the AWS console or complex API calls, you can directly edit your email templates using a familiar native text editor. The application securely uses your own AWS credentials stored locally on your machine to sync these templates with your AWS account. This means you can create, modify, and even test sending emails without ever needing to send your template content or credentials to a third-party server, ensuring your data stays private and the process is much faster and less cumbersome. The innovation lies in creating a seamless, local-first developer experience for a cloud service, drastically reducing the friction typically associated with managing email templates.
How to use it?
Developers can download and install SES Template Maestro on their Mac. After installation, they will need to configure their AWS credentials within the app, which it securely stores and uses to authenticate with AWS SES. Once authenticated, developers can begin creating new templates from scratch, editing existing ones in a user-friendly text editor, and testing them by sending sample emails directly through SES. Changes made locally can be synced to their AWS account with a single click. This offers a significant advantage for developers working on projects that heavily utilize AWS SES for email communication, as it allows for quicker iteration cycles and a more organized workflow compared to solely relying on web-based consoles or manual scripting.
Product Core Function
· Local Template Editing: Offers a native text editor for composing and refining email templates, making the process intuitive and efficient. The value is in providing a familiar and fast editing experience, reducing the complexity of working with raw HTML and JSON formats.
· AWS SES Integration via Local Credentials: Securely syncs templates with your AWS SES account using your existing AWS credentials stored on your machine. This provides a significant security benefit and eliminates the need for cloud-based services or API keys to be exposed to third parties, ensuring data privacy and compliance.
· Template Creation and Management: Allows for the creation of new SES templates directly within the app, bypassing the AWS console. This streamlines the initial setup and ongoing management of email templates, saving developers time and effort.
· Email Testing and Sending: Enables developers to test their templates by sending actual emails directly from the application. This is invaluable for verifying template rendering and content before deploying to production, minimizing the risk of sending out incorrect or poorly formatted emails.
· Offline First Design: Operates locally on your Mac without requiring a persistent internet connection for editing and development, and crucially, no cloud backend is involved. This enhances developer productivity by allowing work on templates anytime, anywhere, and ensures data security as no sensitive information leaves the local environment.
Product Usage Case
· A marketing team developing a new email campaign can use SES Template Maestro to quickly iterate on the HTML and subject line of their announcement email. By editing locally and testing directly, they can see how their changes look and feel in real-time, significantly speeding up the campaign launch process and reducing the back-and-forth with their development team.
· A backend developer building a notification system can use SES Template Maestro to create and manage various transactional email templates (e.g., welcome emails, password reset emails). They can easily craft and test these templates locally before integrating them into their application's API calls, ensuring the system sends out clear and correctly formatted communications to users.
· An independent developer working on a personal project can leverage SES Template Maestro to set up email confirmations or account verification emails without needing to manage complex server infrastructure or sign up for additional cloud services. This allows them to quickly implement essential email features in a secure and cost-effective manner, demonstrating the power of local-first development for small-scale projects.
31
SpatialGuard
Author
Shining_S
Description
SpatialGuard is a novel CAPTCHA system that leverages 3D spatial reasoning to distinguish between humans and AI bots. Instead of traditional visual puzzles, it presents users with interactive 3D scenarios requiring manipulation and understanding of spatial relationships, a task currently challenging for most AI. Its core innovation lies in shifting the defense mechanism from pattern recognition to a more complex cognitive process.
Popularity
Points 1
Comments 2
What is this product?
SpatialGuard is a new type of CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart). Unlike typical CAPTCHAs that ask you to identify traffic lights or click on specific images, SpatialGuard presents interactive 3D environments. You might be asked to rotate objects to match a target shape, navigate a simple 3D maze, or complete a spatial puzzle. The innovation here is that current AI, while excellent at many tasks, still struggles with the intuitive understanding of 3D space and object manipulation that humans do effortlessly. This makes it significantly harder for bots to pass the test, thus improving website security.
How to use it?
Developers can integrate SpatialGuard into their web applications to protect against automated bot submissions, such as spam registration, brute-force attacks, or scraping. It's designed to be embedded as a widget on login pages, signup forms, or comment sections. The integration typically involves a JavaScript SDK that handles the rendering of the 3D challenge and communication with the backend for verification. When a user encounters the SpatialGuard challenge, they interact with the 3D elements directly in their browser. Upon successful completion, the application receives a verification token, allowing the user to proceed. This provides a more robust barrier against bots without overly burdening legitimate human users.
Product Core Function
· 3D spatial puzzle generation: Creates unique, procedurally generated 3D puzzles for each challenge, ensuring variety and preventing bots from simply memorizing solutions.
· Interactive 3D rendering engine: Utilizes web-based 3D technologies (like WebGL) to display and allow user interaction with complex 3D scenes directly in the browser, offering a rich user experience.
· AI-resistant challenge design: Formulates challenges that require sophisticated spatial understanding and manipulation, which are inherently difficult for current AI models to replicate accurately.
· Real-time verification API: Provides a backend service to quickly verify user responses to the spatial challenges, enabling seamless integration into existing security workflows.
· Human-centric usability: Focuses on creating puzzles that are intuitive and engaging for humans, minimizing friction while maximizing security effectiveness.
Product Usage Case
· Protecting user registration forms on e-commerce sites: A user signing up for an account faces a SpatialGuard puzzle. If a bot tries to automate account creation for fraudulent purposes, it will likely fail to solve the 3D spatial reasoning test, blocking the malicious activity.
· Securing comment sections on blogs or forums: To prevent spam comments, SpatialGuard can be deployed. Humans can easily solve a quick 3D object manipulation task, while bots programmed for text-based spam will be deterred.
· Preventing automated ticket scalping for events: When users try to purchase tickets for popular events, a SpatialGuard challenge can be presented. This makes it harder for bots to rapidly buy up all available tickets, ensuring fairer access for human customers.
· Adding a layer of security to API endpoints: For APIs that are susceptible to abuse by bots, SpatialGuard can be used as an authentication step, requiring a successful spatial challenge before granting access to sensitive data or functionalities.
32
CurAIted.dev: AI Dev Digest Engine
Author
mmntns
Description
CurAIted.dev is an AI-powered news aggregator specifically for AI development. It intelligently summarizes high-quality AI content, making it easier for engineers to stay informed without getting overwhelmed. The innovation lies in combining AI summarization with human curation of sources, focusing on foundational AI concepts rather than just product launches. This means engineers get a digestible overview of what truly matters in AI, saving them significant time and effort.
Popularity
Points 2
Comments 1
What is this product?
CurAIted.dev is a smart digest of AI development news. It uses AI (specifically Large Language Models or LLMs) to read through various AI articles and create concise summaries. Think of it like having a super-fast assistant that filters and condenses the most important AI research and trends for you. The 'curated' part means humans also select the original sources, ensuring the content is relevant and high-quality. The innovation is in this hybrid approach: AI for speed and scale in summarization, and human judgment for quality and focus on fundamental concepts, all delivered in a blog-like format.
How to use it?
Developers can use CurAIted.dev by visiting the website regularly to get quick updates on AI advancements. It's designed to be a time-saver, allowing busy engineers to grasp key AI trends and research without needing to read multiple lengthy articles. The platform is built with Astro, a modern web framework, and its content pipeline uses Python and LLMs for efficient crawling and summarization. For developers looking to integrate similar AI summarization capabilities into their own workflows, CurAIted.dev serves as an excellent example of leveraging LLMs for content processing. It's also a testament to building sophisticated applications using cost-effective free tiers, demonstrating lean development practices.
Product Core Function
· AI-powered content summarization: Uses LLMs to condense complex AI articles into easy-to-understand summaries, saving developers time by delivering key insights quickly.
· Human-curated sources: A team carefully selects the original articles to be summarized, ensuring the information is relevant, accurate, and focused on fundamental AI concepts. This provides a quality filter for the AI-generated content.
· Digestible blog-style format: Presents information in a familiar and easy-to-read blog format, making it simple for developers to browse and consume updates on AI development.
· Focus on fundamentals: Prioritizes core AI concepts and research over fleeting product announcements, offering deeper, more impactful knowledge for engineers.
· Cost-effective infrastructure: Built using free tiers for most services, demonstrating efficient resource management and the possibility of launching impactful projects with minimal financial overhead.
Product Usage Case
· A machine learning engineer needs to stay updated on the latest breakthroughs in transformer architectures. Instead of reading dozens of research papers, they can check CurAIted.dev for AI-generated summaries of the most significant new developments, quickly grasping the core innovations and their implications.
· A software developer wants to understand the practical applications of Reinforcement Learning in robotics. CurAIted.dev might surface and summarize articles detailing recent successful RL implementations, providing actionable insights without requiring extensive research into the underlying academic work.
· A startup founder is exploring emerging AI trends to identify potential product opportunities. By following CurAIted.dev, they can efficiently survey the landscape of AI research and identify foundational shifts that could lead to future innovations.
· A data scientist is experimenting with new NLP techniques. CurAIted.dev can provide quick overviews of cutting-edge research in NLP, helping them discover relevant papers or new approaches they might not have found through traditional search methods.
33
Agent Playbook: Interactive AI Agent Sandbox
Author
orlevii
Description
Agent Playbook is an open-source, Storybook-inspired tool that acts as a dedicated playground for developing and debugging AI agents. It addresses the common pain point of slow and disruptive testing cycles in AI agent development. By offering an isolated, interactive environment, it allows developers to rapidly iterate on prompts and tools without needing to run their entire application or write repetitive scripts. This significantly speeds up the development workflow and maintains developer focus. The core innovation lies in applying the component-driven development paradigm from UI frameworks like Storybook to the world of AI agents, enabling a more structured and efficient development process.
Popularity
Points 3
Comments 0
What is this product?
Agent Playbook is essentially a specialized web-based environment designed for developers who build AI agents. Think of it like a "testing kitchen" specifically for your AI creations. Its core technical innovation is to borrow a concept from UI development called "component isolation." Just as Storybook lets you test individual UI elements (like a button or a card) in isolation, Agent Playbook lets you test your AI agents individually. This means you can interact with a single agent, send it specific inputs, and see exactly how it responds and what reasoning steps it took to get there. This is achieved by automatically discovering your defined agents (initially supporting those built with pydantic-ai) and then launching a local web interface. This interface provides a chat-like experience where you can converse with your agent, observe its internal thought process (reasoning steps), and make quick changes to its prompts or logic, with updates reflecting almost instantly (hot-reloading). So, its value is in making AI agent development significantly faster and more predictable by allowing focused, iterative testing.
How to use it?
Developers can integrate Agent Playbook into their AI agent development workflow by installing it (typically via pip for Python projects). Once installed, and assuming their AI agents are structured using compatible libraries like pydantic-ai, Agent Playbook can automatically detect these agents. The tool then launches a local web server that hosts a user-friendly interface. Developers can access this interface through their web browser. Within this interface, they can select an agent they want to test, input various queries or prompts, and observe the agent's responses and internal reasoning. If a change is made to the agent's code or prompt, the playbook will often reflect these updates with minimal delay, allowing for a very rapid feedback loop. This makes it ideal for scenarios where you're constantly tweaking an agent's instructions or the tools it has access to, and you need to see the results of those changes immediately without redeploying your entire system.
Product Core Function
· Automatic agent discovery: The value here is that developers don't need to manually configure each agent they want to test. The system intelligently finds your AI agents, saving setup time and reducing the chance of errors. This means you can get to testing your agent's behavior much faster, which is crucial for rapid iteration.
· Interactive chat interface: This function provides a direct way to communicate with your AI agent in a simulated environment. The value is that it offers a realistic testing ground to see how the agent handles various conversational inputs and requests, allowing you to identify conversational flow issues or unexpected responses.
· Reasoning step inspection: This core feature allows you to see the "thought process" of your AI agent. The value is in understanding *why* an agent produced a particular output. This is invaluable for debugging, as it pinpoints where the agent's logic might be flawed, leading to more effective fixes and improvements.
· Hot-reloading for rapid iteration: This means that when you make changes to your agent's code or prompts, the playbook updates the agent's behavior in the interface almost instantly. The value is a dramatically reduced development cycle. You can test a change, see its effect immediately, and then make another adjustment without any significant delay, which greatly enhances productivity and experimentation.
· Component-like isolation for agents: Borrowing from UI development, this allows testing agents independently of the larger application. The value is that it simplifies debugging and development by preventing interference from other parts of your system. You can focus solely on the agent's performance and behavior, making it easier to pinpoint and resolve issues.
Product Usage Case
· A developer is building an AI agent that summarizes long documents. They've written the prompt and a tool that accesses the document. Using Agent Playbook, they can repeatedly feed different documents to the agent and instantly see if the summaries are accurate and concise. If the summaries are too long or miss key points, they can adjust the prompt in the playbook and see the effect immediately, without restarting their entire application. This solves the problem of slow testing cycles when refining summarization quality.
· An AI agent is designed to book appointments. It needs to understand user requests, check availability via a calendar API, and confirm the booking. When developing this agent, the developer can use Agent Playbook to simulate various user requests ('Book a meeting for next Tuesday at 3 PM'). They can then inspect the agent's reasoning to see if it correctly parsed the date and time, if it accurately queried the calendar API (even if the API interaction is mocked in the playbook), and if it generated the correct confirmation message. This helps debug issues related to natural language understanding and API integration in a controlled environment.
· A developer is experimenting with different LLM models for a chatbot. They can configure Agent Playbook to use various models and then have it interact with a set of predefined test dialogues. By observing the agent's responses and reasoning steps across different models, they can quickly identify which model performs best for their specific use case, greatly accelerating model selection and A/B testing of LLM capabilities.
34
KanjiType
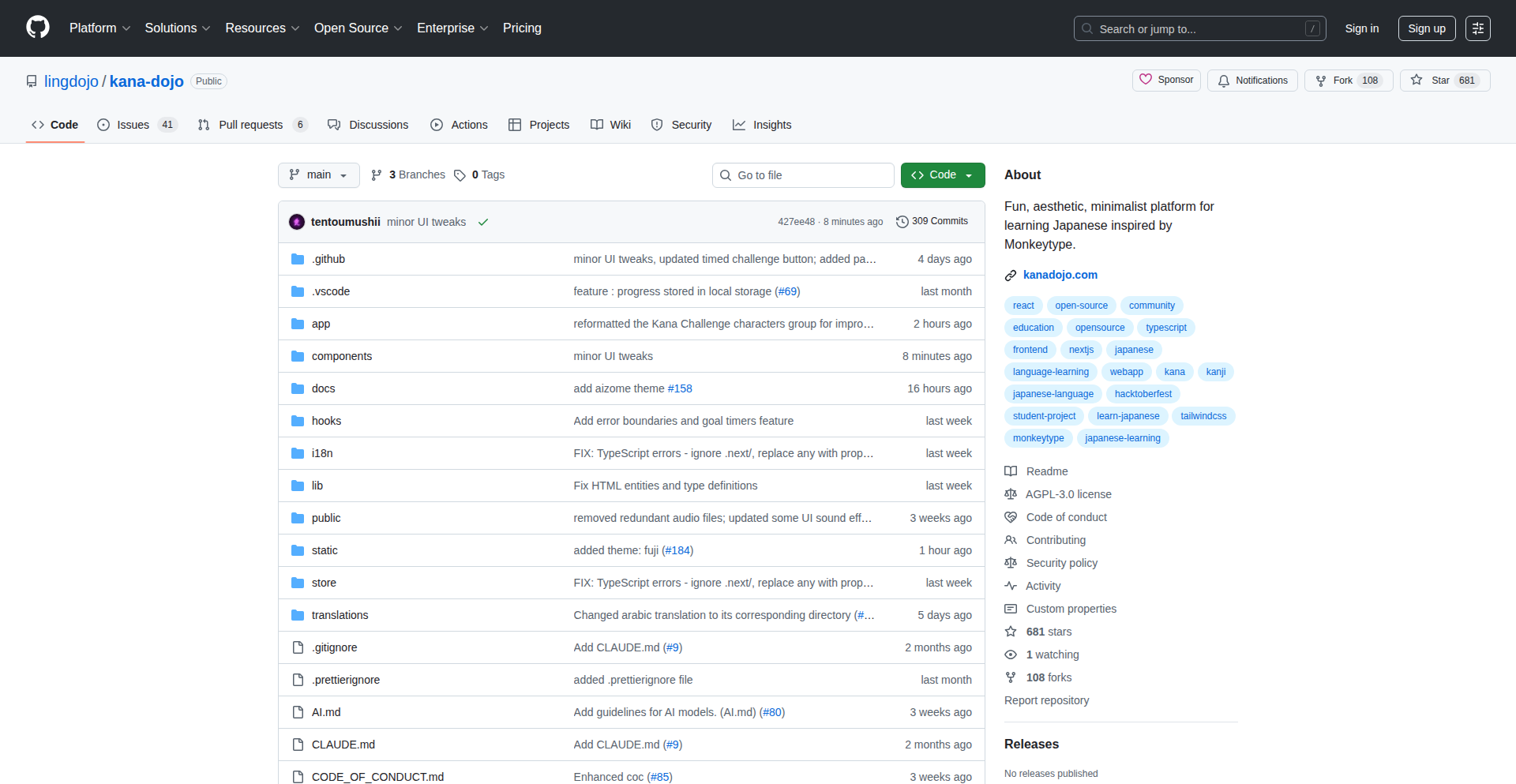
Author
aladybug
Description
KanjiType is a free, open-source Japanese learning platform inspired by Monkeytype, designed to help users practice Kanji and vocabulary. Its core innovation lies in applying gamified typing mechanics to language learning, offering a fun and customizable experience without subscription fees. This addresses the common frustration of paywalls and limited free options in language learning apps, providing a community-driven alternative.
Popularity
Points 3
Comments 0
What is this product?
KanjiType is a web application that reimagines language learning through a typing-game interface. Instead of rote memorization, users practice Japanese Kanji and vocabulary by typing them out rapidly, similar to how touch-typing trainers work. The underlying technology likely involves front-end frameworks for interactive UI (like React or Vue.js), efficient data handling for large character sets, and potentially some backend logic for user progress tracking and customization options. The innovation is in translating the addictive, skill-building nature of typing games into the challenging domain of Japanese language acquisition, making it more engaging and less intimidating.
How to use it?
Developers can use KanjiType by visiting the project's website. They can directly start practicing Kanji and vocabulary through interactive typing exercises. For developers interested in contributing or customizing, the platform is open-source on GitHub. This means they can fork the repository, modify the code to add new features, improve existing ones, or integrate it with other learning tools. They can also self-host the application if they prefer a private instance. The platform is designed to be user-friendly, requiring no complex setup for basic usage.
Product Core Function
· Customizable practice modes: Users can select specific Kanji or vocabulary sets to practice, tailoring the learning experience to their current skill level and goals. This provides targeted learning and efficiency, ensuring users focus on what they need to improve.
· Typing-based learning engine: Leverages fast-paced typing to reinforce character recognition and recall. This makes learning feel like a game, increasing engagement and retention compared to traditional methods.
· Progress tracking and statistics: Users can monitor their speed, accuracy, and learning streaks, providing motivation and insights into their improvement. This data-driven approach helps users understand their progress and stay committed.
· Open-source and community-driven: The platform's code is publicly available, allowing for community contributions, bug fixes, and feature development. This fosters a collaborative environment and ensures the platform evolves based on user needs, offering a sustainable and adaptable learning resource.
· Ad-free and subscription-free: Provides an entirely free and ad-free learning experience. This removes financial barriers to learning Japanese, making high-quality education accessible to everyone.
Product Usage Case
· A beginner Japanese learner struggling with Kanji memorization can use KanjiType to practice specific sets of characters, improving their recognition speed and accuracy through timed typing challenges. This solves the problem of tedious memorization by making it fun and interactive.
· An intermediate learner aiming to expand their vocabulary can select themed vocabulary lists to type out, reinforcing their understanding and recall of new words in a dynamic way. This offers a practical application for new vocabulary beyond simple flashcards.
· A developer interested in contributing to open-source projects could fork KanjiType, add a new feature like spaced repetition integration, and submit a pull request. This demonstrates how the project serves as a platform for developers to hone their skills and contribute to a valuable tool.
· An educator looking for free, engaging resources for their students can direct them to KanjiType, providing a supplementary tool that makes learning Kanji and vocabulary more enjoyable and effective. This offers a cost-effective and motivating alternative to expensive learning software.
35
JIT-Compiled AI Agents
Author
ardmiller
Description
This project explores the idea of Just-In-Time (JIT) compiling AI agents, specifically inspired by the concept of MCP (Master Control Program) agents from Tron. The core innovation lies in translating the decision-making logic of AI agents into executable code on the fly, rather than relying on traditional interpreted execution. This could significantly boost the performance and responsiveness of AI agents.
Popularity
Points 3
Comments 0
What is this product?
This project is an experimental investigation into enhancing AI agent performance by using Just-In-Time (JIT) compilation. Imagine AI agents as little digital brains that make decisions. Normally, these brains think step-by-step, which can be a bit slow. This project's idea is to take the agent's thought process and, at the exact moment it's needed, convert it into highly optimized, ready-to-run computer instructions (like compiling a program). This is similar to how modern programming languages make their code run much faster by compiling it right before it's executed. The innovation is applying this speed-up technique to the dynamic and emergent behavior of AI agents, moving beyond static, interpreted AI models.
How to use it?
Developers can use this as a conceptual blueprint or a foundational library for building high-performance AI systems. It's designed for scenarios where AI agents need to react extremely quickly and efficiently, such as in real-time simulations, complex game AI, or high-frequency trading algorithms. The integration would involve defining the agent's behavior in a high-level language or a structured format, and then using the JIT compilation engine to transform this logic into native machine code for execution, offering a significant speed boost compared to traditional AI frameworks that rely on interpreters.
Product Core Function
· Dynamic Agent Logic Compilation: Translates AI agent decision logic into optimized machine code at runtime, enabling faster execution and reduced latency for AI-driven actions. This is valuable because it makes AI agents react much quicker, which is crucial for real-time applications.
· JIT Compilation Engine for AI Models: Provides a framework for performing Just-In-Time compilation specifically tailored for AI agent architectures, offering a performance advantage over purely interpreted AI models. This is useful for developers who need the absolute best performance from their AI agents without sacrificing flexibility.
· MCP-Inspired Agent Framework: Structures AI agents in a way that facilitates JIT compilation, drawing inspiration from concepts like Tron's MCP for modular and efficient agent design. This helps in creating more organized and efficient AI agents, making them easier to manage and optimize.
Product Usage Case
· Real-time Strategy Game AI: In a fast-paced RTS game, AI agents controlling units need to make split-second decisions. By JIT compiling their decision trees, these agents can respond to enemy actions and manage resources far more effectively, leading to a more challenging and dynamic gameplay experience. This solves the problem of slow AI reactions that make games feel sluggish.
· Robotics and Autonomous Systems: For robots navigating complex environments or controlling delicate machinery, rapid and precise decision-making is paramount. JIT compiling the AI control logic allows for near-instantaneous adjustments to motor commands and pathfinding, improving safety and operational efficiency. This addresses the need for AI that can react immediately to changing physical conditions.
· High-Frequency Trading Bots: In financial markets, milliseconds matter. AI bots executing trades need to process market data and make decisions at extreme speeds. JIT compilation can shave off critical nanoseconds, enabling these bots to capitalize on fleeting market opportunities more effectively. This is valuable for optimizing trading strategies where speed is a competitive advantage.
36
Go-async: Typed Tasks with Async/Await
Author
unkn0wn_root
Description
Go-async is a Go library that brings the power of asynchronous programming, similar to async/await found in other languages, directly into Go. It achieves this by implementing typed Tasks and providing a structured way to handle concurrent operations, making it easier to write non-blocking code and manage complex asynchronous workflows without the traditional complexities of Go's goroutines and channels for every async operation.
Popularity
Points 3
Comments 0
What is this product?
Go-async is a Go library that introduces a modern asynchronous programming paradigm, inspired by the async/await keywords common in languages like Python or JavaScript. It allows developers to write code that appears sequential but executes asynchronously, managing concurrent operations efficiently. The core innovation lies in its implementation of 'typed Tasks'. Think of a Task as a placeholder for a value that will be available in the future, and this placeholder is type-safe, meaning you know exactly what kind of data it will hold. This eliminates common errors associated with managing asynchronous results. Essentially, it simplifies writing concurrent code by providing a more intuitive control flow for operations that don't need to block the main execution thread, reducing the mental overhead of dealing with callbacks or complex channel patterns for many scenarios.
How to use it?
Developers can integrate Go-async into their Go projects by importing the library. You define a 'Task' for an operation that might take time, like fetching data from a network or performing a heavy computation. Then, you can 'await' the result of this Task within another asynchronous function. This means your program doesn't stop and wait for the Task to complete; instead, it can go do other things. When the Task is finished, Go-async seamlessly provides the result. This is particularly useful in applications requiring high concurrency, such as web servers handling many requests simultaneously, or in data processing pipelines where multiple stages can run in parallel. It's about making concurrent Go code easier to write, read, and maintain by abstracting away some of the low-level concurrency primitives when a higher-level, structured approach is more suitable.
Product Core Function
· Typed Task Creation: Allows developers to define asynchronous operations that return a specific, known type of result. This enhances type safety and prevents runtime errors when handling results from concurrent operations.
· Async/Await Syntax: Provides a more readable and intuitive way to write asynchronous code, making it look sequential while executing concurrently. This simplifies the control flow for complex asynchronous workflows.
· Concurrent Task Execution: Enables multiple tasks to run concurrently without blocking the main thread, significantly improving application performance and responsiveness, especially in I/O-bound operations.
· Error Handling for Tasks: Offers structured mechanisms for handling errors that may occur during asynchronous operations, ensuring robustness and easier debugging of concurrent processes.
Product Usage Case
· Building a high-performance web API: Imagine a web server that needs to fetch data from multiple external services before responding to a user request. Go-async allows you to initiate these fetches concurrently and 'await' their results, dramatically reducing the overall request latency and improving the user experience.
· Parallel data processing pipelines: In scenarios where you need to process large datasets in stages, Go-async can be used to run different processing steps in parallel. For example, fetching data, transforming it, and then storing it can all be managed as independent tasks that run concurrently, speeding up the entire process.
· Asynchronous background jobs: For tasks that don't need immediate user feedback, like sending out emails or generating reports, Go-async provides a clean way to offload these operations to run in the background without impacting the responsiveness of the main application thread.
· Building responsive UIs (in a Go context, e.g., server-rendered): For applications that involve fetching data for display, using Go-async can ensure that the server remains responsive to other requests while waiting for data to load, leading to a smoother overall experience.
37
AgenticLLM-Elixir
Author
kenforthewin
Description
OpEx is an agentic LLM toolkit designed for Elixir developers. It allows them to leverage the power of large language models (LLMs) within their Elixir applications, enabling more intelligent and interactive functionalities. The core innovation lies in its approach to building LLM-powered agents that can execute complex tasks autonomously, simplifying integration and development for Elixir developers.
Popularity
Points 3
Comments 0
What is this product?
This project, OpEx, is a toolkit that helps Elixir developers build 'agentic' applications using Large Language Models (LLMs). Think of LLMs like advanced AI brains that can understand and generate text. 'Agentic' means these AI brains can act independently to achieve goals. OpEx provides the tools and structure for Elixir developers to easily connect their Elixir code to these LLM brains, allowing them to create applications that can reason, plan, and execute tasks. The innovative part is how it simplifies the process of making these LLMs work like smart assistants within Elixir, handling the complex communication and orchestration required for them to be truly useful.
How to use it?
Elixir developers can use OpEx by integrating it into their existing or new Elixir projects. It acts as a bridge, allowing them to send prompts and instructions to an LLM and receive structured responses. This can be used for a variety of tasks, such as automatically generating code, summarizing documents, answering complex queries, or even controlling other parts of their application based on AI-driven decisions. The toolkit aims to make this integration as seamless as possible, so developers can focus on the business logic rather than the intricate details of LLM interaction.
Product Core Function
· LLM Agent Orchestration: Enables developers to define and manage multiple LLM agents that can collaborate to solve a problem. The value here is in allowing complex, multi-step AI tasks to be broken down and handled efficiently, making sophisticated AI capabilities accessible.
· Prompt Engineering Abstractions: Provides convenient ways to construct and manage prompts sent to LLMs. This is valuable because well-crafted prompts are crucial for getting accurate and useful responses from LLMs, and OpEx makes this process more manageable and repeatable.
· Tool Integration for Agents: Allows LLM agents to interact with external tools or services (e.g., databases, APIs). The value is in empowering AI agents to perform actions in the real world or access real-time data, extending their capabilities beyond just text generation.
· State Management for Agents: Helps agents maintain context and memory across multiple interactions. This is crucial for building conversational AI or agents that need to remember past actions and decisions, providing a more intelligent and coherent user experience.
· Asynchronous LLM Communication: Handles the communication with LLMs in a non-blocking way, which is essential for building responsive Elixir applications. This ensures that your application doesn't freeze while waiting for an AI to respond, maintaining a smooth user experience.
Product Usage Case
· Automated Code Generation: A developer could use OpEx to build a tool that takes a natural language description of a feature and automatically generates the Elixir code for it. This solves the problem of tedious boilerplate code writing and speeds up development.
· Intelligent Customer Support Bot: Imagine an Elixir-based customer support system enhanced with OpEx. The LLM agent could understand complex user queries, access product documentation, and generate helpful, personalized responses, reducing the workload on human support staff.
· Data Analysis and Summarization: Developers could use OpEx to build applications that automatically analyze large datasets, identify key trends, and generate concise summaries. This is invaluable for extracting insights from data without manual review.
· Content Creation Assistant: For applications that involve generating articles, marketing copy, or social media posts, OpEx can power an AI assistant that helps brainstorm ideas, draft content, and refine existing text, significantly improving content production efficiency.
38
SwiftShare Hub
Author
benjohnson8
Description
SwiftShare Hub is a developer-built experiment designed to streamline cross-platform file sharing. It tackles the inherent complexity of transferring files between different operating systems (like Android to Mac, or iPhone to Windows) by offering a simple, web-based solution. Unlike ecosystem-locked tools like AirDrop or account-requiring services, SwiftShare Hub allows users to upload files and share them instantly via a QR code or a short numeric code, accessible from any device with a web browser. This innovative approach removes the need for installations or logins, focusing on speed and privacy, with files automatically disappearing after 30 minutes.
Popularity
Points 2
Comments 0
What is this product?
SwiftShare Hub is a web application acting as a frictionless bridge for file sharing across any devices and operating systems. The core technical innovation lies in its simplicity: it leverages web technologies to bypass the need for dedicated apps or account registrations, which are common friction points in existing solutions. When you upload a file, the server generates a unique, short-lived link. This link is then presented as a QR code or a simple 6-digit code. Anyone with the link or code can access the file directly from their browser on their device, regardless of its OS. The files are ephemeral, auto-deleting after a set time to ensure privacy and reduce server load. So, what's the value? It provides a universally accessible and temporary way to send files without the hassle of setup or privacy concerns of permanent storage.
How to use it?
