Show HN Today: Discover the Latest Innovative Projects from the Developer Community
 ShowHN Today
ShowHN Today
- Continue with Google
Show HN Today: Top Developer Projects Showcase for 2025-10-04
SagaSu777 2025-10-05
Explore the hottest developer projects on Show HN for 2025-10-04. Dive into innovative tech, AI applications, and exciting new inventions!
Summary of Today’s Content
Trend Insights
The surge in projects focused on enhancing developer workflows, particularly those integrating AI and cross-language compatibility, signifies a clear trend. Developers are seeking tools that streamline complex processes, such as running code in diverse environments or managing AI models effectively. The emphasis on local-first and privacy-centric applications, especially those leveraging web technologies like WebGPU and Transformers.js, highlights a growing demand for powerful yet accessible tools that don't compromise user data. For aspiring creators and innovators, this means there's a fertile ground for building solutions that empower developers, offer novel ways to interact with AI, and prioritize user privacy. Think about how you can abstract away complexity, democratize access to advanced technologies, or create more intuitive interfaces for powerful systems. The hacker spirit thrives in identifying these pain points and crafting elegant, functional solutions.
Today's Hottest Product
Name
Run – A Universal CLI Code Runner Built with Rust
Highlight
This project innovates by creating a single, lightweight command-line tool that can execute code snippets and files across a vast array of programming languages, both interpreted and compiled. It intelligently detects languages, compiles temporary files for compiled languages, and offers a unified REPL experience. Developers can learn about cross-language runtime management, efficient CLI design, and Rust's capabilities for system-level tools.
Popular Category
AI/ML Tools
Developer Productivity
CLI Tools
Web Development
Data Visualization
Popular Keyword
AI
LLM
Rust
CLI
API
Observability
TUI
WebGPU
Transformer
Technology Trends
Cross-Language Execution Environments
AI-Powered Development Assistants
Decentralized/Local-First Applications
Enhanced Developer Workflows
Privacy-Focused Tools
Scientific Computing with ML
LLM Interaction and Integration
Observability for Complex Systems
Project Category Distribution
Developer Tools (30%)
AI/ML Applications (25%)
Productivity Tools (20%)
Web Applications (15%)
Utilities (10%)
Today's Hot Product List
| Ranking | Product Name | Likes | Comments |
|---|---|---|---|
| 1 | Polyglot Runner CLI | 84 | 34 |
| 2 | LLM Math Navigator | 5 | 4 |
| 3 | OneDollarChat | 4 | 3 |
| 4 | DigitalToothFairyCert | 6 | 0 |
| 5 | TypeScript-to-SQL Lambda Compiler | 4 | 1 |
| 6 | Surf-Wayland: The Wayland-Native Suckless Browser | 3 | 2 |
| 7 | BetterSelf: Spaced Repetition for Knowledge Retention | 5 | 0 |
| 8 | GlassSearch | 1 | 4 |
| 9 | LocalCopilot-API | 3 | 1 |
| 10 | Offline Ledger Companion | 4 | 0 |
1
Polyglot Runner CLI
Author
esubaalew
Description
This project is a universal command-line interface (CLI) tool designed to execute code written in various programming languages. It streamlines the process of running single code snippets, entire files, or even code piped from standard input. The innovative aspect lies in its ability to support both interpreted and compiled languages with a unified interface, offering language-specific interactive environments (REPLs) that can be switched on the fly. So, this is useful for developers who frequently switch between different programming languages and want a single, easy-to-use tool to run their code without complex setup.
Popularity
Points 84
Comments 34
What is this product?
Polyglot Runner CLI is a versatile command-line tool built using Rust that acts as a single point of entry for executing code across a wide spectrum of programming languages. Its core innovation is the abstraction layer it provides, allowing developers to run code written in languages like Python, JavaScript, Ruby (interpreted) and Rust, Go, C/C++ (compiled) using the same commands. It intelligently detects the language based on provided flags or file extensions. For compiled languages, it can create temporary build artifacts and execute them. The tool also offers an interactive mode (REPL) for each supported language, enabling real-time code experimentation and iteration. This means you don't need to remember specific compilation commands or interpreter paths for each language, simplifying your development workflow significantly.
How to use it?
Developers can use Polyglot Runner CLI by installing it via Cargo (Rust's package manager) as `cargo install run-kit` or by downloading pre-compiled binaries from its GitHub repository. Once installed, you can run code in several ways: directly from a flag (e.g., `run --python 'print("Hello")'`), by executing a file (e.g., `run main.py`), or by piping input to it (e.g., `echo '1+1' | run --javascript`). For interactive sessions, simply type `run` and then use commands like `:lang python` to switch to the Python REPL, `:lang go` for Go, and so on. This offers a seamless way to test small code chunks or script snippets without leaving your terminal. So, this is useful for quickly testing out ideas or running small scripts in any language you have installed on your system.
Product Core Function
· Universal Code Execution: Ability to run code from various programming languages (interpreted and compiled) using a single command. This is valuable because it reduces the mental overhead of remembering specific execution commands for each language, making it faster to switch between projects or experiment with new languages.
· File and Snippet Execution: Supports running entire code files as well as one-off code snippets provided directly via command-line flags. This is useful for quickly testing small pieces of logic or executing script files without needing to open a full IDE or editor.
· Standard Input Piping: Allows code to be executed by piping data from standard input, making it ideal for processing data streams or working with the output of other command-line tools. This is helpful for data manipulation tasks and integrating with existing command-line workflows.
· Interactive REPLs: Provides language-specific Read-Eval-Print Loops (REPLs) that can be switched between interactively. This offers a dynamic environment for experimenting with language features, debugging, and exploring code in real-time, enhancing the learning and development process.
Product Usage Case
· Testing small Python functions: A developer needs to quickly test a short Python function they just wrote. Instead of opening a Python interpreter or a file, they can simply type `run --python 'def add(a, b): return a + b; print(add(2, 3))'` and get the output immediately. This saves time and context switching.
· Running a Go utility script: A developer has a small Go script for a specific task, like renaming files. They can run it directly using `run my_script.go` without needing to manually compile it first using `go build`. The tool handles the compilation and execution behind the scenes, simplifying the process.
· Processing piped data with JavaScript: A developer has a stream of JSON data from another command and wants to quickly parse and transform it using JavaScript. They can pipe the data like `cat data.json | run --javascript 'JSON.parse(stdin).map(item => item.name)'`. This allows for rapid data processing without complex scripting.
· Experimenting with Rust syntax: A new Rust developer wants to try out a specific syntax or library feature. They can enter the Rust REPL by typing `run` and then `:lang rust`, and then write and execute Rust code interactively to understand its behavior and refine their understanding.
2
LLM Math Navigator

Author
tamnd
Description
This project is 'The Little Book of Maths for LLMs', a concise resource explaining the essential mathematics required to understand Large Language Models (LLMs). It demystifies complex concepts like linear algebra, calculus, and probability, making advanced AI more accessible to developers.
Popularity
Points 5
Comments 4
What is this product?
This project is an educational resource, presented as a 'Little Book', that breaks down the fundamental mathematical principles underpinning Large Language Models (LLMs). It focuses on the core math needed, such as matrix operations for understanding neural network layers, derivatives for model optimization, and probability distributions for token prediction. The innovation lies in its targeted approach, filtering out general math and highlighting only what's crucial for grasping LLM mechanics, thus reducing the learning curve for developers interested in AI.
How to use it?
Developers can use this resource as a guide to build a foundational understanding of LLMs. It's perfect for those who have some programming experience but find the underlying math of AI daunting. By reading through the explanations and examples, developers can gain the confidence to explore LLM architectures, fine-tune models, or even contribute to AI research. Integration isn't in the traditional software sense, but rather intellectual integration: applying the learned math concepts to real-world AI development challenges.
Product Core Function
· Linear Algebra Essentials for Neural Networks: Explains how matrix multiplication and vector operations are the building blocks of how LLMs process information, helping developers understand layer transformations.
· Calculus for Model Optimization: Details concepts like gradients and backpropagation, showing how LLMs learn and improve by minimizing errors, crucial for understanding training processes.
· Probability and Statistics for Language Understanding: Covers probability distributions and sampling methods, explaining how LLMs predict the next word and generate coherent text, enabling developers to grasp the probabilistic nature of language generation.
· Concise and Focused Content: Curates only the most relevant mathematical topics for LLMs, saving developers time by avoiding unnecessary mathematical theory and directly addressing their learning needs.
· Accessible Explanations: Translates complex mathematical jargon into understandable terms, making advanced AI concepts approachable for a broader range of developers.
Product Usage Case
· A junior AI developer struggling to understand how Transformer models work can use this book to quickly grasp the linear algebra behind attention mechanisms, enabling them to better debug or modify existing models.
· A data scientist wanting to fine-tune an LLM for a specific task can refer to the calculus sections to understand the optimization process and how learning rates affect convergence, leading to more efficient model training.
· A hobbyist interested in building their own simple language generator can use the probability sections to understand how to sample from word distributions, allowing them to implement basic text generation capabilities.
· An engineer integrating LLM APIs into their application can use this resource to gain a deeper appreciation for the model's capabilities and limitations, leading to more informed design decisions and better error handling.
3
OneDollarChat
Author
skrid
Description
A global chat platform where every message incurs a $1 cost, designed to encourage thoughtful communication and explore the economic impact on online interactions. The core innovation lies in implementing a token-based payment system for each message sent, leveraging blockchain technology to ensure transparency and security of transactions.
Popularity
Points 4
Comments 3
What is this product?
OneDollarChat is a novel messaging application that introduces a pay-per-message model, costing $1 for each message sent. This isn't just about charging users; it's an experiment to see how this economic incentive affects the nature of online conversations. By making communication have a tangible cost, the platform aims to foster more deliberate and meaningful exchanges, reducing spam and superficial interactions. The underlying technology likely involves a custom-built token or integration with existing cryptocurrency rails, using smart contracts to manage message credits and ensure all transactions are recorded on a distributed ledger. This approach brings a level of accountability and value to each piece of communication that traditional free chat apps lack.
How to use it?
Developers can integrate with OneDollarChat by using its API to send and receive messages. To initiate a chat, a user would first pre-purchase message credits, effectively paying $1 per credit. These credits are then consumed each time a message is sent. The API would allow applications to check a user's credit balance, send messages on their behalf, and receive incoming messages. This could be used in various scenarios, such as a premium support chat where users pay for direct expert advice, or a specialized community forum where only serious participants contribute. The integration process would involve setting up an API key and understanding the request/response structure for message handling and credit management.
Product Core Function
· Message Transaction System: Implements a system where each message sent consumes a $1 credit. The value is that it encourages users to be more concise and consider the importance of their message before sending, leading to higher quality interactions and reducing noise.
· Global Accessibility: Allows users from anywhere in the world to connect and communicate. The value here is enabling cross-border dialogue with a built-in mechanism for valuing every exchange, potentially fostering more considered international discussions.
· Transparency and Security: Leverages underlying blockchain principles for secure and transparent transactions. The value is in providing users with confidence that their payments are managed fairly and that the system is resistant to manipulation, building trust in the platform.
· User Credit Management: Enables users to purchase and manage their message credits. This provides a direct way for users to control their spending and understand the value of their communication, offering a sense of agency over their participation.
Product Usage Case
· Premium Support Chat: Imagine a software company offering direct, real-time chat support with their senior engineers. Users would pay $1 per message to ask questions and receive expert guidance, ensuring they only engage when they have a critical issue and that support staff are highly valued for their time. This solves the problem of overwhelming support queues and ensures only serious inquiries receive premium attention.
· Exclusive Expert Forums: A platform could host forums where users pay to ask questions to renowned experts in a specific field, such as medical advice or financial planning. Each question posed costs $1, ensuring experts are compensated for their time and knowledge, and that participants ask well-thought-out questions. This addresses the challenge of getting high-quality, dedicated expert time without overwhelming them.
· High-Stakes Collaborative Projects: For small, critical project collaborations, a team could use OneDollarChat where every message within the project channel costs $1. This encourages extreme focus and efficiency in communication, ensuring that only essential information is shared and that discussions remain on track, solving the problem of prolonged, unproductive team meetings and scattered communication.
· Personalized Coaching Sessions: A life coach or mentor could offer paid chat sessions through this platform. Each message exchanged could cost $1, allowing clients to pay for focused, direct guidance and accountability, and for coaches to monetize their time effectively. This provides a structured and monetized way to deliver personalized coaching interactions.
4
DigitalToothFairyCert
Author
joerock
Description
A simple yet delightful web application that generates personalized Tooth Fairy certificates for children who have lost a tooth. It addresses the small but meaningful need of parents to create a memorable experience, leveraging basic web technologies to provide a charming digital artifact.
Popularity
Points 6
Comments 0
What is this product?
DigitalToothFairyCert is a web-based tool that allows parents to quickly create customized certificates for their children from the Tooth Fairy. The innovation lies in its simplicity and focus on a specific, emotionally driven use case. It uses straightforward front-end technologies (likely HTML, CSS, and JavaScript) to dynamically populate a certificate template with child's name, date, and a personalized message. This bypasses the need for complex design software or printing, offering an instant, digital solution to a common parental ritual. The value is in making a child's milestone feel more magical and official, with minimal effort.
How to use it?
Developers can use DigitalToothFairyCert by visiting the hosted web application. Parents would navigate to the site, input their child's name, the date of the lost tooth, and perhaps a small message. Upon submission, the application generates a visually appealing certificate that can be downloaded as an image or PDF. For developers interested in the technical aspect, the project likely demonstrates a clean front-end structure, possibly utilizing a simple templating engine or direct DOM manipulation for certificate generation. It's a prime example of a 'micro-solution' built with readily available web tools. The usage for parents is to simply create a fun keepsake.
Product Core Function
· Personalized certificate generation: Dynamically inserts child's name and date into a pre-designed certificate template, providing a custom touch. This makes the certificate feel unique to each child, enhancing the magic of the Tooth Fairy tradition. The technical implementation likely involves JavaScript to capture user input and update HTML elements.
· Instant download capability: Allows users to immediately download the generated certificate as a digital file (e.g., PNG, JPG, or PDF). This offers immediate gratification and a tangible (printable) outcome. This is achieved through browser APIs for file generation or rendering.
· Simple, intuitive user interface: Designed for ease of use by parents, requiring minimal technical knowledge. The value here is accessibility and speed, ensuring that creating this special item is not a chore but a quick, enjoyable process.
· Themed visual design: Features child-friendly graphics and fonts to create a whimsical and magical aesthetic. This contributes to the emotional value of the certificate, making it more appealing to children. The technical aspect involves CSS styling to create the visual appeal.
Product Usage Case
· Parent wanting to create an immediate, printable souvenir for a child who lost a tooth, but doesn't have design software or time for elaborate crafting. They use the web app, fill in the details, and print the certificate within minutes, making the child's experience more special and memorable.
· A parent looking for a quick and digital way to document a child's milestone. The generated certificate serves as a digital keepsake that can be easily stored or shared, preserving the memory of this childhood event without needing physical storage space.
· A developer looking for a simple example of a functional web application that solves a specific user need with minimal complexity. They can learn from its straightforward front-end implementation, templating, and user interaction patterns, inspiring their own small-scale creative coding projects.
5
TypeScript-to-SQL Lambda Compiler
Author
jeswin
Description
This project introduces a novel approach to building type-safe database queries directly within TypeScript. It translates familiar TypeScript lambda expressions into executable SQL queries, effectively bringing the expressiveness of LINQ-to-SQL to the JavaScript ecosystem. The core innovation lies in its ability to leverage TypeScript's strong typing system to guarantee query correctness at compile time, thus reducing runtime errors and improving developer productivity when interacting with SQL databases from a TypeScript codebase.
Popularity
Points 4
Comments 1
What is this product?
This is a compiler that bridges the gap between modern TypeScript and traditional SQL databases. It allows developers to write database queries using TypeScript's type-safe lambda functions (like `(x) => x.name === 'John'`). The compiler then analyzes these lambdas and transforms them into accurate and efficient SQL statements (e.g., `SELECT * FROM users WHERE name = 'John'`). The key technical insight is utilizing TypeScript's static type checking to ensure that the queries you write are valid before your code even runs. So, this means fewer bugs and more confidence when fetching data. This is useful because it makes database interactions safer and more intuitive, especially for front-end or Node.js developers who might not be SQL experts.
How to use it?
Developers can integrate this by defining their database schemas in TypeScript. Then, instead of writing raw SQL strings, they can use the provided library to write query logic using TypeScript's familiar functional programming constructs. The compiler will automatically generate the corresponding SQL. For example, you might use it like `db.users.where(user => user.age > 18).select(user => user.name)`. This directly translates to `SELECT name FROM users WHERE age > 18`. This is useful for quickly building data access layers in Node.js applications or even for client-side applications that need to interact with backend databases, providing a type-safe and productive way to query data.
Product Core Function
· Type-safe query generation: Leverages TypeScript's static typing to ensure SQL queries are syntactically correct and reference valid database columns and tables before runtime. This reduces the chance of runtime errors caused by typos or incorrect query structures, making your data fetching more reliable.
· Lambda expression to SQL translation: Converts familiar TypeScript arrow functions and lambda expressions into standard SQL query strings. This allows developers to express complex query logic in a readable and concise manner, similar to LINQ in C#, making database interactions feel more natural within a JavaScript environment.
· Schema-aware query building: Understands the structure of your database tables as defined in TypeScript, enabling intelligent query construction. This means the compiler can help you avoid common mistakes by knowing what fields and relationships exist, leading to more robust and maintainable database code.
· Compile-time error checking: Catches potential query errors during the TypeScript compilation phase, rather than at runtime. This significantly speeds up the development cycle by identifying and fixing bugs early, saving debugging time and preventing production issues.
Product Usage Case
· Building a type-safe API backend with Node.js: A developer can use this to create an API that interacts with a PostgreSQL database. Instead of manually writing SQL queries for fetching user data, they can define a `User` interface in TypeScript and then write queries like `db.users.filter(u => u.isActive && u.role === 'admin').select(u => u.email)`. This ensures that only valid fields like `isActive`, `role`, and `email` are used, preventing common SQL injection vulnerabilities and ensuring data integrity. This is useful for securely and efficiently retrieving specific user information.
· Developing a front-end data dashboard: A front-end application built with React or Vue.js that needs to pull filtered and aggregated data from a backend API that uses this compiler. Developers can write TypeScript functions on the client-side that get translated to SQL on the server. For instance, to get the total sales for a specific product category, a developer might write `getDataForCategory('electronics', '2023-01-01')`, which gets transformed into a SQL query like `SELECT SUM(price) FROM orders WHERE category = 'electronics' AND order_date >= '2023-01-01'`. This makes it easy to build dynamic and data-driven user interfaces without writing raw SQL.
· Creating internal tools for data analysis: A company might build internal command-line tools for their data analysts using Node.js. This tool could allow analysts to write simple TypeScript scripts to query production databases for reports. For example, an analyst could write `fetchUsersBySignupDateRange('2024-01-01', '2024-01-31')` which compiles to `SELECT * FROM users WHERE signup_date BETWEEN '2024-01-01' AND '2024-01-31'`. This empowers non-SQL-expert analysts to perform ad-hoc data queries safely and efficiently.
6
Surf-Wayland: The Wayland-Native Suckless Browser
Author
gc000
Description
Surf-Wayland is a port of the minimalist, keyboard-centric 'suckless surf' browser to the Wayland display server. It provides a streamlined browsing experience by focusing on essential functionalities and efficient resource utilization, while embracing the modern Wayland architecture for improved security and performance.
Popularity
Points 3
Comments 2
What is this product?
This project is a web browser designed with the 'suckless' philosophy in mind, meaning it prioritizes simplicity and efficiency. Unlike many bloated browsers, it strips away unnecessary features to offer a fast and resource-light experience. The key innovation here is its native port to Wayland. Wayland is a modern display server protocol that aims to replace the older X11, offering better security, performance, and graphics handling. By porting Surf to Wayland, this project makes a lean, powerful browsing tool available in a cutting-edge graphical environment. Think of it as taking a highly optimized, no-frills engine and making it run smoothly on a brand new, highly efficient chassis. The value is a faster, more responsive, and potentially more secure browsing experience for users who appreciate minimalism and modern technology. So, this is useful to you because it offers a lightweight and performant alternative to common browsers, especially if you're already using or interested in Wayland.
How to use it?
Developers can use Surf-Wayland by compiling it from source and running it as a standalone application on a Wayland-enabled desktop environment (like GNOME, KDE Plasma, or Sway). Its core interaction model is heavily keyboard-driven, with commands issued through a dedicated input area or keybindings, minimizing reliance on a mouse. This makes it ideal for users who prefer to stay on the keyboard for most of their tasks. Integration into existing workflows can involve scripting or custom keybinding setups. The value here is a highly customizable and efficient browsing tool that can be tightly integrated into a developer's preferred command-line or keyboard-centric workflow. So, how this is useful to you is that it allows you to browse the web efficiently without constantly reaching for your mouse, and it plays nicely with modern operating systems.
Product Core Function
· Wayland Native Rendering: Utilizes the Wayland protocol for drawing the browser interface, offering potentially smoother graphics and better integration with Wayland compositors, leading to a more fluid visual experience and improved resource management. This is useful because it means the browser will perform better on modern Linux systems.
· Minimalist Design Philosophy: Focuses on essential browsing features, avoiding feature bloat. This results in faster startup times and lower memory consumption, making it ideal for resource-constrained systems or users who prioritize speed and simplicity. This is useful because it means your computer will run faster and you'll have more memory available for other applications.
· Keyboard-Centric Navigation: Employs a command-line-like interface and extensive keyboard shortcuts for page navigation, searching, and tab management, enhancing productivity for keyboard power users. This is useful because it allows you to control the browser very quickly without taking your hands off the keyboard.
· Extensible Configuration: While minimalist, it allows for customization through configuration files, enabling users to tailor its behavior and keybindings to their specific needs. This is useful because you can make the browser work exactly how you want it to.
· Integration with External Tools: Can be designed to work in conjunction with external tools for tasks like downloading or rendering specific content, leveraging the strengths of other command-line utilities. This is useful because it allows you to combine the browser with other powerful tools you might already use.
Product Usage Case
· A developer using Surf-Wayland on a minimalist Sway window manager setup to quickly browse documentation, opening new tabs and searching for information entirely via keyboard shortcuts, significantly speeding up their research workflow. This solves the problem of slow, mouse-heavy browsing during focused development sessions.
· A user on a low-resource server or older laptop running Surf-Wayland to access web pages efficiently without the heavy RAM footprint of mainstream browsers, providing a usable web experience where other browsers would struggle. This solves the problem of slow performance on underpowered hardware.
· A power user creating custom keybindings within Surf-Wayland to directly trigger specific scripts or system commands related to web content (e.g., saving an article to a personal knowledge base), integrating browsing seamlessly into their overall productivity system. This solves the problem of fragmented workflows by allowing browsing and personal productivity tools to be tightly coupled.
7
BetterSelf: Spaced Repetition for Knowledge Retention
Author
adamgol
Description
BetterSelf is a novel application designed to combat the pervasive problem of forgetting what we learn. It leverages the principles of spaced repetition, a proven learning technique, to ensure that valuable insights from books, podcasts, and personal notes are not lost over time. By intelligently reminding users of learned material at increasing intervals, BetterSelf helps solidify knowledge, making it stick. This project showcases an innovative approach to personal productivity by applying sophisticated learning algorithms to everyday knowledge acquisition.
Popularity
Points 5
Comments 0
What is this product?
BetterSelf is a personal knowledge management tool that uses an intelligent spaced repetition system to help users remember what they learn. Unlike traditional note-taking apps where information can easily be forgotten, BetterSelf actively re-surfaces your notes and lessons at optimal times. The core technical insight is the application of algorithms that determine when you are most likely to forget something and schedule a reminder for you to review it just before that happens. This is based on the scientific principle that reviewing information at increasing intervals strengthens memory recall. So, it's like having a personal tutor that ensures you never lose the valuable lessons you encounter, making your learning truly stick. This means you get more long-term value from the books you read, the podcasts you listen to, and the ideas you jot down.