Developers can use SwiftShare Hub by simply visiting the website (SpeedyShare.app as per the original project). They upload their desired file through the web interface. The system then provides a QR code and a 6-digit code. These can be shared instantly with recipients. For example, a developer working on a mobile app might want to quickly share a screenshot or a small build artifact with a colleague on a different platform. They upload it to SwiftShare Hub, get the QR code, and their colleague scans it with their phone or enters the code on their computer, and the file is immediately available for download. It's designed for ad-hoc sharing, making it useful for quick collaboration and testing scenarios.
Product Core Function
· Universal File Upload: Enables users to upload any file type from their device to the web server. The value here is the ability to initiate the sharing process without device or OS constraints.
· QR Code Sharing: Generates a scannable QR code that directly links to the uploaded file. This is valuable for quick, contactless sharing, especially between mobile devices and desktops.
· Short Code Sharing: Provides a 6-digit alphanumeric code for accessing files, useful for situations where QR code scanning isn't feasible or for sharing verbally. This offers an alternative access method that is easy to remember and communicate.
· Browser-Based Access: Allows recipients to download files directly through their web browser without installing any software. This significantly reduces friction and broadens accessibility across all internet-connected devices.
· Ephemeral File Storage: Automatically deletes uploaded files after a configurable period (e.g., 30 minutes). This provides peace of mind regarding data privacy and reduces unnecessary storage overhead.
· Anonymous Analytics: Collects basic, non-identifiable usage data to understand user behavior and improve the service without compromising user privacy. This is valuable for maintaining a privacy-focused service while gaining insights for development.
Product Usage Case
· A developer needs to send a design mockup image from their Mac to a colleague using an Android phone. Instead of emailing attachments or using a clunky cloud service, they upload the image to SwiftShare Hub, get a QR code, and their colleague scans it with their phone to download the image instantly.
· During a hackathon, a team member needs to quickly share a small script file with other members who are using a mix of Windows and Linux machines. They upload the script via SwiftShare Hub, share the 6-digit code in their team chat, and everyone can access and download the file without any installation steps.
· A QA tester wants to share a crash log file from an iOS device with a remote developer on a Windows PC. They upload the log file through SpeedyShare.app on their iPhone, and share the generated link via a messaging app. The developer can then access and download the log file on their Windows machine directly from their browser.
· A user wants to share a recipe they just found online with a friend who is at home. They copy the URL, upload it (as a link that can be opened by the recipient), generate a QR code, and send it to their friend. The friend scans the QR code on their phone, and the recipe page opens, making it a quick way to share web content.
39
Martillo: Hackable Lua Command Palette
Author
sjdonado
Description
Martillo is a highly customizable, open-source alternative to tools like Raycast, built entirely in pure Lua. It empowers developers to create custom workflows, automate tasks, and leverage a powerful command palette with fuzzy search. Its innovation lies in its zero-configuration loading of Lua files and its declarative configuration, making it incredibly easy to extend and share. It seamlessly integrates with macOS system APIs through Hammerspoon, offering a deep level of control and automation.
Popularity
Points 2
Comments 0
What is this product?
Martillo is a developer-centric command palette and workflow automation tool. At its core, it's a framework written in Lua, a lightweight scripting language. The 'hackable' aspect means you can easily modify and extend its functionality by dropping your own Lua scripts into a designated folder. It uses Hammerspoon, a powerful macOS automation tool, to interact directly with your operating system at a deep level. The innovation here is its simplicity and extensibility: no complex setup, just pure Lua code that's easy to read, write, and share. This allows for incredibly tailored automation and task management.
How to use it?
Developers can use Martillo by writing custom Lua scripts. These scripts can define new commands, create shortcuts, and automate repetitive tasks. You can configure keybindings, define custom aliases for complex commands, and chain actions together using provided helper functions. The configuration is stored in a single file, making it easy to manage and share your custom setup. For example, you could write a script to quickly open specific project folders, run build commands, or even control application windows with custom shortcuts. It integrates by running as a background process on macOS and is activated by a keyboard shortcut.
Product Core Function
· Customizable Command Palette: Provides a fuzzy search interface for quickly finding and executing commands, scripts, or workflows. The value is in streamlining access to frequently used actions and reducing context switching.
· Lua Scripting Engine: Allows users to write custom automation scripts in Lua, enabling deep customization of workflows and system interactions. The value is in empowering users to build exactly what they need for their specific development environment.
· Zero-Configuration Script Loading: Scripts placed in the 'store/' directory are automatically loaded, simplifying the process of adding new functionality. The value is in rapid iteration and experimentation with new automation ideas.
· Declarative Configuration: All settings, including keybindings and aliases, are defined in a single, readable configuration file, making it easy to manage and share. The value is in promoting reproducible and shareable automation setups.
· Hammerspoon Integration: Leverages Hammerspoon's access to macOS system APIs for advanced automation, such as window management, clipboard manipulation, and process control. The value is in unlocking powerful system-level automation capabilities that are not typically available.
· Pre-built Actions: Ships with over 60 ready-to-use actions, including clipboard history, process management, window positioning, and utility functions. The value is in providing immediate utility and examples of what can be achieved with Martillo.
Product Usage Case
· Scenario: A developer frequently switches between multiple project directories and needs to quickly open them in their IDE. How it solves the problem: They can write a Lua script that defines a command like 'open project-name' which, when executed via Martillo's command palette, automatically navigates to and opens the specified project in their preferred IDE. This saves significant time compared to manual navigation.
· Scenario: A user wants to quickly copy the current URL from their browser to their clipboard and then paste it into a specific note-taking application. How it solves the problem: A Lua script can be created to capture the active browser tab's URL and then trigger a paste action in a designated application, automating a common, multi-step process.
· Scenario: A developer needs to manage running processes on their machine, frequently needing to kill unresponsive applications. How it solves the problem: Martillo includes a process killer action, allowing them to quickly search for and terminate processes directly from the command palette without needing to open the Activity Monitor. This provides a faster and more integrated way to manage system resources.
· Scenario: A user wants to quickly resize and position windows on their screen for an optimal multi-tasking layout. How it solves the problem: Martillo's window positioning actions allow for pre-defined or custom window arrangements to be applied with a simple keyboard shortcut or command, enhancing productivity by creating consistent and efficient desktop environments.
40
XMacroCLI: Header-Only C CLI Parser
Author
tyk001
Description
XMacroCLI is a minimalist, header-only Command Line Interface (CLI) parser for C. It uses a clever C preprocessor technique called X-Macros to achieve simplicity and ease of integration. It can parse common command-line arguments like flags (e.g., -h) and options that take integer, float, or string values (e.g., --port 8080). The key innovation is its header-only nature and the X-Macro implementation, which means developers can easily drop it into their C projects without complex build processes or external dependencies. This solves the common problem of needing a straightforward way to handle user input from the command line in C applications, especially for smaller projects where heavy frameworks are overkill.
Popularity
Points 2
Comments 0
What is this product?
XMacroCLI is a C library that helps your program understand commands and settings you type when you run it from your terminal. Think of it like teaching your C program to read instructions. The 'header-only' part means you don't need to compile a separate library file; you just include a single file in your project, making it super easy to add to existing or new C code. The 'X-Macros' technique is a C preprocessor trick that allows the code to be defined once and used in multiple places, leading to less repetition and a more maintainable codebase. It's designed to be lightweight and efficient, focusing on the core task of parsing basic command-line arguments for flags and options, without getting bogged down in complex features. This means if you're writing a C program and want a simple way to let users specify things like a port number or a configuration file path directly when they launch your program, XMacroCLI offers a clean and integrated solution.
How to use it?
Developers can use XMacroCLI by simply including the provided header file in their C project. They then define their expected command-line arguments (flags and options with their types) using the X-Macro structure within the header file itself. At runtime, they pass the program's arguments (like `argc` and `argv` from `main`) to the XMacroCLI parsing function. The library will then parse these arguments and populate variables or structures defined by the developer, making the parsed values readily available for use in the C code. This integration is seamless, requiring minimal boilerplate code and avoiding the need for complex build system configurations. It's ideal for scenarios where you're building command-line utilities, embedded systems that receive configuration via command-line, or any C application where user input from the terminal is a requirement.
Product Core Function
· Argument Parsing: The core capability is to parse command-line arguments provided by the user. This allows developers to build interactive and configurable C applications by understanding what the user intends to do or what settings they want to apply when running the program. The value here is enabling dynamic behavior based on user input.
· Flag Handling: Specifically handles simple flags like '-h' for help or '-v' for verbose output. This is a fundamental aspect of command-line interfaces, enabling quick toggling of program behaviors or providing immediate information to the user. The value is providing clear and concise control over program execution.
· Option Parsing with Data Types: Supports options that take arguments, such as '--port 8080' or '--config my_settings.txt'. It can correctly interpret these arguments as integers, floats, or strings. This is crucial for passing configuration parameters to an application, allowing users to specify values like network ports, file paths, or numerical thresholds without modifying the source code. The value is offering flexible and data-aware input handling.
· Header-Only Integration: The library is provided as a single header file, meaning it can be directly included in any C project without the need for separate compilation or linking steps. This significantly simplifies project setup and maintenance, especially for smaller projects or when rapidly prototyping. The value is reducing build complexity and accelerating development.
· X-Macro Implementation: Leverages X-Macros for defining argument structures and parsing logic. This is an advanced C preprocessor technique that allows for code generation and reduced duplication, leading to a more concise and maintainable parser. The value is in offering an elegant and efficient technical solution for a common programming problem.
Product Usage Case
· Developing a simple C-based network utility that needs to accept a port number and an IP address from the command line. XMacroCLI can parse '--port 8080' and '--address 192.168.1.1', making it easy to configure the network connection without hardcoding values, thus solving the problem of flexible network configuration.
· Building a C command-line tool for processing text files, where users might want to specify input and output file paths, and perhaps a processing mode flag (e.g., '--mode fast'). XMacroCLI can handle '--input input.txt', '--output output.txt', and '-m fast', allowing users to control file operations and processing logic directly from the terminal, solving the problem of automated file processing with user-defined parameters.
· Creating a C embedded system application that needs to receive initial configuration parameters upon boot from a serial console or a bootloader. XMacroCLI can be used to parse these parameters, enabling dynamic setup of the embedded device without requiring code changes, thus solving the problem of configurable embedded system initialization.
· Writing a C library that requires users to specify certain parameters during its usage, like sampling rates for sensor data or thresholds for alarm conditions. By using XMacroCLI, the library users can pass these parameters via the command line when running a test application or an example, providing a clear and accessible way to experiment with different settings, solving the problem of easy parameter experimentation for library users.
41
LindraAI-WebAPI
Author
valliveeti
Description
LindraAI-WebAPI transforms any website into a programmable API using an advanced browser agent. It leverages a powerful combination of Gemini 2.5 Pro and Flash for highly efficient, low-token context processing, enabling cost-effective automation of web actions. The core innovation lies in its ability to dramatically reduce the expense typically associated with browser automation, making complex web tasks accessible for broader application.
Popularity
Points 2
Comments 0
What is this product?
LindraAI-WebAPI is a service that acts as a smart intermediary between you and any website. Think of it like giving a website a translator and a helper that can understand your instructions. Instead of you manually clicking and typing on a website, you can tell LindraAI what you want to do, and it will use its advanced 'browser agent' – a sophisticated piece of software – to perform those actions. The 'browser agent' is built using cutting-edge AI models like Gemini 2.5 Pro and a system called 'Flash', which are incredibly good at understanding web content and performing tasks. The key innovation here is how efficiently it works. Traditional tools that automate browser actions can be very expensive and slow because they often need to 'read' a lot of information from the webpage. LindraAI significantly cuts down on this 'reading' process, making it much cheaper and faster to automate tasks, without sacrificing accuracy. So, what's the benefit for you? It means you can automate more complex tasks on more websites for less money, opening up possibilities for new tools and services.
How to use it?
Developers can integrate LindraAI-WebAPI into their applications by interacting with it through a chat interface or an API. You can simply describe the task you want to accomplish on a specific website, and LindraAI will generate an API endpoint or provide the automated results. For instance, if you need to extract data from a public website, you can instruct LindraAI to do so. It will then perform the necessary actions in a simulated browser environment and return the data to you in a structured format. This allows for seamless integration into existing workflows, custom dashboards, or automated reporting systems. The primary use case is to simplify web scraping and automated web interactions, making them accessible to developers who might not have deep expertise in browser automation tools, or for businesses looking to reduce operational costs for such tasks.
Product Core Function
· Website to API Conversion: Transforms any website into a callable API, allowing programmatic access to its content and functionality. Value: Enables developers to build applications that interact with web data and services without manual intervention, saving significant development time and resources.
· Efficient Browser Agent: Utilizes a highly optimized browser agent powered by Gemini 2.5 Pro and Flash for minimal token usage. Value: Dramatically reduces the cost and increases the speed of web automation tasks, making previously uneconomical automation feasible.
· Action Automation: Automates any user action on a website, such as form filling, data extraction, or navigation. Value: Frees up human resources from repetitive web-based tasks, allowing for focus on higher-value activities.
· Cost-Effective Automation: Provides a more affordable alternative to existing browser automation solutions. Value: Democratizes web automation, making it accessible to a wider range of projects and businesses, and improving ROI for automated processes.
· High Accuracy: Achieves comparable accuracy to existing methods despite reduced context usage. Value: Ensures reliable and trustworthy automated outcomes, critical for data integrity and process reliability.
Product Usage Case
· Automating competitor price monitoring: A business can use LindraAI-WebAPI to regularly check competitor websites for price changes and automatically update their own pricing strategies. This solves the problem of manual, time-consuming price tracking.
· Building custom data aggregators: A developer could use LindraAI-WebAPI to gather specific information from multiple news websites and present it in a single, personalized feed. This addresses the challenge of fragmented information sources.
· Creating automated lead generation tools: A sales team could employ LindraAI-WebAPI to scrape contact information from professional networking sites or business directories. This resolves the issue of inefficient manual lead prospecting.
· Developing automated customer support bots: A company could integrate LindraAI-WebAPI to allow a bot to navigate their own website or help documentation to find answers to common customer queries. This improves customer service efficiency and reduces wait times.
42
Claude.ai Image Generation
Author
sahli
Description
This project integrates image generation capabilities directly into Claude.ai, a conversational AI. It allows users to create images using natural language prompts, effectively bridging the gap between text-based AI and visual content creation.
Popularity
Points 2
Comments 0
What is this product?
This project is a feature within Claude.ai that allows users to generate images by describing what they want in plain text. Instead of needing to learn complex image editing software or specialized prompting techniques, you simply tell Claude.ai what kind of image you envision. The innovation lies in the seamless integration of a diffusion model (a type of AI that creates images from noise based on a text description) directly into a conversational AI experience. This means the AI understands your text requests and can translate them into visual output without you needing to switch tools or know specific coding languages. So, what's in it for you? It makes visual content creation accessible to anyone who can describe their idea, democratizing art and design.
How to use it?
Developers can use this feature by interacting with Claude.ai through its web interface or API. You would provide a textual prompt, like 'a futuristic cityscape at sunset with flying cars,' and Claude.ai will process this request and return a generated image. For developers looking to integrate this into their own applications, the Claude.ai API (if available for this feature) would be the key. They could send image generation requests to the API and receive the generated image data back to display or use in their own user interfaces. This means you can embed AI-powered image creation directly into your apps, websites, or workflows. So, what's in it for you? You can build applications that offer instant visual content generation, enhancing user engagement and simplifying creative processes.
Product Core Function
· Natural Language Image Prompting: Users can describe desired images using everyday language, which the AI interprets to create visuals. This removes the technical barrier to entry for image creation. So, what's in it for you? You can get the exact image you imagine without needing to be a graphic designer.
· Seamless Conversational Integration: Image generation is part of the ongoing conversation with Claude.ai, allowing for iterative refinement of prompts and images. This makes the creative process more dynamic and less rigid. So, what's in it for you? You can tweak your image ideas iteratively within the same conversation, making the creation process smoother.
· Underlying Diffusion Model: Leverages advanced AI models to translate textual descriptions into high-fidelity images. This is the core technology that makes the magic happen. So, what's in it for you? You benefit from cutting-edge AI capabilities to produce impressive visual outputs.
Product Usage Case
· Content Creation for Blogs/Social Media: A blogger needs an illustration for a post about sustainable energy. They describe 'a vibrant green planet powered by wind turbines and solar panels' to Claude.ai and receive a unique image instantly, saving time and money on stock photos or graphic designers. So, what's in it for you? Generate custom visuals for your content quickly and affordably.
· Prototyping and Concept Visualization: A game developer needs to quickly visualize a character concept. They prompt Claude.ai with 'a stoic knight in ornate silver armor holding a glowing sword' and get several visual interpretations to help refine their ideas. So, what's in it for you? Speed up your brainstorming and concept development with rapid visual feedback.
· Personalized Art Generation: A user wants a unique piece of art for their desktop background. They describe 'a serene forest scene with a hidden waterfall and mystical creatures' and Claude.ai generates a one-of-a-kind image. So, what's in it for you? Create personalized and unique artwork that reflects your imagination.
43
ImgExtender: AI-Powered Visual Workflow Accelerator
Author
olivefu
Description
ImgExtender is a lightweight, in-browser web tool designed to address common image manipulation frustrations. It leverages AI and efficient algorithms to provide essential image editing capabilities, from AI outpainting and upscaling to background removal and compression, all without requiring complex software installations or specialized hardware.
Popularity
Points 2
Comments 0
What is this product?
ImgExtender is a collection of advanced image processing tools accessible directly through your web browser. It tackles issues like AI-generated images with incorrect dimensions, blurry screenshots, detail loss in compressed images, time-consuming background edits, and the need to switch between multiple applications for simple tasks. Its innovation lies in bringing sophisticated AI capabilities (like generative fill for expanding images and deep learning for unblurring) and traditional editing functions into a single, user-friendly interface. The core idea is to eliminate the complexity and fragmentation of existing tools, offering a fast and predictable way to enhance images for everyone.
How to use it?
Developers can use ImgExtender by simply visiting the website (imgextender.com). For quick asset generation or manipulation, they can upload an image, select the desired operation (e.g., 'Extend Image', 'Unblur Image', 'Remove Background'), adjust parameters if needed, and download the processed result. This is particularly useful for rapid prototyping, creating visual assets for web applications or presentations without needing to open a full-fledged graphics editor. Integration scenarios might involve using ImgExtender as a standalone tool for personal projects or quickly preparing images before uploading them to a content management system.
Product Core Function
· AI Image Extension (Outpainting): Seamlessly expands image canvas using generative AI, preventing awkward borders and maintaining visual coherence. This is valuable for adapting AI-generated art or photos to specific aspect ratios needed for websites or social media.
· AI Image Generation: Creates sharp and clean images from text prompts, offering a streamlined way to produce unique visuals without extensive design skills.
· Image Unblurring: Restores clarity to blurry images using a multi-stage deep learning pipeline, making old photos or slightly out-of-focus shots usable.
· Image Upscaling: Enlarges images by 2x to 8x while preserving and recovering texture details, useful for making low-resolution images presentable without pixelation.
· Background Removal: Accurately removes image backgrounds, even with complex elements like hair or soft edges, simplifying the process of isolating subjects for compositing or design.
· Image Compression: Reduces file sizes of large images significantly without a noticeable loss in quality, improving website loading times and saving storage space.
· Basic Editing Tools (Crop, Resize, Filters, Text): Offers essential image manipulation functions for quick adjustments and enhancements, acting as a convenient all-in-one solution for everyday visual tweaks.
Product Usage Case
· A web developer needs to quickly expand a banner image to fit a new website layout. Instead of using Photoshop, they upload the image to ImgExtender, use the 'Extend Image' feature with AI outpainting, and get a seamlessly expanded image in minutes.
· An AI artist has generated a character portrait but it has an unintended blur. They use ImgExtender's 'Unblur Image' function to sharpen the details, making the artwork production-ready.
· An e-commerce seller wants to showcase a product on a clean white background. They upload their product photo to ImgExtender, use the 'Remove Background' feature, and quickly get a transparent PNG ready for their online store.
· A content creator has a high-resolution image that's too large for their blog. They use ImgExtender's 'Image Compressor' to significantly reduce the file size, improving page load speed for their readers.
· A student needs to include a specific aspect ratio image in a presentation but only has a differently shaped source image. They use ImgExtender's 'Crop' and potentially 'Extend Image' features to adapt the image perfectly.
44
Browser Embedded Firmware Simulator
Author
grog6
Description
This project is a web-based simulator that allows developers to write and test embedded system firmware directly in their browser. It eliminates the need for physical hardware and complex wiring setups, accelerating the prototyping phase for embedded projects. The core innovation lies in its ability to accurately simulate microcontroller behavior and firmware execution within a web environment, making embedded development more accessible and efficient.
Popularity
Points 2
Comments 0
What is this product?
This is a web application that lets you write firmware code for microcontrollers and then run that code in a simulated environment, all within your web browser. The main technical breakthrough is creating a virtual representation of a microcontroller (like the STM32F4) and its associated hardware, allowing your Rust firmware to interact with this virtual hardware as if it were real. This means you can test your code without needing to buy expensive development boards, connect any wires, or worry about damaging physical components. It's like having a miniature, virtual laboratory for your embedded projects right on your screen.
How to use it?
Developers can use this simulator by visiting the website and writing their embedded firmware code directly in the provided editor. The simulator currently supports STM32F4 microcontrollers and the Rust programming language, with plans to expand support for more microcontrollers. Once the code is written, the developer can 'run' it, and the simulator will execute the firmware, showing the behavior and output as if it were running on actual hardware. This allows for rapid iteration and debugging of firmware logic, device drivers, and application code. It can be integrated into a developer's workflow by serving as a primary tool for initial firmware testing and validation before deploying to physical hardware, saving significant time and resources.
Product Core Function
· Firmware development environment: A browser-based code editor to write embedded firmware in Rust, providing a convenient and accessible platform for coding without local setup.
· Microcontroller simulation: Emulates the behavior of specific microcontrollers (initially STM32F4), allowing firmware to execute and interact with virtual hardware components as if it were on a real chip.
· Hardware interaction simulation: Simulates the output and input of common embedded peripherals and GPIO pins, enabling developers to test sensor readings, actuator control, and communication protocols virtually.
· Rapid prototyping and testing: Enables quick iteration and debugging of firmware logic by eliminating the need for physical hardware deployment, significantly speeding up the development cycle.
· Remote development and collaboration: As a web-based tool, it facilitates remote development and makes it easier to share and test firmware code among team members without requiring identical hardware setups.
Product Usage Case
· Scenario: A developer is building a new IoT device using an STM32F4 microcontroller and needs to test the code for blinking an LED and reading a button press. Problem solved: Instead of buying a development board, wiring it up, and flashing the code, the developer can write the Rust firmware in the browser simulator, see the virtual LED blink, and simulate button presses to verify the logic instantly.
· Scenario: A team is developing a complex motor control firmware for an STM32F4 and wants to test the control algorithms before hardware is available. Problem solved: The simulator allows them to write and test the firmware that interacts with virtual motor drivers and sensors. They can fine-tune PID controllers or other algorithms in a safe, simulated environment, reducing the risk of damaging expensive motor hardware when it's eventually connected.
· Scenario: An embedded systems student is learning Rust and embedded programming but lacks access to physical development kits. Problem solved: The simulator provides a free and accessible platform for the student to write, test, and experiment with embedded firmware concepts without any financial barrier or complex setup, fostering hands-on learning.
45
O(1) Time Machine for Simulations
Author
0_of_1
Description
This project presents a novel approach to simulating systems where time progresses, without needing to store the entire history of states. It achieves constant time complexity (O(1)) for simulating forward or backward in time, which is a significant breakthrough for simulations that typically consume vast amounts of memory and processing power when tracking history.
Popularity
Points 1
Comments 1
What is this product?
This is a groundbreaking simulation engine that allows you to move forward and backward in simulated time with unprecedented efficiency. Unlike traditional simulation methods that require storing every single state change to enable time travel (which quickly becomes memory-intensive), this project uses a clever mathematical and algorithmic approach to reconstruct past or future states on demand. The core innovation lies in avoiding the need for a 'history buffer' by leveraging properties of the simulation model itself to calculate any point in time in constant (O(1)) time, meaning the time it takes doesn't increase with the duration of the simulation. This is transformative because it unlocks simulations of much longer durations or more complex systems that were previously computationally infeasible.
How to use it?
Developers can integrate this engine into their simulation-based applications. For instance, in game development, it could enable advanced rewind mechanics or complex AI decision-making by allowing rapid state exploration. In scientific computing, it could accelerate the analysis of dynamic systems by enabling quick iteration through different time points. The integration would involve defining the state variables of the simulation and the rules that govern their evolution over time, which the engine then uses to manage the temporal aspects of the simulation. The key benefit for developers is the ability to build features that require temporal manipulation without the typical performance penalties.
Product Core Function
· Constant Time Temporal Navigation: Allows jumping to any point in simulated time, forward or backward, in a fixed amount of time (O(1)). This means you can instantly rewind or fast-forward your simulation, making debugging and state exploration extremely fast, which is invaluable for identifying bugs or understanding complex behaviors without waiting.
· Zero History Buffer Requirement: Eliminates the need to store a large history of simulation states. This drastically reduces memory consumption, enabling simulations of much longer durations or with more complex state variables that would otherwise be impossible to run, directly addressing the memory bottleneck in many simulation projects.
· Predictive State Reconstruction: The system can calculate the state of the simulation at any arbitrary past or future point without explicit storage. This is crucial for features like 'undo' functionality in creative tools or 'what-if' scenario analysis in scientific models, providing immediate insights without computational delay.
· Integration-Friendly API: Designed to be easily plugged into existing simulation frameworks or custom applications. Developers can define their simulation's state and transition logic, and the O(1) time machine handles the temporal management, accelerating development cycles and reducing boilerplate code for time-related features.
Product Usage Case
· Game Development Rewind Feature: A game developer can use this to implement a 'rewind' mechanic where players can instantly go back in time to undo mistakes. The O(1) complexity ensures a seamless and responsive user experience, as the game state is reconstructed instantly, unlike traditional methods that would require loading from a save or complex state diffing, making the feature feasible even for long game sessions.
· Scientific Modeling 'What-If' Analysis: A researcher simulating a physical system can quickly explore different initial conditions or parameter changes by jumping to various points in simulated time. This allows for rapid hypothesis testing and discovery of emergent behaviors that might be missed with slower, history-dependent simulation methods, significantly speeding up the research process.
· Interactive Design Tool State Management: A designer working on an interactive application can use this to provide robust undo/redo functionality. The ability to navigate time in O(1) makes the editing experience fluid and responsive, even with hundreds of complex operations, making complex design iterations practical and user-friendly.
46
EternalLicense Tools
Author
mddanishyusuf
Description
This project introduces a novel approach to software licensing, aiming to provide 'pay once, use forever' tools. The core innovation lies in how it manages software access and usage rights, moving away from traditional subscription models towards a perpetual ownership paradigm. It tackles the problem of recurring costs for users and explores alternative monetization for developers.
Popularity
Points 2
Comments 0
What is this product?
This project is an experimental framework for creating software tools that offer perpetual usage rights after a single purchase. Instead of relying on subscription fees, it explores mechanisms for developers to grant users permanent access to their software. The underlying technical idea likely involves a form of local or cloud-based activation/validation system that is designed to be durable and independent of ongoing service fees. This could involve generating unique, verifiable license keys tied to hardware, user accounts, or a decentralized ledger, allowing the software to function indefinitely without requiring continuous checks against a central server that might shut down. The innovation is in decoupling software access from a recurring service cost, offering a user-friendly and potentially more cost-effective ownership model.
How to use it?
Developers can integrate this framework into their applications by implementing the provided licensing logic. This involves generating and managing unique licenses for each purchase. Users would typically receive a license key or a digital entitlement upon purchasing the tool. The software then uses this information to authenticate and unlock its full functionality permanently. The usage scenario revolves around building desktop applications, mobile apps, or even web services where a one-time purchase is desirable, eliminating the need for users to worry about monthly or annual payments. Integration might involve using SDKs or APIs provided by the framework to handle license verification and activation directly within the application code.
Product Core Function
· Perpetual License Generation: This feature allows developers to create unique, unforgeable license keys that grant permanent access to their software. The value is in enabling a 'buy once' model, simplifying customer acquisition and reducing churn associated with subscription fatigue.
· Offline Activation/Validation: The system is designed to validate licenses even without a constant internet connection, allowing for truly 'forever' use. This provides a robust user experience, especially for users with intermittent internet access, and ensures long-term accessibility.
· Developer Monetization Framework: Provides a mechanism for developers to earn revenue through one-time sales rather than relying on subscriptions. This offers a clear path to income while building user loyalty through permanent access.
· License Management Dashboard: A backend interface for developers to track sales, manage issued licenses, and potentially handle support requests related to licensing. This streamlines the business side of selling perpetual software.
· User License Portal: A portal for end-users to manage their purchased licenses, retrieve keys, and access download links. This enhances user convenience and self-service support.
Product Usage Case
· A freelance graphic designer needs a professional photo editing software. Instead of paying a monthly subscription that adds up over time, they can purchase 'EternalLicense Tools' based software for a one-time fee and use it for all their future projects indefinitely. This solves the problem of escalating costs for essential professional tools.
· A small game studio develops a niche indie game. To attract players who are tired of 'games as a service', they can package their game with the 'EternalLicense Tools' framework, offering a single purchase for full ownership. This helps them stand out in a crowded market by offering a distinct value proposition.
· A developer creates a utility tool for system administrators that requires periodic updates but not necessarily continuous online service. By using 'EternalLicense Tools', they can sell the initial version with a perpetual license and offer future major updates as optional paid upgrades, balancing revenue with long-term user value and avoiding ongoing service infrastructure costs.
47
RunOS: Instant Kubernetes Orchestrator
Author
dib85
Description
RunOS is a platform that provides production-ready Kubernetes clusters in minutes, pre-configured with databases, message queues, observability tools, and AI capabilities. It addresses the common pain point of lengthy and complex Kubernetes infrastructure setup, offering a controlled, self-hosted experience without weeks of manual configuration. The core innovation lies in its agent-based architecture utilizing gRPC streams and KVM virtualization for rapid, secure, and flexible cluster deployment.
Popularity
Points 2
Comments 0
What is this product?
RunOS is a system designed to automate the creation and management of Kubernetes clusters. Imagine wanting to run your applications in a robust, scalable environment like Kubernetes, but the setup process is usually very complicated and time-consuming. RunOS tackles this by using lightweight software agents that communicate securely with a central control system. These agents can then automatically set up virtual machines using KVM (a technology that allows your computer to run other operating systems efficiently), install Kubernetes, and configure all the necessary components like networking, storage, and databases. The key technical insight is that the agents initiate the communication, meaning you don't need to open up your network to the internet, making it more secure and simpler to set up. This approach allows you to get a fully functional Kubernetes cluster ready in 5-10 minutes, a significant leap from traditional methods.
How to use it?
Developers can use RunOS in several ways, depending on their infrastructure needs. For a quick start and to test AI workloads, they can opt for 'RunOS Cloud,' which provides managed dedicated servers with pre-defined configurations, including GPU passthrough for AI tools. Alternatively, for maximum control and to leverage existing hardware, developers can choose the 'Bring Your Own Node' option, where they run the RunOS node agents on their own machines or servers. This provides complete tenant isolation as the developer manages the underlying infrastructure. Integration typically involves accessing the RunOS dashboard to initiate cluster creation, selecting desired services and configurations, and then letting the platform handle the automated provisioning. For advanced users, the upcoming open-source agent code will allow for deeper customization and integration into existing CI/CD pipelines.
Product Core Function
· Automated Kubernetes Cluster Provisioning: Enables rapid creation of production-ready Kubernetes clusters within 5-10 minutes, significantly reducing setup time and effort for developers needing scalable application environments.
· Pre-configured Service Integrations: Offers one-click installation and configuration of essential services like PostgreSQL, Kafka, RabbitMQ, MinIO, and AI tooling (Ollama, LiteLLM), simplifying the deployment of complex application stacks and eliminating the need for manual service setup.
· Secure Agent-Based Architecture: Utilizes gRPC bidirectional streams initiated by agents to communicate with the backend, eliminating the need for public IP addresses and complex firewall configurations, thereby enhancing security and ease of deployment.
· KVM Virtualization for Flexibility: Leverages KVM for efficient and isolated virtual machine provisioning, providing a robust foundation for Kubernetes nodes and supporting GPU passthrough for demanding AI workloads.
· OS-Level WireGuard Networking: Implements WireGuard VPN at the operating system level for secure communication between cluster nodes and for SSH access, ensuring consistent security and simplifying troubleshooting even if Kubernetes components falter.
· Centralized Orchestration with Local Execution: Manages complex configurations, such as WireGuard and service deployments, through a central backend that sends commands to agents, which then execute them locally on the nodes for efficient and reliable cluster management.
· Version Compatibility Management: Addresses the challenge of maintaining compatibility across numerous services and Kubernetes versions by rigorously testing and managing complex compatibility matrices, ensuring a stable and reliable cluster environment for applications.
Product Usage Case
· A startup team needs to quickly deploy a microservices application with a managed PostgreSQL database and Kafka for message queuing. Instead of spending days configuring Kubernetes, networking, and database instances, they use RunOS to spin up a cluster with all these services pre-installed and configured in under 10 minutes, allowing them to focus on building their application features.
· A data science team wants to experiment with large language models (LLMs) using tools like Ollama. They have a powerful GPU-enabled server but need a Kubernetes environment to manage deployments. RunOS's KVM with GPU passthrough capability allows them to provision a Kubernetes cluster on their existing hardware with AI tooling configured in minutes, enabling rapid iteration on their AI projects without complex infrastructure setup.
· A developer is building a distributed system and needs secure communication between multiple nodes, including both Kubernetes traffic and direct SSH access. By using RunOS's OS-level WireGuard implementation, they ensure that all traffic is encrypted and routed securely, and troubleshooting is simplified due to the layered security approach, which also prepares them for future multi-cluster peering needs.
· A development team facing the constant challenge of updating and maintaining compatibility across a dozen microservices and their dependencies. RunOS's focus on version management and compatibility testing allows them to deploy and update these services reliably, avoiding the common 'dependency hell' that can plague complex Kubernetes deployments.
48
GitHubVelocity Insights
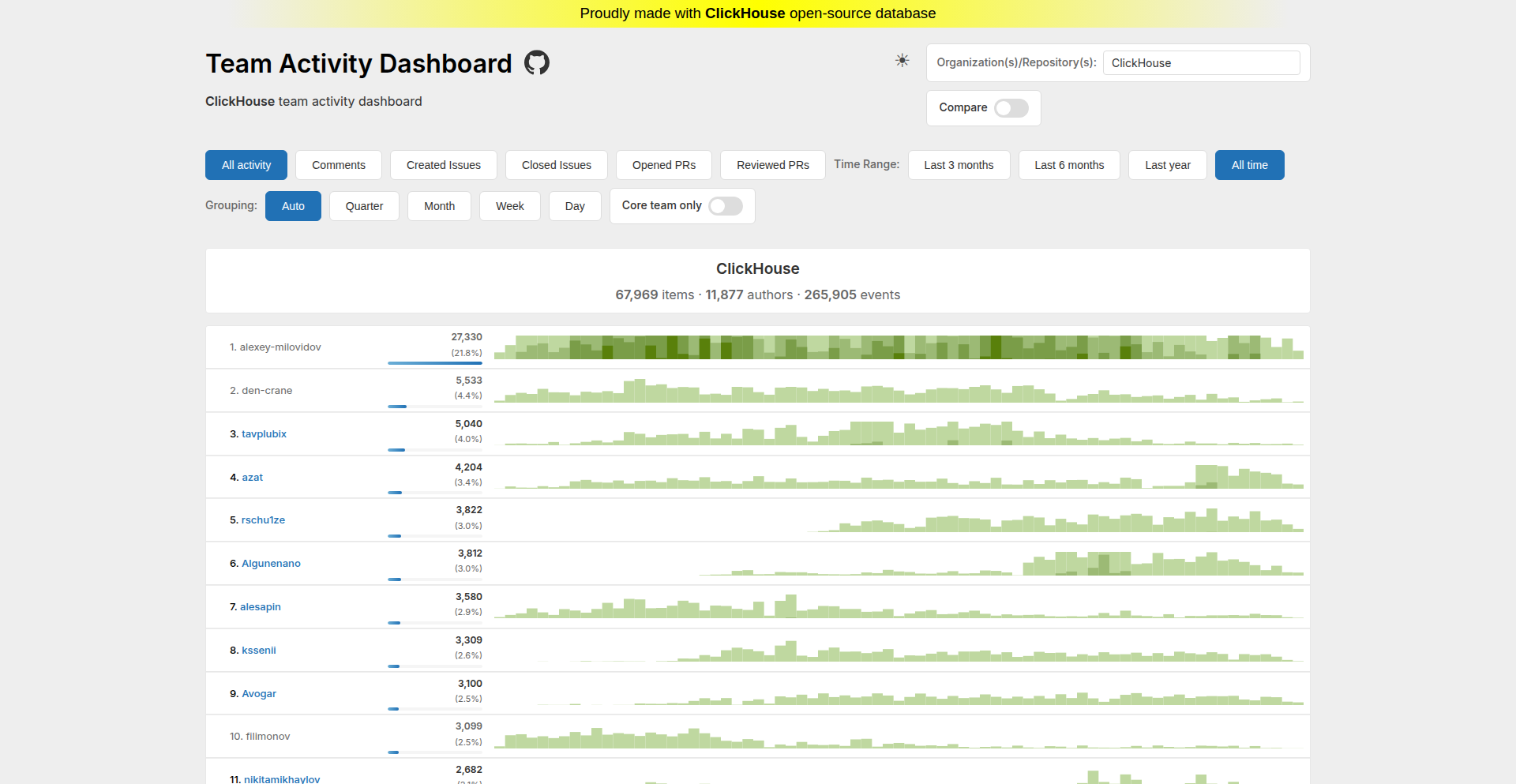
Author
AlexClickHouse
Description
A website that visualizes and compares team activity across GitHub repositories. It goes beyond simple metrics to reveal contribution patterns, identify key team members, and offer insights into project dynamics. The core innovation lies in its detailed analysis of commit messages and activity types, providing a deeper understanding of how teams collaborate and contribute.
Popularity
Points 2
Comments 0
What is this product?
GitHubVelocity Insights is a web application designed to offer a granular view of team performance and engagement on GitHub. Instead of just counting commits, it analyzes the *nature* of contributions. For instance, it can tell you who is consistently fixing bugs, who is leading new feature development, or how different teams' activities compare across projects. The technical ingenuity comes from parsing commit history and other GitHub events to extract meaningful patterns, offering a more nuanced perspective than standard GitHub analytics. So, what's the use for you? It helps you understand team dynamics, identify potential bottlenecks or high performers, and make data-driven decisions about resource allocation and team structure.
How to use it?
Developers can use GitHubVelocity Insights by navigating to the website and selecting the GitHub repositories they are interested in. They can then specify parameters such as date ranges, team members, and types of activity to compare. The platform visualizes this data through interactive charts and reports, allowing for easy interpretation. It can be integrated into team workflows by providing regular reports to management or by using it as a tool for individual developers to understand their own contribution impact. So, what's the use for you? You can easily plug it into your team's regular reporting or use it for quick performance checks, saving you manual data collection and analysis time.
Product Core Function
· Repository Activity Comparison: Allows users to compare the commit frequency, issue engagement, and pull request activity of different GitHub repositories. This is technically achieved by fetching data from the GitHub API and processing it to highlight trends. The value is in understanding how different projects are progressing and where attention might be needed.
· Team Member Contribution Analysis: Identifies key contributors within a team and analyzes their specific contribution patterns (e.g., bug fixes, feature additions, code reviews). This involves sophisticated parsing of commit messages and associated metadata. The value is in recognizing individual strengths and ensuring balanced workload distribution.
· Contribution Pattern Visualization: Presents complex data on team activity in easy-to-understand visual formats like charts and graphs. This leverages front-end visualization libraries to make the data accessible. The value is in making raw data actionable and understandable for both technical and non-technical stakeholders.
· Commit Message Insight Extraction: Analyzes the content of commit messages to categorize contributions (e.g., 'fix', 'feat', 'chore'). This uses string processing and potentially simple keyword matching or more advanced natural language processing techniques. The value is in understanding the *intent* behind code changes, not just the quantity.
Product Usage Case
· Scenario: A project manager wants to assess the health of multiple ongoing projects. How it helps: They can use GitHubVelocity Insights to compare the overall activity levels and pinpoint which projects are lagging in terms of recent commits or issue resolution, enabling them to allocate resources more effectively. This solves the problem of having a vague sense of project status and provides concrete data.
· Scenario: A team lead wants to identify potential burnout or recognize top contributors. How it helps: By analyzing individual contribution patterns and frequency over a period, they can spot team members who are consistently over-contributing or those who might be less engaged, facilitating conversations about workload and recognition. This addresses the challenge of subjective performance assessment.
· Scenario: A developer wants to understand the impact of their contributions over time. How it helps: They can track their own commit history, categorized by feature development or bug fixing, to see how their efforts align with project goals and to have tangible data to showcase their achievements. This provides a personal dashboard for growth and accountability.
· Scenario: A company wants to onboard new developers by understanding existing team workflows. How it helps: By examining the contribution patterns and the types of issues addressed by established team members, new hires can gain a quick understanding of the team's collaborative style and common problem-solving approaches. This accelerates the ramp-up process and reduces the learning curve.
49
KubeFlow Navigator
Author
kunobi
Description
A desktop application that consolidates Kubernetes resource visibility with GitOps reconciliation status from Flux or Argo CD, reducing the need to switch between multiple tools. It provides a unified view of workloads, sync status, drift indicators, and revision history, enhancing developer productivity in managing complex Kubernetes environments.
Popularity
Points 2
Comments 0
What is this product?
KubeFlow Navigator is a local desktop tool designed to simplify the management of Kubernetes deployments, especially when using GitOps tools like Flux or Argo CD. Instead of jumping between different command-line interfaces and web dashboards, this app pulls information directly from your Kubernetes API server. It then combines your running applications (workloads) with the synchronization status reported by GitOps controllers (Flux or Argo). The innovation lies in presenting this disparate information in a single, intuitive interface, highlighting discrepancies (drift) and recent changes, thus making it much easier to understand the current state of your systems. It's like having a central control panel for your Kubernetes world, specifically tuned for GitOps workflows.
How to use it?
Developers can install KubeFlow Navigator on their local machine. Once installed, they connect it to their Kubernetes clusters. The application then queries the Kubernetes API to fetch details about deployed resources and also retrieves reconciliation status information published by Flux or Argo CD. This allows developers to browse resources, see if they are in sync with their desired state defined in Git, inspect differences between the actual and desired state, and even view Helm chart history, all within a single application window. For those who want to experiment without connecting to a live production cluster, a built-in local environment is provided for testing GitOps workflows. This means you can get a comprehensive overview of your deployments and their GitOps status without complex configuration or context switching.
Product Core Function
· Unified Kubernetes Resource and GitOps Status View: Consolidates information about deployed applications and their synchronization state with Git, making it easier to understand what's running and if it's up-to-date. This helps quickly identify issues without needing to check multiple dashboards.
· Drift Detection Indicators: Visually highlights when a running resource in Kubernetes deviates from its desired state in Git, enabling prompt identification and resolution of configuration inconsistencies. This saves time by pinpointing problems before they escalate.
· Revision and History Tracking: Displays recent revisions of deployments and Helm chart history, providing context for changes and facilitating rollbacks or understanding past states. This is crucial for debugging and auditing.
· Multi-Cluster Management: Allows developers to work with multiple Kubernetes clusters simultaneously without the hassle of manually switching kubeconfig files, streamlining operations for complex environments. This reduces cognitive load and potential errors.
· Integrated Local Testing Environment: Offers a sandboxed environment for practicing and testing GitOps workflows, allowing developers to experiment safely without impacting live production systems. This accelerates learning and development cycles.
Product Usage Case
· Troubleshooting a deployment drift: A developer notices an application is not behaving as expected. They open KubeFlow Navigator, select the relevant cluster and namespace, and immediately see a 'drift' indicator next to the deployment. By clicking on it, they can see the exact differences between the Kubernetes resource and the configuration in their Git repository, allowing them to quickly pinpoint and fix the discrepancy.
· Verifying GitOps sync status for a new feature rollout: After pushing a new feature branch to Git and triggering a Flux/Argo CD sync, a developer uses KubeFlow Navigator to confirm that all related Kubernetes resources (Deployments, Services, Ingresses) are successfully synchronized and healthy. This provides immediate visual confirmation, reducing anxiety about the deployment process.
· Comparing configurations across multiple staging environments: A team manages several staging Kubernetes clusters, each with slightly different configurations. KubeFlow Navigator allows them to easily switch between these clusters and compare the status and configurations of key applications, ensuring consistency and identifying any accidental deviations.
· Onboarding a new team member to a complex GitOps setup: A new developer joins the team and needs to understand the state of various microservices managed by GitOps. KubeFlow Navigator provides an accessible, visual overview of all resources, their sync status, and recent changes, significantly reducing the learning curve compared to relying solely on command-line tools.
50
ChordCanvas Pro
Author
mike_xilo
Description
A free, offline, no-signup web tool for generating custom guitar chord diagrams. It specifically addresses the complexity of chords found in genres like jazz and bossa nova, offering a frustration-free way to visualize and export these intricate fingerings. Its innovation lies in its accessibility and focus on advanced chord voicings.
Popularity
Points 2
Comments 0
What is this product?
ChordCanvas Pro is a web application that allows musicians, particularly guitarists learning challenging music like jazz or bossa nova, to create highly customized chord diagrams. Instead of relying on generic chord shapes, it lets you precisely define the notes played on each string and fret. This is achieved through a user-friendly interface where you can visually place 'dots' on a virtual fretboard to represent finger positions. The core innovation is its ability to handle and represent complex chord voicings, which are often difficult to notate and share using standard methods. It removes the technical barrier of learning esoteric notation or dealing with clunky software, providing a direct, visual solution.
How to use it?
Developers can use ChordCanvas Pro directly in their browser without any installation or signup. For guitarists, the process involves navigating to the website, using the visual editor to place dots on the fretboard for each desired chord. You can specify the root note, any alterations (like sharps, flats, or extensions), and decide which strings are muted or open. The tool then renders a clear, professional-looking chord diagram. This diagram can be exported as a PDF for printing or sharing, making it incredibly useful for creating personal study materials, lesson plans, or sharing complex chord ideas with bandmates. It integrates seamlessly into a musician's workflow by providing instant, accessible visualization.
Product Core Function
· Customizable Fretboard Editor: Allows precise placement of finger positions on a virtual guitar fretboard, enabling the visualization of any chord shape. The value is in offering granular control for complex voicings beyond basic open chords.
· Advanced Chord Voicing Support: Designed to accurately represent chords with extensions, alterations, and unusual fingerings common in jazz and bossa nova. This solves the problem of standard tools failing to capture these nuanced musical ideas.
· Instant PDF Export: Generates high-quality PDF files of the created chord diagrams for easy printing, sharing, and integration into sheet music or study guides. The value is in providing a professional output format for practical use.
· Offline Functionality: Works entirely in the browser without an internet connection after initial load, ensuring accessibility even in remote practice spaces or when network connectivity is unreliable. This removes a significant usage barrier.
· No Signup Required: Users can immediately start creating chord diagrams without the need for account creation or personal information. This prioritizes user privacy and immediate usability, embodying a 'hacker's' approach to frictionless tooling.
Product Usage Case
· A jazz guitarist learning a complex Freddie Green voicings for a big band arrangement. ChordCanvas Pro allows them to precisely diagram these specific inversions and share them with bandmates for rehearsal, solving the problem of misinterpreting or forgetting the exact fingerings.
· A music theory student studying chord substitutions in a bossa nova piece. They can use ChordCanvas Pro to visualize the alterations and extensions of each substitution chord, making the theoretical concepts more concrete and understandable for their learning process.
· A guitar instructor creating custom handouts for students learning advanced fingerpicking patterns. They can diagram specific chords used in these patterns with accuracy, providing clear visual aids that go beyond generic chord charts.
· A songwriter experimenting with novel chord progressions. ChordCanvas Pro provides a rapid way to visualize and test out unusual voicings, helping them to explore new sonic territories without getting bogged down in manual notation.
51
Embedr: AI Hardware Whisperer
Author
sinharishabh
Description
Embedr is an AI copilot specifically designed for embedded engineers. It tackles the common pain points of hardware development, such as slow prototyping, debugging complex hardware issues, and understanding why peripherals aren't responding. It understands project structures and board setups for popular MCUs like ESP32, STM32, and RP2040, offering AI-powered assistance for register explanations, peripheral configurations, linker errors, and build issues. It even suggests fixes for hardware faults and integration problems, aiming to be an IDE that actively assists during wiring, flashing, and debugging.
Popularity
Points 2
Comments 0
What is this product?
Embedr is an AI-powered assistant, much like a smart copilot, tailored for the unique challenges faced by embedded engineers. Instead of being a general-purpose AI chatbot, Embedr is trained on the specific workflows and jargon of hardware development. It can 'read' your project files and understand your hardware setup, helping you decipher cryptic error messages related to microcontrollers (MCUs) like ESP32, STM32, and RP2040. It can explain complex technical terms like 'registers' and 'linker scripts,' and even suggest solutions for problems you encounter when connecting different hardware components or when your code doesn't behave as expected. Think of it as a highly knowledgeable partner who can instantly help you understand and fix hardware-related problems, accelerating your development process.
How to use it?
Developers can use Embedr by integrating it into their existing development workflow. You can point Embedr to your project's structure, and it will analyze your board configuration. When you encounter a build error, a strange peripheral behavior, or a cryptic message from your compiler, you can ask Embedr for help. It can explain the issue in plain English and suggest concrete steps to resolve it. For example, if an ESP32's I2C communication is failing, you can describe the problem to Embedr, and it can help you check register configurations, identify potential hardware conflicts, or suggest code modifications. It can also help you generate build systems or understand how to set up different toolchains for your specific project, making the initial setup and ongoing development much smoother.
Product Core Function
· Understanding project structure and board setup: This function allows Embedr to analyze your existing code and hardware configuration, so it can provide context-aware assistance tailored to your specific project, saving you time explaining your setup.
· Explaining MCU-specific details (registers, peripheral configs): Embedr can demystify complex technical terms related to microcontrollers, such as what specific registers control a sensor or how to configure a particular peripheral, making it easier for you to understand and utilize hardware features effectively.
· Debugging build errors and linker issues: When your code won't compile or link, Embedr can pinpoint the cause of the problem and suggest specific fixes, reducing the frustration and time spent on troubleshooting compilation problems.
· Suggesting solutions for hardware faults and integration problems: If a hardware component isn't working as expected or two components are not communicating properly, Embedr can analyze the situation and propose potential solutions, helping you overcome hardware integration challenges.
· Generating build systems and selecting toolchains: Embedr can assist in setting up the necessary tools and build environments for your embedded project, simplifying the initial project setup and ensuring compatibility.
· Guiding through bring-up steps and driver-level debugging: For new hardware or complex functionalities, Embedr can provide step-by-step instructions for getting started and debugging at a low level, ensuring you can get your hardware operational efficiently.
Product Usage Case
· A developer is trying to get an OLED display working on an RP2040 microcontroller using I2C. They are encountering strange data corruption. They can tell Embedr about their wiring and code. Embedr can analyze the I2C peripheral configuration registers and suggest checking for bus capacitance issues or clock stretching problems, which are common culprits for this type of error, thus helping them fix the display issue faster.
· An engineer is working on an STM32 project and their code fails to link due to an undefined symbol in a custom bootloader. They can share their linker script and error message with Embedr. Embedr can then explain how the linker script is organized and identify the missing section or symbol definition, guiding the engineer to correct the linker script and successfully build their project.
· A hobbyist is new to ESP32 and wants to interface a specific sensor. They are unsure about the correct GPIO pin assignment and SPI configuration. They can describe their goal to Embedr, which can then suggest the recommended pin configurations for SPI on the ESP32 and provide example code snippets for initializing the SPI peripheral, accelerating their learning and implementation.
· A team is experiencing intermittent failures with a custom communication protocol on an embedded device. Debugging involves complex timing issues. Embedr can help analyze the low-level driver code and suggest strategies for instrumenting the code to capture timing critical data, and then help interpret that data to identify the root cause of the intermittent failures, saving significant debugging time.
52
Unified Payment Gateway Sandbox Simulator
Author
g-sudarshan
Description
This project offers a unified User Acceptance Testing (UAT) environment for payment gateway integrations. It acts as a sophisticated mock service, allowing developers to simulate various payment gateway behaviors and real-world scenarios without needing to set up individual sandbox accounts for each provider. This significantly simplifies and accelerates the payment integration testing process, addressing the common pain points of inconsistent testing environments and the difficulty of replicating complex payment lifecycles.
Popularity
Points 2
Comments 0
What is this product?
This project is a cloud-based sandbox simulator designed specifically for developers who integrate payment gateways into their applications. Instead of dealing with the hassle of creating and managing multiple, often inconsistent, sandbox accounts for different payment providers like Stripe, Razorpay, Paytm, or Visa, this tool provides a single, unified environment. It mimics the APIs of these gateways and can simulate a wide range of real-world payment events and edge cases, such as captures, refunds, chargebacks, disputes, delayed webhooks, and even network downtime. The core innovation lies in its ability to abstract away the complexities of individual gateway testing into a single, predictable interface. This means developers can test their payment logic more comprehensively and reliably, reducing the chances of production issues related to payment processing.
How to use it?
Developers can integrate this simulator into their development workflow in several ways. The most common approach is to configure their application's payment integration code to point to the simulator's API endpoints during local development or in a dedicated UAT environment. This allows them to test core payment flows, error handling, and webhook processing without incurring actual transaction fees or interacting with live payment systems. For CI/CD pipelines, the simulator can be used in a 'headless' mode, enabling automated contract testing for payment-related functionalities. The simulator also offers the flexibility to create custom gateway profiles, allowing teams to define specific failure rates, latency, or webhook delivery patterns to rigorously test their application's resilience. Essentially, it acts as a drop-in replacement for real payment gateways during the testing phase.
Product Core Function
· Mock APIs for multiple payment gateways: This allows developers to simulate interactions with popular payment providers like Stripe, Razorpay, Paytm, and more, enabling comprehensive testing of their integration logic against familiar interfaces. The value is in avoiding the setup overhead of individual gateway sandboxes.
· Simulation of real-world payment scenarios: This includes testing captures, refunds, partial refunds, chargebacks, disputes, settlement delays, and failed payouts. The value is in uncovering potential issues in complex transaction lifecycles that are hard to replicate otherwise.
· Emulation of webhook behavior: The simulator can mimic various webhook delivery patterns, including delays, skips, and inconsistencies. This is crucial for ensuring applications can reliably handle asynchronous payment notifications, reducing critical bugs in production.
· Network and system downtime simulation: Developers can test how their application behaves during network outages or simulated delays in payment processing. This helps build more resilient and fault-tolerant payment systems.
· 3-D Secure and OTP mock pages: This allows for the testing of authentication flows without requiring actual user interaction or verification processes, streamlining the testing of secure checkout experiences.
· UPI timeouts and pending states simulation: Crucial for regions where UPI is prevalent, this function helps test how applications handle the asynchronous and sometimes delayed nature of UPI transactions.
· Hosted dashboard for transaction monitoring: Provides a visual interface to review simulated transactions, trigger lifecycle events manually or on a schedule, and re-trigger webhooks. The value is in easy debugging and scenario replication.
· Custom gateway profiles with configurable rules: Enables advanced testing by defining specific parameters like failure percentages, latency, and webhook disorder. This empowers teams to stress-test their integrations under various conditions and identify vulnerabilities.
· CI-friendly headless payment flows: Facilitates automated testing within continuous integration pipelines, ensuring that payment integrations remain robust with every code change. The value is in preventing regressions and enabling faster release cycles.
Product Usage Case
· A startup building an e-commerce platform needs to integrate with multiple payment gateways to offer diverse payment options. Instead of spending days setting up individual sandbox accounts for Stripe, Razorpay, and Paytm, they can use this simulator to test all integrations simultaneously in a single environment, significantly reducing development time and accelerating their go-to-market strategy.
· An engineering team is developing a complex subscription service with recurring payments, refunds, and potential chargebacks. They can use the simulator to rigorously test all these edge cases, including simulating delayed webhooks and settlement issues, ensuring their system is robust and can handle financial complexities accurately before going live.
· A developer is working on a mobile payment application and needs to test the user authentication flow, including 3-D Secure and OTP verification. The simulator can mock these authentication pages, allowing them to test the entire checkout process without needing actual test cards or phone numbers, making testing faster and more efficient.
· A company wants to ensure their payment processing system can withstand network interruptions. They can configure the simulator to introduce random network downtime and observe how their application recovers and handles pending transactions, ensuring business continuity even during adverse network conditions.
53
Reddit Visa Timeline Extractor
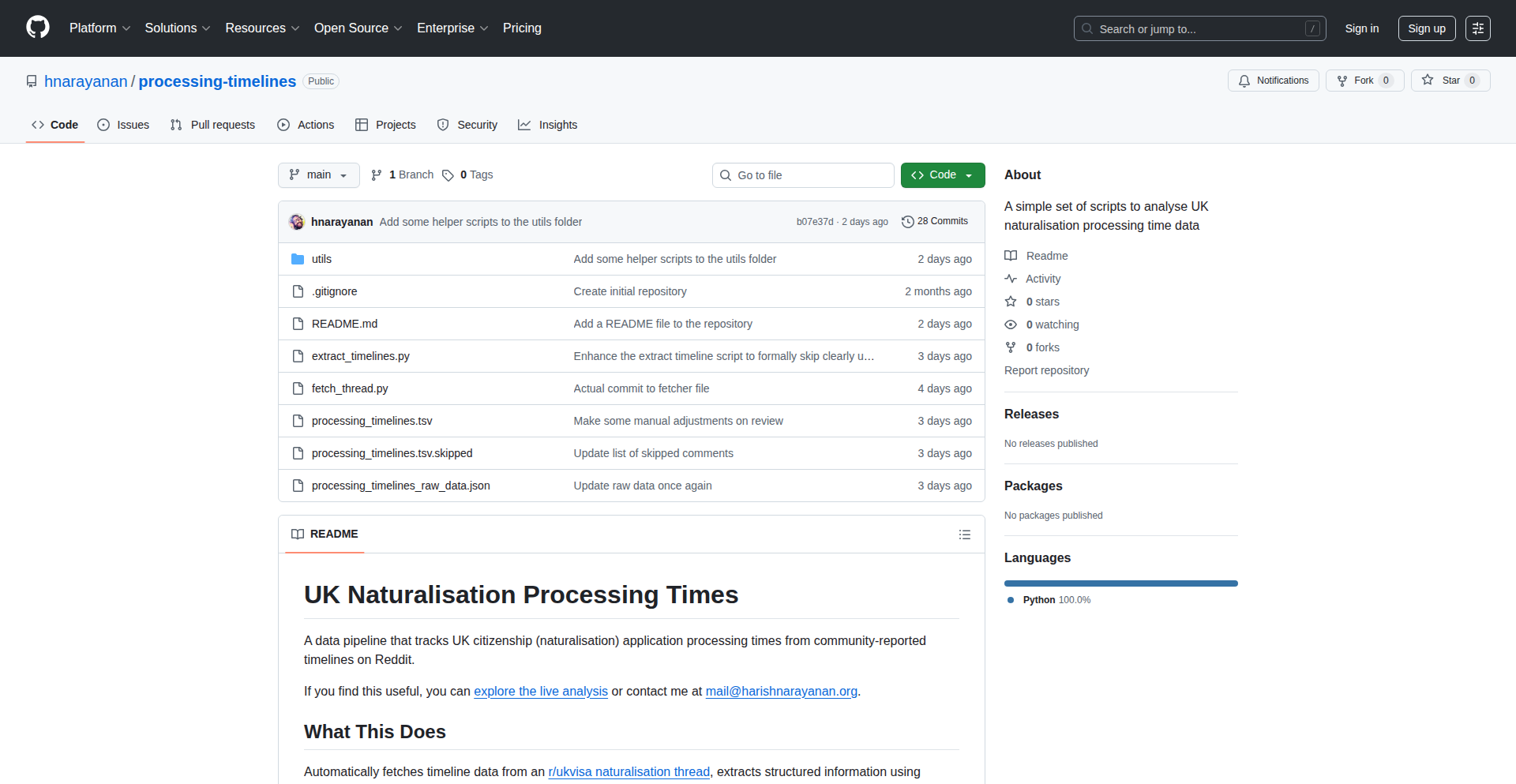
Author
hnarayanan
Description
A project that automatically extracts UK visa application timelines from Reddit comments. It utilizes natural language processing and data extraction techniques to identify key dates and events related to visa processes, providing valuable insights for individuals navigating the UK immigration system. This innovation addresses the difficulty in finding consolidated, real-world visa experience data.
Popularity
Points 2
Comments 0
What is this product?
This project is a custom-built data pipeline designed to scour Reddit, a popular online forum, for posts and comments discussing UK visa applications. The core innovation lies in its ability to understand the context of these comments, identify specific dates, and associate them with visa application milestones like application submission, interview dates, or decision notifications. It leverages Natural Language Processing (NLP) to interpret unstructured text and extract structured data. Essentially, it's a sophisticated search and analysis tool for visa applicant experiences, turning scattered online conversations into a useful dataset.
How to use it?
Developers can integrate this pipeline into their own applications or use it as a standalone tool for research and analysis. The output would typically be a dataset containing extracted timelines, possibly in a CSV or JSON format, which can then be visualized or further processed. Potential use cases include building dashboards for immigration consultants, creating tools for prospective visa applicants to gauge realistic timelines, or for researchers studying immigration patterns. The technical implementation would involve setting up the data fetching mechanism from Reddit's API, running the NLP models for extraction, and storing the results.
Product Core Function
· Automated Reddit comment scraping: Efficiently collects relevant visa-related discussions from Reddit, saving manual search time.
· Natural Language Processing (NLP) for timeline extraction: Identifies and structures key dates and events from unstructured text, making raw data actionable.