How to use it?
Developers can integrate BetterSelf into their personal learning workflows. The app allows users to input notes, summaries, or key takeaways from various sources. BetterSelf's backend then manages the scheduling of review prompts. For developers, this means they can use BetterSelf to track technical concepts, new programming languages, or design patterns they are learning. By actively reviewing these items as prompted, they can ensure they retain this knowledge for future project use. The integration is straightforward: simply input your learning material, and the app handles the rest. This helps developers build a stronger, more accessible mental library of technical information, directly boosting their problem-solving capabilities.
Product Core Function
· Spaced Repetition Algorithm: This core function intelligently schedules reviews of learned material at increasing time intervals, based on how well you recall the information. Its value is in dramatically improving long-term knowledge retention, ensuring that coding best practices or system architecture concepts don't fade away.
· Note Ingestion: Allows users to easily add text-based notes, insights, and summaries from any learning source. The value here is a centralized repository for all your important learnings, making it easy to capture ideas as they arise, no matter the context.
· Scheduled Reminders: Delivers timely notifications to prompt users for review sessions. The application value is in proactively engaging users with their knowledge, preventing the passive loss of information and ensuring consistent learning.
· Progress Tracking: Provides insights into learning patterns and retention rates. The technical value is in offering data-driven feedback on learning effectiveness, allowing users to refine their study habits and maximize their learning efficiency.
Product Usage Case
· A developer learning a new framework like React. Instead of just reading documentation once, they input key concepts and code snippets into BetterSelf. The app reminds them to review specific hooks or state management principles over days and weeks, ensuring they master the framework rather than just skimming it. This helps them build more complex and robust React applications with confidence.
· A software architect studying complex distributed systems. They add notes on CAP theorem, eventual consistency, and message queues. BetterSelf prompts them to revisit these topics at strategic intervals, solidifying their understanding. This allows them to design more resilient and scalable systems by drawing on deeply ingrained knowledge, reducing costly design errors.
· A junior developer encountering new debugging techniques. They record the steps and logic behind effective debugging. BetterSelf ensures they repeatedly practice recalling these techniques. This leads to faster and more efficient problem-solving in their daily coding tasks, increasing their productivity and value to the team.
· A team lead who wants to share best practices with their team. They can use BetterSelf as a personal tool to reinforce their own understanding of leadership principles and technical standards. By having this knowledge readily accessible and well-retained, they can more effectively mentor and guide their team, fostering a culture of continuous improvement.
8
GlassSearch
Author
eightballsystem
Description
GlassSearch is a privacy-focused, transparent search engine that prioritizes user engagement over AI-driven results. Its core innovation lies in a clearly defined, observable algorithm that ranks search results based on title, snippet, click-through rate, and recency. This approach offers a refreshing alternative to AI-saturated search experiences, providing users with a more understandable and trustworthy way to find information.
Popularity
Points 1
Comments 4
What is this product?
GlassSearch is a search engine built from the ground up with transparency and user privacy as its guiding principles. Unlike many modern search engines that heavily rely on complex, opaque AI models to determine search results, GlassSearch employs a straightforward, visible algorithm. This algorithm considers factors like the relevance of the search term to the page title and description, how often users click on a particular result, and how recently the content was published. The 'no AI' stance means it's not trying to guess what you want or personalize results in ways that might compromise your privacy. So, what's in it for you? You get search results that are easier to understand and trust, without your data being constantly analyzed by AI.
How to use it?
Developers can use GlassSearch just like any other search engine, by visiting its homepage and entering their queries. The platform is designed to be accessible, requiring no special plugins or complex integration. Its core value for developers lies in its demonstration of a simpler, more transparent search indexing and ranking mechanism. This can serve as inspiration for building custom search solutions for internal projects, personal websites, or even as a backend for niche applications where AI-driven complexity is unnecessary or undesirable. Imagine building a specialized knowledge base for your team and wanting a search function that clearly shows why certain documents are prioritized – GlassSearch's philosophy provides a blueprint.
Product Core Function
· Transparent Ranking Algorithm: The algorithm that determines search result order is openly visible, allowing users to understand why certain links appear higher. This addresses the 'black box' problem of many search engines, providing predictability and trust, which is valuable for users who want to understand the 'why' behind their search results.
· Privacy-First Design: GlassSearch explicitly avoids AI in its search process and front-end, minimizing data collection and user tracking. This is crucial for users concerned about their digital footprint and the pervasive use of personal data by tech giants, offering peace of mind and a cleaner browsing experience.
· User Engagement as a Signal: The ranking heavily relies on user interaction metrics like click-through rates, indicating a focus on what users actually find valuable. This means results are more likely to be relevant and useful in a practical sense, directly benefiting users by surfacing content that others have found helpful.
· No Front-End JavaScript: This technical choice leads to faster page load times and reduced potential for browser-based tracking or malicious code execution. For users, this means a snappier and more secure browsing experience, and for developers, it showcases efficient web development practices.
Product Usage Case
· A developer building a personal portfolio website might use the principles behind GlassSearch to create a simple, self-hosted search for their blog posts, ensuring that the ranking logic is straightforward and easily maintainable, unlike relying on a complex external search service.
· An academic researcher looking for alternative search paradigms could use GlassSearch to understand how traditional relevance signals, combined with user feedback, can effectively surface information without the computational overhead and potential bias of AI models, helping them identify relevant literature more efficiently.
· A privacy-conscious individual who is tired of personalized advertising and AI-driven recommendations can use GlassSearch as their primary search engine, experiencing a cleaner, less intrusive way to find information, which directly translates to a more focused and less overwhelming online search experience.
9
LocalCopilot-API
Author
lbaune
Description
This project exposes your local Copilot (or similar AI code assistants) as a standard OpenAI-style API. This means you can integrate the power of your AI coding companion into any application or workflow that already talks to OpenAI's API, unlocking faster, more context-aware AI assistance directly within your development tools, without relying on external cloud services.
Popularity
Points 3
Comments 1
What is this product?
LocalCopilot-API is a clever wrapper that makes your locally running AI code assistant, like GitHub Copilot or other LLMs trained for code, accessible through a familiar API format, identical to the one OpenAI uses for its models (like GPT-3.5 or GPT-4). Think of it as building a bridge. Instead of your other tools having to learn a completely new way to talk to your local AI, they can just use the language they already know – the OpenAI API language. The innovation lies in abstracting the complexity of the local AI's interface and presenting it in a universally understood way, enabling seamless integration and allowing you to leverage the speed and privacy of local AI with the flexibility of cloud AI workflows. So, this means you get the benefits of a powerful AI coding assistant that understands your project context, runs on your machine for privacy and speed, and can be plugged into any existing system that supports OpenAI's API.
How to use it?
Developers can use this project by running the LocalCopilot-API server on their local machine. Once the server is running, they can configure their IDE extensions, command-line tools, or custom scripts to point to this local API endpoint instead of an external OpenAI API. For example, an IDE extension that normally calls `api.openai.com` can be reconfigured to call `http://localhost:PORT` (where PORT is the port your LocalCopilot-API server is listening on). The key is that the requests sent to your local server will mimic the structure of OpenAI API requests, and the responses will also be formatted in the same way. This makes it incredibly easy to swap out cloud-based AI services for your local AI assistant in any scenario where API compatibility is maintained. So, this means you can instantly upgrade your existing AI-powered developer tools with the capabilities of your local AI, enhancing productivity and control.
Product Core Function
· Local LLM Integration: Connects to various locally running AI models, including those optimized for code generation, allowing developers to utilize their preferred AI. This is valuable because it democratizes access to powerful AI capabilities, removing the reliance on expensive cloud services and offering more control over AI models.
· OpenAI-Compatible API: Emulates the standard OpenAI API, allowing any tool or application designed to work with OpenAI to seamlessly connect to the local AI. This is valuable because it enables a vast ecosystem of existing tools and integrations to be immediately leveraged with local AI, saving development time and effort.
· Customizable Toolchain Integration: Provides a flexible endpoint for integrating local AI assistance into custom scripts, build processes, or other developer workflows. This is valuable for automating tasks, generating code snippets, or providing context-aware help within specific development environments, boosting efficiency.
· Privacy and Speed Enhancement: By running the AI inference locally, this project significantly reduces latency and enhances data privacy, as sensitive code and project information never leaves the developer's machine. This is valuable for organizations with strict data security policies or developers who require the fastest possible AI response times.
· AI Model Agnosticism: Designed to be adaptable to different local AI models, offering developers the flexibility to choose and switch between various open-source or privately hosted LLMs. This is valuable for future-proofing and ensuring compatibility with evolving AI technologies.
Product Usage Case
· IDE Code Completion and Generation: An IDE extension that typically uses OpenAI's API for code suggestions can be reconfigured to use LocalCopilot-API. Instead of sending your code to OpenAI's servers, it sends it to your local machine, getting instant, context-aware code completions. This solves the problem of slow or privacy-concerning cloud-based code assistance, offering a faster and more secure alternative.
· Automated Code Review and Refactoring: A custom script that analyzes code for potential issues or suggests refactoring could be enhanced by calling LocalCopilot-API. The script sends code snippets to the local AI for analysis, receiving suggestions for improvements, which can then be automatically applied. This addresses the need for efficient, on-demand code quality checks within a development pipeline.
· Command-Line Interface (CLI) Tool Augmentation: A CLI tool for generating boilerplate code or performing specific code transformations can be integrated with LocalCopilot-API. Developers can invoke the CLI tool, which then leverages the local AI to generate complex code structures or implement specific logic based on user prompts, solving the problem of repetitive coding tasks.
· Internal Developer Tooling Integration: Companies can build internal tools that utilize their existing AI models for tasks like generating documentation, writing unit tests, or answering developer questions, all powered by LocalCopilot-API. This allows for highly customized and secure AI assistance tailored to the company's specific codebase and workflows.
10
Offline Ledger Companion
Author
sras-me
Description
This project is a minimalist, plain HTML accounting tool designed for personal finance tracking, especially when on the go. It addresses the inconvenience of entering financial transactions from mobile devices or when offline, by offering a web-based interface that stores data locally using the browser's IndexedDB. Its core innovation lies in its zero-backend architecture and seamless integration with cloud storage services for syncing, allowing users to manage their finances with flexibility and ease.
Popularity
Points 4
Comments 0
What is this product?
This project is a simple, client-side accounting application. It's built entirely with HTML, meaning it runs directly in your web browser without needing to install anything or connect to a server. The innovation here is its ability to function completely offline. All your financial transaction data is stored securely within your browser's local storage (specifically, IndexedDB). This means you can add expenses, income, and manage budgets even when you have no internet connection. For syncing data across multiple devices or backing it up, it cleverly utilizes free cloud services like getpantry.cloud or jsonbin.io by exporting and importing your encrypted financial data as a compressed JSON file. It also supports exporting your data in the standard ledger-cli format, allowing for advanced analysis with dedicated tools.
How to use it?
Developers can use this tool in several ways. The simplest is to visit the provided URL directly in their browser to start managing their personal finances immediately. Alternatively, they can download the plain HTML file and open it from their local file system, ensuring complete offline functionality. For data synchronization, developers can set up an account with a service like jsonbin.io or getpantry.cloud, create a data store (e.g., a 'bin' on jsonbin.io), and then configure the app to use the provided API endpoint and authorization headers in the 'remote' section of the application. This allows for seamless data backup and access from any device with a web browser. The app's input format is designed to be familiar to ledger-cli users, making it easy to adapt.
Product Core Function
· Offline Transaction Entry: The ability to record financial transactions anytime, anywhere, without an internet connection. This is valuable for capturing expenses immediately, even when traveling or in areas with poor connectivity, ensuring no financial detail is missed.
· Local Data Storage: Securely stores all financial data directly on the user's device using IndexedDB. This provides privacy and offline access, meaning sensitive financial information doesn't need to be constantly transmitted to a remote server.
· Cloud Syncing (via external services): Enables synchronization of financial data across multiple devices by exporting and importing encrypted JSON files to services like jsonbin.io or getpantry.cloud. This ensures data consistency and backup without requiring complex server setups.
· Ledger-CLI Data Export: Allows users to export their journal entries in the widely-used ledger-cli text format. This is crucial for users who want to leverage the powerful reporting and analytical capabilities of dedicated command-line accounting tools.
· Batch Transaction Entry with Auto-Calculation: Facilitates entering multiple transactions for the same date or using a common source account, with automatic calculation of missing amounts. This significantly speeds up the process of logging recurring or similar transactions.
· Basic Budget Tracking: Provides a simple mechanism to set monthly budget allocations and track spending against them, including carry-over from previous months. This offers a quick overview of financial health and helps manage spending proactively.
Product Usage Case
· A frequent traveler who needs to log expenses on the go: This tool allows them to enter receipts and spending directly from their phone, even on an airplane or in remote locations, then sync the data later when they have internet access.
· A developer who prefers plain text and command-line tools but needs a mobile-friendly interface for quick entries: They can use this HTML app for fast mobile data input and then export to ledger-cli format for in-depth analysis on their desktop.
· Someone concerned about data privacy and security: By storing data locally and only using encrypted exports for syncing, this app offers a higher degree of control over personal financial information compared to many cloud-only solutions.
· A user managing personal finances on multiple devices (e.g., laptop and tablet): The cloud sync feature allows them to maintain a consistent financial record across all their devices without manual file transfers.
11
CivitasForge: AI-Powered Civilization Blueprint Framework

Author
mnm
Description
This project, CivitasForge, is an experimental framework designed to leverage the power of advanced AI models, like Gemini Pro 2.5 and GPT-4, to conceptualize and stress-test societal blueprints. It acts as a 'Django for Civilization,' providing a structured approach to developing and refining ideas for societal organization, economics, and governance by simulating dialogues and critiques from historical figures and different perspectives. Its innovation lies in its meta-cognitive approach to problem-solving, using AI not just for generation but for rigorous evaluation and co-creation of complex systems.
Popularity
Points 3
Comments 1
What is this product?
CivitasForge is a conceptual framework that harnesses large language models (LLMs) to deeply analyze and iterate on ideas for building societies. Think of it like a sophisticated simulation tool for social engineering. Instead of writing code for a web application like Django, you're using AI's analytical and creative capabilities to 'code' or blueprint entire societal structures. The core innovation is using AI to embody different viewpoints – from historical economists like Adam Smith to modern political figures – to challenge, refine, and synthesize proposed societal models. This allows for rapid prototyping of ideas and identifying potential flaws or improvements before real-world implementation, essentially making complex social planning interactive and dynamically responsive.
How to use it?
Developers and thinkers can use CivitasForge by feeding its core documentation and their own societal concepts into an AI chat interface, such as Google AI Studio. The AI can then be prompted to explore these concepts from various angles, critique them using simulated historical or theoretical lenses, and even help synthesize alternative solutions. For instance, you could input a proposed economic policy and ask the AI, 'How would a neoclassical economist critique this?' or 'Generate a counter-argument from a socialist perspective.' The framework facilitates this by providing a structure for the AI to access and process information, enabling users to engage in high-level discourse and co-creation with the AI to design more robust and well-considered societal frameworks. The output can be used to refine proposals, generate detailed explanations, or even hypothesize practical implementations.
Product Core Function
· AI-driven Ideation and Synthesis: Leverages LLMs to generate novel ideas and synthesize complex concepts for societal structures. This is valuable for overcoming creative blocks and exploring a wider range of potential solutions for societal challenges.
· Simulated Critical Analysis: Uses AI to simulate dialogues and critiques from diverse perspectives, including historical figures and theoretical schools of thought. This helps identify weaknesses in proposed plans and encourages more resilient designs by preemptively addressing potential criticisms.
· Iterative Blueprint Refinement: Facilitates a cyclical process of proposing, evaluating, and refining societal blueprints. This means users can quickly iterate on ideas, making adjustments based on AI feedback, leading to more thoroughly developed and practical plans.
· Perspective Emulation: Enables users to ask AI to respond as specific individuals or ideological viewpoints. This is incredibly useful for understanding how different stakeholders might react to a proposal and for tailoring communication or policy accordingly.
· Knowledge Synthesis and Retrieval: The framework is designed to efficiently process and synthesize information from extensive documentation, allowing the AI to provide contextually relevant insights and explanations on demand, saving users significant research time.
Product Usage Case
· Scenario: A policy maker wants to design a new economic stimulus package. Using CivitasForge, they can feed their proposal into an AI chat and ask it to simulate a debate between Milton Friedman and John Maynard Keynes, identifying potential economic impacts and policy trade-offs based on each economist's known theories. This helps them craft a more balanced and effective stimulus plan.
· Scenario: A city planner is developing a new urban development strategy focused on sustainability. They can use CivitasForge to have the AI critique their plan from the perspective of an environmental ethicist and a historical urban planner like Robert Moses. This helps them anticipate challenges and incorporate more comprehensive environmental and social considerations into their strategy.
· Scenario: An academic researcher is exploring alternative governance models for a decentralized autonomous organization (DAO). They can use CivitasForge to have the AI generate hypothetical scenarios of how different historical political philosophers, like Machiavelli or Locke, would approach governing such an entity, informing the design of more robust and secure DAO structures.
· Scenario: A futurist is brainstorming solutions to global challenges like climate change. They can use CivitasForge to collaborate with AI, feeding it diverse data and asking it to hypothesize solutions, stress-testing them against simulated reactions from various global stakeholders and historical precedents to ensure feasibility and widespread acceptance.
12
AI Movie Trivia Engine
Author
indest
Description
An innovative iOS application that leverages AI to generate dynamic movie quizzes. It tackles the challenge of creating engaging and varied trivia by using sophisticated AI models to understand movie content and formulate questions, offering a fresh take on entertainment apps for movie buffs.
Popularity
Points 1
Comments 2
What is this product?
This project is an iOS app that uses Artificial Intelligence to create movie trivia quizzes. Instead of pre-written questions, the AI analyzes movie data and generates unique questions on the fly. The innovation lies in its ability to understand narrative, characters, and plot points to craft questions that are both challenging and relevant, offering a truly intelligent quiz experience. So, this means you get endless unique movie quizzes without repetitive questions, keeping the fun fresh every time you play.
How to use it?
Developers can integrate this engine into their own applications by accessing its API. It's designed to be a backend service that other apps can query to receive movie trivia questions and answers based on specific movies or genres. This allows for seamless integration into existing entertainment platforms or the creation of entirely new trivia-focused experiences. So, if you're building a movie app, you can easily add a fun trivia component without building the AI logic yourself.
Product Core Function
· AI-powered question generation: Utilizes advanced natural language processing and machine learning models to create contextually relevant movie trivia questions, providing dynamic and engaging content. This is useful for keeping users hooked with ever-changing challenges.
· Movie content analysis: The AI deeply understands plot, characters, and themes from movie databases to formulate accurate and insightful questions. This ensures the quizzes are meaningful and not just random facts.
· Customizable quiz parameters: Allows for the specification of movie genres, release years, or even specific films to tailor the quiz experience. This enables personalized trivia for individual user preferences or targeted content.
· Real-time question and answer delivery: Provides instant trivia questions and their corresponding answers, facilitating a smooth and interactive user experience. This means instant gratification and continuous gameplay.
· Cross-platform potential: While currently an iOS app, the underlying AI engine can be adapted for web or other mobile platforms. This opens up possibilities for broader application and wider audience reach.
Product Usage Case
· A social media platform could integrate this engine to create movie-themed challenges or polls, increasing user engagement by offering interactive content related to trending movies. This solves the problem of generic engagement tools by providing specific, fun content.
· A streaming service might use this to create in-app quizzes for their catalog, enhancing user discovery and retention by gamifying the movie-watching experience. This helps users explore more content in an enjoyable way.
· An educational app focused on film studies could use the AI to generate questions that test comprehension of cinematic elements and narrative structures. This provides a sophisticated learning tool for aspiring filmmakers or critics.
· A party game application could incorporate this engine to provide an endless stream of movie trivia for gatherings, ensuring consistent entertainment without manual question preparation. This eliminates the hassle of preparing game materials.
13
ChronoTune
Author
xSWExET
Description
ChronoTune is a web-based game where users listen to eight randomly selected songs and arrange them on a timeline according to their release dates. It's built as a playful exploration of temporal ordering and data visualization, offering a unique way to engage with music history and develop a sense of chronological awareness. The core innovation lies in its interactive application of data (song release dates) to a gamified experience, prompting users to deduce temporal relationships through auditory and deductive reasoning.
Popularity
Points 2
Comments 1
What is this product?
ChronoTune is an online game that tests your knowledge of music history by having you sort songs based on their release dates. You'll hear eight random songs and then need to place them in chronological order. The underlying technology uses a database of song release dates, fetched via APIs, and a user interface that allows for drag-and-drop manipulation of song elements on a visual timeline. The innovation here is turning a potentially dry data set into an engaging auditory and logical puzzle, encouraging users to intuitively grasp historical context through music.
How to use it?
Developers can use ChronoTune as an example of how to build engaging, data-driven web applications. Its core components, like API integration for song data, dynamic timeline rendering, and interactive user input handling, are transferable to many other projects. For instance, you could adapt the timeline concept to visualize project milestones, historical events, or even user journey progression. The game can be integrated into educational platforms or used as a fun way to explore specific music genres or eras. The underlying principle of mapping abstract data to an intuitive user experience is broadly applicable.
Product Core Function
· Song Selection and Playback: Randomly selects eight songs from a curated database and provides an audio player for users to listen. This addresses the need to efficiently present varied content for user interaction.
· Release Date Data Retrieval: Fetches accurate release dates for songs, likely through music metadata APIs. This demonstrates effective data sourcing and management for factual accuracy.
· Interactive Timeline Interface: Allows users to drag and drop song elements onto a visual timeline, representing their chronological placement. This showcases intuitive UI design for complex data ordering.
· Chronological Sorting Logic: Implements algorithms to compare user-placed song order against actual release dates to determine correctness. This highlights the technical implementation of validation and scoring.
· Gamified Feedback System: Provides immediate feedback on correct and incorrect placements, along with scoring. This illustrates how to create engaging user experiences through game mechanics.
· Endless Mode Variant: Offers an extended play option with increasing difficulty and a survival element. This demonstrates extensibility and replayability in application design.
Product Usage Case
· Educational Tool: A history teacher could use ChronoTune to create interactive lessons on music evolution for a specific decade, helping students understand the timeline of musical styles and artists. It solves the problem of making historical data engaging and memorable.
· Music Discovery Platform: A music streaming service could integrate a similar feature to allow users to explore artists or genres chronologically, revealing trends and influences. This addresses the challenge of presenting music discovery in a novel and informative way.
· Data Visualization Experiment: A developer interested in data visualization could fork ChronoTune to explore different ways of representing temporal data interactively, perhaps for historical timelines or scientific data sets. This provides a concrete example of applying chronological data to a visual medium.
· Personal Project Showcase: A web developer can use this as a reference for building a fun, interactive web application that demonstrates skills in front-end development, API integration, and game logic. It solves the problem of having a portfolio piece that is both technically sound and engaging.
14
RL-Viz: RL-Native Observability Framework
Author
kaushikbokka
Description
RL-Viz is an open-source observability framework built specifically for Reinforcement Learning (RL) ecosystems. It addresses the critical need for tools that understand RL primitives, providing live tracking, per-example inspection, and programmatic access to experiment runs. This allows developers to finally see what's happening during their RL training, debug issues effectively, and understand rollout quality, reward distributions, and failure modes, which are crucial for efficient and effective RL development.
Popularity
Points 3
Comments 0
What is this product?