· Visa-specific entity recognition: Understands terms like 'application submitted', 'biometrics appointment', 'decision received' to accurately map timeline events.
· Data aggregation and structuring: Organizes extracted information into a clear, usable format for analysis and reporting.
· Error handling and noise reduction: Filters out irrelevant comments and handles variations in user language to ensure data quality.
Product Usage Case
· A UK immigration law firm could use this to analyze average processing times for specific visa types based on real applicant experiences shared on Reddit, helping them provide more accurate client estimates.
· Prospective UK visa applicants could use a dashboard powered by this extractor to see the typical journey and wait times reported by others with similar circumstances, reducing anxiety and managing expectations.
· A data journalist could use the extracted timelines to create infographics and reports on immigration trends and bottlenecks in the UK visa system, providing valuable public information.
· A developer building a chatbot for visa inquiries could use this data to train the bot on realistic timelines and common applicant questions, improving its helpfulness.
54
TrustSphere: The Accessible Trust Center
Author
gamalinosqui
Description
TrustSphere is a free, incredibly straightforward trust center designed to simplify privacy policy and terms of service management for developers. It tackles the common pain point of generating and managing these essential legal documents without the usual complexity and cost, leveraging a clever, automated approach.
Popularity
Points 2
Comments 0
What is this product?
TrustSphere is a project that helps developers create and manage privacy policies and terms of service documents. Instead of hiring expensive lawyers or wrestling with complicated templates, it offers a dead-simple, automated way to get these crucial legal pages up and running for your application. The innovation lies in its simplicity and accessibility – it cuts through the jargon and provides a functional, free solution for a common developer need. This means you can quickly generate essential legal documentation, freeing up your time and resources.
How to use it?
Developers can integrate TrustSphere into their workflow by visiting the project's repository or website. It likely provides straightforward instructions and perhaps a simple interface or code snippets to generate the necessary documents. Think of it like using a template generator, but specifically for legal pages. You'll provide some basic information about your service, and TrustSphere will output a draft policy or terms document. This is useful for any developer building a website or app that collects user data, as these policies are legally required in many jurisdictions.
Product Core Function
· Automated privacy policy generation: This feature allows developers to quickly create a basic privacy policy by answering a few questions about their service. The value is that it significantly speeds up the process of compliance and avoids the need for manual drafting, saving time and reducing legal risk.
· Terms of service creation: Similar to the privacy policy, this function helps generate a standard terms of service document. The value is providing a foundational legal framework for user interactions with the application, protecting both the developer and the user.
· Simplified document management: While not explicitly detailed, a 'trust center' implies a way to keep these documents organized and accessible. The value here is having a central, easy-to-manage location for these important legal texts, making updates and revisions less cumbersome.
· Free accessibility: The project is offered for free, democratizing access to essential legal documentation. The value is that it removes a significant financial barrier for startups and individual developers who might otherwise struggle to afford legal services.
Product Usage Case
· A new mobile app developer needs to launch their app quickly but is concerned about privacy regulations. They can use TrustSphere to generate a compliant privacy policy in minutes, allowing them to focus on app development rather than legal complexities. This solves the problem of delayed launch due to legal documentation bottlenecks.
· A freelance web developer is building a small e-commerce site for a client. To ensure legal protection, they need terms of service. TrustSphere provides a quick and easy way to generate these terms, demonstrating professionalism and mitigating potential legal issues for the client's online store.
· An open-source project maintainer wants to ensure their users understand the terms of contribution and usage. TrustSphere can help them create a clear and concise set of terms, fostering a more transparent and trustworthy community around their project.
55
GreasePanda: Dynamic Web Page Transformer
Author
sudosoft
Description
GreasePanda is a browser extension that allows users to inject custom JavaScript code (userscripts) into any website to instantly modify its appearance, behavior, or functionality. It addresses the challenge of static web content by empowering users to personalize their browsing experience and overcome website limitations.
Popularity
Points 2
Comments 0
What is this product?
GreasePanda is a powerful browser extension that acts like a personalized web tailor. It allows you to write or use small JavaScript programs, called 'userscripts', which then run automatically whenever you visit a specific website. Think of it as giving you a secret remote control for every webpage. Its core innovation lies in its seamless integration of custom code execution, enabling users to dynamically alter websites without needing to be a web developer. This means you can fix annoying website layouts, add missing features, or even automate repetitive tasks on any site you visit.
How to use it?
Developers can use GreasePanda by installing the browser extension. Then, they can create or download userscripts from various online repositories. These scripts are typically written in JavaScript and are configured to run on specific URLs or domains. For example, if you want to make a popular social media site less distracting, you could write a script to hide certain elements or change their colors. Integration is as simple as enabling the script within the GreasePanda extension interface, and the modifications will appear the next time you load that webpage. It's like having a personal web developer for your browser.
Product Core Function
· Userscript Execution Engine: Allows for the reliable and efficient running of custom JavaScript code on any website. This means your personalized modifications will work as intended, directly impacting the web page's presentation and interaction.
· Website Targeting: Enables users to specify exactly which websites a userscript should affect. This prevents unintended changes and ensures your customizations are applied only where you want them, offering precise control over your browsing.
· Script Management Interface: Provides an easy-to-use dashboard for users to enable, disable, and organize their userscripts. This simplifies the process of managing multiple customizations, making it effortless to switch between different personalized browsing experiences.
· Cross-Browser Compatibility: GreasePanda is designed to work across various popular web browsers. This ensures that your personalized web experience is consistent, regardless of the browser you choose to use, maximizing accessibility.
· Community Script Repository Access: Facilitates access to a vast library of pre-written userscripts created by the community. This allows users to leverage existing solutions for common web annoyances or desired enhancements without needing to write code from scratch.
Product Usage Case
· A user finds a news website's font too small and difficult to read. They can use GreasePanda to inject a userscript that increases the font size of all text on that site, making it much more comfortable to read. The value is improved readability and a personalized viewing experience.
· A developer wants to test how a website looks with a different color scheme before implementing it officially. They can write a GreasePanda userscript to override the website's CSS, allowing for rapid visual prototyping directly in the browser. This solves the problem of slow deployment cycles for visual changes.
· Someone frequently visits an e-commerce site with an annoying pop-up that appears every time they add an item to their cart. They can use GreasePanda to write a script that automatically dismisses this pop-up, streamlining their shopping process. This resolves a user frustration and improves efficiency.
· A web scraping enthusiast needs to extract specific data points from a dynamically loading web page. They can use GreasePanda to execute JavaScript that waits for the data to load and then formats it for easier extraction. This overcomes the challenge of extracting data from complex, interactive websites.
56
Openware.py: Multilingual Content-Addressed Function Storage
Author
amirouche
Description
This project introduces Ouverture.py, a Python library for content-addressed storage of multilingual functions. It tackles the challenge of managing and retrieving functions based on their content rather than a fixed identifier, enabling more flexible and resilient distributed systems. This innovation lies in its ability to store and retrieve functions dynamically based on what they do, not just where they are located, opening up new possibilities for decentralized applications and code sharing.
Popularity
Points 2
Comments 0
What is this product?
Openutre.py is a Python library that allows developers to store and retrieve functions based on their content. Instead of referencing a function by its name or a specific file path, it uses a content-addressing system. This means a function is identified by a unique hash of its code. When you need to execute a function, you simply provide its content hash, and Ouverture.py finds and executes the corresponding code. This approach offers enhanced immutability and discoverability for code, especially valuable in decentralized environments where code might be replicated across many nodes or needs to be accessed reliably.
How to use it?
Developers can integrate Ouverture.py into their Python projects to manage and deploy functions in a content-addressed manner. Imagine you have a complex data processing function. You can store it with Ouverture.py, and it will generate a unique identifier (a hash) for that specific function code. Later, anywhere in your application or even in a distributed system, if you need to run that exact data processing logic, you can provide the hash, and Ouverture.py will retrieve and execute the correct function. This is particularly useful for microservices, serverless architectures, or any system where functions need to be deployed and updated reliably and independently. It's as simple as importing the library and using its put and get methods to store and retrieve functions.
Product Core Function
· Content-based function storage: This allows functions to be stored and identified by a hash of their code, ensuring immutability and providing a verifiable way to access specific function versions. This is valuable for ensuring that the exact logic you expect is always executed, preventing accidental or malicious tampering.
· Multilingual support (conceptual): While implemented in Python, the underlying principles of content-addressing can be extended to functions written in different programming languages, enabling cross-language code interoperability and reuse in distributed systems.
· Decentralized retrieval mechanism: Functions can be retrieved from various locations based on their content hash, promoting resilience and availability. This means your application can still access a function even if one storage node goes offline, making your system more robust.
· Integration with distributed systems: The content-addressed nature of functions makes them ideal for distributed computing environments, allowing for easier sharing and execution of code across multiple machines or nodes without relying on centralized registries.
· Immutable function versions: Once a function is stored, its content-based identifier won't change, guaranteeing that you are always referring to the exact code. This is crucial for debugging and maintaining predictable system behavior.
Product Usage Case
· In a decentralized machine learning platform, each training or inference function can be stored using Ouverture.py. If a new dataset requires a slightly modified preprocessing function, it gets a new content hash, and users can explicitly request the older or newer version by its hash, ensuring reproducibility of experiments.
· For a serverless compute environment, Ouverture.py can manage the deployment of individual functions. Instead of versioning by deployment ID, functions are versioned by their content. This allows for easy rollback to a known working version simply by referencing its content hash, simplifying operational management and debugging.
· In a peer-to-peer application where users share computational tasks, Ouverture.py can store the code for these tasks. Any user can request a specific task by its content hash, and the network will find and execute it, fostering efficient code sharing and execution without central servers.
· For IoT device management, firmware updates or specific operational logic can be pushed to devices as content-addressed functions. This ensures that the correct, verified logic is executed on the device, even if the device has intermittent connectivity or is part of a large fleet.
57
RAG-SynthData
Author
scosman
Description
A tool to generate synthetic data for evaluating RAG (Retrieval Augmented Generation) systems. This addresses the challenge of creating diverse and realistic test cases for RAG models, improving their accuracy and reliability by simulating various retrieval and generation scenarios.
Popularity
Points 2
Comments 0
What is this product?
This project is a synthetic data generation engine specifically designed for evaluating Retrieval Augmented Generation (RAG) systems. RAG systems are complex AI models that combine information retrieval with large language models to provide more informed answers. The core innovation lies in its ability to programmatically create a wide range of realistic query-document pairs. This is crucial because testing RAG systems effectively requires a vast and varied dataset that mirrors real-world usage. Without such data, it's difficult to pinpoint weaknesses in how the RAG retrieves information or how well the language model synthesizes it. The system likely employs techniques to simulate different types of user queries (e.g., ambiguous, specific, comparative) and corresponding relevant/irrelevant document snippets, creating a robust testing ground. This is important because it allows developers to rigorously test and improve their RAG models before deploying them, ensuring they perform well under diverse conditions.
How to use it?
Developers can integrate RAG-SynthData into their RAG model development pipeline. It can be used to automatically generate large datasets for training, fine-tuning, and comprehensive evaluation of RAG models. By defining parameters for query complexity, document types, and desired retrieval outcomes, developers can generate tailored datasets. For instance, they might specify to generate 1000 queries that require factual retrieval from a specific domain, or 500 queries that test the model's ability to handle ambiguous information. This allows for systematic testing and identification of performance bottlenecks, ultimately leading to more robust and accurate RAG applications. This is useful because it streamlines the often tedious and expensive process of creating high-quality test data, saving significant development time and resources.
Product Core Function
· Query generation based on customizable parameters: This function uses algorithms to create diverse and realistic user queries. Its value is in simulating a wide spectrum of user intents, from simple information seeking to complex comparative analysis, enabling thorough RAG testing.
· Document snippet synthesis with controlled relevance: This feature generates text snippets that can be marked as relevant or irrelevant to a query. The value here is in precisely controlling the retrieval challenge for the RAG system, allowing developers to test its accuracy in finding the right information.
· Dataset structuring for RAG evaluation frameworks: The system organizes generated data into formats compatible with standard RAG evaluation metrics and tools. This is valuable because it ensures seamless integration with existing testing infrastructure, making it easy to measure performance.
· Scenario simulation for edge cases: This function generates data that specifically targets potential failure points or unusual user behaviors. Its value is in proactively identifying and addressing weaknesses in the RAG system before they manifest in production, leading to greater stability.
· Parameterizable data generation: Users can define the characteristics of the data to be generated, such as the complexity of queries, the length of documents, and the distribution of relevant information. This is valuable because it allows for the creation of highly specific test suites tailored to the unique requirements of a particular RAG application.
Product Usage Case
· Evaluating a customer support RAG system: A developer building a RAG for customer support documentation could use RAG-SynthData to generate queries like 'how to reset my password?' or 'what are the warranty terms for product X?'. The tool would then create relevant document snippets from the knowledge base and also irrelevant ones to test if the RAG accurately retrieves the correct support articles. This helps ensure the chatbot provides accurate solutions to users.
· Testing a medical research RAG: A research team developing a RAG to quickly find information in medical journals could use this tool to generate complex queries like 'what are the latest advancements in gene therapy for cancer?' and simulate the retrieval of relevant research papers versus related but not directly applicable articles. This allows them to assess the RAG's precision in identifying critical research findings.
· Improving an e-commerce product recommendation RAG: A developer could use RAG-SynthData to generate queries about product features or comparisons, such as 'compare battery life of phone A and phone B' or 'find laptops with at least 16GB RAM under $1000'. The tool would then create synthetic product descriptions and reviews to test how well the RAG system retrieves and synthesizes information for accurate recommendations, leading to better customer satisfaction.
· Assessing the robustness of a legal document RAG: A legal tech company could use this to generate queries requiring nuanced understanding of legal jargon or specific case law, like 'what are the implications of the recent ruling on intellectual property in software development?'. The system would then simulate the retrieval of relevant legal documents, helping to evaluate the RAG's ability to handle complex legal reasoning and provide accurate insights.
58
CodeMode: LLM Script Executor
Author
juanviera23
Description
CodeMode is a library that allows Large Language Models (LLMs) to execute small TypeScript scripts directly, rather than coordinating multiple tool calls. This approach leverages the LLM's strength in code generation for single, focused tasks, leading to significant reductions in token usage, improved reliability, and enhanced performance, especially with local LLMs. It solves the problem of LLMs struggling with complex multi-step tool orchestration by treating code execution as a primary interface.
Popularity
Points 2
Comments 0
What is this product?
CodeMode is a novel approach to LLM agent interaction. Instead of providing an LLM with a large set of tools it needs to decide between and orchestrate for complex tasks, CodeMode exposes a secure TypeScript sandbox. The LLM's job is to write a single, self-contained TypeScript script that directly accomplishes the desired outcome. This script is then executed once. The core innovation lies in recognizing that LLMs are often more adept at generating precise code for a specific function than at complex decision-making for sequential tool usage. This simplifies the LLM's task, reduces the overhead of managing multiple tool calls, and makes even smaller, local LLMs more effective. So, it's a way to make LLMs more efficient and reliable by having them write code to solve problems instead of just calling pre-defined functions.
How to use it?
Developers can integrate CodeMode into their LLM-powered applications. The LLM is prompted to generate a TypeScript script to achieve a specific objective. This script is then passed to the CodeMode execution environment, which securely runs the code within the sandbox. The output of the script is returned to the LLM or used by the application. This is particularly useful when you need an LLM to perform a precise operation, like data manipulation, simple calculations, or interacting with a specific API endpoint, where writing a dedicated script is more direct and less prone to errors than a series of tool calls. For example, you could ask an LLM to 'calculate the average of these numbers and return the result as a JSON object', and it would generate a TypeScript script to do just that, which CodeMode would then execute. This allows for seamless integration into workflows where custom logic is needed on demand.
Product Core Function
· TypeScript Sandbox Execution: Securely runs LLM-generated TypeScript code in an isolated environment, ensuring that the LLM's actions are contained and predictable. This provides a robust foundation for LLM-driven operations, making them safer and more manageable.
· Simplified LLM Prompting for Code Generation: Enables developers to prompt LLMs to generate specific code snippets for tasks, rather than complex sequences of tool calls. This makes it easier for LLMs to understand and execute tasks by focusing on their strength in code writing, leading to more direct and effective problem-solving.
· Reduced Token Consumption: By generating and executing single scripts, the need for verbose tool descriptions and multi-turn conversations is eliminated, drastically cutting down the number of tokens LLMs need to process. This leads to significant cost savings and faster response times.
· Enhanced Reliability with Local LLMs: Empowers smaller or local LLMs to perform complex tasks reliably by offloading the execution to a dedicated code environment. This democratizes the use of powerful LLM agents, making them accessible without relying solely on large, cloud-based models.
· Direct Problem Solving via Code: Shifts the paradigm from LLM as a coordinator of tools to LLM as a direct problem solver by generating executable code. This allows for more precise and efficient solutions to specific challenges, embodying the hacker ethos of using code to directly address issues.
Product Usage Case
· Data Transformation: An LLM receives raw data and is prompted to write a TypeScript script to clean, format, or transform it into a desired structure (e.g., converting CSV to JSON, filtering specific entries). CodeMode executes this script, providing the processed data directly. This is useful for ETL pipelines or data preparation tasks where custom logic is required.
· API Interaction with Custom Logic: Instead of instructing an LLM to call multiple API endpoints in sequence, CodeMode allows the LLM to generate a script that calls an API, processes the response, and then perhaps makes another call based on that response, all within a single execution. This is beneficial for dynamic API integrations that require conditional logic.
· Mathematical Computations and Simulations: For tasks involving specific calculations, statistical analysis, or simple simulations, the LLM can generate a TypeScript script to perform these operations accurately. CodeMode executes the script, returning precise numerical results. This is valuable for scientific computing or financial modeling applications.
· Content Generation with Specific Formatting: An LLM can be tasked to generate text content and then write a script to ensure it adheres to strict formatting rules, such as generating a markdown table from a list of items or creating an HTML snippet with specific styling. This ensures output consistency and adherence to predefined standards.
59
InstaSaver CLI
url
Author
qwikhost
Description
InstaSaver CLI is a command-line utility that allows users to download all their saved Instagram photos and videos with a single command. It tackles the common frustration of Instagram not offering a built-in way to bulk export saved content. The innovation lies in its direct interaction with Instagram's underlying data structures (likely leveraging undocumented APIs or web scraping techniques) to efficiently retrieve and download media, providing a simple yet powerful solution for users who want to back up or repurpose their saved Instagram memories.
Popularity
Points 1
Comments 1
What is this product?
InstaSaver CLI is a developer tool designed to bypass Instagram's limitations on exporting saved posts. Instead of manually saving each image or video, this tool automates the process. Technically, it likely simulates a user's interaction with Instagram's web interface or directly queries its internal data APIs, which are not publicly exposed for this functionality. The core innovation is figuring out how to access and extract this saved media data efficiently and reliably, without requiring manual steps for each saved item. This means you get all your saved content in one go, a significant improvement over the manual download process.
How to use it?
Developers can integrate InstaSaver CLI into their workflows or use it as a standalone utility. Typically, it would involve installing the CLI tool on their machine (e.g., via npm or pip, depending on its implementation). Then, by running a simple command in their terminal, authenticated with their Instagram credentials (securely handled, ideally), they can initiate the download of all their saved photos and videos. This could be part of a larger backup script, a personal archiving project, or even a tool for content creators to quickly grab inspiration they've saved.
Product Core Function
· Bulk download of saved Instagram photos: This function uses sophisticated web scraping or API interaction to identify and download all saved image posts. Its value is in preserving visual assets that would otherwise be difficult to access collectively. This is useful for personal archives or for designers seeking visual inspiration.
· Bulk download of saved Instagram videos: Similar to photos, this feature retrieves all saved video posts. The value is in enabling users to retain their favorite video content for offline viewing or repurposing. This is especially helpful for marketers or educators who save video tutorials or clips.
· Simple command-line interface: The value here is extreme ease of use for technical users. A single command bypasses complex manual steps, saving significant time and effort. This is ideal for automated backups or quick content retrieval.
· Authentication and secure handling of user credentials: This ensures that the tool can access your saved posts without compromising your account security. The value is in providing peace of mind and safe access to your data.
Product Usage Case
· Personal media backup: A user wants to ensure they don't lose access to all the inspiring photos and videos they've saved on Instagram over the years. They can run InstaSaver CLI once to download everything to their local hard drive, acting as a personal cloud backup.
· Content creator inspiration vault: A graphic designer frequently saves inspirational images on Instagram. By using InstaSaver CLI, they can quickly export all these saved images into a categorized folder on their computer, making it easier to browse and reference for future design projects.
· Automated archiving script: A developer wants to create a nightly script that backs up all their saved Instagram content. They can incorporate InstaSaver CLI as a step in this script, ensuring their saved media is continuously and automatically archived without manual intervention.
60
Gumpbox AI-Ops Orchestrator
Author
trou3
Description
Gumpbox is a native macOS application that bridges the gap between AI language models and your Linux servers. It allows you to manage and control your server infrastructure through natural language conversations with AI agents like Claude or ChatGPT, eliminating the need for manual command-line interactions. This innovative approach streamlines tasks such as deploying applications, restarting services, and monitoring server health, all while prioritizing security and privacy through local execution.
Popularity
Points 1
Comments 0
What is this product?
Gumpbox is an AI-powered server management tool designed for macOS users. Its core innovation lies in its Model Context Protocol (MCP) server, which runs locally on your Mac. This MCP server acts as a secure intermediary, allowing AI agents like ChatGPT or Claude to understand your commands phrased in natural language and translate them into executable actions on your remote Linux servers. Think of it as giving your AI a direct, secure line to your server infrastructure, so you can chat your way through complex operations instead of remembering obscure commands.
How to use it?
Developers can install Gumpbox on their macOS machines. Once installed, they can configure it to connect to their Linux servers. The application then provides an interface to interact with their chosen AI agent. Instead of logging into a server and typing commands like 'sudo systemctl restart api-service', a developer can simply instruct the AI, for example, 'Restart the API service and check the logs'. Gumpbox securely relays this command, executes it on the server using built-in sandboxing with systemd-run for safety, and then reports the results back to the AI and the user. This allows for a conversational and intuitive approach to server administration and deployment.
Product Core Function
· AI-powered server command execution: Enables natural language commands to be translated into server actions, significantly reducing the learning curve for server management and boosting developer productivity.
· Local MCP server for privacy and security: The Model Context Protocol server runs on the user's Mac, meaning sensitive credentials and commands never leave the local machine, offering a robust privacy-first approach to remote server management.
· Secure AI operations via sandboxing: Utilizes systemd-run for sandboxed execution of AI-generated commands, ensuring that even if an AI command has unintended consequences, it is contained and does not compromise the entire server system.
· Streamlined deployment and management workflows: Allows for conversational triggers for common tasks like deploying new application versions or managing service statuses, making development and operational workflows more efficient and less error-prone.
· Cross-AI compatibility: Designed to work with various AI agents, providing flexibility for developers to choose their preferred AI assistant for server management.
Product Usage Case
· A developer needs to deploy the latest version of their web application to a staging server. Instead of SSHing into the server, navigating to the deployment directory, and running a complex script, they can simply tell Gumpbox, 'Deploy the latest build of my app to the staging environment'. Gumpbox then securely executes the necessary commands on the server.
· A server administrator notices an application is consuming excessive memory. Rather than guessing the cause, they can ask Gumpbox, 'Why is the nginx process using so much memory on the production server?'. Gumpbox will then query the server, gather relevant logs and performance metrics, and present the information to the AI for analysis, potentially identifying the root cause.
· A developer needs to quickly restart a backend service after a configuration change. They can instruct Gumpbox, 'Restart the user-auth service and tail its logs for errors'. Gumpbox handles the restart command and provides a real-time log stream, simplifying the debugging process.
61
DataTalk AI: Conversational BI Engine
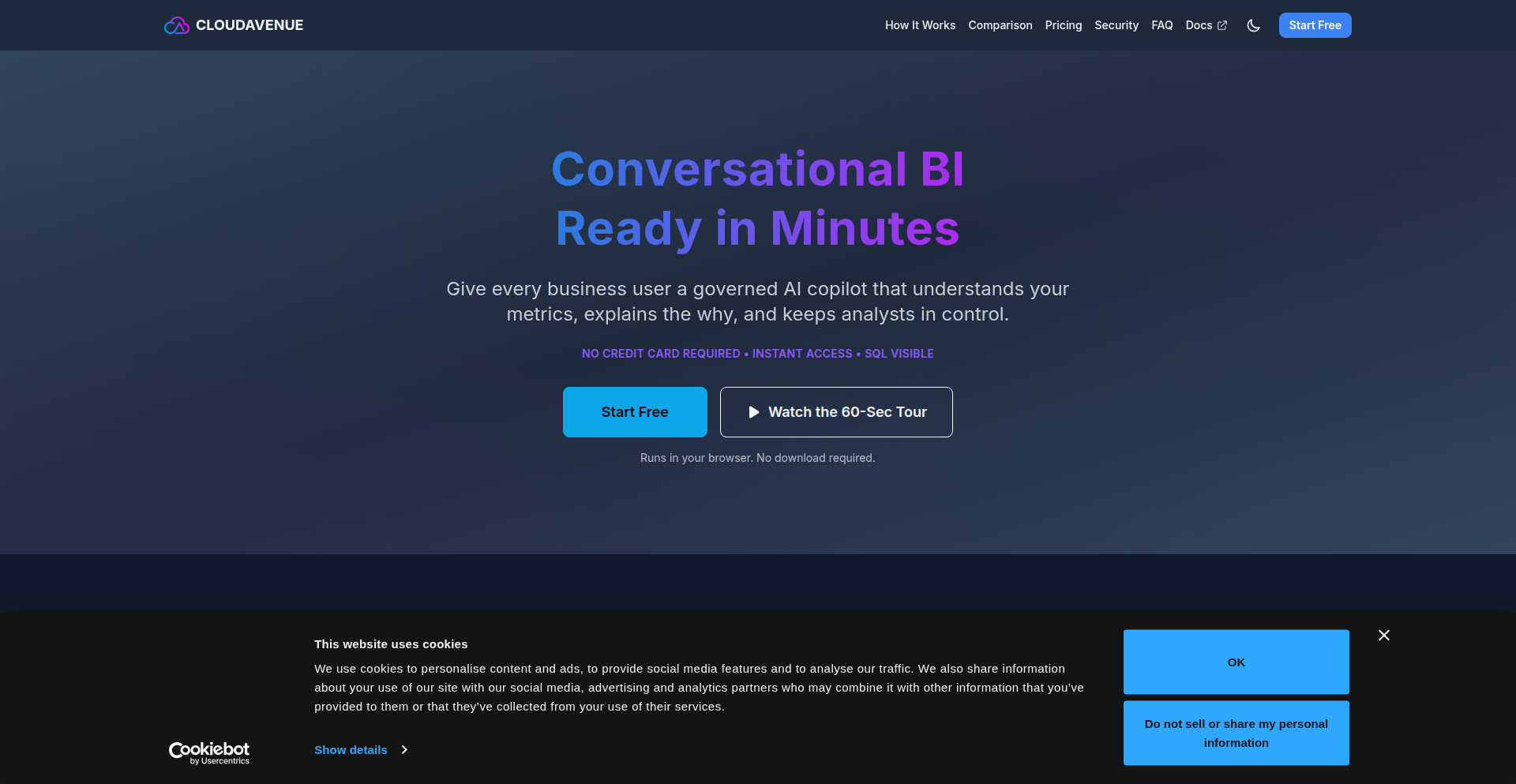
Author
mardel
Description
This is a conversational BI agent that allows business users to interact with their data using natural language. It tackles the problem of data teams spending too much time preparing static reports, while business users often have follow-up questions. DataTalk AI enables direct data exploration, insight discovery, and iterative analysis, bridging the gap between raw data and actionable business intelligence. It's particularly valuable for teams without dedicated data personnel who want to leverage their data immediately.
Popularity
Points 1
Comments 0
What is this product?
DataTalk AI is a platform that uses artificial intelligence to let anyone talk to their business data. Instead of relying on complex dashboards or waiting for data analysts to generate reports, users can simply ask questions in plain English. For example, 'What were our top-selling products last quarter?' or 'Show me the sales trend for the East region.' The innovation lies in its ability to understand these natural language queries, process them against your datasets, and deliver relevant insights, visualizations, or answers in real-time. This transforms static data into a dynamic, interactive resource.
How to use it?
Developers can integrate DataTalk AI into their existing workflows or applications. You can connect your databases (e.g., SQL, PostgreSQL, Snowflake) or upload data files. The platform provides an API for programmatic access, allowing you to embed conversational data exploration into your own products or internal tools. For a quick start, you can use the provided sample dataset (Jaffle Shop) to experience its capabilities before connecting your own data sources. This means your team can get started exploring data without any coding immediately.
Product Core Function
· Natural Language Querying: Allows users to ask data-related questions in plain English, making data accessible to non-technical users. This democratizes data access and reduces the burden on data teams.
· Automated Insight Discovery: The AI engine can proactively identify trends, anomalies, and key performance indicators within the data, surfacing valuable information without explicit user prompting. This helps uncover hidden business opportunities.
· Iterative Data Exploration: Users can refine their queries and explore data in a conversational manner, asking follow-up questions to drill down into specific areas. This speeds up the process of understanding complex data relationships.
· Data Connectivity: Supports connections to various data sources, including popular databases and file formats, ensuring flexibility for different organizational data infrastructures. This means it can work with the data you already have.
· Sample Dataset Trial: Offers a pre-loaded sample dataset for immediate hands-on experience, allowing users to understand the value proposition without the complexity of initial setup. This lets you see the magic happen right away.
Product Usage Case
· A marketing manager wants to understand the performance of a recent campaign. Instead of waiting for a report, they ask DataTalk AI, 'What was the ROI of the summer sale campaign?' The AI analyzes campaign data and provides an immediate answer, allowing the manager to adjust future strategies faster.
· A small business owner without a dedicated data analyst needs to track inventory. They can connect their inventory database and ask, 'Which products are running low on stock?' This helps prevent stockouts and improves operational efficiency.
· A sales team leader wants to identify their best-performing regions. They query DataTalk AI with, 'Show me sales performance by region for Q2.' The AI generates a visual representation and key metrics, enabling the leader to allocate resources more effectively.
· A product manager wants to understand user engagement metrics for a new feature. They can ask, 'What is the average time users spend on the new feature daily?' This helps in understanding adoption and identifying areas for improvement.
62
Crane: macOS Native Container Manager
Author
glsorre
Description
Crane is a native macOS application designed to simplify the management of Apple's container technologies, specifically for developers working within the Apple ecosystem. It tackles the complexity of managing containers directly from the desktop, offering a more intuitive and integrated experience compared to command-line interfaces. The innovation lies in providing a visual and streamlined way to interact with containers on macOS, reducing the learning curve and increasing developer productivity.
Popularity
Points 1
Comments 0
What is this product?