RL-Viz is a specialized toolkit designed to give developers deep insights into their Reinforcement Learning (RL) experiments. Think of it like a dashboard for your RL AI. Standard tools often treat RL experiments like any other software, but RL has unique needs. RL-Viz understands concepts like rewards, actions, states, and environments, which are the building blocks of RL. Its innovation lies in its 'RL-native' approach, meaning it speaks the language of RL. This allows it to offer features like real-time monitoring of agent behavior, the ability to drill down into individual decision-making processes (per-example inspection), and the capability to retrieve this data programmatically for deeper analysis. So, for you, it means you can stop guessing why your RL agent isn't learning and start understanding the root cause of problems.
How to use it?
Developers can integrate RL-Viz into their existing RL training pipelines. This typically involves instrumenting their RL agent's code to send relevant RL-specific metrics and state information to RL-Viz's backend. The framework then provides a user interface (UI) and an API for visualization and analysis. You can use it to monitor live training sessions, pause and inspect specific agent decisions, and analyze historical runs to identify patterns or anomalies. Common integration points include popular RL libraries like Stable-Baselines3, Ray RLlib, or custom-built RL environments. So, for you, this means you can easily plug this into your current RL projects to gain immediate visibility without a massive rewrite.
Product Core Function
· Live Training Monitoring: Enables developers to observe their RL agent's behavior and performance in real-time as it learns. This is valuable because it allows for immediate detection of diverging or inefficient learning, helping to save computational resources and time.
· Per-Example Inspection: Allows developers to examine the specific decisions made by the RL agent for individual training examples (e.g., a single step in a game or simulation). This is crucial for debugging, as it helps pinpoint exactly why an agent made a particular choice, leading to more targeted improvements.
· Reward Distribution Analysis: Visualizes the distribution of rewards received by the RL agent over time. Understanding reward patterns is fundamental to RL, as it directly indicates how well the agent is achieving its goals and where it might be getting stuck.
· Failure Mode Identification: Helps to identify and categorize scenarios where the RL agent fails to perform as expected. This is invaluable for diagnosing complex problems and understanding the limitations of the current agent design or training strategy.
· Programmatic Data Access: Provides an API to access all observed RL experiment data programmatically. This empowers advanced users to perform custom analysis, build custom dashboards, or integrate RL-Viz data into other machine learning workflows for deeper insights.
Product Usage Case
· Debugging a game-playing AI: A developer is training an AI to play a complex video game and notices it gets stuck in a loop. Using RL-Viz, they can inspect the specific state, actions, and rewards at each step of the loop to understand the faulty decision-making process, allowing them to adjust the agent's reward function or training data. This helps them fix the bug faster and improve the AI's performance.
· Optimizing a robotic arm controller: A researcher is developing an RL agent to control a robotic arm for a manufacturing task. They observe that the robot's movements are jerky and inefficient. With RL-Viz, they can visualize the reward distribution and per-example trajectories, identifying specific movements that lead to low rewards. This insight allows them to refine the agent's policy to achieve smoother and more efficient robot arm control.
· Understanding a recommendation system's performance: A team is using RL to personalize content recommendations. They want to understand why certain users receive suboptimal recommendations. RL-Viz can help them analyze the sequence of actions (recommendations) and rewards (user engagement) for individual user sessions, revealing patterns in user behavior that the agent might be misinterpreting, leading to better recommendation strategies.
· Monitoring autonomous vehicle training: Engineers training an autonomous driving system can use RL-Viz to monitor the agent's decisions in various simulated scenarios. They can inspect specific 'critical moments' where the agent made a sub-optimal decision, such as a near-miss, to understand the contributing factors and improve safety protocols. This provides essential visibility into the complex decision-making process of safety-critical systems.
15
Flakegarden: Nix Flake Orchestrator
Author
createaccount99
Description
Flakegarden is a project inspired by shadcn/ui, aimed at simplifying the management and sharing of Nix flakes. It provides a structured and composable way to define, organize, and reuse Nix development environments and system configurations, making complex Nix setups more accessible and maintainable. The core innovation lies in its declarative approach to building and managing dependencies and configurations, allowing for reproducible and portable development environments.
Popularity
Points 2
Comments 0
What is this product?
Flakegarden is a tool that helps developers manage and share their Nix flakes. Nix is a powerful package manager and build system that allows for reproducible development environments. Flakes are a newer feature in Nix that make it easier to manage dependencies and configurations in a structured way. Flakegarden takes inspiration from shadcn/ui, a popular component library for React, by offering a similar philosophy of composability and easy integration. Essentially, it provides a standardized way to define, organize, and share reusable Nix environments and system configurations, much like a component library provides reusable UI elements. This means you can easily assemble complex development setups or server configurations from smaller, well-defined parts, ensuring that your environment is always the same, no matter where you run it. So, what's the value for you? It means less time spent fighting environment issues and more time coding, with the confidence that your project's dependencies and build process are consistent and reproducible.
How to use it?
Developers can use Flakegarden to define their project's Nix flakes in a clear and organized manner. By leveraging Flakegarden's structure, you can import and compose existing flakes for common tasks (like setting up a specific programming language environment, a database, or a CI/CD pipeline) and combine them with your project-specific configurations. This allows for rapid bootstrapping of new projects or complex system setups. Integration typically involves defining your project's flake.nix file using Flakegarden's conventions, specifying which existing flakes (or Flakegarden modules) to include and how to configure them. This makes it easy to share your development environment with team members or deploy your configurations consistently across different machines. So, what's the value for you? It means you can quickly spin up a perfectly configured development environment for any project, or deploy a consistent server setup, by simply composing pre-defined building blocks. It's like having a toolbox of ready-to-use environment configurations that you can assemble as needed.
Product Core Function
· Declarative Environment Composition: Define complex development environments by combining smaller, reusable Nix flakes. This provides a structured way to build up your project's dependencies and tools, making it easier to understand and manage. The value is in creating consistent and reproducible development setups, so you don't have to worry about 'it works on my machine' issues.
· Flake Sharing and Reusability: Easily share your well-defined Nix flakes with others or reuse them across multiple projects. This promotes collaboration and reduces redundant configuration efforts. The value is saving time and effort by leveraging existing, tested configurations.
· Modular System Configuration: Apply the same principles of composability to system-level configurations, allowing for declarative and reproducible server setups. This means you can manage your infrastructure in a code-like fashion, ensuring consistency and simplifying deployments. The value is in creating reliable and easily manageable infrastructure.
· Inspiration from shadcn/ui: Adopt a component-based philosophy for managing infrastructure and development environments, drawing parallels to how UI components are used in web development. This offers a familiar mental model for developers accustomed to modern front-end frameworks. The value is in providing an intuitive and modern approach to complex system management.
Product Usage Case
· Setting up a new Go project with a specific Go version, a PostgreSQL database, and necessary linters: A developer can use Flakegarden to compose a flake that includes a pre-built Go development environment flake, a PostgreSQL flake, and a linter configuration flake, all within their project's flake.nix. This solves the problem of manually installing and configuring each dependency, ensuring a consistent setup for all team members. The value is rapid project bootstrapping and consistent development tooling.
· Creating a reproducible Python development environment for a data science project: A data scientist can use Flakegarden to define a flake that specifies a particular Python version, along with common libraries like NumPy, Pandas, and Scikit-learn. This ensures that the environment is identical for everyone on the team, preventing version conflicts and making collaboration smoother. The value is in eliminating Python environment headaches and enabling seamless team collaboration.
· Deploying a web server with a specific Nginx configuration and a database service: A system administrator can use Flakegarden to define a server configuration that includes a managed Nginx instance and a database service, all declaratively defined. This allows for easily reproducible server deployments and simplifies updates or rollbacks. The value is in creating a robust and easily manageable infrastructure.
16
Enfyra: The Scalable Cluster-Native BaaS
Author
DustinPham12
Description
Enfyra is a Backends-as-a-Service (BaaS) platform designed to natively integrate with and scale within your existing Kubernetes clusters. It offers a suite of backend functionalities, abstracting away complex infrastructure management, allowing developers to focus on building their applications. The core innovation lies in its deep Kubernetes integration, enabling dynamic scaling and resource optimization directly from your cluster's capabilities, meaning your backend grows as your application needs do, seamlessly.
Popularity
Points 2
Comments 0
What is this product?
Enfyra is a cloud-native BaaS that runs inside your Kubernetes environment. Instead of relying on external, often vendor-locked BaaS providers, Enfyra deploys its services directly within your own infrastructure, managed by Kubernetes. This means it leverages the power and flexibility of Kubernetes for scaling, resilience, and resource allocation. It provides common backend functionalities like databases, authentication, and storage, all accessible via simple APIs. The innovation is in making these services truly cluster-native, ensuring they scale efficiently and cost-effectively by utilizing your cluster's existing resources, thus avoiding the typical performance bottlenecks and cost overhead of traditional BaaS solutions.
How to use it?
Developers can integrate Enfyra into their applications by deploying the Enfyra services within their Kubernetes cluster. Once deployed, they can access Enfyra's functionalities (e.g., database operations, user authentication, file storage) through its provided SDKs or direct API calls from their frontend or backend code. This allows for rapid application development without the need to provision and manage separate backend infrastructure. For example, a web application could easily connect to an Enfyra-managed database for data storage and an Enfyra authentication service for user sign-ups and logins, all running within the same Kubernetes cluster as the application itself.
Product Core Function
· Kubernetes-Native Database: Provides a managed database service that scales with your Kubernetes cluster, offering high availability and performance by leveraging the cluster's underlying resources. This means your data storage can grow seamlessly as your application's data load increases.
· Scalable Authentication Service: Offers a secure and scalable authentication and authorization system. It can handle a large number of users and requests by dynamically scaling its resources within your cluster, ensuring reliable user access for your application.
· Integrated File Storage: Delivers a robust and scalable object storage solution for your application's files. It's designed to integrate tightly with your cluster, ensuring that file storage needs are met efficiently as your application's data volume grows.
· Declarative Service Configuration: Allows developers to define and manage backend services using declarative configurations, similar to how they manage other Kubernetes resources. This simplifies deployment and management, allowing for repeatable and automated backend setups.
· Automated Scaling and Resource Management: Automatically scales backend services up or down based on demand and available cluster resources. This ensures optimal performance and cost-efficiency, as you only pay for the resources your backend actually uses.
Product Usage Case
· Developing a new SaaS application that requires a scalable database and user authentication. Enfyra can be deployed within the application's Kubernetes cluster, providing these backend services out-of-the-box, enabling rapid prototyping and deployment without managing separate database servers or authentication systems.
· Building a mobile application with a growing user base that needs reliable backend support for user data and file uploads. Enfyra's cluster-native approach allows the backend to scale automatically as the user base expands, ensuring a smooth user experience without manual infrastructure adjustments.
· Migrating an existing monolithic application to a microservices architecture on Kubernetes. Enfyra can provide managed backend services for individual microservices, simplifying their development and deployment and allowing them to scale independently within the cluster.
17
LazyArchon TUI
Author
ysaad
Description
LazyArchon is a lightweight, terminal-native user interface (TUI) designed to interact with the Archon project management backend. It provides a distraction-free, keyboard-centric way to manage your tasks and projects directly from your command line or IDE, eliminating the need to switch to a browser for quick updates.
Popularity
Points 2
Comments 0
What is this product?
LazyArchon is a Terminal User Interface (TUI) built with Go, utilizing the Bubble Tea framework. Its core innovation lies in providing a highly efficient, keyboard-driven interface for managing tasks within the Archon ecosystem. Instead of opening a web browser, which can be distracting and resource-intensive for simple actions, LazyArchon allows developers to stay in their development environment and manage project statuses, assignments, and details using swift keyboard commands. It's essentially a supercharged, text-based client for Archon that prioritizes speed and focus, inspired by the efficiency of tools like Vim.
How to use it?
Developers can use LazyArchon by installing it as a standalone binary. Once installed, they would typically launch it from their terminal, pointing it to their self-hosted Archon API instance (e.g., `lazyarchon --api-url http://localhost:8181`). The interface then presents projects and tasks in a structured, navigable format. Users can navigate between different views (projects, tasks, statuses) and perform actions like changing task statuses or assigning tasks using predefined keyboard shortcuts, similar to Vim's navigation. This allows for rapid task management without leaving the comfort of their terminal, ideal for developers who prefer a code-centric workflow.
Product Core Function
· Seamless Archon Integration: Connects directly to your Archon backend, allowing for real-time access to your projects and tasks without custom API coding. This means you can start managing your Archon data instantly.
· Vim-like Navigation: Utilizes familiar keyboard shortcuts (h, j, k, l) for fluid movement between projects, tasks, and different sections of the interface. This dramatically speeds up interaction for users accustomed to Vim or similar tools, reducing cognitive load.
· Efficient Task Status Updates: Easily change the status of tasks (e.g., from 'Todo' to 'Doing', 'Review', or 'Done') with simple key presses. This allows for quick progress tracking and keeps your project board up-to-date with minimal effort.
· Task Assignment: Quickly assign tasks to yourself or other team members directly from the terminal. This streamlines collaboration and ensures responsibilities are clear without context switching.
· Focused, Distraction-Free UI: Presents a clean, minimalist interface that keeps developers in their flow state by avoiding browser tabs, notifications, and unnecessary visual clutter. This promotes concentration and productivity.
· Cross-Platform Compatibility: Built in Go, LazyArchon provides a single binary that works seamlessly on Linux, macOS, and Windows. This ensures developers can use their preferred operating system without compatibility issues.
Product Usage Case
· A developer working on a feature can quickly update the status of related tasks to 'In Progress' using LazyArchon without breaking their coding flow or leaving their IDE's terminal. This maintains accurate project status with minimal interruption.
· During a code review, a developer can navigate through tasks marked for 'Review' in LazyArchon, change their status to 'Done' after approval, and then immediately switch to the next task, all via keyboard commands. This expedites the review process.
· A project manager can rapidly browse through all 'Todo' tasks across different projects in LazyArchon, identify bottlenecks, and assign urgent tasks to team members directly from their terminal during a quick check-in. This provides immediate visibility and actionability.
· When a bug is fixed, a developer can instantly move the corresponding task from 'In Progress' to 'In Review' using LazyArchon, ensuring the QA team is notified promptly without manual status changes in a web interface. This accelerates the bug resolution cycle.
18
Tempmail Mail Proxy
Author
rohitoc
Description
This project offers a novel approach to email management by acting as a proxy for your main email account. It's an experimental tool designed to filter and manage incoming emails before they reach your primary inbox. The innovation lies in its ability to intercept, analyze, and potentially categorize or discard emails based on predefined rules or AI-driven insights, all without exposing your primary email address to potential spam or phishing threats. So, this is useful for protecting your main inbox from unwanted messages and enhancing your privacy.
Popularity
Points 2
Comments 0
What is this product?
Tempmail Mail Proxy is a system that sits between the internet and your actual email server, like a smart gatekeeper for your emails. Instead of emails going directly to your Gmail or Outlook, they first go through this proxy. The proxy uses sophisticated techniques, potentially including natural language processing (NLP) and machine learning (ML) models, to understand the content and sender of each email. It can then decide whether to forward the email to your main inbox, put it in a separate folder, or discard it entirely. This provides an extra layer of intelligent filtering and privacy. So, this is useful because it proactively shields your primary inbox from spam, phishing attempts, and general clutter, while also potentially organizing your important emails.
How to use it?
Developers can integrate Tempmail Mail Proxy into their workflow by configuring their domain's Mail Exchanger (MX) records to point to the proxy service. The proxy then receives all incoming emails for that domain. Users can set up custom filtering rules, integrate with third-party services for deeper analysis (e.g., spam detection APIs), or leverage the proxy's built-in intelligent classification. For instance, an e-commerce business could use it to pre-filter customer inquiries, separating urgent issues from general feedback. So, this is useful for developers who want fine-grained control over their email flow, improved security, and automated email processing for their applications or personal use.
Product Core Function
· Email Interception and Forwarding: The proxy captures all incoming emails and intelligently decides whether to forward them to the designated primary inbox, providing a crucial layer of control. Its value is in preventing direct exposure of your main email to the wider internet.
· Intelligent Email Filtering: Utilizes advanced techniques to analyze email content, sender reputation, and patterns to categorize or discard unwanted messages, offering enhanced spam and phishing protection. This saves you time and reduces the risk of security breaches.
· Customizable Rule Engine: Allows users to define specific rules for email handling based on sender, subject, keywords, or other criteria, enabling personalized email management. This means you can tailor the filtering to your exact needs and preferences.
· Privacy Enhancement: Acts as a buffer, preventing direct contact with your primary email address from untrusted sources, significantly reducing the attack surface for malicious actors. This directly contributes to a more secure online presence.
· Potential AI-driven Categorization: May employ machine learning to automatically sort emails into categories (e.g., newsletters, important, personal), aiding in better organization. This streamlines your inbox and makes it easier to find what matters.
Product Usage Case
· A freelance developer signing up for numerous online services and forums can use Tempmail Mail Proxy to create temporary, disposable email addresses that all route through the proxy, ensuring their main inbox remains clean and protected from marketing spam. This solves the problem of a cluttered main inbox and potential security risks from disposable email addresses.
· An online business owner can configure the proxy to filter incoming customer support emails, prioritizing urgent requests based on keywords in the subject line and automatically flagging them for immediate attention, while less critical inquiries are batched for later response. This improves customer service response times and operational efficiency.
· A researcher testing web applications can use the proxy to capture all registration confirmation emails and password reset links generated during testing without revealing their personal email address, keeping their main inbox free from testing-related noise and ensuring secure handling of test credentials. This streamlines the testing process and maintains a clean development environment.
19
PyTorch Visualizer Engine
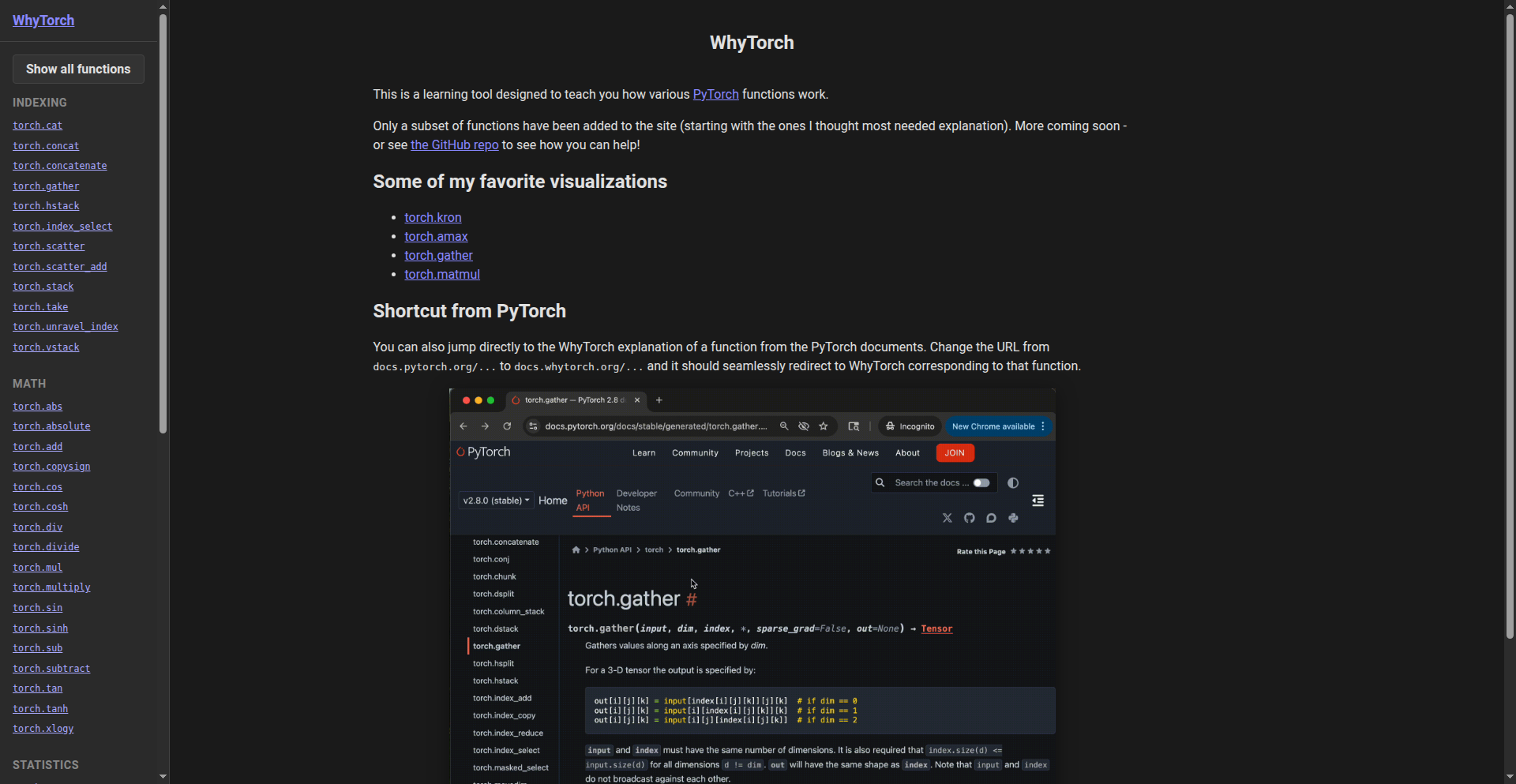
Author
kukanani
Description
WhyTorch is an open-source web application that demystifies complex PyTorch tensor operations. It visually illustrates the element-level relationships between input tensors and output tensors for PyTorch functions. By allowing users to interactively trace data flow, it makes understanding indexing, slicing, and broadcasting significantly more intuitive than traditional documentation. This helps developers quickly grasp how these fundamental operations work, accelerating their learning and debugging process.
Popularity
Points 2
Comments 0
What is this product?
WhyTorch is a web-based tool designed to make understanding PyTorch functions easier for developers. At its core, it employs a visual approach to explain how data moves through PyTorch operations. Imagine you have a specific PyTorch function, like `torch.gather` or `torch.scatter`. Instead of just reading text, WhyTorch shows you two boxes: one for your input data (a tensor) and one for the output data. Then, it draws lines and highlights elements to show exactly how each piece of input data ends up in a specific position in the output. You can click on any number in the output, and WhyTorch will show you which input numbers contributed to it, and vice versa. This visual mapping is the innovation, transforming abstract code into a clear, interactive diagram. So, this is useful because it helps you see the 'why' behind the results of PyTorch functions, making complex operations much easier to digest and learn, especially when reading documentation alone can be confusing.
How to use it?
Developers can use WhyTorch by visiting the open-source website. They can select a PyTorch function to explore, and the application will display sample input tensors and the resulting output tensor. The core usage involves clicking on elements within the input or output tensors. Clicking an output element reveals its origin in the input. Conversely, clicking an input element highlights all the output elements it influences. This interactive exploration can be integrated into a developer's learning workflow when encountering new or confusing PyTorch operations, or during debugging sessions to understand unexpected tensor transformations. It serves as an interactive complement to PyTorch's official documentation, offering a practical way to experiment and gain deeper insights into function behavior.
Product Core Function
· Interactive Tensor Visualization: Displays input and output tensors with clear visual cues, enabling developers to see data transformations directly. This helps understand the magnitude of changes and data flow, making debugging easier.
· Element-Level Tracing: Allows users to click on individual elements in input or output tensors to highlight their relationships, clarifying how specific values are processed and where they originate or end up. This directly answers 'how did this specific number get here?' for debugging purposes.
· Function-Specific Explanations: Provides visual explanations tailored to specific PyTorch functions, breaking down complex operations into understandable visual components. This accelerates learning by focusing on the unique mechanics of each function, reducing the time spent deciphering complex documentation.
· Cross-Referencing Input and Output: Enables seamless switching between understanding input's impact on output and output's derivation from input. This bidirectional understanding is crucial for grasping the full picture of a tensor operation, improving analytical skills.
Product Usage Case
· A machine learning engineer struggling to understand the `torch.gather` function's indexing mechanism. By using WhyTorch, they visually trace how the `index` tensor dictates which elements from the `input` tensor are selected into the `output`. This immediately clarifies the indexing logic, saving hours of manual calculation and documentation review. So, this helps them correctly implement gathering operations in their models.
· A new PyTorch developer is confused by `torch.scatter` and how it overwrites or adds values to an existing tensor. WhyTorch visually demonstrates how the `index` and `src` tensors determine which locations in the `input` tensor are updated and with what values. This practical visual aid helps them confidently use `scatter` for operations like updating embeddings or sparse data. So, this allows them to build more complex data manipulation pipelines.
· A researcher experimenting with advanced tensor manipulations in PyTorch finds that broadcasting is causing unexpected tensor shapes. By visualizing a broadcasting operation in WhyTorch, they can clearly see how dimensions are expanded and aligned, pinpointing the exact source of the shape mismatch. This visual debugging capability drastically reduces the time spent troubleshooting shape-related errors. So, this helps them ensure their tensor operations conform to expected dimensions.
20
AI Sessions MCP: Context Continuity Engine
Author
yoavfr
Description
AI Sessions MCP is a lightweight, local server designed to solve the frustrating problem of losing context when switching between different AI coding assistants like Claude Code, OpenAI Codex, and Gemini CLI. It achieves this by indexing and making searchable your past command-line sessions, allowing you to seamlessly pick up where you left off in any AI agent. So, this helps you avoid re-explaining your previous work and saves you significant time and mental effort.
Popularity
Points 2
Comments 0
What is this product?
AI Sessions MCP is essentially a smart indexer and retriever for your AI coding assistant interactions. When you use AI assistants in your command-line interface (CLI), they often generate session files that contain your prompts and the AI's responses. This project builds a small, local server that scans these session files for various AI tools (like Claude Code, OpenAI Codex, Gemini CLI, and opencode). It then creates an index, allowing you to search through your past conversations and retrieve them. The innovation lies in its ability to create a unified, searchable history across different AI tools, effectively creating a 'memory' for your AI development workflow. So, this provides a persistent memory for your AI coding sessions, ensuring you never truly lose your train of thought.
How to use it?
Developers can use AI Sessions MCP by cloning the GitHub repository and running the local MCP server. Once the server is running, you can interact with it via its API or through a simple CLI. For example, you can list all your indexed sessions, search for specific keywords or phrases within past interactions, and then open the full transcript of a chosen session. This project is designed to integrate with your existing AI development workflow, acting as a background service that enhances your interaction with different AI agents. So, you can easily bring up past discussions with AI assistants when needed, directly from your command line.
Product Core Function
· Session Indexing: Automatically scans and indexes session files from various AI coding assistants (Claude Code, Codex, Gemini CLI, opencode) to create a searchable database. This means your past AI conversations are not lost and can be revisited, saving you from repeating yourself.
· Session Listing: Provides a way to view all the indexed AI sessions, giving you an overview of your past work and discussions. This helps you quickly find the relevant context for your current task.
· Keyword Search: Enables searching through your entire history of AI interactions using keywords or phrases. This is crucial for finding specific solutions or ideas you might have explored previously, directly addressing the problem of forgotten details.
· Transcript Retrieval: Allows you to open and read the full, paged transcripts of specific AI sessions. This lets you dive deep into the context and details of a past interaction, ensuring you have all the information at your fingertips.
Product Usage Case
· Scenario: You were working on a complex bug with Codex yesterday, and today you need to resume that task with Claude Code. Instead of trying to remember all the details, you can use AI Sessions MCP to search for 'bug fix' and retrieve the exact session with Codex, then copy the relevant prompts and context into Claude Code. Problem Solved: Seamlessly transfers context between different AI tools, reducing ramp-up time and preventing context switching fatigue.
· Scenario: You've been experimenting with different prompt engineering techniques for generating marketing copy across multiple AI assistants over a week. AI Sessions MCP allows you to search for a specific phrase from a successful marketing campaign to quickly find the best performing prompts and regenerate similar content. Problem Solved: Acts as a centralized knowledge base for prompt experimentation, accelerating the iterative process of finding effective AI prompts.
· Scenario: You're a developer working on a feature that requires using different specialized AI models for code generation, documentation, and testing. AI Sessions MCP ensures that the context and insights gained from one AI interaction are easily accessible when you switch to another, preventing the need to re-explain your overall goal. Problem Solved: Facilitates efficient workflow across diverse AI-powered development tasks by maintaining a unified session history.
21
Squidly
Author
fralps
Description
Squidly is a dashboard that centralizes all your GitHub Actions workflows from multiple repositories. It provides insights into workflow performance, such as success/failure rates and potential bottlenecks, eliminating the need to constantly switch between different repositories. This offers a unified view for better management and understanding of your CI/CD pipelines, making it easier to spot issues and optimize your development processes.
Popularity
Points 2
Comments 0
What is this product?
Squidly is a developer tool designed to solve the problem of managing GitHub Actions workflows across numerous code repositories. Typically, developers have their CI/CD (Continuous Integration/Continuous Deployment) pipelines defined in YAML files within each GitHub repository. When working on multiple projects, it becomes cumbersome to track the status of these workflows, identify failures, or understand performance trends because you have to open each repository individually. Squidly addresses this by aggregating data from all your configured GitHub repositories into a single, intuitive dashboard. It uses the GitHub API to fetch workflow run information, allowing you to see everything at a glance. The innovation lies in its ability to provide a cross-repository overview, turning fragmented workflow statuses into actionable intelligence. So, this helps you by giving you a single pane of glass to monitor all your automated tasks, saving you time and reducing the frustration of manual checking.
How to use it?
Developers can integrate Squidly into their workflow by connecting it to their GitHub account. The tool will then pull in information about the GitHub Actions workflows configured in the repositories you grant it access to. You can use Squidly as a standalone web application or potentially integrate it with your existing developer dashboards. The primary use case is for teams or individual developers managing multiple projects with GitHub Actions. By having a centralized view, you can quickly identify which workflows are failing, which ones are taking too long (bottlenecks), and overall trends in your build and deployment processes. This allows for faster debugging and more proactive optimization of your CI/CD pipelines. So, this helps you by making it incredibly easy to keep an eye on all your automated processes without having to dig through individual project settings.
Product Core Function
· Centralized Workflow Dashboard: Consolidates all GitHub Actions workflow runs from multiple repositories into a single view. This provides an immediate overview of your entire CI/CD landscape, making it simple to see what's happening across your projects at any given time. The value is in saving you from repetitive manual checks across different project pages.
· Performance Insights: Offers analytics on workflow success rates, failures, and potential bottlenecks. This allows you to identify problematic workflows, understand common failure points, and pinpoint areas for optimization. The value is in helping you improve the reliability and efficiency of your automated development processes.
· Cross-Repository Monitoring: Enables monitoring of workflows without needing to navigate into each individual repository. This significantly reduces context switching and streamlines the process of keeping track of your CI/CD status. The value is in saving you considerable time and mental effort.
· Failure Analysis: Highlights specific workflow runs that have failed, providing details that aid in quick debugging. This accelerates the troubleshooting process, allowing you to fix issues faster and get back to developing. The value is in reducing downtime and speeding up issue resolution.
Product Usage Case
· Scenario: A developer working on a microservices architecture with 10+ independent GitHub repositories, each with its own deployment pipeline. Problem: Manually checking the status of each deployment pipeline after code commits is time-consuming and error-prone, leading to delays in identifying failed deployments. Solution with Squidly: Squidly provides a single dashboard showing the status of all 10+ pipelines. The developer can immediately see if any deployments have failed and investigate the specific error without opening each repository. This drastically speeds up the feedback loop and ensures faster resolution of deployment issues.
· Scenario: A team Lead managing a large open-source project with multiple contributors, where CI checks are critical for code quality. Problem: Without a centralized view, it's difficult to get a quick overview of the health of all CI checks across different branches or pull requests, making it hard to identify systemic issues. Solution with Squidly: Squidly aggregates the CI status of all configured workflows. The team lead can quickly spot trends like a specific test suite consistently failing across multiple repositories or branches, allowing them to address the root cause more efficiently. This leads to improved code quality and a more stable development environment.
· Scenario: An individual developer contributing to several side projects that all use GitHub Actions for automated testing and linting. Problem: Forgetting to check the status of a less frequently updated project's CI can lead to accumulated issues that are harder to fix later. Solution with Squidly: Squidly provides a constant, low-effort reminder of the status of all projects. The developer can easily see if any of their side projects have failed builds, prompting them to address the issues proactively rather than letting them pile up. This ensures that all projects remain in a healthy state.
22
FlixJoy-TasteMatch Engine
Author
albertpaulp
Description
FlixJoy is a movie discovery application that leverages a personalized taste-matching engine. It goes beyond simple genre filtering by analyzing implicit user preferences through movie interactions, aiming to surface films that truly resonate with an individual's unique cinematic palate. The core innovation lies in its ability to infer nuanced tastes rather than relying on explicit declarations, thereby solving the common problem of being overwhelmed by choice yet still struggling to find genuinely enjoyable content.
Popularity
Points 1
Comments 1
What is this product?
FlixJoy-TasteMatch Engine is a smart movie recommendation system that learns what you like by observing your behavior, not just by asking you to check boxes. Instead of just recommending movies based on the genres you say you enjoy, it analyzes how you interact with movies (like if you finish them, rewatch scenes, or what you skip) to build a deeper understanding of your unique preferences. The innovative part is its 'implicit preference inference' mechanism, which makes recommendations feel more intuitive and less like generic suggestions. So, what's in it for you? It means you'll spend less time searching and more time watching movies you'll genuinely love.
How to use it?
Developers can integrate FlixJoy's taste-matching engine into their own platforms, such as streaming services, media libraries, or even personalized content dashboards. It can be used via an API, allowing your application to send user interaction data (e.g., movie ID, watch duration, completion status, skip events) to the engine. The engine then returns a ranked list of recommended movies tailored to that specific user's inferred tastes. This means you can quickly enhance your own app with a powerful recommendation feature without building a complex AI system from scratch. The practical application is creating a more engaging user experience by consistently showing them content they're likely to enjoy.
Product Core Function
· Implicit Preference Inference: This function analyzes user interaction data (e.g., watch time, completion rate, skip patterns) to build a nuanced profile of a user's taste without explicit input. This helps surface movies that align with subtle preferences, meaning you get recommendations that feel uncannily accurate.
· Personalized Ranking Algorithm: Based on the inferred preferences, this algorithm ranks potential movie suggestions from most to least likely to be enjoyed by the user. This ensures that the most relevant choices are always presented first, saving you time and frustration in finding your next watch.
· Dynamic Taste Evolution: The engine continuously updates a user's taste profile as they interact with more content, ensuring that recommendations adapt to changing preferences over time. This means the system stays relevant as your tastes evolve, so you're always discovering new favorites.
· API-driven Integration: Provides a clean API for other applications to send user data and receive personalized recommendations, making it easy to integrate this advanced recommendation capability into existing platforms. Developers can leverage this to quickly add sophisticated recommendation features to their apps, enhancing user engagement.
Product Usage Case
· A new indie streaming service wants to differentiate itself by offering highly personalized recommendations. They integrate FlixJoy's TasteMatch Engine by sending user watch data to the API. The engine returns tailored movie suggestions, leading to increased user retention as viewers find content they truly enjoy, solving the problem of generic recommendations common on larger platforms.
· A personal media library application aims to help users rediscover forgotten films. By connecting user viewing history (e.g., watched, not finished, rewatched segments) to FlixJoy's engine, the app can proactively suggest movies that align with the user's past viewing habits, even if they haven't explicitly added them to a watchlist. This helps users overcome content fatigue and rediscover films they might have forgotten they'd like.
· A content curation platform wants to provide users with daily movie picks. They use the FlixJoy engine to analyze a user's recent viewing behavior and generate a daily personalized recommendation. This provides a high-value, individualized service that keeps users coming back for more, solving the challenge of providing fresh, relevant content consistently.
23
PyDepends: Universal Dependency Injection
Author
eric-hermosis
Description
PyDepends is a lightweight, standalone dependency injection system designed to bring the elegant dependency injection patterns found in web frameworks like FastAPI to any Python project. It focuses solely on injecting dependencies, offering a clean and bug-free solution without the overhead of type checking or specific ORM/data validation requirements. This allows developers to easily manage and reuse complex object instances across their applications, making code more modular, testable, and maintainable. So, what's in it for you? You get cleaner, more organized code that's easier to understand and update, saving you time and effort in the long run.
Popularity
Points 2
Comments 0
What is this product?
PyDepends is a minimalist Python library that implements dependency injection. Think of dependency injection as a way to give your code the 'ingredients' it needs to run without that code having to go out and find those ingredients itself. For example, if a function needs to talk to a database, instead of the function creating its own database connection (which can be complex and hard to manage), dependency injection allows you to 'give' it a pre-configured database connection. The innovation here is that PyDepends extracts this powerful concept from frameworks like FastAPI and makes it available as a simple, single-file package. This means you can apply the same clean, modular design principles to any part of your Python application, not just your web APIs. So, what's in it for you? You get to build more robust and easier-to-manage applications by separating concerns and making your code more flexible.
How to use it?
Developers can integrate PyDepends into their projects by simply installing it and then using its core functionalities to register and resolve dependencies. For instance, you might register a database connection or a logging service as a dependency, and then later request that dependency in any part of your application where it's needed. This is done through a simple registration and retrieval mechanism. It supports both synchronous and asynchronous code, allowing for seamless integration into modern Python applications. So, what's in it for you? You can easily inject reusable components or configurations into any function or class, leading to less boilerplate code and better organization.
Product Core Function
· Dependency Registration: Allows developers to define and 'register' objects or services that can be injected into other parts of the application. The value here is in centralizing the creation and management of shared resources, ensuring consistency and making them easily accessible. This is useful for managing database connections, API clients, or configuration settings.
· Dependency Resolution: Enables any part of the application to 'request' and receive an instance of a registered dependency. The value lies in decoupling components; a piece of code doesn't need to know *how* to create a dependency, only that it needs one. This improves testability and modularity. A common scenario is injecting a data access object into a business logic service.
· Sync and Async Support: Provides a unified interface for both synchronous and asynchronous Python code. This is valuable for modern applications that often mix blocking and non-blocking operations, ensuring consistent dependency management across different execution contexts. This is particularly helpful when working with web frameworks that handle asynchronous requests.
Product Usage Case
· Managing Database Connections in a backend service: A developer can register a single database connection pool using PyDepends and then inject it into multiple data access classes or service layers. This avoids creating redundant connections and ensures efficient resource utilization. The problem solved is managing shared resources effectively and preventing resource leaks.
· Injecting Configuration Objects: In a complex application, configuration settings might be loaded from various sources. PyDepends can be used to register a fully resolved configuration object, which can then be injected into any module that needs access to settings. This simplifies configuration management and makes it consistent across the application.
· Testing components in isolation: During unit testing, instead of using actual external services (like a real database or API), developers can use PyDepends to inject mock or stub versions of these dependencies. This allows for faster and more reliable testing of individual code units without external side effects.
24
Namo Semantic Turn Detector
Author
arjunkava
Description
A high-performance, semantic turn detection system designed for real-time applications. This project leverages advanced natural language processing (NLP) techniques to accurately identify and signal conversational 'turns' (i.e., when one speaker stops and another is about to start). Its innovation lies in its semantic understanding, moving beyond simple audio cues to grasp the meaning behind speech, offering a more robust solution for applications like voice assistants, transcription services, and collaborative tools. So, this is useful because it allows software to understand when people are talking in a conversation more naturally, making interactions smoother and more accurate.
Popularity
Points 2
Comments 0
What is this product?
Namo Semantic Turn Detector is a sophisticated system that uses artificial intelligence, specifically Natural Language Processing (NLP), to figure out when one person finishes speaking and another is about to begin in a conversation. Unlike systems that just listen for pauses, this detector analyzes the *meaning* of the speech. It understands the context and the flow of dialogue to make a more intelligent guess about who is next to talk. The innovation here is its 'semantic' capability, meaning it understands the 'why' and 'what' of the conversation, not just the 'when' of silence. This makes it much more reliable and insightful. So, this is useful because it's like giving your software a better ear for conversation, making it understand the rhythm of human interaction more deeply and accurately.
How to use it?
Developers can integrate Namo Semantic Turn Detector into their applications via its API. It typically takes audio streams or transcribed text as input and outputs signals indicating turn changes. This could be used to trigger actions in a voice assistant, manage speaker diarization in transcription software, or control user interfaces in collaborative meeting platforms. The system is designed for high performance, meaning it can process conversations in real-time with low latency. So, this is useful because developers can easily add intelligent conversation awareness to their apps, enabling features that respond dynamically to who is speaking and when.
Product Core Function
· Semantic Turn Identification: The system analyzes the linguistic content of speech to predict speaker changes, going beyond simple audio cues for increased accuracy. This is valuable for building truly intelligent conversational agents. The application scenario is voice assistants or chatbots that need to seamlessly switch between responding to user queries.
· High-Performance Processing: Optimized for speed and low latency, allowing for real-time analysis of conversations. This is crucial for applications requiring immediate feedback, such as live transcription or interactive voice response systems. The application scenario is enabling smooth, uninterrupted user experiences in real-time communication tools.
· Contextual Understanding: The detector considers the semantic context of the dialogue to make more informed turn-taking decisions. This means it can better handle complex conversational flows and overlapping speech. The application scenario is improving the accuracy of meeting summarization or customer service call analysis.
Product Usage Case
· Real-time Transcription Services: Integrating Namo to accurately segment audio into distinct speaker segments, enabling better transcription accuracy and speaker attribution. This solves the problem of unclear speaker changes in automated transcriptions, making them more useful for analysis and record-keeping.
· Interactive Voice Assistants: Using the turn detection to understand when a user has finished speaking and the assistant should respond, leading to a more natural and less frustrating user experience. This addresses the issue of voice assistants cutting users off or responding too late, improving usability.
· Collaborative Meeting Software: Employing the detector to manage screen sharing or annotation rights based on who is currently speaking, ensuring a smoother and more efficient meeting flow. This resolves the challenge of chaotic interaction management in virtual meetings where it's unclear who should be actively contributing.
25
Imbi-Automations
Author
crad
Description
Imbi-Automations is an open-source workflow engine that orchestrates complex, coordinated changes across an entire codebase, leveraging AI and a graph-based representation of projects and their dependencies. It solves the problem of managing and evolving large, interconnected software systems by providing a centralized control plane for configurations, deployments, and operational changes, significantly reducing the time and effort required for tasks like code migration, version upgrades, and standards compliance.
Popularity
Points 2
Comments 0
What is this product?
Imbi-Automations is an advanced workflow engine designed for managing and transforming large software codebases. At its core, Imbi builds a comprehensive 'knowledge graph' that maps every project, service, database, and dependency within your organization. Think of it as a digital map of your entire software ecosystem. This graph is then used by Imbi Automations to intelligently target specific projects based on criteria like programming language, version, or type. It then executes automated workflows that combine AI capabilities with traditional developer tools to apply consistent changes at scale. The innovation lies in its ability to understand the relationships between different parts of your system and execute coordinated, impactful updates, transforming manual, time-consuming tasks into automated processes. This means developers can focus on building new features rather than wrestling with legacy systems or complex migrations.
How to use it?
Developers can integrate Imbi-Automations into their development and operations pipelines. It's particularly useful for organizations with hundreds or thousands of repositories. You can configure Imbi to understand your project structure and dependencies. Then, you define 'automations' – sequences of actions that Imbi will execute. For example, if you need to upgrade all Python projects from version 3.9 to 3.12, you would define an automation that targets all Python projects, uses AI to identify and apply necessary syntax updates, updates tooling, and ensures adherence to your defined project standards. This can be triggered manually or integrated into CI/CD pipelines. The value proposition is that instead of manually touching each project, you define the change once, and Imbi applies it everywhere it's relevant, saving countless hours of developer time and reducing errors.
Product Core Function
· Automated Code Migration: Imbi can automate the migration of hundreds of projects between different version control systems (e.g., GitLab to GitHub) and transform associated CI/CD pipelines (e.g., GitLab CI to GitHub Actions). This saves significant manual effort and reduces the risk of errors during transitions.
· Language and Version Upgrades: It automates the process of upgrading projects to newer language versions (e.g., Python 3.9 to 3.12), ensuring all projects adopt the latest syntax, tooling, and project standards efficiently, preventing months of manual work.
· AI-Powered Code Analysis and Documentation: Imbi leverages AI (like Claude Code) to scan projects and automatically generate comprehensive documentation files (e.g., AGENTS.md). This helps ensure projects are well-documented and ready for AI agents to work on them, improving collaboration and understanding.
· Standards Compliance and Enforcement: The system automatically scans projects for compliance with defined standards and can update project metadata with the results. This ensures consistency across the codebase and helps maintain quality and security.
· Dependency and Infrastructure Management: Imbi can update critical infrastructure components like base Docker images across all projects rapidly. This allows for quick adoption of security patches or updated base images, a process that typically takes months manually.
Product Usage Case
· Migrating hundreds of repositories from GitLab to GitHub: Imbi-Automations was used to automate the entire process, including transforming GitLab CI pipelines to GitHub Actions, saving a substantial amount of engineering time and ensuring a smooth transition for a large organization.
· Upgrading all Python projects from version 3.9 to 3.12: Instead of individual developers manually updating their projects, Imbi-Automations applied the necessary syntax and tooling changes across the entire Python codebase, drastically reducing the upgrade time from months to a much shorter period.
· Generating Agent Readiness Documentation: Imbi scanned all projects and used AI to create detailed AGENTS.md files. This makes it easier for AI agents to understand and contribute to different projects, accelerating AI integration into the development workflow.
· Ensuring Standards Compliance for all Projects: Imbi continuously scans projects for adherence to company standards and automatically updates project facts. This provides an ongoing mechanism for quality assurance and allows for rapid identification and remediation of non-compliance issues.
· Rapidly updating Docker Images: Imbi-Automations updated the base Docker images for all projects in minutes. This is critical for quickly rolling out security patches or adopting new base image features across a large number of services, which would otherwise be a very slow and labor-intensive process.
26
VibeJSON: The Emotionally Intelligent JSON Validator
Author
avh3
Description
VibeJSON is a novel JSON validator that doesn't just check syntax, but also infers the 'vibe' or intended sentiment of your JSON data. It leverages natural language processing (NLP) techniques, applied directly to JSON string values, to assess emotional tone and flag potentially problematic or unusually 'vibey' data structures. This moves beyond traditional validation to offer a deeper understanding of data's intended meaning and potential impact. So, what's the use for you? It helps you catch not just syntactical errors, but also potential misinterpretations or unintended emotional cues in your data, making your applications more robust and user-friendly.
Popularity
Points 2
Comments 0
What is this product?
VibeJSON is a JSON validator with a twist: it's 'vibe-coded'. Unlike standard validators that only check if your JSON structure is correct (like making sure all the commas and brackets are in the right places), VibeJSON also analyzes the text within your JSON values. It uses Natural Language Processing (NLP) to understand the sentiment or emotional tone of these strings. Think of it as a spellchecker for your data's feelings. The innovation lies in applying NLP directly to JSON content to identify potentially awkward, negative, or surprisingly positive 'vibes' in your data. So, what's the use for you? It's like having an extra layer of data quality control that helps you ensure your data not only makes technical sense but also aligns with the intended emotional context of your application.
How to use it?
Developers can integrate VibeJSON into their workflow in several ways. You can use it as a standalone command-line tool to validate JSON files before committing them or deploying them. It can also be integrated into CI/CD pipelines to automatically check the 'vibe' of incoming data. For web applications, it can be used on the backend to validate user-generated JSON content, ensuring it's not only syntactically correct but also emotionally appropriate for your platform. The core idea is to treat your JSON data not just as raw information, but as communication. So, what's the use for you? By embedding VibeJSON in your development process, you can proactively catch data that might cause user confusion or negative sentiment, leading to a better user experience and more trustworthy applications.