Crane is a desktop application for macOS that allows developers to manage containers without needing to rely solely on command-line tools. It leverages Apple's native UI frameworks to provide a user-friendly interface for tasks like creating, starting, stopping, and inspecting containers. The core technical insight is to abstract away the underlying complexities of container orchestration and present them in a visually digestible format. This means that instead of memorizing intricate command-line arguments, developers can interact with their containers through buttons, lists, and clear visual feedback, making container management accessible to a broader range of developers, including those less familiar with advanced CLI operations. The value proposition is significant: it dramatically lowers the barrier to entry for containerized development on macOS.
How to use it?
Developers can download and install Crane like any other macOS application. Once installed, Crane can connect to the underlying container runtime on their Mac (e.g., Docker Desktop or other compatible container engines). From within Crane's interface, developers can visually browse their running and stopped containers, pull new container images, build custom images, and manage volumes and networks. It's designed for seamless integration into a developer's daily workflow, offering a quick and efficient way to inspect and control their containerized applications without leaving their preferred development environment.
Product Core Function
· Container Visualization: Provides a clear, graphical overview of all containers, their status (running, stopped, exited), and key metrics like CPU and memory usage. This helps developers quickly understand the state of their applications and identify potential issues at a glance, saving time spent on manual inspection.
· Container Lifecycle Management: Enables users to start, stop, restart, and remove containers with simple button clicks, eliminating the need to recall and type complex commands. This accelerates development cycles by making routine container operations significantly faster and less error-prone.
· Image Management: Allows developers to browse, pull, and delete container images directly from the application. This streamlines the process of acquiring and managing the base images for their applications, making it easier to experiment with different software versions and dependencies.
· Network and Volume Inspection: Offers visibility into container networks and volumes, helping developers understand how their containers are connected and how data is persisted. This is crucial for debugging complex distributed applications and ensuring data integrity.
· Resource Monitoring: Displays real-time resource utilization (CPU, memory) for individual containers. This provides developers with immediate feedback on the performance of their applications, enabling them to optimize resource allocation and identify performance bottlenecks efficiently.
Product Usage Case
· A web developer needs to quickly spin up a local development environment with a database and a backend service. Instead of typing multiple docker run commands, they can use Crane to visually select the desired images, configure basic settings, and launch all containers with a few clicks, saving significant setup time.
· A mobile developer working on an iOS app that relies on a backend API running in a container needs to check if the API is healthy and processing requests. Crane allows them to instantly see the API container's status, view its logs, and even restart it if necessary, all without switching to a terminal window, ensuring uninterrupted development.
· A data scientist experimenting with different machine learning models needs to manage multiple containerized environments. Crane helps them keep track of each environment, their dependencies, and resource usage, making it easy to switch between experiments and avoid conflicts, leading to more organized and efficient research.
63
HomeGreet: Dynamic Affirmation Widget
Author
vasanthps
Description
This project introduces a dynamic widget for iOS devices that displays personalized affirmations directly on the home screen. It addresses the challenge of seamlessly integrating positive reminders into a user's daily digital environment without requiring them to open an app. The core innovation lies in leveraging native widget capabilities to deliver curated, high-quality affirmations in a distraction-free, visually appealing manner.
Popularity
Points 1
Comments 0
What is this product?
HomeGreet is an application that utilizes the power of native iOS widgets to put uplifting affirmations right on your iPhone or iPad's home screen. Instead of opening an app to find motivation or positive thoughts, HomeGreet presents these messages automatically as a widget. The technical innovation is in how it effectively uses the widget framework to display constantly updating, pre-selected affirmations. This means you get your daily dose of positivity without any extra effort, making it a seamless part of your digital life.
How to use it?
Developers can integrate HomeGreet into their workflow by installing the companion app and configuring their desired affirmations. The app allows users to select from a curated list of high-quality affirmations or even input their own. Once configured, the user simply adds the HomeGreet widget to their iOS home screen. The widget will then automatically refresh and display different affirmations throughout the day, providing a constant stream of positive reinforcement. This is useful for developers who want to create a more mindful and productive personal environment, or for teams looking to foster a positive culture.
Product Core Function
· Dynamic Home Screen Widget: Displays rotating affirmations directly on the user's home screen, providing constant positive reinforcement without app interaction. This is valuable because it makes mindfulness and positive thinking effortless and integrated into daily life.
· Curated Affirmation Library: Offers a collection of high-quality, well-crafted affirmations designed to boost mood and encourage growth. This is valuable for users who want effective, impactful positive messages.
· Customizable Affirmation Input: Allows users to add their own personal affirmations, tailoring the experience to their specific needs and goals. This provides ultimate personalization and relevance.
· Distraction-Free Design: The widget interface is minimalist and clean, ensuring that affirmations are the focus without any visual clutter. This is valuable for users who find traditional apps too distracting.
Product Usage Case
· Personal Productivity Enhancement: A developer can use HomeGreet to keep their mindset focused on goals and overcome creative blocks by having daily motivational quotes appear on their iPhone's home screen, helping them stay on track without needing to open a dedicated app.
· Team Morale Booster: A team lead could encourage team members to use HomeGreet to foster a positive work environment, with affirmations appearing on their devices throughout the day, promoting a sense of shared well-being and motivation.
· Mental Well-being Support: An individual struggling with anxiety or self-doubt can use HomeGreet to receive consistent, gentle reminders of their strengths and positive qualities, providing continuous support and reducing the need to actively seek out comfort.
· Mindful Digital Detox: For users trying to reduce screen time on specific apps, HomeGreet offers a way to still engage with positive content without the temptation to delve into other, potentially distracting applications.
64
SwampOrMatchaAI
Author
fragkakis
Description
A simple web application that uses a machine learning model to distinguish between images of matcha tea and swamp water. This project showcases a practical application of image classification with a fun, relatable, and slightly quirky problem.
Popularity
Points 1
Comments 0
What is this product?
This project is a web-based AI tool designed to tell you if a given image is of matcha tea or swamp water. It leverages a convolutional neural network (CNN), a type of machine learning model specifically good at processing image data. The innovation lies in its focused application to a visually similar but functionally very different set of subjects, demonstrating how AI can be trained to recognize subtle differences in visual patterns. So, what's the use? It provides a quick and entertaining way to see AI's pattern recognition capabilities applied to everyday (or perhaps, not-so-everyday) visual ambiguities.
How to use it?
Developers can use this project as a demonstration of image classification. It can be integrated into other web applications or mobile apps that require visual identification. For instance, a food blogger could use it to automatically tag photos of their matcha creations, or an environmental researcher could potentially adapt the underlying model to identify murky water sources. The core idea is to take the trained model and deploy it as an API endpoint or a client-side JavaScript model. So, what's the use? It offers a ready-to-use example for building visual recognition features into your own projects, saving you the initial setup and training time.
Product Core Function
· Image Upload and Analysis: Allows users to upload an image file and have the AI model process it to determine its classification. The technical value is in the image preprocessing pipeline and the inference step where the trained model makes a prediction. This is useful for any application that needs to analyze user-submitted images.
· Classification Model: Employs a pre-trained convolutional neural network (CNN) to perform binary image classification (matcha vs. swamp). The innovation here is the specific training and fine-tuning of the model for this unique dataset. The value is in providing a tangible example of a functional AI model for a niche but interesting problem, inspiring developers to explore custom model training.
· Web Interface: Provides a user-friendly web interface for interacting with the AI model. This includes input fields for image upload and display areas for the results. The technical value is in demonstrating how to connect a backend AI model to a frontend user experience, making AI accessible. So, what's the use? It offers a blueprint for creating interactive AI-powered web tools.
· Real-time Feedback: The application provides immediate feedback to the user on whether the image is identified as matcha or swamp. This showcases efficient model inference and result presentation. The value is in demonstrating how to deliver quick, actionable insights from AI analysis. So, what's the use? It's a model for building responsive user experiences in AI applications.
Product Usage Case
· A culinary website could integrate this to help users identify if their homemade matcha latte photo is truly 'matcha' quality or if it resembles murky water, potentially offering tips for improvement. It solves the problem of subjective visual quality assessment in a fun way.
· An educational platform for AI enthusiasts could use this project as a hands-on lab to explore image classification, model training, and deployment. Developers can experiment with the model architecture and training data. It solves the problem of needing a simple, yet illustrative, AI project for learning.
· A social media app could add a quirky filter or feature that allows users to 'test' their drink photos, adding an element of gamification and user engagement. It addresses the need for novel and entertaining features in content creation platforms.
· An artist or designer could use this as inspiration for creating abstract art or visual experiments based on the model's classifications, pushing the boundaries of visual interpretation. It solves the problem of finding unique creative prompts by applying a technical lens to an artistic challenge.
65
LinguaForge
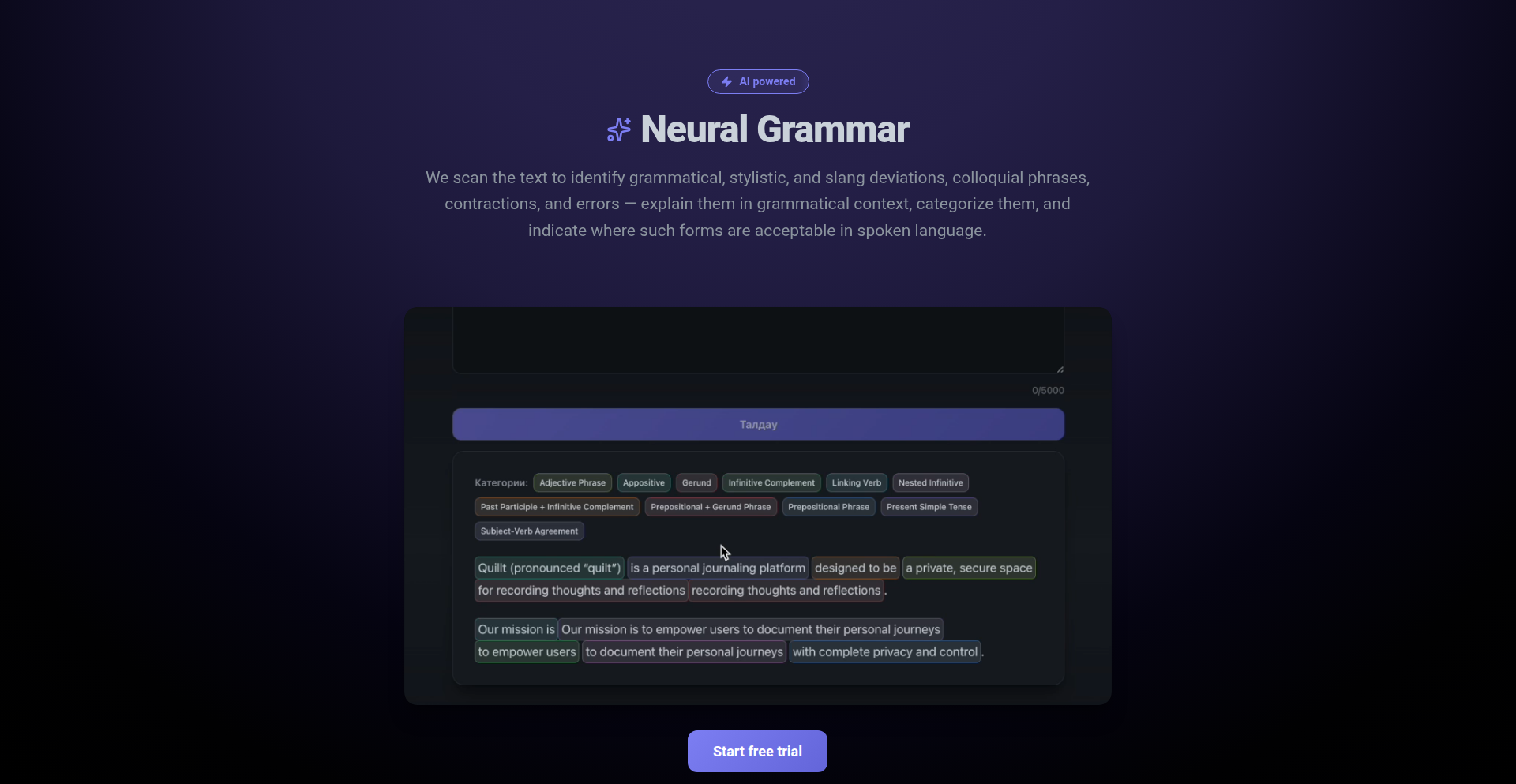
Author
baursha
Description
A self-directed English learning tool leveraging AI-powered content generation and spaced repetition to create personalized learning experiences. It addresses the common challenge of finding relevant and engaging practice material by allowing users to generate content based on their interests and proficiency levels, and then intelligently schedules review sessions to maximize retention.
Popularity
Points 1
Comments 0
What is this product?
LinguaForge is an AI-powered platform designed to help individuals learn and master English more effectively. Its core innovation lies in its ability to generate custom learning content, such as vocabulary lists, sentence examples, and even short stories, tailored to the user's specific interests and learning needs. This is achieved through advanced Natural Language Processing (NLP) and Generative AI models. Furthermore, it incorporates a sophisticated spaced repetition system (SRS) that intelligently schedules reviews of learned material at optimal intervals, preventing forgetting and reinforcing knowledge. So, what's in it for you? Instead of sifting through generic textbooks, you get learning material that's uniquely relevant to your passions, making the learning process more enjoyable and efficient, and significantly improving your long-term retention of new English skills.
How to use it?
Developers can integrate LinguaForge into their existing learning workflows or use it as a standalone application. The platform provides APIs that allow for programmatic generation of learning content, enabling developers to build custom learning modules or applications. For instance, a developer could create a browser extension that automatically generates vocabulary quizzes based on the articles a user is reading online, or a mobile app that provides conversational practice scenarios generated in real-time. The SRS component can also be accessed via API to manage and schedule review sessions. So, how can you leverage this? You can embed personalized English learning experiences directly into your own software or workflows, offering a powerful, tailored educational component to your users or enhancing your personal learning journey.
Product Core Function
· AI-driven content generation: Dynamically creates vocabulary, example sentences, and reading passages based on user-defined topics and complexity levels. This means your learning material is always fresh, relevant, and perfectly suited to your current understanding, making learning feel less like a chore and more like an engaging exploration.
· Personalized learning paths: Adapts the learning material and difficulty based on user performance and feedback, ensuring continuous progress. This ensures you're always challenged appropriately, moving you forward without overwhelming you, and ultimately leading to faster and more sustainable skill acquisition.
· Intelligent spaced repetition system (SRS): Optimizes review scheduling for maximum knowledge retention, ensuring that what you learn stays with you long-term. This feature acts like a personal memory coach, reminding you of what you need to review just before you're likely to forget it, making your study time much more impactful.
· Interest-based learning: Allows users to select topics of interest, which then form the basis for generated learning content, boosting engagement and motivation. Learning becomes more enjoyable and effective when it's tied to things you genuinely care about, transforming the learning process into a rewarding pursuit.
· API for integration: Provides programmatic access to content generation and SRS functionalities, enabling developers to build custom learning applications and integrations. This empowers developers to create unique English learning solutions tailored to specific needs or to infuse their own products with powerful educational capabilities.
Product Usage Case
· A language learning app developer wants to offer users a more engaging way to learn vocabulary related to their hobbies. They can use LinguaForge's API to generate personalized vocabulary lists and example sentences for knitting, astronomy, or any other niche interest, making the app stand out from generic competitors and significantly improving user retention by making learning fun and relevant.
· A content creator wants to build a tool for their audience to practice English by analyzing their favorite movie scripts. They can use LinguaForge to generate comprehension questions, vocabulary exercises, and summary tasks based on uploaded script snippets, providing a highly specific and interactive learning experience that directly addresses their audience's interests and boosts their English comprehension.
· An individual learner struggling with remembering new English words. They can use LinguaForge to generate flashcards and practice quizzes on topics they find interesting. The SRS will then schedule reviews, ensuring they efficiently memorize new vocabulary without the frustration of forgetting, leading to faster and more confident language use in real conversations.
· A developer building an e-learning platform for professionals. They can integrate LinguaForge's content generation to create specialized business English vocabulary and situational dialogues relevant to specific industries (e.g., finance, healthcare), providing highly targeted and practical language training that directly benefits users in their careers and enhances the platform's value proposition.
66
PluginScore AI
Author
blurayfin
Description
PluginScore AI is a web application that provides at-a-glance code quality reports for WordPress plugins. It automates the process of analyzing plugins for security vulnerabilities, performance bottlenecks, adherence to WordPress.org repository policies, and general coding standards. The core innovation lies in its automated aggregation and scoring of complex code analysis results into an easily digestible format, empowering developers and users to quickly understand plugin health without deep manual inspection.
Popularity
Points 1
Comments 0
What is this product?
PluginScore AI is a free, no-signup-required web tool that automatically scans WordPress plugins to assess their code quality. It leverages powerful static analysis tools like 'wp plugin check' (the official WordPress plugin checker) and PHP_CodeSniffer with WordPress coding standards. It then synthesizes these findings into a comprehensive report, including an overall score (0-100), detailed breakdowns by category (security, performance, policy, general coding, accessibility), and lists individual issues with severity and documentation links. The innovation is in its ability to abstract complex technical analysis into a user-friendly score and actionable insights, making code quality visible and understandable to a wider audience, including non-technical users who want to assess plugin trustworthiness.
How to use it?
Developers can use PluginScore AI by simply visiting the website (pluginscore.com) and entering the 'slug' of any WordPress plugin from WordPress.org into the analysis box on the homepage. The system will then either display an existing report or initiate a new scan for that plugin. This allows developers to quickly check their own plugins, analyze competitor plugins, or evaluate third-party plugins before integration. For integration into development workflows, developers could potentially use the generated reports to identify specific areas for improvement in their codebase, or even build automated checks into their CI/CD pipelines if an API were to become available in the future.
Product Core Function
· Automated WordPress Plugin Scanning: Leverages 'wp plugin check' and PHP_CodeSniffer to perform in-depth code analysis, providing automated, hands-off quality assessments. This saves developers significant manual effort in code review and auditing.
· Code Quality Scoring: Assigns an overall 0-100 score and category-specific scores (security, performance, etc.) to objectively quantify plugin quality. This offers a quick, intuitive understanding of a plugin's health and potential risks.
· Detailed Issue Reporting: Lists specific code findings with severity levels and links to documentation, enabling developers to pinpoint and fix issues efficiently. This translates complex error messages into actionable steps for improvement.
· Trend Analysis and History: Tracks scan history and score changes over time, allowing developers to monitor the progress of their plugins and identify regressions. This provides valuable feedback on the impact of code changes and refactoring efforts.
· Leaderboards and Movers: Showcases plugins that are improving or declining in quality, fostering a sense of community competition and encouraging best practices. This highlights industry trends and best-in-class examples for developers to learn from.
Product Usage Case
· A WordPress plugin developer wants to ensure their new plugin meets high standards before launch. They input their plugin's slug into PluginScore AI, receive a report highlighting security weaknesses and performance bottlenecks, and then fix these issues, leading to a more robust and trustworthy plugin.
· A website owner is considering installing a new third-party WordPress plugin and wants to assess its potential risks. They use PluginScore AI to get a quick quality score and check for any critical security or performance warnings, helping them make an informed decision about plugin safety.
· A plugin development agency uses PluginScore AI to benchmark the code quality of their existing client plugins and identify areas for potential refactoring or optimization. This helps them prioritize work and demonstrate tangible improvements to their clients.
· A developer is curious about the code quality of popular WordPress plugins like WooCommerce. They analyze them using PluginScore AI to understand what makes these plugins perform well and identify common patterns or potential areas for improvement in the wider ecosystem.
67
ProsePilot
Author
GrammarChecker
Description
ProsePilot is a Hacker News Show HN project that offers a straightforward grammar and writing mistake correction tool. Its innovation lies in its simplified approach to identifying and rectifying common writing errors, making polished writing more accessible. This project tackles the challenge of delivering accurate writing feedback without overwhelming the user with complex linguistic analysis, focusing on practical improvements. Its value to the developer community lies in its demonstration of efficient text processing and rule-based error detection, serving as a foundation or inspiration for more sophisticated language tools.
Popularity
Points 1
Comments 0
What is this product?
ProsePilot is a technical experiment focused on building a functional grammar checker. At its core, it employs a set of predefined linguistic rules and pattern matching algorithms to scan text for common errors such as subject-verb agreement issues, incorrect tense usage, punctuation mistakes, and basic spelling errors. The innovation here isn't necessarily a groundbreaking AI model, but rather the efficient implementation of these rules to provide immediate and understandable feedback. Think of it like a highly organized checklist for good writing, rather than a deep understanding of nuances. So, for you, this means a more polished and professional piece of writing with less effort.
How to use it?
Developers can integrate ProsePilot into their workflows by utilizing its core logic, likely exposed as a library or API. This could involve: 1. Text Input: Feeding text directly into the checker. 2. Rule Application: The tool processes the input against its internal grammar and style rules. 3. Error Reporting: It returns a list of identified errors with suggested corrections. For example, a developer building a content management system might integrate ProsePilot to automatically flag potential errors in user-submitted articles before publication. This saves time and ensures a higher quality of content. So, for you, this means you can automate the process of ensuring quality in any text-based content you handle.
Product Core Function
· Subject-Verb Agreement Check: Identifies and suggests corrections for mismatches between subjects and verbs in a sentence. This ensures grammatical correctness and clarity in your writing. So, for you, this means avoiding awkward or incorrect sentence structures.
· Tense Consistency Analysis: Detects inconsistent verb tenses within a passage and suggests a more uniform tense. This leads to smoother narratives and prevents reader confusion. So, for you, this means your story or explanation flows logically without jarring shifts in time.
· Punctuation Error Detection: Flags common punctuation mistakes like missing commas, incorrect apostrophe usage, or misplaced periods. This improves readability and professionalism. So, for you, this means your sentences are correctly structured and easy to follow.
· Basic Spelling Correction: Identifies and proposes corrections for common spelling errors. This ensures your writing is error-free and credible. So, for you, this means your message is delivered without distracting typos.
· Common Grammatical Structure Alerts: Highlights frequently misused phrases or incorrect sentence constructions. This helps refine your writing style and avoid common pitfalls. So, for you, this means you're guided towards more standard and effective ways of expressing yourself.
Product Usage Case
· A blogger using ProsePilot to quickly proofread their posts before publishing, ensuring a professional and error-free appearance to their audience. This addresses the problem of time constraints in manual proofreading and the risk of overlooked mistakes. So, for you, this means your blog posts will look more polished and professional.
· A developer integrating ProsePilot into a collaborative writing platform, where it automatically flags potential grammar issues for contributors, improving the overall quality of shared documents. This solves the challenge of maintaining consistent writing standards across a team. So, for you, this means your team's documents will be more accurate and easier to understand.
· A student using ProsePilot to check their essays, ensuring that grammatical errors do not detract from the quality of their arguments. This helps them focus on content while receiving automated assistance with mechanics. So, for you, this means your academic work will be free from common errors, allowing your ideas to shine.
68
ZenMoment: Privacy-First Wellness Engine
Author
951560368
Description
ZenMoment is a minimalist meditation and breathing exercise tool built with a strong emphasis on privacy and performance. It addresses the common issues of data collection and feature bloat found in many wellness apps by offering a simple, client-side experience that runs instantly and without any user accounts or tracking. Its technical innovation lies in its static export architecture and client-side data handling, ensuring a fast, private, and accessible user experience. So, what's in it for you? You get a meditation tool that respects your data and your time, loading in under a second and working offline.
Popularity
Points 1
Comments 0
What is this product?
ZenMoment is a web-based application designed for meditation and breathing exercises. Technically, it leverages Next.js 14 with static export, meaning the entire application is pre-built into static files that can be served instantly. All user data, like daily stats, is stored locally in the browser's localStorage, completely bypassing any server-side processing or data collection. This 'privacy by design' approach eliminates the need for user accounts, cookies, or third-party analytics, making it GDPR/CCPA compliant by default. The innovation here is a radical simplification of the wellness app model, prioritizing user privacy and performance over data monetization and feature overload. So, what's in it for you? You get a meditation tool that's incredibly fast, respects your privacy by not collecting any personal information, and works even when you're offline.
How to use it?
Developers can use ZenMoment by simply visiting the website (zenmoment.net). The application is designed to be used directly through a web browser on any device. For integration into other projects or workflows, the open-source nature of ZenMoment means developers can inspect its codebase, which is built using Next.js 14, TypeScript, Zustand for state management, Framer Motion for animations, and Tailwind CSS for styling. The core functionality is client-side, making it straightforward to understand and potentially adapt. So, what's in it for you? As a developer, you can use it as a ready-made, privacy-respecting wellness tool, or explore its clean, client-side architecture as inspiration for your own projects.
Product Core Function
· Simple meditation timer: Provides pre-set durations (1-15 minutes) for focused meditation sessions. The technical value is in its instant availability and clutter-free interface, offering a distraction-free experience. This is useful for quickly starting a meditation without any setup.
· 4-7-8 breathing exercise with visual guides: Guides users through a specific breathing technique with on-screen visuals. The innovation is in its client-side animation and timing, ensuring accuracy and accessibility without server dependencies. This is useful for users seeking guided relaxation and stress reduction.
· Dark mode: Offers a dark color scheme for improved comfort during low-light conditions or night-time use. This enhances user experience and accessibility, especially for extended sessions.
· Daily stats tracking: Records basic meditation session data locally in the browser's localStorage. The technical value is in its privacy-preserving local storage approach, avoiding external data collection. This is useful for users who want to monitor their practice without sharing their data.
· SEO-optimized blog for meditation content: Provides articles and information related to meditation, optimized for search engines. The technical value is in content delivery and discoverability, making the tool a more comprehensive resource for users interested in mindfulness.
Product Usage Case
· A busy professional needs a quick way to de-stress during a short break. They can open ZenMoment, select a 5-minute meditation timer, and begin immediately without any login or setup. This solves the problem of time-consuming app onboarding and data entry.
· A user is concerned about their online privacy and wants a meditation app that doesn't track their habits. ZenMoment's 'privacy by design' approach, using only local storage and no external tracking, directly addresses this concern, offering peace of mind.
· A developer is building a personal wellness dashboard and wants to integrate a simple, reliable meditation timer. They can examine ZenMoment's open-source codebase, specifically its client-side timer implementation, to understand how to build a similar feature that respects user data.
· Someone wants to practice mindful breathing on their phone while commuting or in a location with poor internet connectivity. ZenMoment's ability to work offline after the initial load ensures they can access the breathing exercises without interruption.
69
AI-First Web Blueprint
Author
kure256
Description
This project proposes a set of open, practical guidelines to make websites understandable and indexable by AI assistants like ChatGPT, Gemini, and Copilot. It addresses the shift in information consumption from traditional browsing to AI interactions, offering a new 'SEO' for the AI era to ensure your content is discoverable and citable by these advanced systems.
Popularity
Points 1
Comments 0
What is this product?
This is a set of evolving best practices, not a framework, designed to make the web 'machine-readable' for AI assistants. It focuses on structured data and clear content presentation, akin to how SEO optimized for search engines. The innovation lies in anticipating and adapting to the way AI models consume and process information, ensuring your digital assets are recognized and utilized by the next generation of information retrieval tools. For developers, this means ensuring their websites aren't invisible to the growing number of users who rely on AI for information.
How to use it?
Developers can integrate these guidelines by structuring their website content and metadata according to the proposed best practices. This involves using semantic HTML, providing clear and concise content, and potentially incorporating specific machine-readable formats (like structured data) as outlined in the project's documentation. The goal is to make it easier for AI assistants to crawl, understand, and accurately cite information from your site. Think of it as adding signposts for AI bots.
Product Core Function
· Machine-Readable Content Structuring: Provides guidelines on organizing web content (text, data) in a way that AI models can easily parse and understand, improving discoverability and accuracy of AI-generated summaries. Value: Ensures your content is accurately represented by AI, leading to better user engagement.
· AI-Centric Metadata Optimization: Offers recommendations for metadata that helps AI assistants identify, index, and cite your content correctly, similar to how meta descriptions and keywords work for search engines. Value: Increases the chances of your site being referenced and credited by AI, boosting authority and traffic.
· Semantic Web Integration: Encourages the use of semantic web technologies and practices to provide explicit meaning to web content, enabling AI to grasp context and relationships more effectively. Value: Allows AI to understand the nuances of your content, leading to more relevant search results and insights.
· Open and Evolving Best Practices: A community-driven approach to defining and refining guidelines, ensuring they remain relevant as AI technology advances. Value: Provides a forward-looking, adaptable solution that stays ahead of the curve in AI information retrieval.
Product Usage Case
· A blogger implementing these guidelines to ensure their articles are accurately summarized and cited by AI assistants like Gemini, driving more traffic to their site. This solves the problem of content being overlooked by the growing AI-powered search user base.
· A developer building a technical documentation website uses the blueprint to make their API references and guides easily discoverable and understandable by AI coding assistants like GitHub Copilot, helping developers find solutions faster. This addresses the challenge of complex technical information being difficult for AI to ingest.
· An e-commerce platform applies these principles to product descriptions, enabling AI assistants to provide more precise product recommendations and comparisons to users, thereby improving conversion rates. This solves the issue of generic AI responses that don't highlight product specifics.
70
WikiJSON-Cleaner
Author
zeronex
Description
This project is a sophisticated data pipeline that transforms the raw XML dump of French Wikipedia into individual, clean JSON files for each article. It tackles the challenge of messy wikitext and complex markup by systematically extracting and structuring article content, infoboxes, categories, and links. The innovation lies in its custom-built, efficient processing of a massive dataset, making it directly usable for Natural Language Processing (NLP) and Large Language Model (LLM) experiments. This offers a cleaner, more accessible dataset for researchers and developers compared to the original Wikipedia dump.
Popularity
Points 1
Comments 0
What is this product?
WikiJSON-Cleaner is a self-built data processing pipeline designed to convert the entire French Wikipedia dump from its raw XML and wikitext format into approximately 2.7 million individual JSON files. The core innovation is its robust approach to parsing and cleaning complex wiki markup, accurately extracting structured data like article sections, infoboxes (transformed into usable JSON objects), categories, and internal links. This results in a dataset that is significantly cleaner and more directly compatible with modern data analysis tools for NLP and LLM tasks, solving the problem of dealing with the inherent messiness and complexity of the original Wikipedia data. The value to you is a readily available, clean dataset that drastically reduces the upfront data wrangling effort for your AI projects.
How to use it?
Developers can use WikiJSON-Cleaner by downloading the generated JSON files. Each JSON file represents a single Wikipedia article and is structured for immediate use. For instance, if you're building an LLM that needs to understand French encyclopedic knowledge, you can directly load these JSON files into your training or fine-tuning process. Integration involves simply reading these files programmatically using standard JSON parsing libraries available in most programming languages (like Python's `json` module). You can then feed this clean data into your NLP models for tasks like text generation, information extraction, or question answering. The value to you is a direct path to using a high-quality, curated dataset without needing to build the complex parsing infrastructure yourself.
Product Core Function
· XML Stream Reading: Processes the large Wikipedia XML dump efficiently by reading it as a stream, preventing memory overload and enabling handling of massive datasets. The value is faster processing and reduced resource consumption when working with huge data archives.
· Wikitext and Markup Removal: Strips away complex wikitext syntax and leftover HTML/XML markup, leaving only the pure article content. The value is a significantly cleaner dataset that is easier for NLP models to interpret and process, reducing noise and improving model accuracy.