Product Core Function
· Vibe Analysis: Analyzes string values within JSON to determine sentiment (positive, negative, neutral, or specific emotions). This adds a layer of qualitative assessment to data validation, making it useful for understanding user feedback or content moderation. So, what's the use for you? It helps you understand the emotional undercurrents in your data.
· Customizable Thresholds: Allows developers to set their own thresholds for what constitutes an 'unacceptable' vibe, enabling fine-grained control over data quality. This means you can tailor the validation to the specific needs and sensitivities of your project. So, what's the use for you? You get to decide what 'good vibes' means for your data.
· Syntax Validation: Includes traditional JSON syntax validation to ensure structural correctness. This provides the foundational reliability you expect from any validator. So, what's the use for you? It guarantees your JSON is technically sound.
· Error Reporting with Context: Provides detailed error messages that include both syntax issues and 'vibe' discrepancies, along with context. This makes debugging faster and more intuitive. So, what's the use for you? It tells you exactly what's wrong and why, in plain language.
Product Usage Case
· Validating user comments submitted in JSON format for a social media platform to filter out negativity or hate speech before it's displayed. This solves the problem of needing to manually review content by providing an automated 'vibe' check. So, what's the use for you? It helps keep your platform safe and welcoming.
· Analyzing product review data stored in JSON to identify trends in customer sentiment, allowing businesses to quickly gauge customer satisfaction without deep manual dives. This helps in proactively addressing customer concerns. So, what's the use for you? It gives you quick insights into what your customers are feeling.
· Ensuring configuration files in JSON format don't contain unintentionally alarming or ambiguous messages that could confuse end-users or system administrators. This prevents operational mishaps due to misinterpretation. So, what's the use for you? It ensures your system configurations are clear and safe.
· Processing chatbot conversation logs (in JSON) to detect negative user interactions that might require follow-up or indicate issues with the bot's responses. This helps in improving chatbot performance and user satisfaction. So, what's the use for you? It helps you make your AI companions better communicators.
27
Melony: Real-time AI-Generated React UI Streamer
Author
ddaras
Description
Melony is an experimental project that streams AI-generated React UIs in real-time. Instead of manually coding every component, it leverages AI to generate UI elements and layouts dynamically, then streams these updates directly to your browser. This tackles the time-consuming nature of front-end development by offering a novel approach to rapid prototyping and UI generation, allowing developers to see AI-driven UI changes as they happen.
Popularity
Points 2
Comments 0
What is this product?
Melony is a demonstration of how AI can be integrated into the front-end development workflow to generate React User Interfaces (UIs) dynamically and stream these changes live. The core innovation lies in the AI's ability to interpret prompts or design specifications and translate them into actual React code, which is then processed and sent to a web browser. Think of it like having an AI co-pilot that can draw UI components for you in real-time as you describe them, without needing a traditional coding loop. This significantly speeds up the ideation and iteration process for UI design and development.
How to use it?
Developers can integrate Melony by setting up the backend AI model to receive design instructions (e.g., text descriptions, basic wireframes, or even other code snippets) and generate React code. This generated code is then streamed to a frontend application that interprets and renders these React components. The primary use case is for rapid prototyping, where developers can quickly visualize different UI ideas by simply describing them to the AI and seeing the results instantly. It can also be used for generating boilerplate UI code or exploring different design variations with minimal manual effort.
Product Core Function
· Real-time UI generation: Leverages AI to create React components and layouts on the fly, allowing for immediate visualization of design ideas. This means you can describe a button and see it appear instantly, saving you the time of writing the code yourself.
· AI-powered component creation: The AI interprets user input (like text descriptions) and translates it into functional React code, abstracting away much of the manual coding effort. So, instead of typing `const Button = () => <button>Click me</button>`, the AI can generate this for you based on your description.
· Live streaming of UI updates: Changes made by the AI are streamed directly to the browser, enabling a dynamic and iterative design process. You don't need to refresh your page to see the AI's latest creation; it appears as it's generated.
· Experimental integration with AI models: Explores novel ways to connect AI capabilities with front-end development frameworks, pushing the boundaries of what's possible in automated UI design. This is about exploring new possibilities and finding smarter ways to build UIs.
· Prompt-based UI design: Enables developers to describe desired UI elements or layouts using natural language or structured prompts, making the design process more intuitive and accessible. You can tell the AI 'create a card with an image and some text' and it will do it.
Product Usage Case
· Rapid prototyping of web applications: A developer can quickly generate a series of different landing page layouts by simply describing each version to Melony. This allows for much faster exploration of design directions compared to manual coding.
· Iterative UI design with AI feedback: A designer can use Melony to generate initial UI mockups, and then provide feedback to the AI to refine them in real-time. For example, 'make the header larger' or 'add a sidebar' can be processed instantly.
· Educational tool for learning React and AI integration: Students can use Melony to understand how AI can generate code and how that code can be rendered in a web browser, providing a hands-on learning experience for modern development techniques.
· Generating boilerplate UI for common patterns: Instead of writing the same basic form or navigation bar code repeatedly, a developer could use Melony to generate these common patterns quickly based on specific requirements, saving considerable development time on repetitive tasks.
· Exploring novel UI interactions: Developers can experiment with AI-generated dynamic interfaces where elements respond to user input in unpredictable yet functional ways, opening up new possibilities for interactive web experiences.
28
Zhi - Zero-Trust Encrypted Messaging
Author
txthinking
Description
Zhi is a groundbreaking end-to-end encrypted messaging application built on a zero-trust architecture. This innovative approach ensures that no single party, not even the service provider, can access the content of your messages. It leverages advanced cryptographic techniques to guarantee user privacy and data integrity, addressing the critical need for secure communication in an increasingly data-sensitive world. So, this is useful because it provides unparalleled privacy for your conversations, meaning your messages are truly yours and protected from unauthorized access.
Popularity
Points 2
Comments 0
What is this product?
Zhi is an end-to-end encrypted messaging application that fundamentally operates on the principle of zero-trust. This means that instead of trusting a central server to manage and protect your messages, Zhi distributes trust and verification across the network. The core innovation lies in its decentralized key management and the robust implementation of symmetric and asymmetric encryption. Every message is encrypted before it leaves your device and can only be decrypted by the intended recipient, using keys that are securely managed and never exposed to the Zhi servers. This contrasts with traditional messaging apps where the service provider often holds the keys or can potentially access message content. So, this is useful because it offers a higher level of security and privacy than typical messaging apps, ensuring your sensitive conversations remain confidential.
How to use it?
Developers can integrate Zhi's core messaging and encryption functionalities into their own applications or services. This can be achieved by utilizing Zhi's open-source libraries or APIs, which are designed for ease of integration. For example, a developer building a secure internal communication platform for a company could leverage Zhi to ensure all internal communications are end-to-end encrypted without needing to build complex encryption infrastructure from scratch. Alternatively, a developer could fork the project and extend its features, perhaps adding richer media support or custom notification systems, all while inheriting the strong security guarantees. So, this is useful because it allows developers to quickly add robust, secure messaging to their projects, saving significant development time and effort while ensuring high security standards.
Product Core Function
· End-to-End Encryption: Messages are encrypted on the sender's device and decrypted on the recipient's device, ensuring only the intended parties can read them. This protects against eavesdropping by network intermediaries or the service provider. The value is in absolute message privacy.
· Zero-Trust Architecture: No single entity, including the service provider, is inherently trusted with message content. This enhances security by distributing trust and requiring verification at multiple points. The value is in preventing single points of failure and ensuring data sovereignty.
· Decentralized Key Management: Encryption keys are managed and distributed in a secure, often peer-to-peer, manner. This means keys are not stored centrally, reducing the risk of mass data breaches. The value is in enhanced resilience and security of cryptographic keys.
· Secure Messaging Protocol: A custom or well-established secure protocol is used for message transmission, ensuring integrity and authenticity. This guarantees that messages are not tampered with during transit and originate from the claimed sender. The value is in reliable and trustworthy communication.
· Privacy-Preserving Metadata: Efforts are made to minimize or obfuscate any metadata associated with messages, further protecting user privacy. This limits the information that could be gleaned about who is communicating with whom and when. The value is in comprehensive privacy protection beyond just message content.
Product Usage Case
· Building a secure whistleblowing platform: A journalist could use Zhi to create a secure channel for anonymous sources to submit sensitive information, ensuring the conversations are completely private and untraceable. This addresses the critical need for source protection in journalism.
· Developing a secure internal team communication tool: A company dealing with highly sensitive intellectual property or client data could integrate Zhi into their internal chat application. This would ensure that all internal discussions remain confidential and protected from corporate espionage or accidental leaks. This solves the problem of secure internal collaboration.
· Creating a secure voting or consultation system: For organizations that need to conduct sensitive polls or consultations, Zhi could form the backbone of a system where participant responses are encrypted and anonymous, ensuring the integrity and privacy of the outcome. This addresses the challenge of trustworthy anonymous feedback.
· Enabling secure communication for healthcare professionals: Doctors and nurses could use a Zhi-based app to discuss patient cases, ensuring HIPAA compliance and patient confidentiality. This solves the problem of secure and compliant communication in a regulated industry.
29
Global Prayer Map
Author
lukethedev
Description
Global Prayer Map is a real-time, interactive web application that allows users to anonymously share prayer requests, which are then visualized on a live map. It addresses the need for connection and support by fostering a global community around shared intentions, emphasizing privacy and accessibility.
Popularity
Points 2
Comments 0
What is this product?
Global Prayer Map is a web-based platform designed to connect people through prayer. Users can submit a prayer request, and this request is displayed as a point on a world map without revealing their personal location. The core technology involves a frontend interface for submission and display, likely using a mapping library (like Leaflet or Mapbox GL JS) and a backend to store and serve prayer requests. The innovation lies in its real-time, anonymous, and geographically distributed nature, creating a sense of shared humanity and collective support. So, what's in it for you? It offers a way to anonymously express your needs and connect with others globally, finding solace and support without compromising your privacy. It's a digital space for empathy and encouragement, making the world feel a little smaller and more connected.
How to use it?
Developers can integrate the concept of anonymized, location-based data sharing into their own applications. For example, a community organizing tool could use this model to show where local needs are arising without tracking individuals. The frontend can be built with standard web technologies (HTML, CSS, JavaScript frameworks like React or Vue), and the backend could utilize databases like PostgreSQL with PostGIS for geospatial queries or NoSQL databases for simpler data storage. A developer could also extend this by adding features like categories for prayer requests, sentiment analysis of requests, or even localized prayer groups. So, how can you use this? Imagine building an application that visualizes crowd-sourced environmental data or citizen science observations in real-time, or a platform for anonymous reporting of community issues, all while respecting user privacy.
Product Core Function
· Anonymous Prayer Request Submission: Users can submit prayer requests without any personal identification, ensuring privacy. This allows individuals to openly share their concerns, needs, or gratitude. So, what's in it for you? You can express your thoughts and feelings without fear of judgment or exposure.
· Live Map Visualization: Submitted prayer requests are displayed as markers on an interactive world map, showcasing the global reach of these intentions. This creates a visual representation of shared human experiences. So, what's in it for you? You can see the collective needs and hopes of people worldwide, fostering a sense of global community and shared purpose.
· Real-time Updates: The map dynamically updates to show new prayer requests as they are submitted, reflecting the ongoing nature of human concerns and support. So, what's in it for you? You witness the immediate impact of collective prayer and support in a live, evolving environment.
· Privacy-Focused Design: The platform intentionally avoids saving user locations or personal information, prioritizing user safety and anonymity. So, what's in it for you? You can engage with the platform with complete peace of mind, knowing your personal data is protected.
Product Usage Case
· A developer could adapt this model to create a crisis reporting tool where citizens anonymously report local issues (e.g., potholes, damaged infrastructure) on a map, allowing authorities to visualize problem areas without identifying the reporters. This helps in efficient resource allocation and community problem-solving. So, how does this help you? It provides a direct, anonymous channel to report issues that affect your community, leading to faster resolution.
· A social impact organization could use a similar approach to visualize real-time humanitarian needs in different regions, allowing donors and volunteers to see where support is most critical. This increases transparency and effectiveness in aid distribution. So, how does this help you? You can contribute to meaningful causes with greater confidence, knowing where your help is most needed.
· An educational platform might use this concept to display anonymous student questions or points of confusion on a topic, allowing instructors to gauge understanding and address common difficulties across a virtual classroom. So, how does this help you? It provides an anonymous way to seek clarification without feeling singled out, ensuring everyone gets the support they need to learn.
30
AI Brand Sentinel
Author
maxprehoda
Description
AI Brand Sentinel is a novel platform designed to monitor and optimize how your brand is represented in AI-generated responses. It tracks mentions across various AI platforms like ChatGPT, Claude, and Gemini, and also scans social media and review sites. The innovation lies in its ability to not only alert you to mentions but also to help generate content that AI crawlers are more likely to reference, thereby automating SEO fundamentals and improving your brand's visibility in the burgeoning AI ecosystem. It addresses the critical gap of businesses lacking insight and control over their AI presence.
Popularity
Points 1
Comments 1
What is this product?
AI Brand Sentinel is a pioneering tool that acts as your brand's guardian in the age of artificial intelligence. At its core, it leverages sophisticated web scraping and natural language processing (NLP) techniques to continuously scan major AI models (like ChatGPT, Claude, Gemini) and a wide array of online platforms (social media, review sites) for mentions of your brand. The key innovation is its proactive approach: it doesn't just report; it empowers you to influence AI perception. It achieves this by analyzing what AI systems discuss and then generating content that aligns with these patterns, effectively guiding AI crawlers to reference your brand more favorably. This means you gain visibility and a mechanism to improve your brand's reputation and discoverability within AI-driven information dissemination, solving the problem of an opaque and uncontrollable AI presence.
How to use it?
Developers can integrate AI Brand Sentinel into their existing marketing and SEO workflows. The platform provides a dashboard for real-time monitoring of brand mentions across AI and social platforms, allowing for immediate engagement or strategic response. For content creators and SEO specialists, the 'AI-aware content generation' feature helps produce articles and other materials that are more likely to be picked up and cited by AI models. This can be integrated into content calendars and publishing pipelines. Furthermore, an API is available for connecting AI Brand Sentinel with other marketing automation tools, enabling a more unified approach to online reputation management and AI-driven SEO. The practical application is to ensure your brand is accurately and favorably represented whenever an AI is asked about your industry or related topics.
Product Core Function
· AI Mention Monitoring: Tracks brand appearances in AI responses from platforms like ChatGPT, Claude, Gemini, providing visibility into AI-driven brand perception. This is valuable for understanding how AI models interpret and present your brand to users.
· Social and Review Platform Alerting: Scans social media (Reddit, X, Instagram, TikTok) and review sites (Yelp, Google Reviews) for brand mentions, enabling timely engagement and reputation management. This helps you actively participate in conversations about your brand online.
· AI-Optimized Content Generation: Creates relevant content (articles, descriptions) designed to be more appealing to AI data crawlers, increasing the likelihood of your brand being referenced. This directly boosts your brand's visibility in AI search results and recommendations.
· Automated SEO Fundamentals: Automates tasks like article creation and backlink suggestion, which are crucial for improving your website's ranking and authority in search engines, including those powered by AI. This streamlines your SEO efforts and enhances organic discoverability.
· Performance Dashboard: Provides a centralized view of mention frequency, sentiment, and context across all monitored channels, offering actionable insights into your AI and online presence. This allows you to measure the impact of your efforts and identify areas for improvement.
Product Usage Case
· A SaaS company experiencing a dip in brand mentions in AI chatbot responses. Using AI Brand Sentinel, they identified that their competitors were frequently appearing in answers related to specific industry pain points. By leveraging the AI-optimized content generation, they created blog posts addressing these pain points, which were then picked up by AI models, leading to a significant increase in their brand's appearance in AI-generated solutions.
· An e-commerce business noticing negative sentiment in user reviews on platforms like Reddit and Google. AI Brand Sentinel alerted them to these mentions, allowing their customer support team to promptly address customer concerns and engage in conversations. This real-time intervention helped mitigate negative impacts and improve overall brand perception.
· A marketing agency looking to offer advanced AI SEO services to clients. They use the API to integrate AI Brand Sentinel into their client reporting dashboards, providing clients with a clear overview of their AI presence and a strategy for improvement, thereby differentiating their service offering.
31
RevenuePerDownload Explorer
Author
buraste
Description
This project analyzes mobile app data to uncover the true value of apps, focusing on Revenue Per Download (RPD) instead of just download numbers. It identifies apps that are generating significant income with a smaller user base, revealing hidden gems and market opportunities. So, this is useful because it helps you understand which apps are actually making money, guiding you towards more profitable app development or investment decisions.
Popularity
Points 2
Comments 0
What is this product?
RevenuePerDownload Explorer is a tool that estimates the revenue generated by mobile apps based on their app store category rankings, estimated download numbers, and prevailing market trends. Unlike traditional analytics that solely highlight download counts, this tool focuses on RPD, a metric that reflects how much money each download is worth. The innovation lies in its ability to surface apps with high RPD, indicating strong monetization strategies and user engagement, even if their overall download numbers are not astronomical. So, this is useful because it provides a more accurate picture of an app's financial success and potential, helping you identify overlooked profitable niches.
How to use it?
Developers and investors can use this tool by exploring the data to identify app categories or specific apps that demonstrate high RPD. You can filter apps by age, competition level, and category to discover profitable niches. For example, a developer looking for their next app idea can search for categories with high RPD and low competition. It can be integrated into a research workflow to validate market demand and potential profitability before committing to development. So, this is useful because it allows you to make data-driven decisions about app creation and investment, increasing your chances of success.
Product Core Function
· Estimate app revenue using category rankings and download data: This function uses sophisticated algorithms to infer revenue, providing a proxy for actual earnings. This is valuable for understanding an app's financial performance without direct access to its internal data.
· Calculate Revenue Per Download (RPD) for thousands of apps: This core metric directly shows how much value each user brings in terms of revenue. It's crucial for identifying efficient monetization strategies and high-value user bases.
· Filter apps by age, competition level, and category: This allows for targeted analysis, helping users find specific opportunities within defined market segments. This is useful for pinpointing underserved or highly profitable niches.
· Highlight apps making significant revenue with minimal users: This feature uncovers the 'hidden champions' of the app market, apps that are highly efficient in their monetization. This provides inspiration and validation for lean, profitable app development.
Product Usage Case
· A developer looking for a new app idea can use this tool to discover that a niche flight tracker app with very few reviews is generating substantial monthly revenue. This suggests a high RPD within that specific app category, indicating a potentially profitable area to explore. This solves the problem of finding a market with proven demand and monetization potential.
· An investor can analyze a list of apps and identify a reference app with a moderate number of downloads but a very high monthly revenue. This insight, powered by the RPD metric, reveals that the app has a highly engaged and monetizable user base, making it a potentially attractive investment. This addresses the need to identify financially successful apps beyond surface-level download metrics.
· A game developer can find a zombie game from Hong Kong that earns $22 per user. This specific RPD data points to a highly effective monetization strategy for that particular game and region, offering valuable insights for designing in-app purchases or subscription models for their own games. This helps in understanding successful monetization patterns in different markets.
32
LLM Hallucinated WebApp Engine
Author
unbehagen
Description
This project is a proof-of-concept web server that uses a Large Language Model (LLM) to simulate a dynamic web application. Instead of actually building the backend logic, the LLM generates HTML responses based on a prompt describing the desired app, request path, and URL parameters. This allows for rapid prototyping and idea validation by 'hallucinating' a functional frontend, significantly reducing initial development time and enabling quick iteration on product concepts.
Popularity
Points 2
Comments 0
What is this product?
This is an LLM-powered web server that pretends to be a real web application. It works by taking a prompt that describes what your app should do and then, for each incoming web request, it asks the LLM to generate the HTML for the next page. It remembers only the last page's HTML, the URL path, and any parameters you passed. This forgetfulness is by design to keep things simple and focused on rapid generation. The core innovation is using an LLM to bypass traditional frontend/backend development for early-stage idea testing, enabling you to see a simulated version of your app almost instantly, even though the response time is slower than a real app. So, what's in it for you? You can quickly visualize and test product ideas without writing any code, speeding up the innovation cycle.
How to use it?
Developers can use this project to quickly spin up a simulated version of their web application idea. You provide a detailed prompt to the LLM describing your app's purpose, user flow, and desired UI elements. The project then acts as a web server that intercepts requests. For each request, it feeds the LLM the current context (last HTML, path, parameters) and your app description, prompting it to generate the subsequent HTML. This can be integrated by simply pointing your browser to the running server and interacting with the hallucinated app. It's ideal for quickly demonstrating concepts to stakeholders or exploring different UI/UX possibilities before committing to full development. So, how can this help you? You can rapidly prototype user interfaces and test product flows without writing a single line of backend code, saving significant development effort in the early stages.
Product Core Function
· LLM-driven HTML generation: Uses an LLM to dynamically generate HTML content for web pages, allowing for rapid creation of app interfaces without traditional templating. This is valuable for quickly visualizing application logic and user experience.
· Stateful (limited) context retention: Retains only the last generated HTML, the request path, and URL parameters to inform the LLM's next generation. This simple state management helps the LLM maintain some continuity in the 'hallucinated' app, providing a more coherent user experience for testing.
· Prompt-based application definition: Defines the web application's behavior and appearance through a single, descriptive prompt to the LLM. This allows for flexible and easy modification of app ideas by simply changing the prompt, offering a quick way to iterate on product concepts.
· Simulated web server: Acts as a web server that responds to HTTP requests, mimicking the behavior of a deployed web application. This is useful for creating interactive demos and prototypes that can be accessed via a browser.
Product Usage Case
· Rapid prototyping of e-commerce product pages: A developer could prompt the LLM to create a product detail page for an online store, including images, descriptions, and an 'add to cart' button. The LLM would then generate the HTML for this page, allowing for immediate review of the layout and flow before actual backend integration. This solves the problem of needing to see a visual representation of a product page quickly.
· Testing different user onboarding flows: For a new SaaS product, a developer could use this to simulate multiple variations of an onboarding wizard. By adjusting the prompt, they can quickly generate different sequences of screens and instructions, allowing them to test which flow is most intuitive and effective without building each step. This addresses the challenge of exploring multiple user experience pathways efficiently.
· Creating interactive mockups for client presentations: Instead of static wireframes, a designer could use this to create a simple, interactive mockup of a mobile app feature. The LLM could generate screens for user interaction, allowing a client to click through a simulated experience and provide more informed feedback. This solves the need for more engaging and realistic client demonstrations.
· Exploring alternative API response simulations: Developers testing a frontend that consumes a specific API can use this to simulate various API responses. By crafting prompts that describe the expected JSON structure and content, the LLM can generate HTML that reflects how the frontend would render different data scenarios, helping to identify potential display issues early. This tackles the problem of needing to test frontend behavior with diverse data without setting up a full mock API.
33
Sora2VideoAI-Cleaner
Author
bingbing123
Description
This project is an experimental AI-powered tool designed to automatically remove dynamic watermarks from AI-generated videos, specifically those from Sora2. It leverages frame-level detection and maintains temporal consistency across video frames to intelligently identify and smooth out watermark areas, resulting in a cleaner video output. The core innovation lies in its approach to AI-driven video cleanup, offering creators a more efficient way to refine their visual content without manual intervention. This is useful for anyone who needs to repurpose or enhance AI-generated videos that have embedded dynamic watermarks.
Popularity
Points 2
Comments 0
What is this product?
Sora2VideoAI-Cleaner is a novel AI application that tackles the problem of dynamic watermarks appearing on AI-generated videos, such as those from Sora2. Traditional methods for removing watermarks can be tedious and time-consuming, especially when the watermark moves or changes throughout the video. This tool employs advanced AI techniques, specifically frame-level detection to pinpoint the watermark's location in each video frame and then utilizes temporal consistency to ensure the removal process is smooth and natural across consecutive frames. This means it doesn't just blur a watermark; it intelligently reconstructs the underlying image based on surrounding frames, creating a visually cohesive result. This approach is innovative because it moves beyond simple static removal to a dynamic, intelligent cleanup, offering a significant improvement in video editing efficiency and quality for AI-generated content.
How to use it?
Developers can use Sora2VideoAI-Cleaner as a tool to process their AI-generated videos. The project is built with Python, OpenCV for image processing, and incorporates lightweight diffusion-based filters. For integration, developers could potentially build a web pipeline where videos are uploaded, processed by the Python backend that runs the cleaner, and then the cleaned video is made available for download. This would be particularly useful in content creation workflows where rapid iteration and cleanup of AI-generated assets are crucial. The project is also open to community feedback on integrating real-time processing, suggesting that future versions might offer even faster processing for web applications.
Product Core Function
· Dynamic watermark detection: The system identifies watermarks that shift or animate across video frames, making it effective for complex AI-generated content. This provides value by automating a labor-intensive part of video editing.
· Frame-level analysis and temporal consistency: By examining each frame and ensuring continuity between them, the tool ensures that watermark removal is seamless and doesn't introduce jarring artifacts. This leads to a professional-looking output without manual frame-by-frame adjustments.
· AI-based video restoration: The core function uses AI to not just erase but also to intelligently reconstruct the video content behind the watermark, maintaining visual integrity. This is valuable for preserving the artistic intent of the AI-generated video.
· Python and OpenCV implementation: The project is built on widely adopted and powerful open-source libraries, making it accessible for developers to understand, modify, and integrate into their own projects. This fosters community collaboration and further innovation.
Product Usage Case
· A content creator generates multiple AI videos for a social media campaign but finds that the embedded watermarks detract from the professional look. Using Sora2VideoAI-Cleaner, they can quickly process these videos, removing the watermarks to create a more polished and engaging final product, saving hours of manual editing.
· A developer building an AI video editing platform wants to offer a feature for cleaning up AI-generated content. They can integrate Sora2VideoAI-Cleaner into their backend pipeline, providing their users with an automated way to remove dynamic watermarks, thereby enhancing their platform's capabilities.
· A researcher studying the output of AI video generation models wants to objectively analyze the generated content without the distraction of watermarks. They can use the tool to clean the videos for clearer visual analysis, aiding in their research.
34
Qatsi: Hierarchical Argon2id Passphrase Generator
Author
renecoignard
Description
Qatsi is a novel passphrase generator that leverages the Argon2id hashing algorithm to create a hierarchy of secure, deterministic passphrases. Instead of relying on random character generation, Qatsi derives passphrases from a master secret and a hierarchical path, ensuring that each generated passphrase is unique and securely linked to its parent. This approach significantly enhances security by making passphrases resistant to brute-force attacks and enabling a structured, manageable approach to password management.
Popularity
Points 1
Comments 0
What is this product?
Qatsi is a deterministic passphrase generator that uses Argon2id, a highly secure hashing algorithm, to create a structured set of passphrases. Imagine a tree where each branch represents a different service or account. You start with one main secret (like the root of the tree), and then you navigate down the branches using specific paths to generate a unique passphrase for each service. The innovation here is that it's not random; it's derived from your master secret and the path you choose. This means if you know the master secret and the path, you can regenerate the exact same passphrase every time. The use of Argon2id is crucial because it's designed to be very resistant to specialized hardware attacks, making brute-force attempts incredibly difficult and resource-intensive. So, for you, this means incredibly strong, unguessable passphrases that are also logically organized and reproducible.
How to use it?
Developers can integrate Qatsi into applications where robust and structured password generation is required. The core idea is to use a single, highly secure master secret and define hierarchical paths for different user accounts or services. For instance, a user might have a path for their 'email' service, another for 'banking', and specific sub-paths for individual banks or email providers. When a user needs a passphrase for a new service, Qatsi can generate it based on the master secret and the corresponding path. This can be used in password managers, secure identity systems, or even for generating API keys. The integration would involve providing the master secret and the desired path to the Qatsi library, which then returns the generated passphrase. This offers a unified and secure way to manage credentials across multiple platforms, reducing the risk of weak or reused passwords.
Product Core Function
· Hierarchical Passphrase Generation: Creates a unique passphrase for each specific application or service based on a master secret and a navigational path. This is valuable because it allows for a structured and organized approach to password management, ensuring that each credential is distinct and linked to its intended use, reducing the risk of password reuse.
· Argon2id Hashing Integration: Employs Argon2id, a modern and highly secure hashing algorithm, to derive passphrases. This is valuable for security-conscious applications as Argon2id is designed to be computationally expensive for attackers to crack, offering superior protection against brute-force and dictionary attacks compared to older algorithms.
· Deterministic Output: Generates the same passphrase every time for a given master secret and path combination. This is valuable for reproducibility and recovery; if a passphrase is lost, it can be regenerated using the original secret and path, eliminating the need for complex reset procedures.
· Customizable Path Structure: Allows users to define their own hierarchical paths to organize passphrases. This is valuable for personalization and logical organization, enabling users to tailor their password structure to their specific needs and mental models for managing digital identities.
Product Usage Case
· Password Manager Enhancement: A password manager could use Qatsi to generate unique, strong passphrases for each website the user visits, derived from a single master password. This solves the problem of users having to create and remember many different complex passwords for various online accounts.
· Secure API Key Generation: For developer tools or services that require API keys, Qatsi can generate hierarchical and deterministic keys tied to specific projects or environments. This simplifies key management and ensures that if a key is compromised, only a specific, limited-scope key is affected, not a master key.
· Multi-Factor Authentication Seed Generation: Qatsi could be used to generate a deterministic seed for time-based one-time password (TOTP) generators. This means a user's TOTP authenticator app could be backed up and restored by simply saving the master secret and the derivation path, rather than relying on fragile QR codes or cloud backups.
· Developer Credential Management: In a development environment, Qatsi can create distinct, secure credentials for accessing different databases, cloud services, or internal tools, all derived from a single developer secret. This streamlines secure access management for development teams and reduces the security risk associated with shared or weak credentials.
35
PromptPal: The AI System Prompt Catalog
Author
xakpc
Description
PromptPal is a curated collection of effective system prompts for various AI models. It addresses the challenge of prompt engineering by providing pre-tested, categorized prompts that unlock specific AI capabilities. The innovation lies in the systematic organization and sharing of these prompt 'recipes,' reducing the trial-and-error for developers seeking to leverage AI for diverse tasks.
Popularity
Points 1
Comments 0
What is this product?
PromptPal is a digital library of system prompts, which are special instructions given to AI models like large language models (LLMs) to guide their behavior and output. Think of them as pre-written 'cheat codes' for AI. The innovation is in its structured approach to cataloging and sharing these prompts, making it easier for developers to discover and utilize the most effective instructions for tasks ranging from creative writing to code generation. This saves immense time compared to figuring out the right instructions from scratch.
How to use it?
Developers can use PromptPal by browsing the catalog to find prompts relevant to their specific AI project. For example, if you need an AI to act as a helpful customer service agent, you can search for 'customer service persona' prompts. You can then copy and paste these prompts into your AI model's input to immediately benefit from its specialized capabilities. It can be integrated into workflows by bookmarking useful prompts or building custom prompt sets for recurring tasks. This allows developers to quickly set up the desired AI behavior for their applications.
Product Core Function
· Prompt Discovery: Enables users to search and filter a growing database of system prompts based on AI task and desired output. This is valuable because it quickly surfaces effective prompt strategies, saving developers hours of experimentation.
· Prompt Categorization: Organizes prompts into logical categories (e.g., creative writing, coding assistance, data analysis). This is valuable as it provides a structured way to explore AI capabilities and find prompts tailored to specific domains.
· Prompt Sharing and Collaboration: Allows community members to contribute and upvote prompts. This is valuable for fostering a collaborative environment, leading to a more comprehensive and refined collection of prompt engineering best practices.
· Prompt Versioning and Feedback: Offers a mechanism to track prompt iterations and gather user feedback. This is valuable for refining prompt effectiveness over time and ensuring users are employing the most robust instructions.
Product Usage Case
· Scenario: A developer building a content generation tool needs an AI that can write engaging blog posts. By using PromptPal, they can find and adapt a 'blog post writer' prompt, immediately improving the quality and creativity of the generated content without extensive prompt tuning.
· Scenario: A data scientist is experimenting with an LLM for sentiment analysis and struggles to get accurate results. PromptPal offers a collection of 'sentiment analysis' prompts, providing them with proven instructions that significantly enhance the AI's ability to correctly identify sentiment in text.
· Scenario: A game developer wants to use an AI to generate character backstories. PromptPal's 'creative writing' or 'character generation' prompts can be quickly applied, enabling the AI to produce richer and more detailed backstories with less effort from the developer.
· Scenario: A student learning about AI prompt engineering can use PromptPal to understand how different prompts influence AI behavior, providing practical examples and accelerating their learning curve.
36
FormForge
url
Author
darkhorse13
Description
FormForge is an open-source alternative to Typeform, focusing on empowering developers to build highly customizable and data-rich forms. Its innovation lies in a modular architecture and deep integration possibilities, allowing for complex logic, custom branding, and seamless data flow directly into developer workflows. This solves the problem of rigid, templated form builders by offering a developer-centric platform that prioritizes flexibility and control.
Popularity
Points 1
Comments 0
What is this product?
FormForge is a developer-focused, open-source platform for creating interactive forms. Unlike traditional form builders that offer limited customization, FormForge is built with a modular system. This means developers can easily extend its functionality, integrate it with their existing backend systems, and apply unique styling. Its core innovation is the ability to treat forms not just as data collection tools, but as dynamic interfaces that can trigger complex workflows and provide rich user experiences. So, this is useful for you because it gives you complete control over your forms, allowing them to do more than just collect information, but also act as integral parts of your applications.
How to use it?
Developers can use FormForge by either self-hosting the core engine or integrating its API into their applications. The platform provides a developer kit (SDK) for building custom form components and integrating with various databases, analytics tools, or other services. Common integration scenarios include embedding forms into web applications for user feedback, lead generation, or event registration, with real-time data synchronization to a chosen backend. So, this is useful for you because you can easily plug FormForge into your existing projects, making data collection and user interaction a seamless part of your development process.
Product Core Function
· Modular Form Builder: Allows developers to assemble forms from reusable components, offering flexibility in design and functionality. This provides value by enabling rapid creation of unique form experiences tailored to specific needs, applicable in any scenario requiring custom data input.
· Customizable UI/UX: Enables complete control over the visual appearance and user interaction flow of forms, going beyond basic styling. This adds value by allowing brands to maintain consistent identity and improve user engagement through polished and intuitive interfaces, useful for marketing and user experience design.
· API-First Integration: Designed with a robust API for seamless integration with backend services, databases, and third-party tools. This is valuable for developers needing to automate data processing and connect form submissions to existing workflows, essential for any application relying on real-time data and automation.
· Extensible Component System: Developers can build and deploy their own custom form elements to extend the platform's capabilities. This is useful for creating highly specialized forms that cater to niche requirements or complex data entry tasks, valuable in specialized industries or for advanced applications.
· Open-Source Community Support: Benefits from community contributions and transparency, fostering rapid development and issue resolution. This offers value through access to a collaborative ecosystem and a platform that is constantly being improved, making it reliable and adaptable for long-term use.
Product Usage Case
· Customer Feedback Loop Enhancement: A SaaS company integrates FormForge into their product to gather detailed user feedback after feature releases. They use custom form components to collect specific usage data alongside qualitative comments, which are then automatically piped into their CRM and analytics dashboard. This solves the problem of generic feedback forms by providing actionable insights for product improvement.
· Interactive Product Demos: An e-commerce startup uses FormForge to build an interactive product recommendation quiz. Users answer a series of questions, and the form dynamically presents product suggestions based on their choices, with the results directly updating a personalized landing page. This enhances customer engagement and drives conversions by offering tailored product discovery.
· Event Registration with Dynamic Pricing: An event organizer uses FormForge to manage registrations for a multi-day conference. The form logic adjusts ticket prices based on the user's selected workshops and early bird discounts, and automatically syncs registrant data with their event management system and payment gateway. This streamlines the registration process and reduces manual error in complex pricing scenarios.
· Internal Tool Development: A development team builds a custom bug reporting form using FormForge that includes integrated code snippet editors and automatic environment variable capture. This allows developers to submit detailed and context-rich bug reports directly into their issue tracker, improving debugging efficiency and collaboration.
37
Jilebi: AI-Driven Plugin Sandbox Runtime
Author
datron
Description
Jilebi is an innovative MCP runtime designed to sandbox plugins, offering robust management of permissions, environment variables, and plugin state. This allows developers to securely integrate and run third-party or AI-generated code within an MCP server environment. The core innovation lies in its ability to abstract away complex server setup, enabling developers to focus on code creation and leveraging community-built or AI-generated plugins with ease and safety. So, this product helps developers build and deploy AI agents and MCP plugins more efficiently and securely, by abstracting away infrastructure concerns and providing a controlled execution environment. This means less time spent on setup and more time on innovation, with the added benefit of safely using external code.
Popularity
Points 1
Comments 0
What is this product?
Jilebi is an MCP (Machine Code Processor, though the context suggests it's more of a general-purpose agent/plugin framework) runtime that acts as a secure playground for plugins. Think of it like a specialized operating system for AI agents and their tools. It ensures that each plugin, whether developed by the community or generated by an AI from a specification, runs in isolation. This isolation prevents any malicious or buggy code from affecting the main server or other plugins. Jilebi manages what resources a plugin can access, like files or network connections, and controls its environment. The key technical insight here is creating a flexible and secure abstraction layer for plugin execution, which is crucial for building complex, modular AI systems. So, what this does for you is provide a safe and standardized way to run code, especially AI-generated code, without the usual risks and setup headaches.
How to use it?
Developers can use Jilebi by downloading and running it as their MCP server's core. You can then install and manage various plugins through its command-line interface (CLI). For AI developers specifically, Jilebi provides an environment where AI agents can be deployed as plugins. The AI can generate code based on a given specification, and Jilebi can then execute that code within its sandboxed environment, managing its interactions with the server. Integration involves configuring Jilebi with your desired plugins and defining the permissions for each. So, you can take AI-generated code, plug it into Jilebi, and have it run safely within your existing MCP setup, unlocking new capabilities without manual server reconfigurations.
Product Core Function
· Plugin Sandboxing: Isolates plugin execution to prevent interference with the main server or other plugins, enhancing security and stability. This is valuable for running untrusted code safely.
· Permission Management: Allows granular control over resources (files, network, etc.) that each plugin can access, ensuring a secure execution environment. This is critical for preventing data breaches or unauthorized actions.
· Environment Variable Management: Manages the environment variables plugins operate within, providing a consistent and predictable runtime. This helps in reproducible development and deployment.
· Plugin State Management: Keeps track of each plugin's internal state, allowing for seamless resumes and more sophisticated plugin behavior. This enables more complex and interactive agent functionalities.
· AI Code Integration: Facilitates the integration of AI-generated code by providing a standardized runtime and sandbox. This accelerates the development of AI-powered applications by allowing AI to directly contribute executable logic.
Product Usage Case
· AI Agent Development: An AI agent is tasked with generating code to perform a specific function, like data analysis. Jilebi can then execute this AI-generated code in a sandbox, allowing the agent to directly contribute to the system's functionality without manual code review or complex deployment steps.
· Modular MCP Server Enhancement: A developer wants to add new features to an MCP server using community-developed plugins. Jilebi allows these plugins to be installed and run securely, even if their origin or quality is unknown, preventing system instability or security risks.
· Rapid Prototyping with AI: Imagine prototyping a new feature by describing it to an AI. Jilebi can take the AI's output code, run it in isolation, and allow developers to quickly test and iterate on the functionality before integrating it formally.
· Secure Third-Party Tool Integration: When using external tools or libraries as plugins within an MCP system, Jilebi's sandboxing ensures that these tools only have access to the necessary resources, mitigating potential security vulnerabilities.
· Decoupled Development Workflow: Jilebi enables teams to work on plugins independently, with the confidence that they can be easily sandboxed and integrated into the main server. This speeds up development cycles and simplifies collaboration.
38
PINN-Singularity-Explorer
Author
Flamehaven01
Description
This project is an open-source re-implementation of groundbreaking research in detecting unstable singularities in fluid dynamics using Physics-Informed Neural Networks (PINNs). It addresses the challenge of non-reproducible ML research by providing executable code that can predict finite-time blow-ups in partial differential equations (PDEs) with high numerical precision. It makes complex, century-old physics problems more accessible for study and verification.
Popularity
Points 1
Comments 0
What is this product?
This project implements a novel approach to detect critical points, known as singularities, in fluid dynamics simulations. Instead of relying solely on traditional, often computationally intensive, mathematical methods, it leverages Physics-Informed Neural Networks (PINNs). PINNs are a type of machine learning model that not only learns from data but also incorporates the underlying physical laws (like the equations governing fluid motion) into their training process. The innovation lies in its ability to achieve extreme numerical precision (residuals as low as 10^-13), discover hidden parameters through automated inference, and predict lambda (a key indicator of instability) with less than 1% error compared to established methods. This allows researchers to tackle previously intractable fluid dynamics problems and verify complex scientific findings.
How to use it?
Developers can use this project as a framework for their own research in fluid dynamics or scientific machine learning. It's built with PyTorch and CUDA for GPU acceleration, making it efficient for complex computations. You can integrate its PINN solver into your own simulations to analyze the stability of fluid flows or other physical systems governed by PDEs. The project includes comprehensive tests, automated CI/CD, and clear documentation, making it easier to reproduce results and build upon existing work. It's ideal for anyone who wants to explore the frontiers of scientific ML or needs a robust tool for high-precision numerical analysis in physics.
Product Core Function
· Lambda prediction formulas: Accurately estimates instability indicators with less than 1% error, allowing for early detection of critical points in simulations.
· Automated parameter discovery via funnel inference: Identifies unknown variables in physical models by intelligently searching parameter spaces, simplifying model building.
· High-precision Gauss-Newton optimization: Solves complex equations with an extraordinary level of accuracy, ensuring reliable and trustworthy simulation results.
· Multi-stage training with configurable precision targets: Allows for fine-tuning the learning process to achieve specific levels of accuracy required for demanding scientific applications.
· PINN solver framework: Provides a ready-to-use engine for building and training physics-informed neural networks, accelerating research in scientific machine learning.
Product Usage Case
· A researcher studying turbulence in weather models can use this tool to precisely identify when and where instabilities might lead to extreme weather events, improving forecasting.
· A computational physicist working on simulating nuclear fusion can employ this detector to pinpoint potential runaway reactions in their plasma models, ensuring safety and efficiency.
· An engineer designing advanced aircraft wings can use the high-precision optimization to better understand and predict aerodynamic instabilities at high speeds, leading to safer and more efficient designs.
· A student learning scientific machine learning can experiment with this project to gain hands-on experience in applying PINNs to solve complex, real-world physics problems and understand reproducible research practices.
39
BrowserLLM Forge
Author
blurayfin
Description
BrowserLLM Forge is a privacy-focused collection of AI tools that run entirely within your web browser. It leverages cutting-edge web technologies like Transformers.js and WebGPU to enable local processing of text, vision, and audio models. The core innovation lies in its complete client-side execution, meaning no data ever leaves your device, offering unparalleled privacy and offline capabilities. This is a playground for experimenting with AI without the need for servers or data sharing.
Popularity
Points 1
Comments 0
What is this product?
BrowserLLM Forge is a project that brings powerful AI models, like those used for understanding text, images, and sound, directly to your browser. Think of it like having a mini artificial intelligence assistant that lives entirely on your computer, not on some faraway server. The magic behind it is a JavaScript library called Transformers.js, which allows these complex AI models to run efficiently using your computer's graphics card (via WebGPU) or a general-purpose computing technology (WebAssembly, or WASM). This means you can use AI for tasks like summarizing text or analyzing images without sending your sensitive data anywhere, and once the AI models are downloaded, you can even use them offline. So, what's the benefit for you? It means you can explore AI's capabilities with complete peace of mind about your data's privacy, and even use it when you're not connected to the internet.
How to use it?
Developers can integrate BrowserLLM Forge's capabilities into their own web applications by leveraging the underlying JavaScript libraries. For instance, if you're building a content creation tool, you could use it to automatically generate summaries or analyze sentiment from user-submitted text. If you're developing a photo editing app, you could integrate vision models to automatically tag images or detect objects. The project is designed for easy integration, acting as a client-side AI engine. You'd typically initialize the models and then call specific functions to process your data. The immediate value for developers is the ability to offer advanced AI features directly within their web products without the overhead and privacy concerns of server-side AI processing.
Product Core Function
· Local Text Model Processing: Enables AI to understand and generate text directly in the browser, valuable for summarization, sentiment analysis, and text generation in applications without sending data to servers.
· Client-Side Vision Analysis: Allows AI to interpret images and videos within the browser, useful for automatic image tagging, object detection, and visual content moderation in web applications, ensuring user privacy.
· In-Browser Audio Processing: Facilitates AI analysis of audio data locally, ideal for voice command recognition or audio transcription features in web-based tools without data transmission.
· Offline AI Capabilities: Once models are downloaded, AI functionalities are available even without an internet connection, enhancing user experience for applications used in diverse environments.
· Privacy-Preserving AI: All AI computations happen on the user's device, guaranteeing that sensitive personal data never leaves their control, a critical feature for applications handling personal information.
Product Usage Case
· A web-based journaling app could use local text models to automatically generate summaries of journal entries, providing users with quick overviews without ever uploading their personal thoughts.
· An e-commerce platform could integrate local vision models to automatically tag product images, improving searchability and categorization without sending sensitive product imagery to external services.
· A browser extension for researchers could use in-browser audio processing to transcribe spoken notes directly into a document, keeping research data private and accessible offline.
· A collaborative online whiteboard tool could leverage local text and vision models for real-time content analysis and suggestion, enhancing teamwork while ensuring all work remains on the user's machine.
40
RepoSlice-LLM
Author
peterdunson
Description
A web-based tool that renders GitHub repositories into an interactive HTML view, allowing developers to selectively choose which files to include for Large Language Model (LLM) processing. It intelligently skips irrelevant files like lock files and dependency directories. The core innovation lies in its ability to efficiently curate code snippets for LLMs, overcoming token limits and reducing hallucinations by providing focused, relevant input. This solves the problem of manually picking files for LLM analysis, which is time-consuming and error-prone.
Popularity
Points 1
Comments 0
What is this product?
RepoSlice-LLM is a project that takes a GitHub repository, turns it into a web page, and then lets you easily select which specific files you want to send to an AI language model. Think of it like creating a custom "code package" for the AI. It automatically hides things you usually don't need, like those huge dependency files (node_modules) or configuration files that aren't actual code. The AI-ready output (called CXML) updates dynamically as you check and uncheck boxes. This is a clever way to tackle the problem where AI models can't handle the entire code of a big project at once (token limits), and manually picking files is a pain. It ensures the AI gets the right code to work with, reducing mistakes and improving its understanding.
How to use it?
Developers can use RepoSlice-LLM by pointing it to a GitHub repository. The tool will render the repository's file structure as an interactive HTML page. Developers can then click checkboxes next to the files they want the LLM to analyze. They can also use quick filters, like "Python only" or "No tests," to further refine the selection. Once the desired files are selected, the clean, curated code content can be copied. This is perfect for scenarios where you're asking an LLM to review code, refactor a specific module, or explain a part of your project. Instead of pasting the whole repo and hoping for the best, you provide a precise and manageable subset of code.