· Section Reconstruction: Reorganizes the extracted content into logical sections based on Wikipedia's structure. The value is organized data that reflects the original article's flow, making it easier for analysis and consumption by AI models that benefit from semantic structure.
· Infobox Parsing to JSON Object: Converts the structured information found in Wikipedia infoboxes (like key-value pairs for a person or place) into a standard JSON object. The value is that this structured data can be easily queried and used in applications, providing quick access to key facts about an article's subject.
· Metadata Extraction (Categories, Links): Extracts essential metadata such as article categories and internal/external links. The value is enriched data that allows for more sophisticated analysis, such as understanding article relationships or exploring the Wikipedia knowledge graph.
Product Usage Case
· Building a French-language LLM for general knowledge: Developers can use the 2.7 million JSON files as a training corpus to teach an LLM about French culture, history, and science. This solves the problem of needing a large, well-structured dataset for comprehensive language understanding.
· Developing a specialized search engine for French Wikipedia: Researchers can build a more intelligent search engine that leverages the structured data (infoboxes, categories) to provide more precise and context-aware results than a simple keyword search. This addresses the challenge of navigating and finding specific information within a vast knowledge base.
· Creating an AI-powered summarization tool for French articles: Developers can train a model on these clean JSON articles to generate concise summaries of French Wikipedia pages. This solves the problem of quickly grasping the main points of lengthy articles without manual effort.
· Conducting linguistic research on French Wikipedia content: Academics can use this dataset for various linguistic analyses, such as studying word frequencies, sentence structures, or the evolution of language within the French Wikipedia. This provides a clean and accessible dataset for empirical linguistic studies.
71
DNA-SeqCompress
Author
bruinmeister
Description
DNA-SeqCompress is a novel AI context window compression technique inspired by DNA's efficient information encoding. It tackles the limitation of AI models' ability to process long texts by intelligently summarizing and retaining crucial information, much like DNA sequences store vast biological data concisely. This means AI can 'remember' and reason over much larger amounts of information without losing key details, making it more powerful for complex tasks.
Popularity
Points 1
Comments 0
What is this product?
DNA-SeqCompress is an innovative approach to overcome the limited context window of AI models. Current AI models struggle to process and 'remember' very long pieces of text. This project draws an analogy from DNA, which stores incredibly complex genetic information in a highly compressed format. DNA-SeqCompress applies similar principles of identifying essential 'sequences' and relationships within text to create a condensed representation. This compressed representation can then be fed to an AI model, allowing it to understand and utilize information from much longer sources than previously possible. The core innovation lies in using biological inspiration to solve a computational bottleneck, effectively creating a smarter way for AI to handle large datasets.
How to use it?
Developers can integrate DNA-SeqCompress into their AI pipelines to preprocess text data before feeding it to language models. Imagine you have a lengthy research paper, a book, or a massive log file you want an AI to analyze. Instead of feeding the whole text, you first use DNA-SeqCompress to create a summarized, yet information-rich, version. This compressed output can then be used by the AI model for tasks like summarization, question answering, or trend analysis. This integration would typically involve calling a library or API provided by DNA-SeqCompress within your AI application's data processing layer.
Product Core Function
· Semantic Compression Algorithm: Compresses long text inputs by identifying and preserving key semantic information, enabling AI to process more data efficiently. This directly addresses the 'so what does this do for me?' by allowing your AI applications to handle larger datasets without sacrificing understanding.
· Information Retention Mechanism: Ensures that crucial details and relationships within the text are maintained during compression, preventing information loss. This is valuable to you because it means your AI won't 'forget' important nuances, leading to more accurate and reliable results.
· Context Window Extension: Effectively expands the 'memory' capacity of AI models by allowing them to work with compressed representations of longer texts. For you, this means your AI can tackle more complex problems that require understanding extensive context.
· DNA Analogy Engine: Leverages principles from biological DNA sequencing for efficient data encoding and retrieval, providing a novel and potentially more robust compression strategy. This inspires you by showing how cross-disciplinary thinking can unlock new solutions to computational problems.
Product Usage Case
· Analyzing lengthy legal documents: Developers can use DNA-SeqCompress to summarize complex contracts or court proceedings, enabling AI to quickly extract key clauses or identify relevant precedents, saving significant time and effort.
· Processing extensive customer feedback: By compressing large volumes of customer reviews or support tickets, AI can more effectively identify recurring issues and sentiment trends, allowing businesses to improve products and services.
· Summarizing scientific research papers: Researchers can use this tool to get a concise overview of lengthy scientific articles, accelerating the discovery and synthesis of new knowledge.
· Building AI assistants for historical archives: DNA-SeqCompress can help AI models process vast historical texts and documents, enabling more comprehensive and context-aware responses to historical queries.
· Improving AI's understanding of long-form narratives in creative writing: For AI-powered story generation or analysis, this technique can help maintain plot coherence and character development over extended narratives.
72
CBK Agent SDK: The Cognitive Building Blocks for Agents
Author
_pdp_
Description
CBK Agent SDK is a foundational toolkit for developers looking to build sophisticated AI agents. It provides a set of composable 'cognitive primitives' that abstract away complex AI model interactions, enabling developers to focus on agent logic and orchestrate AI capabilities with ease. This solves the challenge of integrating and managing diverse AI models for agentic behavior, offering a more accessible path to creating intelligent, task-oriented agents.
Popularity
Points 1
Comments 0
What is this product?
CBK Agent SDK is a software development kit (SDK) that offers pre-built, reusable components for creating AI agents. Think of it like a LEGO set for AI. Instead of building every single piece of an AI agent from scratch, you get access to 'cognitive building blocks' that represent common AI tasks like understanding language, reasoning, planning, and interacting with tools. These blocks are designed to work together seamlessly, allowing you to assemble powerful agents by connecting these primitives. The innovation lies in its modular design and the abstraction it provides over potentially complex underlying AI models, making agent development more efficient and less prone to integration headaches. So, what does this mean for you? It means you can build smarter AI assistants and automation tools faster, without needing to be an expert in every single AI model.
How to use it?
Developers can integrate the CBK Agent SDK into their projects by installing it as a library. You'll then instantiate different cognitive primitives based on the capabilities your agent needs. For example, if your agent needs to understand user queries, you'd use the 'Natural Language Understanding' primitive. If it needs to plan a sequence of actions, you'd use the 'Planning' primitive. These primitives can be chained together to form complex workflows. The SDK handles the communication with underlying AI models (like LLMs) and manages their outputs. Common integration scenarios include building chatbots, data analysis agents, automated content generation systems, or even sophisticated workflow automation tools. So, how can you use this? You can drop it into your existing application or start a new project to empower it with AI agent capabilities, allowing it to perform complex tasks autonomously.
Product Core Function
· Modular Cognitive Primitives: Provides pre-built AI functionalities like natural language processing, reasoning, and planning, allowing developers to assemble agent capabilities like digital LEGOs, accelerating development by avoiding redundant AI integration efforts.
· Orchestration Layer: Manages the flow of information and execution between different AI primitives, ensuring a coherent and effective agent response, which simplifies the complexity of coordinating multiple AI model interactions for a unified agent behavior.
· Tool Integration: Enables agents to interact with external tools and APIs through defined interfaces, extending the agent's capabilities beyond core AI functions and allowing it to perform real-world actions or access live data.
· State Management: Handles the internal state and memory of the agent, allowing it to maintain context across interactions and make more informed decisions over time, crucial for building persistent and responsive AI assistants.
· Abstracted AI Model Interaction: Shields developers from the intricacies of interacting with specific AI models, offering a unified interface to leverage various AI backends, thereby reducing the learning curve and technical debt associated with AI model management.
Product Usage Case
· Building a Customer Support Chatbot: Use the SDK to create an agent that can understand customer inquiries (NLU primitive), retrieve information from a knowledge base (tool integration), and formulate helpful responses (reasoning and NLU), directly addressing customer issues with less manual intervention.
· Developing an Automated Data Analysis Agent: Construct an agent that can ingest raw data, identify trends and patterns (reasoning and NLU), and generate reports (tool integration with reporting services), streamlining the data analysis process for businesses.
· Creating a Personal Productivity Assistant: Design an agent that can manage schedules, set reminders, and even draft emails based on user prompts (planning, NLU, and tool integration with calendar/email APIs), helping individuals organize their tasks more efficiently.
· Implementing an Intelligent Content Generation Tool: Develop an agent that can generate articles, summaries, or marketing copy based on high-level requirements (NLU for prompt understanding, reasoning for content structure, and NLU for output generation), automating content creation workflows.
· Automating Complex Workflow Execution: Build an agent that can orchestrate a series of steps involving different systems and AI models to complete a business process, such as processing loan applications or managing inventory, leading to significant operational efficiency gains.
73
xemantic-neo4j-kotlin-driver
Author
morisil
Description
This project is a Neo4j driver for Kotlin that significantly reduces the cognitive load for Large Language Models (LLMs) interacting with Neo4j graph databases. It achieves this through idiomatic DSLs for resource management, automatic mapping of data between Neo4j's Cypher query language and Kotlin data classes, and leveraging Kotlin's structured concurrency features. The core innovation lies in simplifying the way AI agents can query and ingest data into a knowledge graph, making their reasoning process more efficient and accurate.
Popularity
Points 1
Comments 0
What is this product?
This is a specialized software library (a Neo4j driver) designed to make it super easy for developers, especially those working with AI and Kotlin, to connect to and work with Neo4j graph databases. Think of Neo4j as a powerful way to store and understand connected data, like relationships between people or concepts. The main 'geeky' idea here is to build this driver in a way that requires minimal 'thinking effort' from AI agents. This is done by automatically translating queries and results between the database's language (Cypher) and clean, structured Kotlin data. It also uses Kotlin's modern asynchronous programming features (coroutines) to handle database operations smoothly and efficiently without explicit 'async' keywords, making the code cleaner and less error-prone. The value is in making AI agents smarter and faster when they need to access information stored in a graph.
How to use it?
Developers can integrate this driver into their Kotlin projects, especially those building AI agents or applications that heavily rely on graph data. It's designed to work seamlessly with Kotlin's coroutines for asynchronous operations, meaning database calls won't block your application. You can use it to define how your AI agent should fetch information from Neo4j (e.g., finding related concepts in a knowledge base) or store new information. The automatic data mapping means you don't have to write a lot of boilerplate code to convert data formats. The associated demo project shows how to use this driver with Ktor (a Kotlin web framework) for building full-stack applications where data needs to be handled asynchronously.
Product Core Function
· Idiomatic DSL for resource management: This means the code for managing database connections and transactions is written in a natural, readable Kotlin style, reducing the chance of errors and making it easier for AI agents to understand and execute. This is valuable because it simplifies complex database interactions, leading to more reliable AI behavior.
· Automatic Cypher input and output mapping to multiplatform data classes: The library automatically converts data between the Neo4j query language (Cypher) and your defined Kotlin data structures. This is extremely useful because it eliminates the need for manual data conversion, saving development time and reducing bugs. For AI agents, this means they can work with data in a format they understand directly.
· Leveraging Kotlin's structured concurrency (coroutines): This allows for efficient handling of asynchronous database operations without the complexity often associated with traditional async programming. The value is in building responsive and performant applications, especially for AI agents that might need to perform many database operations concurrently without blocking.
· Minimal cognitive load for LLMs: The library is designed to reduce the mental effort required for an LLM to interact with the database. This is achieved through clear APIs and automatic data handling, enabling LLMs to focus on reasoning rather than on the intricacies of database interaction. The practical benefit is improved AI performance and accuracy in tasks involving data retrieval and manipulation.
· Strongly typed and compiled feedback: The use of Kotlin's strong typing and compilation provides immediate feedback on errors during development. This is beneficial for developers and AI agents as it catches potential issues early, leading to more robust code and predictable agent behavior.
Product Usage Case
· Building AI agents that use Neo4j as a long-term memory: An AI agent can use this driver to store and retrieve memories as a knowledge graph. For example, if an AI is learning about a topic, it can store facts and relationships in Neo4j. When it needs to recall information, the driver helps it query the graph efficiently. This improves the AI's ability to build complex knowledge and recall it accurately.
· Developing autonomous research systems: Imagine an AI designed to research scientific papers. This driver could allow the AI to ingest research data into Neo4j, build relationships between concepts, and then query this knowledge graph to identify research gaps or connections. This accelerates the research process by automating data organization and retrieval.
· Creating applications with real-time graph data visualization: When building a web application with Ktor that needs to display dynamic relationships between data points (e.g., social networks, recommendation engines), this driver can efficiently fetch data from Neo4j and map it to the application's frontend components. This ensures the application remains responsive and displays up-to-date graph information.
· Simplifying data ingestion pipelines for graph databases: For developers who need to populate a Neo4j database with data from various sources, this driver offers a straightforward way to define ingestion schemas and perform the data mapping automatically. This saves significant development effort and reduces the potential for errors in data loading processes.
74
Teller - Unobtrusive AI Podcast Curator

Author
tellerbr15
Description
Teller is a podcast consumption platform designed to intelligently recommend shows and episodes you'll genuinely enjoy. Its current V1 focuses on perfecting core listening features like library management, playback, queueing, and foundational recommendation algorithms. The innovation lies in its approach to automation that aims to be seamless and 'unnoticed', enhancing the user experience without overt complexity. V2 promises more advanced AI for an even richer, personalized listening journey. This project exemplifies the hacker ethos of leveraging code to solve real-world problems, specifically the challenge of information overload in podcasting.
Popularity
Points 1
Comments 0
What is this product?
Teller is a smart podcast player that uses technology to figure out what you like to listen to, and then suggests new podcasts and episodes you'll probably enjoy. The core idea is to make this recommendation process feel natural and effortless – it should just work without you needing to constantly tweak settings. Think of it as a personal DJ for your podcasts. The V1 version is all about getting the basics right: making it easy to find your podcasts, play them, manage your listening queue, and providing initial recommendations. Future versions (V2) will use more sophisticated AI to make these suggestions even better, truly personalizing your podcast experience. The innovation here is creating an AI that augments your listening without being intrusive, truly making automation go unnoticed.
How to use it?
For developers, Teller can be envisioned as a backend service or an SDK that integrates into existing podcast applications or even builds new ones. You can leverage its recommendation engine to enhance user engagement within your own platform. For instance, if you're building a new podcast app, you could integrate Teller's API to provide personalized episode suggestions to your users from day one, saving you the significant development effort of building a recommendation system from scratch. Alternatively, if you have an existing app, Teller could be a powerful add-on to boost user retention by surfacing relevant content they might have missed. The goal is to offer a robust, yet easy-to-integrate solution for personalized podcast discovery.
Product Core Function
· Personalized Episode Recommendations: Utilizes AI algorithms to analyze listening habits and suggest relevant podcast episodes. This provides value by helping users discover new content they are likely to enjoy, reducing time spent searching and increasing listening satisfaction.
· Seamless Library Management: Offers intuitive tools for organizing and accessing a podcast library. This streamlines the user experience by making it easy to manage subscriptions and find preferred shows, enhancing usability and reducing frustration.
· Intelligent Queue System: Allows users to create and manage a personalized listening queue. This empowers users to curate their listening sessions and stay engaged with content, improving the overall listening flow and preventing content fatigue.
· Foundational Listening Features: Includes essential podcast playback controls and features perfected for user convenience. This ensures a reliable and enjoyable listening experience, forming the bedrock of the platform's utility.
Product Usage Case
· Integrating Teller into a new podcast app to immediately offer intelligent content suggestions to early adopters. This solves the cold-start problem for recommendations and improves initial user engagement.
· Enhancing an existing podcast platform with Teller's recommendation engine to re-engage dormant users by surfacing content tailored to their past listening preferences. This can increase session duration and retention.
· Using Teller's API to power a personalized 'daily digest' feature for a niche podcast network, helping listeners discover highly relevant episodes across multiple shows. This addresses content discoverability challenges within a specific domain.
· Developing a browser extension that leverages Teller to suggest related podcast episodes while a user is browsing other content online. This expands the potential reach of podcast discovery beyond dedicated apps.
75
ArabicFlow
Author
selmetwa
Description
ArabicFlow is an open-source interactive platform designed to revolutionize Arabic language learning. It tackles the frustration of traditional textbooks by offering parallel texts where users can instantly see word meanings, transliterations, and grammar notes with a simple click or drag. Leveraging custom-trained LLMs for Egyptian and Moroccan dialects, it provides AI-generated stories and dialect-specific audio, enabling natural practice beyond standard Arabic.
Popularity
Points 1
Comments 0
What is this product?
ArabicFlow is an innovative open-source edtech platform that makes learning Arabic more intuitive and engaging. Instead of flipping back and forth in a textbook, you can interact directly with the Arabic text. Hover or click on any word, and its translation, pronunciation guide (transliteration), and relevant grammar details pop up immediately, all within the context of the sentence. This interactive approach keeps you focused and speeds up comprehension. A key innovation is its use of custom-trained Large Language Models (LLMs) specifically for Egyptian and Moroccan Arabic dialects. General AI models often struggle with these regional variations, but ArabicFlow's specialized LLMs ensure accurate and natural-sounding dialectal content. This means you're learning the Arabic people actually speak, not just formal written Arabic.
How to use it?
Developers can integrate ArabicFlow into their own learning applications or build new Arabic learning tools leveraging its core components. The platform provides an API that allows developers to fetch interactive text content, access dialect-specific audio, and even utilize the AI story generation capabilities. For end-users, it's as simple as visiting the web platform or any application that has integrated ArabicFlow. You'll experience a seamless learning environment where understanding is always at your fingertips. The open-source nature means developers can contribute to its growth, add new features, or tailor it for specific educational needs, fostering a collaborative ecosystem for Arabic language education.
Product Core Function
· Interactive Parallel Texts: Enables instant on-demand translation and grammar lookup for Arabic words within sentences, enhancing comprehension and reducing cognitive load for learners.
· AI-Generated Content: Creates dynamic stories and sentences in Arabic, providing learners with authentic and evolving practice materials that mirror real-world language use.
· Dialect-Specific LLMs: Utilizes custom-trained AI models for Egyptian and Moroccan Arabic dialects, ensuring accuracy and naturalness in translation and content generation for non-standard Arabic speakers.
· Dialect-Specific Audio: Offers accompanying audio for all content, featuring native pronunciation for specific Arabic dialects, crucial for developing listening comprehension and correct articulation.
· Open-Source Platform: Provides a foundation for community development and integration, allowing other developers to build upon or extend its capabilities, fostering wider adoption and innovation in Arabic edtech.
Product Usage Case
· An Arabic language student struggling with vocabulary retention in traditional textbooks can use ArabicFlow to instantly look up word meanings without breaking their reading flow, leading to faster progress and better retention.
· An edtech startup wanting to create a mobile app for learning Egyptian Arabic can integrate ArabicFlow's dialect-specific LLMs and audio features to provide authentic conversational practice, overcoming the limitations of general-purpose AI tools.
· A university linguistics department researching Arabic dialectal variations can utilize ArabicFlow's AI-generated content and custom LLMs to analyze and present nuanced linguistic patterns in a user-friendly, interactive format.
· A freelance Arabic tutor can embed ArabicFlow's interactive texts into their online lessons, offering students immediate clarification on grammar and vocabulary, making remote learning more effective and engaging.
· A developer interested in contributing to open-source educational tools can fork ArabicFlow, add support for another Arabic dialect, or build a gamified learning experience on top of its robust infrastructure, expanding its reach and impact.
76
GitHub FileStats Enhancer
Author
hacker_rob
Description
A browser extension that enriches the GitHub interface by displaying Lines of Code (LOC) for files and the number of child directories for directories directly within the file browser. This addresses the common need for quick, at-a-glance code size and project structure understanding without needing to clone or inspect individual files, offering immediate value to developers reviewing code or assessing project scope.
Popularity
Points 1
Comments 0
What is this product?
This project is a browser extension designed to overlay useful metadata onto the GitHub file explorer. The core innovation lies in its real-time computation and display of Lines of Code (LOC) for individual files and the count of immediate child items (files or subdirectories) for any given directory. It leverages browser extension APIs to hook into the DOM of GitHub pages, parse file and directory information, and then perform these calculations client-side. The value is in providing instant context about code volume and directory depth, which is normally hidden until a developer explicitly checks or clones the repository. This offers a significant time-saving and cognitive load reduction for developers browsing GitHub.
How to use it?
Developers can install this extension through their browser's extension store (e.g., Chrome Web Store, Firefox Add-ons). Once installed and activated for GitHub.com, as they navigate through repository file views, the extension will automatically render the LOC next to each file name and the child count next to each directory name. This integration is seamless; no manual configuration or command-line interaction is required. It's designed to work directly within the familiar GitHub UI, enhancing productivity during code reviews, project evaluations, or general exploration of open-source projects.
Product Core Function
· Display Lines of Code (LOC) for files: This feature provides immediate insight into the size of individual code files, helping developers quickly gauge the complexity or scope of a specific piece of code without needing to download or open the file. This is valuable for code review efficiency and understanding contribution sizes.
· Display child directory counts: This function shows the number of immediate subdirectories within any given directory, giving developers a quick sense of the branching depth or organizational structure of a repository. This aids in understanding project layout and complexity at a glance.
· Real-time, client-side computation: The extension calculates these statistics directly in the browser as the user navigates GitHub. This means no server-side processing is needed, ensuring low latency and immediate feedback. It's a clever use of available browser resources to enhance the user experience without impacting GitHub's infrastructure.
· Seamless GitHub integration: The extension injects this information directly into the existing GitHub file browser UI, making it feel like a native feature. Developers don't need to learn a new interface; they can benefit from the enhanced information within their familiar workflow.
Product Usage Case
· Code Reviewer assessing pull requests: A developer reviewing a pull request can quickly see the LOC of modified files, helping them prioritize review efforts and understand the scope of changes at a glance. This saves time from manually checking file sizes.
· Open-source Contributor evaluating projects: A developer exploring potential open-source projects to contribute to can get an immediate feel for the project's size and structure by looking at directory counts and file sizes across different modules. This helps in quickly identifying suitable areas for contribution.
· Technical Interviewer or Learner: Someone learning a new codebase or preparing for a technical interview can use this to get a quick understanding of the relative importance or size of different components within a project, aiding in faster comprehension.
· Project Manager or Tech Lead assessing codebase: A lead might use this extension to get a quick overview of the distribution of code across different directories to understand the project's architecture and identify potential areas of bloat or underdevelopment, all without cloning the repository.
77
LiquiDB: Universal DB Orchestrator
Author
grigoras
Description
LiquiDB is an open-source multi-database management tool designed to simplify developer workflows. It addresses the common challenge of interacting with diverse database systems by providing a unified interface and intelligent migration handling. The core innovation lies in its ability to abstract away the complexities of different database syntaxes and connection protocols, allowing developers to manage and migrate data across various SQL and NoSQL databases with ease.
Popularity
Points 1
Comments 0
What is this product?
LiquiDB is an open-source application that acts as a central hub for developers to interact with multiple database systems simultaneously. Instead of learning the unique commands and connection methods for each database (like PostgreSQL, MySQL, MongoDB, etc.), LiquiDB provides a single, consistent interface. Its key technical innovation is a sophisticated abstraction layer that translates developer commands into the specific syntax required by each underlying database. This allows for operations like schema creation, data querying, and, most importantly, database migrations, to be performed uniformly across different database types. This means if you need to move data from a PostgreSQL database to a MySQL database, LiquiDB can handle the translation and execution of the migration steps, saving significant development time and reducing the risk of errors.
How to use it?
Developers can use LiquiDB as a standalone desktop application or integrate it into their CI/CD pipelines. The typical workflow involves configuring connections to their various database instances within LiquiDB. Once connected, developers can execute SQL queries against any connected relational database, perform NoSQL operations on supported document databases, and manage schema changes and data migrations through a declarative migration system. For instance, when starting a new project that might evolve to use different database technologies, a developer can define their initial database schema and migrations within LiquiDB. If they later decide to switch from SQLite to PostgreSQL, LiquiDB can generate and execute the necessary migration scripts to transform the existing data, without requiring the developer to manually rewrite all the SQL.
Product Core Function
· Unified Database Connection Management: Connect to and manage multiple SQL and NoSQL databases from a single interface, abstracting away connection string complexities and offering consistent authentication. This is valuable because it reduces the cognitive load on developers, allowing them to focus on application logic rather than database specifics.
· Cross-Database Schema Migrations: Define and execute database schema changes and data migrations that are independent of the underlying database technology. LiquiDB intelligently handles the translation, enabling seamless transitions between different database systems. This is crucial for agile development, allowing projects to adapt to changing infrastructure needs without costly rework.
· Intelligent Query Translation: Execute queries that can be understood and optimized by different database systems. LiquiDB analyzes the query and generates database-specific versions, simplifying complex data retrieval across diverse data stores. This accelerates development by providing a consistent querying experience.
· Data Synchronization and Transformation: Facilitate the movement and transformation of data between different database types. This includes capabilities for one-time data dumps or ongoing synchronization tasks, solving the problem of integrating disparate data sources. Useful for migrating legacy systems or consolidating data.
· Developer-Centric Workflow Integration: Designed with developer productivity in mind, offering features like easy setup, intuitive UI, and CLI support for automation. This provides a practical tool that fits directly into existing development processes, enhancing efficiency.
Product Usage Case
· Scenario: A startup is building a web application and initially uses SQLite for its simplicity during development. They anticipate needing to scale to PostgreSQL for production. LiquiDB allows them to develop and test their database interactions against SQLite, then with a few configuration changes, seamlessly migrate their data and schema to PostgreSQL without rewriting their application's data access layer. This solves the problem of early-stage technology choices potentially hindering future growth.
· Scenario: A team is working on a microservices architecture where different services use different databases (e.g., one service uses MongoDB for flexible document storage, another uses Redis for caching, and a third uses MySQL for relational data). LiquiDB provides a centralized tool for the team to inspect, query, and manage all these databases from one place, streamlining debugging and operational tasks. This addresses the complexity of managing a polyglot persistence environment.
· Scenario: A developer needs to migrate a large dataset from a legacy MySQL database to a modern cloud-native database like CockroachDB for better scalability and resilience. LiquiDB can analyze the schema and data in MySQL, and then generate and execute the necessary migration scripts to transform and load the data into CockroachDB, minimizing downtime and manual effort. This solves the critical challenge of modernizing data infrastructure.
· Scenario: An application requires reporting that pulls data from both a transactional PostgreSQL database and a data warehouse like ClickHouse. LiquiDB can be used to query and potentially join data from these different sources, providing a unified view for reporting tools or further analysis, without requiring complex ETL pipelines for simple ad-hoc queries. This simplifies data access for analytical purposes.
78
Visuformer-Emotion
url
Author
kinderpingui
Description
A visual tool for designing and testing transformer architectures, with a novel integrated emotion analysis capability. It simplifies the complex process of building and iterating on transformer models, allowing users to experiment with different architectural choices and immediately see how they perform, especially in understanding nuanced human emotions within text.
Popularity
Points 1
Comments 0
What is this product?
Visuformer-Emotion is a sophisticated visual interface that empowers developers and researchers to design and experiment with transformer neural network architectures. Its core innovation lies in the seamless integration of emotion analysis, meaning you can not only build the 'brain' of a language model but also directly assess its ability to interpret and understand human sentiment. Think of it as a digital sandbox where you can drag and drop components to build a transformer, then feed it text and instantly get back an analysis of the emotions conveyed. This bypasses the often tedious and code-heavy process of setting up and evaluating such models from scratch, making cutting-edge AI accessible for more people.
How to use it?
Developers can use Visuformer-Emotion by accessing its intuitive graphical interface. You can select and connect different types of transformer layers (like attention mechanisms and feed-forward networks) to construct your desired architecture. Once the model is designed, you can input text data, and the tool will provide an emotion analysis report, indicating sentiments such as joy, sadness, anger, etc. This makes it incredibly useful for rapid prototyping, educational purposes, or for quickly evaluating the emotional intelligence of custom transformer models without needing to write extensive code for setup and data processing. It's designed for integration into existing workflows through its API or as a standalone platform for experimentation.
Product Core Function
· Visual Transformer Architecture Design: Allows users to build transformer models by interactively connecting predefined neural network blocks, simplifying complex model creation. The value is faster experimentation and easier understanding of how different components affect overall performance.
· Real-time Emotion Analysis Integration: Directly analyzes input text for emotional content within the designed transformer, providing insights into sentiment. This provides immediate feedback on the model's ability to understand nuances, crucial for applications dealing with human communication.
· Iterative Model Testing and Refinement: Enables users to quickly test design choices and observe their impact on emotion analysis results, facilitating a rapid development cycle. The value is in accelerating the discovery of optimal model configurations for specific tasks.
· Pre-configured Building Blocks: Offers a library of common transformer components (e.g., multi-head attention, positional encoding) to accelerate the design process. This saves developers time and reduces the cognitive load of remembering and implementing intricate details.
· Output Visualization of Emotion Detection: Presents emotion analysis results in an easily digestible format, such as charts or sentiment scores. This makes the AI's understanding understandable to a wider audience, not just AI experts.
Product Usage Case
· Scenario: A content creator wants to build a tool to automatically categorize customer feedback into positive, negative, or neutral sentiments with a focus on specific emotional nuances like 'frustration' or 'excitement'. Visuformer-Emotion allows them to visually design a transformer tuned for sentiment analysis and quickly test its performance on sample feedback, providing immediate insights into the model's effectiveness in identifying these specific emotions, saving significant development time.
· Scenario: An educator is teaching about deep learning and wants to provide students with a hands-on experience of building and understanding transformer models without requiring deep coding expertise. Visuformer-Emotion provides an interactive environment where students can visually construct architectures and see the direct impact on emotion analysis, making abstract concepts tangible and fostering a deeper learning experience.
· Scenario: A developer is working on a chatbot that needs to respond empathetically. They can use Visuformer-Emotion to design a transformer that not only understands the user's query but also accurately detects the user's emotional state, allowing the chatbot to tailor its responses more effectively. This directly addresses the technical problem of building emotionally aware conversational AI.
79
Java Pseudo-Data Forge
Author
barlogg
Description
A Java library for programmatically generating realistic, customizable fake data. It tackles the common developer challenge of needing diverse and representative datasets for testing, development, and demonstration purposes, especially in early-stage projects where real data might be scarce or sensitive. Its innovation lies in its flexible, rule-based generation engine that allows for complex data relationships.
Popularity
Points 1
Comments 0
What is this product?
Java Pseudo-Data Forge is a Java library designed to create artificial data that mimics real-world data. It's not just about spitting out random numbers; it's about generating data that adheres to specific patterns, types, and even interdependencies. For example, you can define that a 'user' record should have an 'age' that's realistic for an adult, and a 'city' that logically matches a 'country'. The core innovation is its expressive configuration system that allows developers to define these rules, making the generated data highly controllable and representative. This is incredibly useful for simulating various scenarios without relying on actual sensitive information or waiting for data pipelines to be ready.
How to use it?
Developers can integrate this library into their Java projects by including it as a dependency. Once added, they can then define data models and specify generation rules using a fluent API or configuration files. For instance, a developer might want to generate 100 fake customer records for a new e-commerce platform. They would configure the generator to create fields like 'firstName', 'lastName', 'emailAddress' (ensuring it's a valid email format), 'purchaseHistory' (perhaps a list of random product IDs), and 'registrationDate' (within a specific timeframe). The library then generates these records, which can be used for populating databases, running performance tests, or showcasing application features. This is incredibly useful for simulating real-world usage patterns and testing edge cases in a controlled environment.
Product Core Function
· Customizable Data Type Generation: Enables the creation of various data types such as strings, numbers, dates, booleans, and more, each with configurable constraints. This allows developers to generate data that precisely matches the expected types in their application, making testing more accurate.
· Rule-Based Data Relationships: Supports defining dependencies between data fields, ensuring generated data is logically consistent. For example, if generating addresses, a generated 'state' can be constrained to only appear within a valid 'country'. This is valuable for simulating realistic data structures and avoiding nonsensical data combinations during testing.
· Pattern Matching and Regular Expressions: Allows data generation to follow specific patterns or regular expressions, crucial for fields like phone numbers, postal codes, or unique identifiers. This ensures generated data conforms to real-world formats, essential for validation and integration testing.
· List and Collection Generation: Facilitates the generation of lists or collections of data, such as a list of product orders for a customer or a list of associated tags for an article. This is extremely useful for testing applications that handle complex, multi-item data structures.
· Data Distribution Control: Offers options to control the distribution of generated values (e.g., uniform, normal distribution) for numerical or date fields. This is important for performance testing and understanding how an application behaves under different data load characteristics.
Product Usage Case
· Populating a new e-commerce database with thousands of realistic user profiles, product listings, and order histories to test backend performance and business logic before going live.
· Creating synthetic datasets for machine learning model training where real-world data is limited or privacy-sensitive, ensuring the model learns from diverse and representative examples.
· Developing and testing APIs that consume or produce complex JSON payloads, by generating varied and valid input/output structures to ensure robustness and error handling.
· Building interactive demos or prototypes that require realistic data to showcase functionality without the overhead of setting up a full data backend or using sensitive production data.
· Simulating concurrent user actions by generating a large volume of user interactions (e.g., clicks, form submissions) to stress-test application scalability and identify potential bottlenecks.
80
DataStructuresMasterPro
Author
shhabmlkawy
Description
A comprehensive 1600-page data structures book featuring 130 original, academic-style problems with complete solutions, proofs, amortized analysis, diagrams, and detailed explanations. It includes two novel data structures: the Layered Summary Heap (LSH) and the Triple-L Heap, designed for advanced university learning, engineer self-study, and technical interview preparation.
Popularity
Points 1
Comments 0
What is this product?
This project is an extensive data structures book aimed at deepening understanding of fundamental and advanced concepts. It goes beyond typical textbook material by offering 130 unique, rigorously explained problems, often mirroring the complexity of technical interview challenges. The innovation lies not only in the breadth and depth of coverage but also in the inclusion of two newly designed data structures, the Layered Summary Heap (LSH) and the Triple-L Heap. These new structures offer potential for more efficient problem-solving in specific scenarios, pushing the boundaries of current data structure knowledge. So, what's in it for you? It's a definitive resource to master data structures, gain an edge in technical interviews, and explore cutting-edge algorithmic ideas.
How to use it?
Developers can use this book as a primary learning resource for advanced data structures courses, a self-study guide for professional development, or a targeted preparation tool for technical interviews. Each problem is presented with full solutions, including proofs and amortized analysis, allowing for deep dives into algorithmic efficiency. The inclusion of diagrams aids visual understanding. For those interested in the latest research, the new LSH and Triple-L Heap structures can be studied for their design principles and potential applications. Integrations would involve applying the learned principles and algorithms to real-world software development challenges, optimizing code performance, and designing more efficient systems. So, how do you use it? You read it, you solve the problems, and you apply the knowledge to build better software.
Product Core Function
· 130 Original Academic-Style Problems: Provides a vast collection of unique challenges to test and improve understanding of data structures, going beyond standard textbook examples. This is useful for sharpening problem-solving skills and preparing for complex coding scenarios.
· Complete Solutions and Proofs: Offers detailed step-by-step solutions, including mathematical proofs and amortized analysis for each problem, enabling a thorough grasp of algorithmic correctness and efficiency. This helps in writing robust and performant code.
· Amortized Analysis: Explains the average-case performance of algorithms over a sequence of operations, crucial for understanding efficiency in dynamic scenarios. This knowledge is key to optimizing long-running processes and resource-intensive applications.
· Inclusion of Novel Data Structures (LSH and Triple-L Heap): Introduces two self-designed data structures, offering new ways to approach specific problems and potentially leading to performance improvements. This is valuable for engineers looking for innovative solutions and pushing performance limits.
· Diagrams and Detailed Explanations: Utilizes visual aids and comprehensive text to clarify complex concepts, making abstract ideas more concrete and easier to learn. This aids in understanding intricate algorithms and data manipulation.
· Technical Interview Preparation Focus: Many problems are designed to resemble real-world technical interview questions, providing targeted practice for aspiring and experienced software engineers. This directly helps in landing jobs at top tech companies.
Product Usage Case
· A software engineer preparing for interviews at a top-tier tech company can use the book to practice problems related to heaps, trees, and hashing, mimicking the types of questions asked in interviews. This addresses the need for targeted interview preparation and boosts confidence.
· A university student in an advanced data structures course can refer to the book for in-depth explanations and proofs of complex algorithms like those involving union-find or RMQ (Range Minimum Query), deepening their theoretical understanding. This helps in achieving academic excellence and building a strong foundation.
· A seasoned developer facing performance bottlenecks in a system involving frequent data updates and queries could study the new Layered Summary Heap (LSH) or Triple-L Heap structures. By understanding their design, they might find a more efficient data management approach for their specific use case. This solves the problem of optimizing existing systems.
· A hobbyist programmer wanting to gain a deeper understanding of algorithmic complexity beyond superficial knowledge can work through the problems, focusing on the amortized analysis. This enhances their ability to write more efficient and scalable code for personal projects. This answers the 'why is this useful for me?' by providing practical coding improvements.
81
Wegent-Cloud-AI-Dev-Platform
Author
qdaxb
Description
Wegent is an open-source cloud coding agent platform that allows developers to define and run AI agent teams using YAML configurations. It leverages multiple execution engines like Agno and Claude, supports both dialogue and coding modes, and provides isolated sandbox environments for simultaneous execution. The platform facilitates advanced collaboration patterns for complex tasks and integrates with code services for AI-driven development workflows.
Popularity
Points 1
Comments 0
What is this product?
Wegent is an open-source platform designed to empower developers by orchestrating AI agents in the cloud for coding and knowledge-discovery tasks. Its core innovation lies in its 'configuration-driven' approach, meaning you define what your AI agent team should do using simple YAML files and a web interface, rather than needing to write custom code for each new task. It supports diverse AI 'brains' (like Agno and Claude) and allows these teams to work together using different collaboration styles (e.g., everyone working at once, or one leader directing others). Crucially, each team operates in its own secure 'sandbox,' so you can run many different agent teams at the same time without them interfering with each other. This means you get a flexible, scalable, and safe way to harness AI for complex software development and information retrieval.
How to use it?
Developers can use Wegent by defining their agent team's behavior and goals in YAML configuration files. These files specify the agents involved, their roles, the execution flow, and the AI models they should use. The web UI provides an easy way to manage and launch these teams. For coding tasks, Wegent integrates with services like GitHub and GitLab, enabling AI-powered code generation, review, and debugging. For dialogue-based tasks, like gathering insights from news articles or retrieving specific information, developers can set up agent teams to collaborate in various modes to efficiently process and summarize information. The platform's sandbox feature ensures that multiple, distinct workflows can run concurrently without conflict, making it ideal for managing diverse development projects or research tasks.
Product Core Function
· Configuration-Driven Agent Teams: Define and manage personalized AI agent teams using YAML and a web UI. This allows for flexible and repeatable workflows without custom coding, meaning you can quickly set up AI to help with specific tasks.
· Multi Execution Engines (Agno, Claude): Supports various underlying AI models for both conversational and coding tasks. This provides flexibility in choosing the best AI 'brain' for your specific problem, meaning your AI can be tailored for optimal performance.
· Isolated Sandbox Environments: Each agent team runs in its own secure space, allowing multiple teams to operate simultaneously. This ensures stability and prevents interference, meaning you can run many AI experiments or workflows at once without issues.
· Advanced Collaboration Modes (Parallel, Leader-based): Enables agents within a team to work together in structured ways for complex tasks. This means AI teams can tackle intricate problems more effectively by coordinating their efforts, leading to better results.
· AI Coding Integration (GitHub/GitLab): Connects with code repositories for AI-driven development workflows like code generation, review, and automated testing. This directly boosts developer productivity by automating repetitive or complex coding tasks.
Product Usage Case
· Automated Code Refactoring: A developer needs to refactor a large codebase for better maintainability. They can configure an agent team in Wegent to analyze the code, identify areas for improvement, propose refactored code snippets, and even automatically create pull requests on GitHub. This saves significant manual effort and time for developers.
· Market Research and Insight Generation: A product manager needs to gather insights on a new market trend from various news sources and competitor websites. They can set up a dialogue-mode agent team in Wegent to crawl these sources, extract relevant information, synthesize findings, and present a concise summary. This provides quick, data-driven insights for strategic decisions.
· Bug Triage and Resolution Assistance: A QA team is overwhelmed with bug reports. A Wegent agent team can be configured to analyze incoming bug reports, classify their severity, assign them to appropriate developers, and even suggest potential solutions based on historical data and code analysis. This streamlines the bug management process and accelerates issue resolution.
· AI-Assisted Feature Development: A startup wants to quickly prototype a new feature. They can use Wegent to create an agent team that helps with generating boilerplate code, writing unit tests, and even drafting documentation based on feature descriptions. This dramatically speeds up the initial development phase.
82
Quantum Alpha Builder
url
Author
Hellene
Description
This project pioneers the use of quantum computing to democratize stock portfolio creation. It enables users to construct investment portfolios in seconds, without needing prior financial expertise. The core innovation lies in leveraging quantum algorithms to explore vast combinatorial possibilities for optimal asset allocation, a task computationally prohibitive for classical computers.
Popularity
Points 1
Comments 0
What is this product?
Quantum Alpha Builder is a revolutionary platform that harnesses the power of quantum computing to build stock investment portfolios. Instead of relying on traditional, time-consuming financial analysis, it uses quantum algorithms to rapidly assess a multitude of potential stock combinations and identify those that are most likely to achieve desired investment goals (like maximizing returns or minimizing risk). The innovation is in applying quantum annealing or gate-based quantum computation to solve the complex optimization problem of portfolio diversification and selection. This means it can explore more scenarios faster and find better solutions than classical methods.
How to use it?
Developers can integrate Quantum Alpha Builder into their applications or use it as a standalone service. The typical usage involves defining investment parameters (e.g., risk tolerance, desired return, specific sectors to include/exclude) and then submitting these parameters to the quantum optimizer. The output is a highly optimized portfolio of stocks. For developers, this could mean building a new generation of FinTech apps that offer unparalleled investment optimization capabilities to their end-users, or integrating this powerful backend into existing trading platforms.
Product Core Function
· Quantum Portfolio Optimization: Leverages quantum algorithms (e.g., QAOA, VQE, or annealing) to find optimal asset allocations by exploring a vast solution space. This delivers portfolios that are theoretically superior to those found by classical heuristics, offering potentially higher returns or lower risk for the same investment.
· Seconds-to-Portfolio Generation: Achieves near-instantaneous portfolio creation through the inherent speed advantage of quantum computation for certain optimization problems. This drastically reduces the time traditionally required for investment analysis and construction, making sophisticated strategies accessible quickly.
· No-Code Financial Insight: Abstracts away the complexity of quantum computing and financial modeling, allowing users with no technical or financial background to generate sophisticated investment strategies. This democratizes access to advanced investment tools.
· Customizable Investment Parameters: Allows users to define specific investment objectives, risk appetites, and constraints, ensuring the generated portfolio aligns with individual needs. This provides tailored solutions, making the quantum optimization relevant and practical for a wide range of users.
Product Usage Case
· A FinTech startup wants to build a mobile app that offers personalized, ultra-fast investment advice. Using Quantum Alpha Builder, they can provide users with a quantum-optimized portfolio in seconds, directly from their phone, solving the problem of slow and complex traditional investment advice and offering a competitive edge.
· An investment firm is looking to enhance its existing trading platform with advanced analytics. They can integrate Quantum Alpha Builder's API to offer their clients portfolios that are optimized using quantum computing, solving the challenge of finding the absolute best allocation strategies in a rapidly changing market and improving client outcomes.
· A hobbyist investor wants to experiment with cutting-edge investment strategies without hiring a financial advisor. They can use Quantum Alpha Builder as a tool to quickly generate and test various quantum-optimized portfolios, solving the problem of limited access to sophisticated financial tools and enabling hands-on learning.
83
Journiv Privacy-First Journal
Author
swalabtech
Description
Journiv is a self-hosted, privacy-focused journaling application that aims to be a modern alternative to services like Day One or Apple Journal. It emphasizes data ownership and user control by allowing users to host it themselves. Key features include mood tracking, daily prompts, and insightful analytics, all designed to provide a distraction-free writing experience while keeping personal memories secure and private.
Popularity
Points 1
Comments 0
What is this product?
Journiv is a self-hosted journaling application built with a strong emphasis on privacy and data ownership. Unlike cloud-based journaling apps where your data is stored on someone else's servers, Journiv allows you to host it on your own hardware, giving you complete control over your personal entries and memories. The core technology involves a backend service (likely a web application) that manages your journal entries, mood data, and prompt generation, paired with a frontend interface for writing and viewing. The innovation lies in its commitment to being a modern, feature-rich, and truly private journaling solution that you can own, rather than rent, effectively addressing the concern of data sovereignty for personal reflections.
How to use it?
Developers can use Journiv by deploying it on their own infrastructure, typically using Docker for ease of setup. This involves pulling the Docker image and running it on a server or a personal computer. Once deployed, users access Journiv through a web browser. For developers interested in contributing or extending its functionality, the project is open-source on GitHub. They can clone the repository, set up the development environment (likely involving Node.js or similar web development stacks), and begin modifying the code. The self-hosted nature means developers can integrate it with other self-hosted services or build custom automation around their journal data, for example, triggering backups or analyses.
Product Core Function
· Self-hosted deployment: Enables users to run the journaling app on their own servers, ensuring complete data privacy and control. This means your personal thoughts are not stored by a third party, offering peace of mind and data ownership.
· Privacy-first design: All journal entries, mood data, and personal insights are stored locally or on the user's chosen server, preventing external access and data breaches. This is crucial for sensitive personal reflections.
· Mood tracking: Allows users to log their mood alongside journal entries, providing a visual and analytical way to understand emotional patterns over time. This helps in self-reflection and identifying triggers.
· Daily prompts: Offers curated prompts to inspire writing and overcome writer's block, making journaling a consistent and engaging habit. This feature helps to kickstart reflection and explore different facets of one's life.
· Meaningful insights: Analyzes journal entries and mood data to provide users with personalized insights and trends. This offers a deeper understanding of one's own thoughts, feelings, and experiences.
· Clean and minimal interface: Designed for a distraction-free writing experience, focusing on the content and the act of reflection. This ensures that the writing process is smooth and focused.
· Docker-hostable: Simplifies the deployment process for users, allowing for easy installation and management of the application on various server environments. This makes getting started with self-hosting much more accessible.
Product Usage Case
· A privacy-conscious individual who wants to document their life journey without relying on cloud services. They can self-host Journiv on a Raspberry Pi at home, ensuring their memories are always accessible and private, solving the problem of data security for personal archives.
· A therapist or mental health professional looking for a secure way for clients to journal between sessions. By recommending a self-hosted Journiv, they can ensure client privacy and confidentiality, addressing the need for secure and private therapeutic tools.
· A software engineer who wants to track their personal growth and learnings from side projects. They can integrate Journiv with their development workflow, perhaps using scripts to automatically log project milestones or challenges, enhancing their personal productivity and reflection.
· A content creator who wants to brainstorm ideas and keep a private diary of their creative process. Self-hosting Journiv provides a secure sandbox for their thoughts, free from external algorithms or data collection, protecting their intellectual property.
· An individual experiencing anxiety or depression who wants to monitor their emotional state and identify patterns. The mood tracking and insight features of Journiv can help them visualize their progress and understand their triggers, providing a tool for self-management.
84
Intent-Driven Lead & Content Synthesizer
Author
elephantisfast
Description
This project leverages AI to identify potential customers based on your desired outcome and generates viral content inspired by Reddit trends. It tackles the challenge of finding the right leads and creating engaging content efficiently.
Popularity
Points 1
Comments 0
What is this product?
This is an AI-powered tool that analyzes user intent to find ideal leads and generates content patterns that are likely to go viral. For lead generation, you describe the type of customer you're looking for, and it uses keywords and other signals to find them. For content creation, it analyzes top-performing Reddit posts within a chosen topic to understand what makes them popular and helps you craft similar content. This is valuable because it automates and optimizes two time-consuming aspects of business growth: finding customers and creating engaging material.
How to use it?
Developers can integrate this tool into their sales and marketing workflows. For lead generation, you would input a clear description of your target customer (e.g., 'SaaS companies in the fintech space looking for a new CRM'). The tool then surfaces a list of matching leads. For content writing, you select a topic (e.g., 'AI in healthcare'), and the tool provides insights and draft content based on trending Reddit discussions. This can be used for automated outreach, personalized marketing campaigns, or to quickly brainstorm blog posts and social media updates.
Product Core Function
· AI-powered lead identification: Utilizes natural language processing and signal analysis to match your lead criteria with potential customers, significantly reducing manual search time.
· Intent-based lead matching: Goes beyond simple keyword matching by understanding the underlying goal you have for your leads, leading to more relevant and high-quality prospects.
· Reddit trend analysis for content: Analyzes viral patterns in popular Reddit posts to understand audience engagement drivers, providing a data-backed approach to content strategy.
· Pattern-based content generation: Assists in writing content by mimicking successful structures and themes found on Reddit, increasing the likelihood of virality and audience resonance.
· Cross-platform content applicability: Leverages the insight that successful Reddit content often translates to other platforms, making the generated content adaptable for various channels.
Product Usage Case
· A startup founder needs to find early adopters for their new productivity app. They describe their ideal user ('developers looking for tools to manage personal projects') and the tool quickly provides a list of relevant individuals or companies, saving hours of manual searching.
· A marketing team wants to create a blog post about the latest trends in renewable energy. They input 'renewable energy' as a topic, and the tool analyzes popular Reddit discussions, highlighting key themes and discussion points that resonate with the audience, helping them draft a more engaging and relevant article.
· A sales representative wants to identify businesses that might be interested in their cybersecurity solution. They specify their target (e.g., 'e-commerce businesses experiencing frequent phishing attacks') and the tool identifies potential leads with publicly available signals indicating this need, streamlining the outreach process.
· A content creator wants to generate social media updates about emerging AI technologies. The tool analyzes trending AI discussions on Reddit and provides catchy headlines and content ideas that are already proven to capture attention, accelerating their content production.
85
GoLang Multi-Tenant Agent SDK
Author
tech-aguirre
Description
This project offers an open-source SDK built in GoLang for creating multi-tenant agents. It addresses the common challenge of managing separate environments or user data within a single application instance, without relying on Python. The innovation lies in providing a robust, Go-native framework to isolate and manage these tenants efficiently.
Popularity
Points 1
Comments 0
What is this product?
This is a Software Development Kit (SDK) written in Go. Think of it as a toolbox for developers who are building applications that need to serve multiple distinct customers or groups (tenants) from a single codebase. Normally, managing this separation can be complex, involving intricate database schemas or separate deployments. This SDK provides pre-built components and patterns to make this isolation seamless. The core innovation is its GoLang implementation, offering performance and idiomatic Go development for multi-tenancy, bypassing the need for other languages like Python, which might be less performant or harder to integrate in a Go ecosystem. So, this helps you build scalable and secure applications that can host many users or businesses independently, all from one application, without the usual headaches.
How to use it?
Developers can integrate this GoLang SDK into their existing or new Go applications. It acts as a foundational layer for handling tenant-specific logic, data, and configurations. You would typically initialize the SDK and then use its provided interfaces and functions to access tenant-aware services. For example, when a request comes in, the SDK can help identify which tenant the request belongs to and ensure that all subsequent operations are scoped to that tenant's data. This means you can build features that are inherently secure and isolated for each customer. So, this helps you quickly build complex multi-tenant systems in Go, saving you time and reducing the risk of data leaks between tenants.
Product Core Function
· Tenant Identification: Provides mechanisms to automatically detect and identify the current tenant based on request parameters (like subdomains, headers, or API keys), ensuring that all subsequent operations are correctly scoped. The value is enabling secure and automatic data segregation. This is useful in any multi-user or multi-organization application.
· Data Isolation: Offers strategies and utilities to ensure that data for one tenant is completely separate from another, often through database sharding or scoped queries. The value is preventing data breaches and ensuring compliance. This is crucial for SaaS applications and platforms.
· Configuration Management: Allows for tenant-specific configurations to be loaded and applied dynamically, enabling customization per tenant without modifying core application code. The value is offering flexibility and easy customization for individual clients. This is great for platforms that need to offer unique settings to different users.
· Resource Scoping: Ensures that any resources (like files or caches) are also isolated per tenant, preventing cross-tenant access and interference. The value is maintaining a clean and secure environment for each tenant. This is important for applications handling user-uploaded content or shared resources.
Product Usage Case
· Building a SaaS CRM: A developer needs to build a Customer Relationship Management system for multiple businesses. Using this SDK, they can ensure that each business's customer data, deals, and notes are completely separate, even though they are all using the same application instance. This solves the problem of data privacy and security for each business client.
· Developing a Multi-Organization Project Management Tool: For a tool that helps different companies manage their projects, this SDK can be used to isolate project data, user permissions, and team structures for each organization. This prevents accidental data sharing between competing companies using the same platform. This solves the problem of complex access control and data segregation in a shared environment.
· Creating a White-Label E-commerce Platform: A developer wants to offer a customizable e-commerce solution to various clients. The SDK can manage tenant-specific branding, product catalogs, and order processing, ensuring each client's storefront is unique and their data is secure. This addresses the need for efficient customization and secure data management in a scalable platform.
· Implementing a Shared Backend for Mobile Apps: For a service powering multiple mobile applications for different clients, this SDK can manage tenant-specific user accounts, settings, and application data. This allows for a single, efficient backend infrastructure serving multiple distinct apps without data leakage. This solves the challenge of managing shared backend resources for diverse client applications.
86
Parenthesis Puzzler
Author
smatthewaf
Description
This project explores multiple innovative approaches to solving the 'Valid Parenthesis' problem, a common programming challenge. It goes beyond a single, straightforward solution by demonstrating diverse techniques, including algorithmic thinking, data structure utilization, and potentially even domain-specific optimizations, offering a comprehensive understanding of how to tackle this problem from various angles.
Popularity
Points 1
Comments 0
What is this product?
This project is a deep dive into the 'Valid Parenthesis' problem, a classic computer science puzzle. It presents four distinct solutions, each showcasing different programming paradigms and data structures. The innovation lies not just in finding *a* solution, but in exploring *multiple* efficient and elegant ways to solve it, highlighting the power of algorithmic thinking and problem decomposition. For developers, this means understanding that even seemingly simple problems can have rich, multifaceted solutions, fostering a deeper appreciation for computational logic.
How to use it?
Developers can use this project as a learning resource to understand different algorithmic strategies for parsing and validating structured data. Each solution can be integrated into a larger application where parenthesis balancing is critical, such as parsing code, validating configuration files, or processing mathematical expressions. The project provides ready-to-use code examples that can be adapted and tested, accelerating development and improving code quality in scenarios requiring robust syntax checking.
Product Core Function
· Stack-based Parenthesis Validation: Leverages the LIFO (Last-In, First-Out) property of stacks to efficiently match opening and closing parentheses. This is valuable for ensuring that nested structures are correctly ordered, crucial for parsing any language or data format.
· Recursive Parenthesis Checking: Employs recursion to break down the problem into smaller, self-similar sub-problems. This offers an elegant, often more readable solution for understanding structural relationships, beneficial for complex hierarchical data validation.
· Iterative String Traversal with State Tracking: Utilizes a loop and state variables to track the balance of parentheses without explicit auxiliary data structures. This approach emphasizes efficiency in terms of memory usage, ideal for scenarios with strict resource constraints.
· Optimized Pattern Matching: Potentially explores more advanced string manipulation or regular expression techniques for a concise and performant solution. This highlights the power of leveraging built-in language features for rapid problem-solving.
Product Usage Case
· Validating Syntax in a Custom Programming Language: When building a compiler or interpreter for a new programming language, ensuring that all opening braces, brackets, and parentheses are correctly matched is fundamental. This project provides the core logic for such validation, ensuring syntactical correctness.
· Parsing and Validating Configuration Files: Many configuration file formats use nested structures or delimiters that require balanced pairing. Using the techniques from this project, developers can reliably parse and validate these files, preventing application errors due to malformed configurations.
· Processing Mathematical Expressions: In applications that evaluate mathematical formulas, correctly identifying and balancing parentheses is essential for operator precedence and expression integrity. This project offers foundational algorithms for such processing.
· Developing a Text Editor with Real-time Syntax Highlighting: For a text editor that highlights programming code, checking parenthesis balance in real-time is key to providing accurate feedback to the user. The efficient algorithms presented can be adapted for this purpose.
87
Shelly Systems: Code-Driven Process Modeling
Author
chrisshella2
Description
Shelly Systems is a novel approach to process and system modeling. It allows users to define complex processes and systems using YAML, a human-readable data format, while incorporating spreadsheet-like formulas for dynamic behavior and data analysis. The core innovation lies in its ability to generate visual flowcharts directly from this code, offering a single source of truth for system design and documentation that is easily maintainable and adaptable. This addresses the common pain point of manually creating and updating intricate diagrams in rapidly evolving systems.
Popularity
Points 1
Comments 0
What is this product?
Shelly Systems is a system for modeling processes and systems where the 'code' is written in YAML, similar to how you might define configurations for software. The truly innovative part is that this YAML can include spreadsheet-like formulas. Think of it like telling your system's blueprint not just what things are, but how they should behave or calculate values, much like an Excel sheet. It then takes this structured YAML and automatically generates visual flowcharts. This means you're not just drawing boxes and arrows; you're defining the logic and relationships in a way that a computer can understand and visualize, creating a definitive, up-to-date representation of your system.
How to use it?
Developers can use Shelly Systems by writing their process or system logic in YAML files. These files can define nodes (representing steps or components), transitions between them, and importantly, include formulas for data manipulation or conditional logic, much like you'd use in a spreadsheet. For example, you could define a step that calculates shipping costs based on weight and destination using a formula. These YAML definitions can then be used to automatically generate flowcharts, providing a clear visual representation of the entire system. This is particularly useful for complex workflows, business logic, or even software architecture diagrams where consistency and up-to-date documentation are crucial. The project can be integrated into CI/CD pipelines to automatically generate or update diagrams whenever the underlying code changes, ensuring documentation always matches reality.
Product Core Function
· YAML-based process definition: Enables developers to define complex systems and processes in a structured, human-readable format. This provides a single source of truth for system logic, reducing ambiguity and making collaboration easier. So, instead of trying to remember intricate steps, you have it all documented clearly.
· Spreadsheet-like formulas: Allows for dynamic calculations and conditional logic within the process definitions. This means your models can adapt and respond to changing data or scenarios, making them more powerful and realistic. This is useful for automating calculations or decision-making within your visualized processes.
· Automated flowchart generation: Translates the YAML definitions and formulas into visual flowcharts. This eliminates the tedious manual effort of drawing diagrams and ensures that the visual representation always accurately reflects the defined logic. This saves a significant amount of time and reduces errors in documentation.
· Single source of truth for documentation: By deriving diagrams directly from code, Shelly Systems ensures that the documentation is always synchronized with the actual system or process. This is invaluable for maintaining complex systems and onboarding new team members. You always know your diagrams are current and correct.
Product Usage Case
· Modeling a complex e-commerce checkout process: A developer can use Shelly Systems to define all the steps, conditional logic (e.g., applying discounts based on user type), and data transformations (e.g., calculating tax based on location) in YAML. The system then generates a flowchart of the entire checkout flow, which can be used for code reviews, testing, or explaining the process to stakeholders. This helps in identifying potential bottlenecks or edge cases in the checkout flow.
· Documenting API request/response workflows: For microservices architecture, a developer can model the sequence of API calls, data mapping between services, and error handling logic using Shelly Systems. The generated flowcharts offer a clear overview of inter-service communication, aiding in debugging and understanding system interactions. This makes it easier to grasp how different parts of the system talk to each other.
· Designing business logic for backend services: Before writing code, a product manager or engineer can outline complex business rules and decision trees in Shelly Systems. The visual output helps in validating the logic with non-technical stakeholders and serves as a detailed specification for the development team. This ensures everyone understands the intended business logic before coding begins.