Product Core Function
· Interactive Repository Rendering: Displays a GitHub repository's files and folders in a user-friendly HTML format, making it easy to navigate and understand the project structure. This helps developers quickly grasp the organization of a codebase without needing to clone it locally.
· Selective File Inclusion via Checkboxes: Allows developers to precisely select individual files or directories they want to include for LLM processing. This is crucial for managing LLM token limits and ensuring that only relevant code is analyzed, leading to more accurate and focused AI outputs.
· Automatic Bloat Skipping: Intelligently identifies and excludes common, large, and often irrelevant files or directories like `package-lock.json` or `node_modules`. This significantly reduces the amount of data that needs to be processed, saving time and computational resources for the LLM.
· Quick Filtering Options: Provides pre-defined filters such as "Python only" or "No tests" to rapidly narrow down the file selection. This streamlines the process of isolating specific types of code for analysis or review, improving developer efficiency.
· Dynamic LLM-Ready Output (CXML Generation): Generates a clean, consolidated representation of the selected code (CXML format) that is optimized for LLM input. This ensures that the AI receives well-formatted and contextually relevant code, minimizing the risk of misunderstandings or hallucinations.
Product Usage Case
· Code Review with AI: A developer needs an LLM to review a specific feature implemented in a Python module within a large Django project. They use RepoSlice-LLM to render the repository, then select only the relevant Python files for that feature and the associated template files. The generated CXML is then fed to an LLM to get targeted feedback, avoiding the token limits of the entire project.
· Explaining a Codebase to a New Team Member: To quickly onboard a new developer, a team lead uses RepoSlice-LLM to create a focused view of the core components of their application. They select the primary service files and critical utility functions. This curated view, presented via the generated CXML, helps the new member understand the essential parts of the codebase without being overwhelmed by the full project complexity.
· Debugging a Specific Bug: When an LLM is used to help debug a complex issue, developers can use RepoSlice-LLM to isolate the files that are most likely related to the bug. By deselecting unrelated modules and focusing on the relevant code paths, they provide the LLM with a precise context to analyze, increasing the chances of finding the root cause of the problem.
· Refactoring Assistance: A developer wants to refactor a specific microservice. They use RepoSlice-LLM to select all files belonging to that service. The LLM then receives this precisely defined set of code, enabling it to provide more accurate and helpful suggestions for refactoring without getting distracted by code from other services.
41
Radkit: Rust A2A Agent SDK
Author
irshadnilam
Description
Radkit is a Rust-based SDK designed for building agent-to-agent (A2A) communication systems. Its core innovation lies in providing a robust and efficient framework for agents to discover, interact with, and coordinate with each other directly, bypassing traditional centralized intermediaries. This opens up possibilities for decentralized applications and peer-to-peer intelligence sharing. So, what's the value for you? It allows developers to build more resilient, direct, and potentially more private communication channels between intelligent agents, reducing reliance on single points of failure and enabling novel decentralized workflows.
Popularity
Points 1
Comments 0
What is this product?
Radkit is a software development kit (SDK) written in the Rust programming language. Its primary purpose is to facilitate 'agent-to-agent' (A2A) communication. Imagine you have multiple independent software agents, each with its own intelligence or task. Radkit provides the tools and protocols to allow these agents to find each other, talk to each other, and work together seamlessly, directly. This is different from systems where agents have to go through a central server. The innovation here is the direct, native approach in Rust, a language known for its performance and safety, enabling efficient and reliable peer-to-peer interactions between these agents. So, how does this help you? It means you can build systems where independent pieces of software can collaborate and share information without needing a central coordinator, leading to more robust and potentially more scalable decentralized systems.
How to use it?
Developers can integrate Radkit into their Rust projects to enable A2A communication. This typically involves defining agent roles, message structures, and the logic for how agents discover and respond to each other. You would leverage Radkit's libraries to manage network connections, message serialization/deserialization, and agent discovery mechanisms. For example, you might use it to build a decentralized marketplace where buyer agents can directly negotiate with seller agents, or a distributed sensor network where data from multiple sensors are aggregated and processed by specialized agents. So, what's the benefit for you? It provides a ready-made foundation for building complex, interconnected agent systems, saving you the considerable effort of designing and implementing secure and efficient direct communication protocols from scratch.
Product Core Function
· Agent Discovery: Enables agents to find and register themselves within a network of other agents, facilitating peer-to-peer connections without a central registry. The value here is in creating dynamic and resilient agent networks.
· Secure Messaging: Provides mechanisms for agents to exchange messages securely, ensuring confidentiality and integrity of communications. This is crucial for sensitive data exchange between agents.
· Protocol Abstraction: Offers a standardized way for agents to define and implement their communication protocols, simplifying the development of interoperable agent systems. This means different agents can talk to each other more easily.
· Asynchronous Communication: Supports non-blocking message passing, allowing agents to perform other tasks while waiting for responses, leading to higher overall system efficiency and responsiveness. This prevents agents from getting 'stuck' waiting for each other.
Product Usage Case
· Building a decentralized autonomous organization (DAO) where member agents can vote on proposals and coordinate actions directly. Radkit would handle the secure proposal dissemination and voting aggregation.
· Creating a distributed computing system where specialized agents can discover and utilize each other's processing power for complex computations, like scientific simulations or AI model training. Radkit facilitates the task allocation and result gathering.
· Developing a secure peer-to-peer data sharing platform where agents representing data owners can directly exchange data with agents representing data consumers under predefined rules. Radkit manages the secure and direct connection.
42
WineAppImageForge
Author
exaroth
Description
This project is a utility designed to help developers create self-contained game AppImages that run on Linux using Wine. The core innovation lies in automating the complex process of bundling Windows executables, their dependencies, and the Wine environment into a single, portable AppImage file. This solves the problem of easily distributing and running Windows games on Linux without requiring users to manually install Wine or manage game dependencies.
Popularity
Points 1
Comments 0
What is this product?
WineAppImageForge is a developer tool that simplifies the creation of portable application packages, specifically for Windows games on Linux. It leverages the AppImage technology, which packages an application and all its dependencies into a single file. For games designed for Windows, Wine is an essential compatibility layer that allows these applications to run on Linux. This tool intelligently bundles the game executable, its required DLLs, registry settings, and a compatible Wine environment into a single AppImage. When you run this AppImage on a Linux system, it unpacks itself, sets up the necessary Wine environment, and launches the game. The innovation here is the automation of this otherwise intricate setup process, making it significantly easier to distribute and run Windows games on Linux with a single click, much like a native application. So, for you, this means the ability to share your Windows games with Linux users effortlessly, and for Linux users, it means playing those games without the hassle of complex installations or compatibility issues.
How to use it?
Developers can use WineAppImageForge by providing it with the Windows game executable and any necessary configuration files or dependencies. The tool then guides the developer through the process of specifying which Wine version to use, what runtime libraries are needed, and how to configure the Wine prefix. Once configured, the tool builds the AppImage. The resulting AppImage can then be distributed to end-users. Linux users simply download the AppImage file, make it executable (e.g., `chmod +x game.AppImage`), and run it (e.g., `./game.AppImage`). No installation of Wine or game dependencies is required on the user's system. This is incredibly useful for game developers wanting to reach a broader audience or for individuals who want to create easy-to-share game packages for friends. The integration is straightforward, typically involving a command-line interface or a configuration file that outlines the game's requirements.
Product Core Function
· Automated Wine Environment Bundling: The tool automatically detects and bundles a specific Wine version and its necessary components along with the game. This is valuable because it ensures that the game runs with a consistent and tested environment, eliminating 'it works on my machine' issues. The application scenario is distributing games to users who may not have Wine installed or configured correctly.
· Dependency Management: It identifies and includes essential Windows libraries (DLLs) and runtime components that the game relies on. This is crucial for preventing runtime errors and crashes that occur when dependencies are missing. For developers, this means a more reliable distribution for their games, and for users, it means a higher chance of the game launching successfully.
· AppImage Packaging: The final output is a single, executable AppImage file, which is a universal format for Linux applications. This is valuable because AppImages are portable, self-contained, and do not require installation on the target system. Developers can simply share this one file, and users can run it on almost any modern Linux distribution, significantly simplifying distribution and installation.
· Configuration Flexibility: Allows developers to specify Wine versions, Wine prefixes, and other settings to optimize compatibility for specific games. This technical capability is important for addressing the wide array of Windows game requirements. The application scenario is tailoring the packaging for demanding or older Windows games that might have specific Wine version needs.
Product Usage Case
· A small indie game developer wants to release their Windows-based 2D RPG on Linux. They use WineAppImageForge to bundle the game executable, its DirectX runtime dependencies, and a suitable Wine version into an AppImage. They can then share this single AppImage file on their website or platforms like itch.io, allowing Linux users to download and play the game immediately without any manual setup, effectively expanding their market reach.
· A user has a collection of older Windows-only point-and-click adventure games that they want to play on their Linux laptop. They use WineAppImageForge to create individual AppImages for each game. This allows them to keep their game collection neatly organized and portable, playable on any Linux machine they use, without cluttering their system with Wine installations or game-specific configurations. This solves the problem of fragmented game libraries and complex setup for legacy titles.
· A game modder creates a significant modification for a popular Windows game. To make it easy for other players on Linux to install and run the modded version, they use WineAppImageForge to package the modded game into an AppImage. This ensures that everyone, regardless of their Linux expertise, can easily experience the modded game, fostering community engagement and easier adoption of mods.
43
Eurosend: Peer-to-Peer Parcel Network
Author
RoelandK
Description
Eurosend is a novel peer-to-peer platform designed to revolutionize local parcel delivery. It addresses the high cost of traditional shipping by connecting individuals who need to send packages with those who are already traveling along the desired route. The core innovation lies in creating a decentralized logistics network where users can offer and accept delivery services for a fee, aiming to provide cheaper shipping for senders and an income stream for carriers. This project showcases a community-driven approach to solving a common logistical challenge through creative use of existing travel patterns.
Popularity
Points 1
Comments 0
What is this product?
Eurosend is a decentralized parcel delivery network that leverages the concept of crowdsourcing for logistics. Instead of relying on large, centralized shipping companies, it connects individuals needing to send packages with other individuals who are already traveling between two points. The underlying technology could involve a robust matching algorithm that identifies optimal routes and available carriers based on user-submitted origin and destination data. Smart contracts or a secure payment system could be employed to facilitate transactions, ensuring trust and reliability between senders and carriers. The innovation lies in its ability to transform underutilized travel capacity into a viable and cost-effective delivery service, effectively democratizing logistics.
How to use it?
Developers can integrate Eurosend's functionality into their own applications or services. This could involve using an API to query for available carriers on specific routes, submitting new delivery requests, or managing transactions. For example, an e-commerce platform could use Eurosend to offer a cheaper, local delivery option to its customers. Individual users could also interact with the platform through a dedicated app or website to become either senders or carriers, defining their shipping needs or available travel routes and prices. The system's flexibility allows for diverse integration scenarios, from enhancing existing logistics workflows to building entirely new delivery solutions.
Product Core Function
· Route Matching Engine: This component intelligently matches package delivery requests with available carriers based on their travel routes and schedules. The value is in optimizing delivery times and reducing empty travel legs, making shipping more efficient.
· Secure Transaction System: Facilitates payments between senders and carriers, ensuring secure and timely transactions. This provides trust and a reliable economic incentive for participation in the network.
· User Profile Management: Allows users to create profiles, list their travel routes as potential carriers, and specify their shipping requirements as senders. This builds a community and facilitates discovery of matching opportunities.
· Notification System: Keeps users informed about the status of their deliveries, available routes, and potential matches. This ensures transparency and smooth operation of the decentralized network.
Product Usage Case
· An online artisan marketplace can use Eurosend to offer its customers a significantly cheaper and more personalized local delivery option for handmade goods. This solves the problem of high shipping costs for small businesses and enhances customer satisfaction.
· A student traveling home for the holidays could use Eurosend to offset their travel expenses by picking up and delivering small packages along their route. This provides a practical way to earn money while traveling and solves the need for local, affordable shipping.
· A small business owner needing to send urgent documents across town could utilize Eurosend to find an individual already traveling in that direction, ensuring faster delivery than traditional couriers at a lower cost. This addresses the need for quick and economical ad-hoc delivery services.
44
Text2Video AI Forge
Author
qwikhost
Description
A novel video editing tool that leverages AI to transform textual descriptions into visual video edits. This project unlocks a new paradigm in video creation by allowing users to command complex editing actions with simple natural language prompts, bypassing traditional timeline-based interfaces. The innovation lies in its sophisticated Natural Language Processing (NLP) and computer vision integration, enabling the AI to understand and execute editing instructions.
Popularity
Points 1
Comments 0
What is this product?
Text2Video AI Forge is a groundbreaking video editing platform powered by artificial intelligence. It interprets user-defined text prompts and automatically applies those edits to a video. Instead of manually dragging clips, adjusting timelines, or selecting specific effects, you simply describe what you want. For instance, a prompt like 'remove the red car in the background' or 'add a dramatic zoom effect to the main subject' would be understood and executed by the AI. The core innovation is the deep learning models that translate semantic meaning from text into concrete video manipulation operations, making advanced editing accessible to a wider audience.
How to use it?
Developers can integrate Text2Video AI Forge into their workflows via an API. This allows for programmatic control over video editing. Imagine building a content generation pipeline where videos are automatically edited based on user feedback or pre-defined content strategies. For example, a marketing team could use this to quickly generate variations of promotional videos by simply changing text parameters. Or a streamer could use it to automatically highlight key moments by describing them, saving significant post-production time. Integration involves sending text prompts and the video file to the API, and receiving the edited video back.
Product Core Function
· Text-based editing commands: Enables users to instruct video edits using natural language prompts. This simplifies complex editing tasks, making them accessible to individuals without extensive video editing expertise, thus democratizing creative control.
· AI-powered video analysis: The system understands video content to accurately apply edits. This ensures that AI-driven edits are contextually relevant and precise, avoiding generic or misplaced modifications, leading to higher quality results.
· Automated effect generation: The AI can generate and apply various video effects based on text descriptions. This provides a powerful way to quickly experiment with different visual styles and moods, accelerating the creative process and enabling rapid prototyping of visual aesthetics.
· Scene understanding for targeted edits: The AI can identify specific objects or actions within a video to perform precise edits. This allows for fine-grained control, such as isolating and modifying specific elements without affecting the rest of the video, leading to sophisticated and professional-looking edits.
Product Usage Case
· A social media content creator wants to quickly generate multiple versions of a promotional video by changing the call to action text and adding emphasis to specific product shots. By using Text2Video AI Forge, they can input prompts like 'replace the ending text with 'Shop Now!', and 'apply a slow-motion effect to the product demonstration segment', drastically reducing the time spent on manual editing and allowing for rapid A/B testing of video variations.
· A documentary filmmaker needs to remove an accidental background element (e.g., a stray person) from several clips without re-shooting. They can use the tool with a prompt such as 'remove the person walking in the background of this scene' to automatically identify and digitally erase the unwanted element, saving considerable post-production effort and preserving the integrity of the footage.
· A game streamer wants to automatically create highlight reels of their best plays. They can potentially hook up a system that monitors gameplay events and then uses Text2Video AI Forge to describe those moments, e.g., 'add a victory fanfare and zoom in on the winning shot', to automatically generate dynamic and engaging clips for their audience, enhancing their content output and engagement.
45
PomodoroZen
Author
Codegres
Description
A minimalist Pomodoro timer built with modern web technologies, offering a distraction-free approach to focused work. It leverages a clean UI and unobtrusive notifications to help users manage their work intervals effectively. The innovation lies in its simplicity and the focus on a seamless user experience, eliminating common digital distractions.
Popularity
Points 1
Comments 0
What is this product?
PomodoroZen is a web-based application designed to help individuals improve their focus and productivity using the Pomodoro Technique. The core principle involves breaking down work into timed intervals, traditionally 25 minutes in length, separated by short breaks. PomodoroZen implements this with a clean, intuitive timer that runs in the browser. Its innovation is in its minimalist design and the careful consideration of user experience to minimize distractions, unlike feature-heavy or overly complex alternatives. This means it's less likely to become a distraction itself, which is crucial for its intended purpose. So, what's in it for you? It's a simple, effective tool to help you get more done by working in focused bursts without the overwhelm of complicated software.
How to use it?
Developers can use PomodoroZen directly in their web browser. Simply navigate to the application's URL. It requires no installation or complex setup. For integration into workflows, developers might bookmark it for quick access during coding sessions. The timer can be started, paused, and reset with minimal interaction. Notifications can be configured to signal the end of work intervals and breaks, ensuring users stay on track without needing to constantly monitor the timer. So, what's in it for you? You get an instant, ready-to-use productivity booster that seamlessly fits into your existing work environment.
Product Core Function
· Customizable Work/Break Intervals: Allows users to set their preferred duration for work sessions and short/long breaks, offering flexibility to adapt to different work styles and tasks. This provides personalized productivity management.
· Unobtrusive Notifications: Utilizes browser notifications to alert users when intervals end, ensuring they are gently reminded to switch tasks without jarring alerts or disruptive pop-ups. This keeps the user in their flow state.
· Minimalist User Interface: Features a clean and uncluttered design, reducing visual noise and cognitive load, enabling users to focus solely on their work. This means less time fiddling with settings and more time doing.
· Session Tracking (potential future enhancement): While not explicitly stated, a potential for basic session tracking could allow users to see their completed Pomodoro cycles, offering a sense of accomplishment and helping to identify patterns in their productivity. This provides insights into personal work habits.
· Cross-Browser Compatibility: Built with web technologies, ensuring it works across various modern browsers without requiring specific plugins or downloads. This offers accessibility and convenience.
Product Usage Case
· During a long coding sprint: A developer can set their PomodoroZen timer to 25-minute work sessions and 5-minute breaks. This helps them maintain focus on complex tasks, prevents burnout by enforcing regular short rests, and allows them to come back to the code with a fresh perspective. It solves the problem of getting lost in code for hours without a break, which can lead to errors and reduced efficiency.
· For studying or learning a new technology: A student or developer can use PomodoroZen to break down study material into manageable chunks. Each 25-minute session is dedicated to a specific topic, followed by a short break to digest information. This makes learning less daunting and improves information retention. It addresses the challenge of information overload and maintaining engagement during extended learning periods.
· Managing remote work distractions: For remote workers, PomodoroZen can act as a gentle reminder to stay on task, even with the inherent distractions of a home environment. The unobtrusive notifications ensure they don't miss important work periods or break times. This helps maintain discipline and structure in a less supervised work setting.
· Reducing mental fatigue during repetitive tasks: When performing tasks that are less engaging but require precision, like data entry or debugging routine issues, PomodoroZen's timed intervals can prevent mental fatigue and maintain accuracy. The breaks offer a mental reset, ensuring continued high-quality output. This tackles the issue of boredom leading to mistakes in repetitive work.
46
Caccepted: Browser-Native Habit Forge
Author
yusufaytas
Description
Caccepted is a local-first challenge and todo tracker. It empowers users to achieve consistency with goals, habits, workouts, and projects directly within their browser, operating offline and without requiring any account creation. The innovation lies in its simplicity and privacy-focused, browser-only execution, offering a streamlined alternative to complex, cloud-dependent tracking applications.
Popularity
Points 1
Comments 0
What is this product?
Caccepted is a digital tool designed to help you stick to your personal goals, be it daily habits, workout routines, or ongoing projects. Its core technical innovation is that it runs entirely in your web browser, meaning all your data is stored locally on your device, not on some remote server. This 'local-first' approach ensures you can use it even when you have no internet connection, and crucially, you don't need to sign up for an account. Think of it as a personal digital notebook that's always available and private, built with web technologies for maximum accessibility. The value here is absolute privacy and constant availability, letting you focus on your goals without worrying about data breaches or internet access.
How to use it?
Developers can integrate Caccepted's principles into their own applications by adopting a local-first architecture. This involves using browser-based storage mechanisms like LocalStorage or IndexedDB to store user data directly on the client-side. For a web application, this means building the UI and logic to interact solely with the browser's capabilities, minimizing or eliminating the need for a backend server for core functionality. Developers could leverage this for simple note-taking apps, personal dashboards, or any tool where user data privacy and offline access are paramount. The practical benefit is creating apps that are faster, more reliable, and inherently more secure for users who value their data's privacy.
Product Core Function
· Local-first data storage: All your goals and progress are saved directly on your device, ensuring privacy and offline access. This means your data is always with you and never leaves your computer, which is great for peace of mind.
· No account creation required: You can start tracking immediately without signing up or providing any personal information. This bypasses the hassle of account management and potential data leaks.
· Offline functionality: Works seamlessly even without an internet connection. You can update your goals or log progress anytime, anywhere, making it incredibly reliable.
· Simple, unified dashboard: Provides a clear overview of all your active challenges, habits, and projects in one place. This helps you visualize your commitments and stay organized without being overwhelmed.
· Habit and challenge tracking: Designed to help you build consistency by tracking daily or weekly activities. This makes it easy to monitor your progress towards habit formation or project completion.
Product Usage Case
· A freelance writer uses Caccepted to track their daily word count goals and weekly article deadlines, ensuring they stay productive even when working from remote locations with spotty internet. This solves the problem of needing consistent tracking without relying on a cloud service that might be inaccessible.
· A fitness enthusiast uses Caccepted to log their workout routines and track progress on 30-day fitness challenges. Because it works offline, they can update their logs immediately after each workout at the gym, without needing to worry about data syncing later.
· A student uses Caccepted to manage their personal projects and study habits. The 'no login' aspect means they can quickly jot down tasks and track progress without the overhead of creating and managing another online account, keeping their digital life simple and focused.
47
AutoRules AI
Author
turblety
Description
AutoRules AI is a cutting-edge tool that leverages Natural Language Processing (NLP) and Artificial Intelligence (AI) to automatically scan and analyze files against a predefined list of questions. Instead of manual review, this project offers an automated way to ensure compliance, quality, or adherence to specific criteria within documents, code, or any text-based data. The core innovation lies in its ability to interpret human-readable questions and translate them into actionable checks against file content.
Popularity
Points 1
Comments 0
What is this product?
AutoRules AI is an intelligent system designed to automate the process of checking various files against a set of questions. It employs sophisticated Natural Language Processing (NLP) techniques to understand the intent behind your questions and then uses AI algorithms to scan through your files, identifying whether the content satisfies those questions. Think of it as a highly intelligent assistant that reads your documents and tells you if they answer specific queries, without you having to read them yourself. The innovation here is moving beyond simple keyword matching to true semantic understanding of both the questions and the file content, enabling more nuanced and accurate analysis.
How to use it?
Developers can integrate AutoRules AI into their workflows by providing it with a list of questions and the target files for analysis. This can be done programmatically via an API or through a command-line interface. For instance, in a software development context, you could use it to check if code documentation addresses specific security concerns, if configuration files adhere to best practices, or if user-generated content meets moderation guidelines. The system processes the files and returns a report indicating which questions were met and which were not, along with relevant excerpts from the files. This saves significant manual effort and ensures consistency in checks.
Product Core Function
· Natural Language Question Parsing: Interprets user-defined questions in plain English, understanding the underlying intent and requirements for the file analysis. This is valuable because it allows for flexible and human-readable rule creation, rather than requiring complex scripting.
· AI-powered Content Analysis: Utilizes machine learning models to semantically understand the content of various file types, going beyond simple keyword searches. This provides a deeper and more accurate assessment of whether the file meets the criteria of the questions.
· Automated File Scanning: Efficiently processes multiple files against the question list, identifying matches and discrepancies. This is useful for quickly checking large volumes of data or for continuous monitoring of files.
· Compliance and Quality Reporting: Generates clear reports detailing which questions were answered and which were not, often with supporting evidence from the file content. This offers actionable insights for improving quality or ensuring adherence to standards.