88
SuperCurate: CognitiveArchive Engine
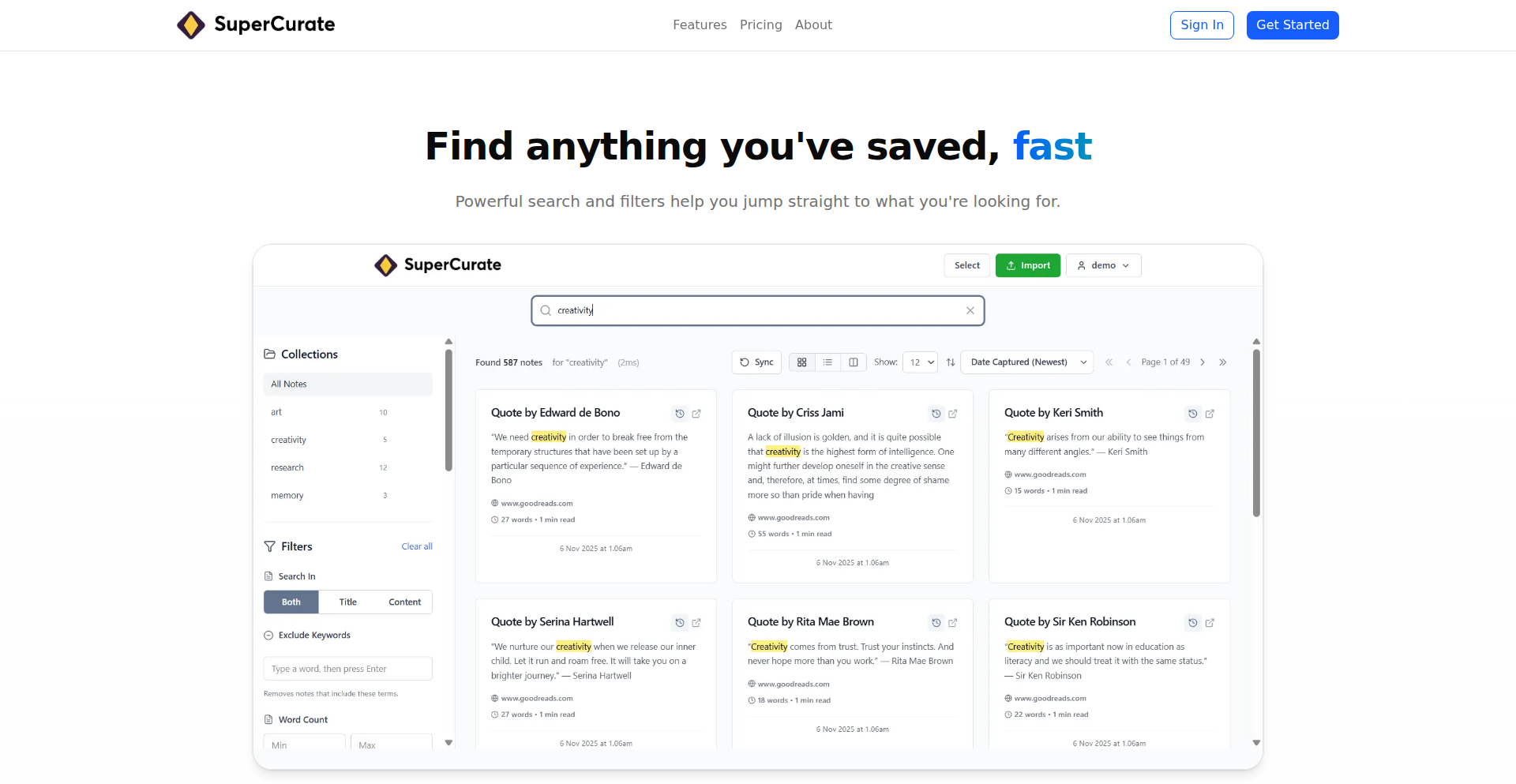
Author
superdocs1
Description
SuperCurate is a personal knowledge management tool that functions like a digital filing cabinet for your notes, web clippings, images, and PDFs. It tackles the problem of information overload by providing fast, filtered search, content organization into collections, and the innovative ability to search *inside* PDF documents, even highlighting and jumping to specific pages. This means you spend less time hunting for information and more time using it.
Popularity
Points 1
Comments 0
What is this product?
SuperCurate is a sophisticated system designed to help you manage and retrieve your personal information effortlessly. At its core, it employs advanced indexing techniques to make searching through various file types, including text notes, web captures, images, and PDFs, incredibly fast. The innovation lies in its deep PDF search capability, which goes beyond simple file naming to understand and index the text content within PDFs. This allows for precise retrieval and immediate navigation to the exact piece of information you need, solving the frustration of sifting through lengthy documents. So, it's a super-powered brain extension for your digital life.
How to use it?
Developers can integrate SuperCurate into their workflows by using its built-in import features for common formats like Evernote ENEX, Markdown, PDFs, and images. The SuperCurate Web Clipper, a Chrome extension, allows for one-click saving of web content directly into your curated library. For more advanced integration, imagine building custom tools that query your SuperCurate library to enrich applications with relevant personal knowledge. For instance, a developer could create a script to automatically pull relevant design assets or research papers based on a project's keywords, all powered by SuperCurate's fast search. This gives developers a readily accessible, organized repository of their digital resources.
Product Core Function
· Fast, filtered search: Quickly locate any note or file using powerful search operators, saving you time and mental effort in finding what you need.
· Content organization into collections: Structure your information logically, making it easy to browse and retrieve related items, improving your workflow and decision-making.
· Import from multiple formats: Seamlessly bring your existing notes, web clippings, and documents into one unified system, consolidating your knowledge base.
· Search inside PDFs with highlighting and page jumping: Access specific information within PDF documents instantly, eliminating the need to manually scan long texts and boosting your research efficiency.
· Web Clipper extension: Capture web content directly into your library with a single click, ensuring no valuable insights are lost and making information gathering seamless.
Product Usage Case
· A freelance writer uses SuperCurate to store all their research articles and notes. When working on a new piece, they can quickly search for specific quotes or data points across hundreds of PDFs and web clippings, dramatically speeding up their writing process.
· A software developer imports all their technical documentation, tutorials, and personal code snippets into SuperCurate. When encountering a problem, they can instantly search for solutions or examples within their past findings, reducing debugging time and improving coding speed.
· A student organizing lecture notes and research papers can use SuperCurate to find specific concepts or definitions within their imported PDFs. The ability to jump directly to the relevant page saves them hours of study time during exam preparation.
· A designer uses the web clipper to save inspirational images and articles. Later, they can easily search for specific styles or themes within their saved clippings to quickly reference ideas for new projects.
89
TrailerFlow
Author
naimurhasanrwd
Description
TrailerFlow is a browser extension that streamlines the movie discovery process. It directly addresses the pain point of manually searching for movie trailers by allowing users to right-click on any movie title on any webpage and instantly watch the trailer in a popup window. This eliminates the need for tab switching and manual searches, saving valuable time and enhancing the browsing experience, especially for those with limited free time or who aren't avid movie buffs.
Popularity
Points 1
Comments 0
What is this product?
TrailerFlow is a browser extension that acts as a smart movie trailer assistant. The core innovation lies in its ability to detect movie titles on any webpage, even those that typically prevent right-click actions, and then seamlessly pull and display the corresponding trailer in a convenient popup. It leverages background scripting and potentially web scraping techniques to identify movie titles and then interfaces with YouTube's API (or similar video platforms) to fetch and embed the trailer, creating a friction-free viewing experience. The clever part is its adaptability, working even on sites that try to block this kind of interaction, and offering a manual search fallback.
How to use it?
To use TrailerFlow, simply install it as a browser extension. When you encounter a movie title on a website (like a streaming service's catalog, a blog post, or a news article), you can right-click on the title. A context menu will appear with an option to 'Watch Trailer'. Clicking this will open a small popup window showing the trailer. If a website disables normal right-clicking, you can usually achieve the same result by holding down the Alt or Option key while right-clicking. There's also a manual search option available by clicking the extension's icon in your browser toolbar, which is useful if automatic detection fails or for initiating a search directly.
Product Core Function
· Instant Trailer Playback: Detects movie titles on any webpage and displays trailers in a popup. This solves the problem of needing to manually search for trailers, saving time and effort for users trying to decide on a movie.
· Cross-Site Compatibility: Works on various websites, including those that disable right-click functionality, ensuring a consistent experience. This addresses the frustration of common web limitations that hinder user interaction.
· Seamless Integration: Integrates directly into the browser's context menu, making it intuitive and easy to access without disrupting the browsing flow. This means users don't have to learn new interfaces or complex commands.
· Manual Search Option: Provides a fallback for automatic detection, allowing users to search for trailers manually via the extension icon. This ensures functionality even in edge cases and provides more control to the user.
Product Usage Case
· A user browsing a local streaming service's website that lacks trailer previews. Instead of copying titles and searching YouTube, they can right-click a movie title and watch the trailer instantly in a popup, making a quick decision on whether to watch it.
· A tech blogger writing about upcoming movies. Readers can right-click the movie titles mentioned in the article and immediately see the trailers without leaving the blog post, enhancing engagement and providing immediate value.
· A user on a movie review site encountering a film they've never heard of. They can right-click the title and watch the trailer to gauge their interest, preventing wasted time on movies they might not enjoy.
· Someone encountering a website that actively tries to prevent right-clicking. TrailerFlow's Alt/Option key workaround allows them to still access the trailer functionality, demonstrating its robust problem-solving approach.
90
TeslaPassengerStream
Author
tesladrivewatch
Description
A free, until 2026, platform for passengers in Tesla vehicles to stream YouTube and other videos directly on the car's screen, addressing the boredom of long drives with an innovative in-car entertainment solution. The core technical innovation lies in its seamless integration and user-friendly interface designed specifically for the Tesla ecosystem.
Popularity
Points 1
Comments 0
What is this product?
TeslaPassengerStream is a specialized software solution that allows Tesla passengers to watch videos from platforms like YouTube directly on the car's infotainment screen. The underlying technology cleverly leverages the car's existing connectivity and display capabilities to create an engaging entertainment experience. The innovation is in packaging this functionality into an easy-to-use application that respects Tesla's in-car user interface guidelines, offering a delightful distraction for occupants without compromising the driver's focus.
How to use it?
For Tesla owners, using TeslaPassengerStream is straightforward. Once installed (likely through a simple process that might involve sideloading or a specific Tesla-compatible app store if one becomes available), passengers can access the platform via the car's main touchscreen. They would then be able to search for videos, select content, and enjoy playback. The system is designed to work seamlessly, much like any other built-in Tesla feature, making it intuitive for non-technical users to operate.
Product Core Function
· In-car video streaming: Enables passengers to watch YouTube and other video content on the Tesla's main screen, turning travel time into entertainment time.
· Intuitive user interface: Designed to be simple and easy for passengers to navigate and control, minimizing distractions and maximizing enjoyment.
· Seamless integration: Works harmoniously with the Tesla vehicle's existing systems, providing a fluid and integrated experience.
· Content discovery: Allows passengers to search and select videos, offering a personalized entertainment journey.
· Free access until 2026: Provides a significant period of complimentary use, making advanced in-car entertainment accessible to more users.
Product Usage Case
· A family on a long road trip can keep children entertained with their favorite cartoons on the Tesla's screen, making the journey more pleasant for everyone.
· A business traveler can catch up on industry news or watch presentations during a commute, using the car as a mobile workspace and entertainment hub.
· Friends heading to a destination can enjoy shared video content or music videos together, enhancing the social aspect of the drive.
· Passengers can use the platform to watch tutorials or educational content while waiting for the driver to finish a task, making downtime productive.
91
WinsleyAI-PR
Author
maikop
Description
WinsleyAI-PR is an AI-powered public relations tool designed to help founders craft personalized pitches for both journalists and podcasters. It differentiates itself by learning the user's unique writing style and integrating proprietary pitch templates and individual contact research to generate highly targeted outreach. The core innovation lies in its personalized AI, Winsley, which goes beyond simple keyword matching to find truly aligned contacts through vector search, aiming to democratize access to high-quality PR tools.
Popularity
Points 1
Comments 0
What is this product?
WinsleyAI-PR is an intelligent system that assists in generating effective public relations pitches. Unlike generic PR platforms, it utilizes a sophisticated AI named Winsley that actually learns and mimics your writing style from your own text samples. This AI then leverages expert-developed pitch templates and performs in-depth research on each potential media contact. A key technical aspect is the use of vector search, which is a more advanced way of finding relevant contacts compared to simple keyword searches; it understands the semantic meaning and context, leading to a much better match. So, it's like having a highly skilled PR assistant that understands you and knows who to contact and what to say. This addresses the problem of generic, ineffective pitches that often get ignored, and it provides powerful PR capabilities to founders without the cost of a traditional agency.
How to use it?
Developers can integrate WinsleyAI-PR by using its API to programmatically generate and send pitches. The system can be incorporated into existing marketing automation workflows or CRM platforms. For instance, a startup could use the API to automatically generate personalized outreach emails to a list of journalists or podcasters identified by their system, based on new product launches or company news. The API allows for customization of the AI's output, enabling fine-tuning of the pitch content before sending. Pitches can be sent directly through integrated Gmail accounts, and follow-up scheduling can be automated, streamlining the entire PR outreach process.
Product Core Function
· AI-powered personalized pitch generation: Learns your writing style to create pitches that sound authentically yours, making your outreach more engaging and effective. This is valuable because it increases the likelihood of your pitch being read and responded to.
· Journalist and podcaster outreach: Supports pitching to both media types, broadening your reach and increasing opportunities for coverage. This is useful for founders looking for comprehensive media exposure.
· Vector search for contact alignment: Uses advanced semantic search to find media contacts who are genuinely relevant to your story, rather than just matching keywords, ensuring your pitches land in the right hands. This saves time and improves the success rate of your PR efforts.
· Individual contact research integration: Automatically researches each media contact to tailor your pitch, demonstrating you've done your homework and increasing your credibility. This personalization makes your pitches stand out from generic templates.
· Direct Gmail integration and follow-up scheduling: Allows seamless sending of pitches via your existing Gmail account and automates follow-up reminders, simplifying your workflow and ensuring no opportunities are missed. This makes managing your PR outreach much more efficient.
Product Usage Case
· A SaaS startup launching a new feature can use WinsleyAI-PR to generate personalized pitches to tech journalists. The AI will analyze the startup's existing press releases and blog posts to adopt their tone and voice. Then, it will research specific journalists who have covered similar technologies, and craft pitches highlighting how the new feature addresses issues those journalists have previously written about, leading to more targeted and impactful media coverage.
· A mobile app developer aiming for podcast interviews can use WinsleyAI-PR to create pitches for relevant podcasters. The AI will learn the developer's speaking style from their past interviews or blog content, and then identify podcasts whose audience aligns with the app's target users. The generated pitches will explain why the app is a compelling topic for that specific podcast's listeners, increasing the chances of securing an interview slot.
· A founder seeking to scale their PR efforts without a large agency retainer can use WinsleyAI-PR as a cost-effective solution. By inputting their company's messaging and target media types, the system can generate a high volume of personalized pitches, allowing the founder to focus on building relationships and managing media responses, thereby achieving significant PR outcomes with limited resources.
92
Feature-Scoped Isolation Engine
Author
rida
Description
BranchBox is a novel tool designed to tackle the common complexities of parallel development, especially when working with multiple coding agents or features simultaneously. It tackles the chaos of shared ports, diverging worktrees, conflicting databases, and leaking environment variables by creating fully isolated, self-contained development environments for each individual feature. This ensures that each feature's development doesn't interfere with others, making parallel work significantly more predictable and manageable. The core innovation lies in its comprehensive isolation strategy, extending to Git worktrees, devcontainers, Docker networks, databases, ports, and environment variables.
Popularity
Points 1
Comments 0
What is this product?
Feature-Scoped Isolation Engine (BranchBox) is a developer tool that creates completely separate, isolated development environments for each specific coding task or feature you're working on. Imagine having a clean, dedicated workspace for every new idea or bug fix, ensuring that nothing from one workspace accidentally messes up another. It achieves this by managing distinct Git worktrees, devcontainers (think mini-operating systems for your code), Docker networks (how containers talk to each other), databases, network ports, and environment variables for each feature. This means if you're working on Feature A and need port 8000, and Feature B also needs port 8000, they won't clash. The innovation is in its granular, feature-level isolation, preventing the common 'dependency hell' and 'state corruption' issues that plague developers juggling multiple concurrent tasks.
How to use it?
Developers can use BranchBox to manage complex projects where multiple features are being developed concurrently, or when collaborating with AI coding agents. It's integrated into your development workflow by setting up a BranchBox environment for each feature branch. Instead of working directly on your main codebase, you initiate a BranchBox for that feature. This automatically spins up the necessary isolated components (like a dedicated database instance or a specific set of environment variables). You then develop within this isolated environment. When you're done, you can easily tear down the environment, leaving your main project pristine. This is particularly useful for Continuous Integration/Continuous Deployment (CI/CD) pipelines or for teams where different developers might be working on overlapping parts of a project.
Product Core Function
· Isolated Git Worktree Management: Provides a clean, separate version of your codebase for each feature, preventing merge conflicts and accidental modifications across branches. This means your work on one feature won't accidentally alter code intended for another.
· Isolated Devcontainer Provisioning: Sets up a dedicated containerized development environment for each feature, ensuring consistent dependencies and runtime configurations without affecting other projects. This prevents 'it worked on my machine' issues and ensures that library versions for one feature don't conflict with another.
· Isolated Docker Network Creation: Establishes unique Docker networks for each feature's environment, preventing network port collisions and ensuring that services running for one feature cannot be accessed by or interfere with services from another feature. This is crucial for microservices development or when running multiple applications that rely on specific ports.
· Isolated Database Instances: Allows each feature to have its own dedicated database instance, completely separate from other features or the main application database. This prevents data corruption or unintended data leaks between different development efforts.
· Independent Port Allocation: Guarantees that each feature's development environment can utilize its own set of network ports without conflict with other active environments. This is essential when running multiple web servers or services locally.
· Scoped Environment Variable Management: Ensures that environment variables are specific to each feature's development environment, preventing sensitive information or configuration settings from leaking between different tasks. This enhances security and prevents misconfigurations.
· Secure Credential Sharing (Optional): Safely mounts shared credentials into feature environments only when explicitly needed, balancing security with the convenience of accessing shared resources. This allows developers to securely access common resources without exposing sensitive data across all environments.
Product Usage Case
· Concurrent Feature Development: A developer is working on a new user authentication module and a performance optimization for the API simultaneously. By using BranchBox, each feature gets its own isolated environment. The authentication feature can use its own database schema and ports, while the performance feature can run its benchmarks and simulations without affecting the authentication module's development, leading to a smoother, less error-prone development cycle.
· AI Agent Collaboration: A team is using an AI coding agent to refactor a large portion of their application. To ensure the AI's experimental code doesn't destabilize the main development branch, a dedicated BranchBox environment is created for the AI's work. This isolates the AI's code, dependencies, and runtime from the human developers' environments, allowing for safe experimentation and review.
· Microservices Development: A developer is working on a complex microservices architecture where several services need to run locally. Each microservice or group of related services can be launched within its own BranchBox environment, with its own dedicated ports and Docker network. This prevents port conflicts between services and ensures that changes to one service's dependencies don't inadvertently break another, simplifying local testing and debugging.
· Database Migrations and Testing: Before applying a major database migration to production, a developer needs to test it thoroughly. BranchBox can spin up a completely isolated environment with a copy of the production database schema and data. The migration can then be applied and tested without any risk to the active development databases or the main application.
· Onboarding New Developers: A new team member needs to get up to speed on a complex project with many moving parts. Instead of having them struggle with setting up a monolithic development environment, each major feature or module can be provided as a pre-configured BranchBox environment, allowing the new developer to focus on learning the code and logic rather than the environment setup.
93
Web2Knowledge AI Agent Foundation
Author
ahmedelhadidi
Description
This project transforms any website into a readily usable knowledge base for AI agents, powered by a 1-click deployment. It addresses the challenge of feeding unstructured web data to AI models by offering a streamlined workflow for knowledge extraction and organization, making web content accessible for AI consumption.
Popularity
Points 1
Comments 0
What is this product?
Web2Knowledge AI Agent Foundation is a tool that allows you to take any website and automatically convert its content into a structured knowledge base that AI agents can understand and query. The core innovation lies in its ability to scrape website data, process it (often involving techniques like text summarization, entity recognition, and semantic indexing), and then present it in a format suitable for AI models like large language models (LLMs). This avoids the manual effort of data collection and preprocessing, which is a significant bottleneck in AI development.
How to use it?
Developers can use this project by pointing it to a target website. The system will then crawl and extract relevant information. The output is a knowledge base that can be integrated into AI agent frameworks. For example, you might feed this knowledge base into a Retrieval-Augmented Generation (RAG) system, where the AI agent can retrieve information from this website-derived knowledge base to answer user queries more accurately and contextually. The '1-click deploy' aspect suggests a user-friendly interface or script that automates the setup process, making it accessible even for those less familiar with deep AI infrastructure.
Product Core Function
· Website Scraping and Content Extraction: Automatically gathers all textual content from a given website, ensuring comprehensive data capture for the AI agent. This is valuable because it eliminates the need for developers to manually copy-paste or build custom scrapers for each new website.
· Knowledge Structuring and Indexing: Processes the extracted text into a format that AI models can efficiently search and understand, often using vector embeddings or semantic graphs. This adds value by making the raw website data discoverable and retrievable by AI, moving beyond simple keyword matching.
· 1-Click Deployment: Simplifies the setup and integration process, allowing developers to quickly get started without complex configuration. This is valuable for rapid prototyping and for developers who want to focus on the AI agent's logic rather than infrastructure.
· AI Agent Integration Ready: The output knowledge base is designed to be compatible with common AI agent architectures, such as RAG systems. This provides direct utility by bridging the gap between web data and AI capabilities, enabling more informed and context-aware AI responses.
Product Usage Case
· Building a Customer Support Bot: A company can use this tool to turn their product documentation website into a knowledge base for their AI customer support agent. When a customer asks a question, the agent can instantly retrieve accurate information from the official documentation, improving response times and accuracy.
· Creating a Research Assistant for Specific Topics: A researcher studying a particular field can point this tool to a collection of relevant academic websites or blogs. The resulting knowledge base can then be used by an AI assistant to summarize research papers, find related concepts, or generate literature reviews, significantly accelerating the research process.
· Developing an E-commerce Product Recommender: An online retailer can use this to extract product details from their website, including descriptions, specifications, and reviews, to build a knowledge base. An AI agent can then leverage this to provide highly personalized product recommendations to customers based on their preferences and past interactions.
94
Tf-Dialect
Author
iacguy
Description
Tf-dialect is a novel tool designed to bridge the gap between AI-generated Infrastructure as Code (IaC) and existing organizational standards. It allows AI coding agents to produce Terraform configurations that are not just functional, but also adhere to your team's specific conventions, security policies, and best practices. This means AI can now manage your infrastructure without compromising on established guidelines, making IaC more accessible and manageable for teams adopting AI workflows.
Popularity
Points 1
Comments 0
What is this product?
Tf-dialect is a system that enables AI coding agents to generate Terraform code that is context-aware of your organization's specific infrastructure standards and policies. Traditionally, AI-generated Terraform is great for new projects but struggles with existing infrastructure that has established rules. Tf-dialect solves this by allowing you to 'teach' AI agents your organization's preferred way of writing Terraform, ensuring consistency and compliance even when AI is creating the code. The core innovation lies in a novel 'Meta-Configuration' or MCP approach, which acts as a set of guidelines that the AI agent follows when generating Terraform. This allows for flexible yet controlled IaC generation.
How to use it?
Developers can integrate Tf-dialect into their AI-powered infrastructure management workflows. You would typically define your organization's Terraform standards in a Meta-Configuration format (MCP). This MCP then acts as a guide for coding agents when they are tasked with generating or modifying Terraform code for your infrastructure. Instead of just asking the AI to 'create a VPC', you'd prompt it to 'create a VPC following our organization's MCP'. This ensures the output is not only correct but also compliant with your specific requirements, making it seamless to adopt AI for infra tasks in an existing environment.
Product Core Function
· Meta-Configuration Processing: Tf-dialect interprets a structured set of organizational standards (MCP) to guide AI's Terraform generation. This ensures generated code aligns with your team's predefined best practices, security requirements, and naming conventions. The value is consistent, compliant, and manageable IaC, even when generated by AI.
· Context-Aware IaC Generation: Enables AI agents to produce Terraform code that understands and respects existing infrastructure setups and organizational policies. This prevents AI from creating incompatible or non-compliant resources, solving the problem of AI-generated code clashing with established infrastructure. The value is seamless integration of AI into existing infra management.
· Developer Productivity Boost: By automating the adherence to standards, Tf-dialect frees up developers from manually reviewing and correcting AI-generated Terraform. This significantly speeds up the process of adopting AI for infrastructure tasks and reduces the burden on human oversight. The value is faster infrastructure deployment and reduced manual effort.
· Policy Enforcement for AI: Provides a mechanism to enforce specific infrastructure policies through AI-generated code. This acts as a guardrail, ensuring that any infrastructure provisioned by AI meets your organization's security and compliance mandates. The value is enhanced security and compliance for AI-driven infrastructure.
Product Usage Case
· An enterprise with strict security policies wants to use AI agents to provision new cloud resources. Tf-dialect allows them to define their security compliance rules in the MCP, ensuring the AI agent generates Terraform for secure VPCs, firewalls, and access controls that meet their specific requirements. This solves the problem of potentially insecure AI-generated infrastructure.
· A DevOps team is migrating to a new cloud provider and wants to leverage AI for generating the initial Terraform configurations. By using Tf-dialect with an MCP that dictates their preferred module structure and variable usage, they can ensure the AI-generated Terraform is immediately adoptable and consistent with their established internal patterns. This solves the challenge of AI output not fitting their existing operational framework.
· A startup aims to rapidly scale its infrastructure using AI. Tf-dialect, configured with their lean operational standards, allows AI agents to generate scalable and cost-effective Terraform for new services. This speeds up their growth by enabling AI to handle the bulk of IaC generation while adhering to their efficient operational philosophy. This solves the problem of needing to scale infrastructure quickly without compromising on operational efficiency.
95
VibeAgent Visualize
Author
ktotheb
Description
A visual dashboard for AI agents, making their decision-making processes transparent and understandable for developers. This project tackles the 'black box' problem often found in AI systems, especially those interacting with tools like Cursor.
Popularity
Points 1
Comments 0
What is this product?
VibeAgent Visualize is a tool that transforms abstract AI agent actions into a comprehensible visual flow. Instead of just seeing the final output of an AI agent (e.g., code generated or an action taken), you can see a step-by-step breakdown of how it arrived at that decision. It uses a mockup approach, meaning it's a conceptual demonstration of how this visualization could work, likely employing graph-based representations or state diagrams to map the agent's 'thought process.' The innovation lies in providing a debugging and understanding layer for AI agents, which are becoming increasingly complex.
How to use it?
Developers can use VibeAgent Visualize to integrate it with their AI agent frameworks. When an agent runs, instead of just receiving a result, it would emit a stream of its internal states and decisions. VibeAgent Visualize would then consume this stream and render it as an interactive diagram. This allows developers to pinpoint where an agent might be going wrong, understand why it chose a particular path, or simply gain confidence in its behavior. It's particularly useful for agents that interact with development tools like Cursor, allowing developers to see precisely how the agent is 'thinking' about modifying code.
Product Core Function
· Visual state representation: Displays the internal states and transitions of an AI agent as a clear diagram, helping developers understand the agent's logic flow and identify potential issues in its decision-making process. The value is in demystifying complex AI behavior, making debugging faster and more intuitive.
· Action tracing: Logs and visualizes the specific actions an AI agent takes, such as calling specific functions or interacting with external tools. This provides a granular view of the agent's execution, enabling developers to verify that the agent is behaving as intended and to debug unexpected outcomes.
· Tool integration mockup: Demonstrates how AI agent visualizations can be applied within development environments like Cursor. This highlights the practical application of the visualization technique for AI agents that assist in coding, allowing developers to see how the agent plans to modify code before it's executed.
· Agent behavior analysis: Facilitates deeper analysis of agent performance by providing a visual history of its operations. Developers can review past executions to understand recurring patterns, identify areas for improvement, and optimize agent strategies.
Product Usage Case
· Debugging AI-assisted code generation: A developer is using an AI agent within Cursor to refactor a piece of code. The agent produces incorrect code. VibeAgent Visualize would show the developer exactly which steps the agent took, where its reasoning went awry, and what alternatives it considered, enabling quick identification of the bug in the agent's logic, rather than just the generated code.
· Understanding complex AI workflows: An AI agent is designed to perform a multi-step task, like researching a topic and then writing a report. VibeAgent Visualize would map out each research query, data processing step, and writing decision, allowing the developer to grasp the overall workflow and ensure each part contributes correctly to the final output.
· Improving AI agent reliability: By visualizing the decision-making of an agent over many runs, developers can spot inconsistencies or common failure points. This allows for targeted improvements to the agent's algorithms or training data, leading to more robust and reliable AI assistance.
· Explaining AI agent choices to collaborators: When working in a team, visualizing an AI agent's reasoning can help explain its behavior to other team members, even those less familiar with the specifics of AI implementation. This fosters better communication and shared understanding of how AI tools are being used.
96
ThinkReview: In-Browser AI Code Review Copilot
Author
jkshenawy22
Description
ThinkReview is an open-source browser extension that enhances code reviews by integrating AI directly into your workflow. It provides a private chat interface within your Pull Request (PR) or Merge Request (MR) views on platforms like GitLab, GitHub, Azure DevOps, and Bitbucket. A key innovation is its support for local LLMs via Ollama, meaning your code never leaves your machine, offering privacy and control. It's designed to assist developers in identifying potential issues, understanding complex logic, and drafting review comments without automatically posting them, keeping the human reviewer in complete control.
Popularity
Points 1
Comments 0
What is this product?
ThinkReview is a smart browser extension that acts like an AI assistant for your code reviews. Instead of sending your code to a remote server for analysis, it can run AI models directly on your computer using a technology called Ollama. This means your sensitive code stays private. It attaches to the usual code review pages on popular platforms like GitHub or GitLab and gives you a chat window. You can ask the AI questions about the code changes, like 'What does this function do?' or 'Are there any potential bugs here?'. The AI's suggestions are for your eyes only, so you can decide exactly what to communicate to your team. This offers a novel approach to AI-assisted code reviews that prioritizes privacy and developer agency.
How to use it?
Developers can install ThinkReview as a browser extension (e.g., on Chrome). Once installed, it automatically integrates with the PR/MR interfaces of supported platforms. For local AI capabilities, developers need to have Ollama installed and a compatible LLM downloaded. Then, in ThinkReview's settings, they can point the extension to their local Ollama instance. This allows for private, on-device code analysis. Developers can then open any PR/MR, and a private chat panel will appear where they can interact with the AI to get insights into the code changes. This provides a seamless way to leverage AI without disrupting existing workflows or compromising code security.
Product Core Function
· Private AI Chat for Code Reviews: Provides a dedicated chat interface within the PR/MR view, allowing developers to ask AI questions about code changes and receive private, contextualized answers. This helps in understanding complex logic and potential issues before they go to production.
· Local LLM Support via Ollama: Enables running AI models directly on the developer's machine, ensuring code privacy and eliminating reliance on external services. This is crucial for teams with strict data security policies or those working in air-gapped environments, offering a secure and cost-effective solution.
· Multi-Platform Integration: Seamlessly integrates with major code hosting platforms like GitLab, GitHub, Azure DevOps, and Bitbucket. This broad compatibility means developers can use ThinkReview across their existing toolchains without needing to switch platforms.
· Draft Comment Generation: The AI can help generate draft comments for code reviews based on its analysis. This saves developers time by providing a starting point for feedback, making the review process more efficient.
· Developer Control and Agency: Unlike automated commenting bots, ThinkReview's AI suggestions are non-intrusive and require explicit user action before any comments are posted. This ensures that developers retain full control over the review process and communication, fostering a more collaborative and less disruptive AI experience.
Product Usage Case
· A developer working on a self-hosted GitLab instance needs to review a critical piece of code. They install ThinkReview and configure it to use a local LLM. They open the MR, ask ThinkReview to explain a complex algorithm, and identify potential edge cases, all without sending the proprietary code off their network. This ensures the code remains secure while still benefiting from AI assistance.
· A team using GitHub is experiencing slow code review turnaround times. One developer uses ThinkReview to quickly get an AI-powered summary of changes in a large PR and asks it to highlight potential performance bottlenecks. This allows them to focus their manual review on the most critical aspects, speeding up the overall review process.
· A developer is new to a large codebase and is struggling to understand a set of changes. They use ThinkReview to ask the AI to break down the functionality of a modified module and explain the impact of the changes. This helps them grasp the context quickly and provide more informed feedback, improving the quality of the review.
· A company has strict regulations about sending code to third-party services. They can leverage ThinkReview with Ollama to perform AI-assisted code reviews entirely within their secure development environment, meeting compliance requirements while still enhancing developer productivity.