Product Usage Case
· Code Review Automation: A development team can use AutoRules AI to automatically check if their codebase adheres to specific coding standards or addresses common security vulnerabilities by posing questions like 'Does this function handle potential SQL injection?' or 'Are all critical dependencies updated?'. This significantly speeds up the review process and reduces human error.
· Document Validation: For businesses, AutoRules AI can be used to verify if contracts, terms of service, or marketing materials contain specific legal clauses or product claims by asking questions like 'Does this contract include a force majeure clause?' or 'Are all product features accurately represented?'. This ensures regulatory compliance and brand consistency.
· Data Quality Assurance: Researchers or data analysts can employ AutoRules AI to check if datasets meet certain quality criteria by asking questions like 'Are all required fields populated in this record?' or 'Does this data point fall within an acceptable range?'. This helps maintain the integrity of important data.
· Content Moderation: Platforms that deal with user-generated content can use AutoRules AI to flag content that might violate policies by asking questions like 'Does this comment contain hate speech?' or 'Is this image inappropriate?'. This assists human moderators in identifying problematic content more efficiently.
48
Elector: Stealth-Web Electron Browser
Author
jamescampbell
Description
Elector is a minimalist browser built with modern web technologies, specifically designed to automatically connect to your local Tor service. It offers a streamlined approach to anonymous browsing, leveraging Electron to create a lightweight desktop application. This project addresses the need for a simple, secure way to access the Tor network without the complexity of full Tor Browser setups, especially for users already running Tor on their system.
Popularity
Points 1
Comments 0
What is this product?
Elector is a desktop browser application built using Electron, a framework that allows developers to build native desktop applications using web technologies like HTML, CSS, and JavaScript. The core innovation here is its seamless integration with a local Tor (The Onion Router) service. When you launch Elector, it automatically establishes a connection to your running Tor instance. This means all your web traffic through Elector is automatically routed through the Tor network, providing anonymity and privacy. Think of it as a dedicated, lightweight gateway to the Tor network for your browsing activities. It's built for speed and simplicity, cutting down on the features of larger browsers to focus on secure, private connections.
How to use it?
If you are running Tor on your system, for example, using Homebrew on macOS, Elector should work out-of-the-box. You simply download and run the Elector application. It will detect your running Tor service and automatically route your browsing through it. For users with different Tor configurations, you might need to adjust your Tor configuration file (torrc) to ensure Elector can properly connect. The primary use case is for developers or privacy-conscious individuals who want a quick and easy way to browse the internet anonymously using Tor, perhaps for testing websites for privacy, accessing geo-restricted content, or simply for enhanced personal privacy without needing to install and manage the full Tor Browser bundle.
Product Core Function
· Automated Tor Connection: Automatically establishes a secure connection to a locally running Tor service, simplifying the process of using the Tor network for anonymous browsing. This means your internet traffic is anonymized without manual configuration.
· Lightweight Electron Framework: Built with Electron, Elector is designed to be a very light and responsive desktop application. This provides a fast and uncluttered browsing experience compared to more feature-rich browsers, ensuring it doesn't consume excessive system resources.
· Enhanced Security Features (v2.0): The latest version incorporates modern Electron security features. This implies a focus on mitigating common vulnerabilities and ensuring the integrity of the browsing environment, offering peace of mind for users concerned about their online security.
· Minimalist User Interface: Elector focuses on core browsing functionality with a clean and simple interface. This reduces potential attack vectors and keeps the user experience straightforward, allowing you to focus on your browsing without distractions.
Product Usage Case
· Privacy-Conscious Development Testing: Developers can use Elector to test how their web applications perform and appear when accessed through the Tor network. This helps identify potential privacy leaks or unexpected behavior that might occur when users are browsing anonymously.
· Secure Access to Sensitive Information: For individuals who need to access sensitive information online or perform transactions where anonymity is paramount, Elector provides a straightforward tool to ensure their connection is routed through the Tor network, adding an extra layer of privacy.
· Bypassing Geo-Restrictions for Research: Researchers or users who need to access content or websites that are restricted based on their geographical location can use Elector to appear as if they are browsing from a different location through the Tor network, facilitating unrestricted research.
· Quick Anonymous Browsing for Everyday Use: For users who occasionally want to browse the internet privately without the overhead of setting up complex VPNs or specialized browsers, Elector offers a quick and efficient solution to connect to Tor and browse anonymously.
49
Cirquery - Nested JSON Query DSL
Author
mtsnrtkhr
Description
Cirquery is a novel, human-readable query language designed to navigate and extract data from deeply nested JSON structures. It addresses the common frustration developers face when dealing with complex, multi-layered JSON objects, offering a more intuitive and expressive way to query this data compared to traditional programmatic approaches. Its innovation lies in its declarative syntax, making it easier to read and write queries, and its efficient parsing engine that handles complex nesting with grace.
Popularity
Points 1
Comments 0
What is this product?
Cirquery is a domain-specific language (DSL) that allows developers to write simple, English-like queries to extract specific pieces of information from JSON data that has many layers within layers (nested). Think of it like a specialized search engine for your JSON files. Traditional methods often involve writing lots of repetitive code to dig through these nested structures. Cirquery simplifies this by letting you describe *what* you want, not *how* to find it step-by-step. The core innovation is creating a syntax that feels natural to humans while being powerfully interpreted by the system to pinpoint your data. So, this is useful because it saves you from writing tedious code and makes understanding your data extraction logic much clearer, especially for complex JSON.
How to use it?
Developers can integrate Cirquery into their applications by embedding the Cirquery parsing library into their backend code (e.g., in Python, Node.js, or Go). They would then pass their JSON data and a Cirquery string to the library. The library interprets the Cirquery string and returns the requested data. Common use cases include data processing pipelines, API response parsing, configuration file management, and log analysis where structured but deeply nested data is prevalent. So, this is useful because it allows you to easily and reliably get the specific data you need from complex JSON without writing complicated code, making your application logic cleaner and less error-prone.
Product Core Function
· Human-readable query syntax: Allows developers to write queries in a natural language style, making code more maintainable and understandable. This reduces the learning curve and the time spent debugging complex data access logic, which is valuable for faster development cycles.
· Nested data traversal: Efficiently navigates through arbitrarily deep JSON structures, extracting specific fields or collections without manual pathing. This is crucial for handling modern API responses and complex data formats, saving significant development effort.
· Field selection and filtering: Enables precise extraction of desired fields and the application of conditions to filter data, ensuring only relevant information is retrieved. This optimizes data processing and reduces memory usage by avoiding the need to load entire datasets when only a subset is required.
· Support for various data types: Handles querying across strings, numbers, booleans, arrays, and nested objects within the JSON. This broad compatibility ensures Cirquery can be used with a wide range of JSON data, making it a versatile tool for diverse data analysis tasks.
Product Usage Case
· Extracting a specific user's address from a nested user profile object in a social media API response. Instead of writing code like `response['data']['users'][0]['profile']['addresses'][0]['street']`, you could write a Cirquery like `user profile addresses street`. This makes the intent immediately clear and easier to manage when the JSON structure changes.
· Aggregating all product prices from a deeply nested e-commerce catalog. A query could target all price fields within product objects, even if products are nested within categories and subcategories. This is useful for tasks like price comparison or inventory valuation without needing to manually iterate through multiple levels of arrays and objects.
· Filtering log entries to find all error messages that occurred within a specific request ID. Cirquery could target log entries where `message` contains 'error' and `requestId` matches a given value, even if these fields are buried within different nested structures. This helps in quickly diagnosing issues by efficiently pinpointing relevant log data.
· Parsing complex configuration files with nested settings for different application modules. Cirquery can extract specific configuration values for a particular module without loading the entire configuration, which is efficient and reduces the potential for unintended side effects from incorrect configuration access.
50
ZapForms: Instant API Forms & Webhooks
Author
skrid
Description
ZapForms is a revolutionary tool that allows developers to create public forms with built-in instant APIs and webhook capabilities. It tackles the common problem of efficiently collecting data from users and integrating it into existing workflows without complex backend development. The innovation lies in its ability to generate a unique API endpoint and webhook for each form, enabling seamless data flow and automation.
Popularity
Points 1
Comments 0
What is this product?
ZapForms is a service that lets you build forms for public use, and as soon as someone submits a response, it's instantly available through a ready-to-use API and can trigger automated actions via webhooks. The core technical insight is abstracting away the traditional complexities of setting up a database, backend server logic, and API endpoints for form submissions. Instead, it provides these functionalities out-of-the-box. For instance, when you create a form, ZapForms automatically provisions a dedicated API endpoint for that specific form. This means you don't have to write any server-side code to receive and process form data. The webhook functionality allows you to send form submission data in real-time to any other service or application that can receive HTTP requests, enabling powerful automation workflows.
How to use it?
Developers can use ZapForms by simply signing up, creating a new form through their intuitive interface, and defining the fields they need. Once the form is created, ZapForms provides a unique API endpoint (e.g., a POST request URL) that can be used to submit data directly to the form. Additionally, developers can configure webhook URLs to send form submission data to their own applications or third-party services like Zapier, Integromat, or Slack. This makes it ideal for integrating with existing project management tools, CRMs, notification systems, or custom databases without needing to build a dedicated backend for each form.
Product Core Function
· Instant API Endpoint Generation: Each form automatically gets its own unique API endpoint for receiving data submissions. This means you can collect data programmatically without writing any backend code, which is invaluable for rapid prototyping and data collection.
· Real-time Webhook Support: Form submissions can trigger instant notifications or data transfers to other services via webhooks. This enables powerful automation, allowing you to instantly add leads to your CRM, create tasks in a project management tool, or send alerts, saving significant development and integration time.
· Customizable Form Fields: Users can define various field types (text, email, numbers, checkboxes, etc.) to capture the specific information they need. This flexibility ensures you can collect the right data for any use case, from simple contact forms to more complex surveys.
· Secure Data Handling: ZapForms ensures that form submissions are handled securely. This is crucial for protecting user data and maintaining trust, especially when dealing with sensitive information.
Product Usage Case
· Building a quick contact form for a personal website and having submissions automatically sent to a Google Sheet. This solves the problem of manually copying and pasting data and enables instant tracking of inquiries.
· Creating a feedback form for a web application and using webhooks to instantly log submissions into a dedicated database or a project management tool like Jira. This helps in quickly addressing user feedback and prioritizing improvements.
· Setting up an event registration form where submissions can trigger personalized confirmation emails via a connected email service. This automates the communication process and enhances user experience.
· Developing a simple lead generation form for a marketing campaign. The API endpoint allows for easy integration with an existing CRM, ensuring leads are captured and processed efficiently without manual data entry.
51
Hlsrecord: The Stream Catcher
Author
zzo38computer
Description
Hlsrecord is a command-line tool designed to capture and record audio/video streams from the internet, specifically targeting HLS (HTTP Live Streaming) protocols. Its core innovation lies in its ability to intercept and save these fragmented media streams into a single, playable file, bypassing the typical limitations of browser-based recording. This offers a robust solution for archiving online video content that would otherwise be ephemeral or difficult to access.
Popularity
Points 1
Comments 0
What is this product?
Hlsrecord is a program that acts like a digital VCR for internet streams. It understands a common way that online videos are delivered called HLS, which breaks a video into tiny pieces. Instead of playing these pieces one after another in your browser, Hlsrecord downloads these pieces and stitches them together into one continuous video file that you can save and watch later, even offline. Think of it as grabbing a live TV broadcast and saving it to your personal video library. The innovative part is its direct interaction with the stream's manifest file (a playlist of all the video pieces) to intelligently assemble the full recording, which is more reliable than simply trying to capture screen output.
How to use it?
Developers can use Hlsrecord from their terminal. You would typically point Hlsrecord to the `.m3u8` playlist file of an HLS stream, which is often found in the page source or network inspector of a streaming website. The tool then downloads all the segment files listed in the playlist and merges them into a single output file, usually in a format like MPEG-TS (Transport Stream), which can then be easily converted to more common formats like MP4 for playback on various devices. It's a straightforward command-line interface, making it ideal for scripting or integrating into automated archiving workflows.
Product Core Function
· HLS Stream Capture: Downloads and concatenates media segments defined in an HLS playlist (.m3u8). This allows you to save online video content that is streamed using this popular protocol, providing a reliable way to archive important or interesting broadcasts.
· Segmented Download and Merging: Intelligently fetches individual video chunks and seamlessly combines them into a single output file. This technical approach ensures data integrity and a smooth playback experience, unlike simpler screen recording methods that can be prone to glitches.
· MPEG-TS Output: Generates output in the MPEG Transport Stream format, a standard for broadcasting and streaming. This format is highly compatible with subsequent conversion tools, making it a flexible starting point for further processing of recorded content.
· Command-Line Interface: Provides a text-based interface for easy scripting and automation. Developers can easily integrate Hlsrecord into batch jobs or custom applications for unattended recording, saving valuable development time.
· Error Handling and Reporting: Includes mechanisms to notify the user if something goes wrong during the recording process, allowing for troubleshooting and bug fixes. This iterative approach to development, common in open-source projects, ensures the tool becomes more robust over time.
Product Usage Case
· Archiving live webinars or online lectures for later review or educational purposes. By using Hlsrecord, you can ensure you have a permanent copy of valuable information that might only be available for a limited time online.
· Saving unique or rare video content from streaming platforms that may not offer download options. This empowers users to preserve digital media that would otherwise be lost, acting as a digital preservation tool.
· Integrating into a media server setup to automatically record specific HLS streams on a schedule. This could be for personal use or for building specialized content archives, demonstrating practical automation capabilities.
· Troubleshooting streaming issues by capturing the exact stream data to analyze its components offline. This provides developers with raw data to diagnose problems with streaming services or their own implementations.
· Creating backups of important video communications or events that are streamed online. Hlsrecord offers a reliable method to secure these recordings for future reference, mitigating the risk of data loss.
52
RBAC-FastAPI-Auth-Boilerplate
Author
farhan0167
Description
A ready-to-use authentication server with a built-in Role-Based Access Control (RBAC) framework for FastAPI applications. It simplifies the common task of managing users, roles, and permissions, allowing developers to focus on core application logic rather than re-writing boilerplate auth code.
Popularity
Points 1
Comments 0
What is this product?
This project is an authentication server designed specifically for FastAPI. At its core, it implements Role-Based Access Control (RBAC). Think of it like this: you have different parts of your system (services and resources), and you can perform specific actions on them (like reading or writing data). This project defines these actions as 'permissions' (e.g., 'service.resource.action'). It then lets you group these permissions into 'roles' (like 'admin' or 'editor'). Finally, users are assigned roles, and the system automatically checks if a user has the necessary permissions for an action based on their assigned role. This means you don't have to manually code permission checks everywhere, saving you time and reducing errors. The innovation lies in its pre-built structure that integrates seamlessly with FastAPI, providing a clean and standardized way to handle authentication and authorization.
How to use it?
Developers can integrate this boilerplate into their FastAPI projects. It acts as a central auth server. You would typically define your users, roles, and the specific permissions associated with each resource in your microservices within this boilerplate. When a user tries to access a protected resource or perform an action, your FastAPI application can query this auth server to verify if the user's assigned role has the required permission. This can be done through API calls to the auth server or by using provided client libraries. The goal is to make adding secure access control to your applications as simple as plugging in a module.
Product Core Function
· User Management: Securely stores and manages user accounts, allowing for registration, login, and profile updates. Value: Reduces the need for developers to build user registration and authentication from scratch.
· Role Definition: Enables the creation and assignment of roles to users (e.g., 'admin', 'editor', 'viewer'). Value: Organizes user access levels logically, making it easier to manage permissions for groups of users.
· Permission Granularity: Defines permissions at a fine-grained level, typically in the format 'service.resource.action' (e.g., 'user_management.users.create'). Value: Provides precise control over what actions users can perform on specific parts of the application.
· RBAC Enforcement: Automatically checks user permissions against required actions based on their assigned roles. Value: Centralizes authorization logic, ensuring consistent security policies across the application and reducing repetitive code.
· FastAPI Integration: Designed to work seamlessly with FastAPI, leveraging its async capabilities and Pydantic models. Value: Developers can quickly incorporate robust authentication into their existing or new FastAPI projects with minimal effort.
Product Usage Case
· Securing a microservice API: Imagine you have a user service and a product service. You can use this boilerplate to define roles like 'product_manager' that can 'create' and 'update' products, while 'customer' roles can only 'read' products. The boilerplate handles checking if a user attempting to modify a product has the 'product_manager' role and the 'product.products.update' permission. This avoids writing complex permission checks within the product service itself.
· Building a multi-tenant application: In an application where different organizations (tenants) use the same codebase, you can assign specific roles and permissions to users within each tenant. For example, a 'tenant_admin' role might be able to manage users and settings only for their own tenant, while a 'tenant_user' role has limited access. The RBAC framework ensures users are restricted to their tenant's resources.
· Developing an administrative dashboard: For applications with administrative backends, this boilerplate is ideal for controlling access to different sections of the dashboard. For instance, a 'content_editor' role might have permissions to write and publish articles, while a 'support_agent' role can only view customer tickets. The system enforces these restrictions automatically.
53
Agentic Church Oracle
Author
joesuh
Description
This project is an AI-powered search engine that uses a sophisticated 'agentic RAG' (Retrieval Augmented Generation) approach to answer questions about churches in Boulder, CO. It leverages data from church websites, YouTube channels, and Google reviews. The core innovation lies in its advanced data processing techniques, like MapReduce and Mixture of Experts, which allow it to intelligently query and synthesize information from multiple sources, providing consolidated and relevant answers to user queries. This means you can get detailed, nuanced information about churches without having to sift through individual websites yourself.
Popularity
Points 1
Comments 0
What is this product?
This project is a specialized search engine built with advanced AI techniques. It functions like a smart assistant for anyone looking for information about churches in Boulder, Colorado. Instead of just searching for keywords, it understands your questions and 'agents' go out to gather information from various sources like each church's website, their YouTube sermons, and customer reviews on Google. It uses clever methods like 'MapReduce' to break down complex questions, send them to individual church databases, and then combine the results into a single, easy-to-understand answer. Another method, 'Mixture of Experts', intelligently decides which type of information (sermons, website text, reviews) is best for answering your question. So, it's a way to get very specific answers about churches, tailored to your needs, much faster and more effectively than traditional search.
How to use it?
Developers can interact with this tool through a web interface (accessible at pastors.ai/churches/boulder). You can type in questions about specific churches or general inquiries, such as 'which churches are family-friendly?' or 'what are the sermon topics this week?'. The system then processes your query using its agentic RAG capabilities, fetches relevant data from the targeted church's information sources, and returns a synthesized answer. For integration into other applications or for experimental purposes, the underlying technology could potentially be exposed via an API in future versions, allowing developers to build custom church information tools or integrate this advanced retrieval mechanism into their own projects.
Product Core Function
· Agentic RAG for targeted information retrieval: This allows the system to understand nuanced questions and retrieve specific information from a vast set of unstructured data sources, providing precise answers that would otherwise require manual research. This is useful for getting detailed insights into church activities, beliefs, or community programs.
· MapReduce query processing: This technique breaks down a user's query into smaller pieces, sends them to individual 'worker' nodes (representing each church's data), and then combines the results. This efficiently handles complex queries across multiple distinct data sets, making it valuable for comparative analysis or broad information gathering on specific church attributes.
· Mixture of Experts (MoE) for result synthesis: This approach intelligently routes parts of a query to specialized AI models (one for sermons, one for websites, one for reviews) and then combines their outputs. This ensures that the most relevant type of information is used to answer the question, leading to more comprehensive and accurate responses. This is helpful when you need a holistic understanding of a church, covering various aspects of its operations and public perception.
· Dynamic query rewriting and reranking: Behind the scenes, the system intelligently refines user queries and the retrieved information to ensure the best possible match and presentation of results. This enhances the user experience by providing more relevant information even if the initial query isn't perfectly phrased, making it easier for anyone to find what they are looking for.
Product Usage Case
· A prospective attendee looking for an LGBTQ-friendly church: Instead of browsing individual church websites, they can ask 'Are there any LGBTQ-friendly churches in Boulder?' The system will query each church's known stance or related content from their website and reviews, then provide a consolidated list of churches that identify as LGBTQ-friendly or have relevant information, solving the problem of finding inclusive communities.
· A researcher studying religious trends in Boulder: They can ask broad questions like 'What are the common sermon themes in Boulder churches?' The MapReduce approach can efficiently gather information from sermon transcripts or descriptions across multiple churches, providing aggregated insights that would be extremely time-consuming to collect manually.
· A newcomer to Boulder wanting to find a church with a strong community outreach program: They can ask 'Which churches have active community service programs?' The system can analyze website content and news or review sections for mentions of volunteer work, charity events, or partnerships, helping them find a church that aligns with their desire to get involved.
· Someone interested in a specific church's recent activities: They could ask 'What was discussed in the recent sermons at [Church Name]?' The system would retrieve and analyze recent sermon content, providing a summary or key topics, solving the need for quick updates on a church's theological focus.
54
PixelPerfect Downscaler
Author
lymanli
Description
An in-browser tool that intelligently downscales pixel art. It automatically detects the upscaling factor and uses nearest-neighbor scaling to precisely restore original pixel dimensions, preserving sharp edges and accurate colors without requiring any installation.
Popularity
Points 1
Comments 0
What is this product?
PixelPerfect Downscaler is a web-based application that specializes in resizing pixel art. Unlike typical image resizing tools that can blur or distort pixel art, this tool uses a technique called nearest-neighbor scaling. This method looks at the closest pixel and duplicates its color. This ensures that each individual pixel remains distinct and sharp, effectively 'undoing' the artificial enlargement that often happens to pixel art. The innovation lies in its ability to automatically detect how much an image has been enlarged and then apply the correct downscaling factor to return it to its original, crisp pixelated state, all within your web browser. So, the value is getting your pixel art back to its intended sharp look without messing it up.
How to use it?
Developers can use PixelPerfect Downscaler by simply visiting the website. They can upload their pixel art images directly into the browser. The tool will then automatically analyze the image to determine the original pixel size and perform the nearest-neighbor downscaling. The output is a crisp, accurately resized pixel art image that can be downloaded. This is useful for game developers working with retro-style graphics, or anyone needing to prepare pixel art assets for different resolutions or platforms. You upload, it fixes, you download – easy.
Product Core Function
· Automatic Upscaling Factor Detection: The tool intelligently figures out how much the pixel art has been enlarged, so you don't have to guess. This ensures the correct downscaling is applied, preserving the art's integrity.
· Nearest-Neighbor Scaling: This core algorithm ensures each pixel is preserved as a distinct block of color, preventing blurriness and maintaining the sharp, defined edges characteristic of pixel art.
· In-Browser Execution: The entire process happens within your web browser, meaning no software needs to be installed. This makes it incredibly accessible and convenient for quick edits or when working on different machines.
· Preservation of Color Accuracy: The tool is designed to maintain the original color palette of the pixel art, ensuring that the downscaled image looks as intended and vibrant as the original.
· Intuitive User Interface: Uploading and downloading images is straightforward, making the tool easy to use even for those less familiar with image manipulation software.
Product Usage Case
· A game developer has a set of pixel art sprites that were created at a lower resolution but have been scaled up for a project. They need to downscale these sprites to fit a new, tighter UI element without losing their distinct pixel look. PixelPerfect Downscaler can be used to upload these sprites, automatically detect the scaling, and output them at their true pixel size, ready for integration.
· A digital artist wants to share their pixel art on a platform that requires smaller image dimensions, but standard resizing tools would ruin the pixelated effect. They can use PixelPerfect Downscaler to precisely shrink the image while keeping the pixel grid intact, ensuring the art looks as intended on the platform.
· A web designer needs to incorporate retro-style pixel art into a website. The original assets might be too large or have been inconsistently scaled. PixelPerfect Downscaler allows them to quickly normalize these assets to a consistent, sharp pixel size directly in their browser before implementing them into the website's layout.